目录
lpop 和 rpop 自然是从左边和从右边删除数据。编辑
简介
提到数据库,大家可能会想到 mysql,它是通过表和字段来存储信息的,表和表之间通过 id 关联,叫做关系型数据库。
它提供了 sql 语言,可以通过这种语言来描述对数据的增删改查。
mysql 是通过硬盘来存储信息的,并且还要解析并执行 sql 语句,这些决定了它会成为性能瓶颈。
也就是说服务端执行计算会很快,但是等待数据库查询结果就很慢了。
那怎么办呢?
计算机领域最经常考虑到的性能优化手段就是缓存了,能不能把结果缓存在内存中,下次只查内存就好了呢?
内存和硬盘的速度差距还是很大的:

所以做后端服务的时候,我们不会只用 mysql,一般会结合内存数据库来做缓存,最常用的是 redis。
因为需求就是缓存不同类型的数据,所以 redis 的设计是 key、value 的键值对的形式。
并且值的类型有很多:字符串(string)、列表(list)、集合(set)、有序集合(sorted set)、哈希表(hash)、地理信息(geospatial)、位图(bitmap)等。
我们分别来试一下。
redis 是分为服务端和客户端的,它提供了一个 redis-cli 的命令行客户端。
首先我们把 redis 服务跑起来。
通过 docker 的形式来跑:
下载一个 docker desktop 桌面端工具:
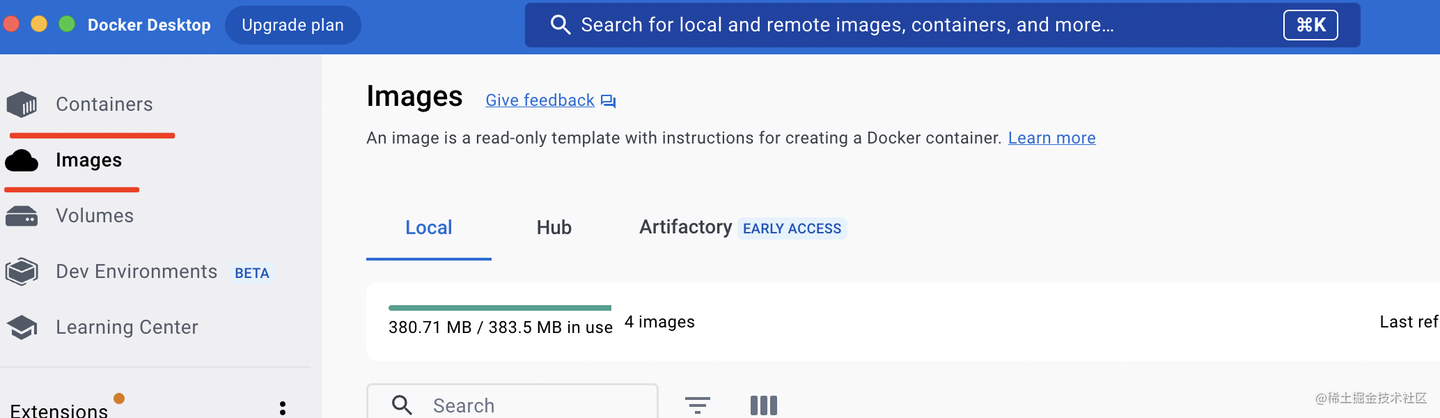
左边分别是镜像和镜像跑起来后的容器。
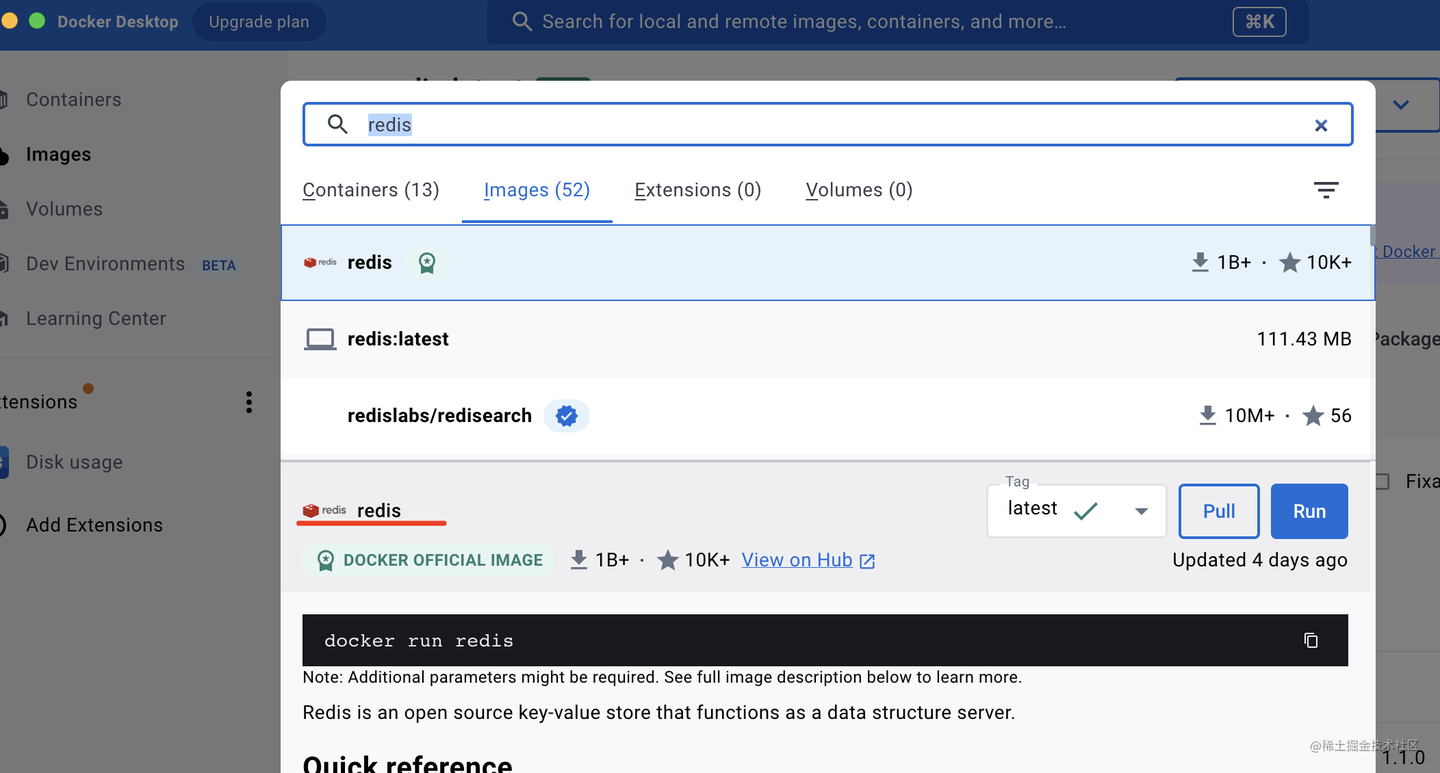
在搜索框搜索 redis,点击 run,把 redis 官方镜像下载并跑起来。
它会让你填一些容器的信息:
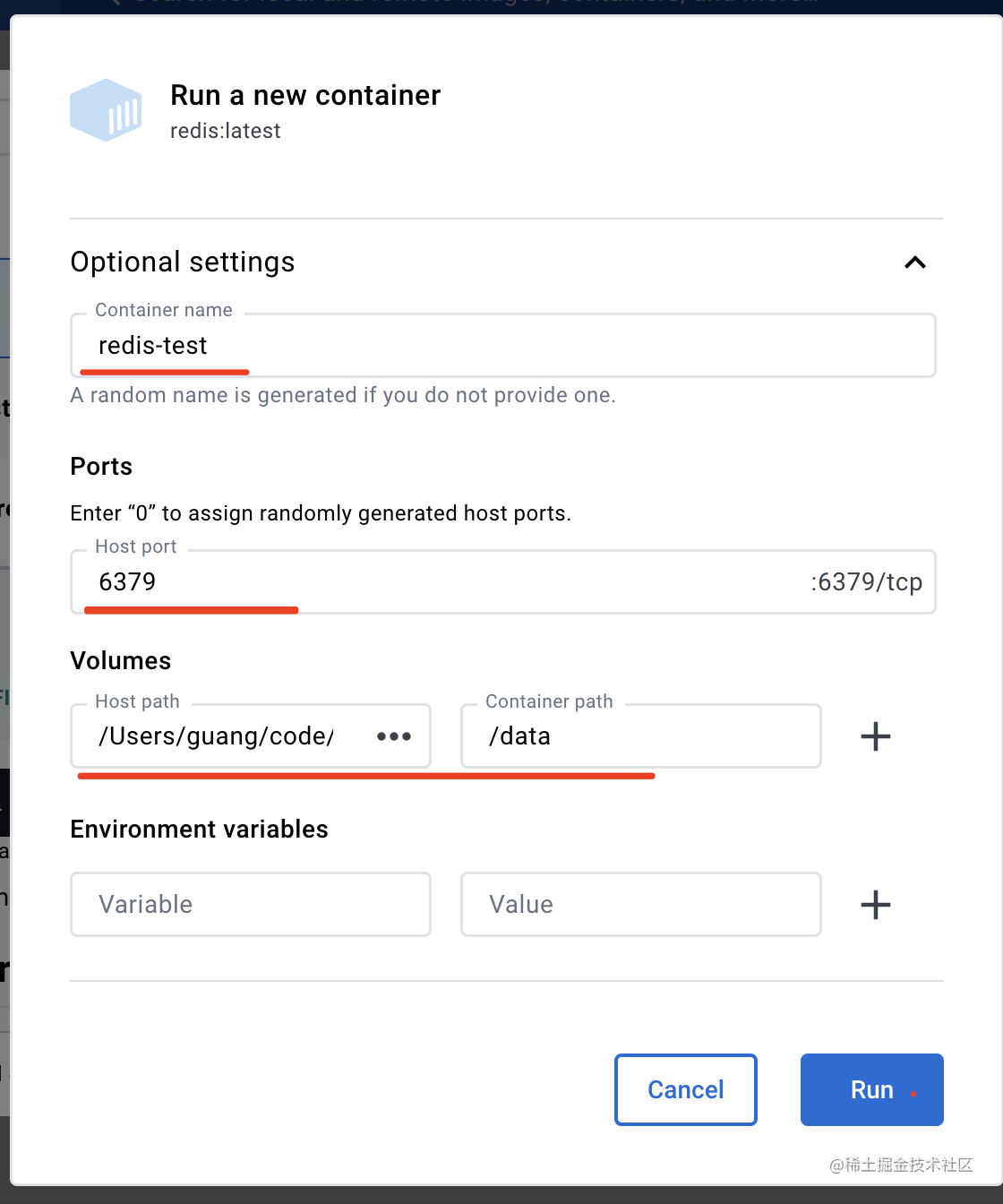
名字没啥好说的。
端口映射就是把主机的 6379 端口映射到容器内的 6379 端口,这样就能直接通过本机端口访问容器内的服务了。
volume 是数据卷,也就是挂载本地目录到容器的一个目录。
为什么要挂载数据卷呢?
