
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
基本信息
标题: C
2
^2
2RL: Content and Context Representation Learning for Gloss-free Sign Language Translation and Retrieval
作者: Zhigang Chen, Benjia Zhou, Yiqing Huang, Jun Wan, Yibo Hu, Hailin Shi, Yanyan Liang, Zhen Lei, Du Zhang
arXiv: https://arxiv.org/abs/2408.09949

摘要
手语表示学习(SLRL)对于一系列与手语相关的下游任务至关重要,如手语翻译(SLT)和手语检索(SLRet)。
最近,许多gloss-based和gloss-free的SLRL方法被提出,显示出有希望的性能。
其中,gloss-free的方法在无需依赖gloss的情况下展现出强大的可扩展性。
然而,由于在编码手语视频复杂、上下文敏感的特征方面存在挑战,目前它面临着次优解,主要是在使用非单调的视频-文本对齐策略时难以辨别关键的手语特征。
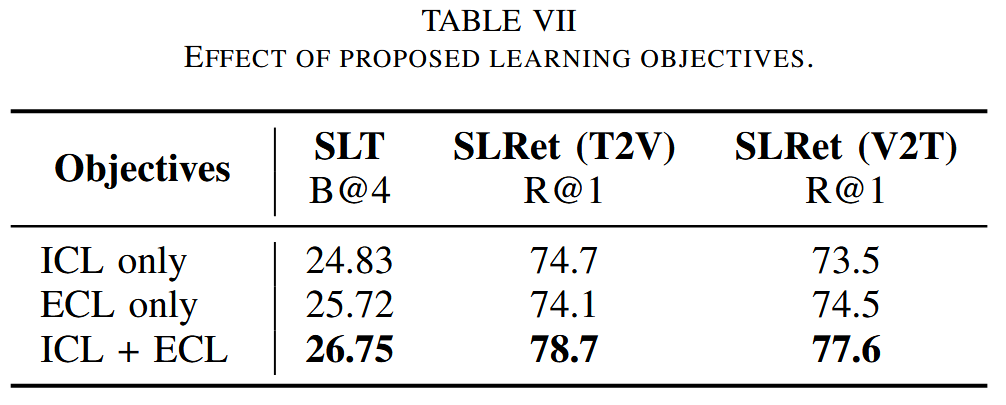
因此,本文提出了一种新的gloss-free SLRL预训练范式,称为C 2 ^2 2RL。具体来说,我们不是仅仅将视频和文本的非单调语义对齐纳入学习语言导向的手语特征,而是强调SLRL的两个关键方面:隐式内容学习(ICL)和显式上下文学习(ECL)。
ICL深入到交流的内容中,捕捉手语的细微差别、强调、时序和节奏。
相比之下,ECL专注于理解手语的上下文意义并将它们转换为等效句子。
尽管其简单,但大量实验证实了ICL和ECL的联合优化导致了鲁棒的手语表示和gloss-free SLT和SLRet任务中的显著性能提升。
值得注意的是,C 2 ^2 2RL在P14T上提高了BLEU-4分数+5.3,在CSL-daily上提高了+10.6,在OpenASL上提高了+6.2,在How2Sign上提高了+1.3。
它还提高了R@1分数,在P14T上提高了+8.3,在CSL-daily上提高了+14.4,在How2Sign上提高了+5.9。
此外,我们在SLRet任务中为OpenASL数据集设置了新的基线。
主要贡献
