同时跟踪任意时刻任意地方的的一切东西

0.摘要
本文提出了一种新的测试时间优化方法,用于从视频序列中估计稠密帧和远距离运动。先前的光流或粒子视频跟踪算法通常在有限的时间窗口内运行,难以通过遮挡进行跟踪并保持估计的运动轨迹全局一致性。本文中我们提出了一个完整的、全局一致的运动表示方法,称为omni-motion,它允许对视频中的每个像素进行准确的、全程的运动估计。OmniMotion使用准3d规范体积(quasi-3D canonical volume)表征视频,并通过局部和规范空间之间的映射执行像素级跟踪。这种表示使我们能够确保全局一致性,可以对遮挡进行跟踪,并对相机和物体运动的任何组合进行建模。TAP-Vid基准和真实世界镜头的广泛评测表明,我们的方法在定量和定性方面都大大优于先前state of art的方法。可在页面 omnimotion.github.io 中进一步了解项目的更多结果。
1. 介绍
运动估计方法传统上遵循两类主要方法:稀疏特征跟踪方法和稠密光流方法[55]。虽然每种类型的方法都被证明对各自的应用是有效的,但两种表示都不能完全模拟视频的运动:两帧光流无法捕获长时间窗口内的运动轨迹,而稀疏跟踪不能模拟所有像素的运动。
许多方法试图缩小这一差距,即在视频中估计稠密的和长程像素轨迹。这些方法的范围从简单地将两帧光流场链接在一起的方法,到最近的直接预测跨多帧的逐像素轨迹的方法[23]。尽管如此,这些方法在估计运动时都使用有限的上下文信息,忽略了时间或空间上遥远的信息。这种局域性可能导致长轨迹上的累积误差和运动估计中的时空不一致。即使先前的方法确实考虑了远程上下文[55],它们也不适用在2D域中,因其在遮挡事件期间出现跟踪丢失的情况。总而言之,产生稠密和远程轨迹仍然是该领域的一个开放性问题,其中有三个关键挑战:(1)在长序列中保持准确的轨迹,(2)通过遮挡跟踪点,(3)保持空间和时间上的一致性。
在本文这项工作中,我们提出了一种视频运动估计的整体方法,该方法使用视频中的所有信息来联合估计每个像素的全程运动轨迹。这种方法,我们称之为OmniMotion,使用一种准3d表示,其中一个规范的3D体积通过一组局部规范双射映射到每帧局部体积。这些双射作为动态多视图几何的某种灵活松弛表示,来对相机和场景运动的组合进行建模。我们的表示保证了循环一致性,并且可以跟踪所有像素,即使在遮挡的情况下(“Everything, Everywhere”)。我们优化了每个视频的表示,以共同求解整个视频的“All at Once”的运动。一旦优化,我们的表示可以在视频中的任何连续坐标进行查询,以接收跨越整个视频的运动轨迹。
综上所述,我们提出了一种方法:1)为整个视频中的所有点产生全局一致的全长运动轨迹,2)可以通过遮挡来跟踪点,3)可以通过相机和场景运动的任何组合来处理户外视频。我们在TAP视频跟踪基准上定量地展示了这些优势[15],在那里我们实现了最先进的性能,大大超过了所有先前的方法。
2. 相关工作
稀疏特征跟踪方法。跨图像的跟踪特征[4,42]对于诸如SFM(Structure from Motion)[1,56,59]和SLAM[17]等广泛的应用至关重要。虽然稀疏特征跟踪[13,43,57,67]可以建立远程对应关系,但这种对应关系仅限于一组独特的兴趣点,并且通常仅限于刚性场景。因此,下面我们将重点关注可以为一般视频产生稠密像素运动的工作。
光流法。光流传统上被表述为一个优化问题[6,7,24,75]。然而,最近的进展使得使用质量和效率更高的神经网络直接预测光流成为可能[20,25,26,61]。RAFT[66]是一种领先的方法,它通过基于4D相关体积的流场迭代更新来估计运动流。虽然光流方法允许在连续帧之间进行精确的运动估计,但它们不适合远程运动估计:将两两光流链接到更长的轨迹中会导致漂移并且无法处理遮挡,而直接计算远距离帧之间的光流(即较大的位移)通常会导致时间不一致[8,75]。多帧光流估计[27,29,52,70]可以解决两帧光流的一些限制,但仍然难以处理远距离运动。
