深度解析:从概念到变革——Transformer大模型的前世今生

知存科技是全球领先的存内计算芯片企业。针对AI应用场景,在全球率先商业化量产基于存内计算技术的神经网络芯片。凭借颠覆性的技术创新,知存科技突破传统计算架构局限,利用存储与计算的物理融合大幅减少数据搬运,在相同工艺条件下将AI计算效率提升2个数量级,充分满足快速发展的神经网络模型指数级增长的算力需求。

1. 大模型的前世今生-预备知识

1.1 知识点简介
-
什么是机器学习?
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习的目的是通过对数据的学习,提取数据中的潜在规律或模式,并利用这些规律或模式来对新的数据进行预测或决策。这个过程通常是通过建立数学模型,并使用算法来优化模型参数完成的。一旦模型训练完成,就可以对新的数据进行自动预测或分类,从而实现计算机的自主学习和智能化决策。
一句话概括:机器学习就是用数据或以往的经验,以此优化计算机程序的性能标准
-
什么是神经网络?
神经网络是一种受到生物神经网络启发的人工智能技术。它由大量的节点(类似于生物神经元)相互连接构成,每个节点都执行特定的数学运算。神经网络的结构模仿了大脑中神经元网络的分层和连接方式,使得信息可以通过这些连接在节点之间传递。在训练过程中,神经网络会根据学习算法调整节点之间的连接权重,以改进其性能。
-
什么是深度学习?
深度学习(Deep Learning,简称DL)是机器学习(Machine Learning,简称ML)的一个子集,它通过使用多层人工神经网络来模拟人脑的分析学习机制,以实现人工智能(Artificial Intelligence,简称AI)的主要技术之一。
深度学习的主要特点是学习样本数据的内在规律和表示层次,这些层次对文字、图像和声音等数据的解释非常关键。深度学习模型,如多层感知器,通过组合低层特征形成更抽象的高层特征,从而发现数据的分布式特征表示。这种学习方式可以是有监督的、半监督的或无监督的,使机器能够执行复杂模式识别任务,如语音识别、图像识别、自然语言处理等。
-
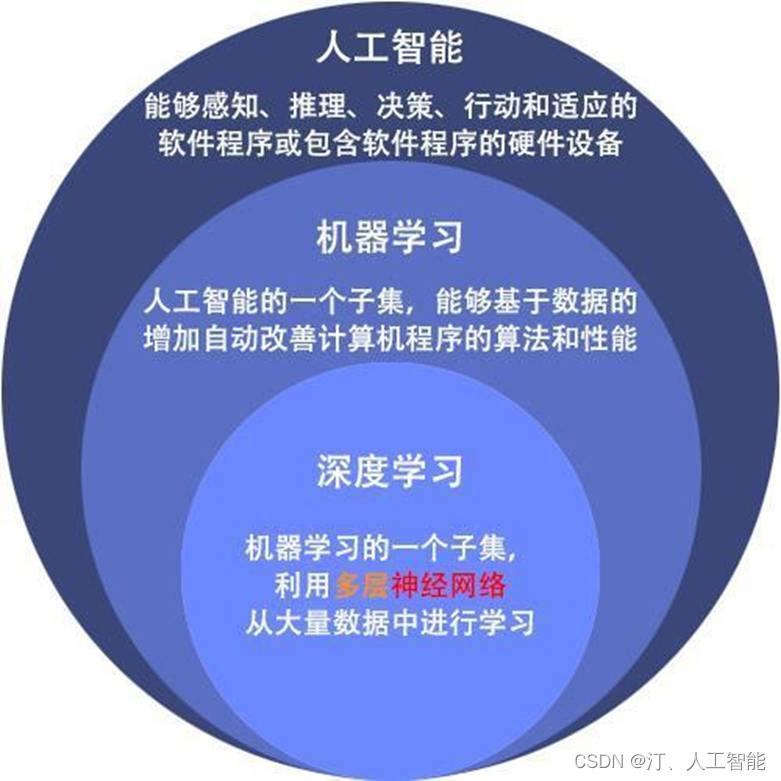
简单概况- 机器学习是很多种方法和模型的总称。
- 神经网络是机器学习模型的一种。
- 深度学习是使用了层数较多的神经网络。
-
什么是NLP?
自然语言处理(Natural Language Processing)。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。

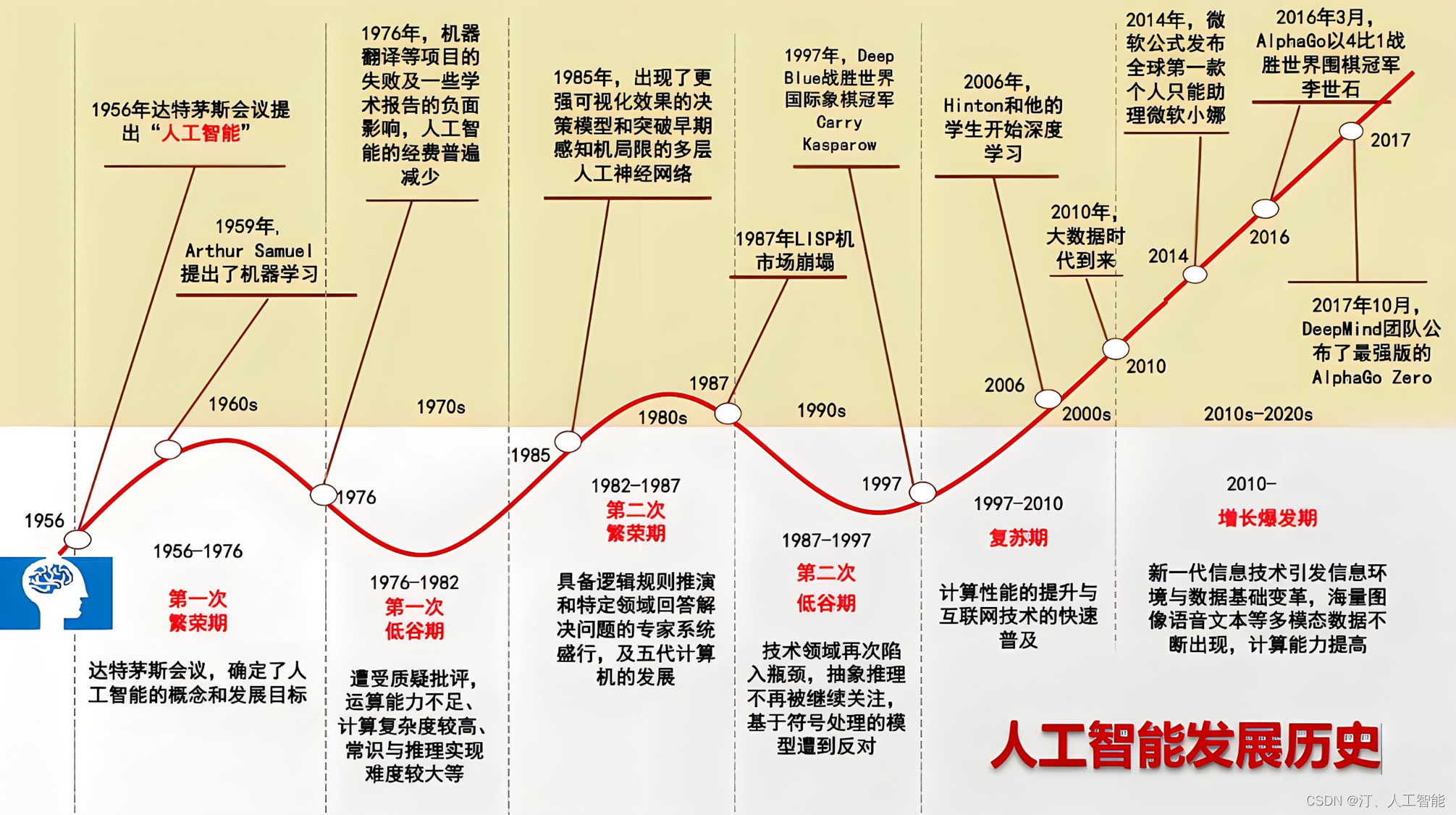
- 人工智能发展史
在人工智能(AI)的后半期发展中,即从上世纪90年代至今,这一领域取得了显著进步和广泛的应用。以下是该时期人工智能发展的关键点和里程碑事件,按照时间顺序进行介绍:
- 稳步发展期(20世纪90年代中-2010年):
网络技术的推动:随着互联网技术的飞速发展,为人工智能提供了丰富的数据资源和更强大的计算能力。专家系统和机器学习:专家系统开始应用于医疗、化学、地质等领域,机器学习技术也得到了进一步的发展和完善。标志性事件:- 1997年,IBM的Deep Blue超级计算机在国际象棋比赛中击败了世界冠军卡斯帕罗夫,这是AI在标准比赛时限内首次战胜人类顶尖选手的里程碑事件。
- 2008年,IBM提出“智慧地球”的概念,预示了AI技术在未来社会发展和人类生活中的应用前景。
- 蓬勃发展期(2011年至今):
大数据、云计算的兴起:随着大数据和云计算技术的广泛应用,AI获得了前所未有的发展机遇。大量的数据为AI提供了丰富的学习资源,云计算则为AI提供了强大的计算能力。深度学习技术的突破:深度学习技术取得了重大突破,使得AI在图像识别、语音识别、自然语言处理等领域取得了显著的进步。例如,深度学习在人脸识别、语音助手、机器翻译等领域的应用已经达到了人类水平甚至超越人类。AI技术的广泛应用:AI技术已经在医疗、金融、教育、交通等多个领域得到广泛应用。例如,在医疗领域,AI可以通过图像识别技术实现医学影像的自动化识别和分析;在金融领域,AI可以通过数据分析技术实现风险评估和信用评级;在教育领域,AI可以通过智能推荐系统实现个性化学习资源的推送;在交通领域,AI可以实现交通流量控制、交通预测和自动驾驶等功能。标志性事件:- 2011年,IBM的Watson人工智能系统在电视智力竞赛节目Jeopardy中击败了人类选手,展示了AI在自然语言处理和知识推理方面的强大能力。
- 2016年,随着AlphaGo在围棋领域的成功,AI在棋类游戏中的表现已经超越了人类顶尖选手。
-
什么是大模型?
