1.3 基于 Transformer 的语言模型
Transformer 是一类基于注意力机制(Attention)的模块化构建的神经网络结构。给定一个序列,Transformer 将一定数量的历史状态和当前状态同时输入,然后进行加权相加。对历史状态和当前状态进行“通盘考虑”,然后对未来状态进行预测。基于 Transformer 的语言模型,以词序列作为输入,基于一定长度的上文和当前词来预测下一个词出现的概率。
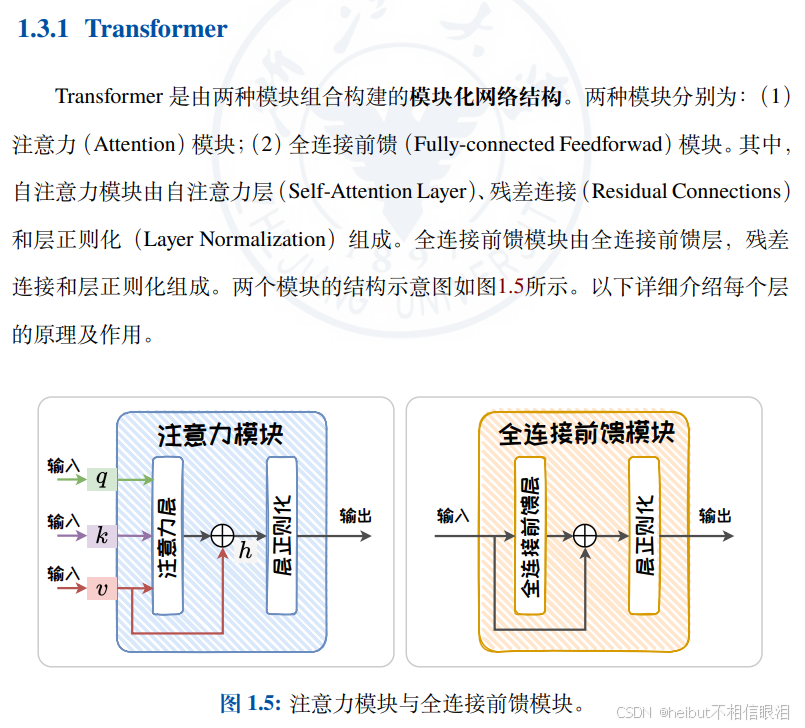
这两个模块组成了transformer 块,模型是由多个块组合而成的
首先,为什么要提出transformer呢,他提出来又是为了解决生成语言模型遇到的哪些问题呢
之前是不是学了RNN,传统的神经网络(如 RNN 和 LSTM)通常需要逐步地处理数据(一个词一个词地处理)
越长越不准确是不是
Transformer 通过一种叫做 自注意力机制(Self-Attention) 的技术,能够同时关注输入序列中的所有位置,解决了这一问题,并且计算上更高效。
自注意力机制计算过程:
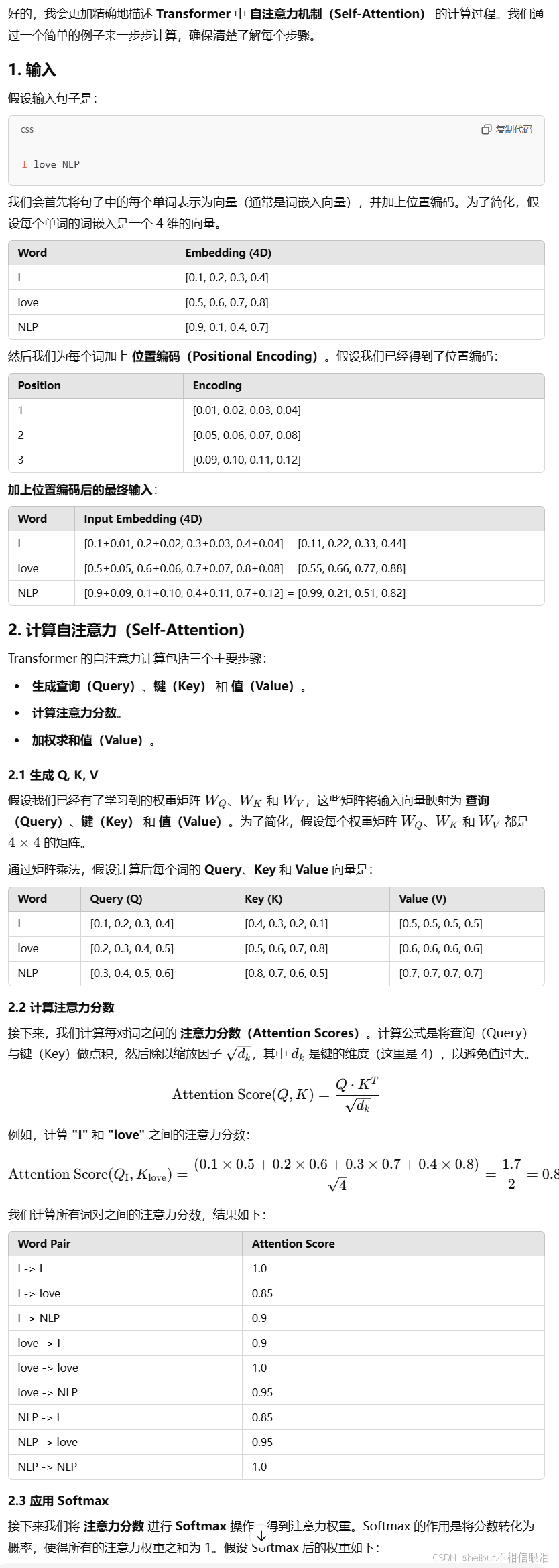

