语言是一套复杂的符号系统。语言符号通常在音韵(Phonology)、词法(Mor- phology)、句法(Syntax)的约束下构成,并承载不同的语义(Semantics)。
语言符号具有不确定性。同样的语义可以由不同的音韵、词法、句法构成的符号来表达;同样的音韵、词法、句法构成的符号也可以在不同的语境下表达不同的语义。因此,语言是概率的。
(“语言是概率的”是指语言的表达和理解往往不是完全确定的,而是受多种因素影响的。在语言的使用中,存在许多可能性和不确定性。)
并且,语言的概率性与认知的概率性也存在着密不可分的关系 。语言模型(Language Models, LMs)旨在准确预测语言符号的概率。
从语言学的角度,语言模型可以赋能计算机掌握语法、理解语义,以完成自然语言处理任务。从认知科学的角度,准确预测语言符号的概率可以赋能计算机描摹认知、演化智能。
1.1 基于统计方法的语言模型
基于统计的语言模型通过直接统计语言符号在语料库中出现的频率来预测语言符号的概率。其中,n-grams 是最具代表性的统计语言模型。 n-grams语言模型基于马尔可夫假设和离散变量的极大似然估计给出语言符号的概率。




👆优缺点需要了解
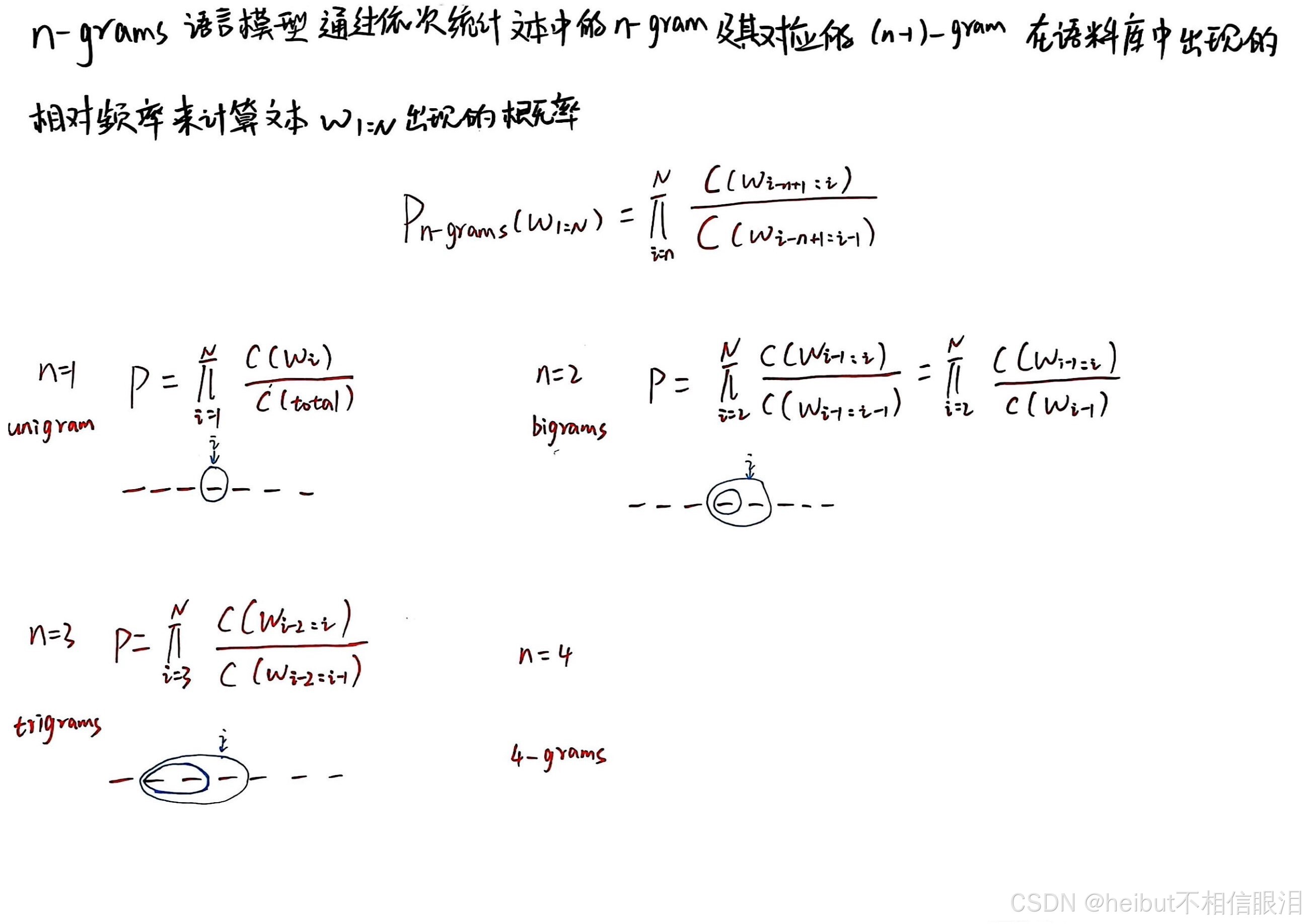
本小节主要讲述n-grams语言模型如何计算语言符号出现的概率。
下一小节讲述n-grams语言模型的原理(n阶马尔可夫假设和离散型随机变量的极大似然估计)



