前提准备:requests、pandas、threading等第三方库的导入(未下载的先进行下载)
导入库代码
from threading import Thread #多线程库
import requests
import pandas as pd
import json #json库
完整步骤
1.在网页找到需要的数据
(1)任意输入出发地——目的地——日期,点击查询(我这里查询的是:2024年7月6日长沙到武汉的票)
(2)打开抓包工具,重新刷新页面
(3)在抓包工具里面找到内容所在页面
通过比对发现车票数据在这个json页面内容里面,但是内容有点复杂,需要我们自己去提取,经过选择,结果如下:
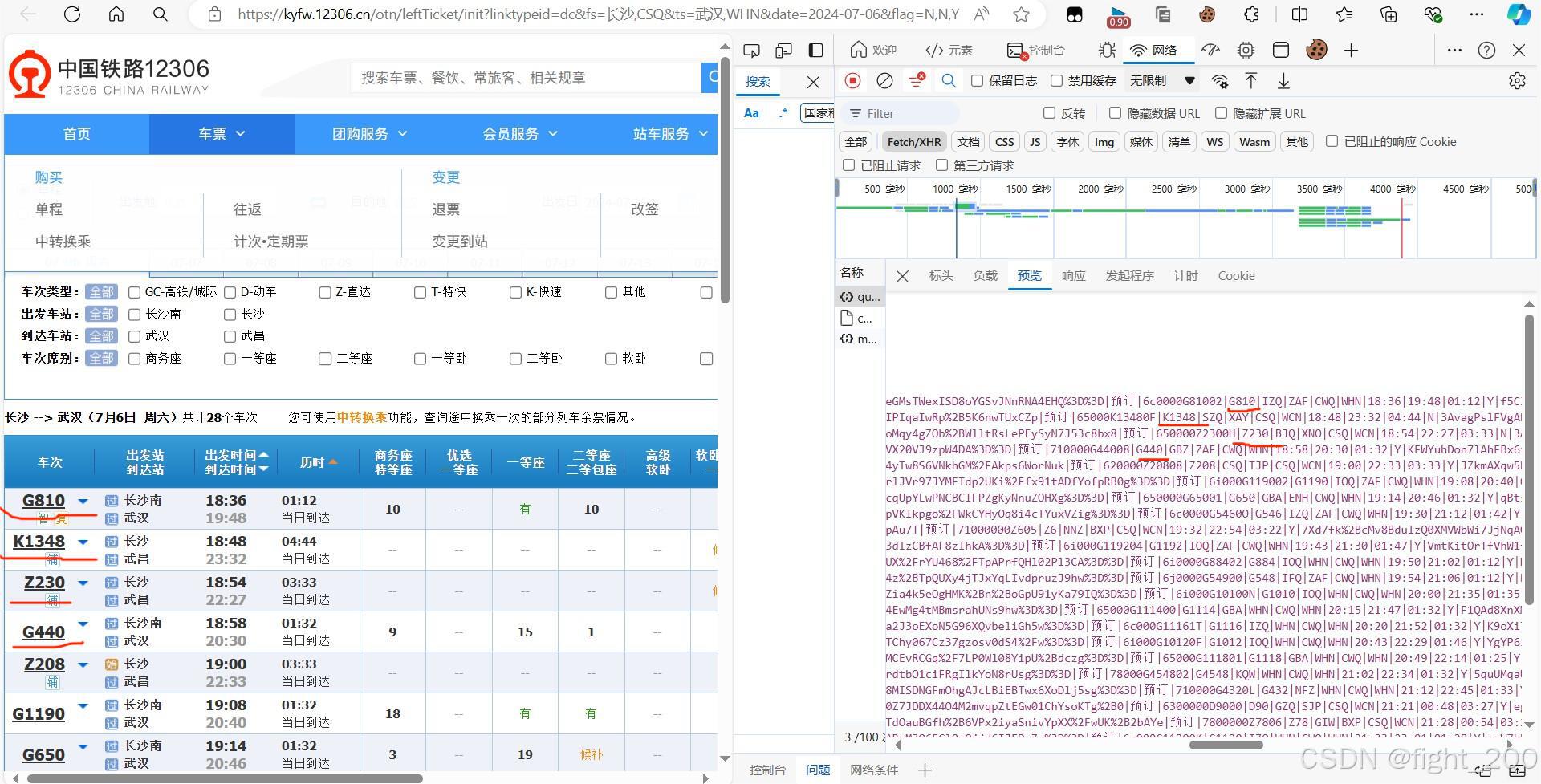
result = front_content.json()['data']['result'] #返回json字典数据
for it in result:
info_list = it.split("|") #切割数据,中文转英文
num = info_list[3]
start = info_list[8] #启动时间
arrive = info_list[9] #到达时间
time = info_list[10] #经历时长
business_seat = info_list[32] #高铁商务座
first_seat = info_list[31] #高铁一等座
second_seat = info_list[30] #高铁二等座
soft_sleeper = info_list[23] #火车软卧
hard_sleeper = info_list[28] #火车硬卧
soft_seat = info_list[27] #火车软座
hard_seat = info_list[29] #火车硬座
none_seat = info_list[26] #无座
2.爬取网页数据(带负载)
①url前半部分
②url后半部分负载
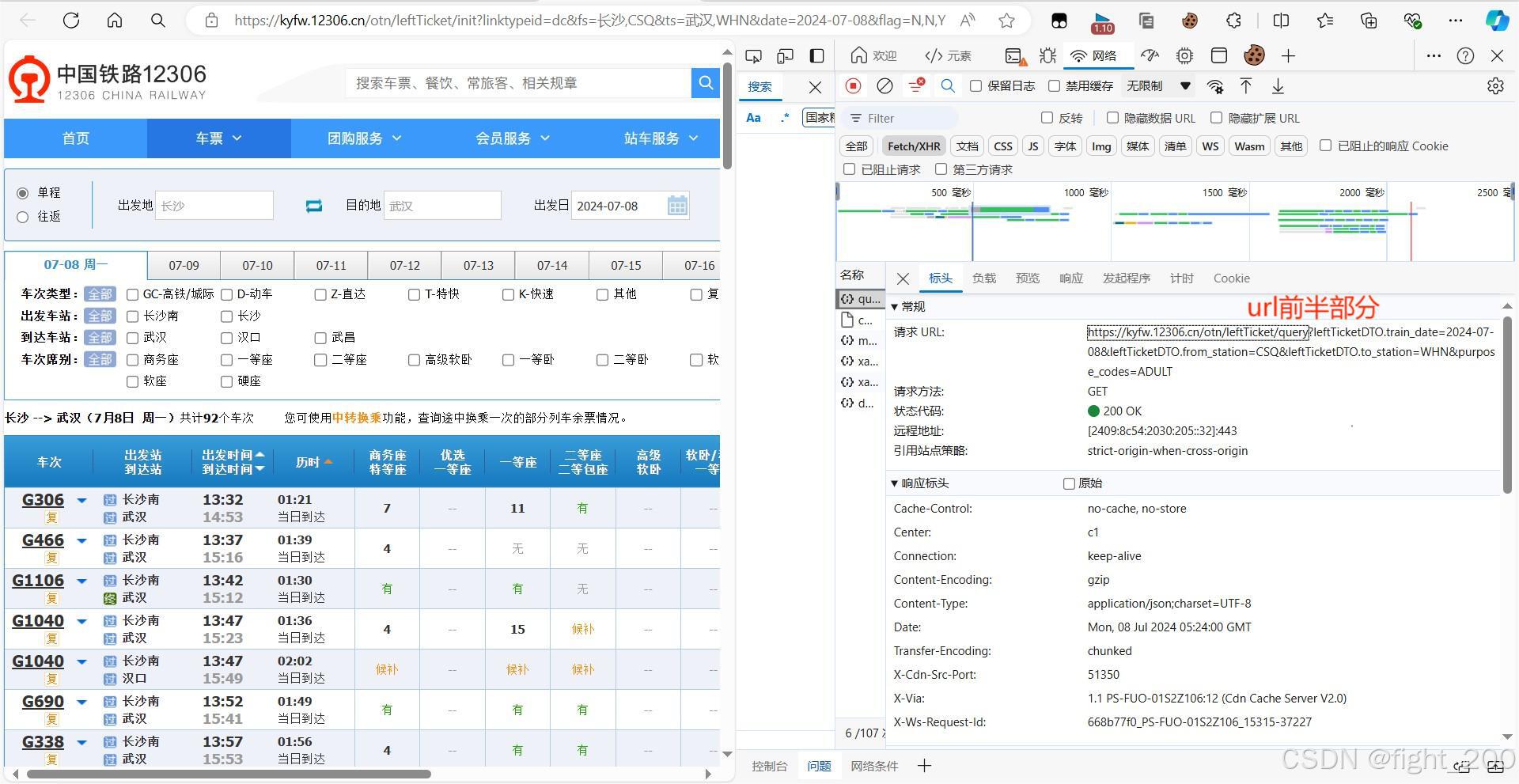
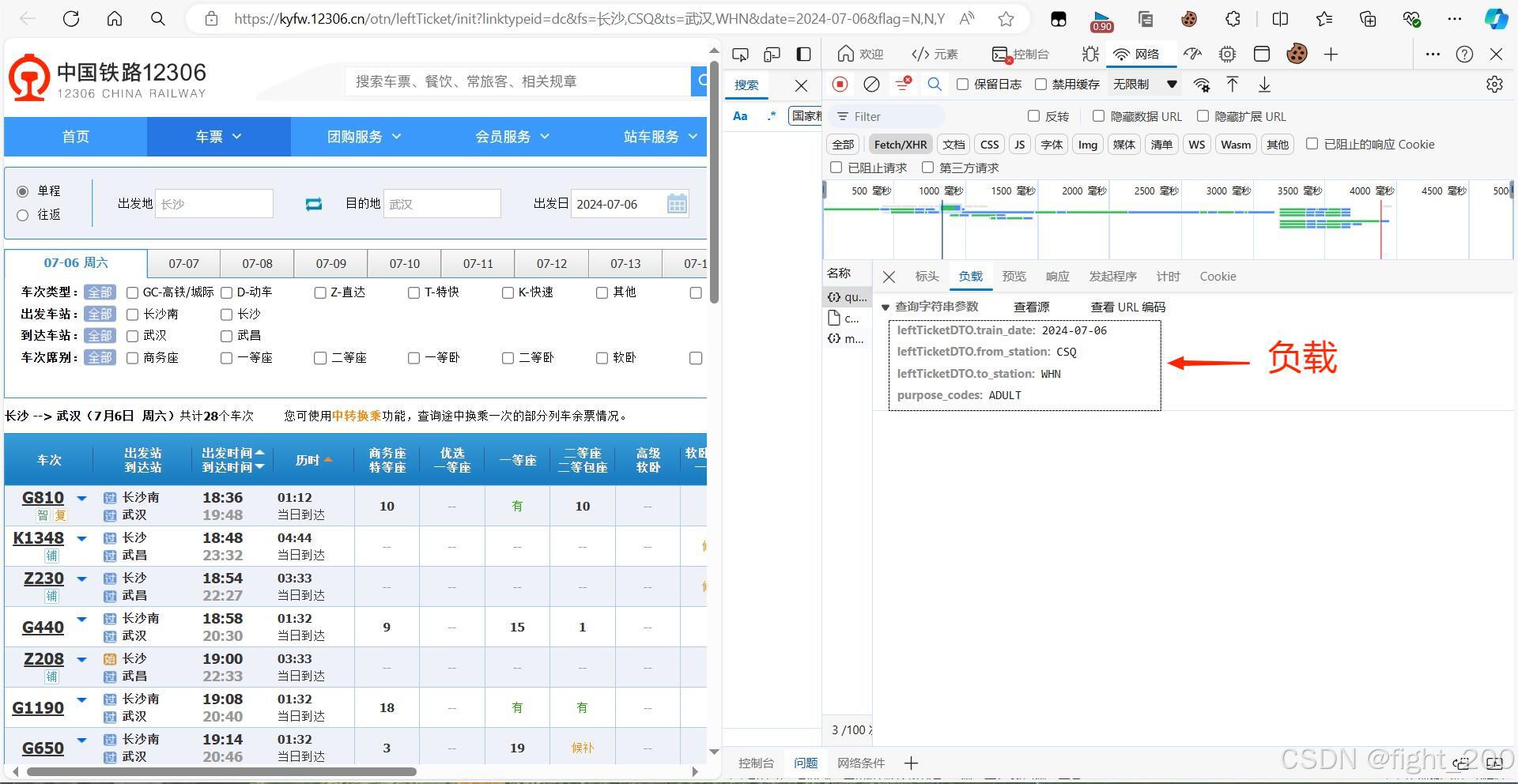
两者结合得到需要的url(带负载,请求头)
front_url = "https://kyfw.12306.cn/otn/leftTicket/query"
data = {
"leftTicketDTO.train_date": time,
"leftTicketDTO.from_station": start,
"leftTicketDTO.to_station": end,
"purpose_codes": "ADULT"
