YOLO (You Only Look Once) 是一种经典的目标检测算法,旨在通过一个统一的卷积神经网络(CNN)进行目标检测,最大化检测速度并保持较高的精度。YOLO 在目标检测领域产生了巨大的影响,并且经过了多个版本的迭代。下面是 YOLOv1(YOLO 的第一版)的详细介绍:
YOLOv1(You Only Look Once)
YOLOv1 于 2016 年由 Joseph Redmon 等人提出,旨在通过“单次看”完成目标检测任务。与其他目标检测方法(如 R-CNN 系列方法)不同,YOLO 不依赖于选择性搜索等区域生成方法,而是直接回归预测整个图像中所有目标的类别和位置。YOLOv1 的核心思想是:将目标检测问题转化为一个回归问题,直接从输入图像中预测目标类别和位置。
YOLOv1 的核心结构
- 单一卷积神经网络:
- YOLOv1 采用了一个单一的卷积神经网络架构来进行目标检测。与传统的目标检测方法不同,YOLO 不需要先生成候选区域(如 R-CNN 中的选择性搜索),而是将目标检测任务直接作为一个回归问题来解决。该网络会根据图像的输入输出预测每个格子中的目标类别和位置。
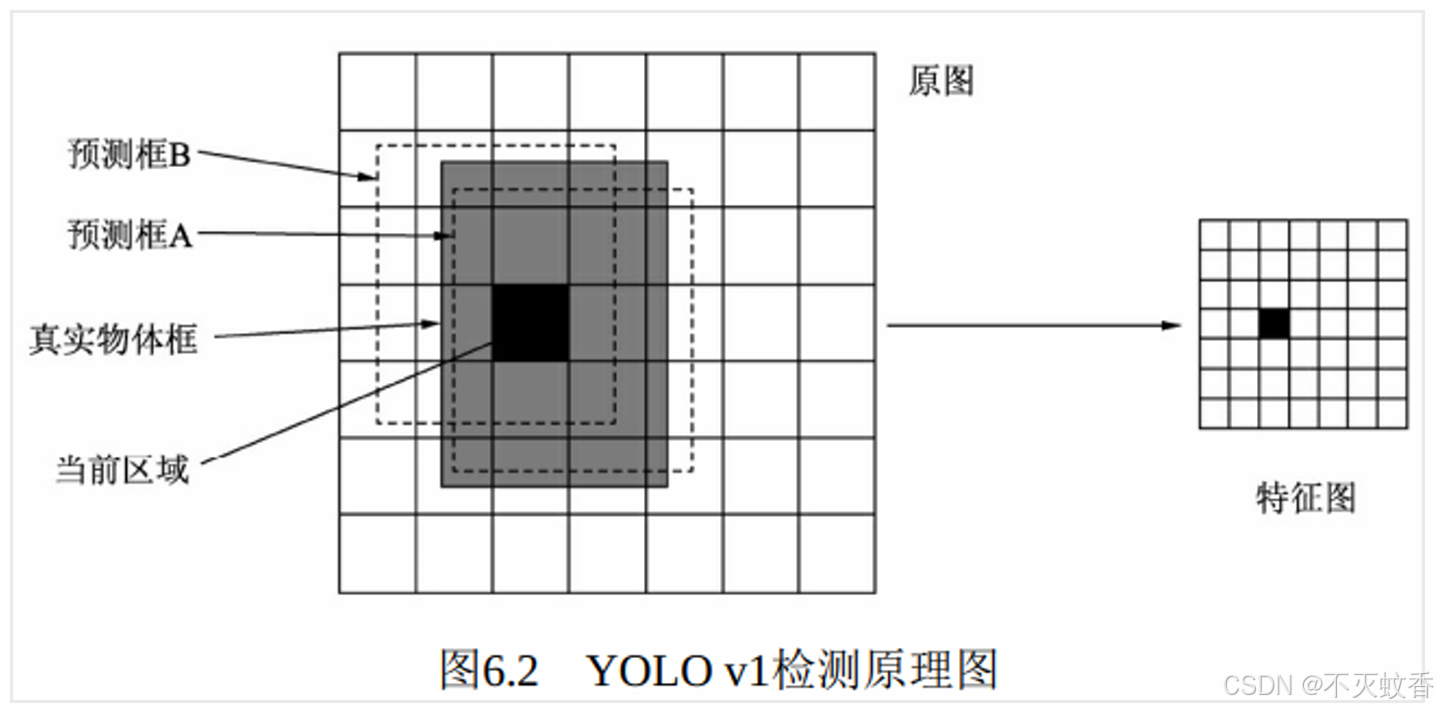
- 网格划分:
- YOLO 将输入图像划分成 S × S 的网格(例如 7×7),每个网格负责预测该区域内的目标。每个网格单元会预测固定数量的边界框(bounding boxes)和对应的置信度分数。此外,网格还会预测这些边界框中物体的类别概率。