因为镜像是不可修改的,每次运行都是全新的,但如果每次跑 redis 镜像,之前的数据都清空了可咋办?
所以要把本机的一个目录挂载上去,数据保存在本机。
跑起来之后是这样的:
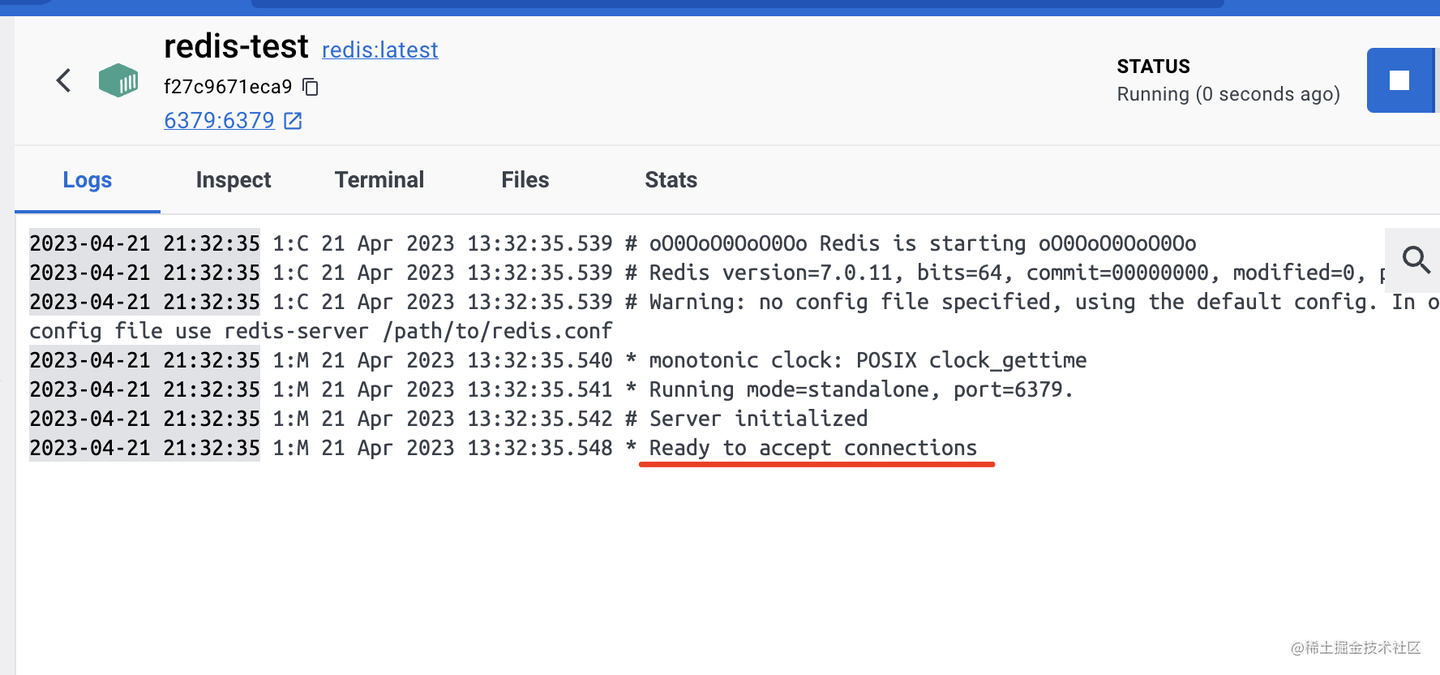
容器内打印的日志说明 redis 服务跑起来了。
files 里可以看到所有的容器内的文件:
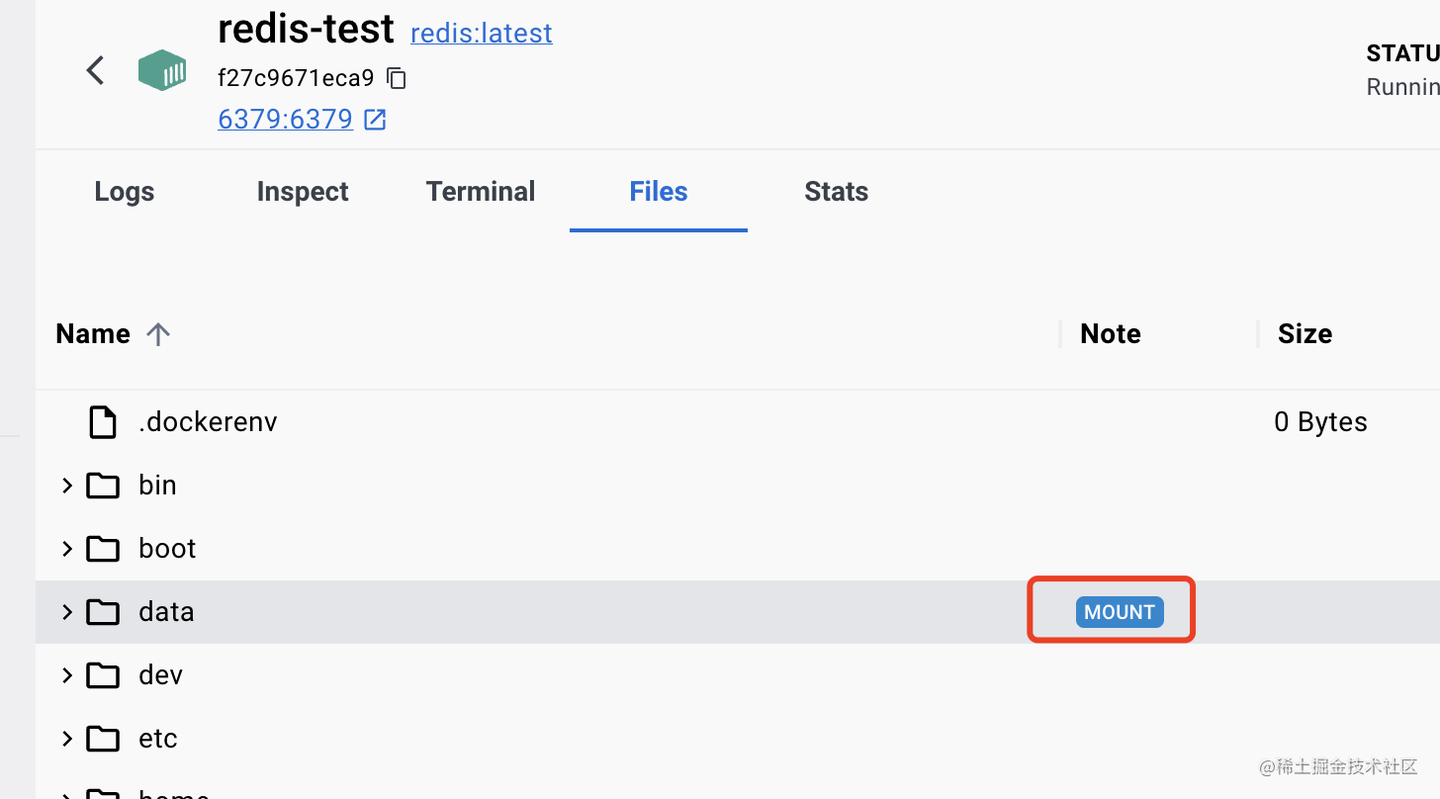
看到这个 mounted 的标志了没?
就代表这个目录是挂载的本地的一个目录。
我们在本地目录添加一个文件。

在容器内的 data 目录就能访问到这个文件了:
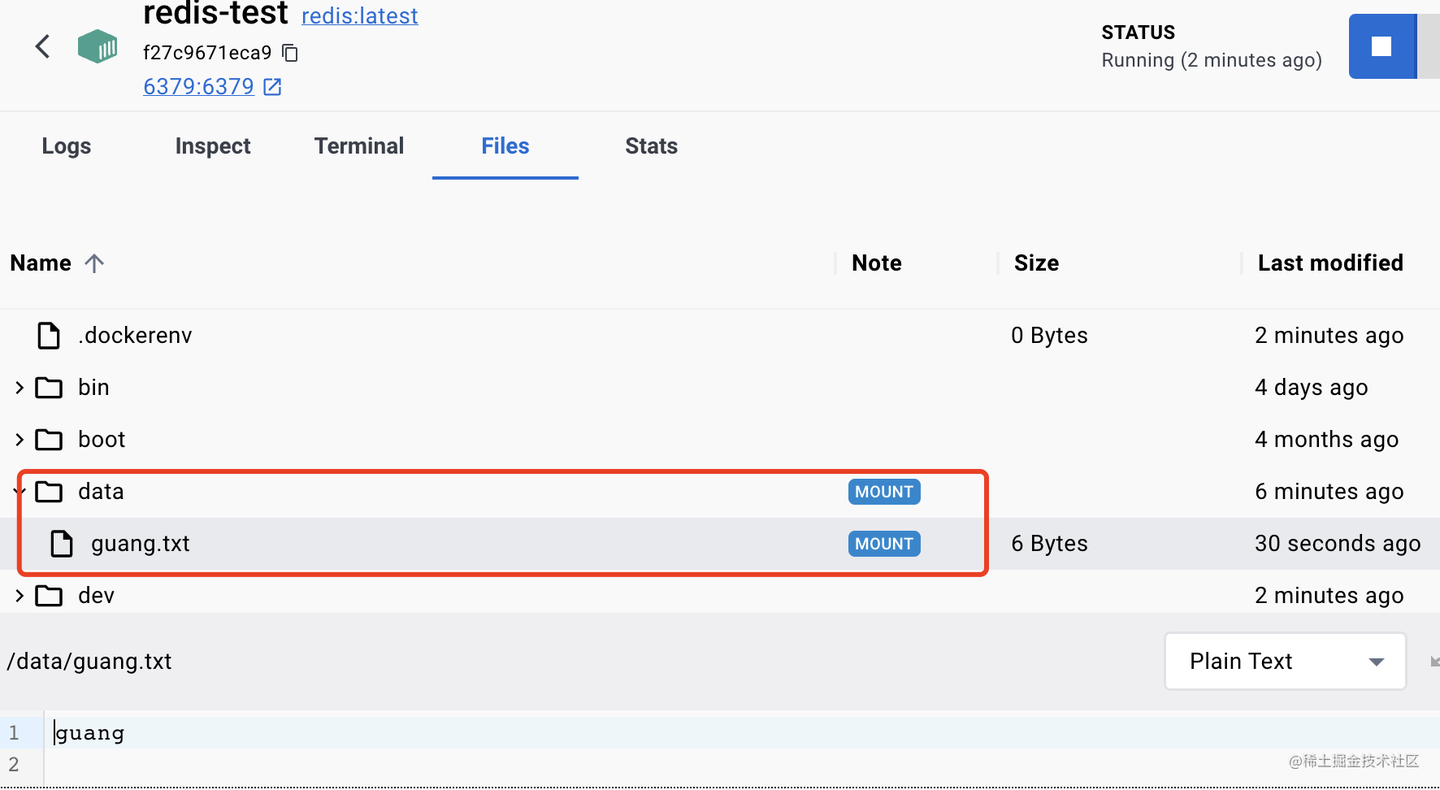
同样,在容器内修改了 data 目录,那本机目录下也会修改。
redis 服务跑起来之后,我们用 redis-cli 操作下。
在 terminal 输入 redis-cli,进入交互模式:
我们在这里做下 string 相关的操作:
文档里的命令有这么几个:

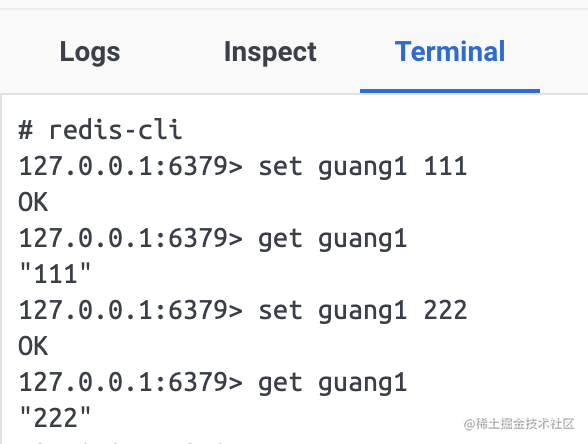
set、get 都挺简单:
incr 是用于递增的:
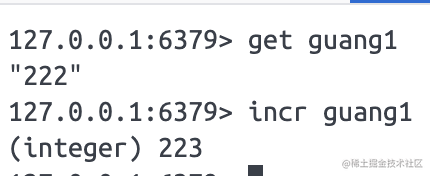
平时我们用的阅读量、点赞量等都是通过这个来计数的。
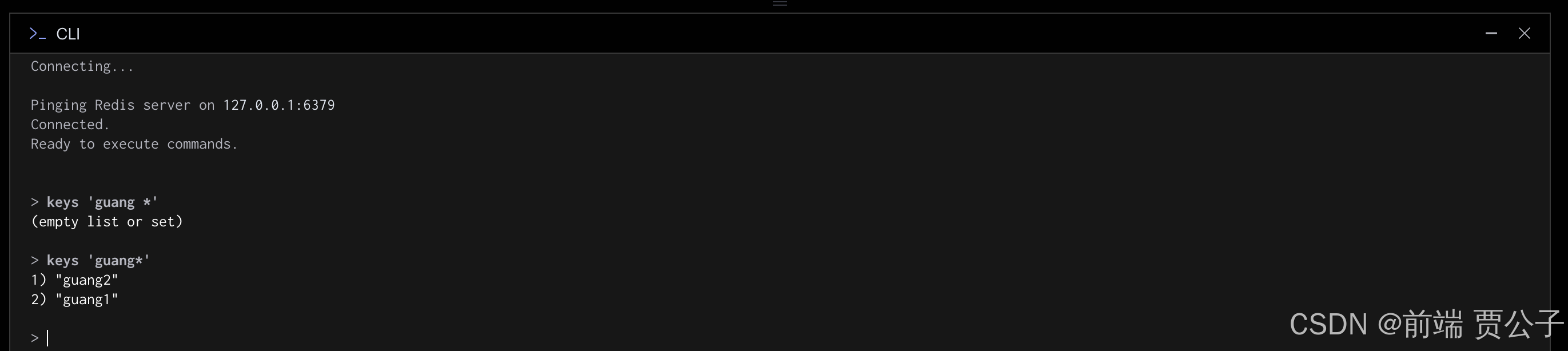
keys 来查询有哪些 key:
当我存了几个 key 后,可以通过 keys 来查询有哪些 key:

keys 后加一个模式串来过滤,常用的是 '*' 来查询所有 key。
redis insight GUI 工具。
这里我们切换成 GUI 工具吧,那个更直观一些。
这个就像 git 有人喜欢用命令行,有人喜欢用 GUI 工具一样。只是习惯问题,都可以。
我用的是 redis insight,一个 mac 上的开源 redis GUI 工具。
输入 ip 和端口之后点击连接:
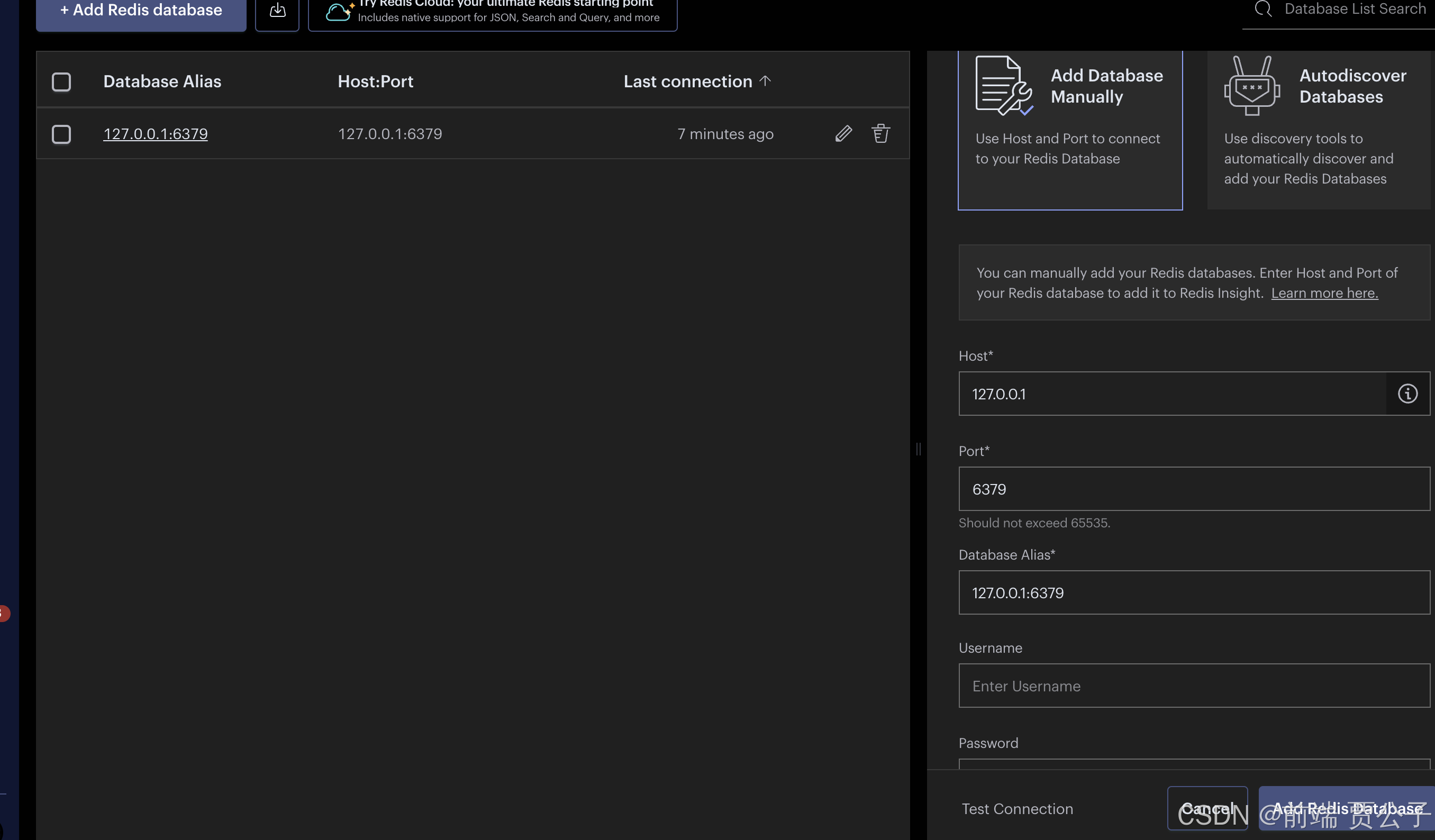

