项目简介
飞桨图像分类套件PaddleClas是飞桨为工业界和学术界所准备的一个图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。本文将对套件的代码进行全面解析,帮助开发者了解其结构组成和运行机制,并通过实际案例,详细解读PaddleClas的运行流程,助力开发者全面、深度、高效地使用套件开发项目。
一、PaddleClas套件的整体文件布局解析
PaddleClas 的主要文件布局整理如下图:
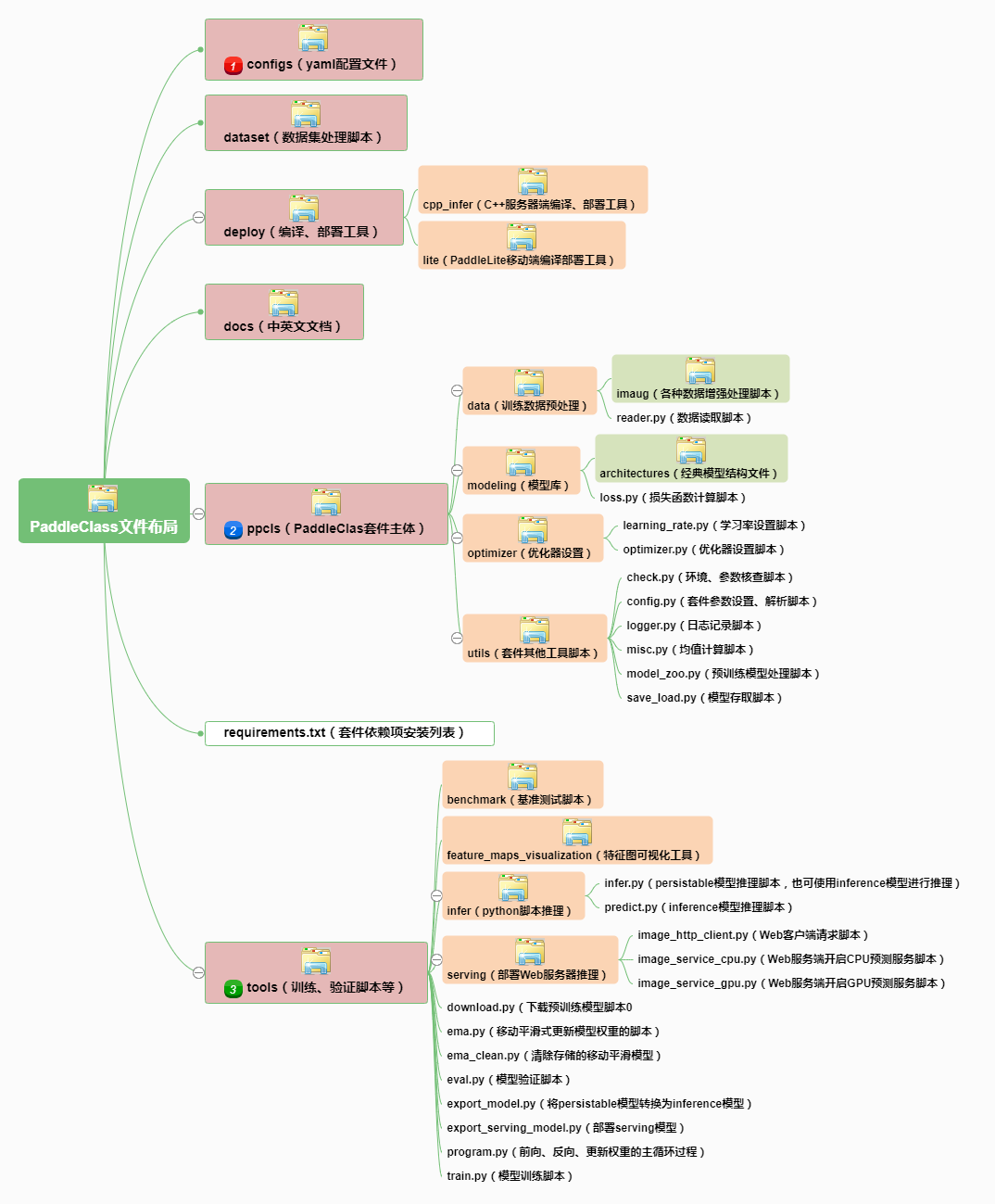
- configs 文件夹下存放训练脚本和验证脚本的yaml配置文件,文件按模型类别存放,quick_start文件夹下存放的是 demo 脚本。
- dataset 文件夹下存放预处理训练数据的脚本,负责将数据集处理为适合Dataloader处理的格式。
- docs 文件夹下存放中英文文档。
- deploy 文件夹存放的是编译、部署工具,有 Paddle Serveing 和 Paddle Lite 两种部署方式。
- ppcls 文件夹下存放PaddleClas框架主体。模型结构脚本、数据增强脚本、优化脚本等DL程序的标准流程代码都在这里。
- tools 文件夹下存放用于模型下载、训练、预测和部署的脚本。
- requirements.txt 文件用于安装 PaddleClas 的依赖项。使用pip进行升级安装使用。
其中 configs、ppcls、tools 三个文件夹最为关键,我们分别重点介绍:
1.configs文件夹
configs 文件夹下按模型类别分别存放了 yaml 初始化文件,用于设置超参。框架为各种模型各个型号都预设了适合的超参,真是贴心。当然,使用时还是要根据自己项目实际情况对超参进行调整。比如归一化训练集数据的超参 mean、std 就需要根据自己的数据集重新计算。
2.ppcls文件夹
- data 文件夹存下放处理数据的脚本,包括模型读取数据的 reader 和数据增广处理脚本。
- modeling 文件夹下存放模型结构及 loss 计算脚本。
- optimizer 文件夹下存放优化器超参(包括优化器种类,正则化项设置)和学习率设置脚本(包括学习率 warmup 和各种 decay 策略)。
- utils 文件夹下存放其他功能脚本(包括脚本参数解析、参数检查、模型存取、日志记录脚本)
3.tools文件夹
- download.py 是下载预训练模型的脚本。
- train.py 和eval.py 是训练和验证模型的脚本。
- ema.py 和ema_clean.py 是计算和清除指数移动均值的脚本,用于提升训练效果。
- export_model.py 和 export_serving_model.py 是转换和部署模型的脚本。
- infer 文件夹下放的是用于(persistable 模型)预测、(inference 模型)推理的脚本。
- program.py 是组装训练过程的脚本。train 过程由此脚本组装好后运行。
PaddleClas 的源码风格清晰、工整,非常好读。在对套件的整体结构有了一定的了解后,我们下面来了解它的工作流程。
二、PaddleClas 套件的训练流程代码解析
1.执行训练脚本
下面的代码启动模型训练过程:
# 进入PaddleClas工作目录
%cd /home/aistudio/PaddleClas/
# 加入系统环境目录
%env PYTHONPATH = .:$PYTHONPATH
# 设定执行GPU硬件
%env CUDA_VISIBLE_DEVICES = 0
# 运行训练脚本(并行)
!python -m paddle.distributed.launch \
--selected_gpus="0" \
tools/train.py \
-c ./configs/quick_start/ResNet50_vd.yaml
# 运行训练脚本(单进程)
!python tools/train.py \
-c ./configs/quick_start/ResNet50_vd.yaml
上面的代码同时给出了单进程和并行执行训练脚本的代码。如果具备分布式训练条件,通过 paddle.distributed.launch 并行运行训练过程可提高训练效率。
-c 参数指定训练过程读取的 yaml 参数设置文件,也可通过 -o 参数手动设置参数。-o 设置的参数优先级更高会覆盖 yaml 文件中的参数设置。
2.训练流程解析
训练流程从 tools/train.py 脚本的 main()函数开始执行。
def main(args):
#【*】设置全局默认generator的随机种子
paddle.seed(12345)
#【*】读取全局设置
config = get_config(args.config, overrides=args.override, show=True)
#【*】设置脚本运行在GPU还是CPU上
# assign the place
use_gpu = config.get("use_gpu", True)
place = 'gpu:{}'.format(ParallelEnv().dev_id) if use_gpu else 'cpu'
place = paddle.set_device(place)
#【*】设定训练过程是否启用并行方式
trainer_num = int(os.getenv("PADDLE_TRAINERS_NUM", 1))
use_data_parallel = trainer_num != 1
config["use_data_parallel"] = use_data_parallel
if config["use_data_parallel"]:
strategy = paddle.distributed.init_parallel_env()
#【*】定义模型对象
net = program.create_model(config.ARCHITECTURE, config.classes_num)
#【*】定义优化器和学习率策略
optimizer, lr_scheduler = program.create_optimizer(
config, parameter_list=net.parameters())
#【*】如设置了并行模式,则置模型并行训练
if config["use_data_parallel"]:
net = paddle.DataParallel(net, strategy)
#【*】读取预训练模型或自己存储的模型
# load model from checkpoint or pretrained model
init_model(config, net, optimizer)
#【*】定义训练集数据读取器
train_dataloader = Reader(config, 'train', places=place)()
#【*】如果设定了启用验证过程,则在主进程中执行验证过程
if config.validate and ParallelEnv().local_rank == 0:
valid_dataloader = Reader(config, 'valid', places=place)()
#【*】初始化epoch轮数和top准确率
last_epoch_id = config.get("last_epoch", -1)
best_top1_acc = 0.0 # best top1 acc record
best_top1_epoch = last_epoch_id
#【*】训练过程循环
for epoch_id in range(last_epoch_id + 1, config.epochs):
#【*】设置模型运行在训练模式下。
net.train()
#【*】调用program.py脚本的run()函数执行模型训练过程
# 1. train with train dataset
program.run(train_dataloader, config, net, optimizer, lr_scheduler,
epoch_id, 'train')
#【*】如果启用了验证过程,则在主进程中执行验证过程
if not config["use_data_parallel"] or ParallelEnv().local_rank == 0:
#【*】执行模型验证过程并打印、保存模型loss、准确率等信息
# 2. validate with validate dataset
if config.validate and epoch_id % config.valid_interval == 0:
#【*】设置模型运行在测试模式下,BN、DropOut等做不同处理。
net.eval()
#【*】执行验证过程前向计算并返回top准确率
top1_acc = program.run(valid_dataloader, config, net, None,
None, epoch_id, 'valid')
#【*】记录top准确率
if top1_acc > best_top1_acc:
best_top1_acc = top1_acc
best_top1_epoch = epoch_id
if epoch_id % config.save_interval == 0:
model_path = os.path.join(config.model_save_dir,
config.ARCHITECTURE["name"])
save_model(net, optimizer, model_path, "best_model")
#【*】打印top准确率
message = "The best top1 acc {:.5f}, in epoch: {:d}".format(
best_top1_acc, best_top1_epoch)
#【*】记录日志
logger.info("{:s}".format(logger.coloring(message, "RED")))
#【*】定期存储模型
# 3. save the persistable model
if epoch_id % config.save_interval == 0:
model_path = os.path.join(config.model_save_dir,
config.ARCHITECTURE["name"])
save_model(net, optimizer, model_path, epoch_id)
