目录
一、神经网络
1. 什么是神经网络
这里我们提到的神经网络,指的是人工神经网络(Artificial Neural Networks, ANNs)。它是一种计算模型,这种模型能够学习和处理复杂的数据模式,通过模拟大脑神经元之间的连接和信号传递来实现。神经网络技术旨在让机器能够像人类一样理解和处理复杂的信息。
2. 神经网络模型
神经网络模型用于处理和学习复杂的数据模式。这类模型在机器学习和人工智能领域中极为重要,因为它们能够处理非线性关系,解决分类、回归、聚类、生成等多种问题。下面给出一些关于神经网络模型的关键概念:
(1)组成部分
| 神经元(节点) | 神经网络的基本单位,相当于人脑神经网络中的神经元。每个神经元接收输入,进行加权求和,并通过激活函数产生输出 |
| 权重 | 连接神经元的权重表示输入信号对输出的影响程度 |
| 偏置 | 每个神经元还可能有一个偏置项,用于调整激活函数的阈值 |
| 激活函数 | 非线性函数,如sigmoid、ReLU(Rectified Linear Unit)、tanh等,用于决定神经元的输出 |
(2)结构
| 输入层 | 接受原始数据输入的神经元层 |
| 隐藏层 | 位于输入层和输出层之间的神经元层,可以有多层,用于提取数据的高级特征 |
| 输出层 | 产生最终预测或分类结果的神经元层 |
(3)学习过程
| 前向传播 | 数据从输入层流经隐藏层到达输出层,每次经过神经元时都会应用权重和激活函数 |
| 损失函数 | 衡量模型预测结果与实际结果之间的差距 |
| 反向传播 | 根据损失函数的梯度,从输出层向输入层反向传播误差,更新权重和偏置 |
| 优化算法 | 如梯度下降,用于调整权重和偏置,以最小化损失函数 |
(4)类型
| 前馈神经网络 | 数据只沿一个方向流动,没有反馈连接 |
| 循环神经网络(RNN) | 允许信息在神经元之间循环,适用于序列数据 |
| 卷积神经网络(CNN) | 特别适合处理图像和视频数据,利用卷积层来检测局部特征 |
| 长短时记忆网(LSTM) | 一种特殊的RNN,能更好地处理长期依赖问题 |
