这里我选择Hadoop2.7.0版本,java8版本,spark2.4.5版本,python3.6版本,hbase 1.2.0,MySQL8.0.23。注意以上版本对应关系不然安装后可能无法使用
1 安装ssh以及配置无密码登录
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
输入如下命令:
$sudo apt-get update
$sudo apt-get install openssh-server #一般的ubuntu不自带服务器的ssh,都有客服端的ssh,需要安装服务器端的ssh
$ssh localhost #启动ssh
#下面配置无密码ssh登录
$cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost,~表示用户的主文件夹
$ssh-keygen -t rsa # 会有提示,一直按回车就可以
$cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了
2 安装java
打开终端
$cd /usr/lib
$sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
$cd ~ #进入hadoop用户的主目录
$cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录(downloads)下
$sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
$cd ~
$gedit ~/.bashrc
打开了hadoop这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH保存.bashrc文件并退出
$source ~/.bashrc
$java -version #查看是否安装成功
3 安装hadoop
打开hadoop文件包目录下的终端,输入以下代码显示安装成功
我们选择将 Hadoop 安装至 /usr/local/ 中:
$sudo tar -zxf ~/下载/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
$cd /usr/local/
$sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
$sudo chown -R yinchen ./hadoop # 修改文件权限
$cd /usr/local/hadoop
$./bin/hadoop version #出现版本信息,表示hadoop安装成功了
Hadoop伪分布式配置
Hadoop伪分布式配置参考:http://dblab.xmu.edu.cn/blog/install-hadoop/
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml),将当中最后两行的内容的
<configuration>
</configuration>
修改为:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hadoop.tmp.dir 是 hadoop文件系统依赖的基本配置,很多配置路径都依赖它,它的默认位置是在 /tmp/{$user}下面,注意这是个临时目录!!!
因此,它的持久化配置很重要的! 如果选择默认,一旦因为断电等外在因素影响,/tmp/{$user}下的所有东西都会丢失,哇咔咔。。。趟过坑的应该知道多么酸爽。。。
注意:
修改完配置需要重新格式化NameNode!!!
所以,建议:最好在安装配置HADOOP的时候,就给配置OK!!!
fs.defaultFS配置数据传输的地址
同样的,修改配置文件 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
dfs.replication设置文件备份数量