PaddleClas 的训练过程和所有分类模型训练过程一样,是一种格式化的“八股文”结构,都遵循“数据处理、定义模型、定义优化器、训练模型、存储模型”等固定步骤。PaddleClas 套件将这些步骤按功能封装在了一些函数和类中,分别存放到了以下7个脚本和1个配置文件中:
- <ppcls/utils/config.py>
- <configs/quick_start/ResNet50_vd.yaml>(yaml配置文件)
- <tools/program.py>
- <ppcls/modeling/architechtures/resnet_vd.py>
- <ppcls/optimizer/learning_rate.py>
- <ppcls/utils/save_load.py>
- <ppcls/data/reader.py>
- <ppcls/modeling/loss.py>
下图梳理了训练过程的“八股结构”和各脚本文件之间的调用关系(同一文件用相同颜色标注):
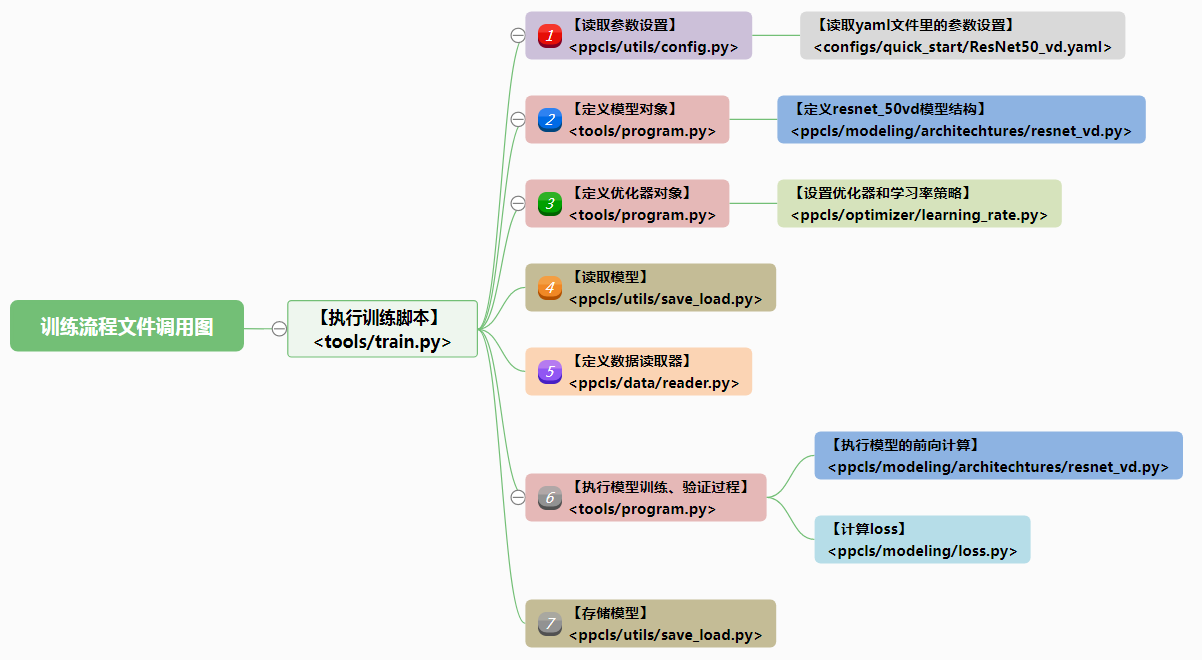
从上图我们了解到,训练过程大致有【读取参数设置】、【定义模型对象】、【定义优化器对象】、【读取模型】 、【定义数据读取器】、【执行模型训练、验证过程】、【存储模型】7个标准步骤(已标注了彩色序号)。下面我们就将这些文件展开,看看训练过程中所有函数和类的调用关系(和上图一样同一文件里的函数和类用相同颜色标注)。整个调用图是一个树状结构。执行各个函数或类方法的顺序就是这颗“调用关系树”从根节点(train.py 脚本的 main()函数)出发,执行深度优先遍历的顺序。同一个节点的子节点按从上到下的顺序遍历。先遍历父节点,后遍历子节点。
整个流程的主要的函数调用关系总结如下图:
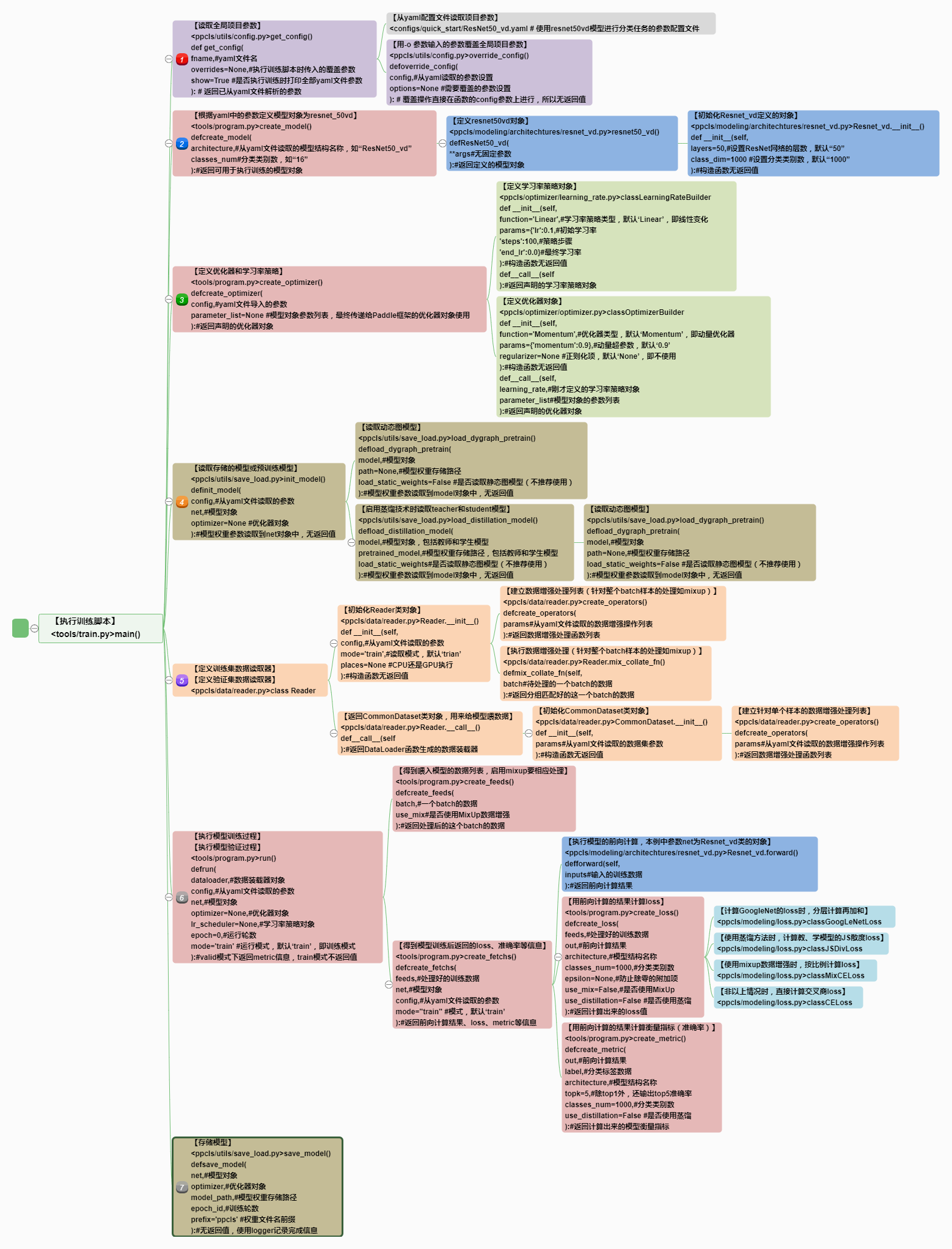
整个训练过程的函数调用流程比较繁杂。我们分而治之,按照前面介绍的训练步骤的“八股结构”,逐个介绍 train()函数中各个步骤的“分枝”。
1)【读取模型训练、验证时的参数设置】

#【*】读取全局设置
config = get_config(args.config, overrides=args.override, show=True)
上面代码调用了 ppcls/utils/config.py 脚本下的 get_config() 函数来完成读取 yaml 文件参数和手工覆盖参数。实际上 get_config() 函数里的功能也进行了高度结构化的函数封装,详细的函数调用图是这样的:

只是,这些参数读取的代码本身与深度学习知识关系不大,很容易读,为了突出重点就没有在总的函数调用关系图中体现。
在调用 train.py 脚本进行训练时,我们用“-c ./configs/quick_start/ResNet50_vd.yaml”参数指定参数配置文件。本步骤就要读取 -c 参数指定的 yaml 文件中的参数配置信息。yaml 文件主要由“模型选择、设置”、“学习率”、“优化器”、“训练过程参数”和“验证过程参数”五个主要部分组成。
mode: 'train' # 当前所处的模式,支持训练与评估模式
ARCHITECTURE: # 【模型结构设置】
name: 'ResNet50_vd' # 指定使用分类模型的结构、配置,本例采用ResNet模型结构,50层的配置
checkpoints: "" # 载入上次保存的模型,不读取设为空值
pretrained_model: "" # 设定载入的预训练模型,不读取设为空值
load_static_weights: False # 读取静态图模型,只是兼容考虑,不推荐使用
model_save_dir: "./output/" # 模型保存目录
classes_num: 102 # 分类类别数
total_images: 1020 # 训练集的图像数量,用于设置学习率变换策略等。
save_interval: 1 # 模型保存间隔轮数(epoch数)
validate: True # 是否进行模型验证
valid_interval: 1 # 执行模型验证间隔轮数(epoch数)
epochs: 20 # 训练轮数
topk: 5 # 验证是除了输出top1,还输出top5准确率
image_shape: [3, 224, 224] # 训练集图片尺寸
LEARNING_RATE: #【学习率设置】
function: 'Cosine' # 设置学习率衰减为余弦衰减
params:
lr: 0.0125 # 初始学习率
OPTIMIZER: #【优化器设置】
function: 'Momentum' # 设置优化器为动量优化器 Momentum
params:
momentum: 0.9 # Momentum优化器的动量超参设为 0.9
regularizer:
function: 'L2' # 添加 L2 正则化项
factor: 0.00001 # 设置 L2 正则化项超参为 0.00001
TRAIN: #【训练过程设置】
batch_size: 32 # 训练batch_size大小
num_workers: 0 # 训练集DataLoader数据读取器使用的子进程数量,以并行读取数据。设为0为只有主进程
file_list: "/home/aistudio/data/data60139/train_list.txt" # 训练集图片列表
data_dir: "/home/aistudio/data/data60139/" # 训练集图片目录
shuffle_seed: 0 # 打乱训练数据顺序的随机数种子
transforms: # (图片转换、数据增强设置)
- DecodeImage: # (图片解码设置)
to_rgb: True # 用cv2读取图片时,数据为gbr模式,要将此项设为True
to_np: False # 是否将读取的数据转为numpy格式
channel_first: False # 有时要将读取的[B,H,W,N]格式数据转为Paddle需要的[B,N,H,W]
- ResizeImage:
size: [224, 224] # 改变图片尺寸大小为224×224
- RandFlipImage: # (随机擦除设置)
flip_code: 1 # 随机擦除模式设为第一种
- NormalizeImage: #(图片标准化设置)
scale: 1./255. # 缩放系数
mean: [0.485, 0.456, 0.406] # rgb各通道均值
std: [0.229, 0.224, 0.225] # rgb各通道标准差
order: ''
- ToCHWImage: # 有时要将读取的[B,H,W,N]格式数据转为Paddle需要的[B,N,H,W]
VALID: #【验证过程设置(参考训练过程设置)】可参考上面训练过程参数设置
batch_size: 20
num_workers: 0
file_list: "/home/aistudio/data/data60139/val_list.txt"
data_dir: "/home/aistudio/data/data60139/"
shuffle_seed: 0
transforms:
- DecodeImage:
to_rgb: True
to_np: False
channel_first: False
- ResizeImage:
resize_short: 256
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
完成yaml脚本的解析后,程序会通过 train.py 脚本的 -o 参数传入的设置,以更高的优先级覆盖通过 yaml 文件设定的参数。
这里介绍一个使用技巧:我们知道,在调用train.py脚本时可以用“-o”或“-override”参数覆盖 yaml 文件中的参数设置。格式如下
!python tools/train.py \
-c ./configs/quick_start/ResNet50_vd.yaml \
-o topk=2
上面我们使用“-o topk=2”覆盖了 topk 参数为 2 (yaml 文件中设置为5)。但是,前面介绍 yaml 文件结构时,我们看到 yaml 文件中的参数是“树形”存放的。如何设置子节点(比如 TRAIN 分支下)上的参数呢?ppcls/utils/config.py 脚本的 override_config() 函数的注释中例举了“-o VALID.transforms.1.ResizeImage.resize_short=300”的写法来设置子节点参数。修改前 yaml 文件中 VALID 分支下的 - ResizeImage 分支下的设置是这样的:
- ResizeImage:
size: [224, 224]
修改后相当于改成了这样:
- ResizeImage:
resize_short: 256
size: [224, 224]
注意:设置 -o 参数并不会改变 yaml 文件中的设置,只是在本次训练或预测时覆盖参数。
2)【定义模型对象】

#【*】定义模型对象
net = program.create_model(config.ARCHITECTURE, config.classes_num)
上面代码调用了 tools/program.py 脚本下的 create_model()函数,以定义模型对象 net,用于前向计算。下面看下 create_model() 函数的代码:
def create_model(architecture, classes_num):
"""
Create a model
Args:
architecture(dict): architecture information,
name(such as ResNet50) is needed
image(variable): model input variable
classes_num(int): num of classes
Returns:
out(variable): model output variable
"""
#【*】设定模型结构的名称、规格。本例中模型结构为resnet_vd,规格为50层,所以name赋值为“ResNet50_vd”
name = architecture["name"]
#【*】设定模型除规格外的其他辅助参数。本例中为空值
params = architecture.get("params", {})
#【*】返回定义的模型对象
return architectures.__dict__[name](class_dim=classes_num, **params)
