目录
一、前言
图像操作其实就是对像素进行操作,这些操作不仅仅是像前面那些基础操作一样简单,只有获取值啊,简单赋值啊之类的。但是像素操作可不止有这么简单。
从今天这节内容开始,我们来一起聊一些更高级的像素操作,我们会讲一些原理,并讲解对应的API,通过实战让大家能够对内容有更深刻的认识。
二、温故知新——像素基本操作
前面我们讲了几个像素基本操作:
获取像素指针:用于后续读取某像素的信息及修改像素。通过像素指针来访问像素。
控制像素范围:将求得的像素值规范到0-255之间。
读写像素,利用像素指针获取像素值及修改像素值。
1、获取像素指针
获取像素指针是可以获得一个指向像素的指针,我们可以使用指针来访问像素值,修改像素值。包括获取灰度图像像素指针和彩色图像像素指针。
获取方式如下:
//灰度图像
src_gray.at<uchar>(y, x); //行在前,列在后,y表示行,x表示列
src_gray.at<uchar>(Point(x, y));
//彩色图像
Vec3b BGR = src.at<Vec3b>(row, col);
int B = BGR.val[0];
int G = BGR.val[1];
int R = BGR.val[2];
Scalar BGR1 = src.at<Vec3b>(Point(col, row));
2、像素范围处理
像素范围处理功能会将所有的输入值都控制在0-255之间,小于0的返回0,大于255的返回255,其他不变。具体API如下:
saturate_cast<uchar>(number);3、读写像素
读写像素是最基本的像素操作,一个是用于获取像素值,一个是用于修改某个位置的像素值,上面获取像素指针的代码同时也读取了像素,写像素代码如下:
//灰度图像
image.at<uchar>(y, x) = 123;
//彩色图像
image.at<Vec3b>(y,x)[0]=0; // blue
image.at<Vec3b>(y,x)[1]=0; // green
image.at<Vec3b>(y,x)[2]=255; // red
三、图像掩膜操作
1、怎么理解掩膜Mask
首先我们先来看一下定义:
掩膜操作是指根据掩膜矩阵(也称作核kernel)重新计算图像中每个像素的值。
我们举个例子来说明一下,然后我们再来解释:

比如上面的这个图中,我们左边是图像,右边是我们的掩膜矩阵,定义说,我们要根据掩膜矩阵重新计算图像中每个像素的值。计算方式如下:
从左边图中找到黄色背景区域(从原图中找到和掩膜矩阵大小相同的区域),对应位置相乘,然后求和:
5 * 0 + 5 * (-1) + 5 * 0 + 5 * (-1) + 5 * 5 + 5 * (-1) + 5 * 0 + 5 * (-1) + 5 * 0 = 5
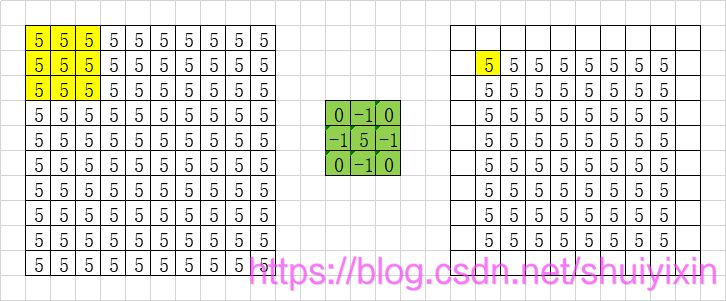
通过计算,我们就会得到右面的图像,左边的3×3的像素,经过计算,会得到右边1×1的像素。然后,我们计算
然后,我们计算下一个像素点,也就是左边的区域往后移动一个区域,一直到最后一个区域结束:
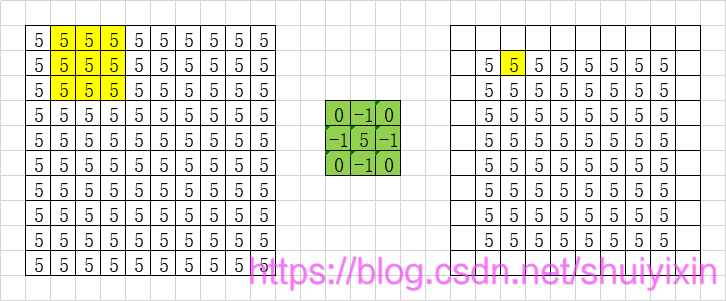
我们会发现,计算过后,图像变小了(最外面有一圈没有计算)。这个问题,我们先留在这里,以后再说。
由于图像所有都是5,五个中心减去四个相邻,最后结果还是5,所以上面这个经过掩膜操作并没有什么太明显的变化。
如果换个矩阵就不一样啦:
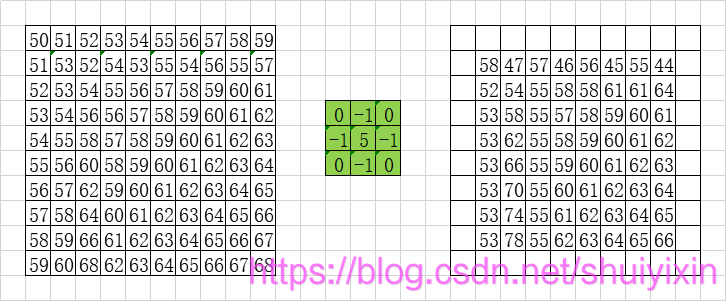
通过上面的介绍,我想,我们可以对掩膜有个更加深刻的了解了,掩膜可以通过邻近像素来修改自身像素值。
2、掩膜实现
了解了具体的原理,我们接下来通过代码来自己实现一下掩膜操作吧!
核心代码就是使用掩膜中心位置的值的五倍,减去上下左右四个位置的值:
for (int i = 1; i < src_gray.rows-1; i++)
{
for (int j = 1; j < src_gray.cols-1; j++)
{
src_new.at<uchar>(i, j) =
src_gray.at<uchar>(i, j) * 5 - //中心
src_gray.at<uchar>(i - 1, j) - //上
src_gray.at<uchar>(i + 1, j) - //下
src_gray.at<uchar>(i, j - 1) - //左
src_gray.at<uchar>(i, j + 1); //右
}
}全部代码如下:
#include<iostream>
#include<opencv2\opencv.hpp>
using namespace std;
using namespace cv;
int main() {
Mat src = imread("./image/sign.png");
if (!src.data)
{
cout << "ERROR : could not load image.\n";
return -1;
}
Mat src_gray;
cvtColor(src, src_gray, COLOR_BGR2GRAY);
imshow("src_gray", src_gray);
Mat src_new = Mat(Size(src_gray.cols,src_gray.rows),CV_8UC1);
for (int i = 1; i < src_gray.rows-1; i++)
{
for (int j = 1; j < src_gray.cols-1; j++)
{
src_new.at<uchar>(i, j) =
src_gray.at<uchar>(i, j) * 5 - //中心
src_gray.at<uchar>(i - 1, j) - //上
src_gray.at<uchar>(i + 1, j) - //下
src_gray.at<uchar>(i, j - 1) - //左
src_gray.at<uchar>(i, j + 1); //右
}
}
imshow("new src_gray", src_new);
waitKey(0);
return 0;
}执行结果如下:


大家就能发现,图像中文字边界的位置的发生了明显变化。
3、API-filter2D
我们自己实现了我们的掩膜操作,在opencv中,我们提供了专门的API来实现掩膜操作:
void filter2D(
InputArray src,
OutputArray dst,
int ddepth,
InputArray kernel,
Point anchor = Point(-1,-1),
double delta = 0,
int borderType = BORDER_DEFAULT
);函数参数含义如下:
(1)InputArray类型的src ,输入图像。
(2)OutputArray类型的dst ,输出图像,图像的大小、通道数和输入图像相同。
(3)int类型的ddepth,目标图像的所需深度。
(4)InputArray类型的kernel,卷积核(或者更确切地说是相关核)是一种单通道浮点矩阵;如果要将不同的核应用于不同的通道,请使用split将图像分割成不同的颜色平面,并分别对其进行处理。。
(5)Point类型的anchor,表示锚点(即被平滑的那个点),注意他有默认值Point(-1,-1)。如果这个点坐标是负值的话,就表示取核的中心为锚点,所以默认值Point(-1,-1)表示这个锚点在核的中心。。
(6)double类型的delta,在将筛选的像素存储到dst中之前添加到这些像素的可选值。
(7)int类型的borderType,用于推断图像外部像素的某种边界模式。有默认值BORDER_DEFAULT。
在一般使用中,我们只涉及到前面四个参数,
对于第五个参数,我们都是默认中心为锚点,
对于第六个参数,一般来说我们很少会设置一个额外的值去调整像素值,所以也是默认为0的。
对于第七个参数,因为是刚开始,我们先不展开说明,因为后续我们还会讲到,在这里,我们先采用默认,让我们把重心放在前四个参数上面。
如下面这个例子:
filter2D( src, dst, src.depth(), kernel );我们来使用一个完整的例子来说明一下:
执行结果如下:


我们能够发现,我们的文字出现了白色的边界。
如果我们再调整一下kernel,我们就可以得到很多类型的图像:

大家也可以自己尝试设置自己的kernel,一般来说有个原则就是尽量核所有数值加起来不要太大。一般都是让求得的值为1。
四、执行时间
我们留意到一个比较重要的内容,就是我们操作像素,是要遍历所有像素的,这是很耗时间的操作。特别是了解深度学习的同学,当做深度学习图像检测要遍历图像做训练时,运算量是极大的,所以我们需要获取执行时间,来分析算法的优劣,进行算法效率比较。
在opencv中,我们提供了专门的API来获取执行时间,全部功能代码如下:
double t = (double)getTickCount();
// do something ...
t = ((double)getTickCount() - t) / getTickFrequency();
cout << "消耗的时间为: " << t << endl;这其中涉及到两个API:
getTickCount();
getTickFrequency();第一个是:函数返回特定事件(例如,当机器打开时)后的刻度数。它可用于初始化RNG或通过读取函数调用前后的计时计数来测量函数执行时间。
第二个是:函数返回每秒的刻度数。
我们通过第一个执行得到运行前和运行后的刻度数,相减后得到运行过程中的刻度时长,然后除以每秒的刻度数,就能得到代码以秒为单位的运行时长了。
举个例子:
double t = (double)getTickCount();
// do something ...
Mat src_new;
Mat kernel = (Mat_<char>(3, 3) << 1, -4, 1, -1, 7, -1, 1, -4, 1);
filter2D(src, src_new, src.depth(), kernel);
imshow("src_new: 1, -4, 1, -1, 7, -1, 1, -4, 1", src_new);
t = ((double)getTickCount() - t) / getTickFrequency();
cout << "消耗的时间为: " << t << endl;执行结果如下:
到这里我们就说完啦,大家多做练习哦!