一.文本预处理
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
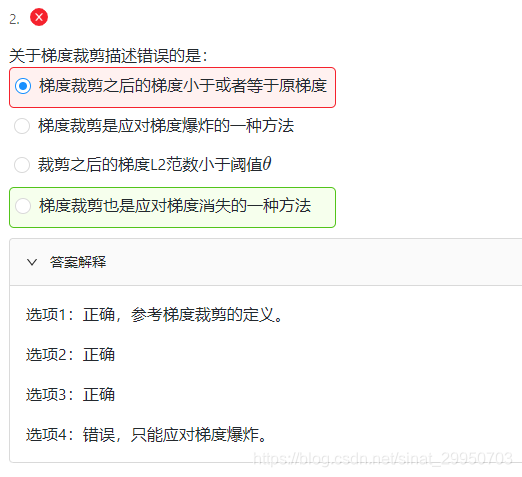
1.读入文本
2.分词
3.建立字典,将每个词映射到一个唯一的索引(index)
4.将文本从词的序列转换为索引的序列,方便输入模型
1.读入文本
import collections
import re
def read_time_machine():
# open 函数打开文本文件,创建文件对象f
with open('/home/kesci/input/timemachine7163/timemachine.txt', 'r') as f:
# f可迭代,for line in f一次读取一行
# 文件的每一行用strip函数 去掉前缀后缀的空白字符(即空格/换行符/制表符),并将所有大写字符转为小写字符
# 其中[^a-z]+ 表示 非小写英文字符组成的至少一个字符
lines = [re.sub('[^a-z]+', ' ', line.strip().lower()) for line in f]
return lines
lines = read_time_machine()
print('# sentences %d' % len(lines)) # 打印文件行数
'''
sentences 3221
'''
2.分词
我们对每个句子进行分词,也就是将一个句子划分成若干个词(token),转换为一个词的序列。
# sentences是一个字符串列表,每个字符串是一个句子
# token-标志:
# 如果是 word,做单词间的分词,每句以空格划分
# 如果是 char,做字符间的分词,将sentences列表的每个字符串(句子)转化为列表
# 无论是以何种方式,返回的是二维列表,一维是sentences的长度,二维是句子分词后的单词/字符的长度
def tokenize(sentences, token='word'):
"""Split sentences into word or char tokens"""
if token == 'word':
return [sentence.split(' ') for sentence in sentences]
elif token == 'char':
return [list(sentence) for sentence in sentences]
else:
print('ERROR: unkown token type '+token)
tokens = tokenize(lines)
tokens[0:2]
'''
[['the', 'time', 'machine', 'by', 'h', 'g', 'wells', ''], ['']]
'''
3.建立字典
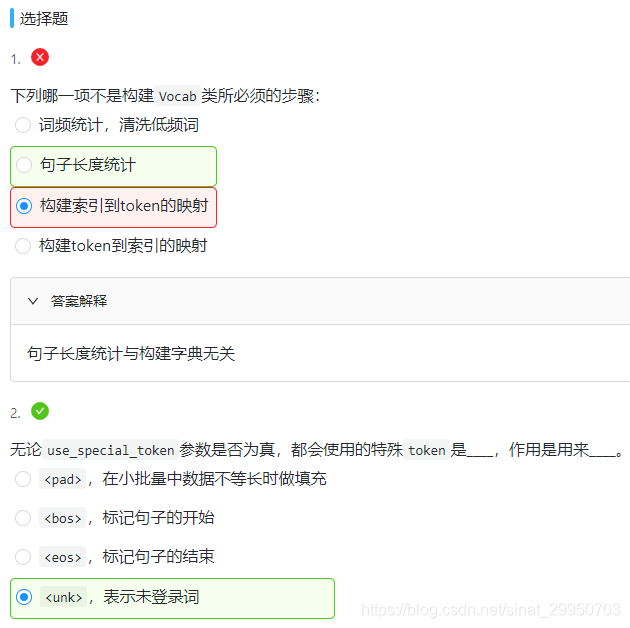
为了方便模型处理,我们需要将字符串转换为数字。因此我们需要先构建一个字典(vocabulary),将每个词映射到一个唯一的索引编号。
class Vocab(object):
# 参数介绍
# tokens: 为上一个分词函数的结果,二维列表
# min_freq-阈值:对出现次数小于该数值的词,忽略
# use_special_tokens: 是否要对使用特殊token
def __init__(self, tokens, min_freq=0, use_special_tokens=False):
# 统计词频
counter = count_corpus(tokens) # <key,value>: <词,词缀>
self.token_freqs = list(counter.items())
# 记录字典所需维护的token
self.idx_to_token = []
if use_special_tokens: # 如果该参数为真,引入4个pad,bos,eos,unk
# padding, begin of sentence, end of sentence, unknown
self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)
self.idx_to_token += ['<pad>', '<bos>', '<eos>', '<unk>']
else:
self.unk = 0
self.idx_to_token += ['<unk>']
# 如果该词的词频大于阈值 并且 该词不在idx_to_token中出现过
# 就取语料库中的词和词频 添加到idx_to_token 中,
self.idx_to_token += [token for token, freq in self.token_freqs
if freq >= min_freq and token not in self.idx_to_token]
self.token_to_idx = dict() # 词到索引的映射 定义为字典
# enumerate枚举idx_to_token中的每个词和每个词的下标
# 将词和每个词的下标添加到 token_to_idx中
for idx, token in enumerate(self.idx_to_token):
self.token_to_idx[token] = idx
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
def count_corpus(sentences):
tokens = [tk for st in sentences for tk in st]
return collections.Counter(tokens) # 返回一个字典,记录每个词的出现次数
4.将词转为索引
使用字典,我们可以将原文本中的句子从单词序列转换为索引序列
for i in range(8, 10):
print('words:', tokens[i])
print('indices:', vocab[tokens[i]])
'''
words: ['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him', '']
indices: [1, 2, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 0]
words: ['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and']
indices: [20, 21, 22, 23, 24, 16, 25, 26, 27, 28, 29, 30]
'''
5.用现有工具进行分词
我们前面介绍的分词方式非常简单,它至少有以下几个缺点:
标点符号通常可以提供语义信息,但是我们的方法直接将其丢弃了
类似“shouldn’t", “doesn’t"这样的词会被错误地处理
类似"Mr.”, "Dr."这样的词会被错误地处理
我们可以通过引入更复杂的规则来解决这些问题,但是事实上,有一些现有的工具可以很好地进行分词,我们在这里简单介绍其中的两个:spaCy和NLTK。
下面是一个简单的例子:
text = "Mr. Chen doesn't agree with my suggestion."