这部分代码的最后一句“return architectures.dict[name](class_dim=classes_num, **params)”中,architectures(注意不是第一行的那个 architecture 参数,那个参数存储的是模型的名称)是 ppcls/modeling 文件夹下的一个包(是一个带 init.py 的文件夹),其通过 init.py 文件导入所有 PaddleClas 继承的模型结构对象。“architectures”通过“dict[name]”列表得到“architectures”中对应的成员类,再通过 “(class_dim=classes_num, **params)”传入的参数将该模型类实例化为对象,最后将模型结构对象返回用于训练。
这部分代码是 PaddleClas 分类套件为了解耦模型结构代码而“展示的技术”~~。PaddleClas 套件并没有将模型结构都写在一个文件里,而是将每种结构(比如 ResNet_vd)写入一个 py 文件,然后使用“all”将该结构的各种配置实例对象(比如"ResNet50_vd", “ResNet101_vd”, “ResNet152_vd”
]等)“暴露出来”,让“architectures”文件夹下的“init.py”文件可以方便的导入。这样做的好处是,日后添加新模型对象更加方便、清晰。
ResNet50
在本代码解析案例中我们采用了著名的 ResNet 模型结构50层的配置。ResNet 通过“跨层连接”的方式,使网络在无法继续通过增加层数来进一步提升性能时,跳过部分层。这样能够大大缓解深层网络中由于梯度爆炸、梯度消失导致的网络退化现象,能够实现成百上千层的网络,大大提升了网络性能。下面我们看看 ResNet 的结构,以及它究竟是如何实现“跨层”连接的。
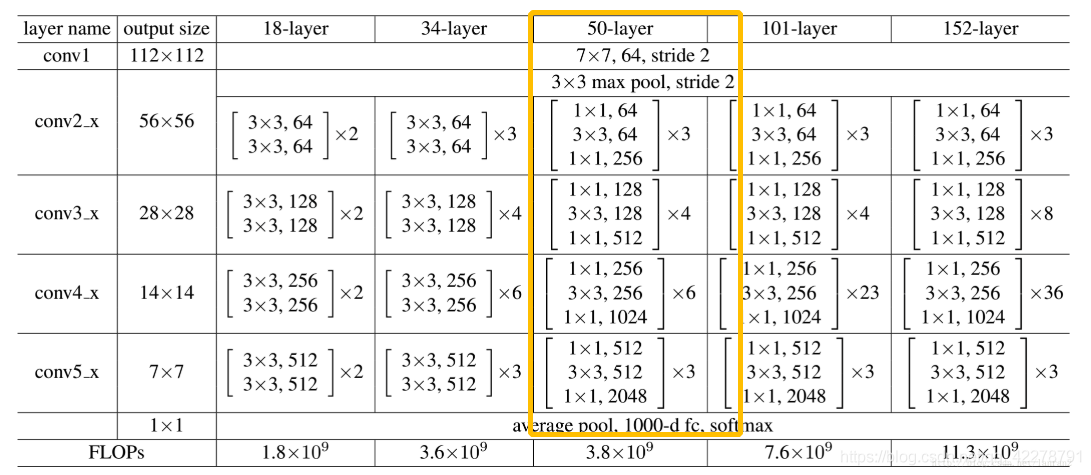
从上面的ResNet结构图我们看到:各种层数配置的 ResNet 网络的“头”、“尾”都是相同的。都是开头先用一个7×7的卷积层提取纹理细节特征,最后接一个 GAP(将特征图降到1×1尺寸)和一个全连接层(对齐输出维度为分类数)。决定“ResNet18、ResNet34、ResNet50、ResNet101、ResNet152”等不同层数配置的是它们各自包括的“残差块”的数量。本项目中,我们分类采用的是 ResNet50 配置,包含A、B、C、D四种残差块的数量分别是3、4、6、3。每个残差块有三个卷积层,所以残差块里一共有(3+4+6+3)×3=48层网络。再加上开头的7×7卷积层和最后的全连接层,整个 ResNet 网络共50层,所以被称为 ResNet50。
下面先看下组成卷积网络的基本 ConvBNLayer 块的定义:
class ConvBNLayer(nn.Layer):
def __init__(self,
num_channels,
num_filters,
filter_size,
stride=1,
groups=1,
act=None,
name=None):
super(ConvBNLayer, self).__init__()
# 定义卷积层
self._conv = Conv2D(
in_channels=num_channels,
out_channels=num_filters,
kernel_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
weight_attr=ParamAttr(name=name + "_weights"),
bias_attr=False)
if name == "conv1":
bn_name = "bn_" + name
else:
bn_name = "bn" + name[3:]
# 定义归一化层
self._batch_norm = BatchNorm(
num_filters,
act=act,
param_attr=ParamAttr(name=bn_name + "_scale"),
bias_attr=ParamAttr(bn_name + "_offset"),
moving_mean_name=bn_name + "_mean",
moving_variance_name=bn_name + "_variance")
def forward(self, inputs):
y = self._conv(inputs)
y = self._batch_norm(y)
return y
上面的 ConvBNLayer 块包含一个卷积层和一个针对 batch 进行的标准化化层,是卷积网络的“基本处理单元”。
下面看看构成 ResNet 网络的基本模块:
# bottle neck 残差块
class BottleneckBlock(nn.Layer):
def __init__(self,
num_channels,
num_filters,
stride,
shortcut=True,
name=None):
super(BottleneckBlock, self).__init__()
# 用于改变通道数的1×1卷积层
self.conv0 = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters,
filter_size=1,
act="relu",
name=name + "_branch2a")
# 用于提取特征的3×3卷积层
self.conv1 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters,
filter_size=3,
stride=stride,
act="relu",
name=name + "_branch2b")
# 用于改变通道数的1×1卷积层
self.conv2 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters * 4,
filter_size=1,
act=None,
name=name + "_branch2c")
# 用于跨层连接时改变通道数的1×1卷积层
if not shortcut:
self.short = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters * 4,
filter_size=1,
stride=stride,
name=name + "_branch1")
self.shortcut = shortcut
self._num_channels_out = num_filters * 4
def forward(self, inputs):
y = self.conv0(inputs)
conv1 = self.conv1(y)
conv2 = self.conv2(conv1)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = paddle.add(x=short, y=conv2)
y = F.relu(y)
return y
就是上面的“bottle neck 残差块”实现了ResNet跨层连接。残差块结构如下图:
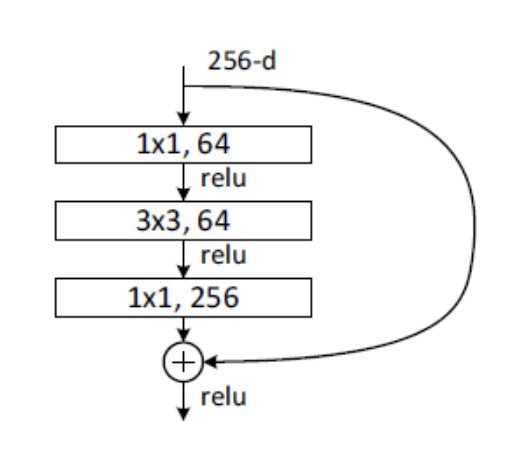
- 在残差块里,提取特征的3×3卷积层的前后各有一个1×1的卷积层,通过这种方式改变卷积层的通道数可以大大降低参数量。
- 在普通的卷积层返回的是卷积计算的结果 F(x) ,而残差卷积层返回的是卷积计算结果 F(x) 与输入的特征图 x 的加和 F(x)+x 。这样做的好处是,在网络进行训练时,如果经过本卷积层并不能提升性能(甚至因为网络退化而降低性能),那么网络就会倾向于通过更新权重参数使F(x)计算结果趋近于0,那么本层的输出就近似是输入的特征图 x , 也就相当于网络计算“跨过了”本层,从而通过跨层连接缓解网络退化现象。
- 需要注意的是,由于bottle neck 残差块需要通过1×1卷积层实现降维,所以它的“short cut”分支也要经过一个1×1的卷积层,而不是直接返回特征图 x 本身。
下面我们看看如何使用上面介绍的“瓶颈残差块”组成大名鼎鼎的 ResNet 网络:
# ResNet网络结构
class ResNet(nn.Layer):
def __init__(self, layers=50, class_dim=1000):
super(ResNet, self).__init__()
self.layers = layers
supported_layers = [18, 34, 50, 101, 152]
assert layers in supported_layers, \
"supported layers are {} but input layer is {}".format(
supported_layers, layers)
# 选择ResNet的配置
if layers == 18:
depth = [2, 2, 2, 2]
elif layers == 34 or layers == 50:
depth = [3, 4, 6, 3]
elif layers == 101:
depth = [3, 4, 23, 3]
elif layers == 152:
depth = [3, 8, 36, 3]
num_channels = [64, 256, 512,
1024] if layers >= 50 else [64, 64, 128, 256]
num_filters = [64, 128, 256, 512]
# 用于提取图片纹理特征的7×7卷积层
self.conv = ConvBNLayer(
num_channels=3,
num_filters=64,
filter_size=7,
stride=2,
act="relu",
name="conv1")
self.pool2d_max = MaxPool2D(kernel_size=3, stride=2, padding=1)
# 根据层数配置添加 bottle net 残差块
self.block_list = []
if layers >= 50:
for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
if layers in [101, 152] and block == 2:
if i == 0:
conv_name = "res" + str(block + 2) + "a"
else:
conv_name = "res" + str(block + 2) + "b" + str(i)
else:
conv_name = "res" + str(block + 2) + chr(97 + i)
bottleneck_block = self.add_sublayer(