特征匹配方法。虽然光流方法通常用于对连续帧进行操作,但其他技术可以估计距离较远的视频帧对之间的稠密对应[41]。有几种方法使用循环一致性[28,74,83]等线索,以自监督或弱监督的方式学习这种对应关系[5,10,13,37,53,71,73,78],而其他方法[18,30,62,68,69]使用更强的监督信号,如从3D重建管道生成的几何对应关系[39,56]。然而,两两匹配方法通常不包含时间上下文,这可能导致长视频的跟踪不一致和遮挡处理不佳。相比之下,我们的方法通过遮挡产生平滑的轨迹。
像素级远程跟踪。最近一个值得注意的方法,PIPs[23],通过在一个小的时间窗口(8帧)内利用上下文来估计通过遮挡的多帧轨迹。然而,为了产生比这个时间窗口更长的视频运动,PIPs[仍然必须链接对应响应,这个过程(1)容易漂移,(2)将失去8帧窗口之外仍然被遮挡的点的轨迹。在我们工作的同时,有几项工作开发了基于学习的方法,用于以前馈方式预测远距离像素级轨迹。MFT[46]学习选择最可靠的光流序列来执行远程跟踪。TAPIR[16]通过采用受TAP-Net[15]启发的匹配阶段和受PIPs[启发的细化阶段[23]来跟踪点。CoTracker[31]提出了一种灵活而强大的跟踪算法,采用transformer架构来跟踪整个视频中的点。我们的贡献是对这些工作的补充:在优化全局运动表示时,这些方法中的任何一种的输出都可以用作输入监督。
基于视频的运动优化。与我们的方法在概念上最相关的是在整个视频上全局优化运动的经典方法[2,12,36,54,55,60,63,72]。例如,粒子视频从初始光流场产生一组半稠密的远程轨迹(称为粒子)[55]。然而,它不会通过闭包进行跟踪;被遮挡的实体在重新出现时将被视为不同的粒子。Rubinstein等人[54]进一步提出了一种组合分配方法,可以通过遮挡进行跟踪,并生成更长的轨迹。然而,该方法仅为具有简单运动的视频生成稠密轨迹,而我们的方法估计一般视频中所有像素的远程运动。与此相关的还有particleSFM[82],它优化了来自成对光流的远程对应。与我们的方法不同,particleSFM专注于SFM框架内的相机姿态估计,其中只有来自静态区域的对应位置被优化,而动态对象被视为离群值。
神经视频表示。虽然我们的方法与最近使用基于坐标的多层感知器(mlp)对视频建模的方法有相似之处[44,58,65],但之前的工作主要集中在诸如新视图合成[38,40,47,48,77]和视频分解[32,81]等问题上。相比之下,我们的工作针对的是稠密、远距离运动估计的挑战。尽管动态新视图合成的一些方法会产生2D运动作为副产品,但这些系统需要已知的相机姿势,并且由此产生的运动通常是错误的[21]。一些动态重建方法[9,76,79,80]也可以产生2D运动,但这些方法通常以物体为中心,专注于铰接物体。或者,基于视频分解的表示(如Layered Neural Atlases[32]Deformable Sprites[81])解决了每帧和全局纹理图集之间的映射。帧与帧之间的对应关系可以通过倒转这种映射来推导,但这个过程成本高且不可靠。此外,这些方法仅限于使用固定顺序的有限数量的层来表示视频,限制了它们对复杂的现实世界视频进行建模的能力。
3. 概述
我们提出了一种测试时间优化方法,用于从视频序列中估计稠密和远距离运动。我们的方法将一组帧和成对噪声运动估计(例如,光流场)作为输入,并使用这些来求解整个视频的完整的、全局一致的运动表示。一旦优化,我们的表示可以用任何帧中的任何像素进行查询,从而在整个视频中产生平滑、准确的运动轨迹。我们的方法可以识别点被遮挡的时间,甚至可以通过遮挡来跟踪点。在接下来的章节中,我们描述了我们的底层表示,称为OmniMotion(第1节),然后描述了我们从视频中恢复这种表示的优化过程(第5节)。
4. OmniMotion表示
正如第1节所讨论的,经典的运动表示,如成对的光流,在物体被遮挡时失去跟踪,并且在多个帧组成对应时可能产生不一致。因此,为了即使通过遮挡也能获得准确、一致的轨迹,我们需要一个全局运动表示,即一种对场景中所有点的轨迹进行编码的数据结构。一种这样的全局表示是将场景分解成一组离散的、深度分离的层[32,81]。然而,大多数现实世界的场景不能被表示为一组固定的、有序的层:例如,考虑一个物体在3D中旋转的简单情况。另一个极端是完全的3D重建,它将3D场景几何、镜头和场景运动分开。然而,这是一个极度不适定的问题。因此,我们要问:在没有明确的动态3D重建的情况下,我们能准确地跟踪现实世界的运动吗?