- 边界框预测:
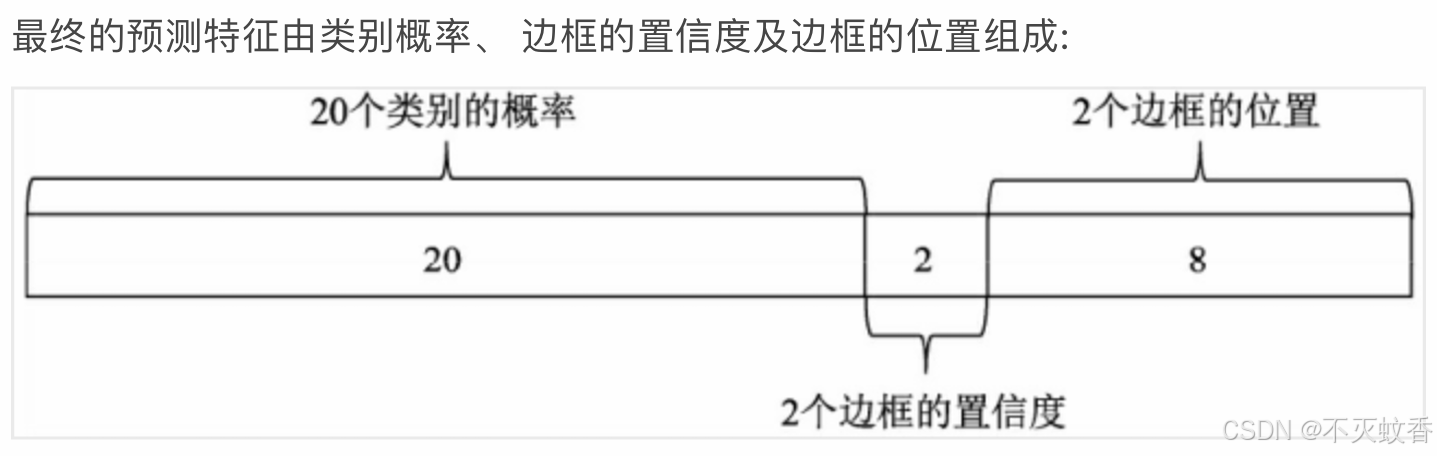
- YOLOv1 对每个网格单元进行 B 个边界框的预测。每个边界框由 (x, y, w, h) 和置信度(confidence)组成,其中:
- (x, y) 是边界框的中心坐标。
- (w, h) 是边界框的宽度和高度。
- 置信度 表示边界框内是否包含目标以及预测框与真实框之间的重叠度(IoU, Intersection over Union)。
- YOLOv1 对每个网格单元进行 B 个边界框的预测。每个边界框由 (x, y, w, h) 和置信度(confidence)组成,其中:
- 类别概率:
- YOLOv1 还会为每个网格单元预测目标的 C 类别概率。每个类别的概率是条件概率,表示该网格单元内是否包含某个类别的目标。
- 最终输出:
- YOLOv1 的输出是一个包含多个边界框及其对应类别的集合。这些输出通过非极大值抑制(NMS, Non-Maximum Suppression)来去除重复的框,最终输出最优的检测结果。
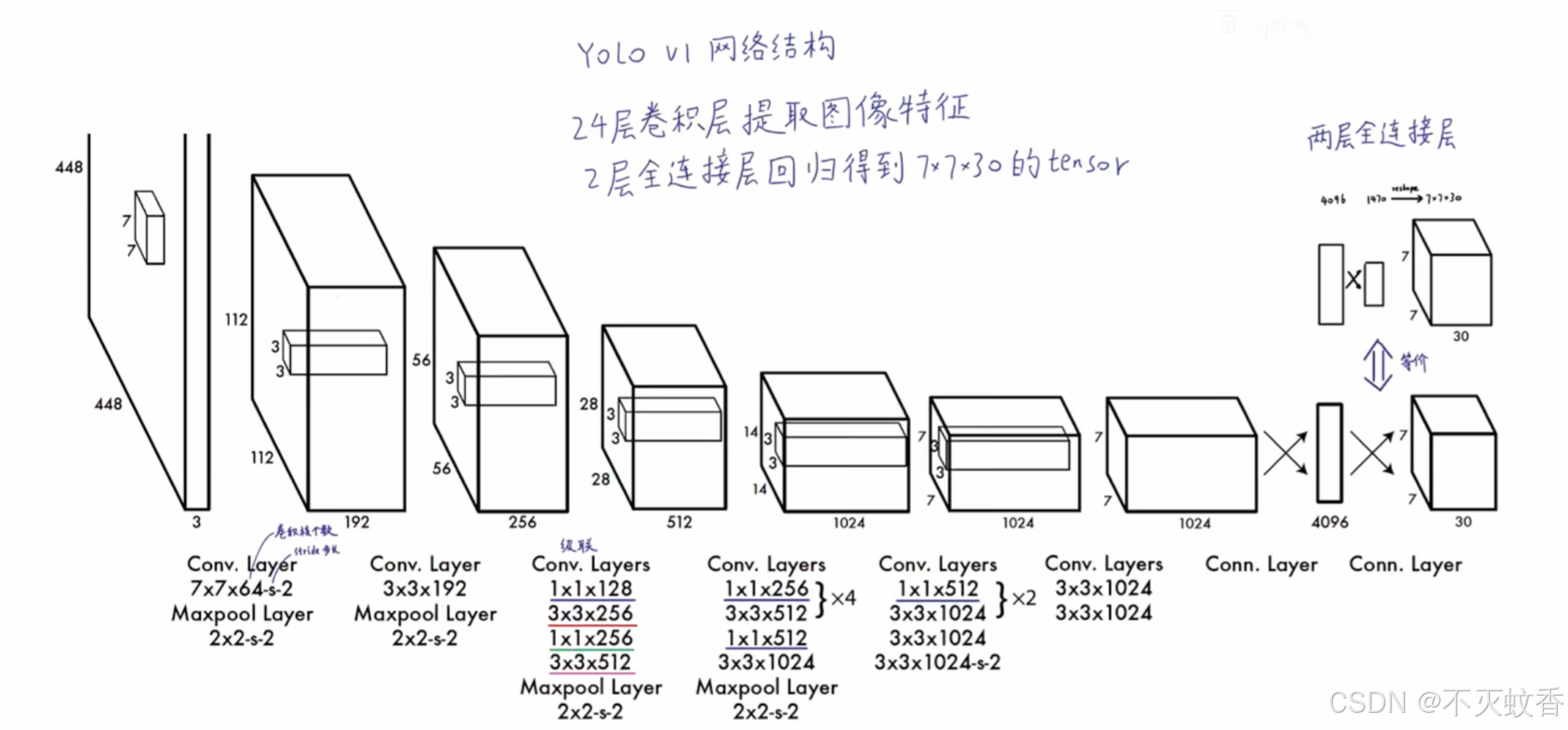


YOLOv1 网络架构
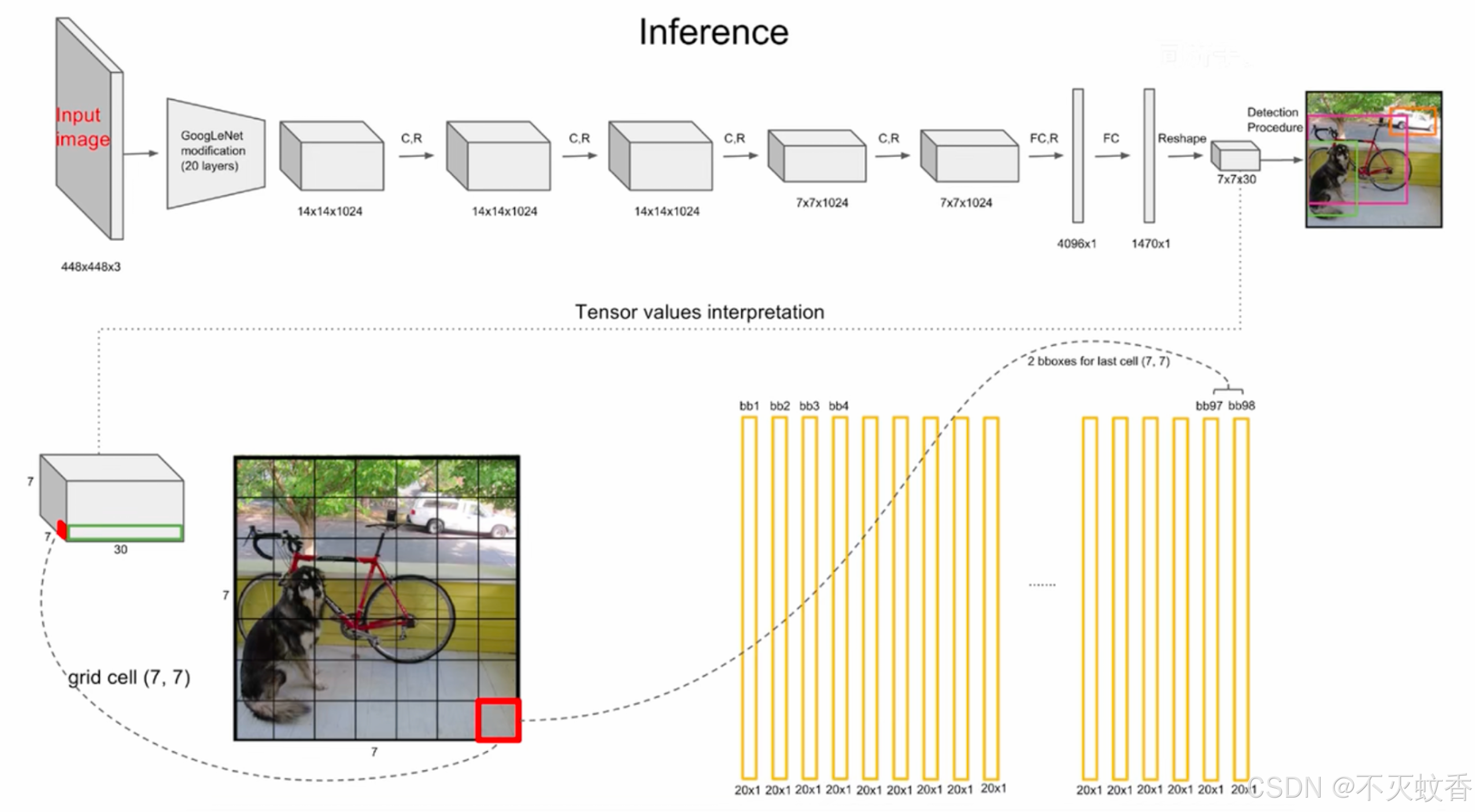
YOLOv1 网络架构的核心部分是一个改进版的 GoogleNet,包含了多个卷积层、池化层、全连接层等。YOLOv1 使用了一个较小的卷积神经网络来处理图像,并且整个网络的输入尺寸通常为 448×448 的图像。网络的输出层是一个 S × S × (B * 5 + C) 的张量,其中:
- S × S:是网格的尺寸(例如 7×7)。
- B:每个网格单元预测的边界框个数。
- 5:每个边界框的参数(x, y, w, h 和置信度)。
- C:类别数。
例如,对于一个 7×7 网格,且每个网格有 2 个边界框,检测 20 种物体类别的模型,网络的输出层将会是: 7×7×(2×5+20)=7×7×30
YOLOv1 损失函数

YOLOv1 使用一个综合性的损失函数,旨在优化位置回归、类别预测以及置信度的预测。损失函数包含三个部分:
- 定位误差(Localization Loss):
- 衡量预测的边界框的中心坐标(x, y)以及宽度、高度(w, h)与真实边界框之间的差异。通常使用 均方误差(MSE)来衡量。
- 置信度误差(Confidence Loss):
- 衡量每个边界框的置信度与真实置信度之间的差异,真实框的置信度为 1,背景框为 0。
- 类别误差(Classification Loss):
- 衡量预测类别的概率与真实类别之间的差异。对于每个网格单元,YOLOv1 预测的类别概率与真实类别进行比较。
YOLOv1 的优缺点
优点:
-
速度快:
- YOLOv1 使用单一的神经网络进行目标检测,避免了像选择性搜索那样繁琐的候选框生成步骤,因此其检测速度非常快。
-
全局信息:
- 由于 YOLO 采用的是一个全图卷积网络,它能够学习图像的全局信息,避免了局部信息丢失的问题。