conv_name,
BottleneckBlock(
num_channels=num_channels[block]
if i == 0 else num_filters[block] * 4,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
shortcut=shortcut,
name=conv_name))
self.block_list.append(bottleneck_block)
shortcut = True
else:
for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
conv_name = "res" + str(block + 2) + chr(97 + i)
basic_block = self.add_sublayer(
conv_name,
BasicBlock(
num_channels=num_channels[block]
if i == 0 else num_filters[block],
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
shortcut=shortcut,
name=conv_name))
self.block_list.append(basic_block)
shortcut = True
# 进行平均池化
self.pool2d_avg = AdaptiveAvgPool2D(1)
# 计算标准差用于初始化后面的全连接层
self.pool2d_avg_channels = num_channels[-1] * 2
stdv = 1.0 / math.sqrt(self.pool2d_avg_channels * 1.0)
# 最后用于输出分类结果的全连接层
self.out = Linear(
self.pool2d_avg_channels,
class_dim,
weight_attr=ParamAttr(
initializer=Uniform(-stdv, stdv), name="fc_0.w_0"),
bias_attr=ParamAttr(name="fc_0.b_0"))
def forward(self, inputs):
y = self.conv(inputs)
y = self.pool2d_max(y)
for block in self.block_list:
y = block(y)
y = self.pool2d_avg(y)
y = paddle.reshape(y, shape=[-1, self.pool2d_avg_channels])
y = self.out(y)
return y
定义好了模型结构类,下面我们就可以用它来声明模型对象了:
# 定义ResNet50配置的模型对象
def ResNet50(**args):
model = ResNet(layers=50, **args)
return model
上面的函数定义并返回了一个配置为50层的 ResNet 模型对象。然后,我们再用下面的代码“暴露”刚才定义的“模型对象”声明函数:
# 在“__all__”中使定义的模型对象可被其他脚本导入
__all__ = ["ResNet18", "ResNet34", "ResNet50", "ResNet101", "ResNet152"]
代码读到这里,您就了解了:为什么 yaml 文件中 ARCHITECTURE: 下的 name: 可以设置为‘ResNet50_vd’了。当然设置为‘ResNet101’也可以,但设为‘ResNet102’显然就不行了。
3)【定义优化器对象】

#【*】定义优化器和学习率策略
optimizer, lr_scheduler = program.create_optimizer(
config, parameter_list=net.parameters())
上面的代码调用了“program.py”脚本里的“create_optimizer()”函数,并根据传入的参数 config 返回了“optimizer”和“lr_scheduler”对象,用于优化模型。下面看下“create_optimizer()”函数的代码:
def create_optimizer(config, parameter_list=None):
#【*】输入的参数config为读取的yaml文件里的参数设置。
#【*】本函数需要使用yaml文件里“OPTIMIZER”和“LEARNING_RATE”分支下的参数设置。
#【*】本函数返回一个“优化器对象”和一个“学习率策略对象”。
"""
Create an optimizer using config, usually including
learning rate and regularization.
Args:
config(dict): such as
{
'LEARNING_RATE':
{'function': 'Cosine',
'params': {'lr': 0.1}
},
'OPTIMIZER':
{'function': 'Momentum',
'params':{'momentum': 0.9},
'regularizer':
{'function': 'L2', 'factor': 0.0001}
}
}
Returns:
an optimizer instance
"""
#【*】使用yaml文件中“LEARNING_RATE”分支下的参数设置定义一个“学习率策略”对象
# create learning_rate instance
lr_config = config['LEARNING_RATE']
lr_config['params'].update({
'epochs': config['epochs'],
'step_each_epoch':
config['total_images'] // config['TRAIN']['batch_size'],
})
lr = LearningRateBuilder(**lr_config)()
#【*】使用yaml文件中“OPTIMIZER”分支下的参数设置定义一个“优化器”对象
# create optimizer instance
opt_config = config['OPTIMIZER']
opt = OptimizerBuilder(**opt_config)
return opt(lr, parameter_list), lr
create_optimizer() 函数先通过 LearningRateBuilder 类创建一个学习率对象,然后根据这个学习率对象设置的学习率或学习率衰减策略,通过 OptimizerBuilder 类建立一个优化器对象并返回。
LearningRateBuilder 类的代码很简单:
class LearningRateBuilder():
"""
Build learning rate variable
https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/layers_cn.html
Args:
function(str): class name of learning rate
params(dict): parameters used for init the class
"""
# 默认设置了线性学习率衰减策略,从0.1经过100次迭代逐步衰减至0.0
def __init__(self,
function='Linear',
params={'lr': 0.1,
'steps': 100,
'end_lr': 0.0}):
self.function = function
self.params = params
def __call__(self):
# 得到所有加载的模块
mod = sys.modules[__name__]
# 得到设置的学习率策略函数,并传入参数用于定义学习率对象
lr = getattr(mod, self.function)(**self.params)
return lr
LearningRateBuilder 类可以在初始化时通过 function 和 params 参数设置四种优化策略,分别是 Cosine、Piecewise、CosineWarmup 和 ExponentialWarmup,并由定义在 ppcls/optimizer/learning_rate.py 脚本里的四个同名类实现。
OptimizerBuilder 类则采用刚才定义优化策略对象作为参数定义优化器对象,代码如下:
class OptimizerBuilder(object):
"""
Build optimizer
Args:
function(str): optimizer name of learning rate
params(dict): parameters used for init the class
regularizer (dict): parameters used for create regularization
"""
# 默认采用动量优化器,动量超参为0.9,不使用正则化项
def __init__(self,
function='Momentum',
params={'momentum': 0.9},
regularizer=None):
self.function = function
self.params = params
# create regularizer
# -定义正则化项-
if regularizer is not None:
mod = sys.modules[__name__]
reg_func = regularizer['function'] + 'Decay'
del regularizer['function']
reg = getattr(mod, reg_func)(**regularizer)()
self.params['regularization'] = reg
def __call__(self, learning_rate, parameter_list):
# 得到所有加载的模块
mod = sys.modules[__name__]
# 得到优化器对象
opt = getattr(mod, self.function)
# 设置优化器对象的学习率策略、正则化项等参数并返回
return opt(learning_rate=learning_rate,
parameter_list=parameter_list,
