
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
基本信息
标题: Fine-tuned CLIP Models are Efficient Video Learners
作者: Hanoona Rasheed, Muhammad Uzair Khattak, Muhammad Maaz, Salman Khan, Fahad Shahbaz Khan
发表: CVPR 2023
arXiv: https://arxiv.org/abs/2212.03640

这项工作探讨了名为ViFi-CLIP(Video Fine-tuned CLIP)的简单基线在将图像预训练的CLIP适应视频领域方面的能力。图示比较了vanilla CLIP及其针对视频进行适配的几个变体(在Kinetics-400上训练,在UCF-101和HMDB-51上评估)的无监督性能。从ViFi-CLIP(第4列)获得的视频嵌入的t-SNE可视化与vanilla CLIP(第1列)、单独调优的视频文本CLIP(第2列)和图像编码器(第3列)的嵌入以及最新的最先进工作XCLIP(最后一列)的嵌入进行了比较(Δ表示与XCLIP的差异)。ViFi-CLIP的嵌入具有更好的可分离性,表明对CLIP的简单微调足以学习合适的视频特定归纳偏差,并且可以与具有专门组件以模拟视频时间信息的更复杂方法相媲美。
摘要
大规模的图像-文本对多模态训练赋予了CLIP模型强大的泛化能力。由于在类似规模上对视频进行训练不可行,最近的方法集中于有效地将基于图像的CLIP迁移到视频领域。在此追求中,添加了新的参数模块来学习时间信息和帧间关系,这需要细致的设计努力。
此外,当在视频上学习得到的模型时,它们往往在给定的任务分布上过度拟合,且在泛化方面存在不足。这引发了一个问题:如何有效地将图像级别的CLIP表示迁移到视频中?
在本工作中,我们表明简单的Video Fine-tuned CLIP(ViFi-CLIP)基线通常足以弥合从图像到视频的领域差距。