dfs.namenode.name.dir设置namenode文件存储的文件夹
dfs.datanode.data.dir设置datanode文件存储的文件夹
$cd /usr/local/hadoop
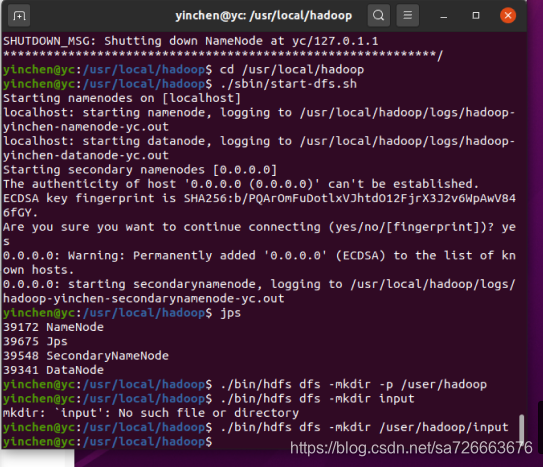
$./bin/hdfs namenode -format #格式化namenode节点
$cd /usr/local/hadoop
$./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
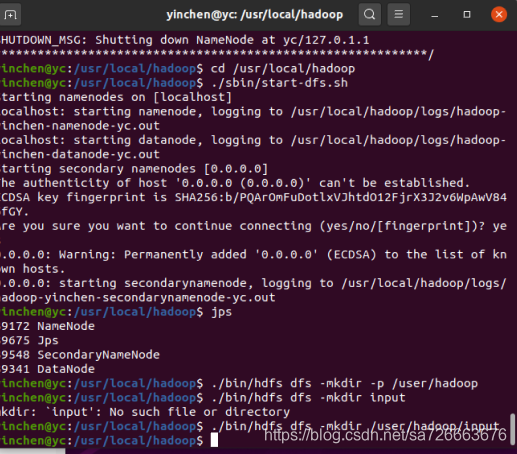
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程:
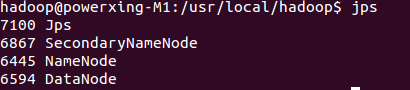
此外,若是 DataNode 没有启动,可尝试如下的方法(注意这会删除 HDFS 中原有的所有数据,如果原有的数据很重要请不要这样做):
- # 针对 DataNode 没法启动的解决方法
- cd /usr/local/hadoop
- ./sbin/stop-dfs.sh # 关闭
- rm -r ./tmp # 删除 tmp 文件,注意这会删除 HDFS 中原有的所有数据
- ./bin/hdfs namenode -format # 重新格式化 NameNode
- ./sbin/start-dfs.sh # 重启
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
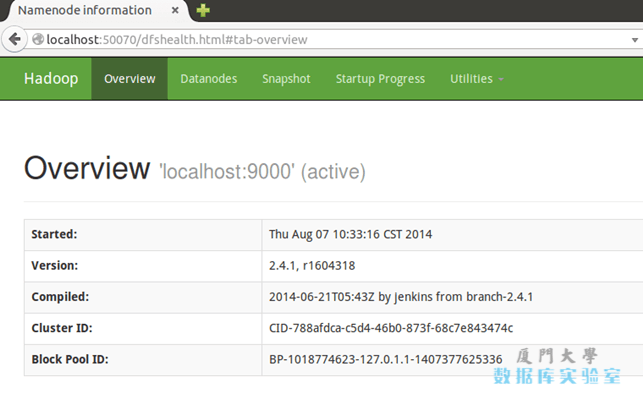
运行Hadoop伪分布式实例
$./bin/hdfs dfs -mkdir -p /user/hadoop
$./bin/hdfs dfs -mkdir /user/hadoop/input
$./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
$./bin/hdfs dfs -ls /user/hadoop/input
$./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input output 'dfs[a-z.]+'
$./bin/hdfs dfs -cat output/*
$rm -r ./output # 先删除本地的 output 文件夹(如果存在)
$./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
$cat ./output/*
$./bin/hdfs dfs -rm -r output # 删除 output 文件夹
$./sbin/stop-dfs.sh #若要关闭 Hadoop,则运行这行代码
下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 就可以!
运行截图
4 安装python 系统自带的python3.8好像版本太高,运行会有问题
因此需要额外再安装python3.6.1版本
当在命令行输入python时出现python3.6时,说明python安装成功。可通过软链接方式设置,一定不要删除ubuntu自带的python3.8,不然系统可能出现问题。
ubuntu安装python3.6: https://mp.csdn.net/editor/html/113042751
5 spark的安装
sudo tar -zxf spark安装包 -C /usr/local/ #解压文件
cd /usr/local
sudo mv ./spark-2.4文件名 ./spark #将解压后的文件重命名为spark
sudo chown -R 用户名 ./spark #设置用户权限,-R后的参数表示计算机用户名