**self.params)()
OptimizerBuilder 可以通过 ppcls/optimizer/optimizer.py 脚本中定义的 Momentum 类和 RMSProp 类返回“动量优化器”或 RMSProp 优化器,还可以通过 L1Decay 类和 L2Decay 类向优化器添加正则化项。实际上后面这几个定义优化器和正则化项的类只是给Paddle框架的优化器类和正则化项类“包了一层皮”。我们也可以直接使用 Paddle 框架其他的优化器类,比如 Adam、SGD 等。
4)【读取模型】

#【*】读取预训练模型或自己存储的模型
# load model from checkpoint or pretrained model
init_model(config, net, optimizer)
init_model() 是 ppcls/utils/save_load.py 脚本中的函数,代码如下:
def init_model(config, net, optimizer=None):
"""
load model from checkpoint or pretrained_model
"""
# -读取存储的模型-
checkpoints = config.get('checkpoints')
if checkpoints:
assert os.path.exists(checkpoints + ".pdparams"), \
"Given dir {}.pdparams not exist.".format(checkpoints)
assert os.path.exists(checkpoints + ".pdopt"), \
"Given dir {}.pdopt not exist.".format(checkpoints)
# 读取模型权重参数
para_dict = paddle.load(checkpoints + ".pdparams")
# 读取优化器参数
opti_dict = paddle.load(checkpoints + ".pdopt")
# 设置模型权重参数
net.set_dict(para_dict)
# 设置优化器参数
optimizer.set_state_dict(opti_dict)
logger.info(
logger.coloring("Finish initing model from {}".format(checkpoints),
"HEADER"))
return
# -读取预训练模型-
pretrained_model = config.get('pretrained_model')
# 读取“是否读取静态模型权重”
load_static_weights = config.get('load_static_weights', False)
# 读取“是否使用蒸馏”
use_distillation = config.get('use_distillation', False)
# 如果 pretrained_model 不为空,则读取预训练模型
if pretrained_model:
# 如果 pretrained_model 是一个列表(有多个预训练模型),则同时读取用于蒸馏的模型
if isinstance(pretrained_model,
list): # load distillation pretrained model
# 处理读取静态图模型的情况
if not isinstance(load_static_weights, list):
load_static_weights = [load_static_weights] * len(
pretrained_model)
load_distillation_model(net, pretrained_model, load_static_weights)
# 正常读取预训练模型,不采用蒸馏。
# 根据 load_static_weights 的设置,处理读取静态图模型的情况
else: # common load
load_dygraph_pretrain(
net,
path=pretrained_model,
load_static_weights=load_static_weights)
logger.info(
logger.coloring("Finish initing model from {}".format(
pretrained_model), "HEADER"))
初始化模型函数 init_model() 即可以用于读取自己保存的模型,也可以用于读取预训练模型。如果同时设置了yaml文件的 checkpoints 和 pretrained_model 项,则优先读取自己保存的模型。读取模型时对“是否采用蒸馏”和“是否读取静态图模型”做了相应处理。读取普通模型使用 load_dygraph_pretrain() 函数处理;如果采用蒸馏技术,则需分别读取“教师模型”和“学生模型”,使用 load_distillation_model() 函数处理。
ppcls/utils/save_load.py 脚本的 load_dygraph_pretrain() 函数代码如下:
def load_dygraph_pretrain(model, path=None, load_static_weights=False):
if not (os.path.isdir(path) or os.path.exists(path + '.pdparams')):
raise ValueError("Model pretrain path {} does not "
"exists.".format(path))
# 如果设置了 load_static_weights 为 True,则读取静态图模型
if load_static_weights:
pre_state_dict = load_program_state(path)
param_state_dict = {}
model_dict = model.state_dict()
# 分层读取静态图模型
for key in model_dict.keys():
weight_name = model_dict[key].name
if weight_name in pre_state_dict.keys():
print('Load weight: {}, shape: {}'.format(
weight_name, pre_state_dict[weight_name].shape))
param_state_dict[key] = pre_state_dict[weight_name]
else:
param_state_dict[key] = model_dict[key]
model.set_dict(param_state_dict)
return
# 读取动态图模型
param_state_dict = paddle.load(path + ".pdparams")
model.set_dict(param_state_dict)
return
load_dygraph_pretrain()函数读取模型时根据 load_static_weights 参数的设置,对读取动态图模型还是静态图模型做了相应处理。
ppcls/utils/save_load.py 脚本的 load_distillation_model() 函数代码如下:
def load_distillation_model(model, pretrained_model, load_static_weights):
logger.info("In distillation mode, teacher model will be "
"loaded firstly before student model.")
# 验证参数合法性
assert len(pretrained_model
) == 2, "pretrained_model length should be 2 but got {}".format(
len(pretrained_model))
assert len(
load_static_weights
) == 2, "load_static_weights length should be 2 but got {}".format(
len(load_static_weights))
teacher = model.teacher if hasattr(model,
"teacher") else model._layers.teacher
student = model.student if hasattr(model,
"student") else model._layers.student
# 读取教师模型
load_dygraph_pretrain(
teacher,
path=pretrained_model[0],
load_static_weights=load_static_weights[0])
logger.info(
logger.coloring("Finish initing teacher model from {}".format(
pretrained_model), "HEADER"))
# 读取学生模型
load_dygraph_pretrain(
student,
path=pretrained_model[1],
load_static_weights=load_static_weights[1])
logger.info(
logger.coloring("Finish initing student model from {}".format(
pretrained_model), "HEADER"))
load_distillation_model() 函数分别读取了教师模型和学生模型,读取操作复用了 load_dygraph_pretrain() 函数。
5)【定义数据读取器】

#【*】定义训练集数据读取器
train_dataloader = Reader(config, 'train', places=place)()
数据读取工作通过调用 ppcls/data/reader.py脚本里的 Reader 类定义的对象完成。Reader 类在进行数据读取后还要对数据进行归一化、数据增强和shuffle等处理。其中,数据增强和shuffle只在训练集数据上使用。我们看下Reader 类的代码:
class Reader:
"""
Create a reader for trainning/validate/test
Args:
config(dict): arguments