我们使用我们提出的表示来回答这个问题,OmniMotion(如图2所示)。OmniMotion将视频中的场景表示为一个规范的3D体,通过局部规范双映射将每帧的场景映射到局部3D体。局部-规范双映射被参数化为神经网络,并在不分离两者的情况下捕获相机和场景运动。因此,视频可以被认为是对固定的静态摄像机产生的局部3D体的渲染。
由于OmniMotion并没有明确地将相机和场景运动分开,因此产生的表示并不是物理上准确的3D场景重建。我们称之为准3D表示。这种动态多视图几何的松弛表示,使我们能够避开动态3D重建具有挑战性的模糊性。然而,我们保留了通过遮挡进行一致和准确的长程跟踪所需的属性:首先,通过在每个局部帧和规范帧之间建立双映射,OmniMotion保证了所有局部帧之间的全局循环一致的3D映射,它模拟了现实世界中度量3D参考帧之间的一对一对应关系。其次,OmniMotion保留了投射到每个像素上的所有场景点的信息,以及它们的相对深度排序,即使它们暂时被遮挡在视野之外,也能被跟踪。在下面的部分中,我们将描述我们的准3D规范体和3D双映射,然后描述如何使用它们来计算任意两帧之间的运动。
4.1. 规范三维体
我们使用规范3D体积 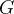
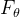
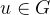
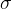

4.2. 3d双射
我们定义了一个连续双射映射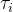
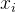
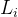
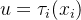
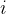
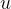
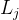

双射映射确保单帧中3D点之间的对应关系都是循环一致的,因为它们源自于相同的规范点。为了允许能够捕捉真实世界运动的表达性映射,我们将这些双射参数化为可逆神经网络(INNs)。受最近同模形状建模工作的启发[35,49],我们使用Real-NVP[14],因为它的公式简单且具有解析可逆性。Real-NVP通过组合称为仿射耦合层的简单双射变换来构建双射映射。仿射耦合层将输入分成两部分:第一部分保持不变,参数化应用于第二部分的仿射变换。
我们修改了这个体系结构,使其也以每帧潜在编码 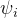
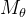

图2:方法概述 (a)我们的OmniMotion表示由一个规范3D体积G和一组双射
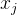
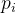
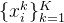
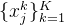
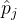
4.3. 计算帧到帧的运动
鉴于这种表示,我们现在描述如何为第 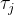
具体来说,由于我们假设相机运动被局部规范双射 ,其中
![o_i=[p_i,0],d=[0,0,1]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9vX2klM0QlNUJwX2klMkMwJTVEJTJDZCUzRCU1QjAlMkMwJTJDMSU1RA%3D%3D)
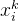
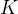
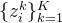
接下来,我们通过将这些样本映射到规范空间,然后查询密度网络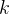

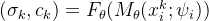

现在,我们可以将射线上的所有 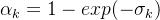
使用类似的过程对 
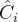
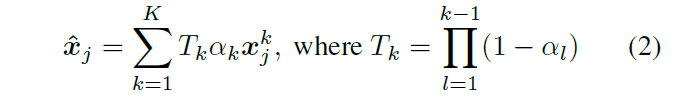
5. 优化
我们的优化过程以一个视频序列和一组噪声对应预测(来自现有方法)作为输入作为指导,并为整个视频生成一个完整的、全局一致的运动估计。
5.1. 采集输入运动数据
在我们的大多数实验中,我们使用RAFT[66]来计算输入对偶对应。我们还实验了另一种密集对应方法TAPNet[15],并在我们的评估中证明,在给定不同类型的输入对应时,我们的方法始终有效。以RAFT为例,我们首先穷举地计算所有成对光流。由于光流方法在大位移下会产生明显的误差,因此我们应用周期一致性和外观一致性检查来过滤掉虚假对应。在被认为可靠的情况下,我们还可以选择通过链接增加流。关于我们的流量收集过程的更多细节在补充材料中提供。尽管进行了过滤,但(现在不完整的)流场仍然存在噪声和不一致。我们现在介绍我们的优化方法,将这些有噪声的、不完整的成对运动整合成完整的、精确的远程运动。
5.2 损失函数
