支持向量机(Support Vector Machine)是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的广义线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
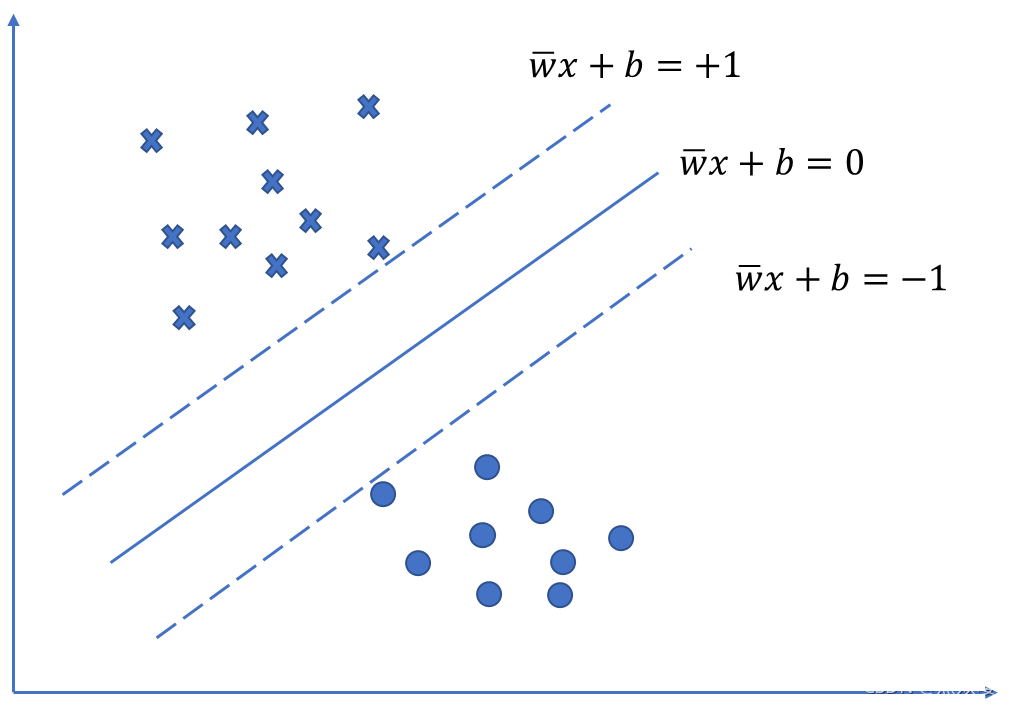
假设两类数据可以被 H = x : w T x + b ≥ c H = {x:w^Tx + b \ge c} H=x:wTx+b≥c分离,垂直于法向量 w w w,移动 H H H直到碰到某个训练点,可以得到两个超平面 H 1 H_1 H1和 H 2 H_2 H2,两个平面称为支撑超平面,题目分别支撑两类数据。而位于 H 1 H_1 H1和 H 2 H_2 H2正中间的超平面是分离这两类数据的最好选择。支持向量就是离分隔超平面最近的那些点。
法向量 w w w有很多种选择,超平面 H 1 H_1 H1和 H 2 H_2 H2之间的距离称为间隔,这个间隔是 w w w的函数,**目的就是寻找这样的 w w w使得间隔达到最大。
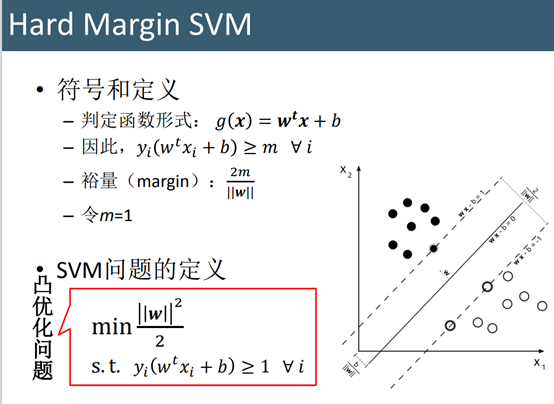


在求解最优化问题中,拉格朗日乘子法(Lagrange Multiplier)和KKT(Karush Kuhn Tucker)条件是两种最常用的方法。在有等式约束时使用拉格朗日乘子法,在有不等约束时使用KKT条件。
-
拉格朗日乘子法
拉格朗日乘子法是一种寻找多元函数在一组约束下的极值的方法。通过引入拉格朗日乘子,可将有 d d d个变量与 k k k个约束条件的最优化问题转化为具有 d + k d+k d+k个变量的无约束优化问题求解。
-
二次规划
二次规划是一类典型的优化问题,包括凸二次优化和非凸二次优化。在此类问题中,目标函数是变量的二次函数,而约束条件是变量的线性不等式。
m i n 1 2 x T Q x + c T x s . t . A ⃗ x ⃗ ≤ b ⃗ min \frac{1} {2} x^T Q x + c^T x \\ s.t. \vec{A} \vec{x} \le \vec{b} min21xTQx+cTxs.t.Ax≤b
具体公式证明:【整理】深入理解拉格朗日乘子法(Lagrange Multiplier) 和KKT条件 - mo_wang - 博客园 (cnblogs.com)
序列最小优化(Sequential Minimal Optimization,SMO)
序列最小优化是将大优化问题分界成多个小优化问题来求解。
SMO算法工作原理:每次循环中选择两个变量进行优化处理。一旦找到一对合适的变量,那么就增大其中一个同时减小另一个。这里的“合适”指的是两个变量必须要符合一定的条件,条件之一就是这两个变量必须要在间隔边界之外,而其第二个条件则是这两个变量还没有进行过区间化处理或者不在边界上。

代码实现
参考《机器学习实战》,代码链接:https://github.com/golitter/Decoding-ML-Top10/tree/master/SVM
这里采用简化的SMO代码,数据集是https://blog.caiyongji.com/assets/mouse_viral_study.csv。
data_processing.py:
import numpy as np
import pandas as pd
# https://zhuanlan.zhihu.com/p/350836534
def data_processing():
data_csv = pd.read_csv('mouse_viral_study.csv')
data_csv = data_csv.dropna()
# print(data_csv)
X = data_csv.iloc[:-1, 0:2].values
# print(X)
Y = data_csv.iloc[:-1, 2].map({0: -1, 1: 1}).values
Y = Y.reshape(-1, 1)
# print(Y.shape)
return X, Y
# X, Y = data_processing()
# print(X)
工具模块,smo_assist.py:
import random
def select_Jrandom(i:int, m:int) -> int:
"""
随机选择一个不等于 i 的整数
"""
j = i
while j == i:
j = int(random.uniform(0, m))
return j
def clip_alpha(alpha_j:float, H:float, L:float) -> float:
"""
修剪 alpha_j
"""
if alpha_j > H:
alpha_j = H
if alpha_j < L:
alpha_j = L
return alpha_j
简化SMO的代码实现,smoSimple.py:
from smo_assist import (
select_Jrandom,
clip_alpha)
import numpy as np
import pdb
def smoSimple(data_mat_in:np.ndarray, class_labels:np.ndarray, C:float, toler:float, max_iter:int):
"""
data_mat_in: 数据集
class_labels: 类别标签
C: 松弛变量
toler: 容错率
max_iter: 最大迭代次数
"""
b = 0; # 初始化b
m, n = np.shape(data_mat_in) # m: 样本数, n: 特征数
alphas = np.zeros((m, 1)) # 初始化alpha
iter = 0 # 迭代次数
while iter < max_iter:
alphaPairsChanged = 0
for i in range(m):
fXi = float(np.multiply(alphas, class_labels).T @ (data_mat_in @ data_mat_in[i, :].T)) + b
"""
(1 , m) * (m, n) * (n, 1) = (1, 1) = 标量
再 加上 b 就是 f(x) 的值
"""
Ei = fXi - float(class_labels[i])
"""
Ei = f(x) - y 预测误差
"""
if (
# 第一种情况:样本被误分类,且权重可以增加
((class_labels[i] * Ei < -toler) # 预测误差与标签方向相反,且误差大于容忍度
and (alphas[i] < C)) # 当前权重小于正则化参数 C,可以增加权重
or
# 第二种情况:样本被误分类,且权重需要调整
((class_labels[i] * Ei > toler) # 预测误差与标签方向相同,且误差大于容忍度
and (alphas[i] > 0)) # 当前权重大于 0,需要调整权重
):
j = select_Jrandom(i, m)
fxj = float(np.multiply(alphas, class_labels).T @ (data_mat_in @ data_mat_in[j, :].T)) + b
Ej = fxj - float(class_labels[j])
alpha_j_old = alphas[j].copy();
alpha_i_old = alphas[i].copy()
if (class_labels[i] != class_labels[j]):
L = max(0, alphas[j] - alphas[i]) # 左边界
H = min(C, C + alphas[j] - alphas[i]) # 右边界
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L == H:
continue # 跳出本次循环
eta = 2.0 * data_mat_in[i, :] @ data_mat_in[j, :].T - data_mat_in[i, :] @ data_mat_in[i, :].T - data_mat_in[j, :] @ data_mat_in[j, :].T
"""
计算 eta = K11 + K22 - 2 * K12 = 2 * x_i * x_j - x_i * x_i - x_j * x_j
"""
if eta >= 0:
continue
alphas[j] -= class_labels[j] * (Ei - Ej) / eta # 更新权重
alphas[j] = clip_alpha(alphas[j], H, L) # 调整权重
if abs(alphas[j] - alpha_j_old) < 0.00001:
continue # 跳出本次循环,不更新 i
alphas[i] += class_labels[j] * class_labels[i] * (alpha_j_old - alphas[j]) # 更新权重
b1 = b - Ei - class_labels[i] * (alphas[i] - alpha_i_old) * data_mat_in[i, :] @ data_mat_in[i, :].T - class_labels[j] *(alphas[j] - alpha_j_old) * data_mat_in[i, :] @ data_mat_in[j, :].T
b2 = b - Ej - class_labels[i] * (alphas[i] - alpha_i_old) * data_mat_in[i, :] @ data_mat_in[j, :].T - class_labels[j] *(alphas[j] - alpha_j_old) * data_mat_in[j, :] @ data_mat_in[j, :].T
