
进程间通信之管道和进程池
一、管道的特点
只能用于具有共同祖先的进程之间进行通信,通常,一个管道由一个进程创建,然后该进程调用fork创建子进程,此后父子进程就可以使用该管道进行通信
管道面向字节流,即管道不晓得自己里面的内容,只是一味按照父子进程之间的协调进行传输信息,父子进程在读取其中的内容时是不看内容是否有\n和\0等含有特殊意义的内容
因为管道的本质是一种内存级文件,所以管道的生命周期伴随着进程的退出而结束
一般而言,,内核会对管道操作进行同步与互斥,同步是指多个进程或线程在访问共享资源或进行特定操作时,按照一定的顺序或规则进行协调,以确保它们之间的操作能够正确、有序地执行,互斥是指在同一时刻,只允许一个进程或线程访问共享资源,以避免多个进程或线程同时访问导致的数据不一致或冲突问题
管道为半双工通道,只能单向传递信息,需要双向通信就要建立两个管道
我们在命令行中使用的|就是匿名通道
二、进程池
1、概念
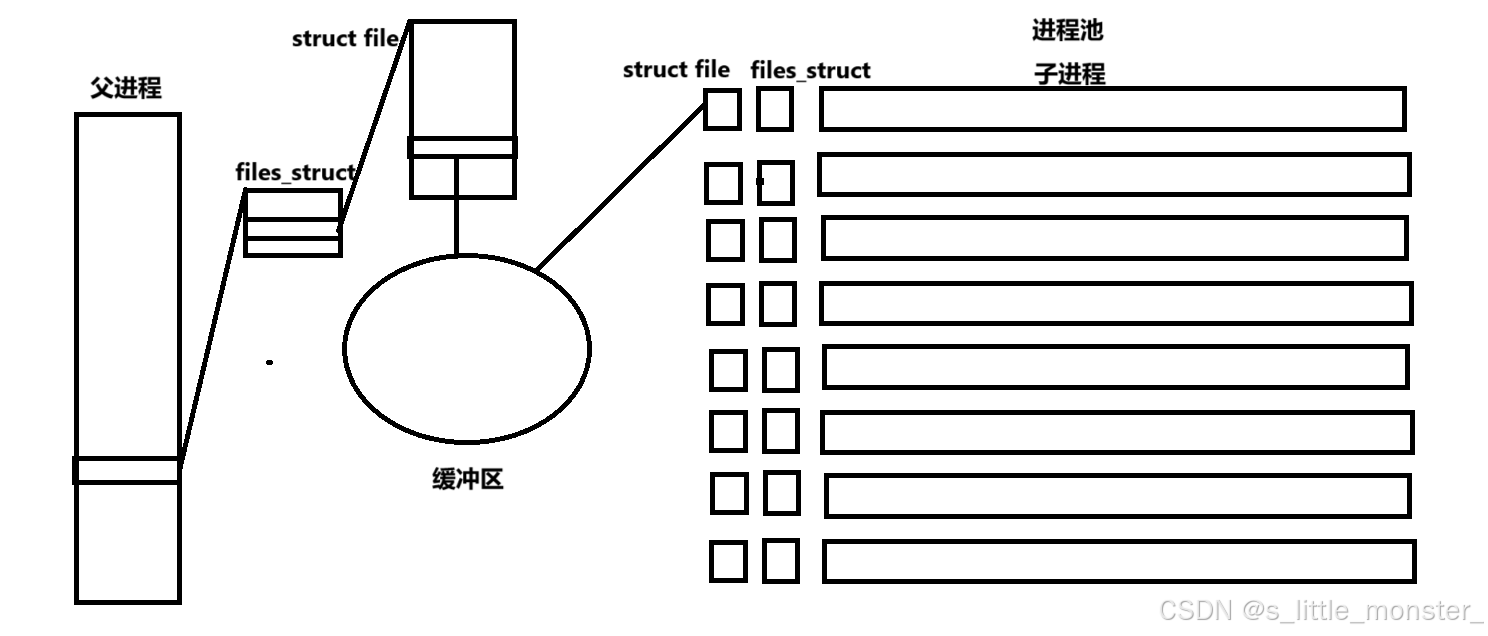
我们知道在我们创建子进程的时候要调用fork函数,这是一个系统调用接口,所以会对系统产生成本,如果我们一次创建很多个进程,那么系统会变得很累,所以我们引入池的概念,进程池可以保证在我们需要使用进程的情况下,由于提前创建了子进程,我们直接分配就行了,避免了我们需要大量进程的情况下操作系统很吃力的情况,对提前创建好的这些子进程进行先描述后组织的
2、用管道实现一个简易进程池
(一)头文件、宏、全局变量和main函数
#include <iostream>
#include <vector>
#include <string>
#include <unistd.h>
#include "task.hpp"
#include <sys/stat.h>
#include <sys/wait.h>
#include <cstdio>
#define PROCESSNUM 10
std::vector<task_t> tasks;
int main()
{
//加载任务
LoadTask(&tasks);
//定义一个vector管理所有的管道,channel是描述,channels是组织
std::vector<channel> channels;
//初始化
InitProcessPool(&channels);
//开始进行
StartProcessPool(channels);
//清理
CleanProcessPool(channels);
return 0;
}
(二)初始化函数InitProcessPool
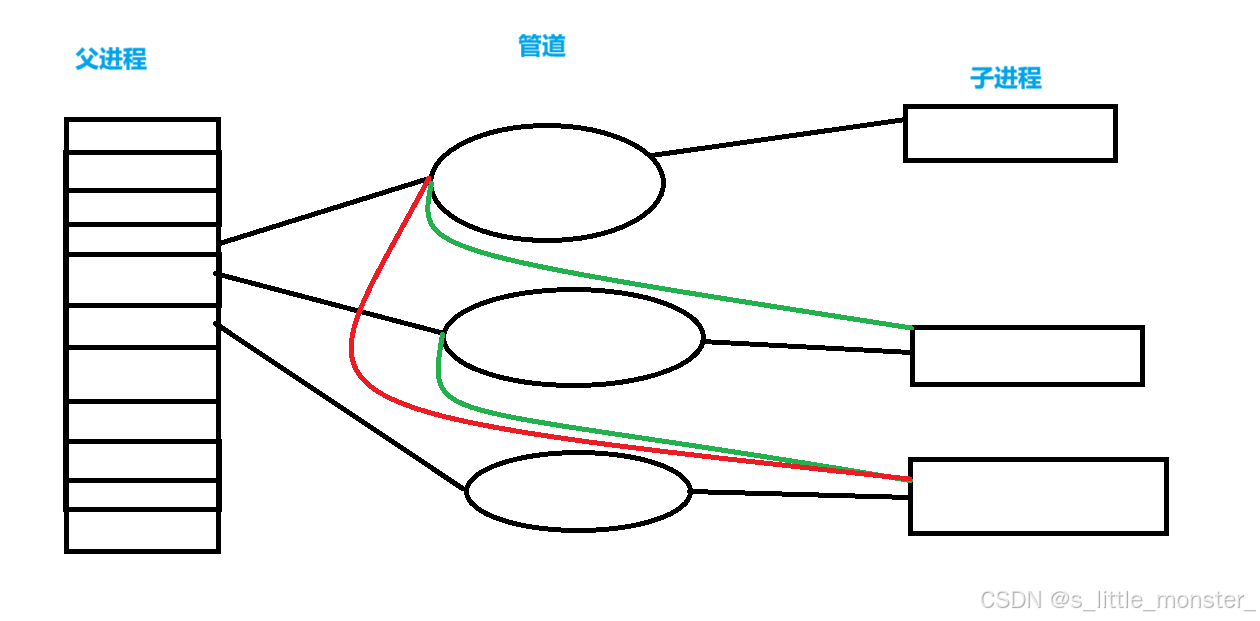
初始化函数里有一个重要的点就是,我们的子进程是循环创建的,所以在创建第一个子进程时没有问题,但是创建第二个子进程开始,因为刚创建出的第二个子进程与父进程是一样的,此时都作为写端连接着一个管道,我们在图中用绿色的线标注出来了,第三个子进程又可以成为第一二个管道的写端,以此类推,每个子进程后创建的子进程都会是上个信道的写端,这与我们想要父进程写,子进程读的要求相悖,所以我们初始化的另一个目的就是将这些多余的连接全部断开,也就是图中彩色的线全部断开,进而保证只有父进程在写端
task.hpp
#pragma once
#include <iostream>
#include <vector>
//定义一个函数指针task_t指向返回值为void,没有参数的函数
typedef void (*task_t)();
void task1()
{
std::cout << "this is task1 running" << std::endl;
}
void task2()
{
std::cout << "this is task2 running" << std::endl;
}
void task3()
{
std::cout << "this is task3 running" << std::endl;
}