# <spaCy方法>
import spacy
nlp = spacy.load('en_core_web_sm') # 导入en的language
doc = nlp(text)
print([token.text for token in doc])
'''
['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']
'''
# <NLTK方法>
from nltk.tokenize import word_tokenize
from nltk import data
data.path.append('/home/kesci/input/nltk_data3784/nltk_data')
print(word_tokenize(text))
'''
['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']
'''
Y = W X + b Y = WX+b Y=WX+b
二.语言模型

1.介绍

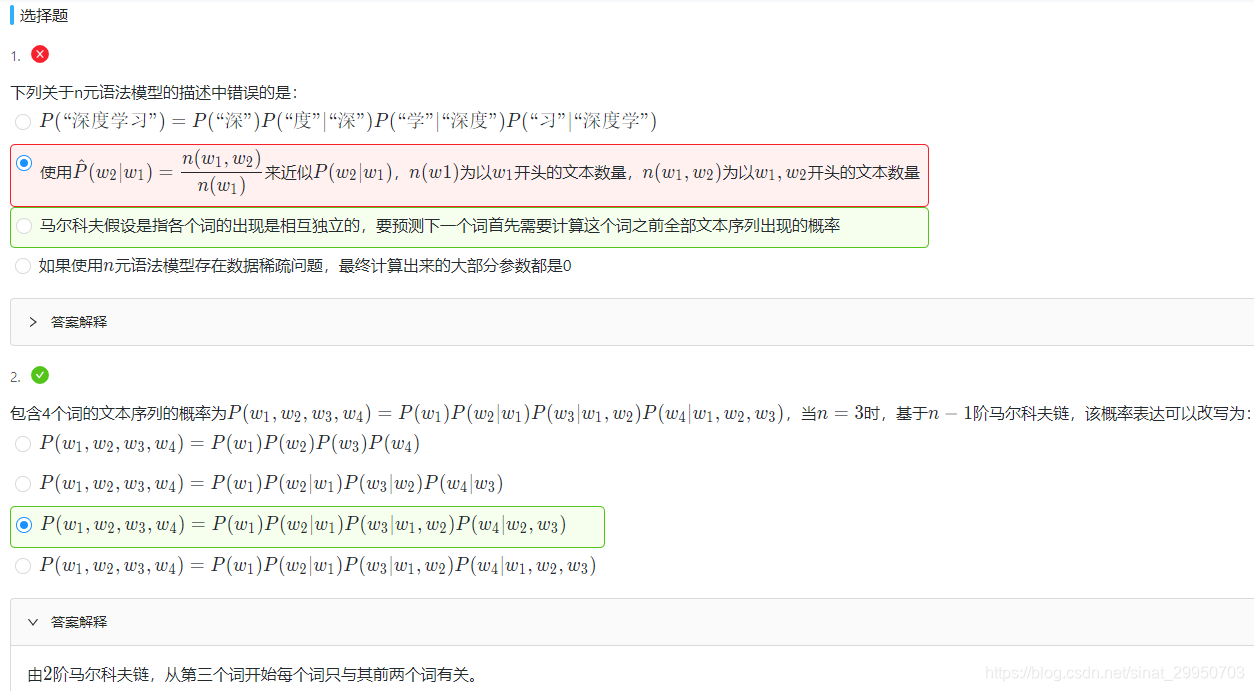
2.n元语法


3.语言模型数据集
读取数据集
with open('/home/kesci/input/jaychou_lyrics4703/jaychou_lyrics.txt') as f:
corpus_chars = f.read()
print(len(corpus_chars)) # 共6万多个字符
print(corpus_chars[: 40]) # 输出前40个字符
corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ') # 将换行回车 换成空格
corpus_chars = corpus_chars[: 10000] # 只保留前1万个字符 作为语料库
'''
63282
想要有直升机
想要和你飞到宇宙去
想要和你融化在一起
融化在宇宙里
我每天每天每
'''
建立字符索引
idx_to_char = list(set(corpus_chars)) # 去重,转为列表,得到索引到字符的映射
# 枚举idx_to_char中的每个字符char和下标i,构造一个字典
char_to_idx = {char: i for i, char in enumerate(idx_to_char)} # 字符到索引的映射
vocab_size = len(char_to_idx) # 记录字典的大小
print(vocab_size)
# 将语料库中的每个字符转化为索引,得到一个索引的序列
corpus_indices = [char_to_idx[char] for char in corpus_chars]
# 取出索引序列的前20个索引
sample = corpus_indices[: 20]
# 取sample中索引对应的字符,
print('chars:', ''.join([idx_to_char[idx] for idx in sample]))
print('indices:', sample)
'''
1027
chars: 想要有直升机 想要和你飞到宇宙去 想要和
indices: [1022, 648, 1025, 366, 208, 792, 199, 1022, 648, 641, 607, 625, 26, 155, 130, 5, 199, 1022, 648, 641]
'''
将前两个代码整个到函数中
定义函数load_data_jay_lyrics,在后续章节中直接调用。
def load_data_jay_lyrics():
with open('/home/kesci/input/jaychou_lyrics4703/jaychou_lyrics.txt') as f:
corpus_chars = f.read()
corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ')
corpus_chars = corpus_chars[0:10000]
idx_to_char = list(set(corpus_chars))
char_to_idx = dict([(char, i) for i, char in enumerate(idx_to_char)])
vocab_size = len(char_to_idx)
corpus_indices = [char_to_idx[char] for char in corpus_chars]
return corpus_indices, char_to_idx, idx_to_char, vocab_size
时序数据的采样
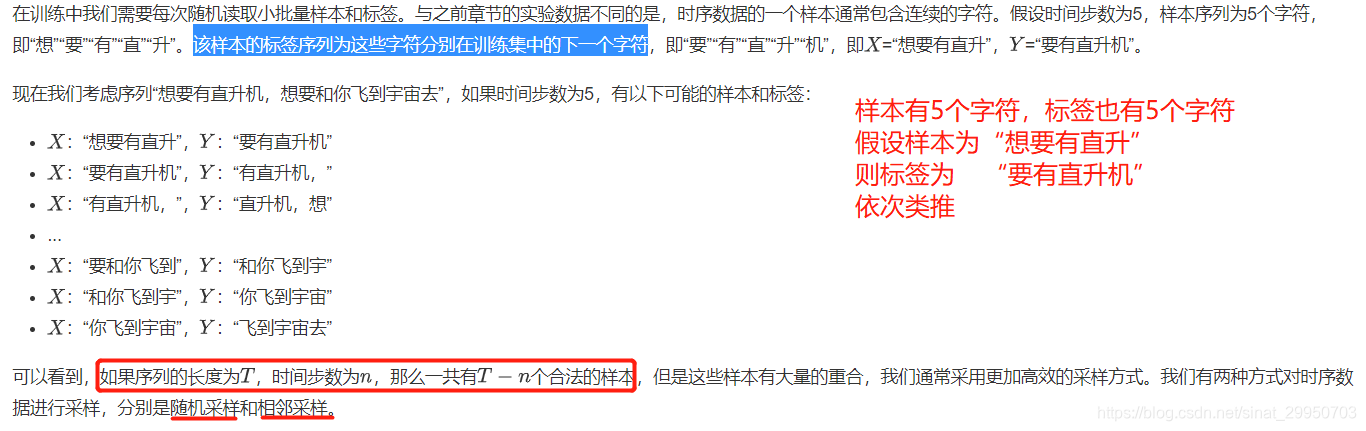
随机采样
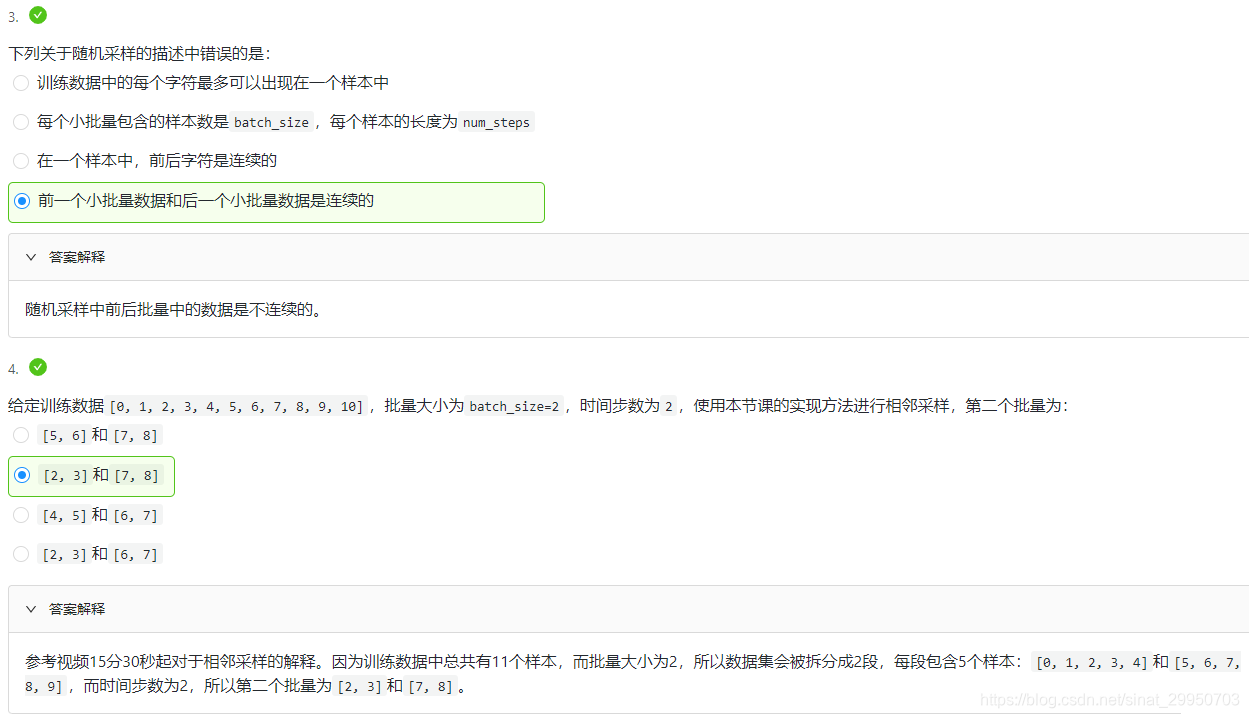
每次从数据里随机采样一个小批量。其中批量大小batch_size是每个小批量的样本数,num_steps是每个样本所包含的时间步数。 在随机采样中,每个样本是原始序列上任意截取的一段序列,相邻的两个随机小批量在原始序列上的位置不一定相毗邻。
如下图所示,若batch_size为2,取两次,时间步数为6
如 原数据为:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
划分为:
[ 0, 1, 2, 3, 4, 5] [ 6, 7, 8, 9, 10, 11] [12, 13, 14, 15, 16, 17] [18, 19, 20, 21, 22, 23]

import torch
import random
'''
参数介绍
corpus_indices 序列
batch_size 批量大小
num_steps 时间步数
device 是否使用GPU
'''
def data_iter_random(corpus_indices, batch_size, num_steps, device=None):
