1 elasticsearch介绍
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。可以很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
2 ES相关的术语介绍
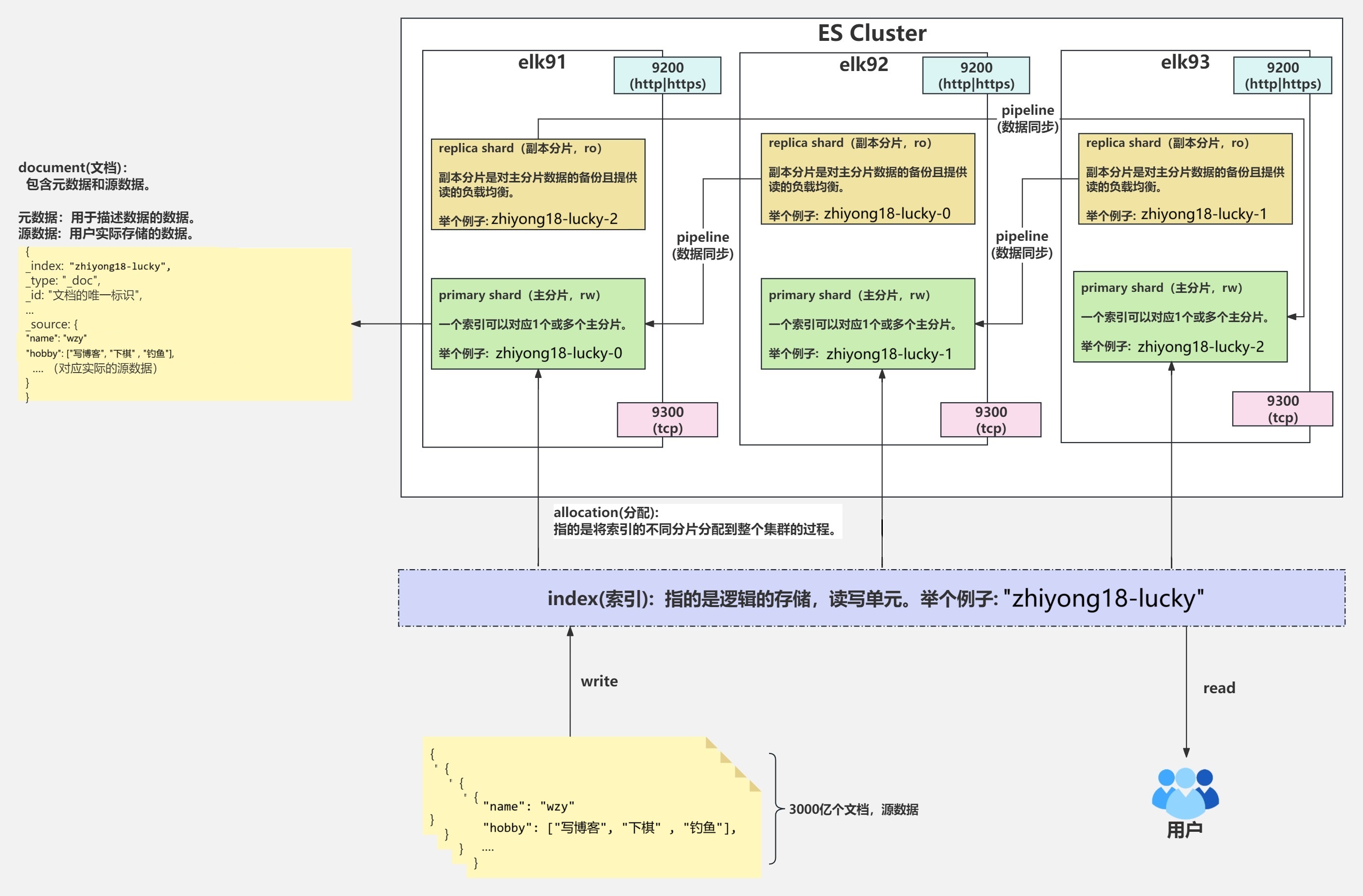
**index:**也叫索引,一个索引最少要有一个分片。指的是逻辑的存储和读取单元。一个索引也可以叫做1个文档名
**shard:**分片,用于实际存储数据信息。索引数据可以分布到集群中的不同节点,每个索引可以分为多个分片。分片可以提高数据存储和查询的效率
**replica:**副本,用于索引分片冗余,以及提高数据的可靠性和查询性能。副本可以分布在不同的节点上,确保即使某些节点故障,数据也不会丢失
**primary shard:**主分片,负责数据的读写
**replica shard:**副本分片,从primary shard同步数据且,负责读的负载均衡。也就是说读数据时,会往多个副本读取。
**allocation:**把索引的不同分片分配到整个集群的过程
**document:**文档,用于的实际数据的载体,分为元数据和源数据
-
源数据:指的是用户实际的存储。数据存储在"_source"字段中
-
元数据:用于描述数据的数据,比如
_index,_id,_type,_source
ES集群颜色和含义:
-
green代表所有的主分片和副本分片都正常访问
-
yellow代码部分副本分片无法访问
- 例如,副本数量大于集群数量。导致没有可用节点分配
-
red代表部分主分片无法访问
ES相关端口:
- 9200,支持http|https协议,对外部提供服务访问
- 9300,支持tcp协议,对内部ES集群进行数据传输
2 elasticsearch的安装
01 单点方式部署
| IP | 主机名 | 内存 |
|---|---|---|
| 10.0.0.091 | elk91 | 2G |
提示:elasticsearch的deb安装包集成了java环境,因此安装包体积较大,也可以二进制部署,软件和java环境分开部署。
1.以7.17.22版本为例:wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.22-amd64.deb
2.安装软件包
dpkg -i elasticsearch-7.17.22-amd64.deb
3.修改配置文件:vim /etc/elasticsearch/elasticsearch.yml
# 指定集群的名称,每个ES集群的名称要唯一
17 cluster.name: wzy-com
# 数据的存储路径,默认即可
33 path.data: /var/lib/elasticsearch
# 日志的存储路径,默认即可
37 path.logs: /var/log/elasticsearch
# 指定监听本地的地址,监听全部则写成 0.0.0.0
56 #network.host: 10.0.0.91
# 对外的访问端口
http.port: 9200
# 集群之间数据传输端口
61 #http.port: 9200
# 部署集群为单点类型
discovery.type: "single-node"
简化的配置为:
[root@elk91~]# yy /etc/elasticsearch/elasticsearch.yml
cluster.name: wzy-com
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.type: "single-node"
3.启动es
systemctl restart elasticsearch.service
[root@elk91~]# netstat -antlp | grep 9[23]00
tcp6 0 0 :::9300 :::* LISTEN 3235/java
tcp6 0 0 :::9200 :::* LISTEN 3235/java
4.如果启动失败,就去看日志:/var/log/elasticsearch/wzy-com.log;或者journalctl -fu elasticsearch
5.访问es