- 我们的研究在手语翻译(SLT)和手语检索(SLRet)任务方面取得了显著进展。与现有的gloss-free方法相比,我们的方法在英语、德语和中文的四个主要手语数据集上表现出显著改进,甚至在CSL-daily数据集上BLEU4评分提高了10+。此外,所提出的方法显著提升了SLRet性能,这些数据集的平均R@1评分提高了5+。
- 我们提出了一种名为C 2 ^2 2RL的创新预训练范式,用于SLRL,该范式将隐式内容学习(ICL)和显式上下文学习(ECL)集成到通用手语表示学习中,从而在非单调对齐条件下实现视觉-文本一致的手语表示学习。
- C 2 ^2 2RL可以成为一种通用的手语表示提取器,旨在灵活适应与手语相关的各种下游任务,并提供与各种现成语言模型骨干的无缝集成。
方法
模型架构
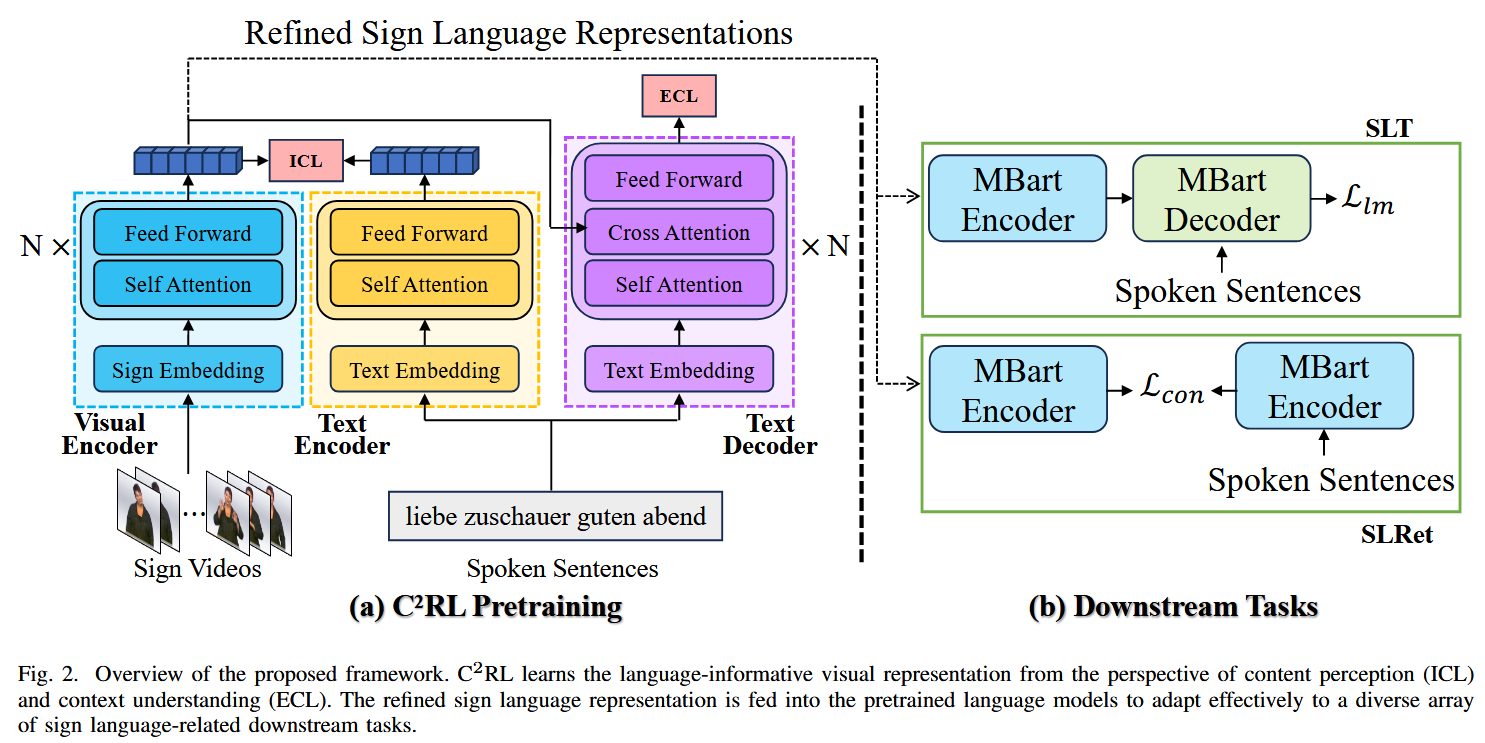
Visual Encoder: ResNet-18 + Conv1D-BN1D-ReLU + FC
Text Encoder, Text Decoder: Transformer (3 layers)
MBart: MBart-large-cc25,标准的Transformer架构模型,带有12个encoder和decoder层
训练
8 * NVIDIA GeForce RTX 3090 GPUs
Pretraining
Implicit Content Learning (ICL):