大模型是指包含超大规模参数(通常在十亿个以上)的神经网络模型。具有以下的特征:
巨大的规模:大模型包含十亿以上参数。这种巨大的模型规模为其提供了强大的表达能力和学习能力。多任务学习:大模型通常会一起学习多种不同的任务,如机器翻译、文本摘要、问答系统等。这可以使模型学习到更广泛和泛化的语言理解能力。强大的计算资源:训练大模型通常需要数百甚至上千个GPU,以及大量的时间,通常在几周到几个月。丰富的数据:大模型需要大量的数据来进行训练,只有大量的数据才能发挥大模型的参数规模优势。
1.2 技术点简介
1.2.1 Token与Word Embedding
Token: 文本中的最小语义单元。Word Embedding:词嵌入。它将最小语义单元,转换为一个个的 词向量(word vector),输入给算法。
举例:
我喜欢跑步
被分成三个token(我、喜欢、跑步),并通过word embedding转换成下列三个词向量
我 : ( 0.3, 0.7, 0.1, 0.4, 0.9, 0.8, 0.2, 0.5, 0.6, 0.1)
喜欢 : ( 0.7, 0.3, 0.2, 0.1, 0.5, 0.3, 0.9, 0.3, 0.7, 0.2)
跑步: ( 0.2, 0.1, 0.9, 0.8, 0.7, 0.5, 0.5, 0.1, 0.9, 0.4)
最终送给算法的输入,就是上面 3*10的矩阵
1.2.2 word2vec
word2vec是Google于2013开源的一个计算词向量(word vector)的工具。Word2vec是一种用于生成词向量的模型,它能够将词语映射到一个连续的向量空间中,使得语义相近的词语在向量空间中的距离也相近。词向量是自然语言处理中的一种重要技术,它能够捕捉词语之间的语义和语法关系,为文本分析、情感分析、文本分类等任务提供有力支持。它有如下特点:
高效:可以在百万数量级的词典和上亿的数据集上进行高效地训练相似性度量:可以很好地度量词与词之间的相似性。
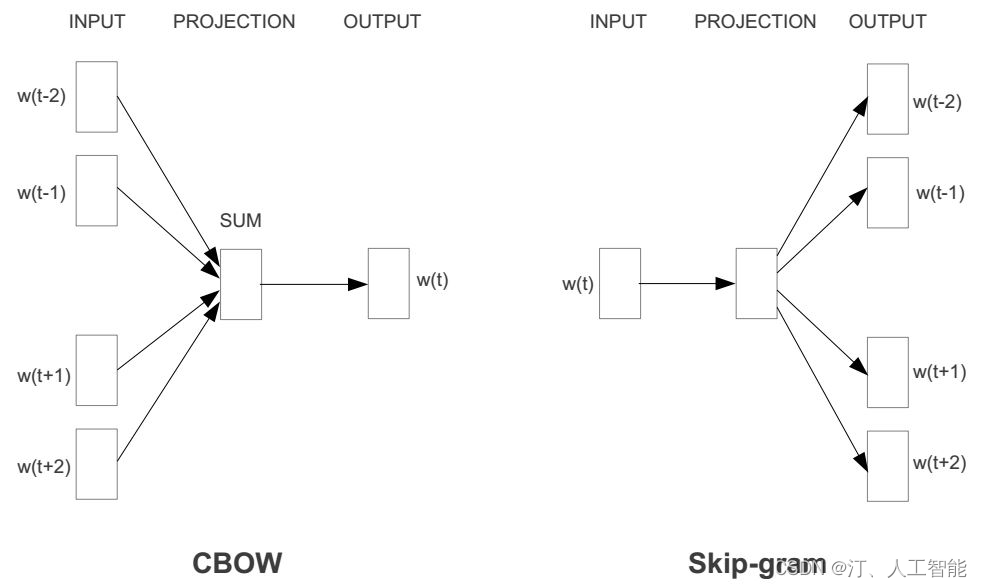
Word2vec模型的核心思想是通过词语的上下文信息来学习词语的向量表示。具体来说,Word2vec模型通过训练一个神经网络模型,使得给定一个词语的上下文时,能够预测该词语本身**(CBOW模型),或者给定一个词语时,能够预测其上下文(Skip-gram模型)**。
-
Skip-gram模型
Skip-gram模型的基本思想是根据当前词来预测其上下文中的词。具体来说,给定一个中心词,模型会尝试预测该词前后一定范围内的词(即上下文词)。通过这种方式,模型可以学习到词语之间的共现关系,并将这些关系编码到词向量中。在训练过程中,模型会优化一个目标函数(如负采样或层次softmax),以最小化预测错误。通过不断地调整词向量的参数,模型能够逐渐学习到词语之间的语义关系。
-
CBOW模型
与Skip-gram模型不同,CBOW模型是通过上下文词来预测中心词。具体来说,给定一个词的上下文(即前后一定范围内的词),模型会尝试预测该中心词本身。CBOW模型的训练过程与Skip-gram类似,也是通过优化目标函数来最小化预测错误。不同的是,CBOW模型更注重上下文信息对中心词的影响,因此它在某些任务中可能表现出不同的性能特点。
CBoW: 根据前后 N 个连续的词,来计算某个词出现的概率
Skip-gram: 与上面相反,是根据某个词,分别计算它前后出现某几个词的各个概率
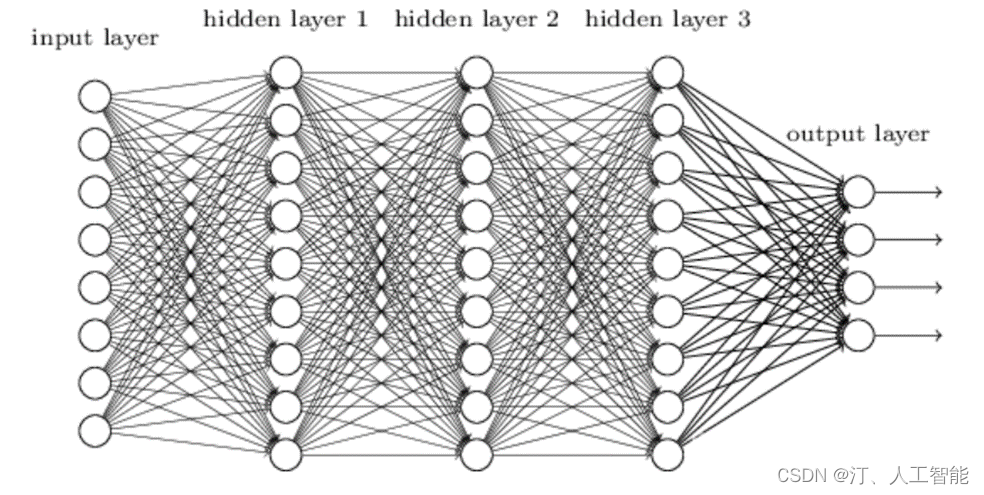
1.2.3 DNN与Linear层
- DNN: 深度神经网络(Deep Neural Networks),由若干Linear层构成。
- Linear层: 全连接层,也叫密集层。其特点是每一个输入跟输出都会相连。
最早提出来的神经网络结构,很快被CNN和RNN取代。
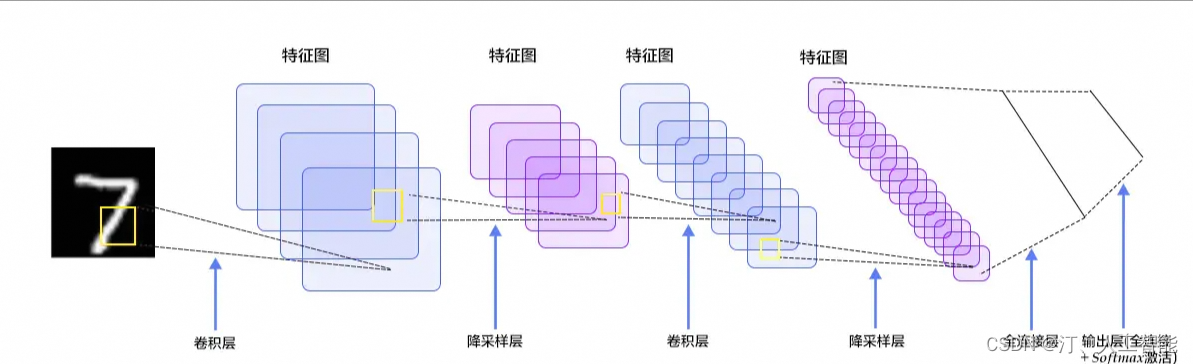
1.2.4 CNN卷积神经网络
CNN(Convolutional Neural Network,卷积神经网络)是一种特殊的深度学习网络结构,特别适用于处理具有网格状拓扑结构的数据,如图像。
-
CNN主要由以下几种层构成:
- 卷积层(Convolutional Layer):通过卷积核对输入数据进行特征提取,得到特征图(feature maps)。
- 激活函数层(Activation Layer):将卷积层的输出结果进行非线性变换,增加网络的非线性特性。常用的激活函数有ReLU、Sigmoid、Tanh等。