同样也可以执行命令:
(不想装 GUI 工具的同学直接用 redis-cli 也是一样的,没啥区别)
list 类型
然后我们继续看 list 类型的数据结构:
文档中有这么几个命令:
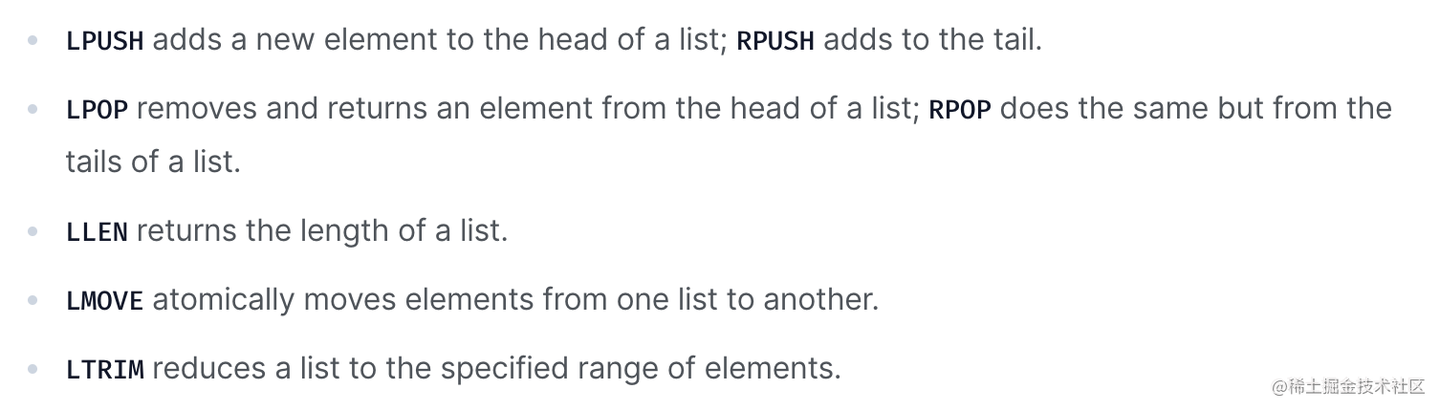
我们试一下:
left push
lpush 是 left push 的意思,执行后会从左到右添加到列表中:
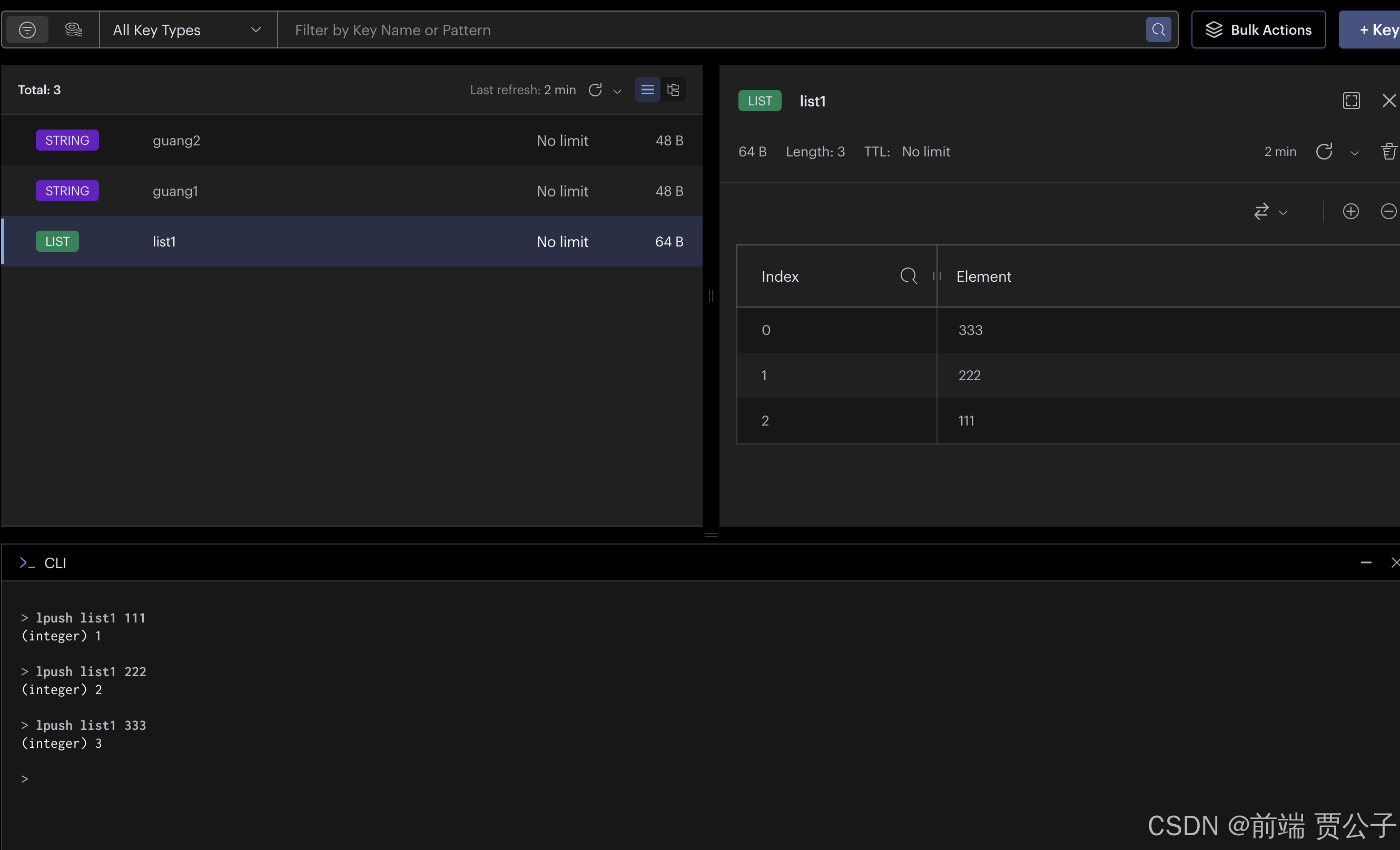
rpush
rpush 是 right push 的意思,执行后会从右往左添加到列表中:
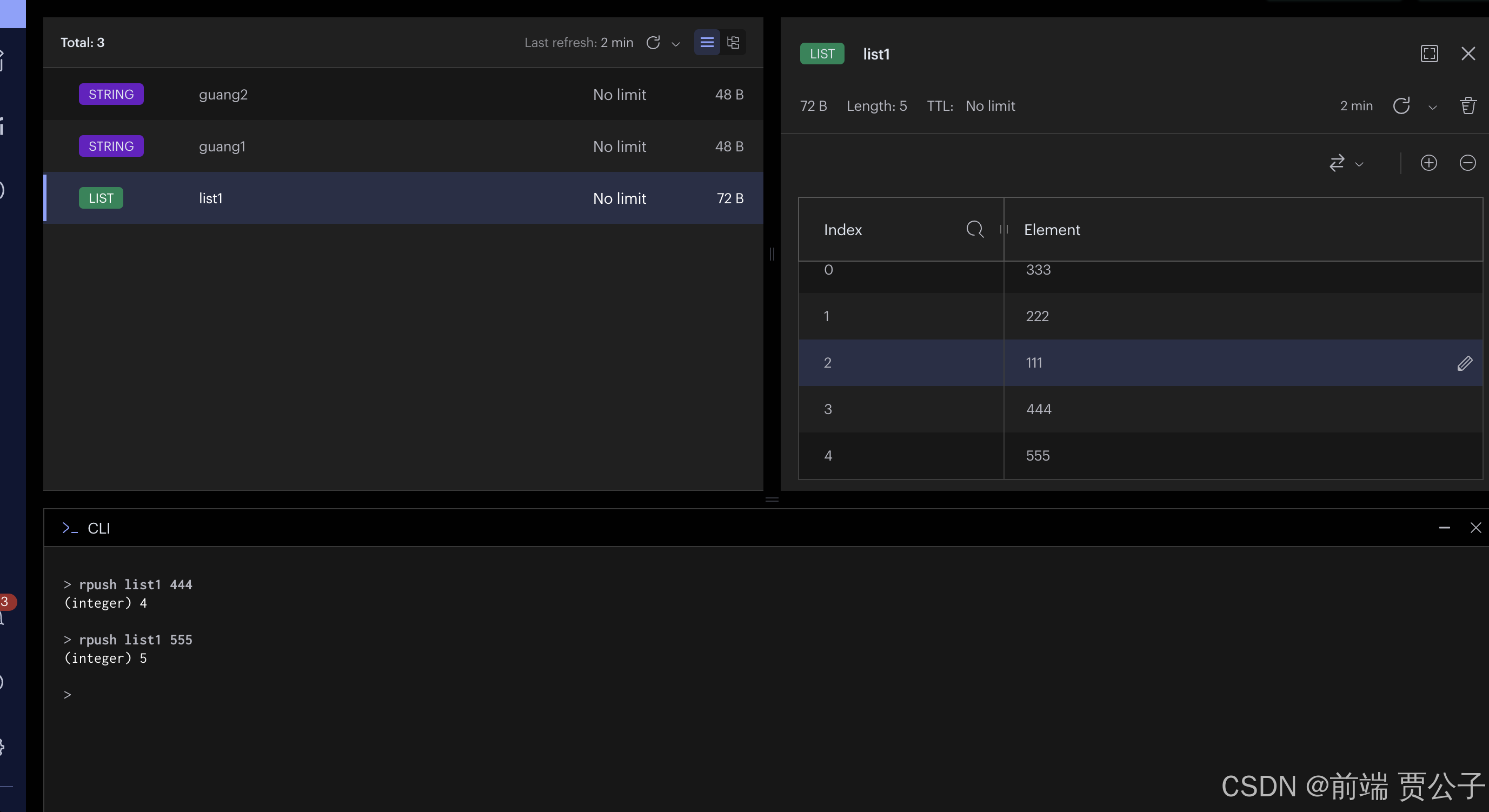
lpop 和 rpop 自然是从左边和从右边删除数据。
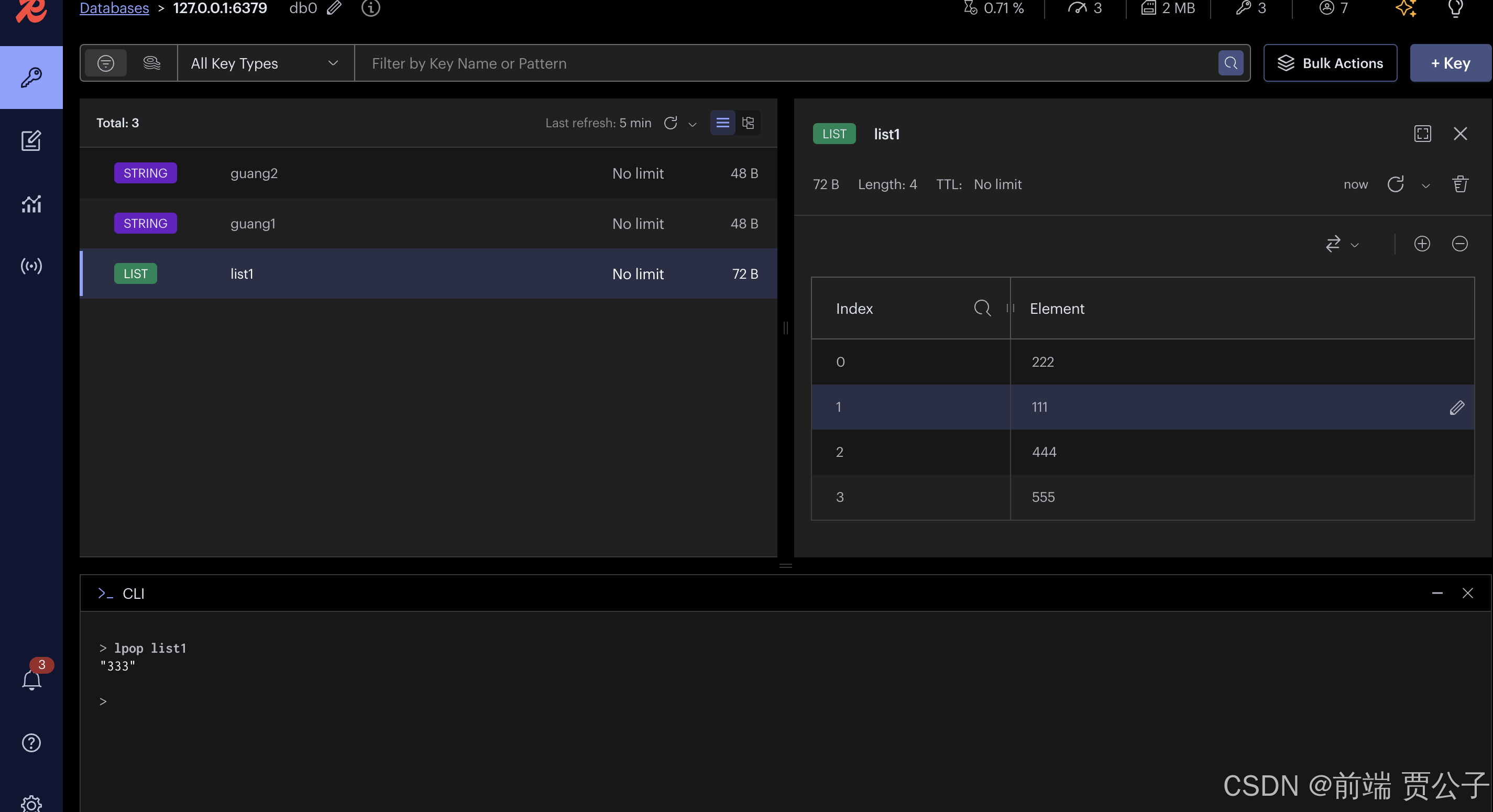
如果想查看数据呢?
在 GUI 里直接点开看就行,但在命令行里呢?
有同学说,不就是 get 么?