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
sudo gedit ./conf/spark-env.sh #编辑spark-env.sh文件
在文件最后一行加入:export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath) 来使hadoop和spark建立联系
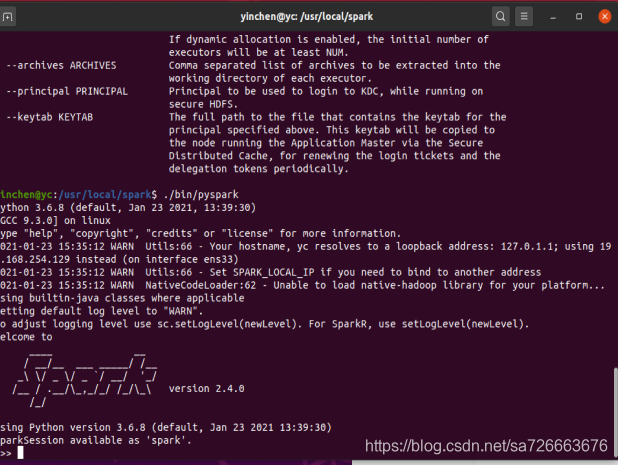
之后直接在命令行输入
$./bin/pyspark 就安装成功出现如下界面:
6 Hbase安装
hbase安装分为3种方式,
单机模式:单纯的用于hbase语法练习
伪分布式模式:用于学习hadoop,spark和hbase之间的交互,模拟实际应用场景
集群模式:用于实际应用场景
6.1 hbase安装:http://dblab.xmu.edu.cn/blog/install-hbase/
说明:HBase的版本一定要和之前已经安装的Hadoop的版本保持兼容,不能随便选择版本。
安装hbase的条件,– jdk– Hadoop( 单机模式不需要,伪分布式模式和分布式模式需要)– SSH
6.2 单机模式配置
用gedit命令打开并编辑hbase-env.sh
gedit /usr/local/hbase/conf/hbase-env.sh
添加以下两行内容:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HBASE_MANAGES_ZK=true
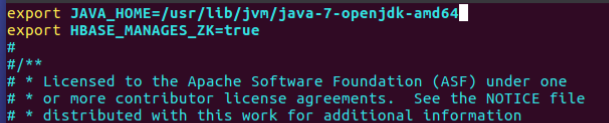
添加完成后保存退出即可。
第一行表示:配置JAVA环境变量
配置HBASE_MANAGES_ZK为true,表示由hbase自己管理zookeeper,不需要单独的zookeeper。
配置/usr/local/hbase/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///usr/local/hbase/hbase-tmp</value>
</property>
</configuration>
不设置的话,hbase.rootdir默认为/tmp/hbase-${user.name},这意味着每次重启系统都会丢失数据。
测试运行:
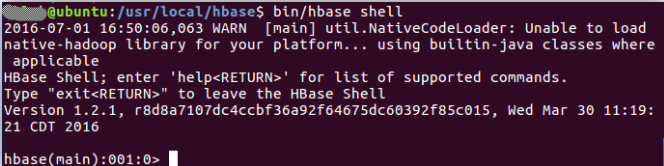
- cd /usr/local/hbase
- bin/start-hbase.sh
- bin/hbase shell
停止HBase运行:bin/stop-hbase.sh
注意:如果在操作HBase的过程中发生错误,可以通过{HBASE_HOME}目录(/usr/local/hbase)下的logs子目录中的日志文件查看错误原因。
6.3 伪分布式模式配置及运行
1.配置/usr/local/hbase/conf/hbase-env.sh
vi /usr/local/hbase/conf/hbase-env.sh
向文件写入一下信息:
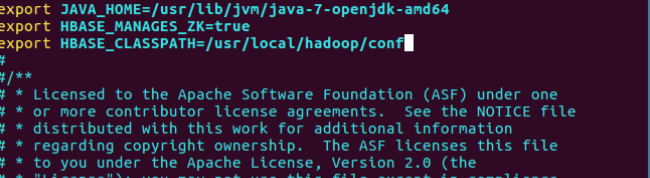
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HBASE_CLASSPATH=/usr/local/hadoop/conf
export HBASE_MANAGES_ZK=true
2.配置/usr/local/hbase/conf/hbase-site.xm
gedit /usr/local/hbase/conf/hbase-site.xml
配置如下内容:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
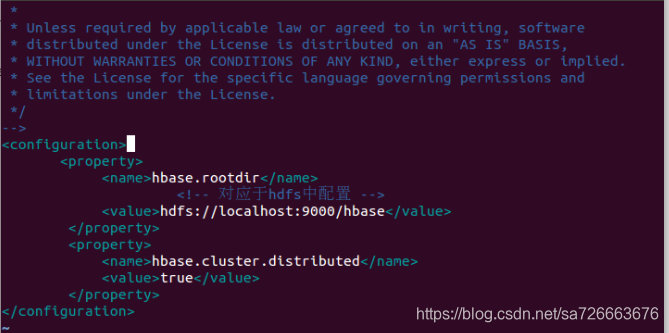
hbase.rootdir指定HBase的存储目录;
hbase.cluster.distributed设置集群处于分布式模式.