- 池化层(Pooling Layer):对特征图进行下采样,减少参数数量和计算量,同时保持特征的空间层次性。常见的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling)。
- 全连接层(Fully Connected Layer):在CNN的尾部,将特征图展开为一维向量,并连接到一个或多个全连接层,用于分类或回归任务。
-
CNN应用场景
CNN在图像和计算机视觉领域有着广泛的应用,包括但不限于以下场景:图像分类:识别图像中的物体并对其进行分类,如手写数字识别、物体识别等。目标检测:在图像中定位并识别出多个目标,如人脸检测、行人检测等。图像分割:将图像分割成多个区域或对象,并识别每个区域或对象的类别,如语义分割、实例分割等。图像生成:根据输入数据或条件生成新的图像,如超分辨率重建、图像风格迁移等。视频分析:对视频序列进行分析和处理,如动作识别、异常检测等。
-
经典算法
LeNet-5:由Yann LeCun等人提出,是第一个成功应用于数字识别问题的卷积神经网络。LeNet-5共有7层,包括3个卷积层、2个池化层和2个全连接层。
2.AlexNet:由Alex Krizhevsky等人提出,赢得了2012年ImageNet图像分类竞赛的冠军。AlexNet共有8层,包括5个卷积层和3个全连接层,引入了ReLU激活函数、数据增强和dropout等技术。VGGNet:由牛津大学的Visual Geometry Group提出,通过堆叠多个3x3的卷积核和2x2的最大池化层来构建深度卷积神经网络。VGGNet有多个版本,其中VGG16和VGG19是最常用的两个版本。ResNet(残差网络):由Kaiming He等人提出,通过引入残差连接(shortcut connections)来解决深度神经网络在训练过程中出现的梯度消失和模型退化问题。ResNet在ImageNet竞赛中取得了非常好的成绩,并且被广泛应用于各种计算机视觉任务中。MobileNet:针对移动设备和嵌入式设备设计的轻量级卷积神经网络。MobileNet采用了深度可分离卷积(depthwise separable convolution)来减少计算量和参数量,同时保持较高的性能。MobileNet有多个版本,如MobileNetV1、MobileNetV2和MobileNetV3等。
识别手写数字的全部过程,可以看到整个过程需要在如下几层进行运算:
-
输入层:输入图像等信息
-
卷积层:用来提取图像的底层特征
-
池化层:防止过拟合,将数据维度减小
-
全连接层:汇总卷积层和池化层得到的图像的底层特征和信息
-
输出层:根据全连接层的信息得到概率最大的结果
-
输入层例子
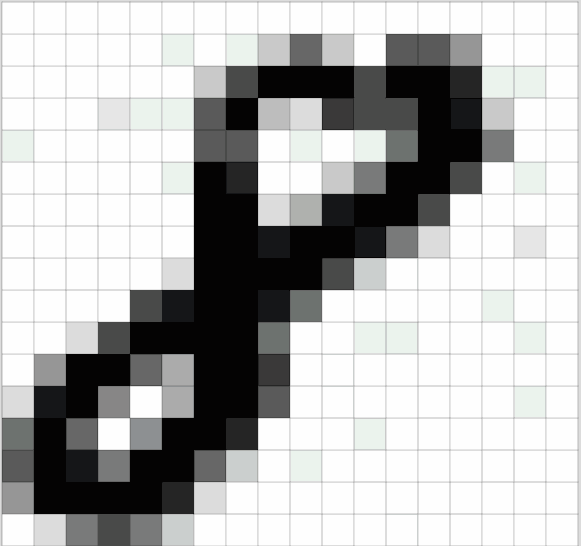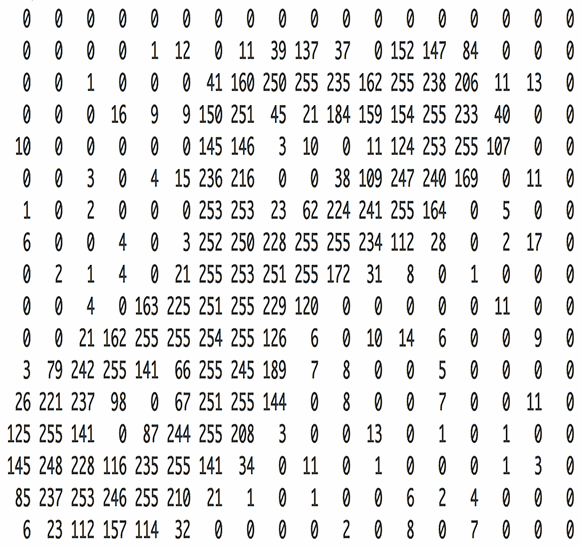
- 卷积层:
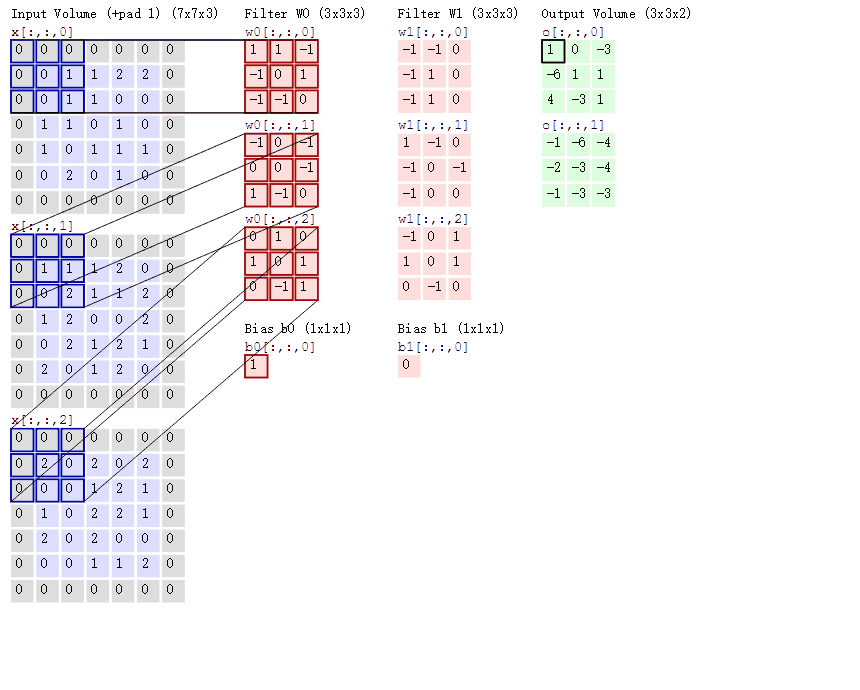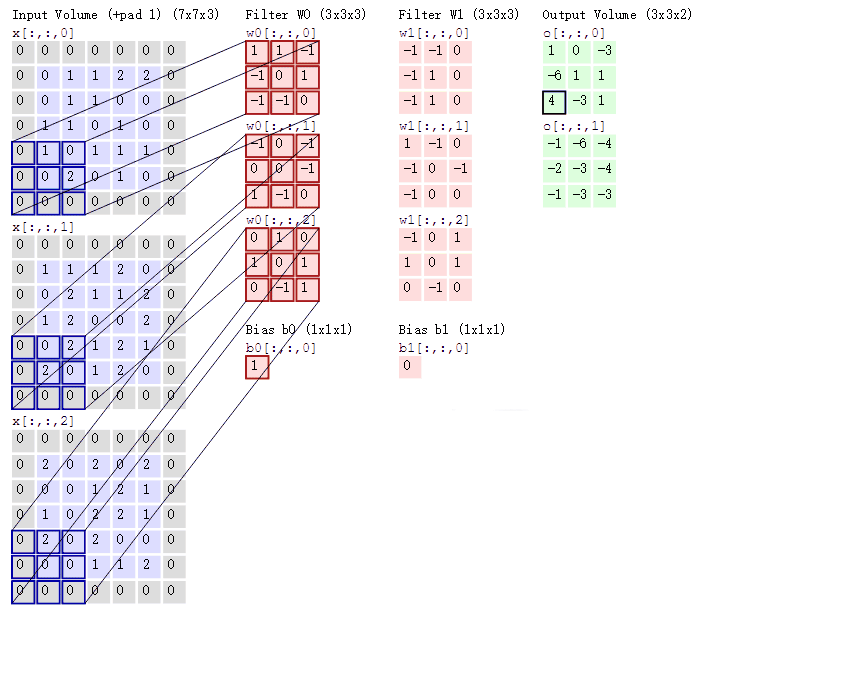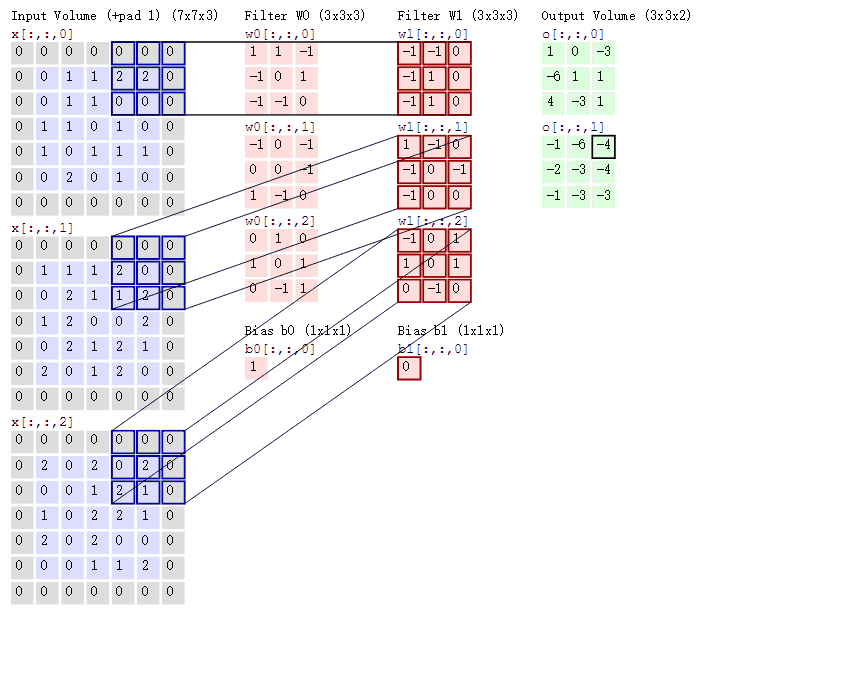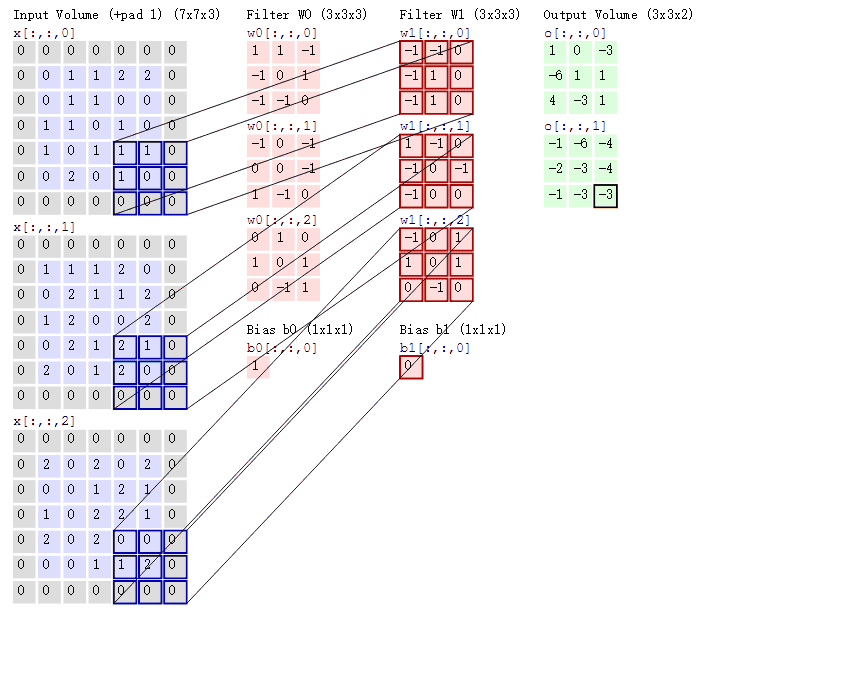
假设我们已经得到图片的二维矩阵了,想要提取其中特征,那么卷积操作就会为存在特征的区域确定一个高值,否则确定一个低值。这个过程需要通过计算其与卷积核(Convolution Kernel)的乘积值来确定。假设我们现在的输入图片是一个人的脑袋,而人的眼睛是我们需要提取的特征,那么我们就将人的眼睛作为卷积核,通过在人的脑袋的图片上移动来确定哪里是眼睛,这个过程如下所示:
整个过程就是一个降维的过程,通过卷积核的不停移动计算,可以提取图像中最有用的特征。我们通常将卷积核计算得到的新的二维矩阵称为特征图,比如上方动图中,下方移动的深蓝色正方形就是卷积核,上方不动的青色正方形就是特征图
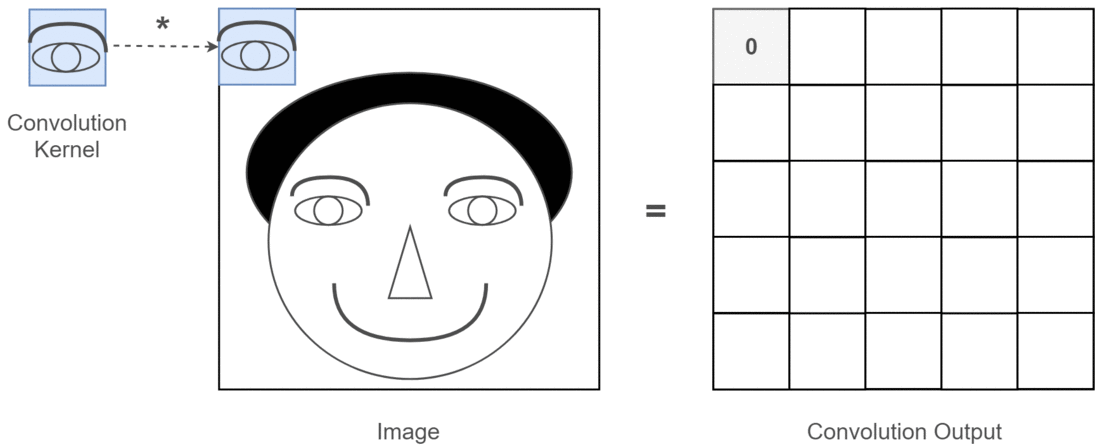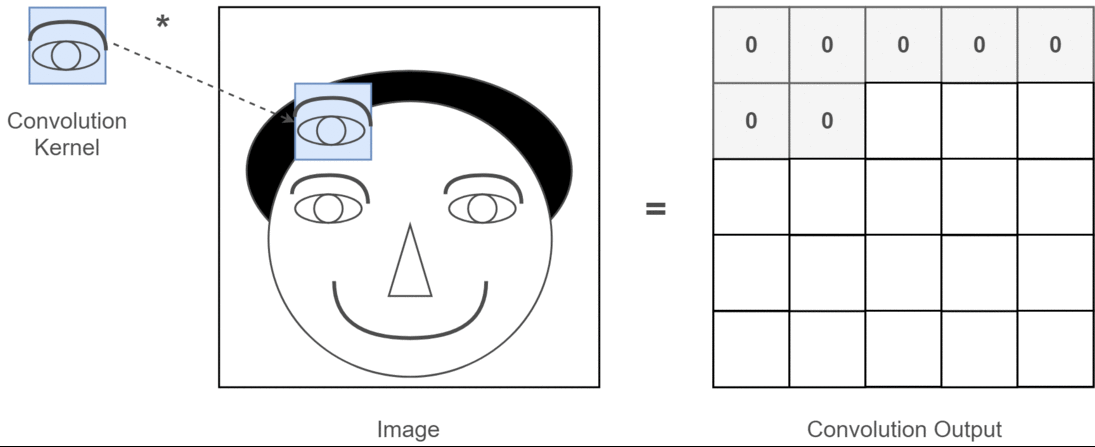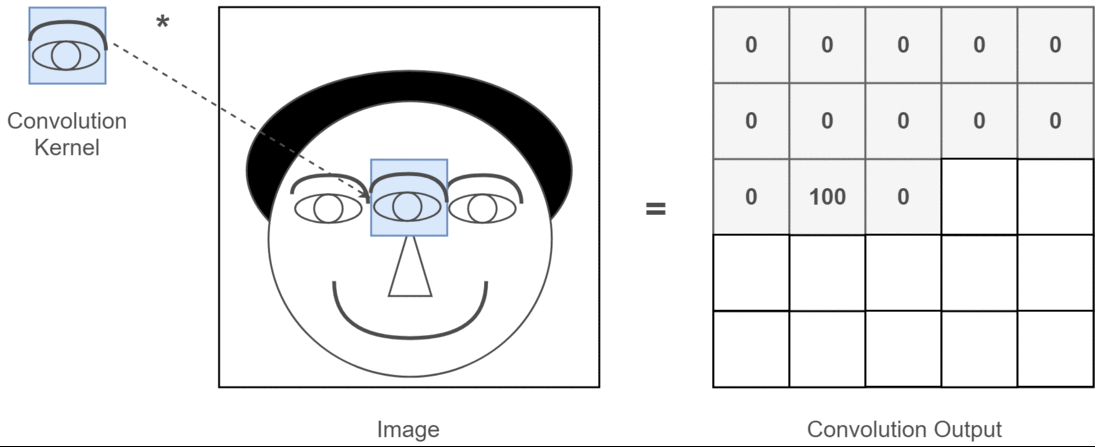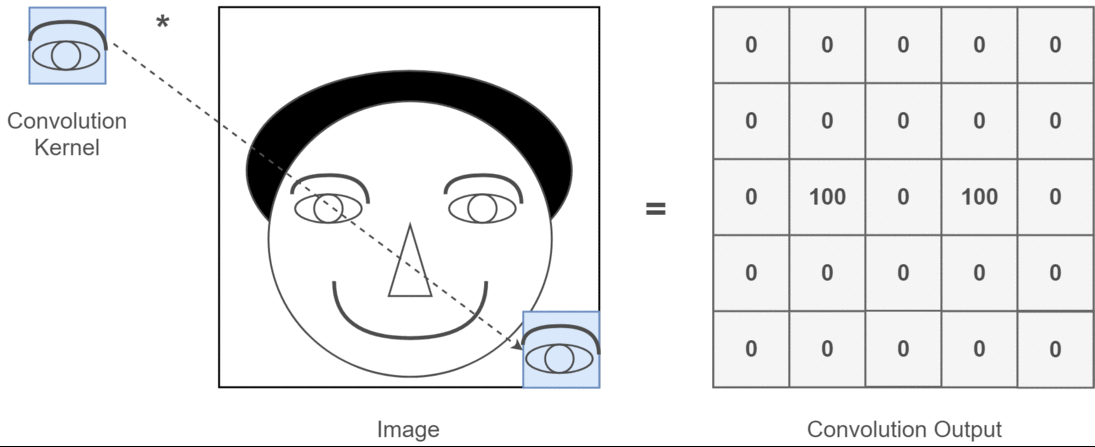
有的读者可能注意到,每次卷积核移动的时候中间位置都被计算了,而输入图像二维矩阵的边缘却只计算了一次,会不会导致计算的结果不准确呢?
