GitHub项目地址:https://github.com/Donvink/Spider.BC
哔哩哔哩代码讲解:https://b23.tv/waSfUa
CSDN博客地址:https://blog.csdn.net/sinat_16020825/article/details/108538779
目录
一、项目简介
1.1 简介
本项目应用Python爬虫、Flask框架、Echarts、WordCloud等技术将豆瓣租房信息爬取出来保存于Excel和数据库中,进行数据可视化操作、制作网页展示。
主要内容包括三部分:
- douban_renting:Python 爬虫将 豆瓣租房上的租房信息爬取出来,解析数据后将其存储于Excel和SQLite数据库中。
- flask_demo:测试使用Flask框架。
- douban_flask:应用Flask框架、Echarts、WordCloud技术将数据库中的租房信息以网页的形式展示出来。
1.2 Results
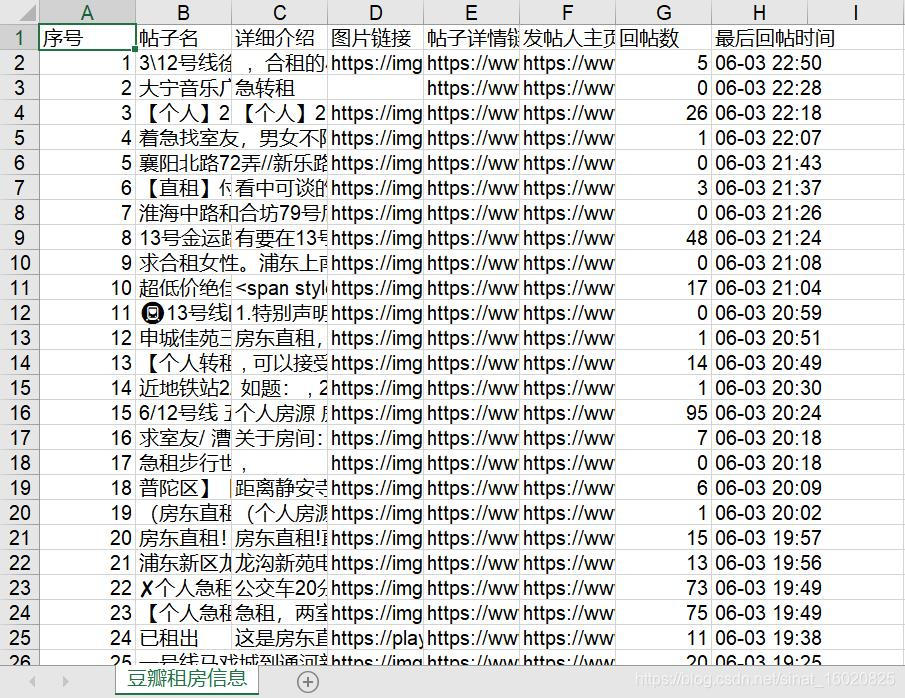
1.2.1 Excel保存数据
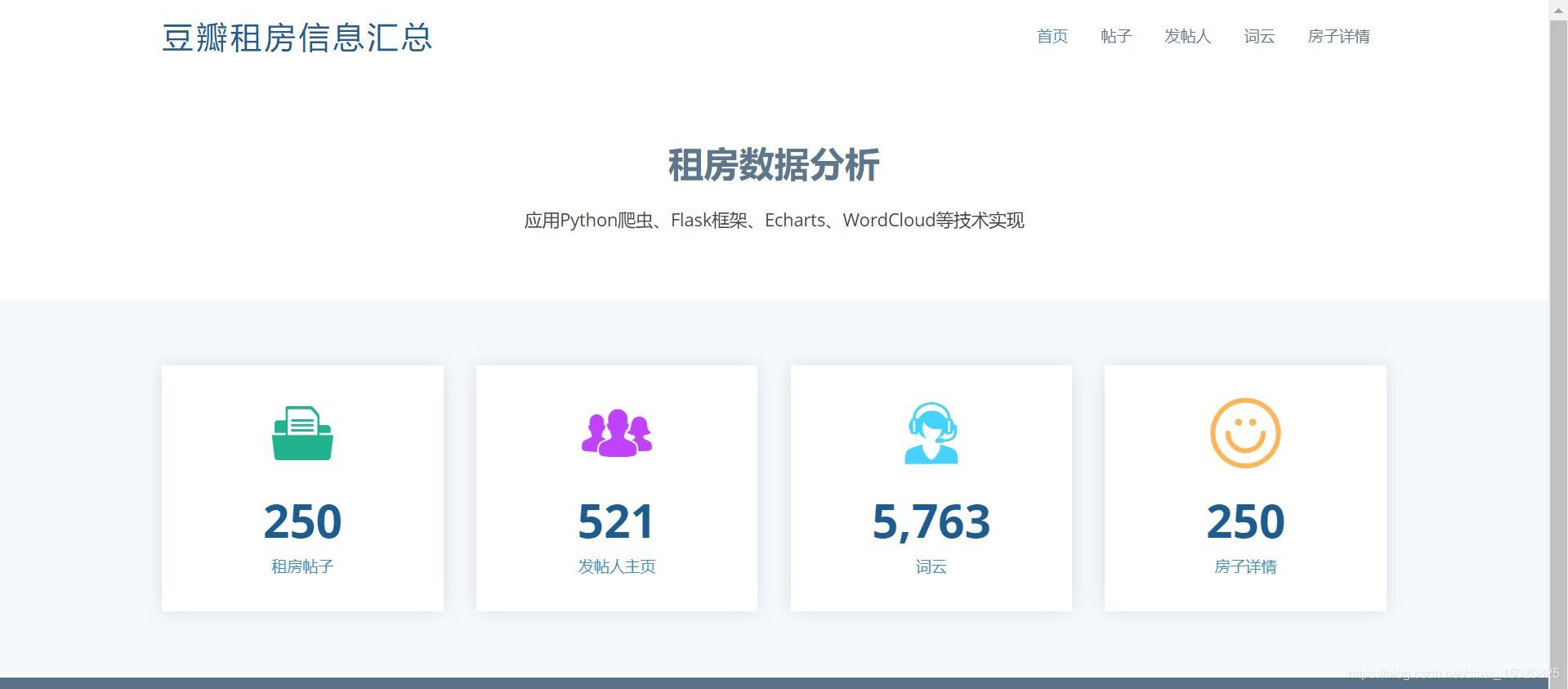
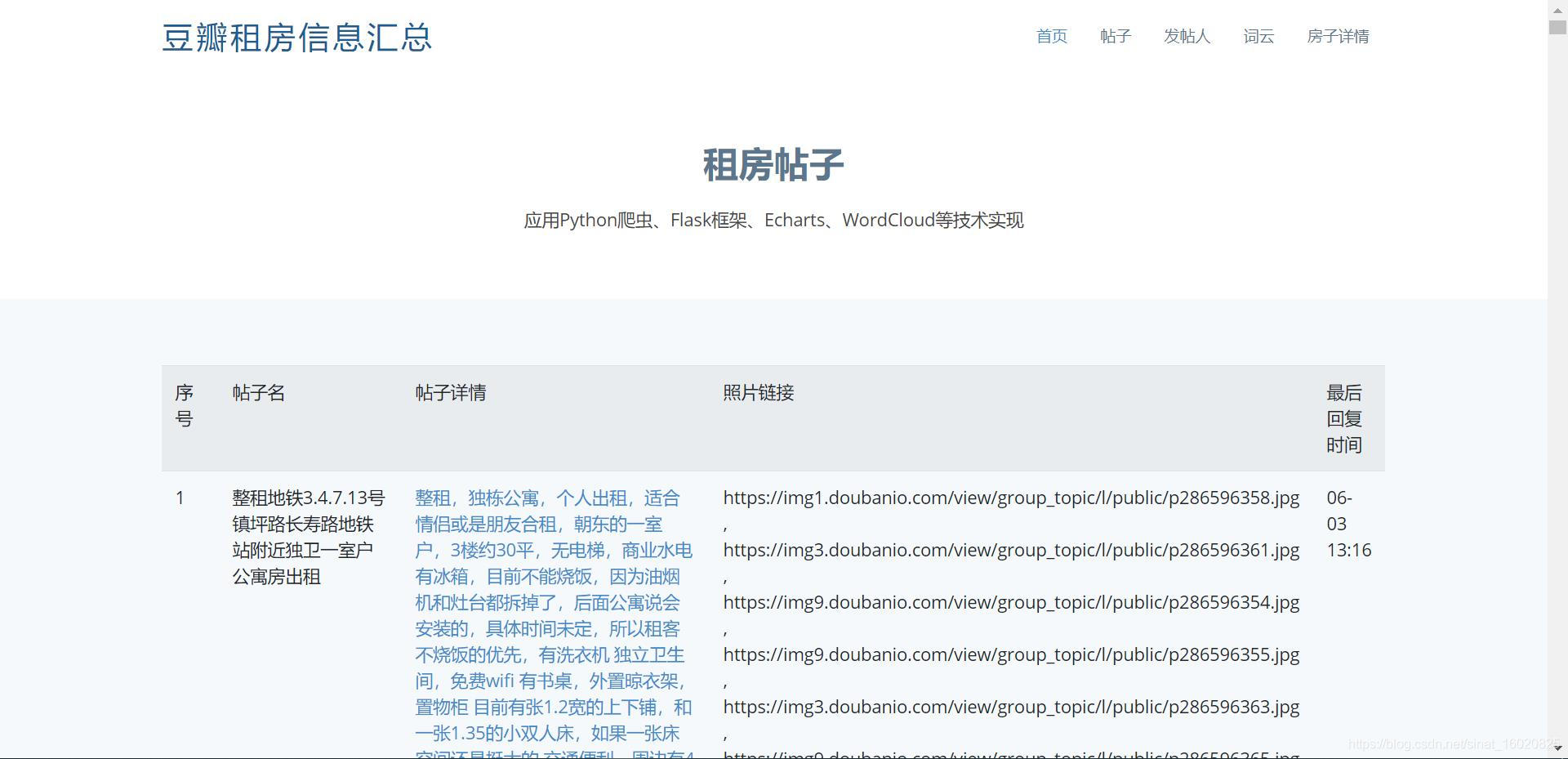
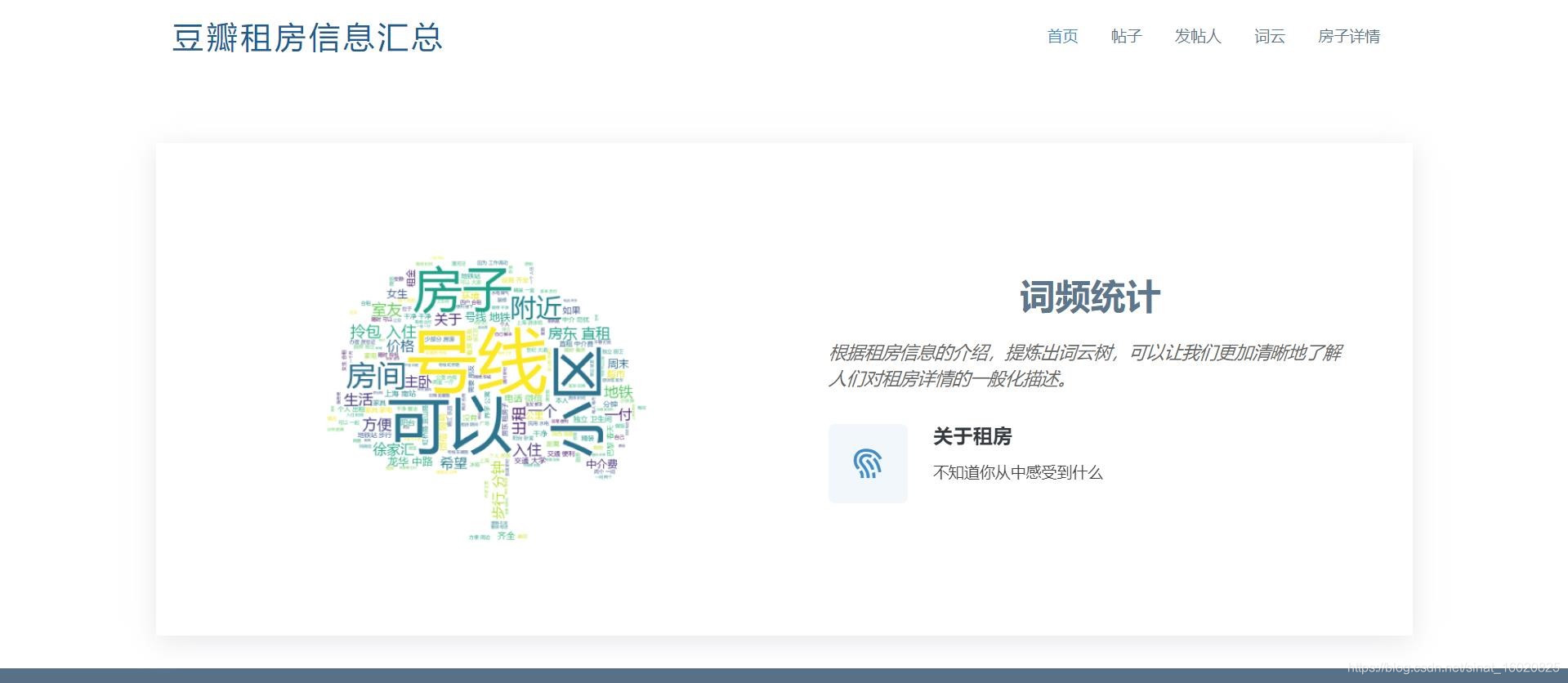
1.2.2 网页展示数据
-
首页
-
帖子列表
-
词云
| 作者 | Donvink |
|---|
二、代码分析
2.1 概述
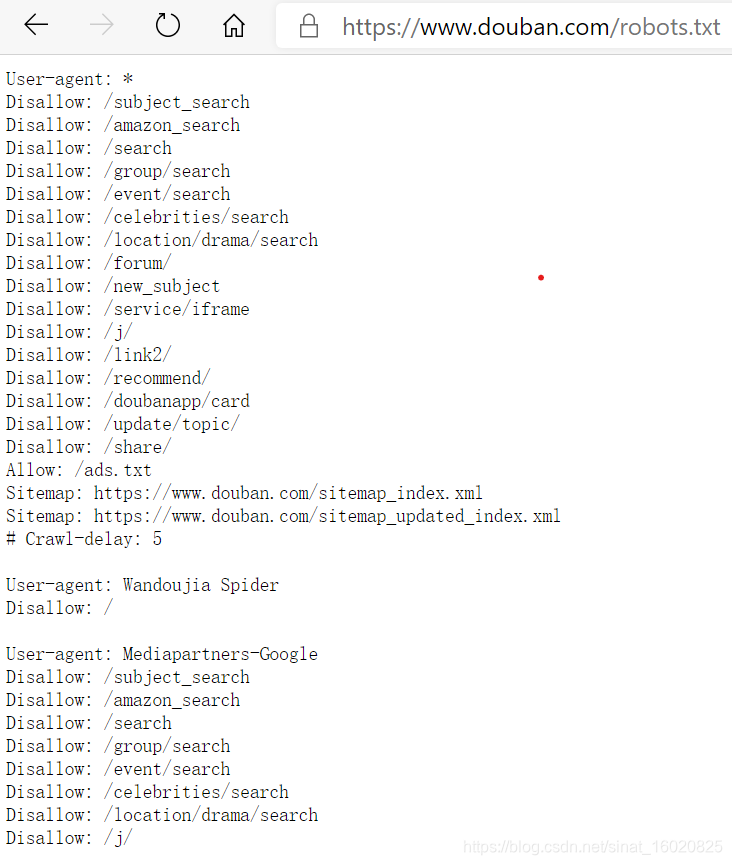
2.1.1 robots协议
在爬取数据之前,必须先查看目标网站的robots协议,查阅网站允许和禁止的爬取的数据,对于网站禁止爬虫访问的数据,一定不要去爬取,否则严重的话需要承担相应的法律责任。网站的robots协议地址一般是:https://网站地址/robots.txt。
豆瓣robots协议地址为:https://www.douban.com/robots.txt。