3.测试运行HBase。SSH->Hadoop->Hbase->Hbase shell
第一步:首先登陆ssh,之前设置了无密码登陆,因此这里不需要密码;再切换目录至/usr/local/hadoop ;再启动hadoop,如果已经启动hadoop请跳过此步骤。命令如下:
ssh localhost
cd /usr/local/hadoop
./sbin/start-dfs.sh
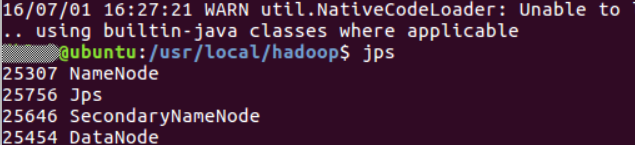
输入命令jps,能看到NameNode,DataNode和SecondaryNameNode都已经成功启动,表示hadoop启动成功,截图如下:
第二步:切换目录至/usr/local/hbase;再启动HBase.命令如下:
cd /usr/local/hbase
bin/start-hbase.sh
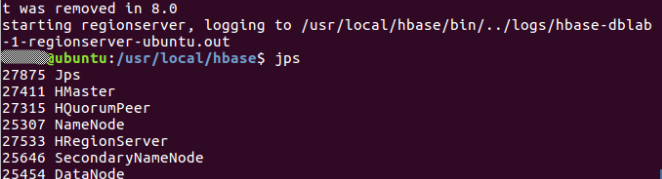
启动成功,输入命令jps,看到以下界面说明hbase启动成功
第三步:进入shell界面:bin/hbase shell

停止HBase运行:bin/stop-hbase.sh
注意:如果在操作HBase的过程中发生错误,可以通过{HBASE_HOME}目录(/usr/local/hbase)下的logs子目录中的日志文件查看错误原因。
这里启动关闭Hadoop和HBase的顺序一定是:登录SSH->启动Hadoop->启动HBase->关闭HBase->关闭Hadoo
6.4 spark连接伪分布式数据库Hbase
启动顺序:SSH->Hadoop->Hbase->pyspark
注意hbase和其他版本配套关系
配置文档:http://dblab.xmu.edu.cn/blog/1715-2/
http://dblab.xmu.edu.cn/blog/install-hbase/
(1)创建一个HBase表
cd /usr/local/hadoop
./sbin/start-all.sh
启动完成以后,一定要输入jps命令查看是否启动成功:如果少了其中一个进程,说明启动失败
2375 SecondaryNameNode
2169 DataNode
2667 NodeManager
2972 Jps
2045 NameNode
2541 ResourceManager
hbase> list #显示当前HBase数据库中有哪些已经创建好的表
如果里面已经有一个名称为student的表,请使用如下命令删除
hbase> disable 'student'
hbase> drop 'student'
hbase> create 'student','info'
hbase> describe 'student'
//首先录入student表的第一个学生记录
hbase> put 'student','1','info:name','Xueqian'
hbase> put 'student','1','info:gender','F'
hbase> put 'student','1','info:age','23'
//然后录入student表的第二个学生记录
hbase> put 'student','2','info:name','Weiliang'
hbase> put 'student','2','info:gender','M'
hbase> put 'student','2','info:age','24'
数据录入结束后,可以用下面命令查看刚才已经录入的数据:
//如果每次只查看一行,就用下面命令
hbase> get 'student','1'
//如果每次查看全部数据,就用下面命令
hbase> scan 'student'
可以得到如下结果:
ROW COLUMN+CELL
1 column=info:age, timestamp=1479640712163, value=23
1 column=info:gender, timestamp=1479640704522, value=F
1 column=info:name, timestamp=1479640696132, value=Xueqian
2 column=info:age, timestamp=1479640752474, value=24
2 column=info:gender, timestamp=1479640745276, value=M
2 column=info:name, timestamp=1479640732763, value=Weiliang
2 row(s) in 0.1610 seconds
(2)配置Spark
请新建一个终端,执行下面命令
cd /usr/local/spark/jars
mkdir hbase
cd hbase
cp /usr/local/hbase/lib/hbase*.jar ./
cp /usr/local/hbase/lib/guava-12.0.1.jar ./ #注意自己包的版本
cp /usr/local/hbase/lib/htrace-core-3.1.0-incubating.jar ./ ##注意自己包的版本
cp /usr/local/hbase/lib/protobuf-java-2.5.0.jar ./ ##注意自己包的版本
打开spark-example-1.6.0.jar下载jar包
mkdir -p /usr/local/spark/jars/hbase/
mv ~/下载/spark-examples* /usr/local/spark/jars/hbase/
编辑器打开spark-env.sh文件
cd /usr/local/spark/conf
vim spark-env.sh
在文件最前面增加下面一行内容:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):$(/usr/local/hbase/bin/hbase classpath):/usr/local/spark/jars/hbase/*
只有这样,后面编译和运行过程才不会出错。
插曲:由于我把上面export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):$(/usr/local/hbase/bin/hbase classpath):/usr/local/spark/jars/hbase/*配置错了导致了如下问题pyspark程序就是不能连接hbase。
yinchen@yc:/usr/local/spark$ ./bin/pyspark --jars ./bin/spark-examples_2.11-1.6.0-typesafe-001.jar
Python 3.6.8 (default, Jan 23 2021, 13:39:30)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
2021-02-17 23:12:39 WARN Utils:66 - Your hostname, yc resolves to a loopback address: 127.0.1.1; using 192.168.254.129 instead (on interface ens33)
2021-02-17 23:12:39 WARN Utils:66 - Set SPARK_LOCAL_IP if you need to bind to another address
2021-02-17 23:12:39 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Python version 3.6.8 (default, Jan 23 2021 13:39:30)
SparkSession available as 'spark'.