}
header = {
"User Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/"
"537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
"Cookie": ("_uab_collina=171612732780866759993918; JSESSIONID=1753D82C75A9D1B5FD26D74F047D5B2F; _jc_save_wfdc_flag=dc; BIGipServerotn=1373176074.50210.0000; BIGipServerpassport=837288202.50215.0000; guidesStatus=off; highContrastMode=defaltMode; cursorStatus=off; route=c5c62a339e7744272a54643b3be5bf64; BIGipServerportal=3084124426.17183.0000; _jc_save_fromStation=%u957F%u6C99%2CCSQ; "
"_jc_save_toStation=%u4E0A%u6D77%2CSHH; _jc_save_fromDate=2024-06-28; _jc_save_toDate=2024-06-28")
}
front_content = requests.get(front_url, params=data, headers=header) #发起requests请求
(注:长沙:CSQ 武汉:WHN,这些城市对应的代码放在文末的json文件里面,需要自取)
3.额外设计
(1)对出发地——目的地——时间,这三个输入增加了一个函数进行判断输入格式或内容是否正确,并返回三个元素组成的列表
#判断函数并且返回出发地——目的地——时间(列表)
def chaxun(city):
#判断出发地
while True:
in_start = input("请输入出发地:\n")
if in_start not in city.keys():
print("输入的城市有误,请重新输入:")
continue
else:
break
#判断目的地
while True:
in_end = input("请输入目的地:\n")
if in_end not in city.keys():
print("输入的城市有误,请重新输入:")
continue
else:
break
# 判断输入时间格式
while True:
time = input("请输入时间(格式:xxxx.xx.xx):\n")