原则上禁止访问robots协议上disallow的地址。
2.1.2 爬取流程
准备工作 -> 获取数据 -> 解析内容 -> 保存数据
调用的库:
import sys
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文件匹配
import urllib # 制定URL,获取网页数据
import urllib.request
import urllib.error
import xlwt # 进行excel操作
import sqlite3 # 进行SQLite数据库操作
需要安装requests、urllib3、xlwt和pysqlite3库,在终端执行一下命令。
pip install requests urllib3 xlwt pysqlite3
2.2 准备工作
URL分析:
首页 https://www.douban.com/group/558444/ (包含50条数据,和第一第二页数据相同);
第一页 https://www.douban.com/group/558444/discussion?start=0;
第二页 https://www.douban.com/group/558444/discussion?start=25。
总结:
1)页面包含x条租房数据,每页25条,
2)每页的URL的不同之处:最后的数值 = (页数 - 1) * 25。
# 1.爬取网页 2、逐一解析网页数据
baseurl = 'https://www.douban.com/group/558444/discussion?start=' # 基本URL
pagecount = 10 # 爬取的网页数量
num = 25 # 每页的帖子数
datalist = getData(baseurl, pagecount, num) # 爬取网页、解析数据
# 调用获取页面信息的函数pagecount次
for i in range(0, pagecount):
url = baseurl + str(i * num) # 拼接网页链接
# 1.爬取网页
html = askURL(url) # 保存获取到的网页源码