我们的定性分析表明,CLIP图像编码器的帧级处理,随后与相应的文本嵌入进行特征池化和相似度匹配,有助于在ViFi-CLIP中隐式地建模时间线索。这种微调有助于模型专注于场景动态、移动对象和对象间关系。对于低数据情况下,全量微调不可行,我们提出了一种“bridge and promp”方法,首先使用微调来弥合领域差距,然后在语言和视觉方面学习提示以适应CLIP表示。
我们在五个视频基准上对这种简单而强大的基线进行了广泛的评估,包括零样本、基线到新领域泛化、少样本和全监督设置。
我们的代码和预训练模型可在https://github.com/muzairkhattak/ViFi-CLIP上获取。
主要贡献
- 我们提出了一种简单但强大的基线,ViFi-CLIP(Video Fine-tuned CLIP),用于将基于图像的CLIP应用于视频特定任务。我们表明,对CLIP进行简单的微调就足以学习视频特定的归纳偏差,从而在下游任务上取得了令人印象深刻的性能。
- 我们对四种不同的实验设置进行了实验,包括零样本、基于基础到新领域的泛化、少样本和全监督任务。与最先进的方法相比,我们展示了更好的或具有竞争力的性能。
- 我们展示了我们提出的“bridge and promp”方法的有效性,该方法首先通过微调来弥合模态差距,随后在CLIP模型的视觉和语言分支中进行提示学习,适用于低数据环境。
方法
整体框架
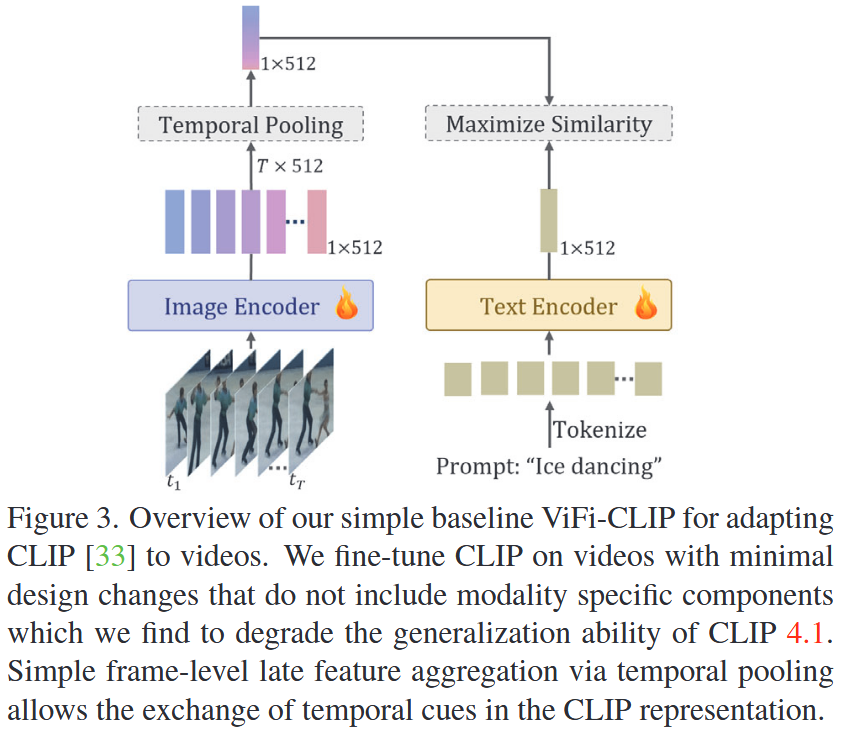
- Temporal Pooling: Mean Pooling
- Image Encoder / Text Encoder: CLIP (ViT-B/16)
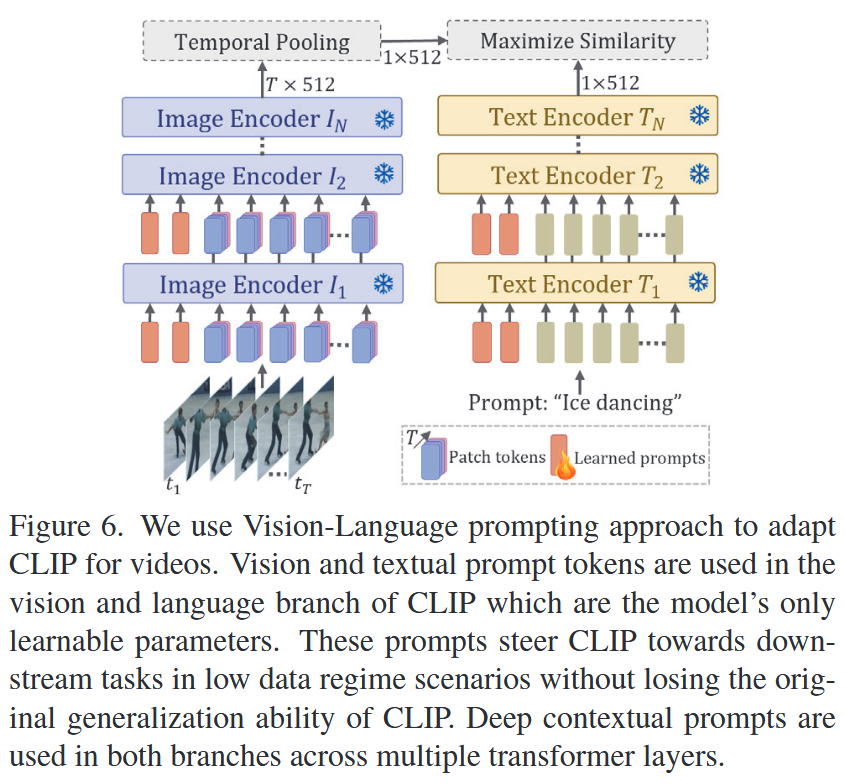
bridge and prompt
实验
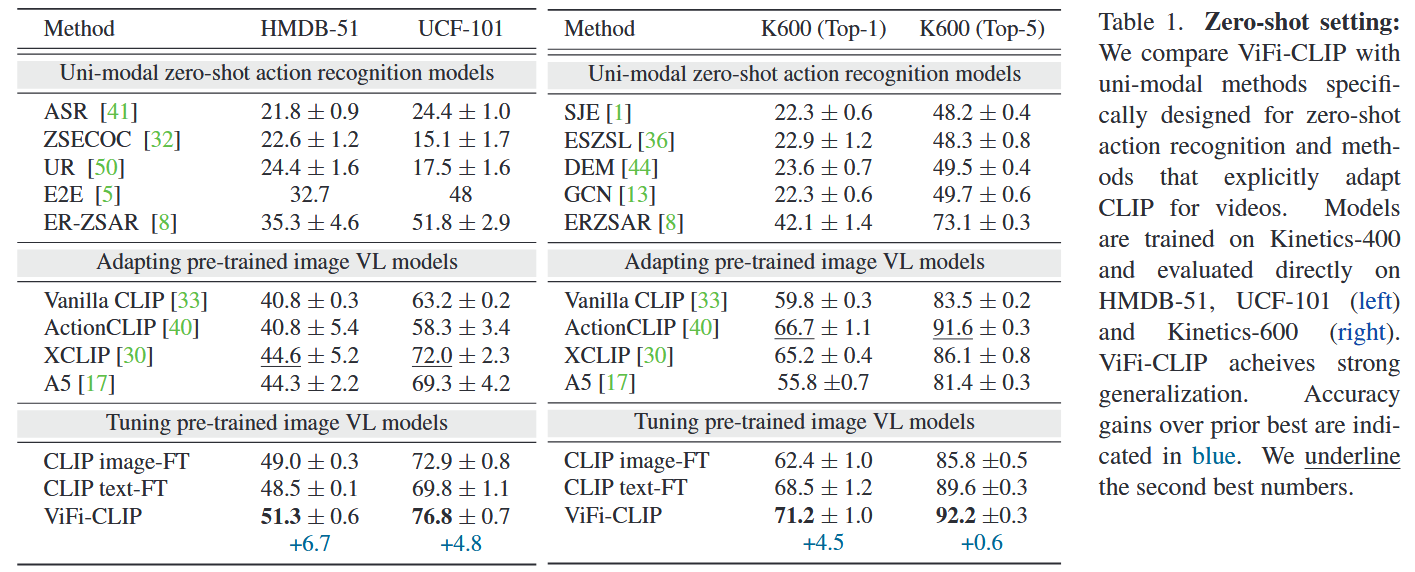
- Zero-shot setting: 源数据集上训练,目标数据集上测试,两个数据集的标签交集为空。
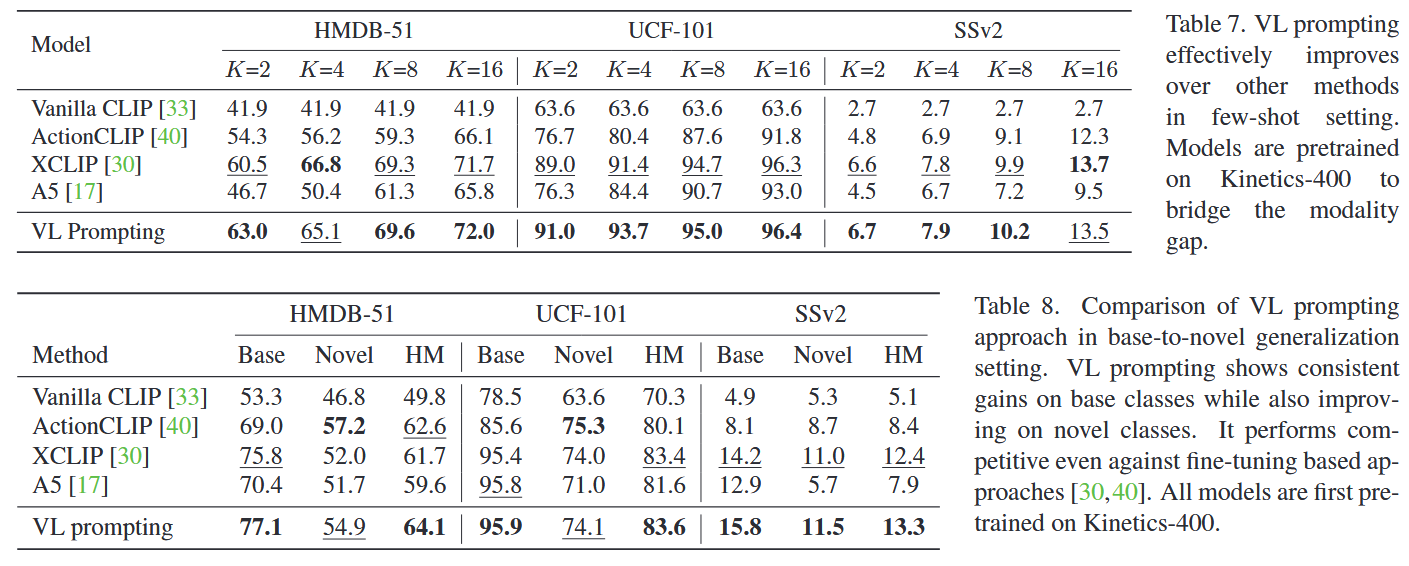
- Base-to-novel generalization: 在数据集上样本数量最多的一半类别上训练,在整个数据集上测试。
