YOLOv2 (You Only Look Once Version 2),也称为 YOLO9000,是目标检测算法 YOLO(You Only Look Once)系列的第二个版本。它在 YOLOv1 的基础上进行了很多改进,以提高检测精度,特别是在小物体检测和多类别检测上取得了显著的进展。YOLOv2 引入了更多的技术细节,并优化了网络结构,进一步提高了检测速度和准确性。
YOLOv2 的主要改进
YOLOv2 主要通过以下几个方面的改进,使得其性能得到了显著提高:
1. Anchor Boxes
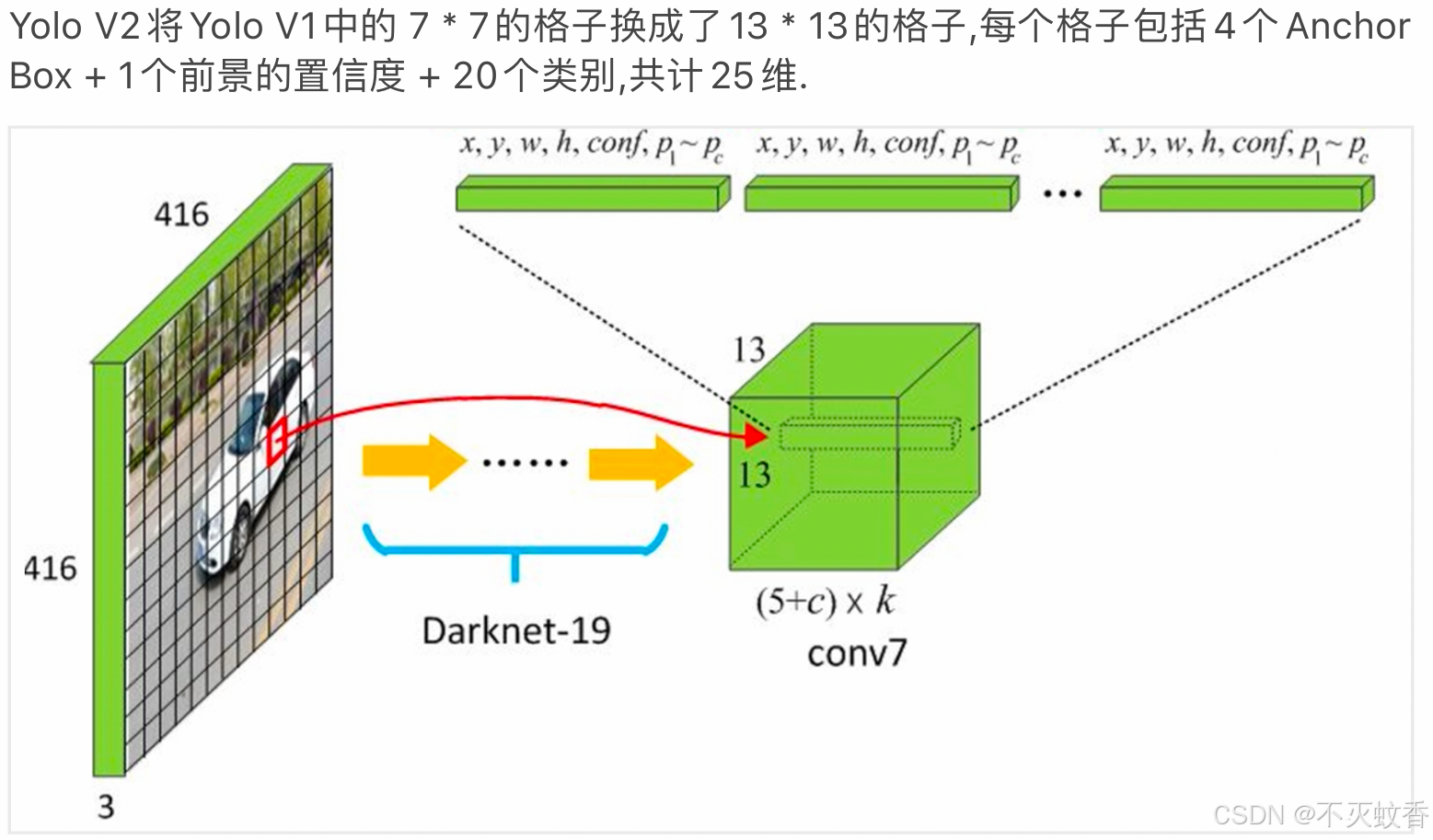
- YOLOv1 通过回归边界框的坐标来预测物体的位置,但其对多个目标重叠的处理能力有限,特别是对于小物体。
- YOLOv2 引入了 anchor boxes,即先验框(也叫锚框)。这些锚框是预定义的边界框(通常有多个大小和长宽比),用于帮助模型更好地拟合物体的尺寸和形状。YOLOv2 使用 k-means 聚类来确定最优的锚框大小。
- 这种方式使得 YOLOv2 在面对不同尺寸的物体时能够更好地进行预测,显著提高了检测的精度。
2. Darknet-19(改进的特征提取网络)
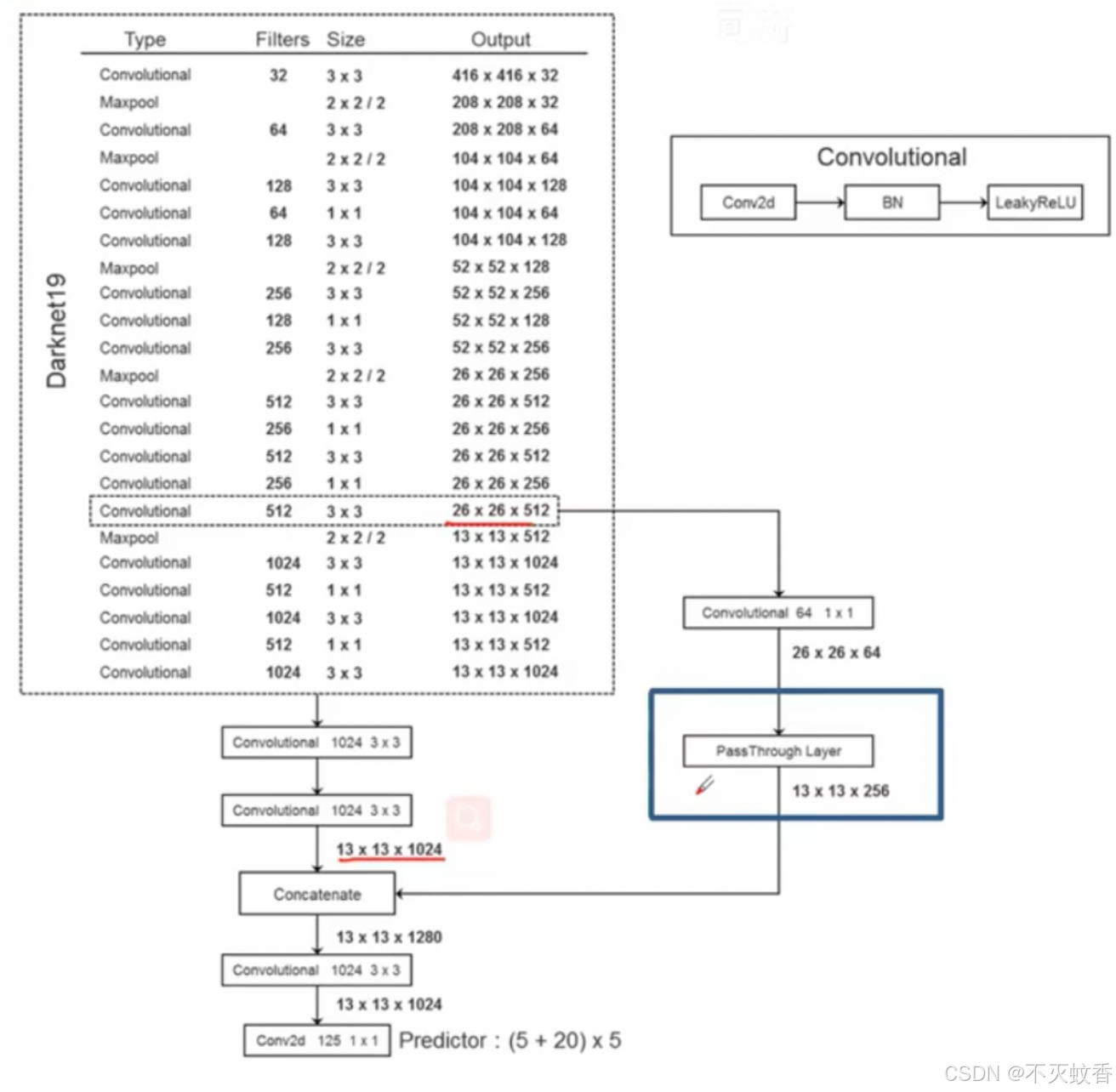
