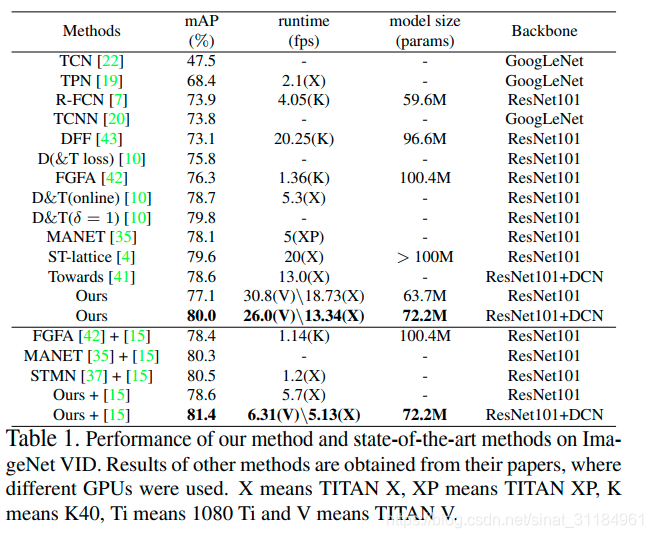
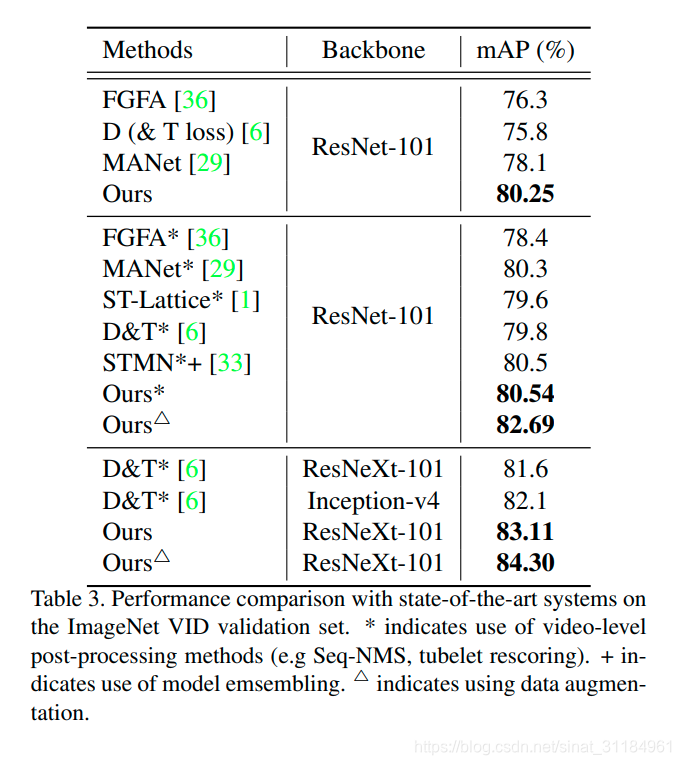
最近由于一些原因在调研视频目标检测现状,从15年ImageNet VID出来后就陆陆续续有做视频目标检测的文章了,到目前为止每年的文章出的都不算多,我就简单记录一下近几年的文章。下面这张是我画的图,简单分类一下。Key Frame就是只在某些关键帧上提feature,然后利用一些光流的信息将关键帧的信息映射到非关键帧,来做非关键帧的检测。自己随手做的记录,很糙,望谅解。。
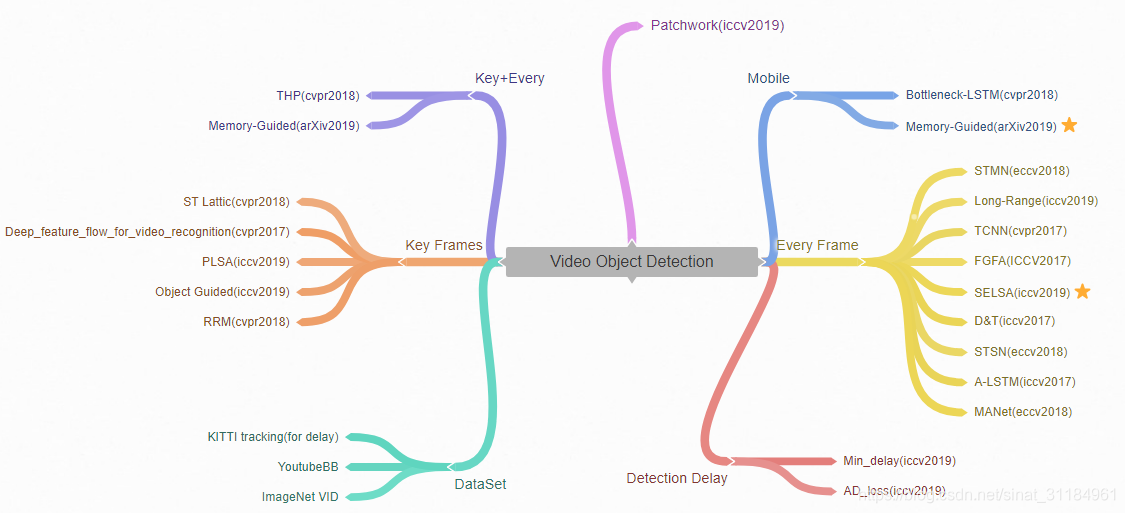
VOD
- TCNN:集成了很多算法,包括光流,跟踪以及图片检测算法,时间很慢,利用了matlab+caffe+python,检测出来的矩形框冗余,及其慢,开源;
- D&T(iccv2017):将图片检测算法和目标跟踪中的互相关操作相结合,在检测网络中引入了互相关的损失函数,利用互相关操作来定位,代码依旧是caffe,无法复现,开源;
- FGFA(iccv2017):利用了flownet计算帧间的光流信息,然后根据这些光流,将当前测试帧前后帧的特征都融合到当前帧上,然后利用这个整合后的信息做检测和分类,速度很慢,开源;
- TD-Graph LSTM(iccv2017) : 利用的不是bbox,而是利用运动的信息来作为监督信号,做弱监督的视频目标检测,测试也不是常规的VID,而是Charades,其中有运动的信息;
- Associated LSTM(iccv2017) :提出了一个LSTM来融合多帧的特征,提出了一个Associated loss来控制融合,实现视频中不同帧中同一个物体的关联,未开源;
- Deep Feature Flow for Video Recognition(cvpr2017) : 他们认为同一个物体在相邻帧之间产生的特征是相似的,于是利用一个轻量的光流网络计算帧之间的关系,然后将关键帧的特征前后传播,不需要在每个帧都提feature,这样使得检测的速度加快,但是精度有一定损失,开源;
- RRM(cvpr2018):这篇文章说是通过整合多帧的信息来加快目标检测,利用相邻帧之间的关系来减少很多冗余的计算,通过相邻帧之间的计算共享,来减少总的运算次数,他们可以在不用任何训练的情况下,加快网络的速度;