>>> host="localhost"
>>> table="student"
>>> conf={"hbase.zookeeper.quorum":host,"hbase.mapreduce.inputtable":table}
>>> keyConv="org.apache.spark.examples.pythonconverters.ImmutableBytesWritableToStringConverter"
>>> valueConv="org.apache.spark.examples.pythonconverters.HBaseResultToStringConverter"
>>> hbase_rdd=sc.newAPIHadoopRDD("org.apache.hadoop.hbase.mapreduce.TableInputFormat","org.apache.hadoop.hbase.io.ImmutableBytesWritable","org.apache.hadoop.hbase.client.Result",keyConverter=keyConv,valueConverter=valueConv,conf=conf)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/spark/python/pyspark/context.py", line 751, in newAPIHadoopRDD
jconf, batchSize)
File "/usr/local/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py", line 1257, in __call__
File "/usr/local/spark/python/pyspark/sql/utils.py", line 63, in deco
return f(*a, **kw)
File "/usr/local/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py", line 328, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.newAPIHadoopRDD.
: java.lang.ClassNotFoundException: org.apache.hadoop.hbase.io.ImmutableBytesWritable
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.util.Utils$.classForName(Utils.scala:238)
at org.apache.spark.api.python.PythonRDD$.newAPIHadoopRDDFromClassNames(PythonRDD.scala:312)
at org.apache.spark.api.python.PythonRDD$.newAPIHadoopRDD(PythonRDD.scala:297)
at org.apache.spark.api.python.PythonRDD.newAPIHadoopRDD(PythonRDD.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
(3)编写pyspark程序读取HBase数据
启动pyspark:/usr/local/spark/bin/pyspark
输入如下代码:
host = 'localhost'
table = 'student'
conf = {"hbase.zookeeper.quorum": host, "hbase.mapreduce.inputtable": table}
keyConv = "org.apache.spark.examples.pythonconverters.ImmutableBytesWritableToStringConverter"
valueConv = "org.apache.spark.examples.pythonconverters.HBaseResultToStringConverter"
hbase_rdd = sc.newAPIHadoopRDD("org.apache.hadoop.hbase.mapreduce.TableInputFormat","org.apache.hadoop.hbase.io.ImmutableBytesWritable","org.apache.hadoop.hbase.client.Result",keyConverter=keyConv,valueConverter=valueConv,conf=conf)
count = hbase_rdd.count()
hbase_rdd.cache()
output = hbase_rdd.collect()
for (k, v) in output:
print (k, v)
1 {"qualifier" : "age", "timestamp" : "1512549772307", "columnFamily" : "info", "row" : "1", "type" : "Put", "value" : "23"}
{"qualifier" : "gender", "timestamp" : "1512549765192", "columnFamily" : "info", "row" : "1", "type" : "Put", "value" : "F"}
{"qualifier" : "name", "timestamp" : "1512549757406", "columnFamily" : "info", "row" : "1", "type" : "Put", "value" : "Xueqian"}
2 {"qualifier" : "age", "timestamp" : "1512549829145", "columnFamily" : "info", "row" : "2", "type" : "Put", "value" : "24"}
{"qualifier" : "gender", "timestamp" : "1512549790422", "columnFamily" : "info", "row" : "2", "type" : "Put", "value" : "M"}
{"qualifier" : "name", "timestamp" : "1512549780044", "columnFamily" : "info", "row" : "2", "type" : "Put", "value" : "Weiliang"}
(4)编写pyspark程序向HBase写入数据
启动pyspark,然后在pyspark shell中输入如下代码
host = 'localhost'
table = 'student' #定义写入的hbase表格名称
keyConv = "org.apache.spark.examples.pythonconverters.StringToImmutableBytesWritableConverter"
valueConv = "org.apache.spark.examples.pythonconverters.StringListToPutConverter"
conf = {"hbase.zookeeper.quorum": host,"hbase.mapred.outputtable": table,"mapreduce.outputformat.class": "org.apache.hadoop.hbase.mapreduce.TableOutputFormat","mapreduce.job.output.key.class": "org.apache.hadoop.hbase.io.ImmutableBytesWritable","mapreduce.job.output.value.class": "org.apache.hadoop.io.Writable"} #conf配置连接数据库的相关信息
rawData = ['3,info,name,Rongcheng','4,info,name,Guanhua'] #rawData为通过hadoop写入hbase数据库的内容
// ( rowkey , [ row key , column family , column name , value ] )
sc.parallelize(rawData).map(lambda x: (x[0],x.split(','))).saveAsNewAPIHadoopDataset(conf=conf,keyConverter=keyConv,valueConverter=valueConv)
此处发现执行后,pyspark会报如下错误,但是数据仍会插入到hbase中.
