目录
线程池核心设计与实现
1、总体设计
Java中的线程池核心实现类是ThreadPoolExecutor,ThreadPoolExecutor实现的顶层接口是Executor,顶层接口Executor提供了一种思想:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如何调度线程来执行任务,用户只需提供Runnable对象,将任务的运行逻辑提交到执行器(Executor)中,由Executor框架完成线程的调配和任务的执行部分。ThreadPoolExecutor将会一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
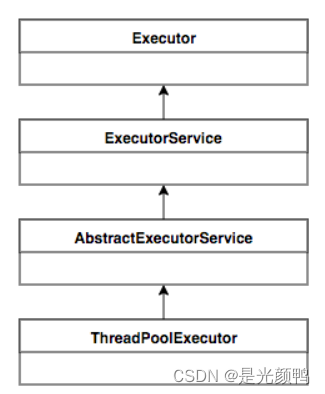
ThreadPoolExecutor运行机制
线程池在内部构建了一个生产者消费者模型,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。线程池的运行主要分成两部分:任务管理、线程管理。任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任务后续的流转:(1)直接申请线程执行该任务;(2)缓冲到队列中等待线程执行;(3)拒绝该任务。线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
线程池运行机制:
- 线程池如何维护自身状态。
- 线程池如何管理任务。
- 线程池如何管理线程。
2、生命周期管理
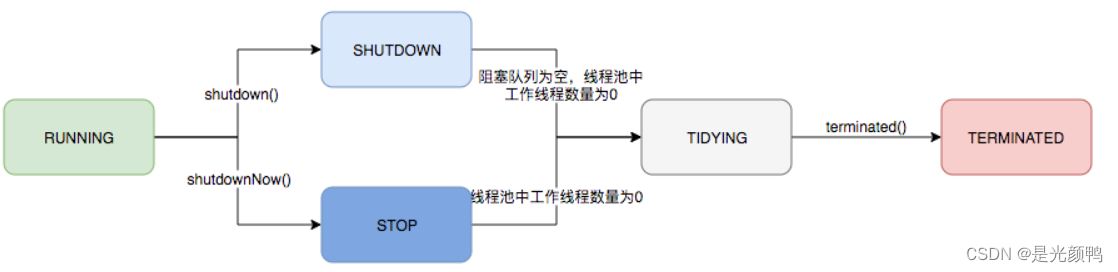
线程池运行的状态,并不是用户显式设置的,而是伴随着线程池的运行,由内部来维护。线程池内部使用一个变量维护两个值:运行状态(runState)和线程数量 (workerCount)。如下代码所示:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));ctl这个AtomicInteger类型,是对线程池的运行状态和线程池中有效线程的数量进行控制的一个字段, 它同时包含两部分的信息:线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount),高3位保存runState,低29位保存workerCount,两个变量之间互不干扰。用一个变量去存储两个值,可避免在做相关决策时,出现不一致的情况,不必为了维护两者的一致,而占用锁资源。
ThreadPoolExecutor的运行状态有5种,分别为:

生命周期转换如下入所示:
参数
keepAliveTime:非核心线程空闲时间(没有任务执行时)达到keepAliveTime,该线程会退出(避免资源浪费就应该要退出)
3、任务执行机制
3.1 任务调度
任务调度是线程池的主要入口,当用户提交了一个任务,接下来这个任务将如何执行都是由这个阶段决定的。了解这部分就相当于了解了线程池的核心运行机制。
首先,所有任务的调度都是由execute方法完成的,这部分完成的工作是:检查现在线程池的运行状态、运行线程数、运行策略,决定接下来执行的流程,是直接申请线程执行,或是缓冲到队列中执行,亦或是直接拒绝该任务。其执行过程如下:
- 首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
- 如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
- 如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个