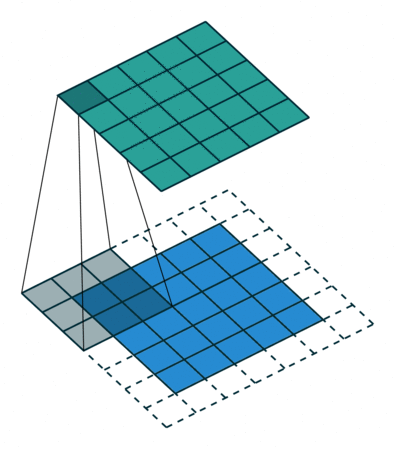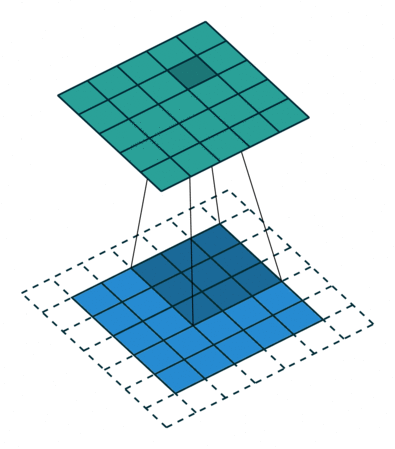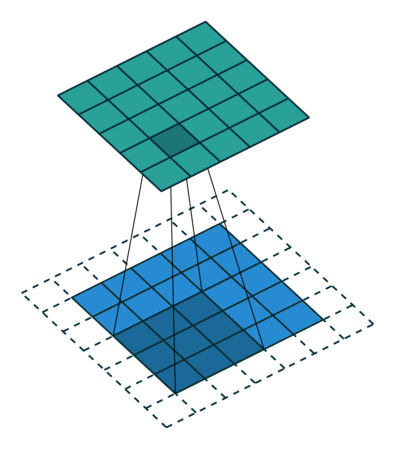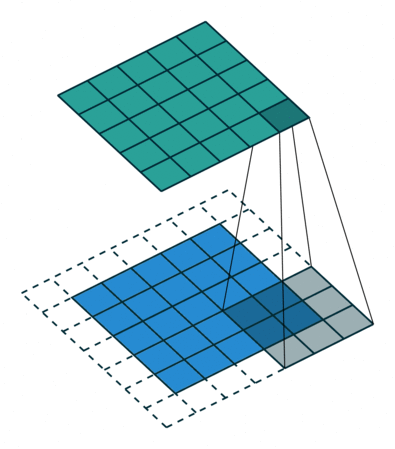
让我们仔细思考,如果每次计算的时候,边缘只被计算一次,而中间被多次计算,那么得到的特征图也会丢失边缘特征,最终会导致特征提取不准确,那为了解决这个问题,我们可以在原始的输入图像的二维矩阵周围再拓展一圈或者几圈,这样每个位置都可以被公平的计算到了,也就不会丢失任何特征,此过程可见下面两种情况,这种通过拓展解决特征丢失的方法又被称为Padding。
按照刚才的思路,输入图片是彩色图片,有三个通道,所以输入图片的尺寸就是7×7×3,而我们只考虑第一个通道,也就是从第一个7×7的二维矩阵中提取特征,那么我们只需要使用每组卷积核的第一个卷积核即可,这里可能有读者会注意到Bias,其实它就是偏置项,最后计算的结果加上它就可以了,最终通过计算就可以得到特征图了。可以发现,有几个卷积核就有几个特征图,因为我们现在只使用了两个卷积核,所以会得到两个特征图
1.2.5 RNN 循环神经网络
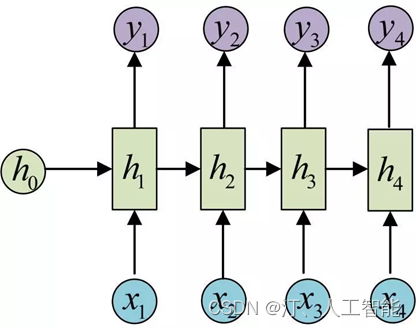
RNN(Recurrent Neural Network,循环神经网络)是一种专门用于处理序列数据的神经网络。与传统的神经网络相比,RNN能够捕捉序列数据中的时间依赖性和模式。
RNN的基本结构包括输入层、隐藏层和输出层。与常规神经网络不同的是,RNN的隐藏层之间是有连接的,这种连接允许RNN保存并利用序列中的历史信息。在每个时间步,RNN都会接收当前的输入和前一个时间步的隐藏状态,并据此计算当前时间步的输出和隐藏状态。这种结构使得RNN非常适合处理序列数据,如文本、语音、时间序列等。
-
RNN应用场景
- 自然语言处理(NLP):RNN在NLP领域的应用非常广泛,如文本分类、情感分析、机器翻译、语音识别、对话系统等。在这些任务中,RNN能够捕捉句子或段落中的语义信息,并据此生成相应的输出。
- 时间序列分析:RNN也常用于处理时间序列数据,如股票价格预测、天气预测、交通流量预测等。通过捕捉时间序列中的历史信息,RNN能够预测未来的趋势或行为。
-
经典算法
基本RNN:这是最简单的RNN结构,包含一个输入层、一个隐藏层和一个输出层。然而,由于基本RNN在处理长序列时存在梯度消失和梯度爆炸的问题,因此在实际应用中往往需要使用更复杂的RNN结构。长短期记忆网络(LSTM):LSTM是一种特殊的RNN结构,通过引入门控机制(如输入门、遗忘门和输出门)来控制信息的流动,从而解决了基本RNN在处理长序列时的梯度消失和梯度爆炸问题。LSTM在许多NLP任务中都取得了很好的效果。门控循环单元(GRU):GRU是LSTM的一个简化版本,它只有两个门(更新门和重置门),并且没有单独的细胞状态。