pyspark.sql.utils.IllegalArgumentException: 'Can not create a Path from a null string'
执行后,我们可以切换到刚才的HBase终端窗口,在HBase shell中输入如下命令查看结果:
hbase> scan 'student'
hbase
就能查看到新增的数据
7 MySQL安装
7.1.首先ubuntu正常安装mysql:
参考博客:https://blog.csdn.net/sa726663676/article/details/113647373
也可参考http://dblab.xmu.edu.cn/blog/install-mysql/(不推荐)
7.2.找到系统对应版本的java JDBC8.0.23 版本对应于我刚刚安装的mysql版本8.0.23 。 如果版本不对应可能导致插曲7.5.1错误
java JDBC8.0.23JDBC 下载: https://dev.mysql.com/downloads/connector/j/?os=26
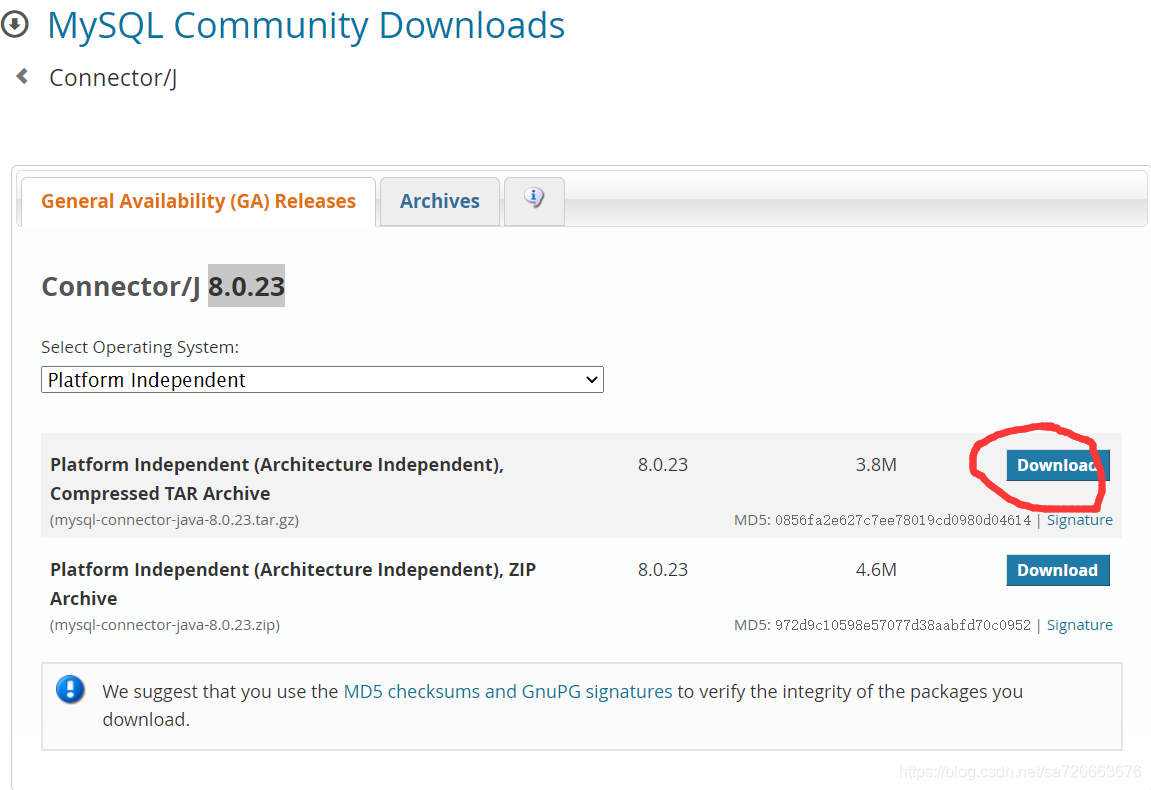
7.3.将下载的tar.gz文件进行解压:
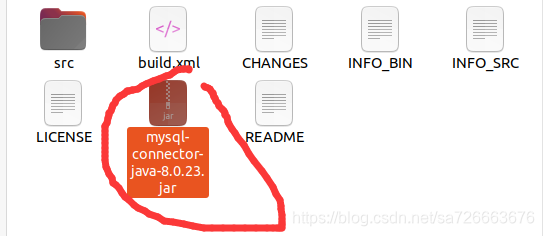
ubuntu的解压命令是tar -zxvf (文件名)**.tar.gz
7.4 解压的画圈文件放在 /usr/local/spark/jars 目录下
注意路径是自己安装的spark路径
使用pyspark连接mysql数据库:
连接之前我们需要先添加些信息
首先打开数据库向数据库添加些表格和信息:

7.5 pyspark通过jdbc连接MySQL数据库:
打开pyspark输入下面两行代码:
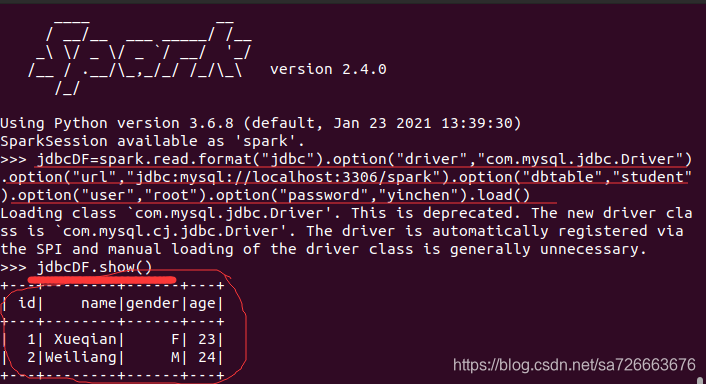
jdbcDF=spark.read.format("jdbc").option("driver","com.mysql.jdbc.Driver").option("url","jdbc:mysql://localhost:3306/spark").option("dbtable","student").option("user","root").option("password","yinchen").load()
jdbcDF.show()
运行结果图:正确连接到了mysql显示了刚刚新建表格的信息
以上代码解读
jdbcDF=spark.read.format("jdbc")
.option("driver","com.mysql.jdbc.Driver")
.option("url","jdbc:mysql://localhost:3306/spark") #ip地址localhost和端口号3306以及连接的数据库名spark,mysql默认为3306,如果端口写错会导致插曲7.5.2错误
.option("dbtable","student") #表名student
.option("user","root") #用户名root
.option("password","yinchen") #密码yinchen
.load()
插曲7.5.1:如果JDBC文件没有复制到pyspark子目录的jar目录中,出现错误如下,因此当出现下面错误的时候考虑JDBC.jar包是否存在或者版本是否正确:
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Python version 3.6.8 (default, Jan 23 2021 13:39:30)
SparkSession available as 'spark'.
>>> jdbcDF=spark.read.format("jdbc").option("driver","com.mysql.jdbc.Driver").option("url","jdbc:mysql://localhost:3306/spark").option("dbtable","student").option("user","root").option("password","yinchen").load()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/spark/python/pyspark/sql/readwriter.py", line 172, in load
return self._df(self._jreader.load())
File "/usr/local/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py", line 1257, in __call__
File "/usr/local/spark/python/pyspark/sql/utils.py", line 63, in deco
return f(*a, **kw)
File "/usr/local/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py", line 328, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o29.load.
: java.lang.ClassNotFoundException: com.mysql.jdbc.Driver
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at org.apache.spark.sql.execution.datasources.jdbc.DriverRegistry$.register(DriverRegistry.scala:45)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions$$anonfun$5.apply(JDBCOptions.scala:99)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions$$anonfun$5.apply(JDBCOptions.scala:99)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.<init>(JDBCOptions.scala:99)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.<init>(JDBCOptions.scala:35)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:32)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:167)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
插曲7.5.2 使用JDBC连接mysql时端口写错了
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Python version 3.6.8 (default, Jan 23 2021 13:39:30)
SparkSession available as 'spark'.