极大似然估计就是估计模型参数,使得在给定数据的条件下,模型生成数据的概率最大化。





以上是n-grams模型公式的推导过程,如果看不懂 记住公式以及会用即可。看不懂也没事,不同模型计算方法也不同,通俗来说,就是用极大似然估计用于计算每个词在给定前一个词的情况下出现的概率
n=2的例子:
通过统计语料库中的 bigram(也就是n为2) 频率来估计这些条件概率,使得在给定前一个词的情况下,当前词的出现概率最大化

n=3:

n-grams
语言模型通过统计词序列在语料库中出现的频率来预测语言符号的概率。其对未知序列有一定的泛化性,但也容易陷入“零概率”的困境。随着神经网络的发展,基于各类神经网络的语言模型不断被提出,泛化能力越来越强。基于神经网络的语言模型不再通过显性的计算公式对语言符号的概率进行计算,而是利用语料库中的样本对神经网络模型进行训练。本章接下来将分别介绍两类最具代表性的基于神经网络的语言模型:基于
RNN 的语言模型和基于 Transformer 的语言。
1.2 基于 RNN 的语言模型
什么是RNN?
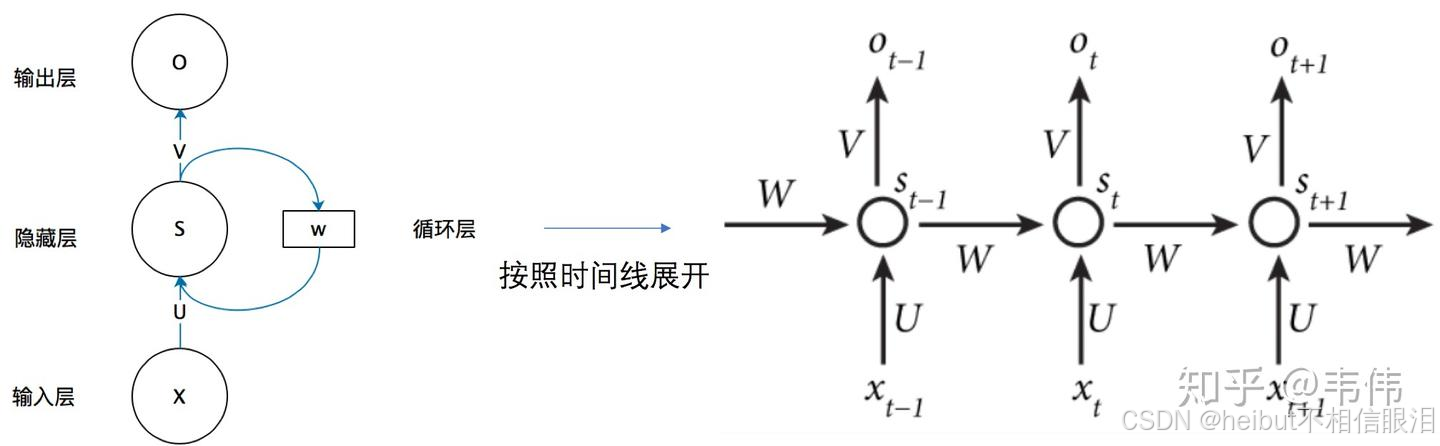
循环神经网络(Recurrent Neural Network, RNN)是一类网络连接中包含环路的神经网络的总称。给定一个序列,RNN 的环路用于将历史状态叠加到当前状态上。沿着时间维度,历史状态被循环累积,并作为预测未来状态的依据。因此,RNN 可以基于历史规律,对未来进行预测。基于 RNN 的语言模型,以词序列作为输入,基于被循环编码的上文和当前词来预测下一个词出现的概率。