if (len(time.split(".")) != 3 or len(time.split(".")[0]) != 4
or len(time.split(".")[1]) != 2 or len(time.split(".")[2]) != 2):
print("输入的时间有误,请重新输入:")
continue
else:
break
time = time.replace('.', '-')
in_start = city[in_start]
in_end = city[in_end]
chaxun_list = [in_start, in_end, time]
return chaxun_list
(2)对需要查询的动车类型单独增加一个函数,返回动车类型
def the_kind():
#输入动车类型
kind_list = ['高铁', '火车', '全部']
while True:
kind = input("请输入要查询的类型(高铁/火车/全部):\n")
if kind in kind_list:
break
else:
continue
return kind
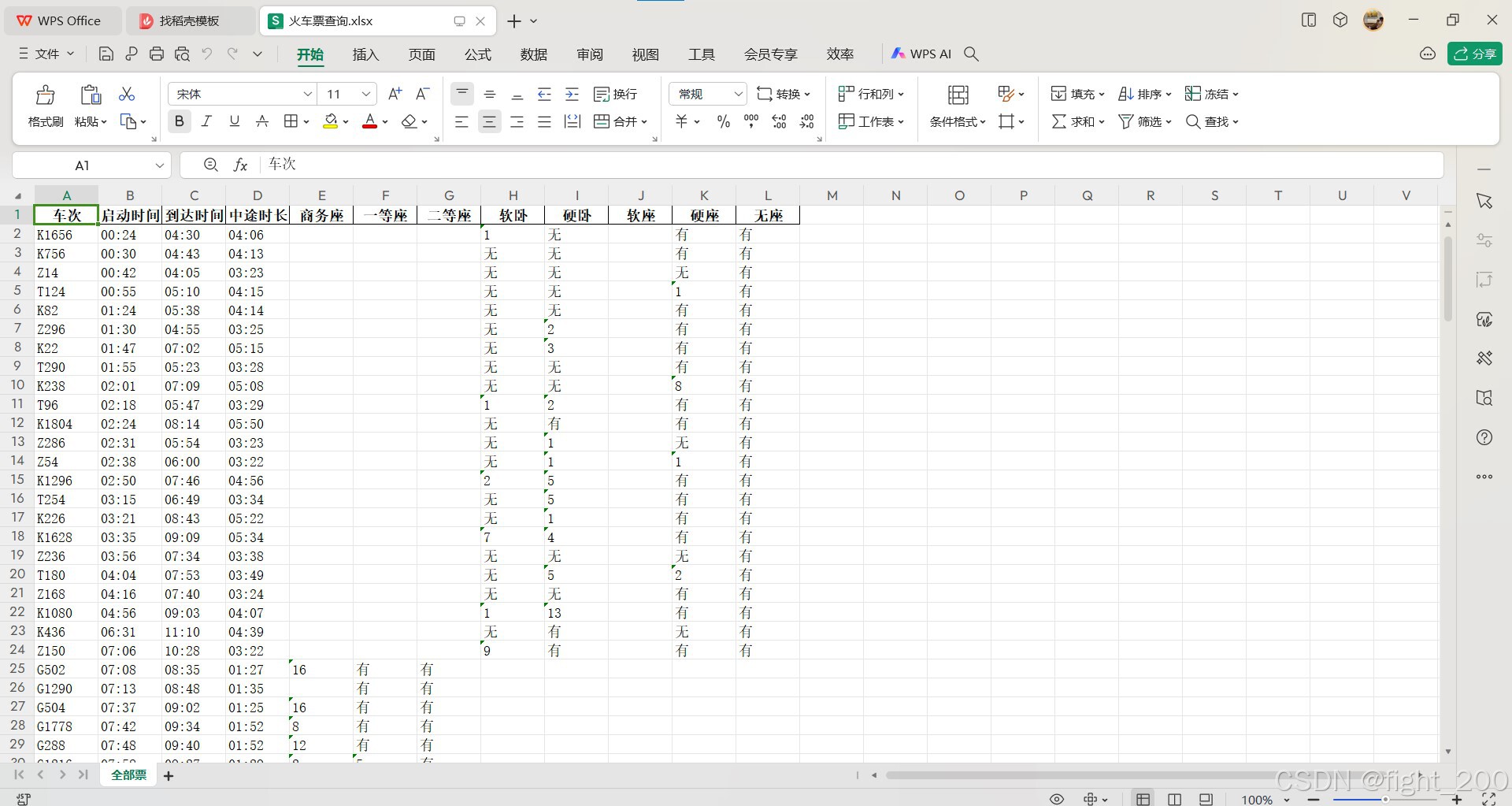
(3)将结果写入excel文件,结果更加整齐清晰
#三种类型票 高铁 火车 全部
content_G = pd.DataFrame(lst_G)
content_KTZ = pd.DataFrame(lst_KTZ)
content_all = pd.DataFrame(lst_all)
if kind == '高铁':
with pd.ExcelWriter("火车票查询.xlsx",mode="w") as w:
content_G.to_excel(w, sheet_name="高铁票", index=False)
elif kind == '火车':
with pd.ExcelWriter("火车票查询.xlsx", mode="w") as w:
content_KTZ.to_excel(w, sheet_name="火车票", index=False)
else:
with pd.ExcelWriter("火车票查询.xlsx", mode="w") as w:
content_all.to_excel(w, sheet_name="全部票", index=False)
4.完整代码
from threading import Thread
import requests
import pandas as pd
import json
#导入城市
f2 = open('city.json', 'r')