- Bottleneck-LSTM(cvpr2018): 在移动端以15FPS运行的视频目标检测器,每帧都做检测,提出的轻量的Bottleneck-LSTM 可以加快帧之间的feature的传播和refine,开源;
- THP(cvpr2018) : 自适应的把序列中的每一帧分成关键帧和非关键帧,对于关键帧和非关键帧做不同的操作,特征的融合是历史帧的特征不断的加入到当前帧中,对于非关键帧,会根据其物体本身的运动程度来给它的特征加掩码,减少计算量,同样也会把关键帧的信息给它,一起做检测分类,速度15.22FPS;
- STSN(eccv2018):对所有帧提取特征,利用可变形卷积对这些特征图进行时空采样,然后根据权重把这些特征加起来,去做最后的检测,没有用到光流网络;
- STMN(eccv2018) : 提出一个时空记忆网络,来建模长时间的目标外观和运动信息,先是在每个帧上提特征,然后用两个STMM将当前帧前后的特征都聚合到当前帧来,开源;
- Scale-Time Lattice(cvpr2018): 平衡精度和速度,将图片检测用在稀疏的关键帧上,用一些简单高效的网络在时间和空间两个维度上不断传播和修正这些检测结果,不开源,79.6mAP(20fps), 79.0mAP(62fps);
- MANet(eccv2018): 对R-FCN这类算法做的改进,对FGFA的改进,分别提取相邻帧的特征,用光流做对齐,分别做了pixel-level和instance-level层面上的对齐,将多帧的特征直接平均得到当前帧的特征;
- Integrated_VID(arXiv2018) : 微软的文章,说是结合了多目标跟踪中的东西,跟之前用前后帧来融合特征的方式不一样,他们维护一个bbox的池,里面放的是当前帧之前的帧的结果,将这些结果与当前的帧做关联,然后利用之前帧的结果来辅助当前帧的分类与评分,未开源;
- SELSA(iccv2019):在FGFA基础上做的优化,也是把不同帧的特征做融合,但是不是用的光流了,而是先在测试帧前后提取proposal,根据他们所提出的相似性度量方式,将这个proposal进行聚类,将聚类后的proposal的特征相融合,用来做最终的分类和bbox回归,开源;
- Min-delay(iccv2019) : 好像和传统的VID不一样,他们预测的是变化,在哪一帧物体发生了比较大的表观变化?论文全是公式,并不能看懂,开源;