# 计算序列能划分成几个样本:
# 减1是因为对于长度为n的序列,X最多只有包含其中的前n-1个字符,最后一个字符给Y使用
num_examples = (len(corpus_indices) - 1) // num_steps # 下取整,得到不重叠情况下的样本个数
example_indices = [i * num_steps for i in range(num_examples)] # 记录每个样本的第一个字符在corpus_indices中的下标.如 0 6 12 18
random.shuffle(example_indices) # 随机采样
# 返回从i开始的长为num_steps的序列:
def _data(i):
# 如取得i为6,则返回【ghijkl】
return corpus_indices[i: i + num_steps]
# 是否使用GPU:
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
for i in range(0, num_examples, batch_size):
# 每次选出batch_size个随机样本
batch_indices = example_indices[i: i + batch_size] # 当前batch的各个样本的首字符的下标
# batch_size=2
# 第一批次
# batch_indices = example_indices[0] = 0
# batch_indices = example_indices[1] = 6
# 第二批次
# batch_indices = example_indices[2] = 12
# batch_indices = example_indices[3] = 18
X = [_data(j) for j in batch_indices]
# 返回从0开始的长为6的序列 [0,1,2,3,4,5]
# 返回从6开始的长为6的序列 [6,7,8,9,10,11]
# 返回从12开始的长为6的序列 [12,13,14,15,16,17]
# 返回从18开始的长为6的序列 [18,19,20,21,22,23]
Y = [_data(j + 1) for j in batch_indices]
# 返回从1开始的长为6的序列 [1,2,3,4,5,6]
# 返回从7开始的长为6的序列 [7,8,9,10,11,12]
# 返回从13开始的长为6的序列 [13,14,15,16,17,18]
# 返回从19开始的长为6的序列 [19,20,21,22,23,24]
yield torch.tensor(X, device=device), torch.tensor(Y, device=device)
my_seq = list(range(30))
for X, Y in data_iter_random(my_seq, batch_size=2, num_steps=6):
print('X: ', X, '\nY:', Y, '\n')
'''
X: tensor([[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17]])
Y: tensor([[ 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18]])
X: tensor([[ 0, 1, 2, 3, 4, 5],
[18, 19, 20, 21, 22, 23]])
Y: tensor([[ 1, 2, 3, 4, 5, 6],
[19, 20, 21, 22, 23, 24]])
'''
相邻采样
在相邻采样中,相邻的两个随机小批量在原始序列上的位置相毗邻。
如下图所示,batch_size为2,每个颜色长度为6
如 原数据为:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
先划分为:
[[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
[15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]]
再划分为
[[ [ 0, 1, 2, 3, 4, 5, 6], [7, 8, 9, 10, 11, 12, 13, 14]],
[ [15, 16, 17, 18, 19, 20], [21, 22, 23, 24, 25, 26, 27] ]]

def data_iter_consecutive(corpus_indices, batch_size, num_steps, device=None):
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
corpus_len = len(corpus_indices) // batch_size * batch_size # 保留下来的序列的长度
corpus_indices = corpus_indices[: corpus_len] # 仅保留前corpus_len个字符
indices = torch.tensor(corpus_indices, device=device)
# resize成(batch_size, )即(2,15)
indices = indices.view(batch_size, -1)
# batch_num = (15-1)/6 = 2
batch_num = (indices.shape[1] - 1) // num_steps
for i in range(batch_num):
i = i * num_steps
X = indices[:, i: i + num_steps]
Y = indices[:, i + 1: i + num_steps + 1]
yield X, Y
'''
# 当i = 0
i = 0
X = indices[0][0:6] = [0,1,2,3,4,5]
Y = indices[0][1:7] = [1,2,3,4,5,6]
