YOLO系列博文:
———————————————————————————————————————————————
1 摘要
- 发表日期:2016年6月
- 作者:Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
- 论文:You Only Look Once: Unified, Real-Time Object Detection
- 代码:https://pjreddie.com/darknet/yolo/
- 主要优缺点:
- YOLO的简单结构,加上其新颖的全图像单次回归,使其比现有的物体检测器快得多,允许实时性能。
- 然而,虽然YOLO的表现比任何物体检测器都快,但与最先进的方法如快速R-CNN相比,定位误差更大。造成这种限制的主要原因有三个:
- 在网格单元中最多只能检测到两个相同类别的物体,限制了预测附近物体的能力;
- 在预测训练数据中未见的长宽比物体时很吃力;
- 由于下采样层,只能从粗略的物体特征中学习。
2 YOLO: You Only Look Once
YOLO是由Joseph Redmon等人提出的,发表于2016年的CVPR会议上,首次展示了一种针对物体检测的实时端到端方法。“YOLO”这个名字是“你只需要看一次”的缩写,意味着它能够通过网络的一次前向传递完成检测任务,这与之前的方法形成了鲜明的对比:早期方法要么使用滑动窗口后接分类器,对于每张图像需要运行数百乃至数千次;要么采用更先进的两步法,第一步检测可能包含物体的候选区域,第二步则对这些候选区域进行分类。此外,YOLO采用了基于回归的更为直接的输出方式来预测检测结果,而Fast R-CNN则使用了两个独立的输出——一个是用于概率估计的分类输出,另一个是用于框坐标预测的回归输出。
2.1 如何工作
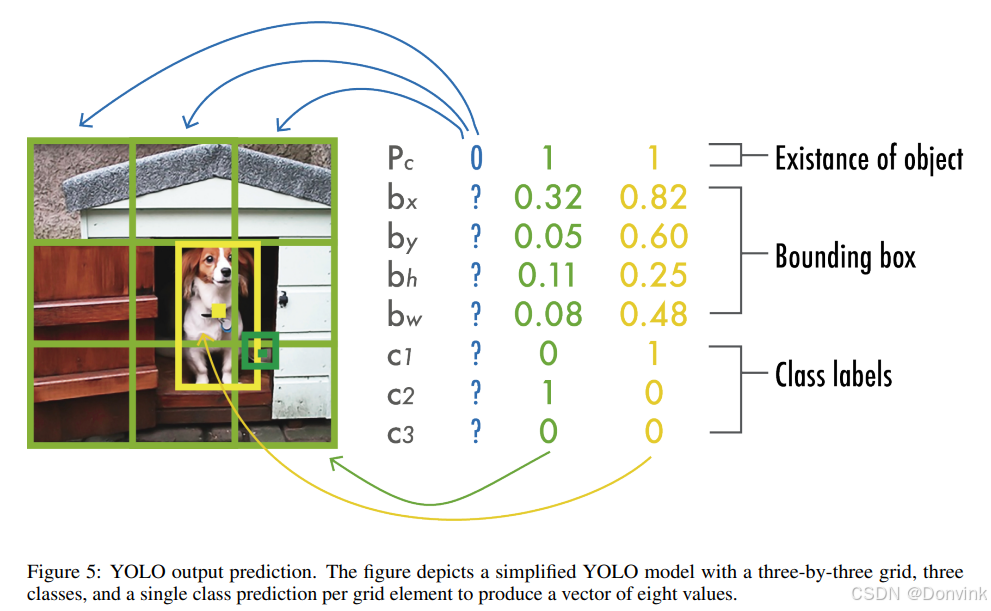
YOLOv1通过同时检测所有的边界框,统一了物体检测步骤。为了实现这一目标,YOLO将输入图像划每个边界框的预测由五个值组成:Pc、bx、by、bh、bw ,其中Pc是bounding box的置信度分数,反映了模型对bbox包含物体的置信度以及bbox的精确程度。bx和by坐标是方框相对于网格单元的中心,bh和bw是方框相对于整个图像的高度和宽度。YOLO的输出是一个S×S×(B×5+C)的张量,可以选择用非最大抑制(NMS) 来去除重复的检测结果。