mode(str): train or val or test
seed(int): random seed used to generate same sequence in each trainer
Returns:
the specific reader
"""
def __init__(self, config, mode='train', places=None):
try:
self.params = config[mode.upper()]
except KeyError:
raise ModeException(mode=mode)
# -参数设置-
use_mix = config.get('use_mix') # 是否使用 mix up 数据增强
self.params['mode'] = mode # 处于训练模式还是验证或测试等模式
self.shuffle = mode == "train" # 训练模式下进行shuffle(打乱顺序)操作
# -设置针对整个 batch 数据进行的处理,如 mix up 数据增强-
self.collate_fn = None
self.batch_ops = []
if use_mix and mode == "train":
self.batch_ops = create_operators(self.params['mix'])
self.collate_fn = self.mix_collate_fn
self.places = places
def mix_collate_fn(self, batch):
# 执行针对整个 batch 的处理
batch = transform(batch, self.batch_ops)
# batch each field
# -将样本进行分组匹配-
slots = []
for items in batch:
for i, item in enumerate(items):
if len(slots) < len(items):
slots.append([item])
else:
slots[i].append(item)
return [np.stack(slot, axis=0) for slot in slots]
def __call__(self):
batch_size = int(self.params['batch_size']) // trainers_num
# 使用 Paddle 框架的 CommnDataset 类定义数据集对象
dataset = CommonDataset(self.params)
# -使用 Paddle 的 DataLoader 类定义数据读取器-
# 处于训练模式则分布式读取数据,其它模式则正常读取,并且不进行数据增强和shuffle操作
if self.params['mode'] == "train":
batch_sampler = DistributedBatchSampler(
dataset,
batch_size=batch_size,
shuffle=self.shuffle,
drop_last=True)
loader = DataLoader(
dataset,
batch_sampler=batch_sampler,
collate_fn=self.collate_fn,
places=self.places,
return_list=True,
num_workers=self.params["num_workers"])
else:
loader = DataLoader(
dataset,
places=self.places,
batch_size=batch_size,
drop_last=False,
return_list=True,
shuffle=False,
num_workers=self.params["num_workers"])
return loader
上面代码中需要注意的是:Reader 类的 mix_collate_fn() 方法进行的是针对一整个 batch 的数据增强处理,在 Reader 类的初始化函数里赋给 self.collate_fn 类成员变量,并且在 Reader 类的__call__() 方法中作为参数传入给 Paddle 框架的 DataLoader() 函数调用;而常见的针对单个样本进行的拉伸、翻转、遮挡等数据增强处理,是在 Reader 类的__call__() 方法中定义 CommonDataset 对象时进行的。下面我们看看 CommonDataset 类的代码:
class CommonDataset(Dataset):
def __init__(self, params):
# -进行参数设置,params存储的参数来自yaml文件-
self.params = params
self.mode = params.get("mode", "train") # 设置运行模式,默认为 train
self.full_lines = get_file_list(params) # 读取数据列表
self.delimiter = params.get('delimiter', ' ') # 读取数据列表采用的分隔符
self.ops = create_operators(params['transforms']) # 建立针对单个样本的数据增强处理序列
self.num_samples = len(self.full_lines) # 设置样本数量
return
def __getitem__(self, idx):
line = self.full_lines[idx] # 读取一条数据记录
img_path, label = line.split(self.delimiter) # 得到图片路径和标签
img_path = os.path.join(self.params['data_dir'], img_path) # 合成完整图片路径
with open(img_path, 'rb') as f: # 读取图片
img = f.read()
return (transform(img, self.ops), int(label)) # 进行针对当个样本的数据增强
def __len__(self):
return self.num_samples # 返回样本数量
CommonDataset 类是继承自 Paddle 框架的 Dataset 类,通过重载 getitem() 方法来读取数据(并进行针对单个样本的数据增强)。
通过阅读以上备份代码可知,读取数据的代码都封装在 ppcls/data/reader.py脚本里,通过 Dataset 类、DataLoader() 函数、DistributedBatchSampler() 函数等 Paddle 框架2.0版本的API实现。详细的使用说明请参考文档:https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/guides/02_paddle2.0_develop/02_data_load_cn.html#id3
6)【执行模型训练、验证过程】

#【*】训练过程循环
for epoch_id in range(last_epoch_id + 1, config.epochs):
#【*】设置模型运行在训练模式下。
net.train()
#【*】调用program.py脚本的run()函数执行模型训练过程
# 1. train with train dataset
program.run(train_dataloader, config, net, optimizer, lr_scheduler,
epoch_id, 'train')
#【*】如果启用了验证过程,则在主进程中执行验证过程
if not config["use_data_parallel"] or ParallelEnv().local_rank == 0:
#【*】执行模型验证过程并打印、保存模型loss、准确率等信息
# 2. validate with validate dataset
if config.validate and epoch_id % config.valid_interval == 0:
#【*】设置模型运行在测试模式下,BN、DropOut等做不同处理。
net.eval()
#【*】执行验证过程前向计算并返回top准确率
top1_acc = program.run(valid_dataloader, config, net, None,
None, epoch_id, 'valid')
#【*】记录top准确率
if top1_acc > best_top1_acc:
best_top1_acc = top1_acc
best_top1_epoch = epoch_id
# 存储最佳模型
if epoch_id % config.save_interval == 0:
model_path = os.path.join(config.model_save_dir,
config.ARCHITECTURE["name"])
save_model(net, optimizer, model_path, "best_model")
#【*】打印top准确率
message = "The best top1 acc {:.5f}, in epoch: {:d}".format(
best_top1_acc, best_top1_epoch)
#【*】记录日志
logger.info("{:s}".format(logger.coloring(message, "RED")))
我们知道,模型训练是在大量 epoch 循环中完成的。由于,我们需要在模型训练的过程中观察训练状态(避免欠拟合、过拟合等问题),所以每个 epoch 循环中的处理除了“训练过程”外还包括“验证过程”。PaddleClas 在训练模型时,根据yaml文件的参数设定定期执行(也可关闭)验证过程。验证时会记录(用于VisualDL进行图形化展示)模型的loss、准确率数据并存储最佳模型的权重参数(以用于推理、部署)。
因为训练过程和验证过程都包含了“前向计算”等相同的步骤,所以都被封装到了 tools/program.py 脚本里的 run() 函数中,只需在训练和验证过程中分别调用即可。需要注意以下两点:
- 由于训练过程和验证过程中模型的BN、Dropout等操作有所不同,所以执行训练过程前要通过 Paddle 框架的 Layer.train() 函数(本项目中实例化为了 net 对象,所以执行 net.train())设置模型对象运行在 train 模式下。同样的道理,执行验证过程前也要执行一下 net.eval() 函数。
