链表的结构分为8中,其实搞懂了单链表和双向哨兵位循环链表,这部分的知识也就掌握的差不多了。双向哨兵位循环链表的结构如下:

下面我从0构建一个双向哨兵位循环链表。
1、准备工作
构建节点结构体,双向循环链表的每一个节点内需要有两个指针变量,一个指针变量指向前一个节点,另一个指针变量指向后一个节点。这里将指向前一个节点的指针变量命名为prev,指向后一个节点的指针变量命名为next,那么节点的结构可以定义为:
typedef int LDataType;
typedef struct LNode
{
LDataType data;
struct LNode* prev;
struct LNode* next;
}LNode;存储的数据类型为LDataType类型。
2、链表的初始化与销毁
在链表的初始化部分,我们需要创建一个哨兵位节点用于后面链表的搭建。它的结构可以定义为下面的形式:

哨兵位节点的prev和next指针均指向自己本身从而形成循环,代码可以写成如下的形式:
LNode* LNodeCreat()
{
LNode* pHead = (LNode*)malloc(sizeof(LNode));
if (pHead == NULL)
{
perror("malloc fail");
return NULL;
}
pHead->next = pHead->prev = pHead;
return pHead;
}链表的销毁部分应该考虑到后续插入来的节点,应该遍历整个链表将每一个节点进行释放并置空,最后再销毁哨兵位的头节点。
void LNodeDestroy(LNode* pHead)
{
assert(pHead);
LNode* cur = pHead->next;
while (cur != pHead)
{
LNode* next = cur->next;
free(cur);
cur = next;
}
free(pHead);
}3、链表的末尾插入
这里将创建一个新的节点封装成一个函数,为了方便后面继续使用。创建的新节点的prev和next均指向NULL,新节点内包含的数据为用户需要插入的数据val.下面是创建节点的函数实现:
LNode* BuyNewNode(LDataType val)
{
LNode* newNode = (LNode*)malloc(sizeof(LNode));
if (newNode == NULL)
{
perror("BuyNewNode malloc fail");
return NULL;
}
newNode->prev = newNode->next = NULL;
newNode->data = val;
}创建的新节点的逻辑结构可以想象成下面的形式:

我们知道,链表的尾插是需要找到尾节点的,在这里可以很方便的找到链表的尾节点tail,因为哨兵位的头节点指向的就是链表的尾节点,所以说不管原链表中是否存在节点在这里均可视为一种情况,插入的逻辑图为:
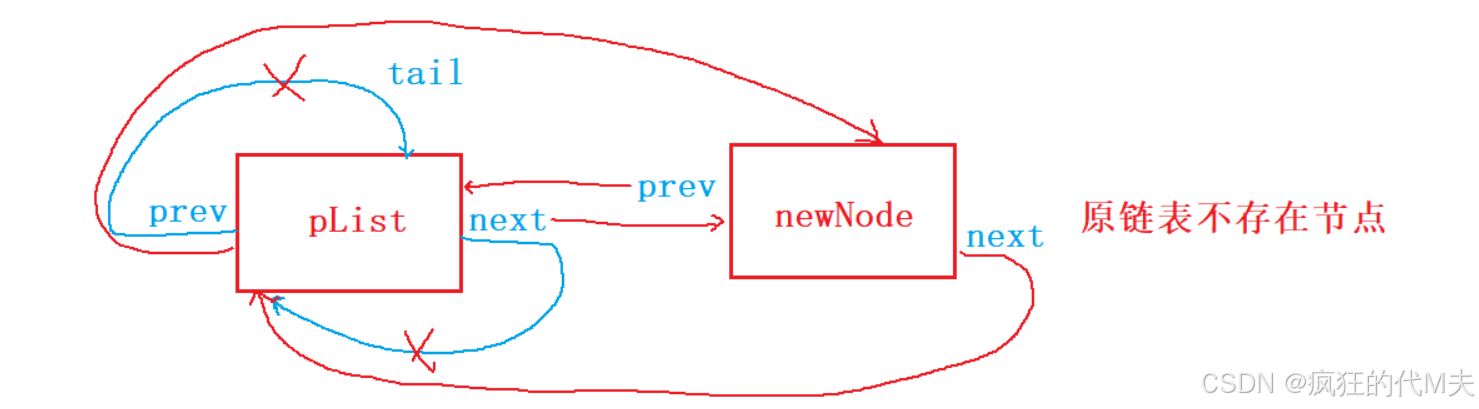