- Memory-Guided(arXiv2019) : 在移动端上的加速,物体在快速运动时,当人眼所看到的影像消失后,人眼仍能继续保留其影像,这种现象被称为视觉暂留现。所以这篇文章利用两种特征提取器,一种主要负责速度,一种负责精度,用他们提出的加速改良后的LSTM来聚合这些特征,用强化学习来决定什么时刻用那种检测器。论文的Slow network提取强特征,Fastnetwork提取弱特征。google的文章,开源,看不懂;
- AD(iccv2019) : 他们提出了一个叫Average delay的指标来衡量视频目标检测的精度,测量的是instance级别的东西。delay指的是一个物体从出现帧与被检测到的帧之间相差的帧数。提出了一个新的测试数据集,VIDT,文章中描述分析了AP的缺陷,无法理解。。。
- Patchwork(iccv2019):既可作检测也可做分类,将视频切成一小段一小段来快速检测,提出了一个attention模块来预测目标位置,利用强化学习来训练;
- PSLA(iccv2019) : 提出了一个Progressive Sparse Local Attention的新模型来代替光流,先计算两帧之间的相对权重,利用这个权重做特征对齐,然后将这些关键帧的特征互相传播,精度没有SELSA高;
-Object Guided(iccv2019):之前那些整合整个序列特征的方式的存储量大,他们是第一个用object guided方式来选择需要存储的特征,存了一个pixel级别和一个instance级别的栈,设计了一个额外的memory network来存储长时间的联系。也是用了关键帧的方式来做,只有在关键帧的时候,才会将特征写入存储,当非关键帧的时候就先将feature map下采样,然后利用memory中的信息来弥补由于下采样造成的恶化; - RND(iccv2019):又是一篇整合多帧特征来检测的文章,通过度量object之间的关系来将多帧的特征整合到当前的帧中来,先用RPN在帧上提proposal,然后选择置信度最高的k个proposal放到proposal的池中,最后通过proposal之间的关系来将其进行融合;
- Long-Range(iccv2019) : 提出了一个temporal relation模块,用来衡量不同帧中检测到的proposal的关系,然后根据相似度将前或后的proposal整合到当前帧中,为了capture长时间的依赖,运行的时间跟图片检测器时间一样,这个relation block看起来很想non-local;