2.2.1 分析页面
1)借助Chrome开发者工具(F12)来分析页面,在Elements下找到需要的数据位置。
2)在页面中选择一个元素以进行检查(Ctrl+Shift+C)(开发者工具最左上方的小箭头),点击页面内容即可定位到具体标签位置。
3)点击Network,可以查看每个时间点发送的请求和交互情况,可点击最上方小红点(停止记录网络日志Ctrl+E)停止交互。
4)Headers查看发送给服务器的命令情况。
5)服务器返回信息可在Response中查看。
2.2.2 编码规范
1)一般Python程序第一行需要加入
# -*- coding = utf-8 -*-
这样可以在代码中包含中文。
2)使用函数实现单一功能或相关联功能的代码段,可以提高可读性和代码重复利用率。
3)Python文件中可以加入main函数用于测试程序
if __name__ == "__main__":
4)Python使用#添加注释,说明代码(段)的作用。
2.2.3 引入模块
sys, bs4 -> BeautifulSoup, re, urllib, xlwt。
2.3 获取数据
python一般使用urllib库获取页面。
获取页面数据:
1)对每一个页面,调用askURL函数获取页面内容
def askURL(url):
"""
得到指定一个URL的网页信息
:param url: 网页链接
:return:
"""
2)定义一个获取页面的函数askURL,传入一个url参数,表示网址,如https://www.douban.com/group/558444/discussion?start=0
# 模拟浏览器头部信息,向豆瓣服务器发送消息
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36 Edg/83.0.478.37'
} # 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
3)urllib.Request生成请求,urllib.urlopen发送请求获取响应,read获取页面内容