GRU在保持LSTM性能的同时,减少了模型的参数数量和计算复杂度。因此,在某些任务中,GRU可能比LSTM更受欢迎。双向RNN(BiRNN):BiRNN由两个RNN组成,一个正向RNN和一个反向RNN。正向RNN按照序列的顺序读取输入,而反向RNN则按照序列的反向顺序读取输入。然后,将两个RNN的输出合并起来,以获取每个时间步的完整上下文信息。BiRNN在处理需要同时考虑前后文信息的任务时非常有用,如命名实体识别、机器翻译等。堆叠RNN(Stacked RNN):堆叠RNN是指将多个RNN层叠加在一起,以构建更深的网络结构。通过堆叠多个RNN层,网络可以学习更复杂的模式和特征,从而提高模型的性能。然而,堆叠RNN也面临着计算复杂度和过拟合等问题。
相比于词袋模型和前馈神经网络模型,RNN可以考虑到词的先后顺序对预测的影响,RNN包括三个部分:输入层、隐藏层和输出层。相对于前馈神经网络,RNN可以接收上一个时间点的隐藏状态。
1.2.6 NLP常见网络
-
Encoder-Decoder结构
-
编码器(Encoder)
编码器的作用是接收输入序列,并将其转换成固定长度的上下文向量(context vector)。这个向量是输入序列的一种内部表示,捕获了输入信息的关键特征。在自然语言处理的应用中,输入序列通常是一系列词语或字符。编码器可以是任何类型的深度学习模型,但循环神经网络(RNN)及其变体,如长短期记忆网络(LSTM)和门控循环单元(GRU),因其在处理序列数据方面的优势而被广泛使用。
-
解码器(Decoder)
解码器的目标是将编码器产生的上下文向量转换为输出序列。在开始解码过程时,它首先接收到编码器生成的上下文向量,然后基于这个向量生成输出序列的第一个元素。接下来,它将自己之前的输出作为下一步的输入,逐步生成整个输出序列。解码器也可以是各种类型的深度学习模型,但通常与编码器使用相同类型的模型以保持一致性。
-
训练过程
在训练Encoder-Decoder模型时,目标是最小化模型预测的输出序列与实际输出序列之间的差异。这通常通过计算损失函数(如交叉熵损失)来实现,并使用反向传播和梯度下降等优化算法进行参数更新。
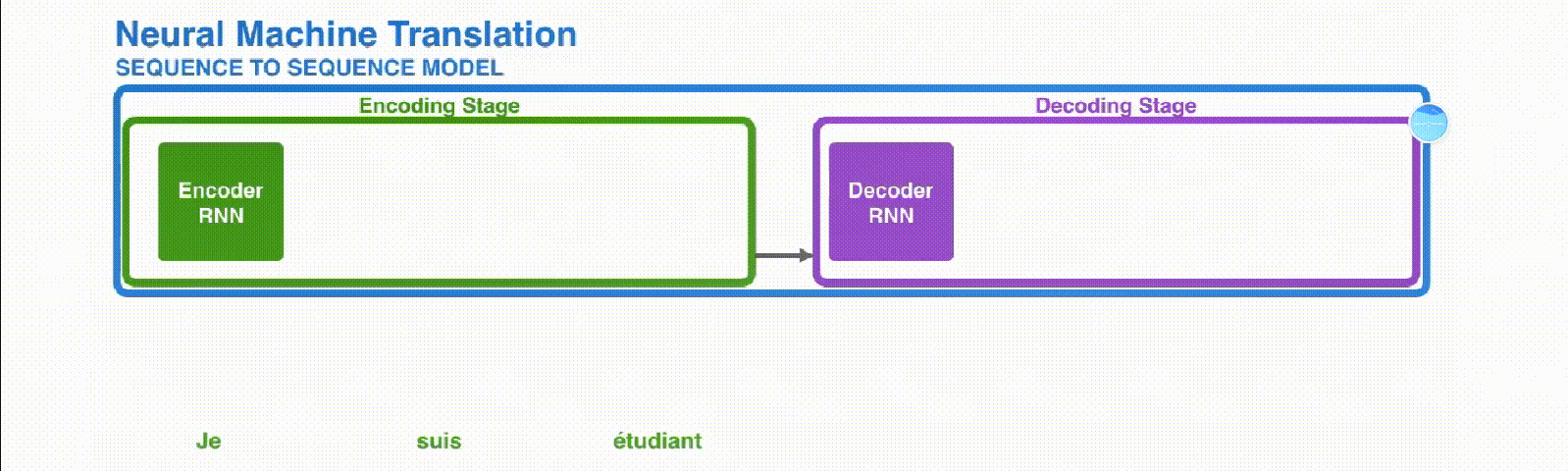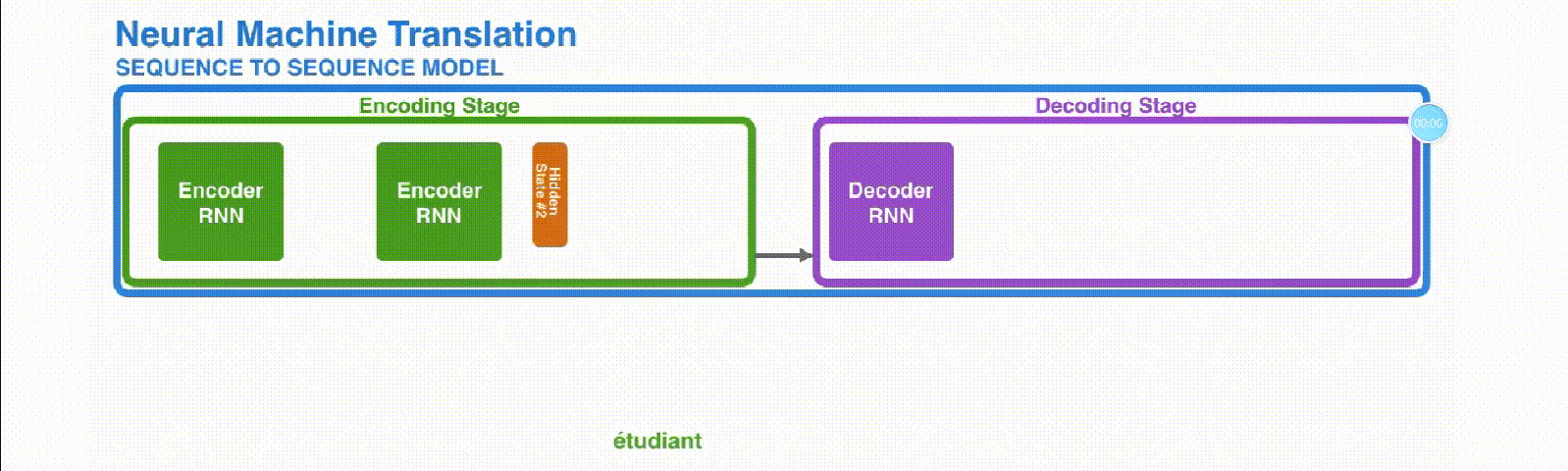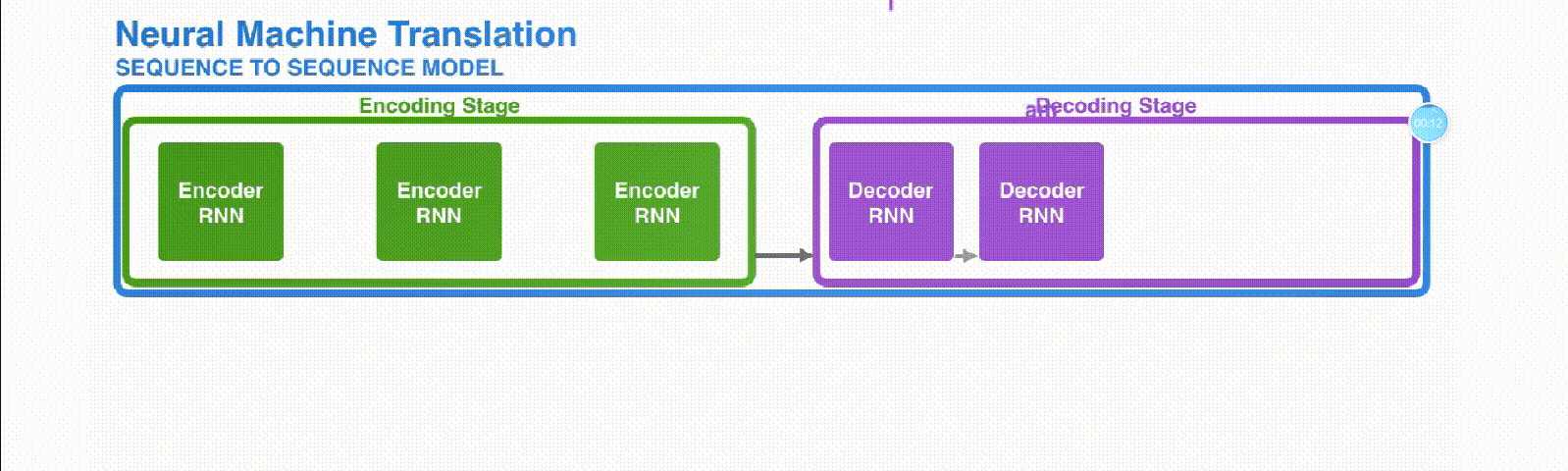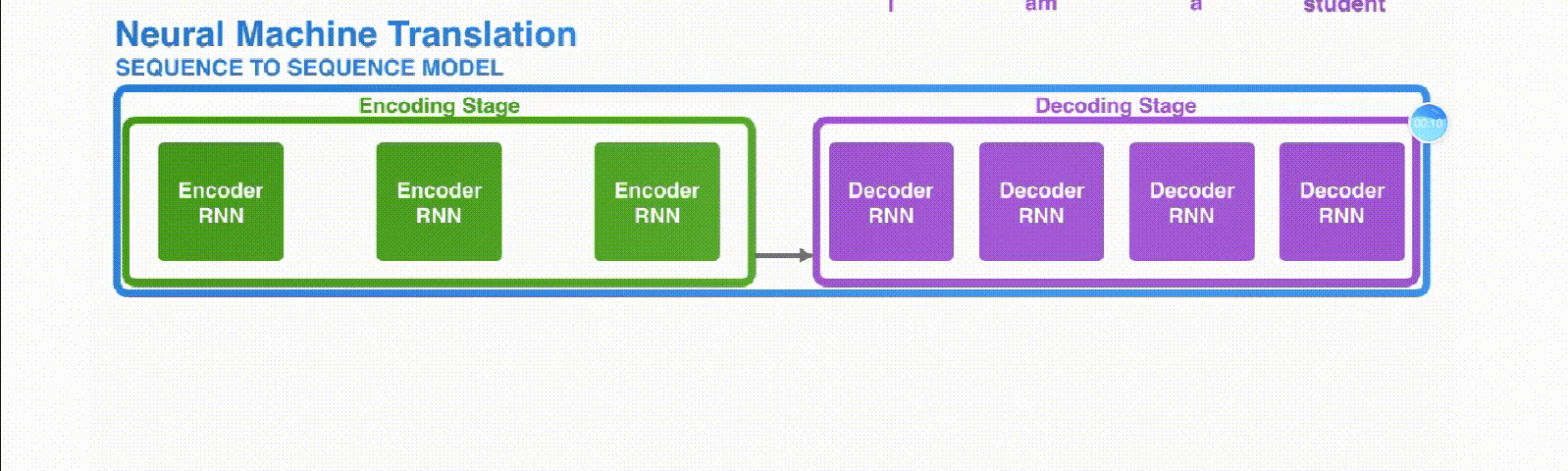
-
Encoder-Decoder的缺陷
- 中间的向量 长度都是固定的
- RNN 结构的 Encoder-Decoder 模型存在长程梯度消失问题
- 对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有有效信息
- 即便 LSTM 加了门控机制可以选择性遗忘和记忆,随着所需翻译的句子难度增加,这个结构的效果仍然不理想
-