X = indices[1][0:6] = [15,16,17,18,19,20]
Y = indices[1][1:7] = [16,17,18,19,20,21]
# 当i = 1
i = 6
X = indices[0][6:11] = [6,7,8,9,10,11]
Y = indices[0][7:12] = [7,8,9,10,11,12]
X = indices[1][6:11] = [21,22,23,24,25,26]
Y = indices[1][7:12] = [22,23,24,25,26,27]
'''
'''
corpus_indices:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
indices:
tensor([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
[15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]])
'''
同样的设置下,打印相邻采样每次读取的小批量样本的输入X和标签Y。相邻的两个随机小批量在原始序列上的位置相毗邻。
for X, Y in data_iter_consecutive(my_seq, batch_size=2, num_steps=6):
print('X: ', X, '\nY:', Y, '\n')
'''
X: tensor([[ 0, 1, 2, 3, 4, 5],
[15, 16, 17, 18, 19, 20]])
Y: tensor([[ 1, 2, 3, 4, 5, 6],
[16, 17, 18, 19, 20, 21]])
X: tensor([[ 6, 7, 8, 9, 10, 11],
[21, 22, 23, 24, 25, 26]])
Y: tensor([[ 7, 8, 9, 10, 11, 12],
[22, 23, 24, 25, 26, 27]])
'''
三.循环神经网络基础
1.循环神经网络 RNN
2.循环神经网络的构造

3.从零开始实现循环神经网络
我们先尝试从零开始实现一个基于字符级循环神经网络的语言模型,这里我们使用周杰伦的歌词作为语料,首先我们读入数据:
import torch
import torch.nn as nn
import time
import math
import sys
sys.path.append("/home/kesci/input")
import d2l_jay9460 as d2l
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
one-hot向量

def one_hot(x, n_class, dtype=torch.float32):
'''
参数介绍:
x 一维向量,每个元素都是索引
n_class 字典大小
dtype 指定返回的数值类型
假设x.shape[0]为n,则返回的result为[n,n_class]大小的矩阵
'''
# 初始化为全0矩阵
result = torch.zeros(x.shape[0], n_class, dtype=dtype, device=x.device) # shape: (n, n_class)
# 将x转为n[n,1]大小,字符的索引处置为1,其他为0
result.scatter_(1, x.long().view(-1, 1), 1) # result[i, x[i, 0]] = 1
return result
x = torch.tensor([0, 2])
x_one_hot = one_hot(x, vocab_size)
print(x_one_hot)
print(x_one_hot.shape)
print(x_one_hot.sum(axis=1))
'''
tensor([[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 1., ..., 0., 0., 0.]])
torch.Size([2, 1027])
tensor([1., 1.])
'''

def to_onehot(X, n_class):
'''
参数介绍:
X 小批量大小
n_class 字典大小
'''
# 每次取出X的一列
return [one_hot(X[:, i], n_class) for i in range(X.shape[1])]
X = torch.arange(10).view(2, 5)
inputs = to_onehot(X, vocab_size)
print(len(inputs), inputs[0].shape)
'''
5 torch.Size([2, 1027])
'''
初始化模型参数
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
# num_inputs: d
# num_hiddens: h, 隐藏单元的个数是超参数
# num_outputs: q
def get_params():
def _one(shape):
param = torch.zeros(shape, device=device, dtype=torch.float32)
nn.init.normal_(param, 0, 0.01)
return torch.nn.Parameter(param)
# 权重参数随机初始化,偏置参数置0
# 隐藏层参数
W_xh = _one((num_inputs, num_hiddens))
W_hh = _one((num_hiddens, num_hiddens))
b_h = torch.nn.Parameter(torch.zeros(num_hiddens, device=device))
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device))
return (W_xh, W_hh, b_h, W_hq, b_q)
定义模型