request = urllib.request.Request(url, headers=head) # 发送请求
html = ''
4)在访问页面时经常会出现错误,为了程序正常运行,假如异常捕获try…except…语句
# 捕获异常
try:
response = urllib.request.urlopen(request) # 取得响应
html = response.read().decode('utf-8') # 获取网页内容
# print(html)
except urllib.error.URLError as e: # 若发生异常,则打印相关信息
if hasattr(e, 'code'): # 异常代码
print(e.code)
if hasattr(e, 'reason'): # 异常原因
print(e.reason)
return html
2.4 解析内容
对爬取的html文件进行解析
1、使用BeautifulSoup定位特定的标签位置
# 2.逐一解析数据
soup = BeautifulSoup(html, 'html.parser') # 对网页源码进行解析
# print(soup) # 测试html是否能被解析
2、使用正则表达式找到具体的内容
for item in soup.find_all('tr', class_=''): # 找到每一个帖子选项(查找符合要求的字符串,形成列表)
# print(item) # 测试:查看item全部信息
data = []
item = str(item) # 转换成字符串
# print(item) # 测试item
# 帖子名
title = re.findall(findTitle, item)[0]
# print(title) # 测试:查看title
data.append(title) # 添加帖子名
# 帖子详情链接
link = re.findall(findLink, item)
# print(link) # 测试:查看link信息
# 进入帖子里爬取租房信息介绍内容和照片
info, imglink = getInfo(link[0])