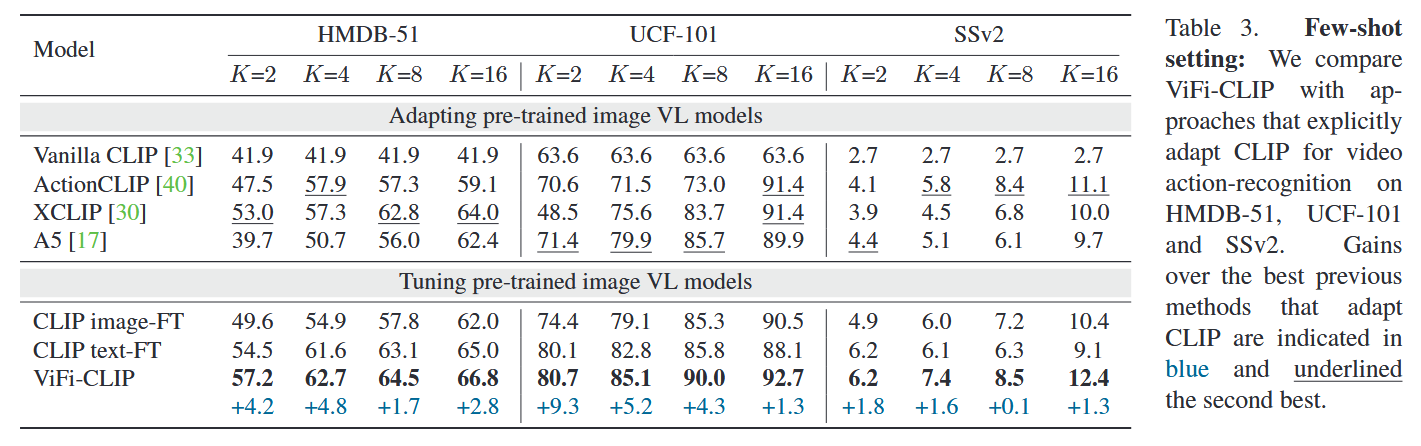
- Few-shot setting: 每个类别取 K 个样本训练。
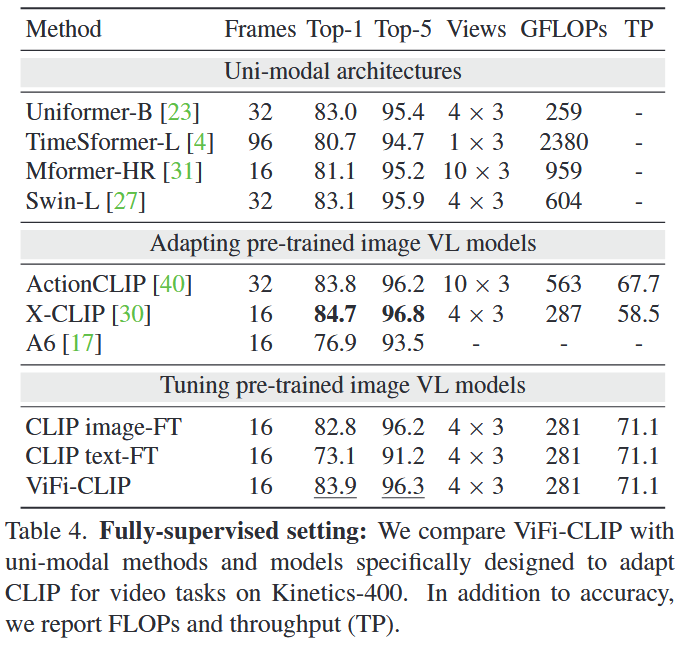
- Fully-supervised setting: 正常。
ViFi-CLIP
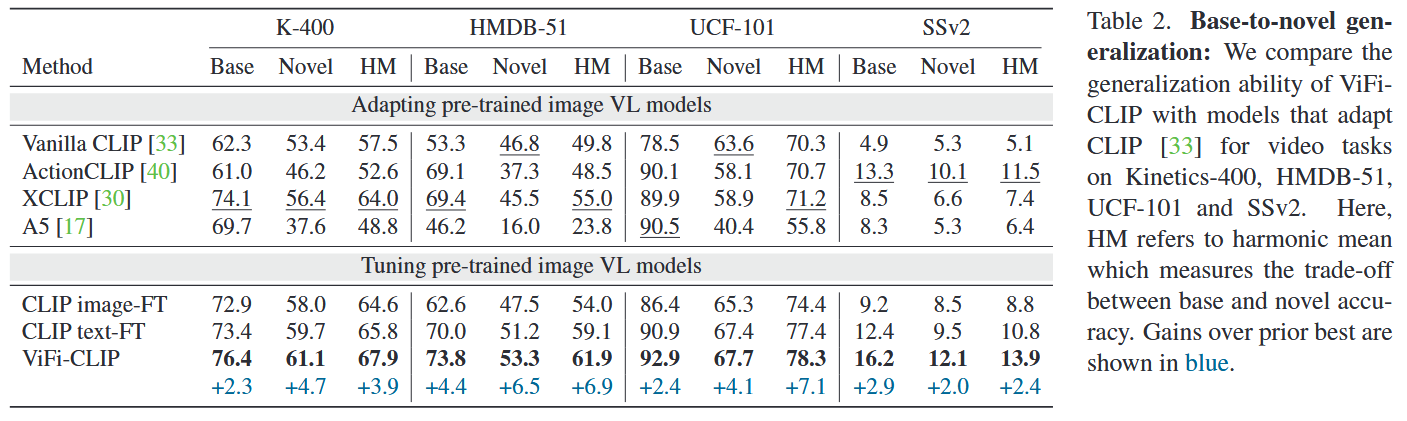
HM: Base和Novel的调和平均


VL prompting
总结
这项工作展示了将基于图像的CLIP模型转移到视频领域的一个常被忽视但简单的基线的重要性。
我们证明了仅对视频数据进行视觉和文本编码器的微调,在监督任务以及泛化任务上表现良好。
结果表明,与为视频专门开发的复杂方法相比,简单解决方案在大多数情况下都具有可扩展性和优势。
在无法进行微调的情况下,我们还提出了一种bridge and prompt方案,该方案使用视频微调表示来快速适应下游视频应用。