我们的主要损失函数是流损失。我们将优化表示的预测流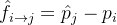
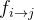
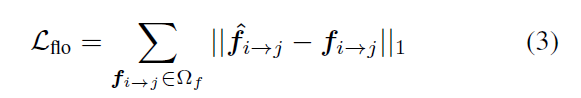
其中 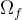
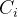
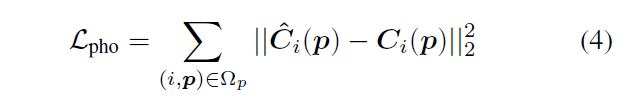
其中 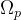


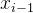
,然后最小化3D加速度,如[38]所示:

其中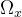
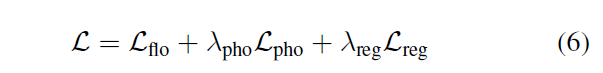
其中权值 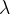
5.3. 基于硬挖掘平衡监督
穷举成对流输入使优化阶段可用的有用运动信息最大化。然而,这种方法,特别是当与流过滤过程相结合时,可能导致动态区域中运动样本的收集不平衡。刚性背景区域通常具有许多可靠的成对对应关系,而快速移动和变形的前景对象在滤波后通常具有更少的可靠对应关系,特别是在远距离帧之间。这种不平衡会导致网络完全关注主导的(简单的)背景运动,而忽略了代表一小部分监督信号的具有挑战性的运动物体。
为了解决这个问题,我们提出了一个简单的策略,用于在训练过程中挖掘困难的例子。具体来说,我们定期缓存流预测,并通过计算预测流和输入流之间的欧几里得距离来计算误差映射。在优化过程中,我们引导采样,使具有高误差的区域更频繁地采样。我们在连续帧上计算这些误差映射,我们假设我们的监督光流是最可靠的。更多细节请参考附录。
5.4. 实现细节
网络结构。我们的六个仿射耦合层的映射网络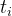
表示。我们将所有像素坐标 ![[-1,1]^2\times [0,2]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUItMSUyQzElNUQlNUUyJTVDdGltZXMlMjAlNUIwJTJDMiU1RA%3D%3D)
训练。用Adam[33]对每个视频序列的表示进行了200K次迭代训练。在每个训练批次中,我们从8对图像中采样256个对应,总共1024个对应。我们的样本
6. 评测
6.1. 基准
我们在TAP-Vid基准上评估了我们的方法[15],该基准旨在评估跨长视频剪辑的点跟踪性能。TAP-Vid包括真实世界的视频与准确的人类注释点轨道和合成视频与完美的地面真实点轨道。每个点轨迹在整个视频中都有注释,当不可见时被标记为遮挡。
数据集。我们对来自TAP-Vid的以下数据集进行了评估:1)DAVIS,这是一个来自DAVIS 2017验证集[50]的30个视频的真实数据集,片段范围为34-104帧,平均每个视频有21.7个点轨道注释。2) Kinetics,一个真实的数据集,包含1189个视频,每个视频有250帧,来自Kinetics-700-2020验证集[11],平均每个视频有26.3个点轨迹注释。为了使评估易于处理,像我们这样的测试时间优化方法,我们随机抽取100个视频的子集,并评估该子集上的所有方法。3) RGB-Stacking[34],一个由50个视频组成的合成数据集,每个视频有250帧和30个音轨。我们排除了合成的Kubric数据集[22],因为它主要用于训练。对于定量评估,我们坚持TAP基准协议,并在256×256分辨率下评估所有方法,但所有定性结果都在更高分辨率(480p)下运行。
评测指标。根据TAP-Vid基准,我们报告了预测轨迹的位置和遮挡精度。我们还引入了一个测量时间相干性的新度量。我们的评估指标包括:
•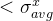

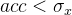
•Average Jaccard (AJ) 在与
•遮挡精度(OA)评估每帧可见性/遮挡预测的准确性。
•时间相干性(TC)通过测量地面真实轨迹和预测轨迹加速度之间的L2距离来评估轨迹的时间相干性。加速度被测量为两个相邻帧之间可见点的流量差。
6.2. 基线
我们将OmniMotion与各种类型的密集对应方法进行比较,包括光流、特征匹配和多帧轨迹估计,如下所示:
RAFT[66]是最先进的双框架流法。我们考虑了两种使用RAFT在测试时生成多帧轨迹的方法:1)将连续帧之间的RAFT预测链接到更长的轨迹中,我们称之为
RAFT- c,以及2)直接计算任何(非相邻)查询和目标帧之间的RAFT流(RAFT-D)。当使用RAFT-D生成轨迹时,我们总是使用先前的流预测作为当前帧的初始化。
PIPs[23]是一种估计可以处理遮挡的多帧点轨迹的方法。默认情况下,该方法使用8帧的时间窗口,必须通过链接生成更长的轨迹。我们使用pip的官方实现来执行链接。
Flow-Walk[5]使用多尺度对比随机漫步,通过鼓励周期跨越时间的一致性来学习时空对应。RAFT类似,我们将链式和直接对应计算分别报告为Flow-Walk-C和Flow-Walk-D。
TAP-Net[15]使用成本量来预测单个目标帧中查询点的位置,以及标量遮挡logit。
Deformable Sprites[81]是一种基于层的视频分解方法。和我们的方法一样,它使用了每个视频的测试时间优化。然而,它不会直接产生帧到帧的对应关系,因为从每帧到规范纹理图像的映射是不可逆的。需要在纹理图像空间中进行最近邻搜索才能找到对应关系。分层神经地图集[32]与Deformable Sprites有相似之处,但需要语义分割掩码作为输入,因此我们选择与Deformable Sprites进行比较。