- 由于验证过程与训练过程不同,不需要执行梯度反向计算和参数更新,而需要计算准确率。那么在执行复用的 run() 函数时要通过参数来进行控制。
下面我们看下训练过程和验证过程都复用的run()函数:
def run(dataloader,
config,
net,
optimizer=None,
lr_scheduler=None,
epoch=0,
mode='train'):
"""
Feed data to the model and fetch the measures and loss
Args:
dataloader(paddle dataloader):
exe():
program():
fetchs(dict): dict of measures and the loss
epoch(int): epoch of training or validation
model(str): log only
Returns:
"""
# 设置loss、准确率的打印间隔,默认为10
print_interval = config.get("print_interval", 10)
# 设置是否进行mix up处理,只在训练过程中进行
use_mix = config.get("use_mix", False) and mode == "train"
# -建立训练信息列表,包括loss、学习率、执行时长、读取时长、topn准确率-
metric_list = [
("loss", AverageMeter(
'loss', '7.5f', postfix=",")),
("lr", AverageMeter(
'lr', 'f', postfix=",", need_avg=False)),
("batch_time", AverageMeter(
'batch_cost', '.5f', postfix=" s,")),
("reader_time", AverageMeter(
'reader_cost', '.5f', postfix=" s,")),
]
if not use_mix:
topk_name = 'top{}'.format(config.topk)
metric_list.insert(
1, (topk_name, AverageMeter(
topk_name, '.5f', postfix=",")))
metric_list.insert(
1, ("top1", AverageMeter(
"top1", '.5f', postfix=",")))
metric_list = OrderedDict(metric_list)
tic = time.time() # 设置记时开始
# -逐 Batch 执行训练(或验证)过程-
for idx, batch in enumerate(dataloader()):
metric_list['reader_time'].update(time.time() - tic) # 记录数据读取时长
batch_size = len(batch[0]) # 记录batch size
feeds = create_feeds(batch, use_mix) # 建立喂入的数据
fetchs = create_fetchs(feeds, net, config, mode) # 执行前向计算并返回结果
# -如果处于训练过程,则执行梯度反向传播计算和模型权重更新-
if mode == 'train':
# -梯度反向传播计算-
avg_loss = fetchs['loss']
avg_loss.backward()
# -更新模型权重参数并清空梯度-
optimizer.step()
optimizer.clear_grad()
metric_list['lr'].update(
optimizer._global_learning_rate().numpy()[0], batch_size)
# -根据设定的策略变更学习率-
if lr_scheduler is not None:
if lr_scheduler.update_specified:
curr_global_counter = lr_scheduler.step_each_epoch * epoch + idx
update = max(
0, curr_global_counter - lr_scheduler.update_start_step
) % lr_scheduler.update_step_interval == 0
if update:
lr_scheduler.step()
else:
lr_scheduler.step()
# -合成并记录(用于VisualDL)训练或验证信息-
for name, fetch in fetchs.items():
metric_list[name].update(fetch.numpy()[0], batch_size)
metric_list["batch_time"].update(time.time() - tic)
tic = time.time()
fetchs_str = ' '.join([str(m.value) for m in metric_list.values()])
if idx % print_interval == 0:
ips_info = "ips: {:.5f} images/sec.".format(
batch_size / metric_list["batch_time"].val)
if mode == 'eval':
logger.info("{:s} step:{:<4d}, {:s} {:s}".format(
mode, idx, fetchs_str, ips_info))
else:
epoch_str = "epoch:{:<3d}".format(epoch)
step_str = "{:s} step:{:<4d}".format(mode, idx)
logger.info("{:s}, {:s}, {:s} {:s}".format(
logger.coloring(epoch_str, "HEADER")
if idx == 0 else epoch_str,
logger.coloring(step_str, "PURPLE"),
logger.coloring(fetchs_str, 'OKGREEN'),
logger.coloring(ips_info, 'OKGREEN')))
# -本轮训练(或验证)结束,记录(用于VisualDL)相应信息-
end_str = ' '.join([str(m.mean) for m in metric_list.values()] +
[metric_list['batch_time'].total])
ips_info = "ips: {:.5f} images/sec.".format(
batch_size * metric_list["batch_time"].count /
metric_list["batch_time"].sum)
if mode == 'eval':
logger.info("END {:s} {:s} {:s}".format(mode, end_str, ips_info))
else:
end_epoch_str = "END epoch:{:<3d}".format(epoch)
logger.info("{:s} {:s} {:s} {:s}".format(
logger.coloring(end_epoch_str, "RED"),
logger.coloring(mode, "PURPLE"),
logger.coloring(end_str, "OKGREEN"),
logger.coloring(ips_info, "OKGREEN"), ))
# -如果处于验证过程,返回topn准确率-
# return top1_acc in order to save the best model
if mode == 'valid':
return metric_list['top1'].avg
run() 函数封装的功能主要是逐 Batch 喂入数据训练模型,定期记录日志(用于VisualDL)、打印训练情况和保存模型。根据传入的 mode 参数的不同设置(train、eval),选择是否执行反向计算、权重更新、学习率调整和返回准确率。其中,喂入模型的数据使用 create_feeds() 函数进行处理,而前向计算过程则封装在 create_fetchs() 函数中。我们先看 create_feeds() 函数:
def create_feeds(batch, use_mix):
image = batch[0] # 将 batch 列表里的第0个元素赋值给图片变量
# 如果启用了 mix up 数据增强,则返回图片的同时要返回进行混合的两张图片 y_a
# 和 y_b 的标签,以及它们的混合比例 lam
if use_mix:
y_a = to_tensor(batch[1].numpy().astype("int64").reshape(-1, 1))
y_b = to_tensor(batch[2].numpy().astype("int64").reshape(-1, 1))
lam = to_tensor(batch[3].numpy().astype("float32").reshape(-1, 1))
feeds = {"image": image, "y_a": y_a, "y_b": y_b, "lam": lam}
# 如果没有启用 mix up 数据增强,则返回图片和对应标签即可
else:
label = to_tensor(batch[1].numpy().astype('int64').reshape(-1, 1))
feeds = {"image": image, "label": label}
return feeds # 返回喂入模型的训练数据
create_feeds() 函数的功能是将读取的数据格式化为字典类型,启用 mix up 时要将标签也“按比例混合”。我们再看看 create_fetchs() 函数:
def create_fetchs(feeds, net, config, mode="train"):
"""
Create fetchs as model outputs(included loss and measures),
will call create_loss and create_metric(if use_mix).