"""
更新 b
"""
if 0 < alphas[i] < C:
b = b1
elif 0 < alphas[j] < C:
b = b2
else:
b = (b1 + b2) / 2.0
alphaPairsChanged += 1
if alphaPairsChanged == 0:
iter += 1
else:
iter = 0
return b, alphas
if __name__ == '__main__':
print( smoSimple(np.array([[1, 2], [3, 4]]), np.array([[-1],[1]]), 0.6, 0.001, 40))
test.py:
from data_processing import *
from smoSimple import *
import numpy as np
import matplotlib.pyplot as plt
# 数据处理和 SVM 训练
data_mat_in, class_labels = data_processing()
b, alphas = smoSimple(data_mat_in, class_labels, 0.6, 0.001, 40)
# 打印结果
print("Bias (b):", b)
print("Non-zero alphas:", alphas[alphas > 0])
# 打印数据形状
print("Shape of data_mat_in:", np.shape(data_mat_in))
print("Shape of class_labels:", np.shape(class_labels))
# 将 Y 转换为一维数组(如果它是二维的)
Y = class_labels
# 提取不同类别的索引
class_1_indices = np.where(Y == 1)[0] # 类别为 1 的样本索引
class_2_indices = np.where(Y == -1)[0] # 类别为 -1 的样本索引
X = data_mat_in
# 绘制散点图
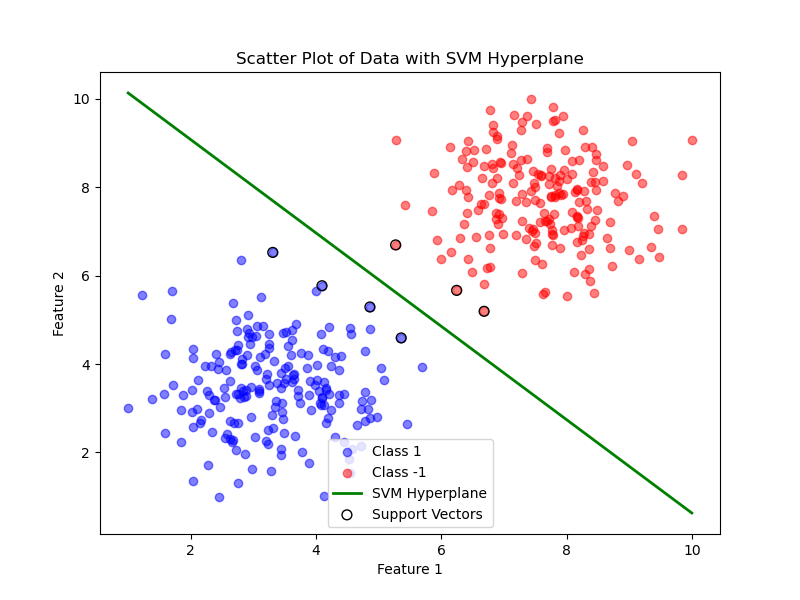
plt.figure(figsize=(8, 6))
plt.scatter(X[class_1_indices, 0], X[class_1_indices, 1], c='blue', label='Class 1', alpha=0.5)
plt.scatter(X[class_2_indices, 0], X[class_2_indices, 1], c='red', label='Class -1', alpha=0.5)
# 计算权重向量 w
w = np.dot((alphas * Y).T, X).flatten()
# print(f"w: {w}")
print("Shape of X:", X.shape) # 应该是 (m, n)
print("Shape of Y:", Y.shape) # 应该是 (m, 1)
print("Shape of alphas:", alphas.shape) # 应该是 (m, 1)
# 绘制超平面
# 超平面方程:w[0] * x1 + w[1] * x2 + b = 0
# 解出 x2: x2 = -(w[0] * x1 + b) / w[1]
x1 = np.linspace(np.min(X[:, 0]), np.max(X[:, 0]), 100)
x2 = -(w[0] * x1 + b) / w[1]
print(f"w_shape: {w.shape}")
# 绘制超平面
plt.plot(x1, x2, label='SVM Hyperplane', color='green', linewidth=2)
# 标出支持向量
support_vectors_indices = np.where(alphas > 0)[0] # 找到所有支持向量的索引
plt.scatter(X[support_vectors_indices, 0], X[support_vectors_indices, 1],
facecolors='none', edgecolors='k', s=50, label='Support Vectors')
# 添加图例和标签
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Scatter Plot of Data with SVM Hyperplane')
plt.legend()
# 显示图形
plt.show()
ML_AI_SourceCode-/支持向量机 at master · sjyttkl/ML_AI_SourceCode- (github.com)
【整理】深入理解拉格朗日乘子法(Lagrange Multiplier) 和KKT条件 - mo_wang - 博客园 (cnblogs.com)