PIPs, TAP-Net和Deformable Sprites直接预测遮挡,但RAFT和Flow-Walk不能。因此,我们遵循先前的工作[15,78],并使用48像素阈值的循环一致性检查来生成这些方法的遮挡预测。对于我们的方法,我们通过首先将查询点映射到目标帧中相应的3D位置来检测遮挡,然后检查该3D位置在目标帧中的透射率。
6.3. 比较
定量比较。我们将我们的方法与表1中TAP-Vid基准的基线进行比较。我们的方法达到了最佳的位置精度、遮挡精度和时间相干性在不同数据集之间保持一致。我们的方法可以很好地处理来自RAFT和TAP-Net的不同输入对偶对应,并且在这两种基本方法的基础上提供了一致的改进。
与直接操作(非相邻)查询和目标帧对的方法(如RAFTD、TAP-Net和Flow-Walk-D)相比,由于我们的全局一致表示,我们的方法实现了更好的时间一致性。与RAFT-C、PIPs和flow - walk - c等流链方法相比,我们的方法具有更好的跟踪性能,特别是在较长的视频上。链接方法随着时间的推移会累积误差,并且对c-clusion的鲁棒性不强。虽然PIPs考虑更宽的时间窗口(8帧)来更好地处理遮挡,但如果它在整个时间窗口之外保持遮挡,它就无法跟踪一个点。相比之下,OmniMotion可以通过扩展遮挡来跟踪点。我们的方法也优于测试时间优化方法Deformable Sprites[81]。Deformable Sprites使用固定顺序的预定义两层或三层来分解视频,并将背景建模为具有每帧同质性的2D地图集,限制了其适合具有复杂摄像机和场景运动的视频的能力。
定性比较。我们将我们的方法与图3中的基线进行了定性比较。我们强调了我们的能够通过(长)遮挡事件识别和跟踪,同时也为遮挡期间的点提供合理的位置,以及处理大的摄像机运动视差。请参考补充视频进行动画比较。

图3:我们的方法与DAVIS基线的定性比较[50]。最左边的图片显示了第一帧中的查询点,右边的三张图片显示了随时间推移的跟踪结果。值得注意的是,我们的方法成功地跟踪了swing和india中的遮挡事件,而基线方法失败了。我们的方法还可以检测遮挡(标记为十字“+”),即使在一个点被遮挡的情况下也能给出合理的位置估计。请参阅补充视频,以更好地可视化跟踪准确性和一致性
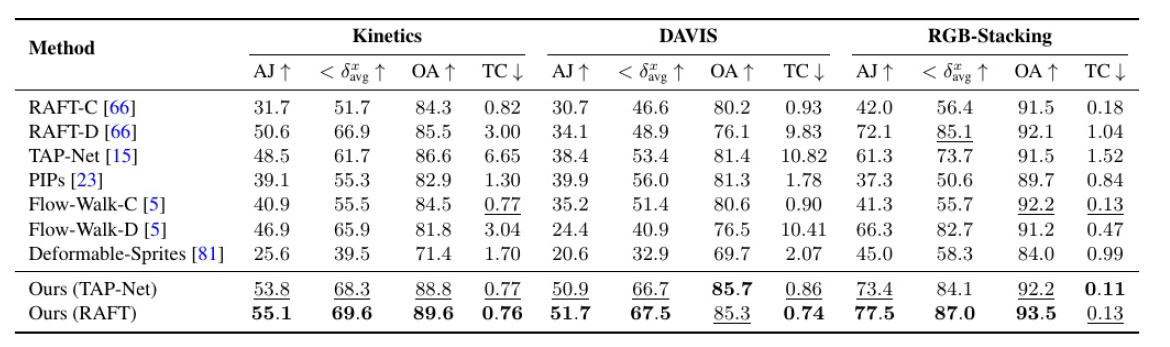
表1:我们的方法与TAP-Vid基准基线的定量比较[15]。我们将我们的方法称为our,并提出了两个变体,our (TAP-Net)和our (RAFT),它们分别使用来自TAP-Net[15]和RAFT[66]的输入对对应进行优化。Ours和Deformable Sprites[81]都通过对每个单独视频的测试时间优化来估计全局运动,而所有其他方法都以前馈方式估计局部运动。我们的方法显著提高了输入对应的质量,在所有测试的方法中实现了最佳的位置精度、遮挡精度和时间一致性。
6.4. 消融和分析
消融。我们在表2中进行消融以验证我们设计决策的有效性。No invertible是一种模型变体,它取代了我们的可逆映射网络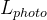
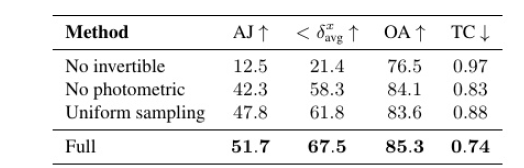
表2:DAVIS的消融性研究[50]
分析。在图4中,我们展示了由我们的模型生成的伪深度图,以演示学习到的深度排序。请注意,这些图不对应于物理深度,尽管如此,它们证明了仅使用光度和流量信号,我们的方法能够对相对深度进行排序不同表面之间的排序,这对于通过遮挡进行跟踪至关重要。补充材料中提供了更多的消融和分析。

图4:从我们的表示中提取的伪深度图,其中蓝色表示更近的物体,红色表示更远。
7. 局限性
像许多运动估计方法一样,我们的方法在快速和高度非刚性运动以及薄结构中挣扎。在这些情况下,成对对应方法可能无法为我们的方法提供足够可靠的对应来计算准确的全局运动。
此外,由于底层优化问题的高度非凸性,我们观察到我们的优化过程对某些困难视频的初始化可能很敏感。这可能会导致次优的局部最小值,例如,规范空间中不正确的表面排序或重复的对象,有时很难通过优化来纠正。
最后,我们当前形式的方法在计算上可能是昂贵的。首先,流收集过程涉及穷尽地计算所有成对流动,其相对于序列长度呈二次缩放。然而,我们相信这个过程的可扩展性可以通过以下方式得到改善探索穷尽匹配的更有效的替代方案,例如,词汇树或基于关键帧的匹配,从运动和SLAM文献中汲取灵感。其次,像其他利用神经隐式表示的方法[44]一样,我们的方法涉及一个相对较长的优化过程。最近在该领域的研究[45,64]可能有助于加速这一过程,并允许进一步缩放到更长的序列。
8. 结论
我们提出了一种新的测试时间优化方法,用于估计整个视频的完整和全局一致运动。我们引入了一种新的视频运动表示,称为OmniMotion,它包括一个准3d规范体积和每帧局部规范双射。omnimotion可以处理具有不同摄像机设置和场景动态的一般视频,并通过遮挡产生准确而平滑的远程运动。我们的方法在定性和定量上都比以前最先进的方法有了显著的改进。
致谢。我们感谢Jon Barron, Richard Tucker, Vickie Ye,Zekun Hao, Xiaowei Zhou, Steve Seitz, Brian Curless和Richard Szeliski对我们的帮助和帮助。这项工作得到了NVIDIA学术硬件拨款和美国国家科学基金会(IIS-2008313和IIS-2211259)的部分支持。王倩倩得到了Google PhD Fellowship的部分支持。
参考文献
- [1]Sameer Agarwal, Yasutaka Furukawa, Noah Snavely, Ian Simon, Brian Curless, Steven M Seitz, and Richard Szeliski.Building Rome in a day.Communications of the ACM, 54(10):105–112, 2011.