>>> jdbcDF=spark.read.format("jdbc").option("driver","com.mysql.jdbc.Driver").option("url","jdbc:mysql://localhost:33060/spark").option("dbtable","student").option("user","root").option("password","yinchen").load()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/spark/python/pyspark/sql/readwriter.py", line 172, in load
return self._df(self._jreader.load())
File "/usr/local/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py", line 1257, in __call__
File "/usr/local/spark/python/pyspark/sql/utils.py", line 63, in deco
return f(*a, **kw)
File "/usr/local/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py", line 328, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o37.load.
: java.sql.SQLNonTransientConnectionException: Unsupported protocol version: 11. Likely connecting to an X Protocol port.
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:110)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:97)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:89)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:63)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:73)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:79)
at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:833)
at com.mysql.cj.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:453)
at com.mysql.cj.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:246)
at com.mysql.cj.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:198)
at org.apache.spark.sql.execution.datasources.jdbc.DriverWrapper.connect(DriverWrapper.scala:45)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:63)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:54)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD$.resolveTable(JDBCRDD.scala:56)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRelation$.getSchema(JDBCRelation.scala:210)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:35)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:167)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.mysql.cj.exceptions.UnableToConnectException: Unsupported protocol version: 11. Likely connecting to an X Protocol port.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at com.mysql.cj.exceptions.ExceptionFactory.createException(ExceptionFactory.java:61)
at com.mysql.cj.protocol.a.NativeCapabilities.setInitialHandshakePacket(NativeCapabilities.java:112)
at com.mysql.cj.protocol.a.NativeProtocol.readServerCapabilities(NativeProtocol.java:506)
at com.mysql.cj.protocol.a.NativeProtocol.beforeHandshake(NativeProtocol.java:385)
at com.mysql.cj.protocol.a.NativeProtocol.connect(NativeProtocol.java:1348)
at com.mysql.cj.NativeSession.connect(NativeSession.java:157)
at com.mysql.cj.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:953)
at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:823)
... 24 more
8.安装kafka
8.1 下载安装kafka
kafka的官方下载地址为:https://kafka.apache.org/downloads
#这里我安装的是0.11.0.3:安装的时候最好注意下版本匹配,此安装包内已经附带zookeeper,不需要额外安装zookeeper.按顺序执行如下步骤:
打开文件下载位置的终端,然后运行如下命令
cd ~/下载
sudo tar -zxf kafka_2.11-0.10.1.0.tgz -C /usr/local
cd /usr/local
sudo mv kafka_2.11-0.10.1.0/ ./kafka
sudo chown -R yinchen ./kafka #注意红色为你自己的电脑用户名
8.2 测试简单实例
接下来在Ubuntu系统环境下测试简单的实例。Mac系统请自己按照安装的位置,切换到相应的指令。按顺序执行如下命令:
# 进入kafka所在的目录
cd /usr/local/kafka
bin/zookeeper-server-start.sh config/zookeeper.properties
命令执行后不会返回Shell命令输入状态,zookeeper就会按照默认的配置文件启动服务,请千万不要关闭当前终端.启动新的终端,输入如下命令:
cd /usr/local/kafka
bin/kafka-server-start.sh config/server.properties
kafka服务端就启动了,请千万不要关闭当前终端。启动另外一个终端,输入如下命令:
cd /usr/local/kafka
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dblab
topic是发布消息发布的category,以单节点的配置创建了一个叫dblab的topic.可以用list列出所有创建的topics,来查看刚才创建的主题是否存在
bin/kafka-topics.sh --list --zookeeper localhost:2181
可以在结果中查看到dblab这个topic存在。接下来用producer生产点数据:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic dblab
并尝试输入如下信息:
hello hadoop
hello xmu
hadoop world
然后再次开启新的终端或者直接按CTRL+C退出。然后使用consumer来接收数据,输入如下命令:
cd /usr/local/kafka
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic dblab --from-beginning
便可以看到刚才产生的三条信息。说明kafka安装成功。
kafka安装参考:http://dblab.xmu.edu.cn/blog/1096-2/