是不行的,get 只适用于 string 类型的数据,list 类型的数据要用 lrange。

输入一段 range,结尾下标为 -1 代表到最后。lrange list1 0 -1 就是查询 list1 的全部数据。
set
接下来我们再来看看 set:

set 的特点是无序并且元素不重复。
当我添加重复数据的时候:
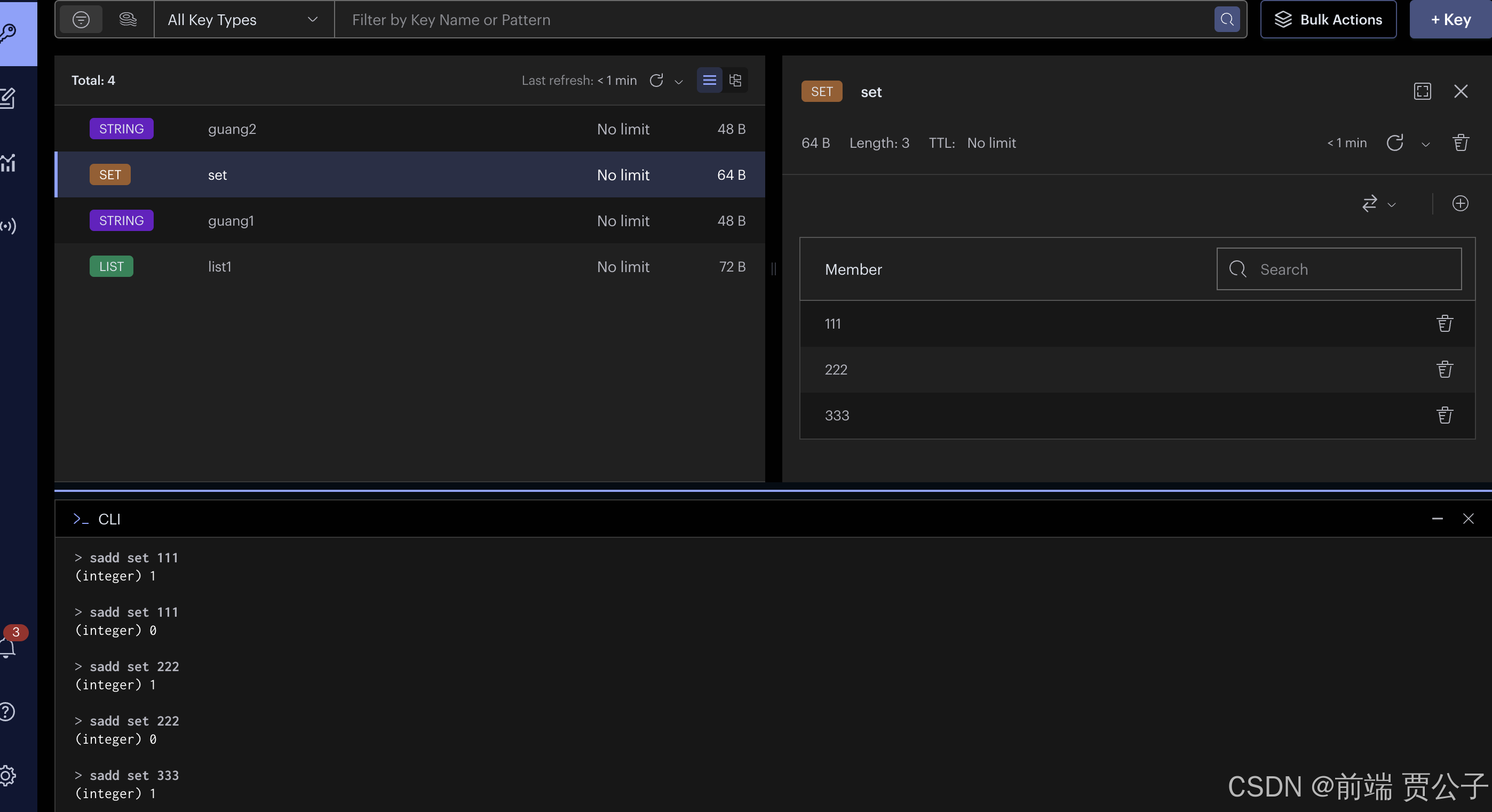
只保留去重后的数据:
可以通过 sismember 判断是否是集合中的元素:
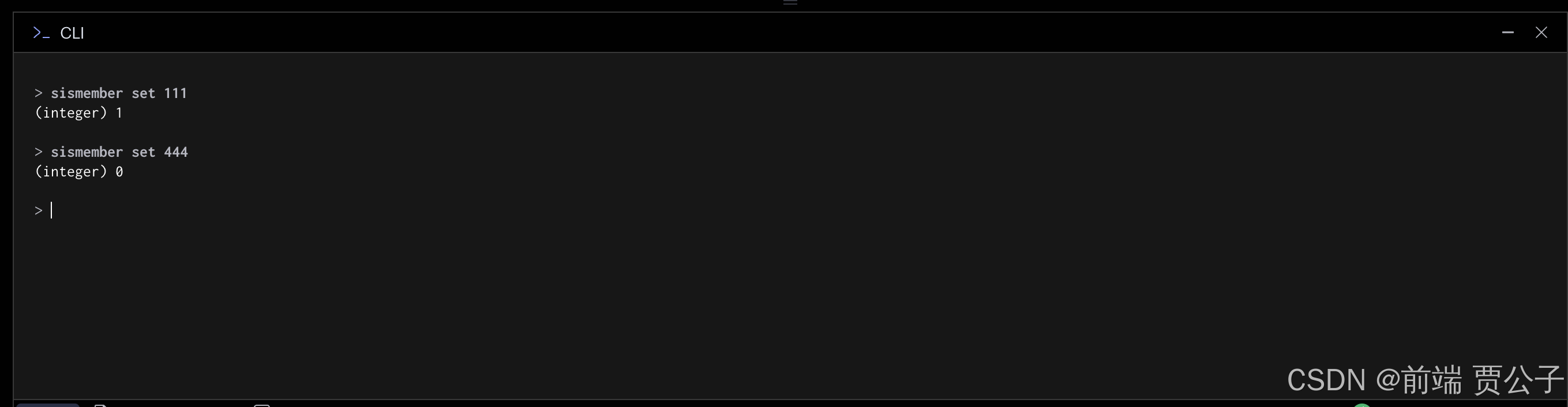
set 只能去重、判断包含,不能对元素排序。
如果排序、去重的需求,比如排行榜,可以用 sorted set,也就是 zset,:
sorted set(可排序)

它每个元素是有一个分数的: 会按照分数来排序:
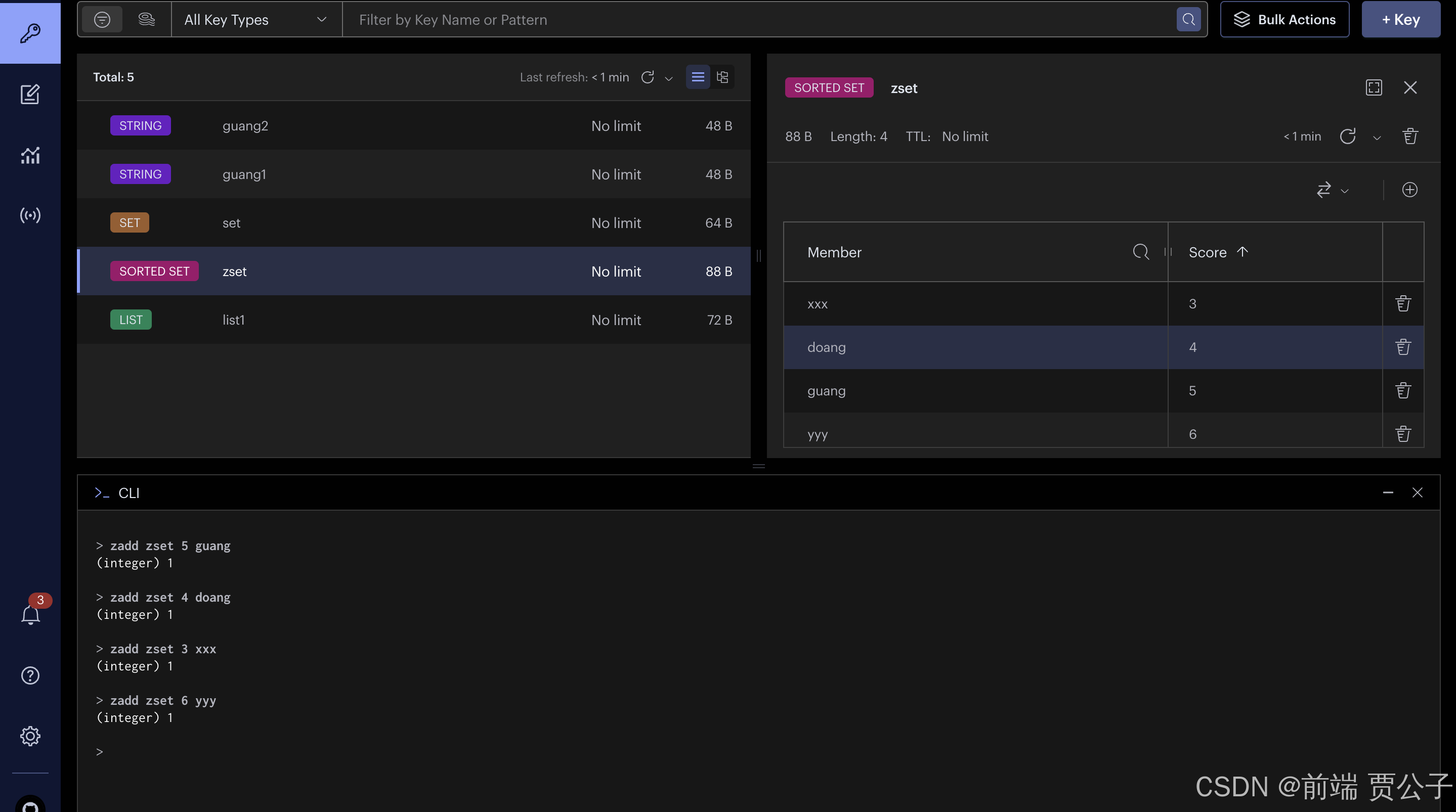
通过 zrange 命令取数据,比如取排名前三的数据:
zrange 命令取数据
通过 zrange 命令取数据,比如取排名前三的数据:

hash
接下来是 hash:

和我们用的 map 一样,比较容易理解:
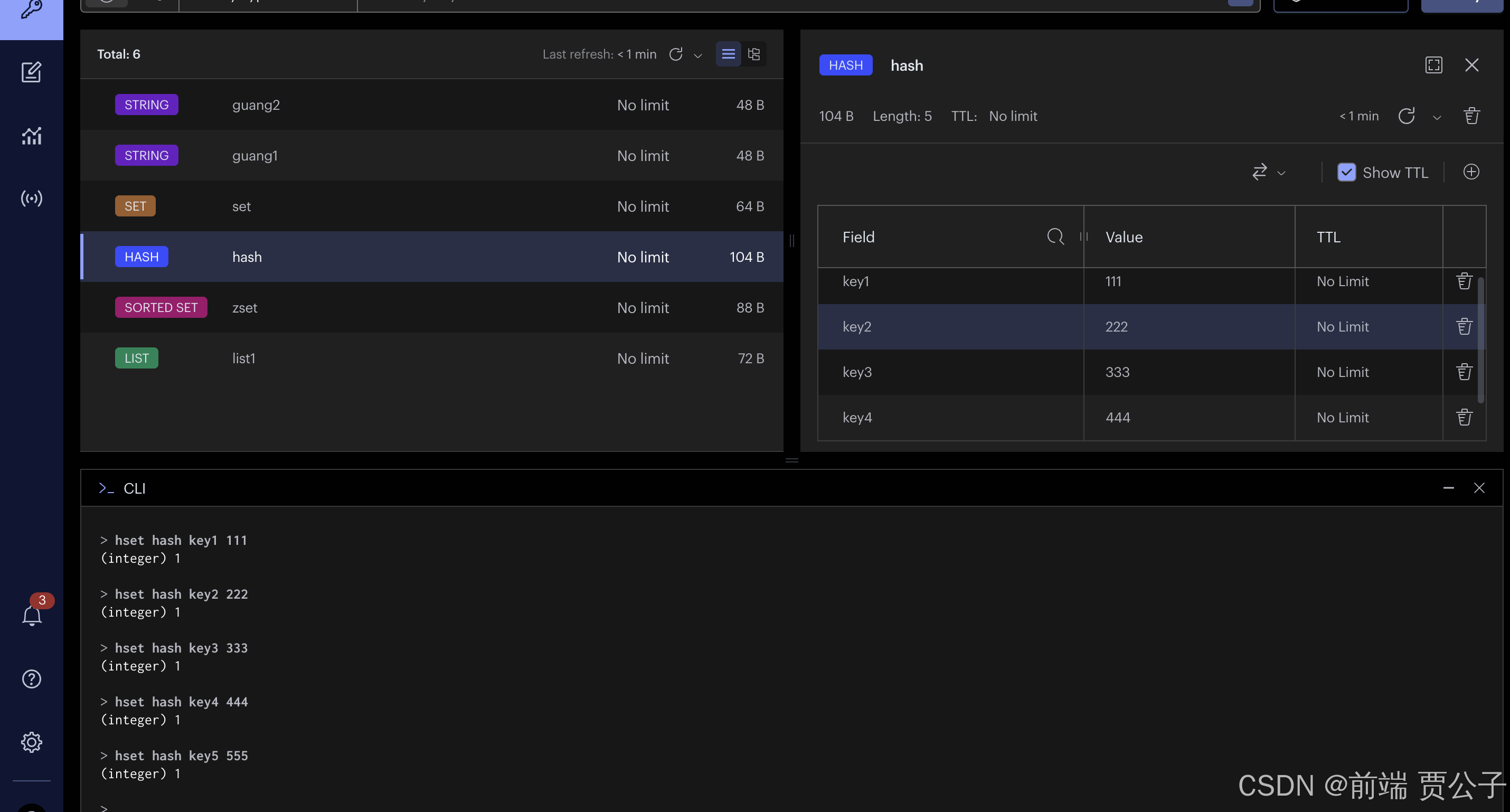
hget 获取key

geo
再就是 geo 的数据结构,就是经纬度信息,根据距离计算周围的人用的:

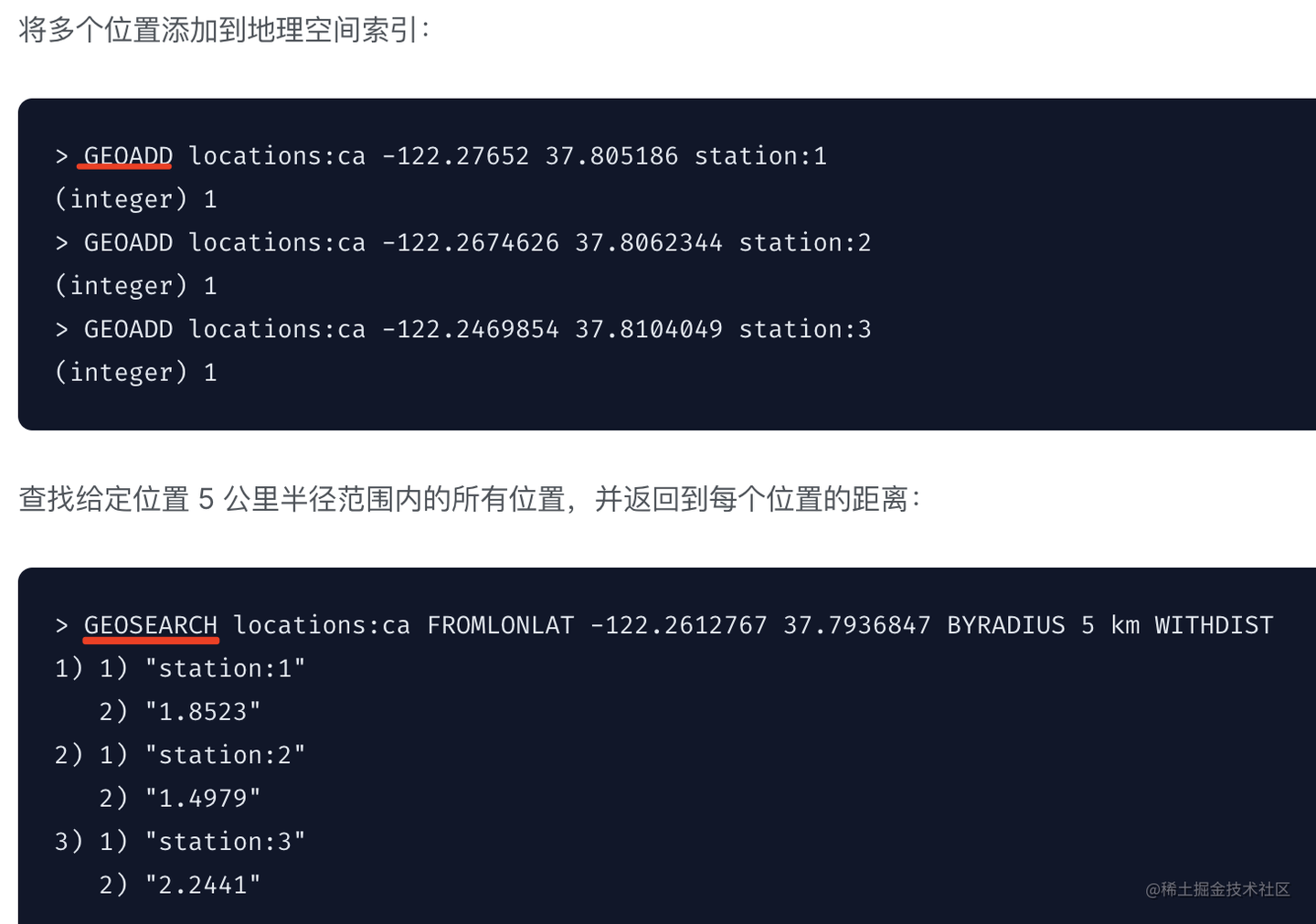
平时我们查找周围的人、周围的 xxx 都可以通过 redis 的 geospatial 数据结构实现。
redis 的数据结构就先介绍到这里。
是不是感觉还挺简单的。
确实,redis 学习成本挺低的,过一遍就会了。
不过一般 redis 的 key 我们会设置过期时间,通过 expire 命令:
expire 过期时间
比如我设置guang1 的 key 为 3 秒过期:
3s 后就查不到了:
想查剩余过期时间使用 ttl:
一些有时效的数据可以设置个过期时间。
总结
因为 mysql 存在硬盘,并且会执行 sql 的解析,会成为系统的性能瓶颈,所以我们要做一些优化。
常见的就是在内存中缓存数据,使用 redis 这种内存数据库。
它是 key、value 的格式存储的,value 有很多种类型,比如 string、list、set、sorted set(zset)、hash、geopitial 等。
灵活运用这些数据结构,可以完成各种需求,比如排行榜用 zset、阅读数点赞数用 string、附近的人用 geopitial 等。
而且这些 key 都可以设置过期时间,可以完成一些时效性相关的业务。
通过 redis 的 npm 包就可以轻松的连接和操作 redis 了,如果在 nest 里,可以封装一个 provider,在里面使用 redis 的 npm 包创建连接。
redis 几乎和 mysql 一样是后端系统的必用中间件了,它除了用来做数据库的缓存外,还可以直接作为数据存储的地方。
学会灵活使用 redis,是后端开发很重要的一步。