注意力分数:表示该词与其他词的关系(即它们的相似度)
最开始的权重矩阵Wq Wk Wv都是随机初始化的,在训练过程中,Transformer 通过 前向传播 计算查询、键、值向量,并通过 反向传播 计算损失和梯度,更新这些权重矩阵。
注意力机制是如何工作的:一个是计算注意力,然后是应用注意力,应用注意力就是他的多头注意力机制,让模型从不同角度理解词之间的关系,Transformer 使用多个“头”来并行计算注意力,每个头关注输入序列的不同部分。
通俗解释:
想象你在翻译一句话时,看到“我喜欢苹果”。你在翻译“苹果”这个词时,可能会特别注意到“喜欢”这个词,因为它描述了“苹果”的情感关联,而不是关注句子中的“我”。注意力机制帮助模型“专注”于输入序列中的关键部分。
简而言之,注意力机制让模型“关注”最相关的信息,忽略不重要的部分,从而提升模型对复杂任务的理解和处理能力。
示例:
假设输入句子为:“我喜欢吃苹果。” 如果我们要生成“吃”的翻译,注意力机制会帮助模型集中注意力在“喜欢”和“苹果”上,而不是“我”。
多头注意力(Multi-Head Attention)机制中每个头(head)有不同的权重矩阵。
具体来说,多头注意力机制的核心思想是将注意力机制应用于多个子空间(不同的子空间代表不同的注意力头),从而能够捕捉输入数据的不同方面信息。每个注意力头都学习不同的查询(Query)、 键(Key)和值(Value) 的权重矩阵。




全连接前馈网络
想象你有一份报告,你希望模型能够通过这份报告给出一个总结。报告的每个部分(比如每一段文字)可能包含不同的信息,而模型通过“全连接前馈网络”来处理这些信息,将它们组合起来生成最终的输出。每一层的神经元都连接到下一层的所有神经元,因此它能够对信息进行广泛的处理和整合。

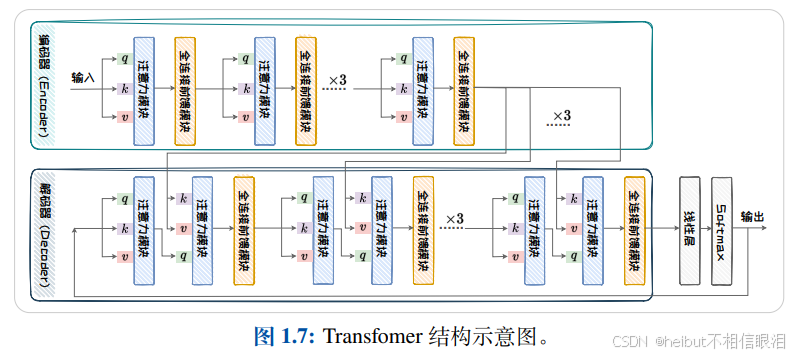
接下来介绍transformer的解码编码结构
Transformer 模型由 编码器(Encoder) 和 解码器(Decoder) 两大部分组成
分别用于输入序列的处理和输出序列的生成。每个编码器和解码器都由多个相同的层堆叠而成,通常是 6 层(但可以根据需要进行调整)。

例子:英文句子翻译成中文
输入句子(英文):
“I love reading books.”
目标输出(中文):
“我 喜欢 读书”
那编码器有什么用呢
解码器有什么作用呢





多层:
可以类比为人类学习语言或理解信息的过程。我们并不是一次就能完全理解一句话或一段话的所有含义,而是需要通过逐渐分析不同的层面(例如词汇、语法、语境等)来逐渐构建出完整的理解。多层编码器的设计就是模拟这种认知过程,逐层逐步提炼和抽象信息。
解码器的那个编码器-解码器注意力机制不太理解
可以将其类比为一个人在翻译一个句子时的思维过程。假设你要把英文句子“I love reading books”翻译成中文。如果你想翻译“I”这个词,你会想到它在句子中的位置和它的作用。你会意识到“I”是主语,在中文中应该翻译为“我”。这个判断是基于你对整个句子的理解,而不仅仅是词汇本身。
同样的,在 Transformer 中,解码器生成每个目标词时,它不仅仅依赖于自己已经生成的部分,还会参考 编码器的输出(也就是源语言的句子)来决定最合适的词语。



再具体一点:


用数学就是