按照推理过程中信号流转的方向,神经网络的正向传播范式可分为两大类:前馈传播范式和循环传播范式。在前馈传播范式中,计算逐层向前,“不走回头路”。而在循环传播范式中,某些层的计算结果会通过环路被反向引回前面的层中,形成“螺旋式前进”的范式。采用前馈传播范式的神经网络可以统称为前馈神经网络(Feed-forward Neural Network,FNN),而采用循环传播范式的神经网络被统称为循环神经网络(Recurrent Neural Network, RNN)。以包含输入层、隐藏层、输出层的神经网络为例。
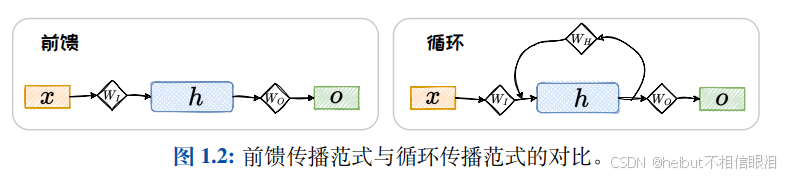
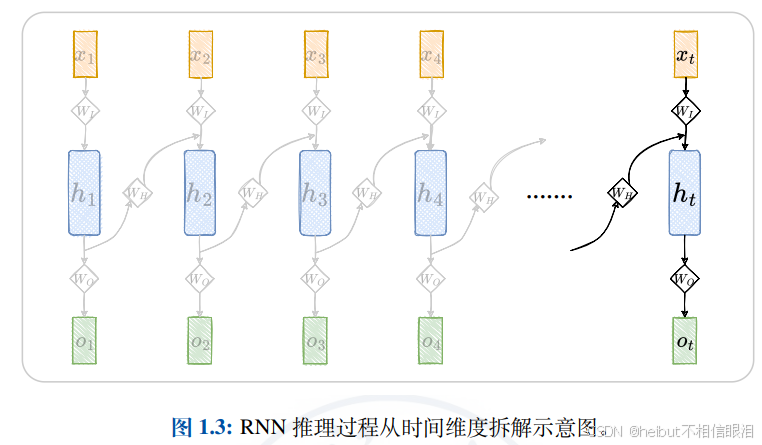
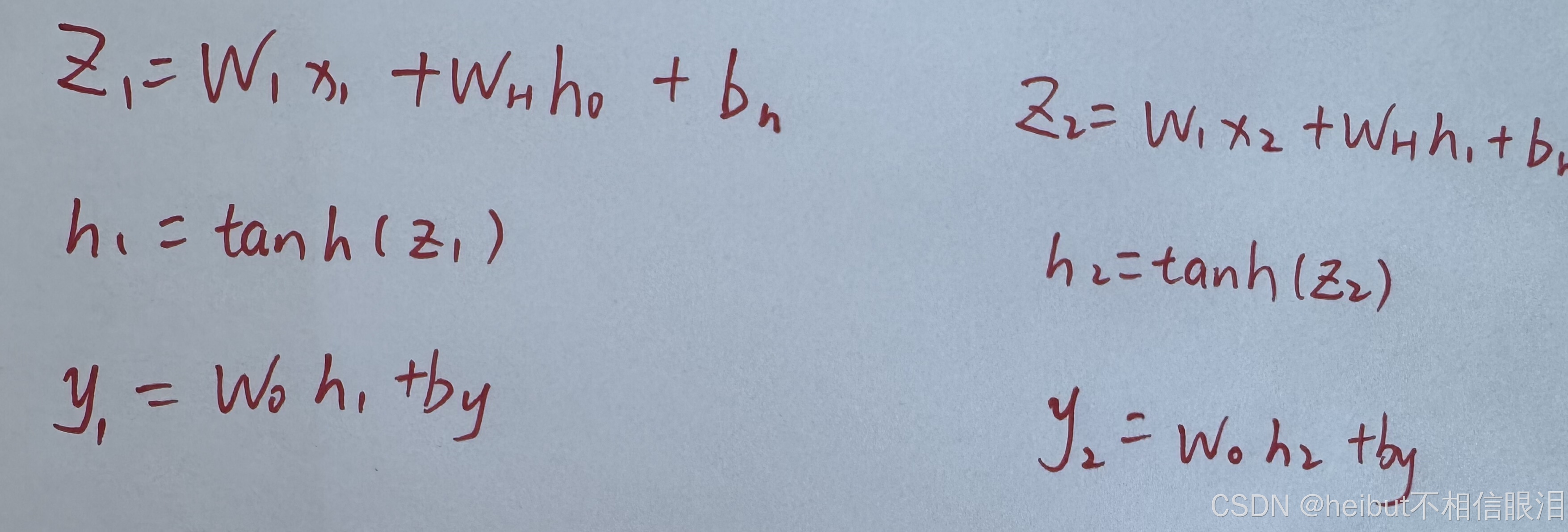
LSTM其实就是RNN的变体,他适合处理序列数据。
这是神经网络:
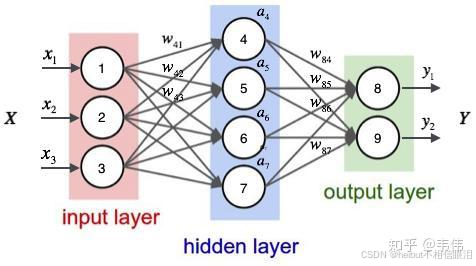
输入通过神经元隐藏层变换然后输出,比如说
现在有两句话:
第一句话:I like eating apple!(我喜欢吃苹果!)
第二句话:The Apple is a great company!(苹果真是一家很棒的公司!)
现在的任务是要给apple打标签 让网络预测Apple是苹果本身还是公司
假设我们现在有大量的已经标记好的数据以供训练模型,当我们使用全连接神经网络时,我们做法是把apple这个单词的特征向量输入到我们的模型中(神经网络),在输出结果时,输出预测概率最大的那个类别
就是分类,让全连接神经网络判断Apple是苹果还是公司
那你会发现,你分类的准确率和你训练用的数据有很大的关系,比如你80%的数据是苹果,20%数据是苹果公司,那么你预测的结果很有可能就是苹果,即使你输入的是公司