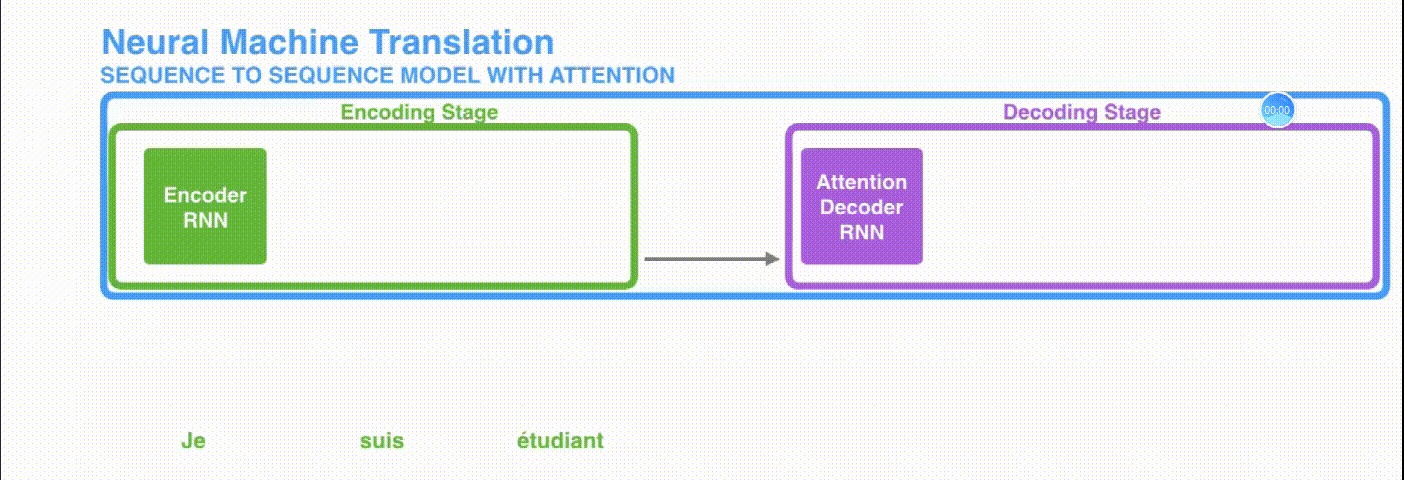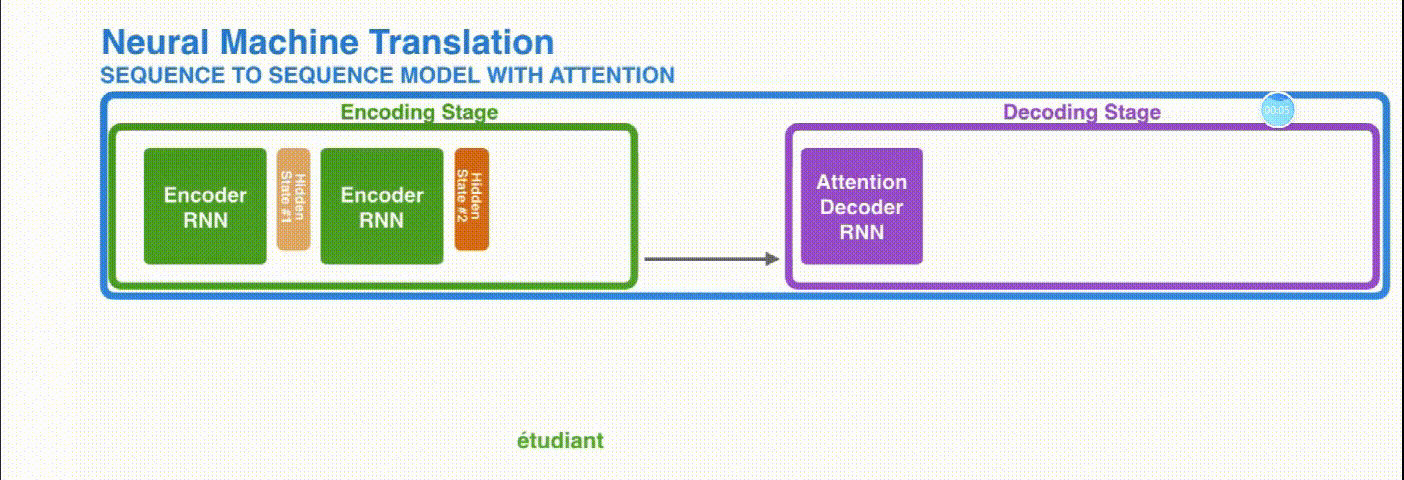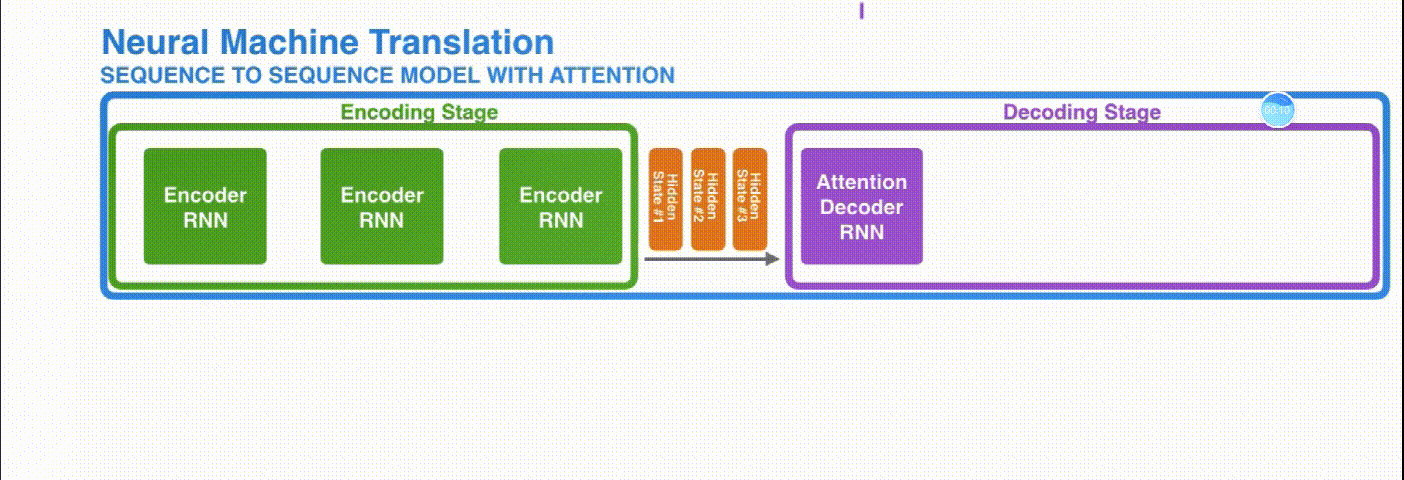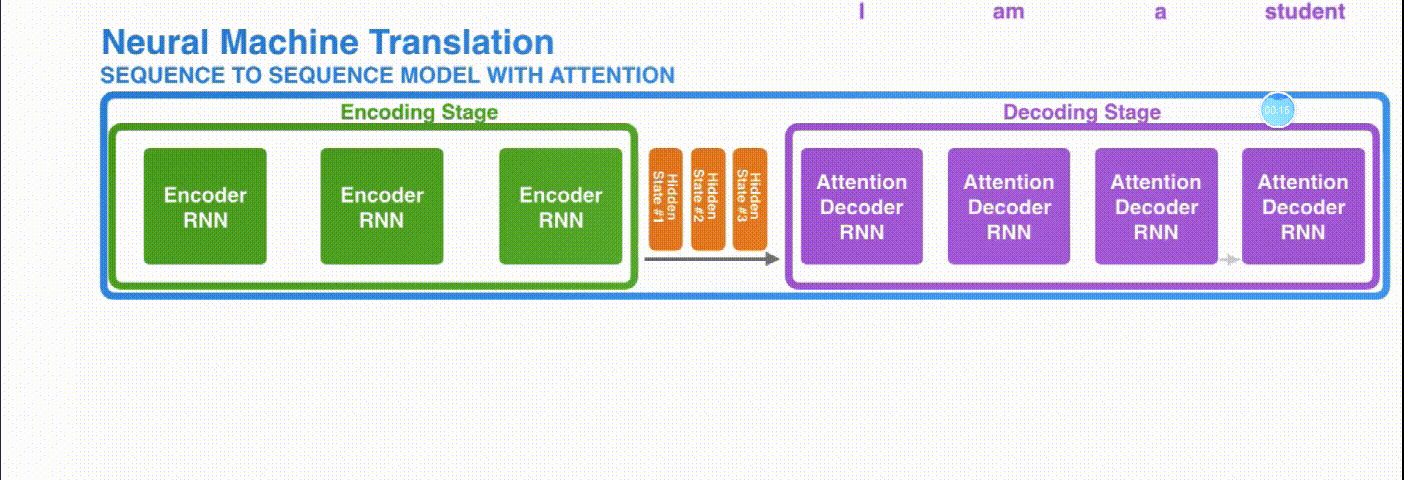
Attention 机制的引入
- Attention 就是为了解决信息过长导致信息丢失的问题
- 在 Attention 模型中,我们翻译当前词,会寻找源语句中相对应的几个词语,然后结合之前已经翻译的序列来翻译下一个词。
-
Attention 如何准确将注意力放在关注的地方
- 对 RNN 的输出计算注意程度,通过计算最终时刻的向量与任意 i 时刻向量的权重,通过 softmax 计算出得到注意力偏向分数,如果对某一个序列特别注意,那么计算的偏向分数将会比较大。
- 计算 Encoder 中每个时刻的隐向量
- 将各个时刻对于最后输出的注意力分数进行加权,计算出每个时刻 i 向量应该赋予多少注意力
- decoder 每个时刻都会将部分的注意力权重输入到 Decoder 中,此时 Decoder 中的输入有:经过注意力加权的隐藏层向量,Encoder 的输出向量,以及 Decoder 上一时刻的隐向量
- Decoder 通过不断迭代,Decoder 可以输出最终翻译的序列。
-
引入 Attention 的 Encoder-Decoder 框架下,完成机器翻译任务的大致流程如下:
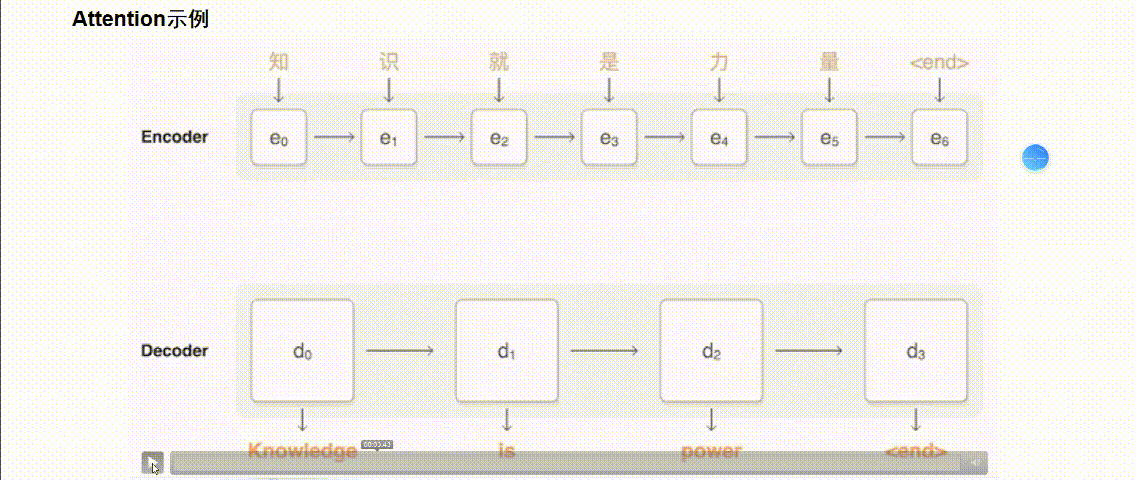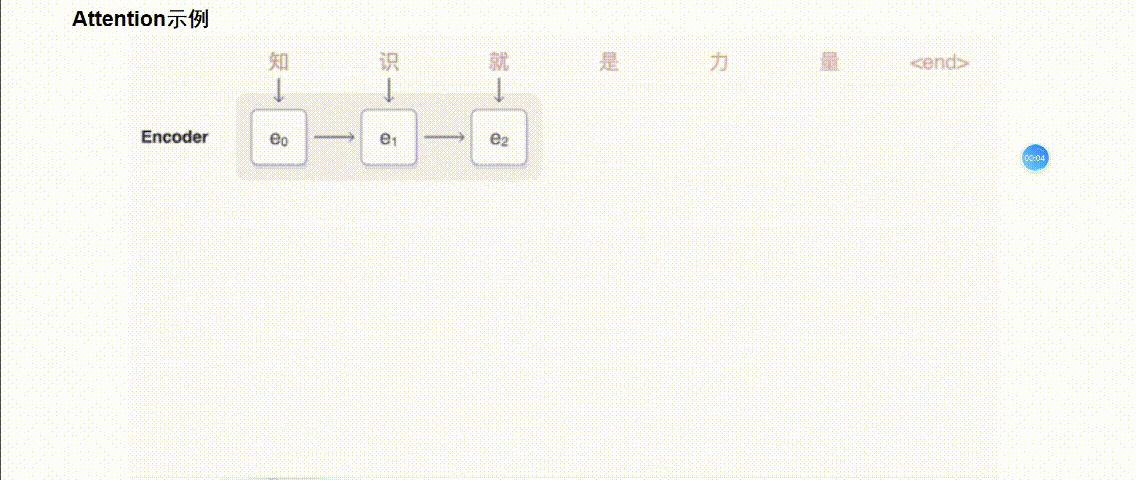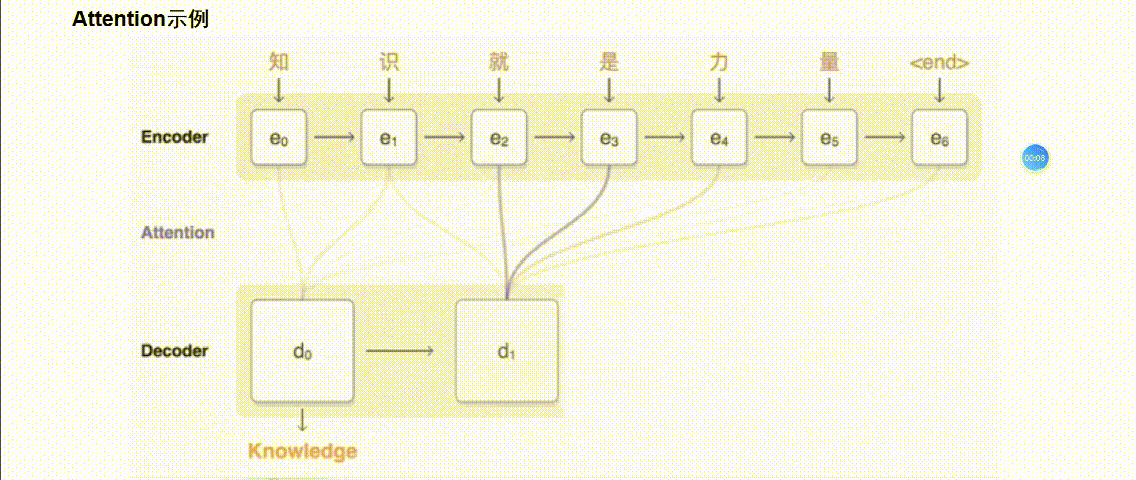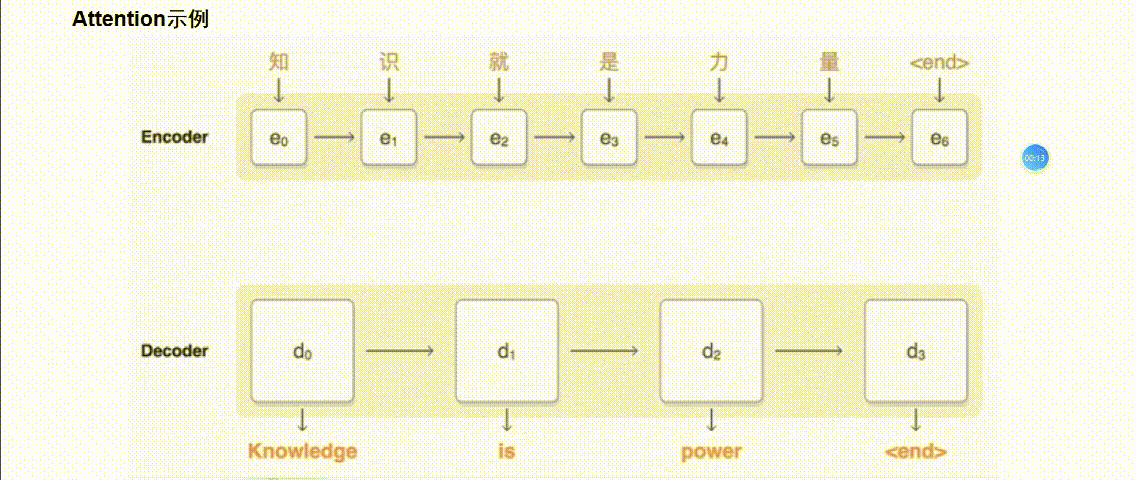
2.Transformer篇
- 前言回顾
RNN(Recurrent Neural Network)在处理序列数据时具有显著的优势,如捕捉时序信息和上下文依赖建模等。然而,RNN的一个主要缺陷是其无法进行高效的并行运算,这主要源于其递归的本质和序列依赖性。以下是对RNN无法并行运算的详细解释,以及Encoder-Decoder模型搭配注意力机制对此问题的改进:
- RNN无法并行运算的原因:
- 递归特性:RNN在每个时间步都依赖于前一个时间步的输出作为当前时间步的输入,这种递归性质使得RNN无法同时处理整个序列,而必须按照时间步的顺序逐个处理。
- 序列依赖性:由于RNN需要捕捉序列中的时序信息,因此它必须按照序列的顺序进行处理。这种序列依赖性限制了RNN的并行计算能力。
2.1 Transformer 简介
Transformer 网络架构架构由 Ashish Vaswani 等人在 Attention Is All You Need 一文中提出,并用于机器翻译任务,和以往网络架构有所区别的是,该网络架构中,编码器和解码器没有采用 RNN 或 CNN 等网络架构,而是采用完全依赖于注意力机制的架构。