city = json.load(f2)
#查询函数
def chaxun(city):
#判断出发地
while True:
in_start = input("请输入出发地:\n")
if in_start not in city.keys():
print("输入的城市有误,请重新输入:")
continue
else:
break
#判断目的地
while True:
in_end = input("请输入目的地:\n")
if in_end not in city.keys():
print("输入的城市有误,请重新输入:")
continue
else:
break
# 判断输入时间格式
while True:
time = input("请输入时间(格式:xxxx.xx.xx):\n")
if (len(time.split(".")) != 3 or len(time.split(".")[0]) != 4
or len(time.split(".")[1]) != 2 or len(time.split(".")[2]) != 2):
print("输入的时间有误,请重新输入:")
continue
else:
break
time = time.replace('.', '-')
in_start = city[in_start]
in_end = city[in_end]
chaxun_list = [in_start, in_end, time]
return chaxun_list
#动车类型函数
def the_kind():
#输入动车类型
kind_list = ['高铁', '火车', '全部']
while True:
kind = input("请输入要查询的类型(高铁/火车/全部):\n")
if kind in kind_list:
break
else:
continue
return kind
#爬取并输出函数
def func(time, start, end, kind):
front_url = "https://kyfw.12306.cn/otn/leftTicket/query"
data = {
"leftTicketDTO.train_date": time,
"leftTicketDTO.from_station": start,
"leftTicketDTO.to_station": end,
"purpose_codes": "ADULT"
}
header = {
"User Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/"