- YOLOv2 使用了一个新的特征提取网络 Darknet-19,这是一个由 19 层卷积层和 5 层最大池化层组成的 CNN 网络。
- 相比 YOLOv1 使用的较浅的网络结构,Darknet-19 增强了对图像特征的提取能力,使得 YOLOv2 在更复杂的场景中能够提取到更丰富的特征。
- Darknet-19 是基于 VGG 的架构,但通过减少全连接层的数量来减少计算量,使得网络更加高效。
3. Batch Normalization(批归一化)
- YOLOv2 引入了 Batch Normalization,这是神经网络中常用的一种技术,能够加速训练并提高模型的稳定性。
- 通过对每一层的输入进行标准化,Batch Normalization 可以减小梯度消失问题,提升模型的收敛速度,进而使得训练更加高效。
4. 多尺度训练

- YOLOv2 在训练过程中采用了 多尺度训练,即在每个训练周期随机改变输入图像的尺寸。这样可以使得模型在不同的尺度下进行训练,提高模型在各种尺寸物体上的适应性。
- 多尺度训练有助于提高模型对不同大小物体的识别能力,尤其是对小物体的识别。
5. 预训练和迁移学习
- YOLOv2 采用了 迁移学习 的策略,先用 ImageNet 数据集上的预训练模型进行训练,再进行目标检测的微调。
- 这样做可以充分利用已有的大规模图像分类数据,提高目标检测的性能和收敛速度。