| 生成对抗网络(GAN) | 由两个神经网络组成,一个生成数据,另一个辨别真假,常用于生成新数据样本 |
| 自编码器 | 用于无监督学习,可以学习数据的压缩表示 |
二、循环神经网络(RNN)
在我们开始了解RNN之前,不妨先看一看最经典的神经网络结构是什么样以及它是如何工作的。
1. 引入
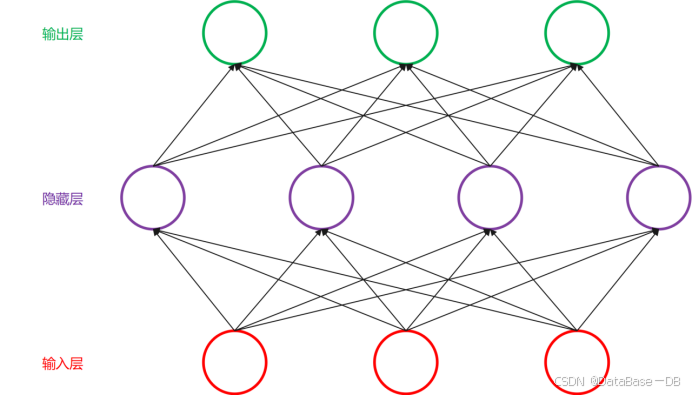
如上图所见,这是一种从下到上的神经网络结构。红色的是输入层,绿色的是输出层,紫色的是中间层(也叫隐藏层)。输入层有3个输入单元,隐藏层有4个单元,输出层有3个单元。
在该结构中,最为重要的是各单元(神经元)之间的连接,每个连接对应一个不同的权重,权重通过训练得到。
2. 神经元
在生物学上,神经元是是神经系统最基本的结构和功能单位。分为细胞体和突起两部分。细胞体由细胞核、细胞膜、细胞质组成,具有联络和整合输入信息并传出信息的作用。突起有树突和轴突两种。树突主要作用是接收其他神经元轴突传来的神经冲动并传给细胞体,轴突的主要作用是通过突触将神经冲动传给其他神经元。
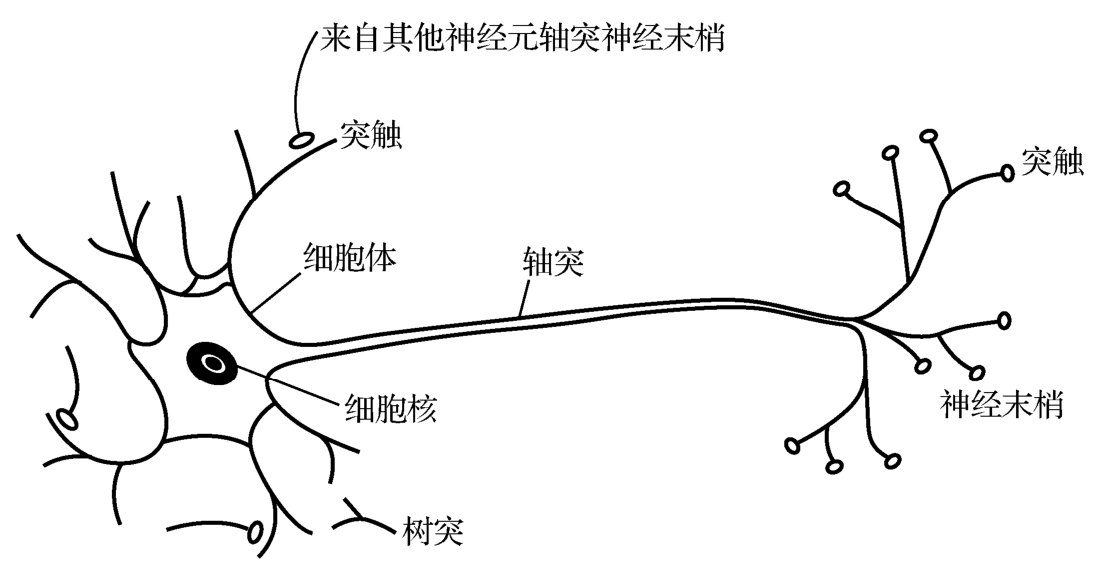
对于神经元模型也是类似的。神经元模型是一个包含输入,输出与计算功能的模型。输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算可以类比为细胞核,通过对输入信号进行加权和偏置产生输出则可以类比为突触。(这种类比并不完全对等)
下面给出一种典型的神经元模型,包含三个输入,一个输出,两个计算。
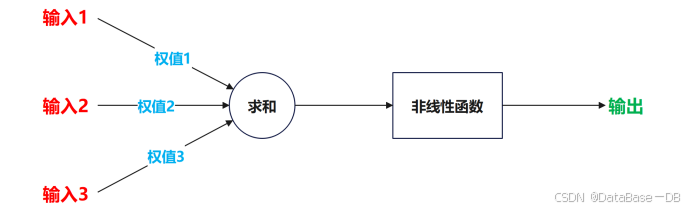
其工作过程为:每一个输入与其对应的权值做乘,得到的所有结果相加,再将相加后结果通过非线性函数计算得到一个输出,将这个过程符号化并写出输出方程如下(b为偏置)。
神经元可以看作一个计算与存储单元。计算是神经元对其输入进行计算的功能。存储是神经元会暂存计算结果,并传递到下一层。
那么我们如何理解上述过程?