"537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
"Cookie": ("_uab_collina=171612732780866759993918; JSESSIONID=1753D82C75A9D1B5FD26D74F047D5B2F; _jc_save_wfdc_flag=dc; BIGipServerotn=1373176074.50210.0000; BIGipServerpassport=837288202.50215.0000; guidesStatus=off; highContrastMode=defaltMode; cursorStatus=off; route=c5c62a339e7744272a54643b3be5bf64; BIGipServerportal=3084124426.17183.0000; _jc_save_fromStation=%u957F%u6C99%2CCSQ; "
"_jc_save_toStation=%u4E0A%u6D77%2CSHH; _jc_save_fromDate=2024-06-28; _jc_save_toDate=2024-06-28")
}
front_content = requests.get(front_url, params=data, headers=header)
front_content.encoding = "utf-8"
front_content.close() #关闭requests
result = front_content.json()['data']['result'] #返回json字典数据
lst_G = [] #高铁信息
lst_KTZ = [] #火车信息
lst_all = [] #全部信息
for it in result:
info_list = it.split("|") #切割数据,中文转英文
num = info_list[3]
start = info_list[8] #启动时间
arrive = info_list[9] #到达时间
time = info_list[10] #经历时长
business_seat = info_list[32] #高铁商务座
first_seat = info_list[31] #高铁一等座
second_seat = info_list[30] #高铁二等座
soft_sleeper = info_list[23] #火车软卧
hard_sleeper = info_list[28] #火车硬卧
soft_seat = info_list[27] #火车软座