- [2]Vijay Badrinarayanan, Fabio Galasso, and Roberto Cipolla.Label propagation in video sequences.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 3265–3272. IEEE, 2010.
- [3]Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman.mip-NeRF 360: Unbounded anti-aliased neural radiance fields.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 5470–5479, 2022.
- [4]Herbert Bay, Andreas Ess, Tinne Tuytelaars, and Luc Van Gool.Speeded-up robust features (surf).Computer vision and image understanding, 110(3):346–359, 2008.
- [5]Zhangxing Bian, Allan Jabri, Alexei A Efros, and Andrew Owens.Learning pixel trajectories with multiscale contrastive random walks.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 6508–6519, 2022.
- [6]Michael J Black and Padmanabhan Anandan.A framework for the robust estimation of optical flow.In Proc. Int. Conf. on Computer Vision (ICCV), pages 231–236. IEEE, 1993.
- [7]Thomas Brox, Christoph Bregler, and Jitendra Malik.Large displacement optical flow.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 41–48, 2009.
- [8]Thomas Brox and Jitendra Malik.Large displacement optical flow: descriptor matching in variational motion estimation.Trans. Pattern Analysis and Machine Intelligence, 33(3):500–513, 2010.
- [9]Hongrui Cai, Wanquan Feng, Xuetao Feng, Yan Wang, and Juyong Zhang.Neural surface reconstruction of dynamic scenes with monocular rgb-d camera.Advances in Neural Information Processing Systems, 35:967–981, 2022.
- [10]Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin.Emerging properties in self-supervised vision transformers.In Proc. Int. Conf. on Computer Vision (ICCV), pages 9650–9660, 2021.
- [11]Joao Carreira and Andrew Zisserman.Quo vadis, action recognition? a new model and the kinetics dataset.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 6299–6308, 2017.
- [12]Jason Chang, Donglai Wei, and John W Fisher.A video representation using temporal superpixels.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 2051–2058, 2013.
- [13]Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich.Superpoint: Self-supervised interest point detection and description.In Proc. Computer Vision and Pattern Recognition Workshops, pages 224–236, 2018.
- [14]Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio.Density estimation using Real NVP.arXiv preprint arXiv:1605.08803, 2016.
- [15]Carl Doersch, Ankush Gupta, Larisa Markeeva, Adria Recasens Continente, Kucas Smaira, Yusuf Aytar, Joao Carreira, Andrew Zisserman, and Yi Yang.Tap-vid: A benchmark for tracking any point in a video.In NeurIPS Datasets Track, 2022.
- [16]Carl Doersch, Yi Yang, Mel Vecerik, Dilara Gokay, Ankush Gupta, Yusuf Aytar, Joao Carreira, and Andrew Zisserman.Tapir: Tracking any point with per-frame initialization and temporal refinement.arXiv preprint arXiv:2306.08637, 2023.
- [17]Hugh Durrant-Whyte and Tim Bailey.Simultaneous localization and mapping: part i.IEEE Robotics & Automation Magazine, 13(2):99–110, 2006.
- [18]Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Pollefeys, Josef Sivic, Akihiko Torii, and Torsten Sattler.D2-net: A trainable cnn for joint description and detection of local features.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 8092–8101, 2019.
- [19]Rizal Fathony, Anit Kumar Sahu, Devin Willmott, and J Zico Kolter.Multiplicative filter networks.In International Conference on Learning Representations, 2021.
- [20]Philipp Fischer, Alexey Dosovitskiy, Eddy Ilg, Philip Häusser, Caner Hazırbaş, Vladimir Golkov, Patrick Van der Smagt, Daniel Cremers, and Thomas Brox.Flownet: Learning optical flow with convolutional networks.arXiv preprint arXiv:1504.06852, 2015.
- [21]Hang Gao, Ruilong Li, Shubham Tulsiani, Bryan Russell, and Angjoo Kanazawa.Monocular dynamic view synthesis: A reality check.In Neural Information Processing Systems, 2022.
- [22]Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, et al.Kubric: A scalable dataset generator.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 3749–3761, 2022.
- [23]Adam W Harley, Zhaoyuan Fang, and Katerina Fragkiadaki.Particle video revisited: Tracking through occlusions using point trajectories.In Proc. European Conf. on Computer Vision (ECCV), pages 59–75. Springer, 2022.
- [24]Berthold KP Horn and Brian G Schunck.Determining optical flow.Artificial intelligence, 17(1-3):185–203, 1981.
- [25]Tak-Wai Hui, Xiaoou Tang, and Chen Change Loy.Liteflownet: A lightweight convolutional neural network for optical flow estimation.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 8981–8989, 2018.
- [26]Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, Alexey Dosovitskiy, and Thomas Brox.Flownet 2.0: Evolution of optical flow estimation with deep networks.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 2462–2470, 2017.
- [27]Michal Irani.Multi-frame optical flow estimation using subspace constraints.In Proc. Int. Conf. on Computer Vision (ICCV), volume 1, pages 626–633, 1999.
- [28]Allan Jabri, Andrew Owens, and Alexei Efros.Space-time correspondence as a contrastive random walk.In Neural Information Processing Systems, pages 19545–19560, 2020.