在最初的YOLO论文中,作者使用了PASCAL VOC数据集,该数据集包含20个类别(C = 20);一个7×7(S = 7)网格最多预测两个类(B = 2),输出7×7×30预测结果。
YOLOv1在PASCAL VOC数据集上达到了63.4的AP。
2.2 网络架构
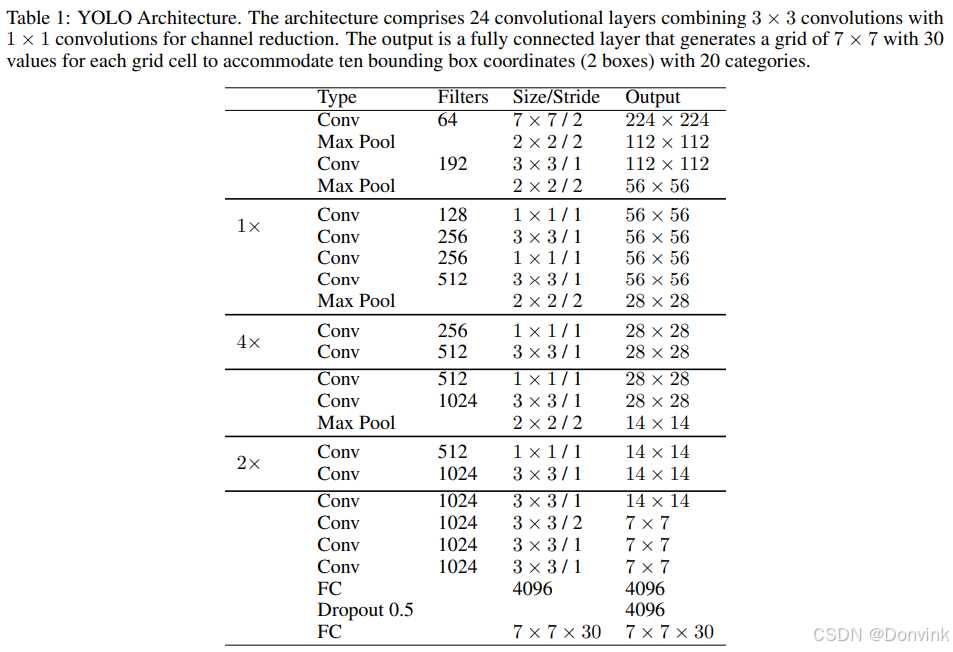
YOLOv1架构包括24个卷积层,然后是两个全连接层,用于预测bbox坐标和概率。除了最后一个层使用线性激活函数外,所有层都使用了漏整流线性单元激活。受GoogLeNet和Network in Network的启发,YOLO使用1×1卷积层来减少特征图的数量并保持相对较低的参数数量。作者还介绍了一个更轻的模型,称为Fast YOLO,由九个卷积层组成。
下表描述了YOLOv1的架构。
2.3 训练
作者使用ImageNet数据集在224x224的分辨率下对YOLO的前20层进行了预训练,然后用随机初始化的权重增加了最后四层,并在448x448的分辨率下用PASCAL VOC 2007和VOC 2012数据集对模型进行了微调,以增加细节,实现更准确的物体检测。对于增强,作者使用了最多为输入图像大小20%的随机缩放和平移,以及HSV色彩空间中上端系数为1.5的随机曝光和饱和度。
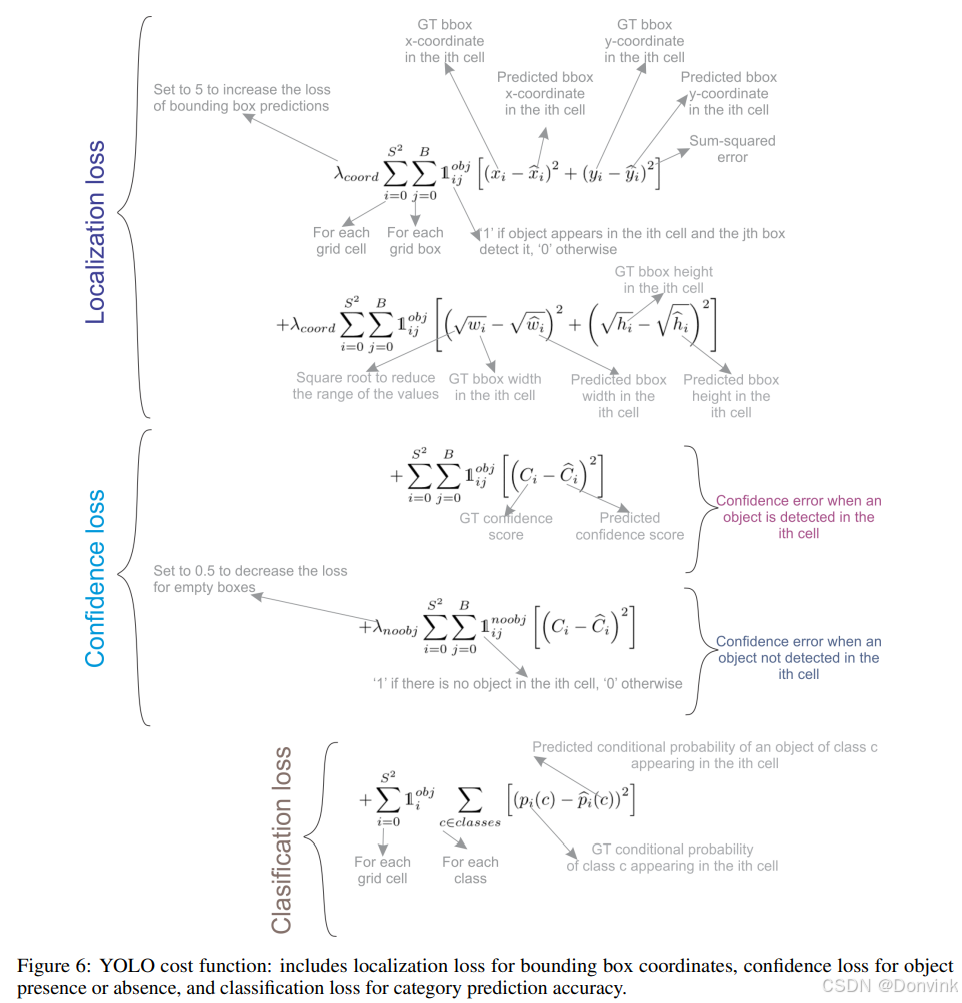
YOLOv1使用了一个由多个和平方误差组成的损失函数,如下图所示。在该损失函数中,λcoord = 5是一个比例因子,赋予边界框预测更多的重要性,而λnoobj = 0.5是一个比例因子,降低不包含物体的框的重要性。λnoobj = 0.5是一个比例因子,它降低了不包含物体的bbox的重要性。

2.4 优缺点
YOLO的简单结构,加上其新颖的全图像单次回归,使其比现有的物体检测器快得多,允许实时性能。
然而,虽然YOLO的表现比任何物体检测器都快,但与最先进的方法如快速R-CNN相比,定位误差更大。造成这种限制的主要原因有三个:
- 在网格单元中最多只能检测到两个相同类别的物体,限制了预测附近物体的能力;
- 在预测训练数据中未见的长宽比物体时很吃力;
- 由于下采样层,只能从粗略的物体特征中学习。