对于某个数据,称之为样本。样本有四个属性,其中三个属性已知,一个属性未知。我们需要做的就是通过三个已知属性预测未知属性。
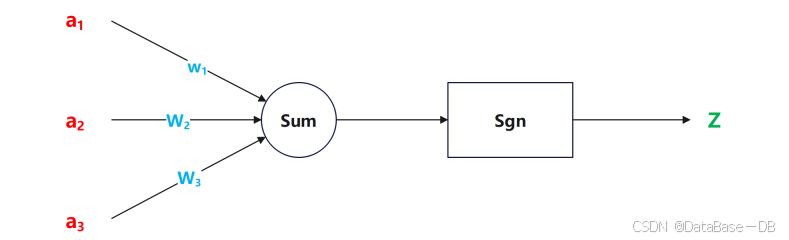
上图所示即为此过程。我们通过三个已知属性a1,a2,a3来计算未知属性z。
我们将已知属性称为特征,未知属性称为目标。假设特征与目标之间确实是线性关系,并且我们已经得到表示这个关系的权值w1,w2,w3。那么,我们就可以通过神经元模型预测新样本的目标。
实际上,关系的权值应该通过学习而动态变化,但早期的模型中权值均为预设,所以并不能学习。
关于隐藏层
我们可以看到,在以上的模型中,并没有涉及到隐藏层。
隐藏层一般出现在较为复杂的神经网络中,它们介于输入层和输出层之间,能够增强网络的表达能力和学习复杂模式的能力。
以下举例说明隐藏层工作原理
假设现在有一个简单的图像分类问题,目标是识别手写数字。我们假设使用的是一个卷积神经网络(CNN),它包含输入层、多个隐藏层(包括卷积层、池化层和全连接层)以及输出层。
输入层输入层接收一张灰度图像,例如一个28x28像素的手写数字图片。
隐藏层
- 卷积层:这个层包含多个卷积核(滤波器),每个卷积核会在输入图像上滑动,计算局部区域的加权和。例如,第一个卷积层可能有32个大小为3x3的卷积核,用于检测边缘、线条和其他简单形状。
- 激活层:通常紧跟着卷积层,应用非线性激活函数,如ReLU,以增加模型的非线性能力。
- 池化层:用于降低特征图的空间尺寸,减少计算量,同时保持最重要的特征。常见的池化操作有最大池化和平均池化。
- 全连接层:将卷积层和平铺后的特征图连接到一起,形成一个全连接的神经网络。这里的神经元可以捕捉到更复杂的特征组合,如数字的形状和模式。
输出层
输出层通常是一个softmax层,它将隐藏层的输出转换为概率分布,表示输入图像属于各个类别的可能性。
隐藏层的工作原理
- 特征检测:在卷积层中,每个卷积核学习检测特定的特征,如边缘、曲线、角等。随着网络深度的增加,隐藏层开始学习更复杂的特征,如数字的组成部分。