函数rnn用循环的方式依次完成循环神经网络每个时间步的计算。
def rnn(inputs, state, params):
# inputs和outputs皆为num_steps个形状为(batch_size, vocab_size)的矩阵
W_xh, W_hh, b_h, W_hq, b_q = params # 模型参数
H, = state # 隐藏层状态
outputs = [] # 空列表
for X in inputs:
# 各个时间步的状态H
H = torch.tanh(torch.matmul(X, W_xh) + torch.matmul(H, W_hh) + b_h)
# 各个时间步的输出Y,并追加到outputs中
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,)
函数init_rnn_state初始化隐藏变量,这里的返回值是一个元组。
# num_hiddens隐藏层个数
def init_rnn_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
做个简单的测试来观察输出结果的个数(时间步数),以及第一个时间步的输出层输出的形状和隐藏状态的形状。
print(X.shape)
print(num_hiddens)
print(vocab_size)
state = init_rnn_state(X.shape[0], num_hiddens, device)
inputs = to_onehot(X.to(device), vocab_size)
params = get_params()
outputs, state_new = rnn(inputs, state, params)
print(len(inputs), inputs[0].shape)
print(len(outputs), outputs[0].shape)
print(len(state), state[0].shape)
print(len(state_new), state_new[0].shape)
'''
torch.Size([2, 5])
256
1027
5 torch.Size([2, 1027])
5 torch.Size([2, 1027])
1 torch.Size([2, 256])
1 torch.Size([2, 256])
'''
裁剪梯度

'''
参数介绍
params 模型的所有参数
theta 阈值
norm 即所有参数的梯度
'''
def grad_clipping(params, theta, device):
norm = torch.tensor([0.0], device=device)
for param in params:
norm += (param.grad.data ** 2).sum()
norm = norm.sqrt().item()
if norm > theta:
for param in params:
param.grad.data *= (theta / norm)
定义预测函数
以下函数基于前缀prefix(含有数个字符的字符串)来预测接下来的 num_chars 个字符。这个函数稍显复杂,其中我们将循环神经单元 rnn 设置成了函数参数,这样在后面小节介绍其他循环神经网络时能重复使用这个函数。
# 先处理prefix,让隐藏状态H记录了前缀信息
def predict_rnn(prefix, num_chars, rnn, params, init_rnn_state,
num_hiddens, vocab_size, device, idx_to_char, char_to_idx):
# num_hiddens = 256
# vocab_size = 1027
state = init_rnn_state(1, num_hiddens, device) # 构造初始化状态
output = [char_to_idx[prefix[0]]] # 定义output列表,记录prefix加上预测的num_chars个字符
for t in range(num_chars + len(prefix) - 1):
# 将上一时间步的输出(output的最后一个字符)作为当前时间步的输入
X = to_onehot(torch.tensor([[output[-1]]], device=device), vocab_size) # X尺寸为[1,1027]
# 计算当前时间步的输出 和 新的隐藏状态
(Y, state) = rnn(X, state, params)
# 下一个时间步的输入是prefix里的字符或者当前的最佳预测字符
if t < len(prefix) - 1:
# 对前 len(prefix)-1 个字符,只要把prefix的下一个字符添加到output当中
output.append(char_to_idx[prefix[t + 1]])
else:
# 找到Y[0]中最大(即为1)的列,将item转为int?添加到output中
output.append(Y[0].argmax(dim=1).item())
# 对output中每个字符索引转换为字符
return ''.join([idx_to_char[i] for i in output])
我们先测试一下predict_rnn函数。我们将根据前缀“分开”创作长度为10个字符(不考虑前缀长度)的一段歌词。因为模型参数为随机值,所以预测结果也是随机的。
predict_rnn('分开', 10, rnn, params, init_rnn_state, num_hiddens, vocab_size,
device, idx_to_char, char_to_idx)
'''
'分开濡时食提危踢拆田唱母'
'''
困惑度
我们通常使用困惑度(perplexity)来评价语言模型的好坏。即“softmax回归”一节中提到的 交叉熵损失函数。困惑度是对交叉熵损失函数做指数运算后得到的值。特别地,