[root@elk91~]# curl http://10.0.0.91:9200
{
"name" : "elk91",
"cluster_name" : "wzy-com",
"cluster_uuid" : "ypPsMv8WQOmQZ3H1VSF-Xw",
"version" : {
"number" : "7.17.22",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "38e9ca2e81304a821c50862dafab089ca863944b",
"build_date" : "2024-06-06T07:35:17.876121680Z",
"build_snapshot" : false,
"lucene_version" : "8.11.3",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
6.卸载es
dpkg命令说明:
-
dpkg -r 卸载
-
dpkg -P 卸载并移除配置文件
卸载后再使用rm -rf /tmp*
02 集群方式部署
1.环境准备
| IP地址 | 主机名 |
|---|---|
| 10.0.0.91 | elk91 |
| 10.0.0.92 | elk92 |
| 10.0.0.93 | elk93 |
- 所有节点设置正确的时间:
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime - 安装ES软件
1.所有节点修改配置文件为:
cat >/etc/elasticsearch/elasticsearch.yml <<EOF
cluster.name: elk-wzy
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
# 配置ES集群的服务发现列表主机
discovery.seed_hosts: ["10.0.0.91","10.0.0.92","10.0.0.93"]
# 配置ES集群启动时参与master选举的节点
cluster.initial_master_nodes: ["10.0.0.91","10.0.0.92","10.0.0.93"]
EOF
最后启动es:systemctl enable elasticsearch --now
2.验证是否为集群还是脑裂。访问任意1个节点,看到主机列表为3个节点就是搭建成功了。否则卸载重新搭建
[root@elk91~]# curl -s 10.0.0.93:9200/_cat/nodes
10.0.0.91 29 96 5 0.66 0.53 0.44 cdfhilmrstw - elk91
10.0.0.93 25 96 2 0.60 0.43 0.22 cdfhilmrstw - elk93
10.0.0.92 48 96 3 0.47 0.57 0.32 cdfhilmrstw * elk92
# 卸载
systemctl disable elasticsearch --now
dpkg -P elasticsearch
rm -rf /tmp/* /var/{log,lib}/elasticsearch
# 安装
dpkg -i elasticsearch-7.17.22-amd64.deb
cat >/etc/elasticsearch/elasticsearch.yml <<EOF
cluster.name: efk-wzy
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["10.0.0.91","10.0.0.92","10.0.0.93"]
cluster.initial_master_nodes: ["10.0.0.91","10.0.0.92","10.0.0.93"]
EOF
systemctl enable elasticsearch --now
03 ES的堆内存设置
此操作为可选项:
-Xms 和 -Xmx 是 JVM(Java 虚拟机)启动参数,用于设置堆内存(Heap Memory)的初始大小和最大大小。这两个参数直接影响 Java 应用的性能和内存管理。建议设置为主机内存的一半
修改 /etc/elasticsearch/jvm.options ,
...
-Xms4096m
-Xmx4096m
...