- 特征组合:全连接层将这些局部特征组合起来,形成对整个图像的综合理解。例如,一个卷积核可能检测到“圆圈”,另一个可能检测到“垂直线”,全连接层将这些信息结合起来,判断图像是否为数字“1”。
- 决策制定:最后,输出层基于隐藏层提取的特征,做出最终的分类决策。
3. 单层神经网络(感知机)
感知机(Perceptron)可以说是最早的具有学习能力的人工神经网络,它是神经网络的基础构建块,主要用于二分类问题。感知机模型由一个输入层直接连接到一个输出层构成,没有隐藏层。下面详细介绍感知机的工作原理:
(1)结构
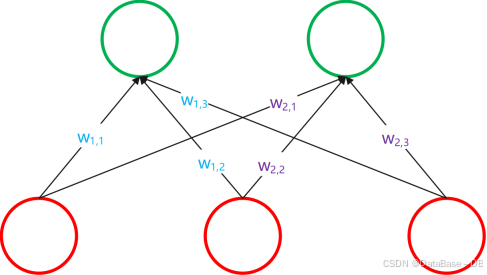
(2)工作原理
1.加权求和:感知机接收一组输入向量x = (x1, x2, ..., xn),每个输入xi都乘以一个权重wi,然后所有加权输入求和,再加上一个偏置b,得到总输入z。
2. 激活函数:总输入z通过一个激活函数f(z)转换为输出y。对于感知机,常用的激活函数是阶跃函数,当z大于0时,输出1;否则输出0。也可以使用其他阈值函数,如sigmoid函数。
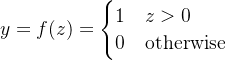
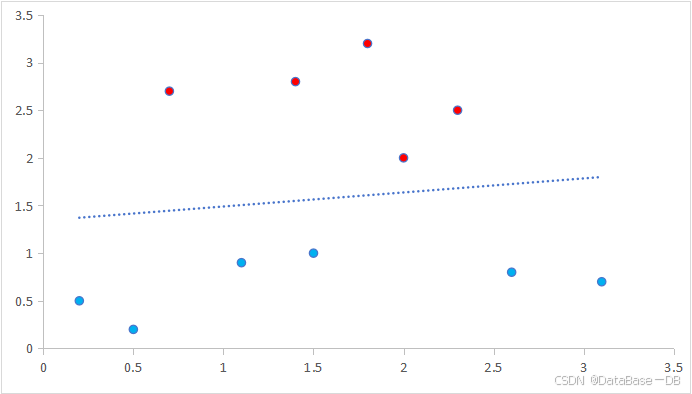
3.决策边界:感知机通过学习权重w和偏置b来定义一个决策边界,这个边界将输入空间分为两部分,一边的点被分类为一类,另一边的点被分类为另一类。
(3)训练过程
感知机的学习过程是通过调整权重和偏置来最小化分类错误。具体步骤如下:
初始化:随机初始化权重w和偏置b。
前向传播:对于每一个训练样本,计算输出y。
比较与更新:比较预测输出y与实际标签,如果分类错误,则按照一定的学习率调整权重和偏置,使分类结果更接近真实标签。
重复迭代:对于训练集中的所有样本重复步骤2和3,直到分类错误不再减少或者达到预设的最大迭代次数。
4. 循环神经网络
循环神经网络(Recurrent Neural Network,简称RNN)是一种特殊类型的神经网络,设计用于处理序列数据,其中数据点之间的顺序非常重要。与传统的前馈神经网络不同,RNN具有反馈连接,允许信息在时间维度上循环,这使得RNN能够记住之前的数据点,从而在处理序列数据时具有上下文意识。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