data.append(info) # 添加详细信息
data.append(imglink) # 添加图片链接
if (len(link) == 2):
data.append(link[0]) # 添加详情链接
# alink = re.findall(findLink, item)[1]
# print(alink) # 测试:查看link信息
data.append(link[1]) # 添加发帖人主页链接
else:
data.append(link[0])
data.append(' ') # 留空
# 回帖数
rcount = re.findall(findRCount, item)[0]
# print(rcount) # 测试:查看回帖数
if rcount == '':
# print(0) # 测试:查看回帖数
data.append(0) # 添加回帖数
else:
# print(rcount) # 测试:查看回帖数
data.append(int(rcount)) # 添加回帖数
# 最后回帖时间
rtime = re.findall(findRTime, item)[0]
# print(rtime)
data.append(rtime) # 添加最后回帖时间
# otitle = titles[1].replace('/', '') # 去掉无关符号,或re.sub()
datalist.append(data) # 把处理好的信息放入datalist
# print(datalist) # 测试
2.5 保存数据
Excel表格存储:利用python库xlwt将抽取的数据datalist写入Excel表格。
def saveData(datalist, pagecount, num, savepath):
"""
将解析后的数据保存在Excel文件中
:param datalist: 网页解析后的数据
:param pagecount: 爬取的网页数量
:param num: 每页的帖子数
:param savepath: Excel文件保存路径
:return:
"""