最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
显然,任何一个有效模型的困惑度必须小于类别个数。在本例中,困惑度必须小于词典大小vocab_size。
定义模型训练函数
跟之前章节的模型训练函数相比,这里的模型训练函数有以下几点不同:
使用困惑度评价模型。
在迭代模型参数前裁剪梯度。
对时序数据采用不同采样方法将导致隐藏状态初始化的不同。
def train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, is_random_iter, num_epochs, num_steps,
lr, clipping_theta, batch_size, pred_period,
pred_len, prefixes):
if is_random_iter:
data_iter_fn = d2l.data_iter_random # 随机采样
else:
data_iter_fn = d2l.data_iter_consecutive # 相邻采样
params = get_params() # 获取参数
loss = nn.CrossEntropyLoss() # 交叉熵损失函数
for epoch in range(num_epochs):
# 在每个epoch开始时候,就要判断是什么采样方式
if not is_random_iter: # 如使用相邻采样,在epoch开始时初始化隐藏状态
state = init_rnn_state(batch_size, num_hiddens, device)
l_sum, n, start = 0.0, 0, time.time() # 为了打印一些信息
# data_iter_fn函数 需要3个参数(序列,批量大小,时间步数),得到data_iter 生成器
data_iter = data_iter_fn(corpus_indices, batch_size, num_steps, device)
for X, Y in data_iter:
# 在每个batch开始时候,也要判断是什么采样方式
if is_random_iter: # 如使用随机采样,在每个小批量更新前初始化隐藏状态
state = init_rnn_state(batch_size, num_hiddens, device)
else: # 否则需要使用detach函数从计算图分离隐藏状态
for s in state:
s.detach_()
# inputs是num_steps个形状为(batch_size, vocab_size)的矩阵,通过to_onehot函数获得
inputs = to_onehot(X, vocab_size)
# outputs有num_steps个形状为(batch_size, vocab_size)的矩阵,通过rnn函数 前向计算获得
(outputs, state) = rnn(inputs, state, params)
# 拼接之后形状为(num_steps * batch_size, vocab_size)
outputs = torch.cat(outputs, dim=0)
# 转置的原因是:
# output形状是(num_steps * batch_size, vocab_size)
# Y的形状是(batch_size, n um_steps),转置后可变成(num_steps * batch_size,)的向量
# 这样跟输出的行一一对应,进行损失函数计算
y = torch.flatten(Y.T)
# 使用交叉熵损失计算平均分类误差
l = loss(outputs, y.long())
# 梯度清0
if params[0].grad is not None: # 如果不是第一个batch
for param in params: # 对梯度的每一个参数
param.grad.data.zero_() # 清零
# 后向计算
l.backward()
grad_clipping(params, clipping_theta, device) # 裁剪梯度
# 用sgd更新参数
d2l.sgd(params, lr, 1) # 因为误差已经取过均值,梯度不用再做平均
# 更新 l_sum 和 n
l_sum += l.item() * y.shape[0]
n += y.shape[0]
# 打印一些信息
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, math.exp(l_sum / n), time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn(prefix, pred_len, rnn, params, init_rnn_state,
num_hiddens, vocab_size, device, idx_to_char, char_to_idx))
训练模型并创作歌词
现在我们可以训练模型了。首先,设置模型超参数。我们将根据前缀“分开”和“不分开”分别创作长度为50个字符(不考虑前缀长度)的一段歌词。我们每过50个迭代周期便根据当前训练的模型创作一段歌词。
num_epochs, num_steps, batch_size, lr, clipping_theta = 250, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
下面采用 随机采样 训练模型并创作歌词。
train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, True, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
'''
epoch 50, perplexity 65.808092, time 0.78 sec
- 分开 我想要这样 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我