(1)了解RNN的多种结构
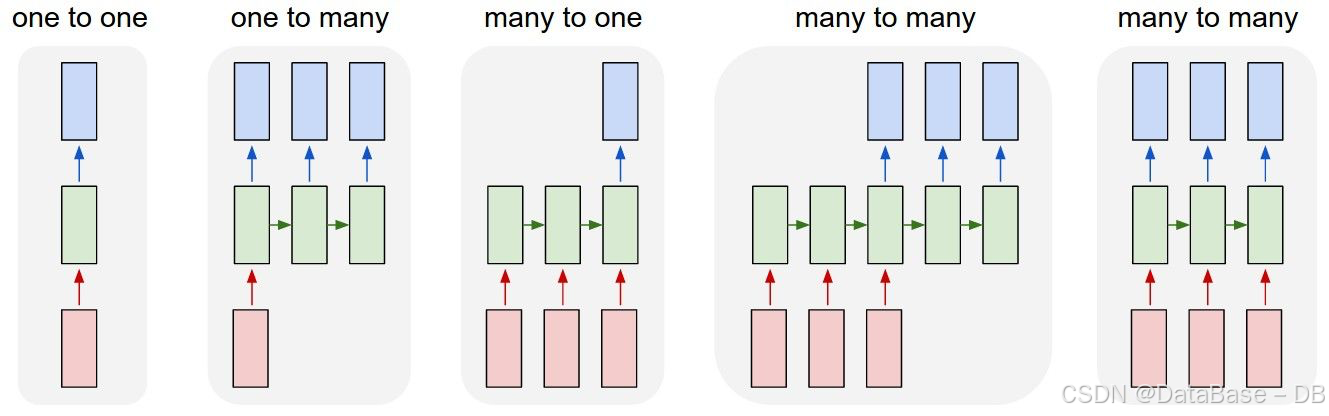
在图中,红色部分表示输入层,绿色部分表示隐藏层,蓝色部分表示输出层。
one-to-one
图中第一部分所示,输入x经过非性变换得到输出y。
one-to-many
图中第二部分所示,在第一个时间步将x作为输入,经过非线性变换得到输出y1和隐藏态h1,隐藏态h1作为下一时间步的输入,经过相同变换得到输出y2和隐藏态h2,如此往复。
另一种结构为在每个时间步都将x作为输入,x和h共同计算得到输出和隐藏态。
many-to-many
图中第五部分所示,在每个时间步接收一个x的输入,生成隐藏态h和输出y,再将隐藏态与下一个x输入到模型中,重复此过程。
其他结构不做展开说明。
(2)Encoder-Decoder
我们可以发现,在上述的RNN多种结构中,对于many-to-many结构,输入和输出序列总是等长的。由于这个限制的存在,经典RNN的适用范围比较小。
所以是否有一种结构,可以处理输入,输出不等长的序列呢?
这种结构是Encoder-Decoder,也叫Seq2Seq(正是baseline的task2中使用的结构),是RNN的一个重要变种,解决了序列长度不同的问题。如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
下文中提到了GRU(门控循环单元)网络,在此做解释,不作详细展开。
GRU(门控循环单元)是RNN的变体,能够有效捕捉长序列语义关联,缓解梯度消失或爆炸现象,其核心结构由更新门和重置门两部分组成。
(3)Seq2Seq具体过程
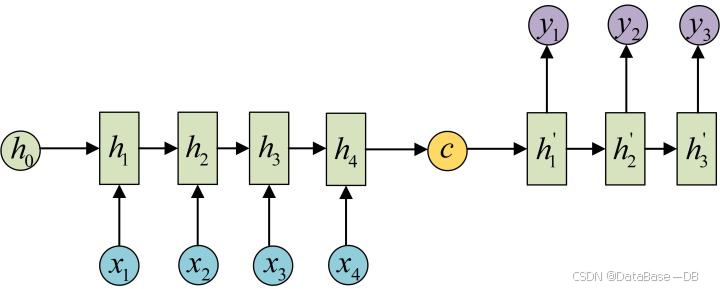
首先,Encoder编码器结构通过GRU网络将输入数据编码成一个上下文语义向量c。
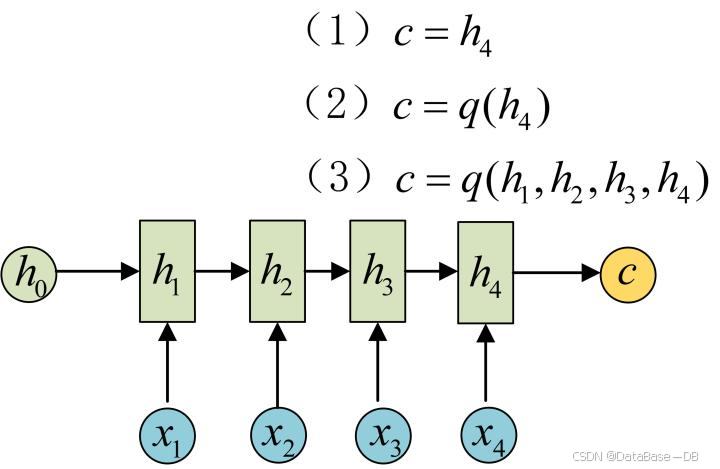
语义向量c可以有多种表达方式,这里将Encoder的最后一个隐藏态h4赋值给c.