void task4()
{
std::cout << "this is task4 running" << std::endl;
}
//加载任务函数,将任务pushback到vector中
void LoadTask(std::vector<task_t> *tasks)
{
tasks->push_back(task1);
tasks->push_back(task2);
tasks->push_back(task3);
tasks->push_back(task4);
}
test.cpp
class channel
{
public:
// 描述父进程的fd,对应子进程的pid,子进程的名字
channel(int cmdfd, int slaverid, const std::string &processname)
:_cmdfd(cmdfd),_slaverid(slaverid),_processname(processname)
{}
int _cmdfd;
pid_t _slaverid;
std::string _processname;
};
void slaver()
{
while(true)
{
// 用于存储从标准输入读取的命令码
int cmdcode = 0;
// 从标准输入(管道)读取数据,尝试读取sizeof(int)字节的数据到cmdcode中
// 如果父进程不给子进程发送数据子进程就会进入阻塞等待
int n = read(0, &cmdcode, sizeof(int));
if(n == sizeof(int))
{
// read的返回值与sizeof(int)相等,就输出子进程pid和获得命令码
// 如果命令码有效就调用task任务,无效就退出
std::cout <<"slaver say@ get a command: "<< getpid() << " : cmdcode: "
<< cmdcode << std::endl;
if(cmdcode >= 0 && cmdcode < tasks.size()) tasks[cmdcode]();
}
else break;
}
}
void InitProcessPool(std::vector<channel>* channels)
{
//用于存储之前创建的管道的写端文件描述符
//目的是让后续创建的子进程可以关闭这些旧的写端文件描述符,避免资源泄漏
std::vector<int> oldfds;
//循环创建子进程
for(int i = 0; i < PROCESSNUM; i++)
{
int pipefd[2] = {0};
int n = pipe(pipefd);
if(n < 0)
{
return;
}
pid_t id = fork();
if(id < 0)
{
return;
}
if(id == 0)
{
//打印子进程pid,打印并关闭上一个管道写端文件描述符
std::cout << "child : " << getpid() << " close history fd: ";
for(auto fd : oldfds)
{
std::cout << fd << " ";
close(fd);
}
std::cout << std::endl;
//关闭写端通道
close(pipefd[1]);
//将当前管道的读端文件描述符复制到标准输入
//这样子进程就可以通过标准输入从管道读取数据
dup2(pipefd[0],0);
// 读取完关闭管道读端
close(pipefd[0]);
// 子进程主要业务
slaver();
//打印子进程要退出了
std::cout << "process : " << getpid() << " quit" << std::endl;
exit(0);
}
//父进程开始
//关闭读端
close(pipefd[0]);
//将当前channel信息添加到channels进行组织