6. 不使用全连接层
- 与 YOLOv1 的网络结构不同,YOLOv2 去除了全连接层(fully connected layers)。这使得 YOLOv2 在保持高效性的同时,减少了参数的数量,从而加速了推理过程。
7. YOLO9000(多类别检测)
- YOLOv2 引入了 YOLO9000,这使得模型可以同时进行 物体检测 和 物体分类,能够识别多达 9000 种类别。
- 通过将 YOLO 与 WordTree(一个层次化的词汇树)结合,YOLO9000 可以通过微调检测到从通用物体到特殊物体的大范围类别。
YOLOv2 网络架构
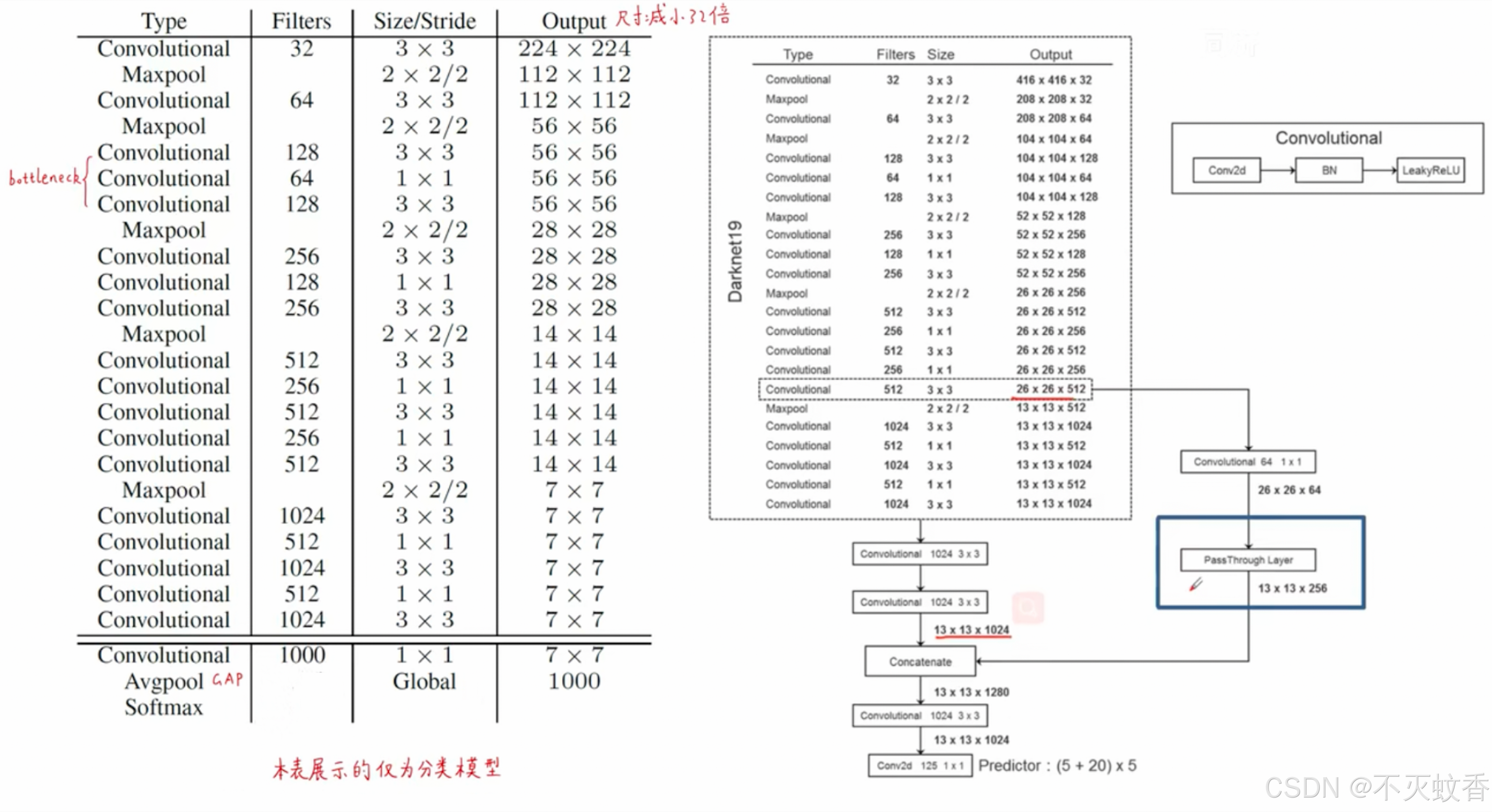
YOLOv2 网络的架构通常包含以下几个部分:
- 输入层:YOLOv2 使用了固定大小的输入图像(通常为 416×416 或 608×608),网络会对输入图像进行缩放。
- Darknet-19 特征提取网络:作为 YOLOv2 的特征提取部分,它由 19 层卷积层和 5 层最大池化层组成。其目的是提取图像中的高层次特征。
- 卷积层和批归一化:使用卷积层和批归一化技术来提取特征,同时减小训练过程中的梯度消失问题。
- 检测头(Detection Head):该部分用于预测边界框(包括位置、尺寸和置信度)以及每个边界框所属的类别概率。