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim)
self.gru = nn.GRU(emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=True)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
# src = [batch size, src len]
embedded = self.dropout(self.embedding(src))
# embedded = [batch size, src len, emb dim]
outputs, hidden = self.gru(embedded)
# outputs = [batch size, src len, hid dim * n directions]
# hidden = [n layers * n directions, batch size, hid dim]
return outputs, hidden之后将c做为初始隐藏态h0输入到Decoder解码器中,通过GRU网络生成最终输出y4。
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.gru = nn.GRU(hid_dim + emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=True)
self.fc_out = nn.Linear(hid_dim * 2 + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs):
# input = [batch size, 1]
# hidden = [n layers, batch size, hid dim]
# encoder_outputs = [batch size, src len, hid dim]
input = input.unsqueeze(1)
embedded = self.dropout(self.embedding(input))
# embedded = [batch size, 1, emb dim]
a = self.attention(hidden[-1:], encoder_outputs)
# a = [batch size, src len]
a = a.unsqueeze(1)
# a = [batch size, 1, src len]
weighted = torch.bmm(a, encoder_outputs)
# weighted = [batch size, 1, hid dim]
rnn_input = torch.cat((embedded, weighted), dim=2)
# rnn_input = [batch size, 1, emb dim + hid dim]
output, hidden = self.gru(rnn_input, hidden)
# output = [batch size, 1, hid dim]
# hidden = [n layers, batch size, hid dim]
embedded = embedded.squeeze(1)
output = output.squeeze(1)
weighted = weighted.squeeze(1)
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim=1))
# prediction = [batch size, output dim]
return prediction, hidden最后将Encoder和Decoder拼接在一起,形成Seq2Seq模型。
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src = [batch size, src len]
# trg = [batch size, trg len]
batch_size = src.shape[0]
trg_len = trg.shape[1]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(batch_size, trg_len, trg_vocab_size).to(self.device)
encoder_outputs, hidden = self.encoder(src)
input = trg[:, 0]
for t in range(1, trg_len):
output, hidden = self.decoder(input, hidden, encoder_outputs)
outputs[:, t] = output
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[:, t] if teacher_force else top1
return outputs虽然Seq2Seq结构在处理如机器翻译,文本摘要等序列生成任务时效果不错,但还是有许多明显的缺点
- 同步编码和解码:在编码阶段,整个输入序列必须被处理完才能开始解码,这限制了模型的并行处理能力,尤其是在长序列的情况下,可能会导致较长的延迟。
- 信息瓶颈:Seq2Seq模型通常依赖于最后一个时间步的隐状态或上下文向量来捕获整个输入序列的信息。然而,这个单一的向量可能不足以完整表示长序列的所有细节,导致信息丢失,特别是在处理非常长的输入序列时。
- 暴露偏差:在训练过程中,解码器总是使用真实的下一个词作为输入(强制)。但在推理时,解码器必须使用自己生成的输出作为下一个时间步的输入。这种训练和推理之间的不一致性可能导致模型在生成长序列时出现错误累积。
- 词汇鸿沟:Seq2Seq模型在处理罕见词或未见过的词时表现不佳,因为它们的训练数据集中可能没有足够的信息来学习这些词的正确使用。
- 长序列的训练难度:处理长序列时,梯度消失或爆炸问题变得更加严重,这使得模型难以学习到输入序列中远距离元素之间的依赖关系。
- 计算资源消耗:Seq2Seq模型在训练和推理时都需要较大的计算资源,尤其是当输入和输出序列长度较大时。这在一定程度上限制了模型的扩展性和实用性。
本篇笔记到此结束,笔记中有不完善或错误的地方会在之后尽可能补充修改。
在下一篇笔记中,我们将涉及到注意力机制,transform模型等概念及解析。