Args:
out(variable): model output variable
feeds(dict): dict of model input variables.
If use mix_up, it will not include label.
architecture(dict): architecture information,
name(such as ResNet50) is needed
topk(int): usually top5
classes_num(int): num of classes
epsilon(float): parameter for label smoothing, 0.0 <= epsilon <= 1.0
use_mix(bool): whether to use mix(include mixup, cutmix, fmix)
Returns:
fetchs(dict): dict of model outputs(included loss and measures)
"""
architecture = config.ARCHITECTURE # 设置模型结构,本项目为Resnet50_vd
topk = config.topk # 设置精确度 top n 的 n,一般是5
classes_num = config.classes_num # 设置分类数
epsilon = config.get('ls_epsilon') # 设置防止除0的附加项
use_mix = config.get('use_mix') and mode == 'train' # 设置是否使用 mix up 数据增强
use_distillation = config.get('use_distillation') # 设置是否使用蒸馏
out = net(feeds["image"]) # 输入图片执行前向计算,并返回结果
fetchs = OrderedDict() # 排序模型训练信息
# 设定损失函数
fetchs['loss'] = create_loss(feeds, out, architecture, classes_num,
epsilon, use_mix, use_distillation)
# 更新模型准确率 top k 信息
if not use_mix:
metric = create_metric(out, feeds["label"], architecture, topk,
classes_num, use_distillation)
fetchs.update(metric)
return fetchs
create_fetchs() 函数里首先执行模型的前向计算过程,然后利用计算结果通过 create_loss() 函数设置优化模型的损失函数,再通过 create_metric() 函数得到 top k 准确率信息并将其返回。create_metric() 函数很简单,就是通过 Paddle 框架的 paddle.metric.accuracy() 函数计算 top k 准确率。我们着重看下设置损失函数的 create_loss() 函数:
def create_loss(feeds,
out,
architecture,
classes_num=1000,
epsilon=None,
use_mix=False,
use_distillation=False):
"""
Create a loss for optimization, such as:
1. CrossEnotry loss
2. CrossEnotry loss with label smoothing
3. CrossEnotry loss with mix(mixup, cutmix, fmix)
4. CrossEnotry loss with label smoothing and (mixup, cutmix, fmix)
5. GoogLeNet loss
Args:
out(variable): model output variable
feeds(dict): dict of model input variables
architecture(dict): architecture information,
name(such as ResNet50) is needed
classes_num(int): num of classes
epsilon(float): parameter for label smoothing, 0.0 <= epsilon <= 1.0
use_mix(bool): whether to use mix(include mixup, cutmix, fmix)
Returns:
loss(variable): loss variable
"""
# 如果模型结构采用了GoogLeNet,需要对返回三部分loss,所以使用专用的 GoogLeNetLoss 类对象处理
if architecture["name"] == "GoogLeNet":
assert len(out) == 3, "GoogLeNet should have 3 outputs"
loss = GoogLeNetLoss(class_dim=classes_num, epsilon=epsilon)
return loss(out[0], out[1], out[2], feeds["label"])
# 如果采用了模型蒸馏技术,则要计算教师模型和学生模型各个类别概率分布的JS散度
if use_distillation:
assert len(out) == 2, ("distillation output length must be 2, "
"but got {}".format(len(out)))
loss = JSDivLoss(class_dim=classes_num, epsilon=epsilon)
return loss(out[1], out[0])
# 如果使用了 mix up 数据增强,则计算 loss 时,要对进行混合的两张图片的
# 分类交叉熵损失按比例加和处理
if use_mix:
loss = MixCELoss(class_dim=classes_num, epsilon=epsilon)
feed_y_a = feeds['y_a']
feed_y_b = feeds['y_b']
feed_lam = feeds['lam']
return loss(out, feed_y_a, feed_y_b, feed_lam)
# 其它情况下直接计算分类的交叉熵损失
else:
loss = CELoss(class_dim=classes_num, epsilon=epsilon)
return loss(out, feeds["label"])
create_loss() 函数对“采用GoogLeNet结构”、“采用模型蒸馏技术”和采用“Mix Up数据增强”三种情况和普通的“直接求交叉熵损失”的情况共四种情况,分别使用 GoogLeNetLoss、JSDivLoss、MixCELoss 和 CELoss 四个类进行相应的处理以设定合适的损失函数。这四个类定义在 ppcls/modeling/loss.py 脚本里。
7)【存储模型】

...
# 存储最佳模型
if epoch_id % config.save_interval == 0:
model_path = os.path.join(config.model_save_dir,
config.ARCHITECTURE["name"])
save_model(net, optimizer, model_path, "best_model")
...
#【*】定期存储模型
# 3. save the persistable model
if epoch_id % config.save_interval == 0:
model_path = os.path.join(config.model_save_dir,
config.ARCHITECTURE["name"])
save_model(net, optimizer, model_path, epoch_id)
...
在 train.py 脚本中,执行 epoch 循环时会定期存储模型。如果设置了“执行验证过程”的话,还会在验证过程中存储最佳模型。这都是通过 ppcls/utils/save_load.py 脚本下的 save_model() 函数实现的。我们看下函数代码:
def save_model(net, optimizer, model_path, epoch_id, prefix='ppcls'):
"""
save model to the target path
"""
# -设置模型存储路径-
model_path = os.path.join(model_path, str(epoch_id))
_mkdir_if_not_exist(model_path)
model_prefix = os.path.join(model_path, prefix)
paddle.save(net.state_dict(), model_prefix + ".pdparams") # 存储模型权重参数
paddle.save(optimizer.state_dict(), model_prefix + ".pdopt") # 存储优化器参数
logger.info(
logger.coloring("Already save model in {}".format(model_path),
"HEADER"))
模型存储是通过 Paddle 框架的 paddle.save() 函数实现的,存储的是模型的 persistable 版本,便于继续训练。注意:优化器参数也是需要存储的。
至此,我们已经将 PaddleClas 分类套件的训练过程全面、系统的进行了一次梳理。下面我们来看看推理过程。