- [29]Joel Janai, Fatma Guney, Anurag Ranjan, Michael Black, and Andreas Geiger.Unsupervised learning of multi-frame optical flow with occlusions.In Proc. European Conf. on Computer Vision (ECCV), pages 690–706, 2018.
- [30]Wei Jiang, Eduard Trulls, Jan Hosang, Andrea Tagliasacchi, and Kwang Moo Yi.Cotr: Correspondence transformer for matching across images.In Proc. Int. Conf. on Computer Vision (ICCV), pages 6207–6217, 2021.
- [31]Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht.Cotracker: It is better to track together.arXiv preprint arXiv:2307.07635, 2023.
- [32]Yoni Kasten, Dolev Ofri, Oliver Wang, and Tali Dekel.Layered neural atlases for consistent video editing.In ACM Trans. Graphics (SIGGRAPH Asia), 2021.
- [33]Diederik P Kingma and Jimmy Ba.Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014.
- [34]Alex X Lee, Coline Manon Devin, Yuxiang Zhou, Thomas Lampe, Konstantinos Bousmalis, Jost Tobias Springenberg, Arunkumar Byravan, Abbas Abdolmaleki, Nimrod Gileadi, David Khosid, et al.Beyond pick-and-place: Tackling robotic stacking of diverse shapes.In Proc. Conference on Robot Learning, 2021.
- [35]Jiahui Lei and Kostas Daniilidis.Cadex: Learning canonical deformation coordinate space for dynamic surface representation via neural homeomorphism.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 6624–6634, 2022.
- [36]José Lezama, Karteek Alahari, Josef Sivic, and Ivan Laptev.Track to the future: Spatio-temporal video segmentation with long-range motion cues.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 3369–3376. IEEE, 2011.
- [37]Xueting Li, Sifei Liu, Shalini De Mello, Xiaolong Wang, Jan Kautz, and Ming-Hsuan Yang.Joint-task self-supervised learning for temporal correspondence.In Neural Information Processing Systems, 2019.
- [38]Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang.Neural scene flow fields for space-time view synthesis of dynamic scenes.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 6498–6508, 2021.
- [39]Zhengqi Li and Noah Snavely.Megadepth: Learning single-view depth prediction from internet photos.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 2041–2050, 2018.
- [40]Zhengqi Li, Qianqian Wang, Forrester Cole, Richard Tucker, and Noah Snavely.Dynibar: Neural dynamic image-based rendering.In Proc. Computer Vision and Pattern Recognition (CVPR), 2022.
- [41]Ce Liu, Jenny Yuen, and Antonio Torralba.Sift flow: Dense correspondence across scenes and its applications.Trans. Pattern Analysis and Machine Intelligence, 33(5):978–994, 2010.
- [42]David G Lowe.Distinctive image features from scale-invariant keypoints.Int. J. of Computer Vision, 60:91–110, 2004.
- [43]Bruce D Lucas and Takeo Kanade.An iterative image registration technique with an application to stereo vision.In International Joint Conference on Artificial Intelligence, volume 2, pages 674–679, 1981.
- [44]Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng.NeRF: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021.
- [45]Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller.Instant neural graphics primitives with a multiresolution hash encoding.In ACM Trans. Graphics (SIGGRAPH), 2022.
- [46]Michal Neoral, Jonáš Šerỳch, and Jiří Matas.Mft: Long-term tracking of every pixel.arXiv preprint arXiv:2305.12998, 2023.
- [47]Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Steven M Seitz, and Ricardo Martin-Brualla.Nerfies: Deformable neural radiance fields.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 5865–5874, 2021.
- [48]Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin-Brualla, and Steven M. Seitz.HyperNeRF: A higher-dimensional representation for topologically varying neural radiance fields.In ACM Trans. Graphics (SIGGRAPH), 2021.
- [49]Despoina Paschalidou, Angelos Katharopoulos, Andreas Geiger, and Sanja Fidler.Neural parts: Learning expressive 3d shape abstractions with invertible neural networks.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 3204–3215, 2021.
- [50]Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool.The 2017 DAVIS challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017.
- [51]René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun.Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020.
- [52]Zhile Ren, Orazio Gallo, Deqing Sun, Ming-Hsuan Yang, Erik B Sudderth, and Jan Kautz.A fusion approach for multi-frame optical flow estimation.In Proc. Winter Conf. on Computer Vision (WACV), pages 2077–2086, 2019.
- [53]Ignacio Rocco, Mircea Cimpoi, Relja Arandjelović, Akihiko Torii, Tomas Pajdla, and Josef Sivic.Neighbourhood consensus networks.In Neural Information Processing Systems, volume 31, 2018.
- [54]Michael Rubinstein, Ce Liu, and William T Freeman.Towards longer long-range motion trajectories.In Proc. British Machine Vision Conf. (BMVC), 2012.
- [55]Peter Sand and Seth Teller.Particle video: Long-range motion estimation using point trajectories.Int. J. of Computer Vision, 80:72–91, 2008.
- [56]Johannes L Schonberger and Jan-Michael Frahm.Structure-from-motion revisited.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 4104–4113, 2016.
- [57]Jianbo Shi et al.Good features to track.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 593–600. IEEE, 1994.