-
实时检测:
- 由于其结构简单且高效,YOLOv1 可以进行实时目标检测,非常适合视频监控、自动驾驶等应用场景。
缺点:
-
小物体检测精度较低:
- YOLOv1 在处理小物体时会出现困难,因为其较大的网格划分使得小物体可能会被忽略或无法精确定位。
-
边界框回归的限制:
- YOLOv1 在回归边界框时,使用了一个固定大小的网格,这可能会导致某些物体被误检测或误分类。
-
无法处理密集目标:
- YOLOv1 对于目标密集的图像(例如多个物体重叠)可能会有检测漏检的情况。
YOLOv1 改进与后续版本
YOLOv1 虽然是一个创新的目标检测方法,但由于它在小物体检测和边界框回归方面存在问题,因此后续的版本(如 YOLOv2、YOLOv3、YOLOv4 和 YOLOv5)对其进行了改进:
- YOLOv2:采用了 anchor boxes 和更多的细节优化,显著提高了检测精度。
- YOLOv3:进一步改进了特征提取网络,增加了多个尺度的预测,并采用了更高效的训练策略。
- YOLOv4 和 YOLOv5:在 YOLOv3 的基础上增加了更多的优化,如数据增强、改进的损失函数、训练技巧等,进一步提高了检测精度和速度。
总结
YOLOv1 通过将目标检测问题转化为回归问题,提供了一种高效、快速的检测方式。尽管它在小物体检测和密集目标的场景中存在一些局限,但它的创新性为后续目标检测方法的发展奠定了基础。如果你有兴趣实现 YOLOv1 或者了解更深入的细节,欢迎继续提问!