这个问题是什么,是我们的模型没有去学习上下文,通俗来说就是没有结合上下文去训练模型,而是单独的在训练apple这个单词的标签
所以我们需要模型能结合上下文去学习知识
因此循环神经网络就被提出来了
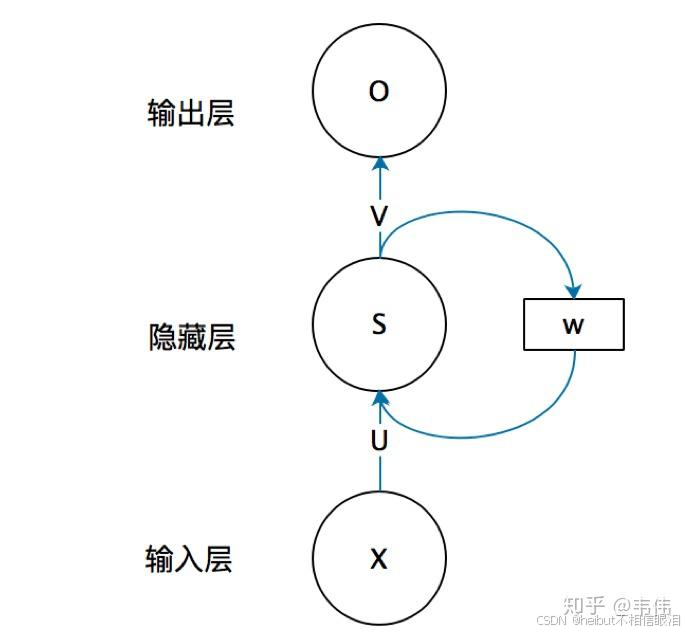
他在做什么事呢
让前一个隐藏层的参数能影响到下一个隐藏层
输出是o w是权重参数
隐藏层用于处理输入数据、提取特征、并最终将信息传递给输出层

那现在假设我们要计算 序列 "I love you"的概率,P(“I love you”) 也就是在 RNN 模型下,给定前面已经看到的词 I,模型预测下一个词的概率
词表:{"I", "love", "you", "like", "enjoy"}
对应的索引:
"I" -> 0
"love" -> 1
"you" -> 2
"like" -> 3
"enjoy" -> 4

词转换成向量,随便转换的,没有规则
就和字典一样,一个字一个位置
因为计算机不能识别文本
012345不好计算


Win Wrec Wout 都是不变的,变得值是x
输入不固定,输出也会收到上个隐藏层的影响
偏置项是帮助拟合数据,调整输出
在训练过程中,偏置项会根据每一层的误差来调整它的值,使得模型的输出更加接近目标。这是为了确保神经网络能够在不同的输入条件下输出准确的结果。



这个softmax会经常用到,将一个向量的值压缩到一个范围在 [0, 1] 之间,所以经常得到的结果时百分之多少,损失函数就是这么来的
尤其是做分类,他会保证所有类别的和为1


如何把y1、y2、y3转换成概率值,下面以Zt为例:


总结 RNN就是能获取到序列的关系,回归到Apple那个例子,就能根据前面的词语判断是苹果还是公司