# print('saving...')
book = xlwt.Workbook(encoding='utf-8', style_compression=0) # 新建workbook
sheet = book.add_sheet('豆瓣租房信息', cell_overwrite_ok=True) # 添加sheet
# 列名
col = ('序号', '帖子名', '详细介绍', '图片链接', '帖子详情链接', '发帖人主页链接', '回帖数', '最后回帖时间')
# 写入列名
for i in range(0, len(col)):
sheet.write(0, i, col[i])
# 将每条帖子的相关内容写入Excel对应行中
for i in range(0, pagecount*num):
# print('第%d条' % (i+1))
data = datalist[i]
sheet.write(i+1, 0, i+1) # 写入序号
for j in range(0, len(data)):
sheet.write(i+1, j+1, data[j]) # 写入数据
book.save(savepath) # 保存文件
# print('Successful!')
数据库存储
def saveData2DB(datalist, dbpath):
"""
将解析后的数据保存在数据库文件中
:param datalist: 网页解析后的数据
:param dbpath: 数据库文件保存路径
:return:
"""
init_DB(dbpath) # 初始化数据库
conn = sqlite3.connect(dbpath) # 连接数据库
cur = conn.cursor() # 获取游标
# 将数据逐一保存到数据库中
for data in datalist:
for index in range(len(data)):
if index != 5: # index为5的数据类型是int
data[index] = '"'+data[index]+'"' # 每项的字符串需要加上双引号或单引号
# 插入字符串,以逗号隔开
sql = '''
insert into renting(
title, introduction, img_link, title_link, person_link, re_count, re_time)
values(%s)''' % ",".join(str(v) for v in data)
# print(sql)
cur.execute(sql) # 执行数据库操作
conn.commit() # 提交
cur.close() # 关闭游标
conn.close() # 关闭连接
2.7 网页展示数据
待更新
2.8 TODO
- 添加筛选:区域、小区名、地铁站等
- 定义类,获取各种不同途径信息(豆瓣、自如、链家、贝壳等)
三、完整代码
# -*- coding = utf-8 -*-
# @Time: 2020/5/30 19:57
# @Author: Donvink
# @File: douban.py
# @Software: PyCharm
"""
查看robots协议:https://www.douban.com/robots.txt
零、流程
准备工作 -> 获取数据 -> 解析内容 -> 保存数据
一、准备工作
URL分析:
首页 https://www.douban.com/group/558444/ (包含50条数据,和第一第二页数据相同)
第一页 https://www.douban.com/group/558444/discussion?start=0
第二页 https://www.douban.com/group/558444/discussion?start=25
1)页面包含x条租房数据,每页25条
2)每页的URL的不同之处:最后的数值 = (页数 - 1) * 25
1、分析页面
1)借助Chrome开发者工具(F12)来分析页面,在Elements下找到需要的数据位置。
2)在页面中选择一个元素以进行检查(Ctrl+Shift+C)(开发者工具最左上方的小箭头),点击页面内容即可定位到具体标签位置。
3)点击Network,可以查看每个时间点发送的请求和交互情况,可点击最上方小红点(停止记录网络日志Ctrl+E)停止交互。
4)Headers查看发送给服务器的命令情况。
5)服务器返回信息可在Response中查看。
2、编码规范
1)一般Python程序第一行需要加入
# -*- coding = utf-8 -*-
这样可以在代码中包含中文。
2)使用函数实现单一功能或相关联功能的代码段,可以提高可读性和代码重复利用率。
3)Python文件中可以加入main函数用于测试程序
if __name__ == "__main__":
4)Python使用#添加注释,说明代码(段)的作用
3、引入模块
sys, bs4 -> BeautifulSoup, re, urllib, xlwt
二、获取数据
python一般使用urllib库获取页面
获取页面数据:
1)对每一个页面,调用askURL函数获取页面内容
2)定义一个获取页面的函数askURL,传入一个url参数,表示网址,如https://www.douban.com/group/558444/discussion?start=0
3)urllib.Request生成请求,urllib.urlopen发送请求获取响应,read获取页面内容
4)在访问页面时经常会出现错误,为了程序正常运行,假如异常捕获try...except...语句
三、解析内容
对爬取的html文件进行解析
1、使用BeautifulSoup定位特定的标签位置
2、使用正则表达式找到具体的内容
四、保存数据
Excel表格存储:利用python库xlwt将抽取的数据datalist写入Excel表格
TODO:
1、添加筛选【区域,小区名,地铁站】
2、定义类,获取各种不同途径信息(豆瓣,自如,链家,贝壳)
"""
import sys
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文件匹配
import urllib # 制定URL,获取网页数据
import urllib.request
import urllib.error
import xlwt # 进行excel操作
import sqlite3 # 进行SQLite数据库操作