代码的实现如下:
void LNodePushBack(LNode* pHead, LDataType val)
{
assert(pHead);
LNode* newNode = BuyNewNode(val);
LNode* tail = pHead->prev;
tail->next = newNode;
newNode->prev = tail;
pHead->prev = newNode;
newNode->next = pHead;
}4、链表的打印
上面实现了链表的尾插,为了验证上述代码的正确性,这里先来写链表的打印,以便及时发现存在的问题。这里的思想就是遍历整个链表打印节点中的数据。
void LNodePrint(LNode* pHead)
{
assert(pHead);
LNode* cur = pHead->next;
while (cur != pHead)
{
printf("%d <=>", cur->data);
LNode* next = cur->next;
cur = next;
}
printf("\n");
}这里先来测试一下上述代码能否正常实现双向带头链表的功能。
//测试代码
void test()
{
LNode* pList = LNodeCreat();
LNodePushBack(pList, 1);
LNodePushBack(pList, 2);
LNodePushBack(pList, 3);
LNodePushBack(pList, 4);
LNodePrint(pList);
LNodeDestroy(pList);
}
int main()
{
test();
return 0;
}输出结果:

5、链表的头部插入
头插的操作是十分简单的,在插入之前记录一下第一个节点的位置用于和新创建的节点链接。逻辑结构可以化成如下的形式:
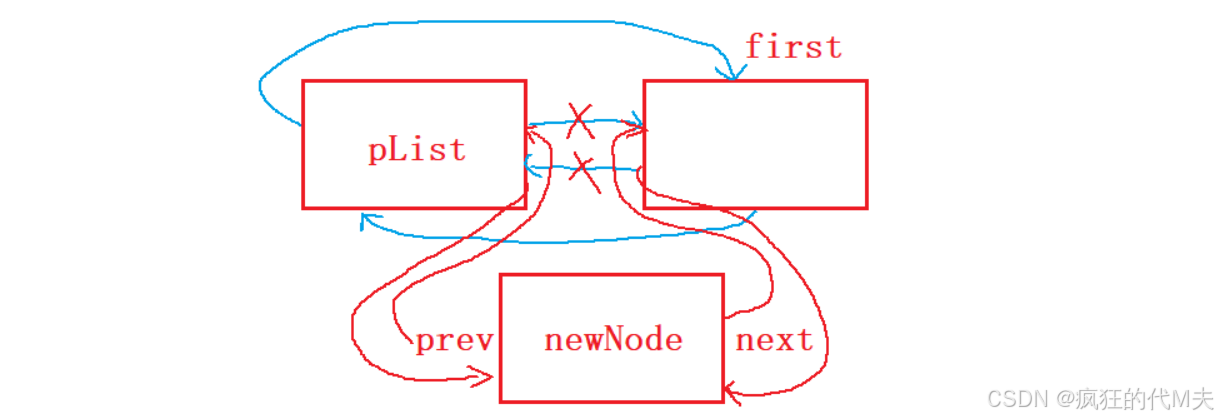
代码实现如下:
void LNodePushFront(LNode* pHead, LDataType val)
{
assert(pHead);
LNode* newNode = BuyNewNode(val);
LNode* first = pHead->next;
newNode->prev = pHead;
pHead->next = newNode;
newNode->next = first;
first->prev = newNode;
}6、链表的尾删
逻辑结构如下图所示:
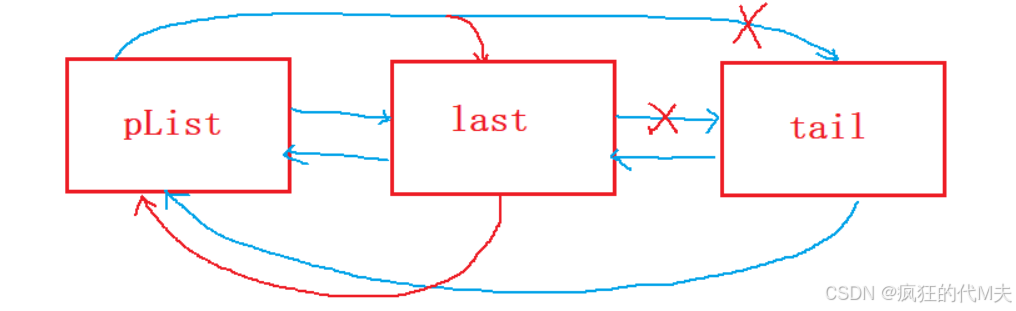
代码实现如下:
void LNodePopBack(LNode* pHead)
{
assert(pHead);
assert(pHead->prev != pHead);
LNode* tail = pHead->prev;
LNode* last = tail->prev;
pHead->prev = last;
last->next = pHead;
free(tail);
tail = NULL;
}7、链表的头删
逻辑结构如下:

代码实现:
void LNodePopFront(LNode* pHead)
{
assert(pHead);
assert(pHead->prev != pHead);
LNode* del = pHead->next;
LNode* first = del->next;
pHead->next = first;
first->prev = pHead;
free(del);
del = NULL;
}8、链表节点的查找
查找到目标节点,返回目标节点的地址,用于后续的操作。代码实现:
LNode* FindNode(LNode* pHead, LDataType val)
{
assert(pHead);
LNode* cur = pHead->next;
while (cur != pHead)
{
if (cur->data == val)
return cur;
cur = cur->next;
}
return NULL;
}9、链表在pos前插入
配合上面的查找函数进行使用,先查找到pos的位置,再进行插入操作。
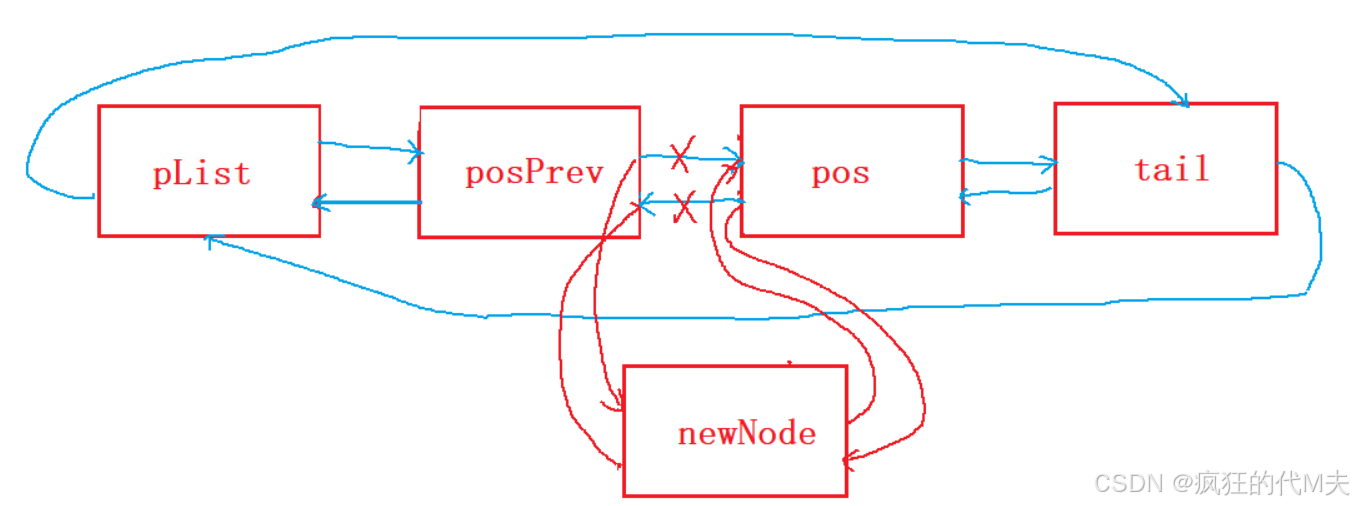
代码实现:
//在pos的前面插入
void LNodeInsert(LNode* pos, LDataType val)
{
assert(pos);
LNode* posPrev = pos->prev;
LNode* newNode = BuyNewNode(val);
posPrev->next = newNode;
newNode->prev = posPrev;
newNode->next = pos;
pos->prev = newNode;
}10、删除pos位置的节点
这个函数还是要配合查找函数进行使用,逻辑图如下:
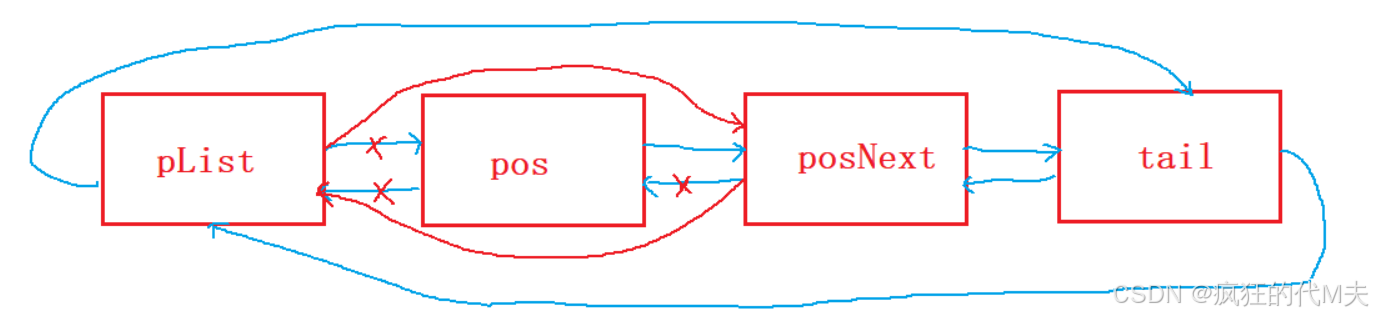
代码实现:
void LNodeErase(LNode* pos)
{
assert(pos);
LNode* posPrev = pos->prev;
LNode* posNext = pos->next;
posPrev->next = posNext;
posNext->prev = posPrev;
free(pos);
pos = NULL;
}至此,哨兵位头节点的双向循环链表已全部实现。希望能帮到读者。