- [58]Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein.Implicit neural representations with periodic activation functions.In Neural Information Processing Systems, volume 33, pages 7462–7473, 2020.
- [59]Noah Snavely, Steven M Seitz, and Richard Szeliski.Modeling the world from internet photo collections.Int. J. of Computer Vision, 80:189–210, 2008.
- [60]Deqing Sun, Erik Sudderth, and Michael Black.Layered image motion with explicit occlusions, temporal consistency, and depth ordering.In Neural Information Processing Systems, volume 23, 2010.
- [61]Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz.Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 8934–8943, 2018.
- [62]Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou.Loftr: Detector-free local feature matching with transformers.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 8922–8931, 2021.
- [63]Narayanan Sundaram, Thomas Brox, and Kurt Keutzer.Dense point trajectories by GPU-accelerated large displacement optical flow.In Proc. European Conf. on Computer Vision (ECCV), pages 438–451. Springer, 2010.
- [64]Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P Srinivasan, Jonathan T Barron, and Henrik Kretzschmar.Block-nerf: Scalable large scene neural view synthesis.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 8248–8258, 2022.
- [65]Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng.Fourier features let networks learn high frequency functions in low dimensional domains.In Neural Information Processing Systems, volume 33, pages 7537–7547, 2020.
- [66]Zachary Teed and Jia Deng.Raft: Recurrent all-pairs field transforms for optical flow.In Proc. European Conf. on Computer Vision (ECCV), pages 402–419, 2020.
- [67]Carlo Tomasi and Takeo Kanade.Detection and tracking of point.Int. J. of Computer Vision, 9:137–154, 1991.
- [68]Prune Truong, Martin Danelljan, and Radu Timofte.Glu-net: Global-local universal network for dense flow and correspondences.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 6258–6268, 2020.
- [69]Prune Truong, Martin Danelljan, Luc Van Gool, and Radu Timofte.Learning accurate dense correspondences and when to trust them.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 5714–5724, 2021.
- [70]Sebastian Volz, Andres Bruhn, Levi Valgaerts, and Henning Zimmer.Modeling temporal coherence for optical flow.In Proc. Int. Conf. on Computer Vision (ICCV), pages 1116–1123. IEEE, 2011.
- [71]Carl Vondrick, Abhinav Shrivastava, Alireza Fathi, Sergio Guadarrama, and Kevin Murphy.Tracking emerges by colorizing videos.In Proc. European Conf. on Computer Vision (ECCV), pages 391–408, 2018.
- [72]John YA Wang and Edward H Adelson.Layered representation for motion analysis.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 361–366, 1993.
- [73]Qianqian Wang, Xiaowei Zhou, Bharath Hariharan, and Noah Snavely.Learning feature descriptors using camera pose supervision.In Proc. European Conf. on Computer Vision (ECCV), pages 757–774, 2020.
- [74]Xiaolong Wang, Allan Jabri, and Alexei A Efros.Learning correspondence from the cycle-consistency of time.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 2566–2576, 2019.
- [75]Philippe Weinzaepfel, Jerome Revaud, Zaid Harchaoui, and Cordelia Schmid.DeepFlow: Large displacement optical flow with deep matching.In Proc. Int. Conf. on Computer Vision (ICCV), pages 1385–1392, 2013.
- [76]Yuefan Wu, Zeyuan Chen, Shaowei Liu, Zhongzheng Ren, and Shenlong Wang.Casa: Category-agnostic skeletal animal reconstruction.Advances in Neural Information Processing Systems, 35:28559–28574, 2022.
- [77]Wenqi Xian, Jia-Bin Huang, Johannes Kopf, and Changil Kim.Space-time neural irradiance fields for free-viewpoint video.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 9421–9431, 2021.
- [78]Jiarui Xu and Xiaolong Wang.Rethinking self-supervised correspondence learning: A video frame-level similarity perspective.In Proc. Int. Conf. on Computer Vision (ICCV), pages 10075–10085, 2021.
- [79]Gengshan Yang, Deqing Sun, Varun Jampani, Daniel Vlasic, Forrester Cole, Huiwen Chang, Deva Ramanan, William T Freeman, and Ce Liu.Lasr: Learning articulated shape reconstruction from a monocular video.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15980–15989, 2021.
- [80]Gengshan Yang, Deqing Sun, Varun Jampani, Daniel Vlasic, Forrester Cole, Ce Liu, and Deva Ramanan.Viser: Video-specific surface embeddings for articulated 3d shape reconstruction.Advances in Neural Information Processing Systems, 34:19326–19338, 2021.
- [81]Vickie Ye, Zhengqi Li, Richard Tucker, Angjoo Kanazawa, and Noah Snavely.Deformable sprites for unsupervised video decomposition.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 2657–2666, 2022.
- [82]Wang Zhao, Shaohui Liu, Hengkai Guo, Wenping Wang, and Yong-Jin Liu.ParticleSfM: Exploiting dense point trajectories for localizing moving cameras in the wild.In Proc. European Conf. on Computer Vision (ECCV), pages 523–542, 2022.
- [83]Tinghui Zhou, Philipp Krahenbuhl, Mathieu Aubry, Qixing Huang, and Alexei A Efros.Learning dense correspondence via 3d-guided cycle consistency.In Proc. Computer Vision and Pattern Recognition (CVPR), pages 117–126, 2016.