def main():
"""
主函数入口
1.爬取网页
2.逐一解析数据
3.保存数据
:return:
"""
print('开始爬取······')
# 1.爬取网页 2、逐一解析网页数据
baseurl = 'https://www.douban.com/group/558444/discussion?start=' # 基本URL
pagecount = 10 # 爬取的网页数量
num = 25 # 每页的帖子数
datalist = getData(baseurl, pagecount, num) # 爬取网页、解析数据
# 3.保存数据
savepath = 'douban_renting.xls' # Excel文件保存路径
saveData(datalist, pagecount, num, savepath) # 将数据保存在Excel中
dbpath = 'douban_renting.db' # 数据库文件保存路径
saveData2DB(datalist, dbpath) # 将数据保存在数据库中
# askURL('https://www.douban.com/group/558444/discussion?start=0') # 测试askURL
print('爬取完毕!')
def getData(baseurl, pagecount, num):
"""
爬取网页,逐一对网页数据进行分析。主要内容有:
'帖子名', '详细介绍', '图片链接', '帖子详情链接', '发帖人主页链接', '回帖数', '最后回帖时间'
:param baseurl: 基本URL
:param pagecount: 爬取的网页数量
:param num: 每页的帖子数
:return:
"""
datalist = []
# 正则表达式规则
findTitle = re.compile(r'title="(.*?)"', re.S) # 找到帖子名,有的帖子名带有\n
findLink = re.compile(r'href="(.*?)"') # 找到帖子详情链接
findRCount = re.compile(r'<.*class="r-count".*>(.*?)</td>') # 找到回帖数
findRTime = re.compile(r'<.*class="time".*">(.*?)</td>') # 找到最后回帖时间
# 注意:正则表达式匹配空格时,需用.*或\s匹配
# 调用获取页面信息的函数pagecount次
for i in range(0, pagecount):
url = baseurl + str(i * num) # 拼接网页链接
# 1.爬取网页
html = askURL(url) # 保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html, 'html.parser') # 对网页源码进行解析
# print(soup) # 测试html是否能被解析
for item in soup.find_all('tr', class_=''): # 找到每一个帖子选项(查找符合要求的字符串,形成列表)
# print(item) # 测试:查看item全部信息
data = []
item = str(item) # 转换成字符串
# print(item) # 测试item
# 帖子名
title = re.findall(findTitle, item)[0]
# print(title) # 测试:查看title
data.append(title) # 添加帖子名
# 帖子详情链接
link = re.findall(findLink, item)
# print(link) # 测试:查看link信息
# 进入帖子里爬取租房信息介绍内容和照片
info, imglink = getInfo(link[0])
data.append(info) # 添加详细信息
data.append(imglink) # 添加图片链接
if (len(link) == 2):
data.append(link[0]) # 添加详情链接
# alink = re.findall(findLink, item)[1]
# print(alink) # 测试:查看link信息
data.append(link[1]) # 添加发帖人主页链接
else:
data.append(link[0])
data.append(' ') # 留空
# 回帖数
rcount = re.findall(findRCount, item)[0]
# print(rcount) # 测试:查看回帖数
if rcount == '':
# print(0) # 测试:查看回帖数
data.append(0) # 添加回帖数
else:
# print(rcount) # 测试:查看回帖数
data.append(int(rcount)) # 添加回帖数
# 最后回帖时间
rtime = re.findall(findRTime, item)[0]
# print(rtime)
data.append(rtime) # 添加最后回帖时间
# otitle = titles[1].replace('/', '') # 去掉无关符号,或re.sub()
datalist.append(data) # 把处理好的信息放入datalist
# print(datalist) # 测试
return datalist
def getInfo(url):
"""
进入每个帖子里爬取租房信息介绍内容和照片链接
:param url: 帖子URL
:return:
"""
tempinfo = []
info = '' # 租房详细信息介绍
tempimglink = []
imglink = '' # 图片链接
# 正则表达式规则
findInfo = re.compile(r'<p>(.*?)</p>', re.S) # 找到帖子详情信息,有的帖子名带有\n
findImgLink = re.compile(r'src="(.*?)"') # 找到帖子附带的照片链接
html = askURL(url) # 保存获取到的网页源码
soup = BeautifulSoup(html, 'html.parser') # 解析网页源码
topic = soup.find_all('div', class_='topic-richtext') # 找到介绍内容和照片所在标签
