RDD分区
在分布式程序中,通信的代价是很大的,因此控制数据分布以获得最少的网络传输可以极大地提升整体性能。所以对RDD进行分区的目的就是减少网络传输的代价以提高系统的性能。
RDD的特性
在讲RDD分区之前,先说一下RDD的特性。
RDD,全称为Resilient Distributed Datasets,是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来操作这些数据。在这些操作中,诸如map、flatMap、filter等转换操作实现了monad模式,很好地契合了Scala的集合操作。除此之外,RDD还提供了诸如join、groupBy、reduceByKey等更为方便的操作(注意,reduceByKey是action,而非transformation),以支持常见的数据运算。
通常来讲,针对数据处理有几种常见模型,包括:Iterative Algorithms,Relational Queries,MapReduce,Stream Processing。例如Hadoop MapReduce采用了MapReduces模型,Storm则采用了Stream Processing模型。RDD混合了这四种模型,使得Spark可以应用于各种大数据处理场景。
RDD作为数据结构,本质上是一个只读的分区记录集合。一个RDD可以包含多个分区,每个分区就是一个dataset片段。RDD可以相互依赖。如果RDD的每个分区最多只能被一个Child RDD的一个分区使用,则称之为narrow dependency;若多个Child RDD分区都可以依赖,则称之为wide dependency。不同的操作依据其特性,可能会产生不同的依赖。例如map操作会产生narrow dependency,而join操作则产生wide dependency。
Spark之所以将依赖分为narrow与wide,基于两点原因。
首先,narrow dependencies可以支持在同一个cluster node上以管道形式执行多条命令,例如在执行了map后,紧接着执行filter。相反,wide dependencies需要所有的父分区都是可用的,可能还需要调用类似MapReduce之类的操作进行跨节点传递。
其次,则是从失败恢复的角度考虑。narrow dependencies的失败恢复更有效,因为它只需要重新计算丢失的parent partition即可,而且可以并行地在不同节点进行重计算。而wide dependencies牵涉到RDD各级的多个Parent Partitions。下图说明了narrow dependencies与wide dependencies之间的区别:
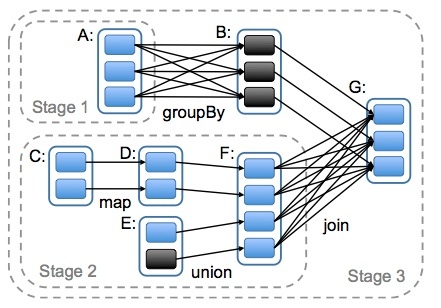
pic-1
本图来自Matei Zaharia撰写的论文An Architecture for Fast and General Data Processing on Large Clusters。图中,一个box代表一个RDD,一个带阴影的矩形框代表一个partition。
另外给一张join的操作过程图片:
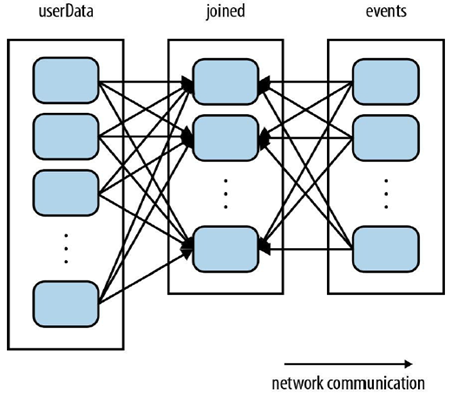
pic-2
RDD分区
我们分析这样一个应用,它在内存中保存着一张很大的用户信息表(UserData)——也就是一个由(UserId, UserInfo)对组成的RDD,其中UserInfo包含一个该用户所订阅的主题列表。该应用会周期性性地将这张表与一个小文件进行组合,这个小文件中存着过去五分钟内发生的事件(events)——其实就是一个由(UserID, LinkInfo)对组成的表。如果我们要进行对用户访问情况的统计,就需要对这两个表进行join操作,以获得(UserID,UserInfo,LinkInfo)信息。
如图pic-2默认情况下,join操作会将两个数据集中的所有的键的哈希值都求出来,将哈希值相同的记录传送到同一台机器上,之后在该机器上对所有键相同的记录进行join操作。
所以这种情况之下,每次进行join都会有数据混洗的问题。造成了很大的网络传输开销。