Transformer原始论文:《Attention is all you need》2017

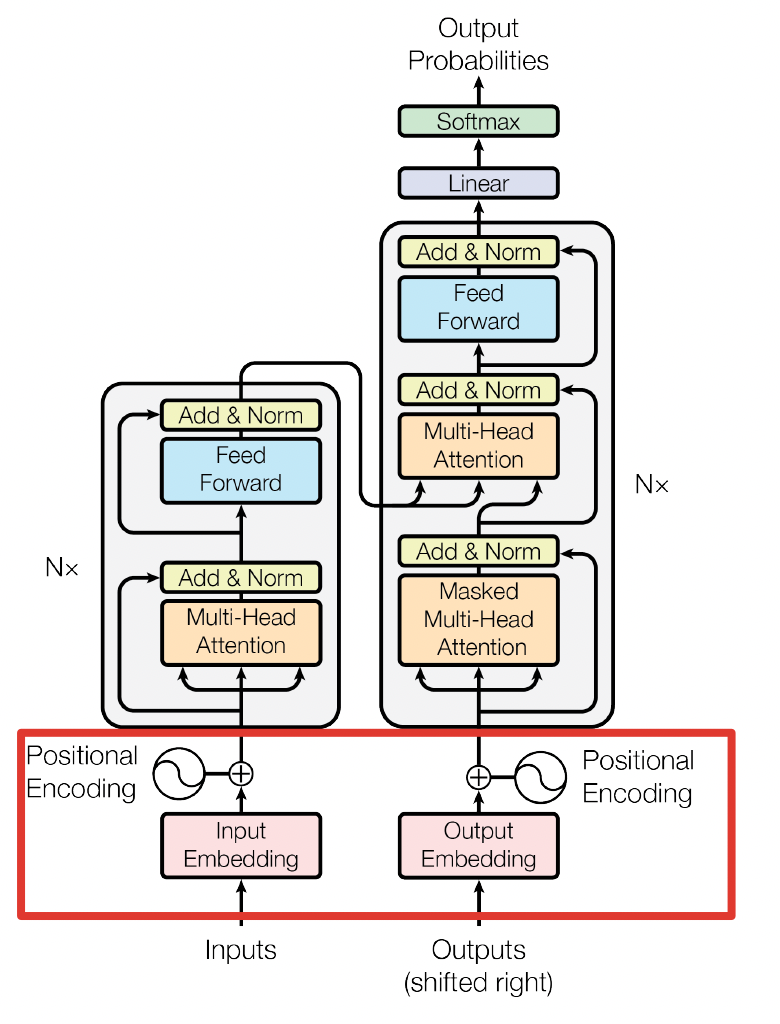
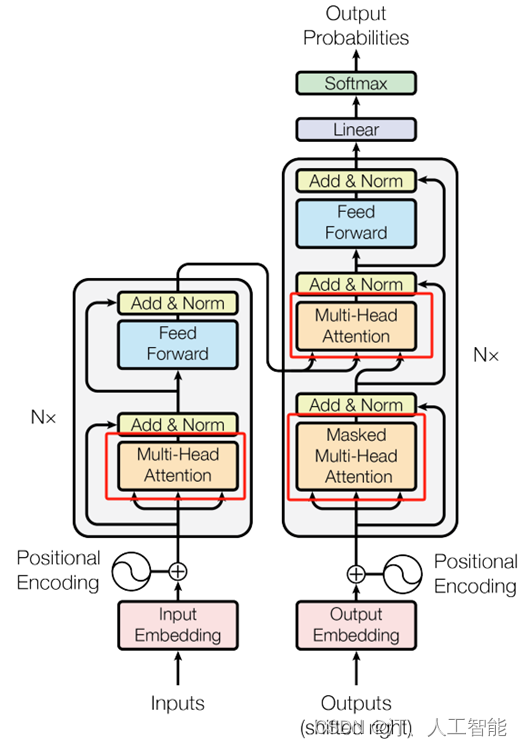
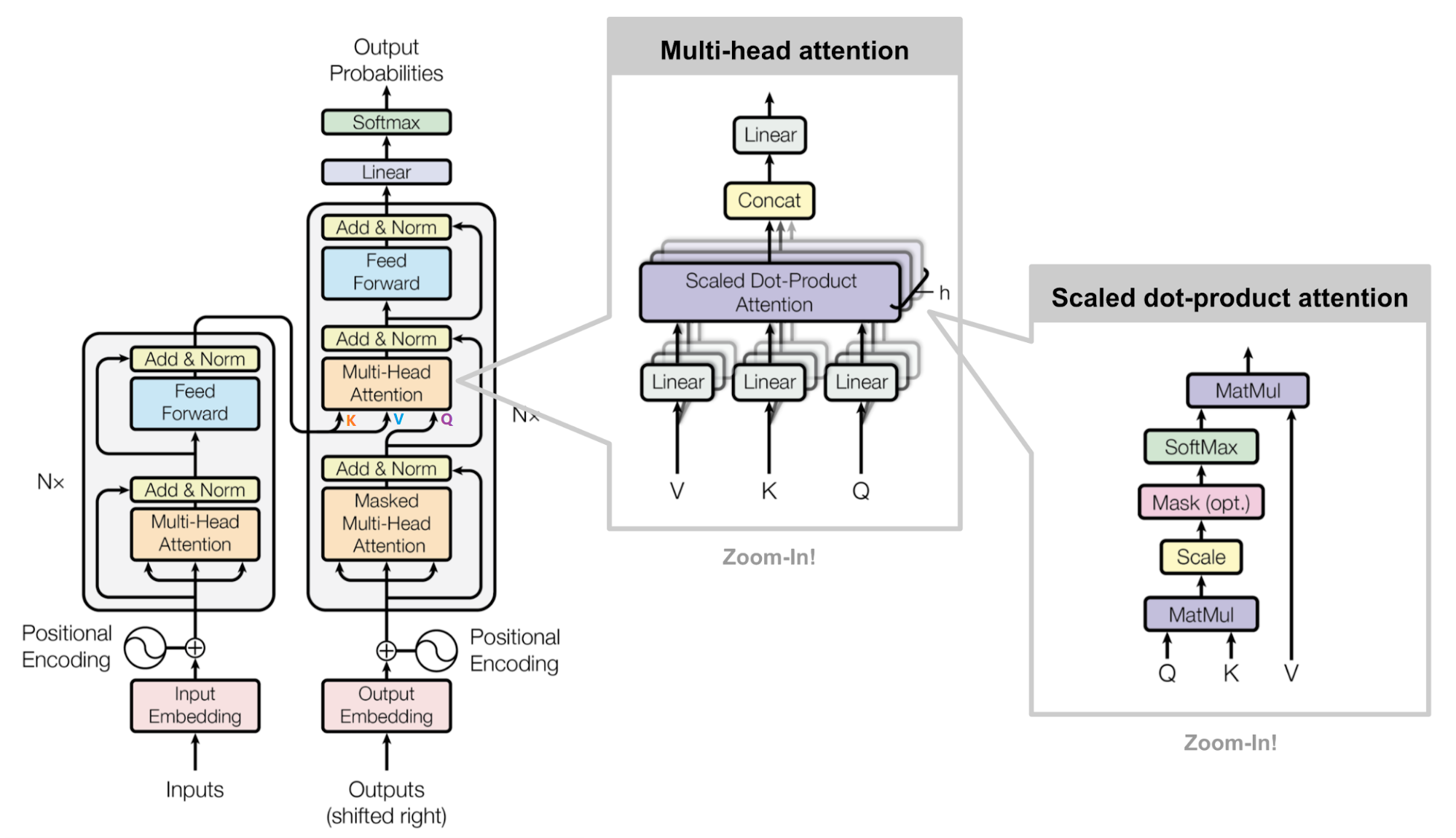
Transformer 模型使用 Self-Attention 结构取代在 NLP 任务中常用的 RNN 网络结构。相比 RNN 网络结构,其最大的优点是可以并行计算。Transformer 的整体模型架构如下图所示:
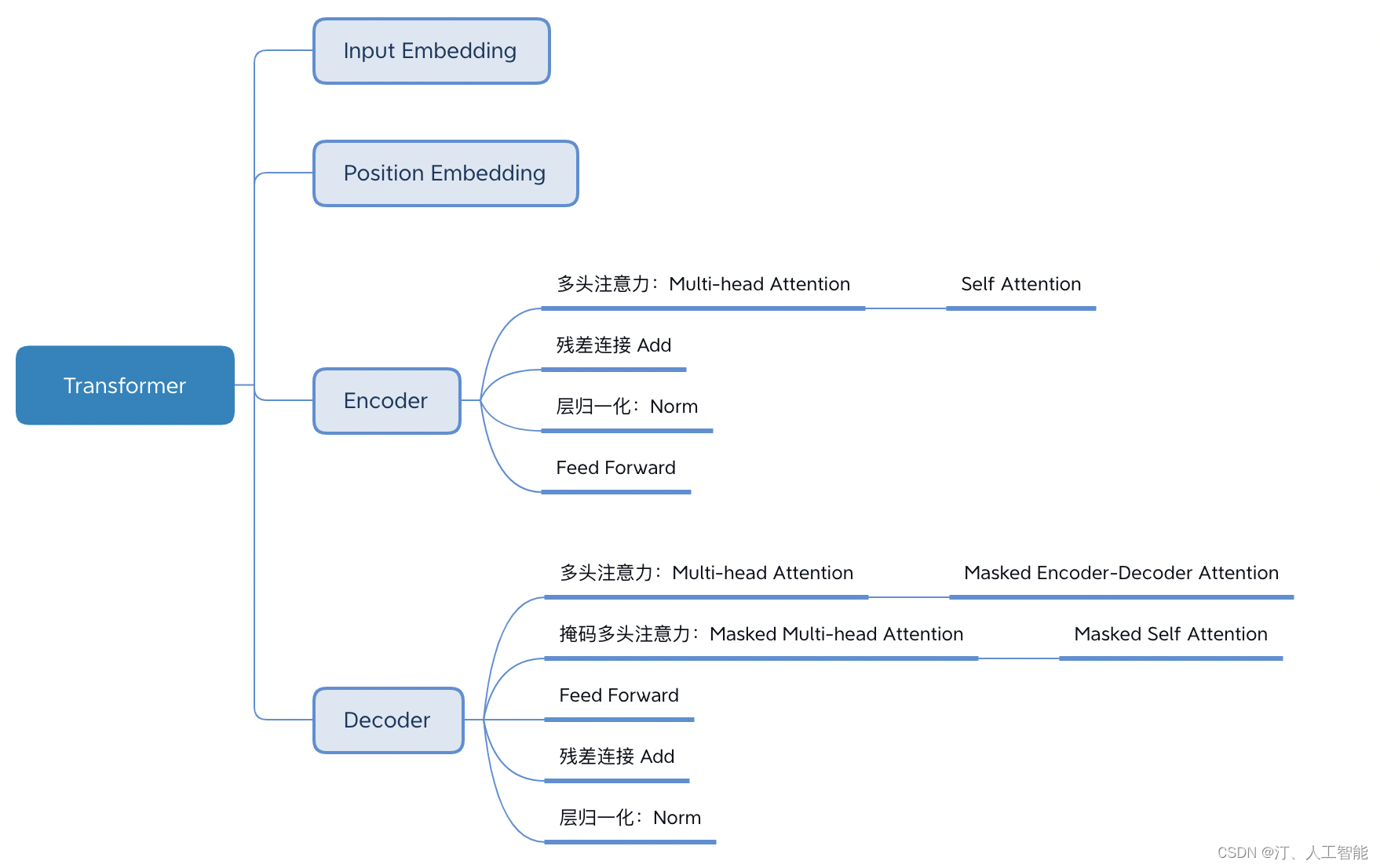
Transformer 的结构解析出来表示,包括 Input Embedding, Position Embedding, Encoder, Decoder。
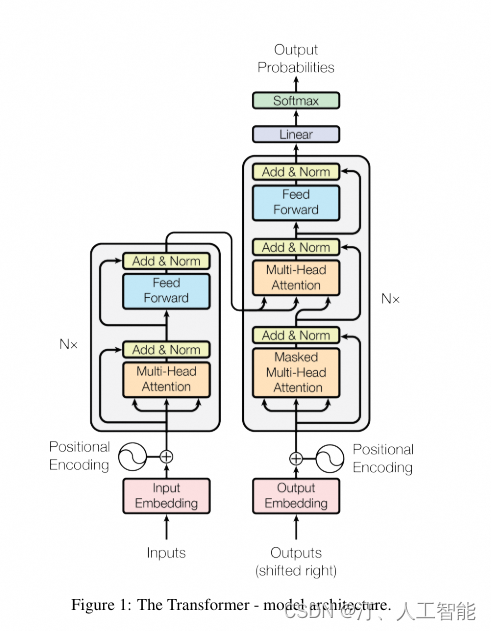
Transformer 改进了 RNN 被人诟病的训练慢的特点,利用 self-attention 可以实现快速并行。下面的章节会详细介绍 Transformer 的各个组成部分。
Transformer 主要由 encoder 和 decoder 两部分组成。在 Transformer 的论文中,encoder 和 decoder 均由 6 个 encoder layer 和 decoder layer 组成,通常我们称之为 encoder block。
Transformer 本质上是一个 Encoder-Decoder 架构。Transformer 的中间部分可以分为两个部分:编码组件和解码组件。如下图所示:
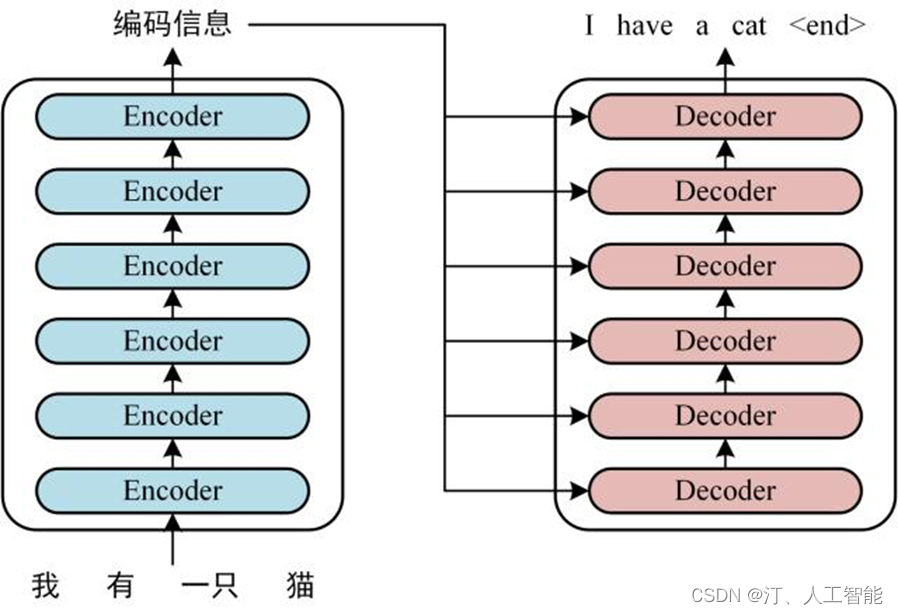
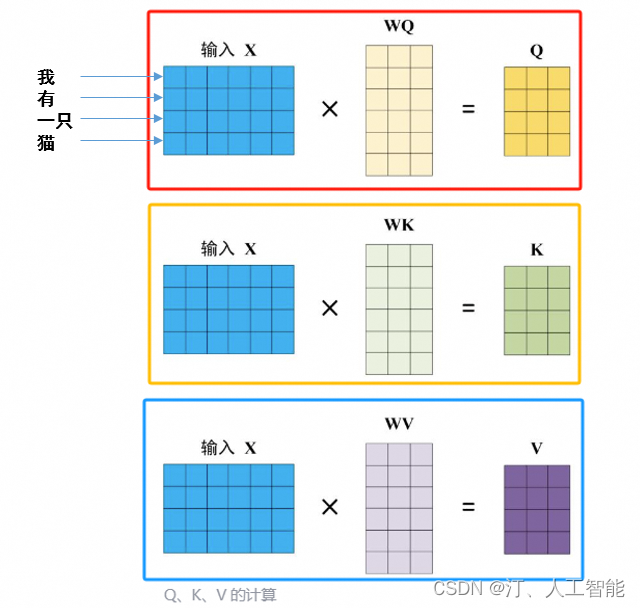
Transformer 输入是一个序列数据,以 “我有一只猫” 为例:Encoder 的 inputs 就是 “i have a cat” 分词后的词向量。
输入 inputs embedding 后需要给每个 word 的词向量添加位置编码 positional encoding。
2.2 Embedding&位置编码 positional encoding
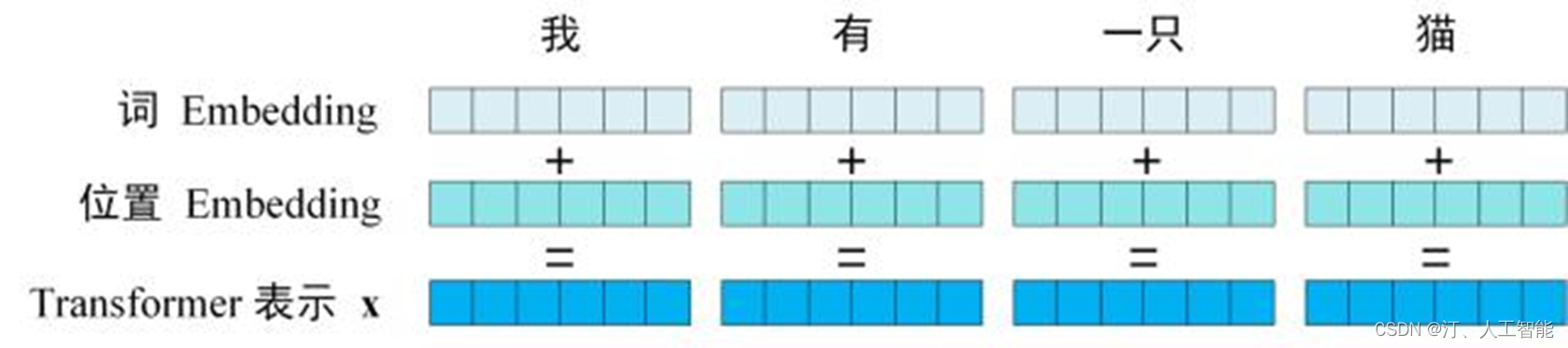
字向量与位置编码的公式表示如下:
X = E m b e d d i n g L o o k u p ( X ) + P o s i t i o n E n c o d i n g X=Embedding Lookup(X)+Position Encoding X=EmbeddingLookup(X)+PositionEncoding
- Input Embedding
可以将 Input Embedding 看作是一个 lookup table,对于每个 word,进行 word embedding 就相当于一个 lookup 操作,查出一个对应结果。