topic = str(topic) # 转换为字符串
# 详细介绍
tempinfo = re.findall(findInfo, topic)
info = " , ".join(str(v) for v in tempinfo) # 帖子里详细介绍内容会有换行,用逗号隔开
# 照片链接
tempimglink = re.findall(findImgLink, topic)
imglink = " , ".join(str(v) for v in tempimglink) # 每个帖子可能会附带多张照片,用逗号隔开
return info, imglink
def askURL(url):
"""
得到指定一个URL的网页信息
:param url: 网页链接
:return:
"""
# 模拟浏览器头部信息,向豆瓣服务器发送消息
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36 Edg/83.0.478.37'
} # 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head) # 发送请求
html = ''
# 捕获异常
try:
response = urllib.request.urlopen(request) # 取得响应
html = response.read().decode('utf-8') # 获取网页内容
# print(html)
except urllib.error.URLError as e: # 若发生异常,则打印相关信息
if hasattr(e, 'code'): # 异常代码
print(e.code)
if hasattr(e, 'reason'): # 异常原因
print(e.reason)
return html
def saveData(datalist, pagecount, num, savepath):
"""
将解析后的数据保存在Excel文件中
:param datalist: 网页解析后的数据
:param pagecount: 爬取的网页数量
:param num: 每页的帖子数
:param savepath: Excel文件保存路径
:return:
"""
# print('saving...')
book = xlwt.Workbook(encoding='utf-8', style_compression=0) # 新建workbook
sheet = book.add_sheet('豆瓣租房信息', cell_overwrite_ok=True) # 添加sheet
# 列名
col = ('序号', '帖子名', '详细介绍', '图片链接', '帖子详情链接', '发帖人主页链接', '回帖数', '最后回帖时间')
# 写入列名
for i in range(0, len(col)):
sheet.write(0, i, col[i])
# 将每条帖子的相关内容写入Excel对应行中
for i in range(0, pagecount*num):
# print('第%d条' % (i+1))
data = datalist[i]
sheet.write(i+1, 0, i+1) # 写入序号
for j in range(0, len(data)):
sheet.write(i+1, j+1, data[j]) # 写入数据
book.save(savepath) # 保存文件
# print('Successful!')
def saveData2DB(datalist, dbpath):
"""
将解析后的数据保存在数据库文件中
:param datalist: 网页解析后的数据
:param dbpath: 数据库文件保存路径
:return:
"""
init_DB(dbpath) # 初始化数据库
conn = sqlite3.connect(dbpath) # 连接数据库
cur = conn.cursor() # 获取游标
# 将数据逐一保存到数据库中
for data in datalist:
for index in range(len(data)):
if index != 5: # index为5的数据类型是int
data[index] = '"'+data[index]+'"' # 每项的字符串需要加上双引号或单引号
# 插入字符串,以逗号隔开
sql = '''
insert into renting(
title, introduction, img_link, title_link, person_link, re_count, re_time)
values(%s)''' % ",".join(str(v) for v in data)
# print(sql)
cur.execute(sql) # 执行数据库操作
conn.commit() # 提交
cur.close() # 关闭游标
conn.close() # 关闭连接
def init_DB(dbpath):
"""
初始化数据库
:param dbpath: 数据库保存路径
:return:
"""
# create table renting
# 若不加if not exists,则每次运行程序需要先删除database;否则不用先删除,但无法更新sql里的格式
sql = '''
create table if not exists renting
(
id integer primary key autoincrement,
title text,
introduction text,
img_link text,
title_link text,
person_link text,
re_count numeric,
re_time text
)
''' # 创建数据表
conn = sqlite3.connect(dbpath) # 创建或连接数据库
cursor = conn.cursor() # 获取游标
cursor.execute(sql) # 执行数据库操作
conn.commit() # 提交
cursor.close() # 关闭游标
conn.close() # 关闭
if __name__ == "__main__": # 当程序执行时
# 调用函数
main()
# init_DB('租房.db') # 测试初始化数据库