- 不分开 别颗去 一颗两 三颗四 一颗四 三颗四 一颗四 一颗四 一颗四 一颗四 一颗四 一颗四 一颗四 一
epoch 100, perplexity 9.794889, time 0.72 sec
- 分开 一直在美留 谁在它停 在小村外的溪边 默默等 什么 旧你在依旧 我有儿有些瘦 世色我遇见你是一场
- 不分开吗 我不能再想 我不 我不 我不 我不 我不 我不 我不 我不 我不 我不 我不 我不 我不 我不
epoch 150, perplexity 2.772557, time 0.80 sec
- 分开 有直在不妥 有话它停留 蜥蝪横怕落 不爽就 旧怪堂 是属于依 心故之 的片段 有一些风霜 老唱盘
- 不分开吗 然后将过不 我慢 失些 如 静里回的太快 想通 却又再考倒我 说散 你想很久了吧?的我 从等
epoch 200, perplexity 1.601744, time 0.73 sec
- 分开 那只都它满在我面妈 捏成你的形状啸而过 或愿说在后能 让梭时忆对着轻轻 我想就这样牵着你的手不放开
- 不分开期 然后将过去 慢慢温习 让我爱上你 那场悲剧 是你完美演出的一场戏 宁愿心碎哭泣 再狠狠忘记 不是
epoch 250, perplexity 1.323342, time 0.78 sec
- 分开 出愿段的哭咒的天蛦丘好落 拜托当血穿永杨一定的诗篇 我给你的爱写在西元前 深埋在美索不达米亚平原
- 不分开扫把的胖女巫 用拉丁文念咒语啦啦呜 她养的黑猫笑起来像哭 啦啦啦呜 我来了我 在我感外的溪边河口默默
'''
接下来采用 相邻采样 训练模型并创作歌词。
train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
'''
epoch 50, perplexity 60.294393, time 0.74 sec
- 分开 我想要你想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我
- 不分开 我想要你 你有了 别不我的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我
epoch 100, perplexity 7.141162, time 0.72 sec
- 分开 我已要再爱 我不要再想 我不 我不 我不要再想 我不 我不 我不要 爱情我的见快就像龙卷风 离能开
- 不分开柳 你天黄一个棍 后知哈兮 快使用双截棍 哼哼哈兮 快使用双截棍 哼哼哈兮 快使用双截棍 哼哼哈兮
epoch 150, perplexity 2.090277, time 0.73 sec
- 分开 我已要这是你在著 不想我都做得到 但那个人已经不是我 没有你在 我却多难熬 没有你在我有多难熬多
- 不分开觉 你已经离 我想再好 这样心中 我一定带我 我的完空 不你是风 一一彩纵 在人心中 我一定带我妈走
epoch 200, perplexity 1.305391, time 0.77 sec
- 分开 我已要这样牵看你的手 它一定实现它一定像现 载著你 彷彿载著阳光 不管到你留都是晴天 蝴蝶自在飞力
- 不分开觉 你已经离开我 不知不觉 我跟了这节奏 后知后觉 又过了一个秋 后知后觉 我该好好生活 我该好好生
epoch 250, perplexity 1.230800, time 0.79 sec
- 分开 我不要 是你看的太快了悲慢 担心今手身会大早 其么我也睡不着 昨晚梦里你来找 我才 原来我只想
- 不分开觉 你在经离开我 不知不觉 你知了有节奏 后知后觉 后知了一个秋 后知后觉 我该好好生活 我该好好生
'''
4.循环神经网络的简介实现
定义模型

rnn_layer = nn.RNN(input_size=vocab_size, hidden_size=num_hiddens)
num_steps, batch_size = 35, 2
X = torch.rand(num_steps, batch_size, vocab_size)
state = None
Y, state_new = rnn_layer(X, state)
print(Y.shape, state_new.shape)
'''
torch.Size([35, 2, 256]) torch.Size([1, 2, 256])
'''
我们定义一个完整的基于循环神经网络的语言模型。
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size):
super(RNNModel, self).__init__()
self.rnn = rnn_layer
# rnn_layer若为双向,就乘2,否则乘1
self.hidden_size = rnn_layer.hidden_size * (2 if rnn_layer.bidirectional else 1)
self.vocab_size = vocab_size # 字典大小
self.dense = nn.Linear(self.hidden_size, vocab_size) # 线性层 在每个时间步给个输出
def forward(self, inputs, state):
# inputs.shape: (batch_size, num_steps)
X = to_onehot(inputs, vocab_size)
# stack 串起来
X = torch.stack(X) # X.shape: (num_steps, batch_size, vocab_size)
# hiddens: 时间步的隐藏状态 state:新的状态
hiddens, state = self.rnn(X, state)
# hiddens.shape: (num_steps * batch_size, hidden_size)三维转为(-1,hidden_size)
hiddens = hiddens.view(-1, hiddens.shape[-1])
output = self.dense(hiddens) # 做线性变换后就得到output