L con = − 1 N ∑ i = 1 N log exp ( Z V 2 T ( i , i ) / τ ) ∑ j = 1 N exp ( Z V 2 T ( i , j ) / τ ) − 1 N ∑ i = 1 N log exp ( Z T 2 V ( i , i ) / τ ) ∑ j = 1 N exp ( Z T 2 V ( i , j ) / τ ) \begin{align*} \mathcal{L}_{\text{con}} = &-\frac{1}{N}\sum_{i=1}^{N}\log\frac{\exp\left(Z_{V 2 T}^{(i, i)}/\tau\right)}{\sum_{j=1}^{N}\exp\left(Z_{V 2 T}^{(i, j)}/\tau\right)} \\ &-\frac{1}{N}\sum_{i=1}^{N}\log\frac{\exp\left(Z_{T 2 V}^{(i, i)}/\tau\right)}{\sum_{j=1}^{N}\exp\left(Z_{T 2 V}^{(i, j)}/\tau\right)} \end{align*} Lcon=−N1i=1∑Nlog∑j=1Nexp(ZV2T(i,j)/τ)exp(ZV2T(i,i)/τ)−N1i=1∑Nlog∑j=1Nexp(ZT2V(i,j)/τ)exp(ZT2V(i,i)/τ)
Explicit Context Learning (ECL):
L lm = − 1 N ∑ i = 1 N ∑ u = 1 U log p ( t i u ∣ t i < u , v i ) \mathcal{L}_{\text{lm}} = -\frac{1}{N}\sum_{i=1}^{N}\sum_{u=1}^{U}\log p\left(t_{i}^{u} \mid t_{i}^{<u}, v_i\right) Llm=−N1i=1∑Nu=1∑Ulogp(tiu∣ti<u,vi)
Loss Function:
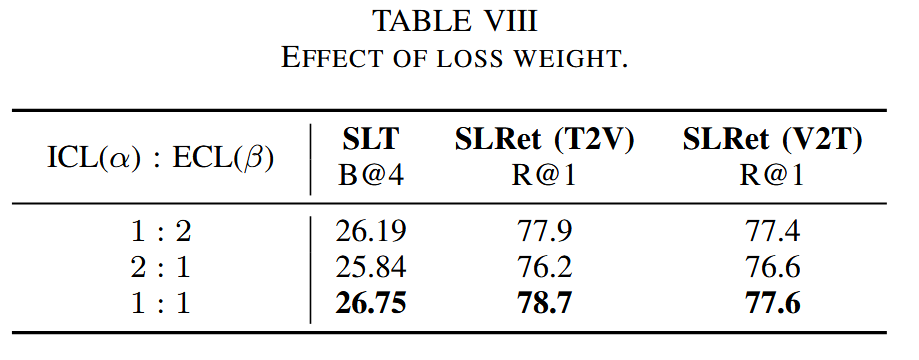
L = α L con + β L lm \mathcal{L} = \alpha \mathcal{L}_{\text{con}} + \beta \mathcal{L}_{\text{lm}} L=αLcon+βLlm
Downstream Tasks
- SLT: 同 L lm \mathcal{L}_{\text{lm}} Llm
- SLRet: 同 L con \mathcal{L}_{\text{con}} Lcon