- 输出层:输出一个 S × S × (B × 5 + C) 的张量,其中:
- S × S:网格的尺寸(通常为 13×13 或 19×19)。
- B:每个网格单元的锚框数量。
- 5:每个边界框的预测信息(位置:x, y, w, h 和置信度)。
- C:类别数。
YOLOv2 损失函数
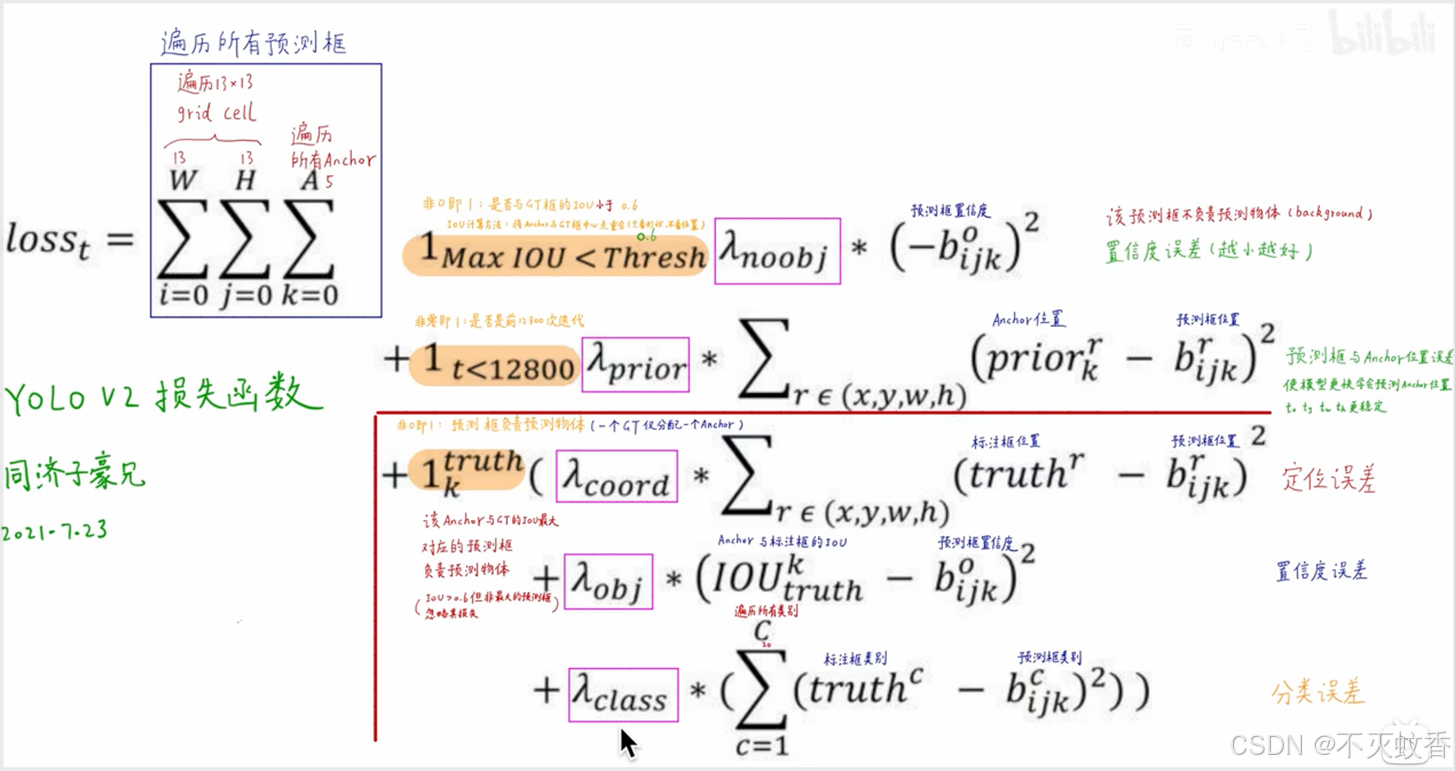
YOLOv2 的损失函数包含三个部分,旨在平衡位置回归、类别预测和置信度预测:
- 定位损失(Localization Loss):通过均方误差(MSE)计算边界框的位置(x, y, w, h)与真实值之间的差异。
- 置信度损失(Confidence Loss):计算预测的置信度与实际置信度之间的误差。
- 类别损失(Classification Loss):衡量预测的类别与真实类别之间的差异,通常使用交叉熵损失(Cross Entropy Loss)来计算。
YOLOv2 的优缺点
优点:
-
速度快,适用于实时检测:
- 由于其轻量级的架构,YOLOv2 保持了 YOLOv1 的速度优势,适用于实时目标检测。
-
改进的小物体检测:
- 引入了 anchor boxes 后,YOLOv2 在检测小物体时的表现比 YOLOv1 更好,能够处理多种尺寸的物体。
-
多类别检测(YOLO9000):