这种情况之下由于UserData表比events表要大得多,所以选择将UserData进行分区。如果对UserData进行分区,之后Spark就会知晓该RDD是根据键的哈希值来分区的,这样在调用join()时,Spark就会利用这一点。当调用UserData.join(events)时,Spark只会对events进行数据混洗操作,将events中特定的UserID的记录发送到userData的对应分区所在的那台机器上。如下图:
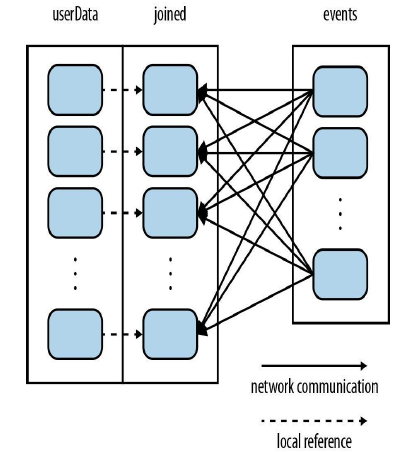
pic-3
自定义分区
我们都知道Spark内部提供了HashPartitioner和RangePartitioner两种分区策略,这两种分区策略在很多情况下都适合我们的场景。但是有些情况下,Spark内部不能符合咱们的需求,这时候我们就可以自定义分区策略。为此,Spark提供了相应的接口,我们只需要扩展Partitioner抽象类,然后实现里面的三个方法:
package org.apache.spark
/**
* An object that defines how the elements in a key-value pair RDD are partitioned by key.
* Maps each key to a partition ID, from 0 to `numPartitions - 1`.
*/
abstract class Partitioner extends Serializable {
def numPartitions: Int
def getPartition(key: Any): Int
def equals(other: Any): Boolean
} def numPartitions: Int:这个方法需要返回你想要创建分区的个数;
def getPartition(key: Any): Int:这个函数需要对输入的key做计算,然后返回该key的分区ID,范围一定是0到numPartitions-1;
equals():这个是Java标准的判断相等的函数,之所以要求用户实现这个函数是因为Spark内部会比较两个RDD的分区是否一样。
假如我们想把来自同一个域名的URL放到一台节点上,比如:http://www.csdn.net和http://www.csdn.net/bolg/,如果你使用HashPartitioner,这两个URL的Hash值可能不一样,这就使得这两个URL被放到不同的节点上。所以这种情况下我们就需要自定义我们的分区策略,可以如下实现:
class IteblogPartitioner(numParts: Int) extends Partitioner {
override def numPartitions: Int = numParts
override def getPartition(key: Any): Int = {
val domain = new java.net.URL(key.toString).getHost()
val code = (domain.hashCode % numPartitions)
if (code < 0) {
code + numPartitions
} else {
code
}
}
override def equals(other: Any): Boolean = other match {
case iteblog: IteblogPartitioner =>
iteblog.numPartitions == numPartitions
case _ =>
false
}
override def hashCode: Int = numPartitions
}因为hashCode值可能为负数,所以我们需要对他进行处理。然后我们就可以在partitionBy()方法里面使用我们的分区:
iteblog.partitionBy(new IteblogPartitioner(20))类似的,在Java中定义自己的分区策略和Scala类似,只需要继承org.apache.spark.Partitioner,并实现其中的方法即可。
在Python中,你不需要扩展Partitioner类,我们只需要对iteblog.partitionBy()加上一个额外的hash函数,如下:
import urlparse
def iteblog_domain(url):
return hash(urlparse.urlparse(url).netloc)
iteblog.partitionBy(20, iteblog_domain)