实验
主实验

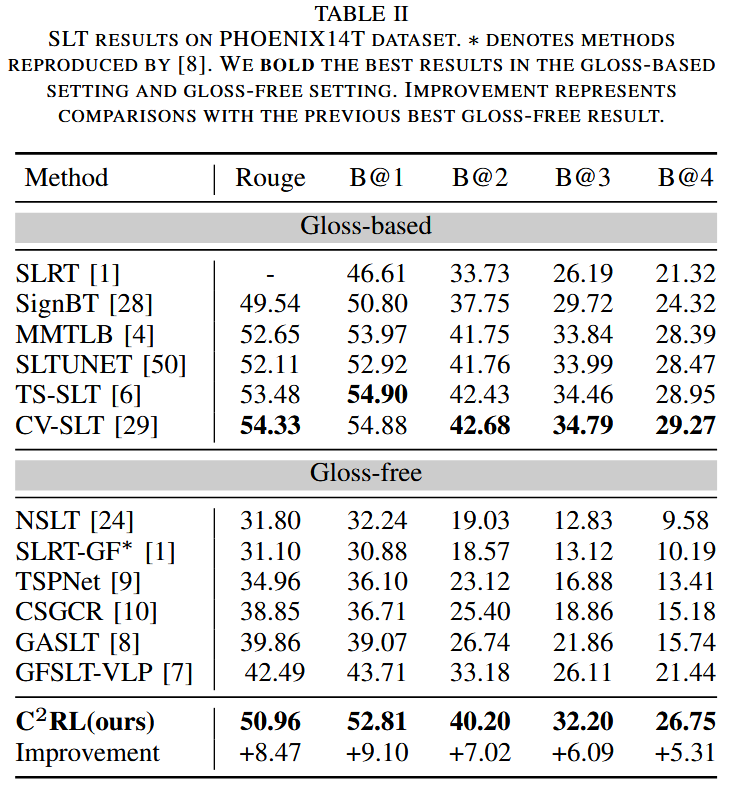
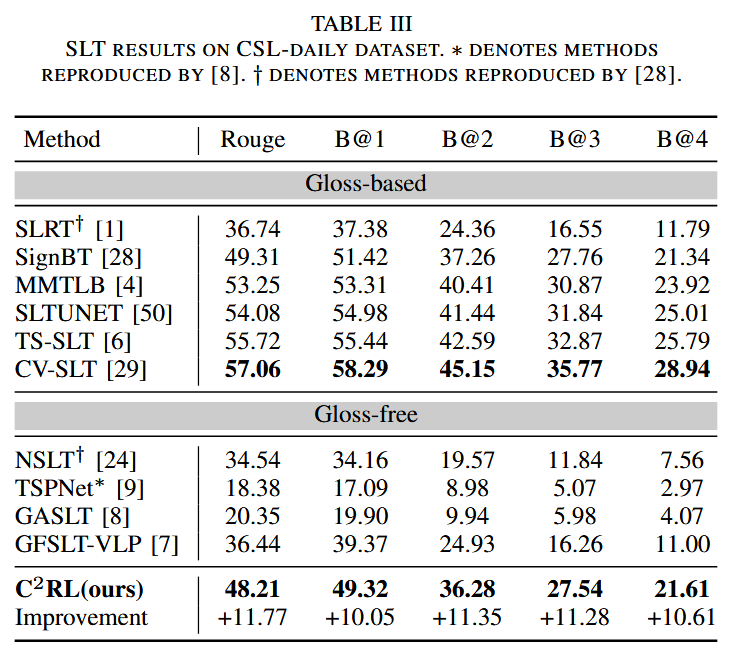
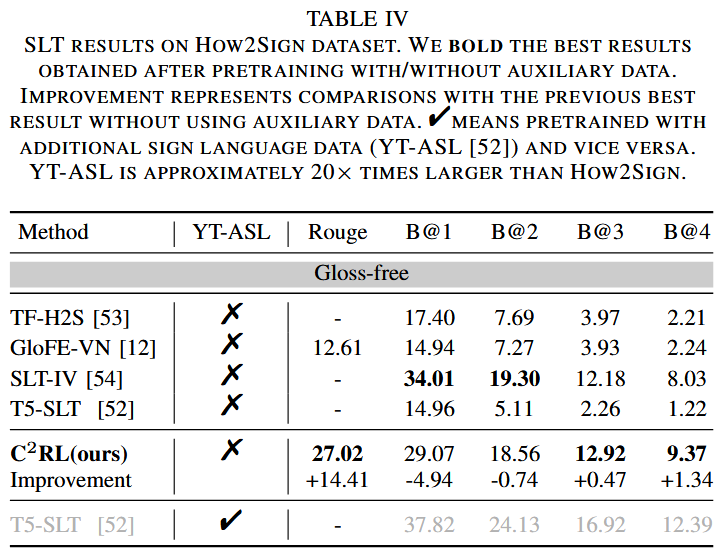
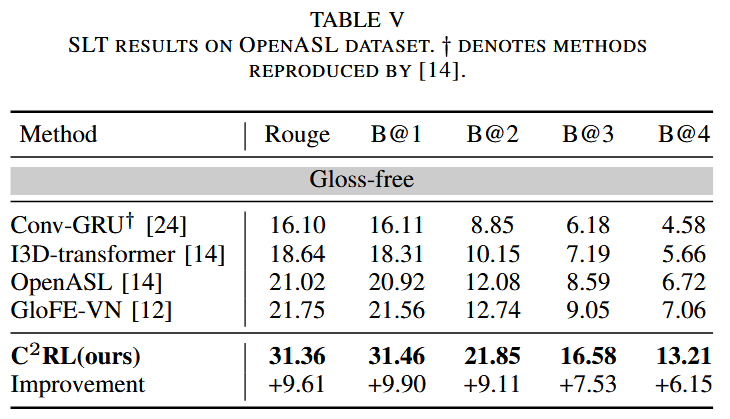
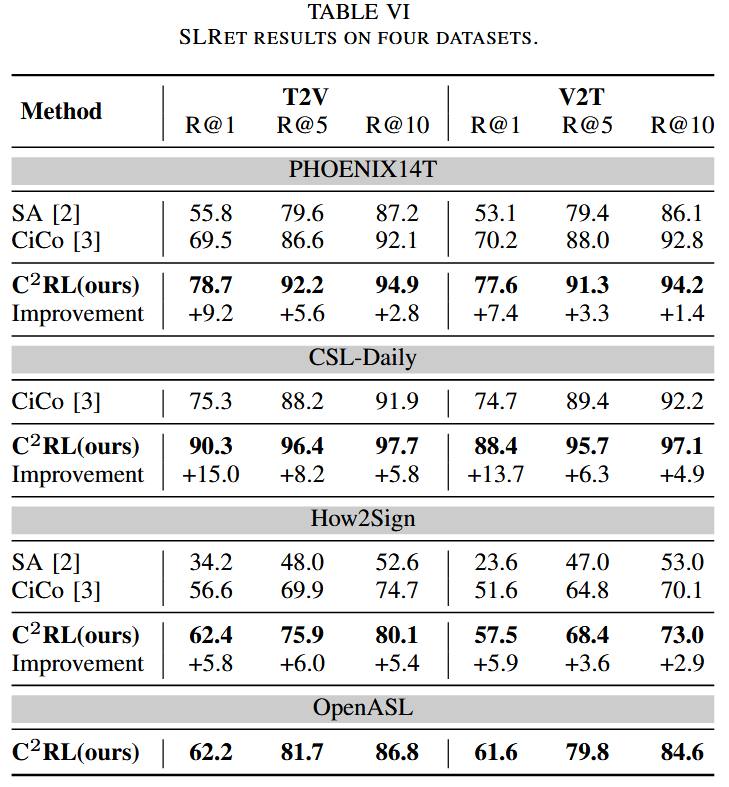
消融实验
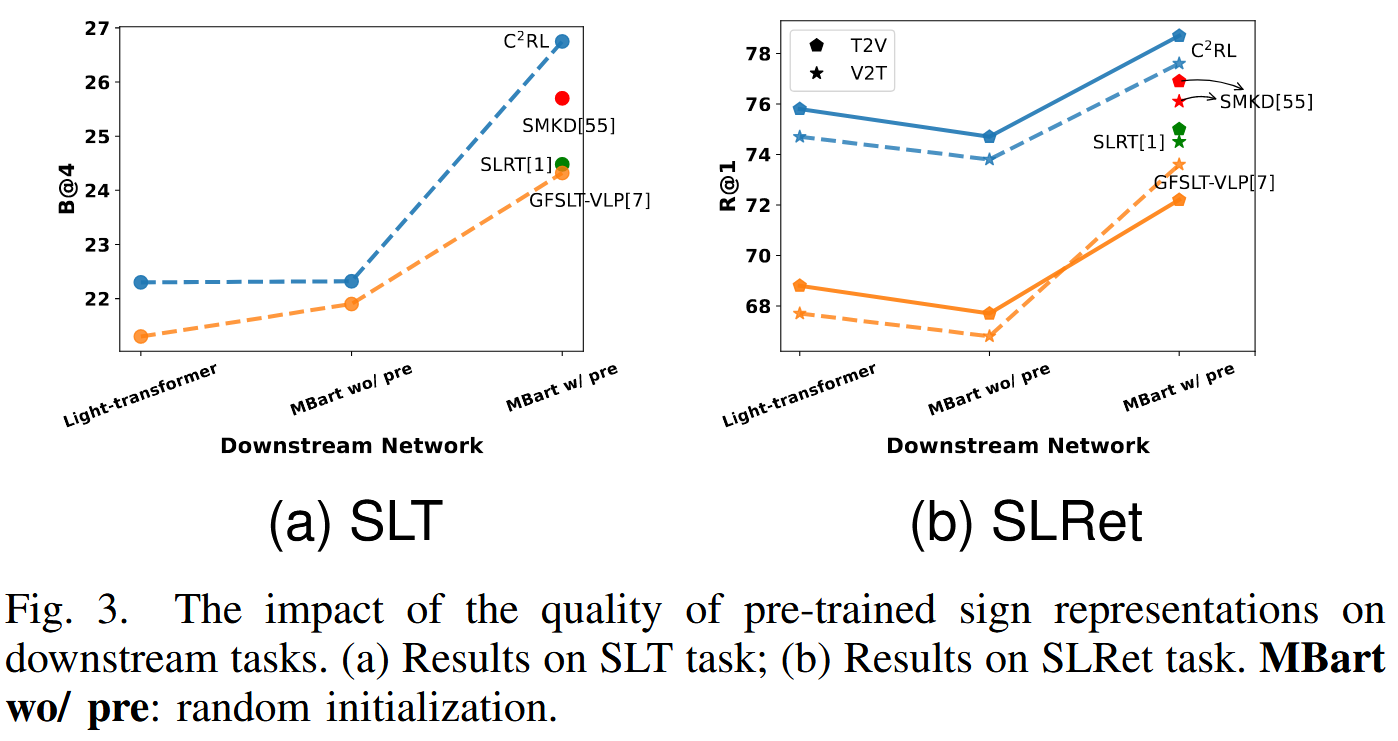
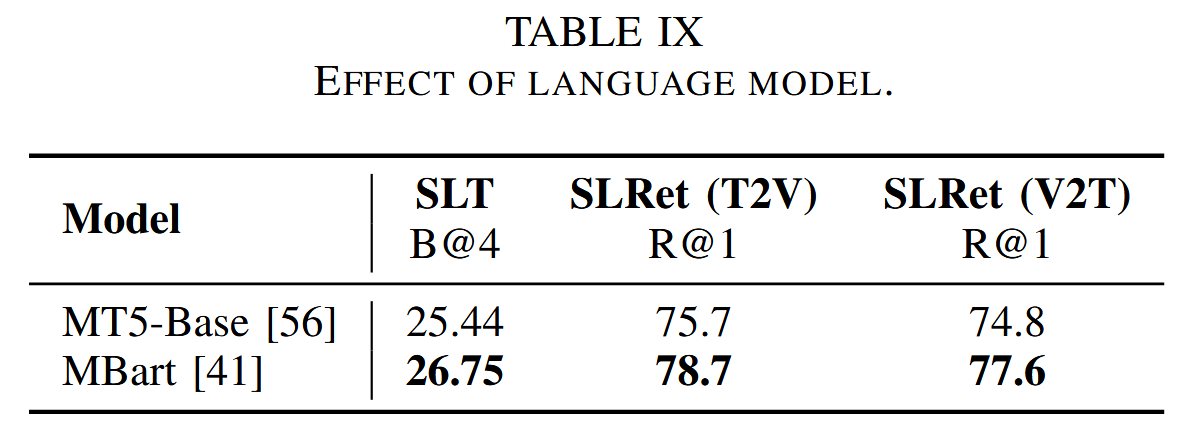
总结
在这篇论文中,我们提出了一种名为C 2 ^2 2RL的创新方法,用于gloss-free手语表示学习(SLRL),该方法结合了隐式内容学习(ICL)和显式上下文学习(ECL)。
这种方法对手语视频有了全面的理解,从而在手语翻译(SLT)和手语检索(SLRet)任务中取得了显著的改进。
虽然该方法简单易懂,但我们希望它能激发SLRL领域的新方向。
由于篇幅限制,我们的研究仅限于手语视频理解。
尽管如此,我们相信这种方法在更广泛的视频理解领域具有潜力,如视频摘要和视频字幕。
我们计划在未来的工作中进一步研究这些潜力。