- YOLOv2 可以识别更多种类的物体,达到 9000 多种类别,适应了大规模物体检测的需求。
-
高精度和高效性:
- YOLOv2 通过优化网络结构和采用多尺度训练,大大提高了精度,同时保持了高效的推理速度。
缺点:
-
处理密集物体有一定困难:
- 对于物体重叠严重的场景,YOLOv2 仍然可能出现检测漏检的情况,尤其是在密集目标的检测中。
-
小物体检测仍有局限:
- 虽然 YOLOv2 在小物体检测上有了改进,但它仍然不如某些其他方法(如 Faster R-CNN)精确,尤其是在图像中物体密集、尺寸差异较大的情况下。
-
对较小物体的定位精度有待提高:
- 尽管引入了 anchor boxes,YOLOv2 在处理小物体时可能仍然不如基于区域的检测方法。
YoloV2源码:
https://www.cnblogs.com/han-sy/p/13301054.html
https://zhuanlan.zhihu.com/p/35325884
YOLOv2 总结
YOLOv2 在 YOLOv1 的基础上做出了很多改进,特别是在 anchor boxes、特征提取网络和多尺度训练方面。它极大地提高了检测精度,尤其是在小物体和多类别检测方面。YOLOv2 保持了 YOLO 系列的一贯优势——高速,并且在 YOLO9000 的支持下,扩展了检测类别的范围,成为了一个在速度和精度上都非常优秀的目标检测算法。