std::string name = "process-" + std::to_string(i);
channels->push_back(channel(pipefd[1],id,name));
//添加这个写端的文件描述符,方便后面的进程关闭它
oldfds.push_back(pipefd[1]);
sleep(1);
}
}
(三)执行函数StartProcessPool
//打印一个选择任务的菜单
void Menu()
{
std::cout << "################################################" << std::endl;
std::cout << "# 1. 任务一 2. 任务二 #" << std::endl;
std::cout << "# 3. 任务三 4. 任务四 #" << std::endl;
std::cout << "# 0. 退出 #" << std::endl;
std::cout << "#################################################" << std::endl;
}
void StartProcessPool(std::vector<channel>* channels)
{
while(true)
{
int select = 0;
Menu();
sleep(1);
//输入选项
std::cout << "Please Enter>> ";
std::cin >> select;
if(select <= 0 || select >= 5) break;
//将控制码也就是选择的数字select1234转化为0123,因为vector下标从0开始,所以要-1
int cmdcode = select - 1;
//通过管道写入信息,等待slaver()读取
write(channels[select]._cmdfd, &cmdcode, sizeof(cmdcode));
sleep(1);
}
}
(四)清理函数CleanProcessPool
void CleanProcessPool(std::vector<channel> &channels)
{
//每个channel对象的左边为父进程的fd,右边为子进程fd,断开父进程fd,然后进程等待
//父进程断开后子进程会在管道中读到0,即文件结束,然后子进程就会终止
//然后被父进程回收
for(const auto &c : channels){
close(c._cmdfd);
waitpid(c._slaverid, nullptr, 0);
}
}
三、进程池其他问题
1、描述整个过程
首先启动进程,将任务函数“上膛”到vector中,然后进行初始化,创建出第一个子进程,第一个子进程执行常规操作,比如将写端关闭,将当前管道读端文件描述符复制到标准输入以来获取标准输入的数据,然后就是等待父进程发送信息,在此同时,父进程也不闲着,将当前读端关闭,然后描述channel进而pushback到channels中进行组织,然后在oldfds中存下管道写端对应的fd,方便后面子进程的断开,然后创建第二个子进程,第二个子进程执行和第一个子进程差不多的操作,唯一的区别就是要将oldfds里面的写端全部断开,然后以此类推
2、细节处理
开始创建第一个子进程并形成管道时,父进程的读端fd==3写端fd==4,到后面就会关闭读端,第二次创建时父进程的读端fd==3写端fd==5,以此类推,父进程的读端将一直为3,而写端递增
创建完成的子进程在父进程发送信息之前都处于阻塞状态,一旦父进程发送信息,比如说上面我们提到的指定某个管道或者指定某个任务
3、标准的制定
一种良好的编程习惯对于一个程序员来说是一件非常好的事情,对于我们main函数中的这三个函数参数,我们发现它们遵守着一定的规则
const &:当我们只进行输入不要输出内容的时候
*:当我们要输出内容的时候,类似于输出型参数
&:当我们既要输入又要输出的时候
今日分享就到这里了~