hard_seat = info_list[29] #火车硬座
none_seat = info_list[26] #无座
dic = {
"车次": num,
"启动时间": start, # 启动时间
"到达时间": arrive, #到达时间
"中途时长": time, #经历时长
"商务座": business_seat, #高铁商务座
"一等座": first_seat, #高铁一等座
"二等座": second_seat, #高铁二等座
"软卧": soft_sleeper, #火车软卧
"硬卧": hard_sleeper, #火车硬卧
"软座": soft_seat, #火车软座
"硬座": hard_seat, #火车硬座
"无座": none_seat #无座
}
#进行三种分类
lst_all.append(dic)
if 'G' in num:
lst_G.append(dic)
else:
lst_KTZ.append(dic)
#dataframe格式设置
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 100)
#三种类型票 高铁 火车 全部
content_G = pd.DataFrame(lst_G)
content_KTZ = pd.DataFrame(lst_KTZ)
content_all = pd.DataFrame(lst_all)
if kind == '高铁':
with pd.ExcelWriter("火车票查询.xlsx",mode="w") as w:
content_G.to_excel(w, sheet_name="高铁票", index=False)
elif kind == '火车':
with pd.ExcelWriter("火车票查询.xlsx", mode="w") as w:
content_KTZ.to_excel(w, sheet_name="火车票", index=False)
else:
with pd.ExcelWriter("火车票查询.xlsx", mode="w") as w:
content_all.to_excel(w, sheet_name="全部票", index=False)
if __name__ == '__main__':
lis = chaxun(city)
in_start = lis[0]
in_end = lis[1]
time = lis[2]
kind = the_kind()
func(time, in_start, in_end, kind)
5.结果

额外:城市代码的city.json文件在本人主页的资源里面,可以直接免费下载保存