return output, state
类似的,我们需要实现一个预测函数,与前面的区别在于前向计算和初始化隐藏状态。
def predict_rnn_pytorch(prefix, num_chars, model, vocab_size, device, idx_to_char,
char_to_idx):
state = None
output = [char_to_idx[prefix[0]]] # output记录prefix加上预测的num_chars个字符
for t in range(num_chars + len(prefix) - 1):
X = torch.tensor([output[-1]], device=device).view(1, 1)
(Y, state) = model(X, state) # 前向计算不需要传入模型参数
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(Y.argmax(dim=1).item())
return ''.join([idx_to_char[i] for i in output])
使用权重为随机值的模型来预测一次。
model = RNNModel(rnn_layer, vocab_size).to(device)
predict_rnn_pytorch('分开', 10, model, vocab_size, device, idx_to_char, char_to_idx)
'''
''分开文空戏白菸液空汹菸诗''
'''
接下来实现训练函数,这里只使用了相邻采样。
def train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes):
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
model.to(device)
for epoch in range(num_epochs):
l_sum, n, start = 0.0, 0, time.time()
data_iter = d2l.data_iter_consecutive(corpus_indices, batch_size, num_steps, device) # 相邻采样
state = None
for X, Y in data_iter:
if state is not None:
# 使用detach函数从计算图分离隐藏状态
if isinstance (state, tuple): # LSTM, state:(h, c)
state[0].detach_()
state[1].detach_()
else:
state.detach_()
(output, state) = model(X, state) # output.shape: (num_steps * batch_size, vocab_size)
y = torch.flatten(Y.T)
l = loss(output, y.long())
optimizer.zero_grad()
l.backward()
grad_clipping(model.parameters(), clipping_theta, device)
optimizer.step()
l_sum += l.item() * y.shape[0]
n += y.shape[0]
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, math.exp(l_sum / n), time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn_pytorch(
prefix, pred_len, model, vocab_size, device, idx_to_char,
char_to_idx))
训练模型
num_epochs, batch_size, lr, clipping_theta = 250, 32, 1e-3, 1e-2
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
'''
epoch 50, perplexity 11.872542, time 0.41 sec
- 分开 我不要你想你 我不要你 你是我不多 我不多这样 我不要你想你我不多 我 我不了你 你我想你 爱你在
- 不分开 你想要你的手不放开 我不到你 你我不要 你是我不多 想 我不要你想你我不多 我 我不了你 你我不
epoch 100, perplexity 1.315003, time 0.42 sec
- 分开 在这样牵着你的手不放开 爱可不可以简简单单没有伤害 你 靠着我的肩膀 你 在我胸口睡著 像这样的生
- 不分开 你这样的担忧 唱着歌 一直走 我想就这样牵着你的手不放开 爱可不可以简简单单没有伤害 你 靠着我的
epoch 150, perplexity 1.069648, time 0.47 sec
- 分开 在这样牵着你的手不放开 爱能不能够永 单纯没有 哀 我 想带你骑单车 我 想和你看棒球 想这样没担
- 不分开 我不能拿简 我妈 我不能我不你 一个会不 能的可以女神语沉默 娘子却依旧每日折一枝杨柳 在小村外
epoch 200, perplexity 1.034269, time 0.41 sec
- 分开 在我痛 难道 手的会有泥鳅简话 是一场悲剧 是它我遇见你的让它就疼的可爱女人 透明的让我感动的可爱
- 不分开 我不能拿不 我觉 我跟了这节奏 后知后觉 又过了一个秋 后知后觉 我该好好生活 我该好好生活 不
epoch 250, perplexity 1.020345, time 0.42 sec
- 分开 在我痛 难道 手不会痛吗 其实我回家你的爱写在西元前 深埋在美索不达米亚平原 用楔形文字刻下了永远
- 不分开 我不能拿爱 我不 带过 直不 痛是你这样痛 有话不以 疗伤止让切就红的可爱女人 温柔的让我心疼的
'''
课后习题
文本预处理
语言模型
循环神经网络基础