- Position Encoding
Transformer 模型中还缺少一种解释输入序列中单词顺序的方法。为了处理这个问题,transformer 给 encoder 层和 decoder 层的输入添加了一个额外的向量 Positional Encoding,维度和 embedding 的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。这个位置向量的具体计算方法有很多种,论文中的计算方法如下
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE(pos,2i)=sin(pos/10000^{2i}/d_{model}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE(pos,2i+1)=cos(pos/10000^{2i}/d_{model}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中 pos 是指当前词在句子中的位置,i 是指向量中每个值的 index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码.
pos 表示单词在句子中的绝对位置,pos=0,1,2…,例如:have在 “i have a cat” 中的 pos=1;dmodel 表示词向量的维度,在这里 dmodel=512;2i 和 2i+1 表示奇偶性,i 表示词向量中的第几维,例如这里 dmodel=512,故 i=0,1,2…255。
Transformer 模型中的位置编码(Positional Encoding,简称 PE)是一个重要的组成部分,用于捕捉序列中单词的位置信息。其中,正余弦位置编码是一种常用的方式,相比于通过训练学习位置编码的方法,它具有一些独特的优点。以下是关于正余弦位置编码与训练方式比较的详细解释:
2.2.1 PE和训练方式的位置编码对比
-
正余弦位置编码(PE)- 定义与原理:
- 正余弦位置编码为每个位置分配一个独特的编码,通常是一个向量。
- 编码通过不同频率的正弦和余弦函数计算得出,以捕捉绝对位置和相对位置信息。
- 编码的维度与词嵌入的维度相同,确保二者可以逐元素相加。
- 优势:
- 固定性:正余弦位置编码是固定的,不依赖于具体的训练数据,因此可以处理任意长度的序列。
- 可解释性:通过正弦和余弦函数的周期性变化,可以直观地理解编码如何捕捉位置信息。
- 低参数量:不需要额外的参数来学习位置编码,减少模型复杂性。
- 定义与原理:
-
训练方式的位置编码- 方法:
- 这种方法通过模型训练来学习位置编码,通常使用一组可学习的参数来表示位置信息。
- 在训练过程中,模型会调整这些参数以优化整体性能。
- 潜在问题:
- 泛化能力:训练得到的位置编码可能过度依赖于训练数据,导致对新序列的泛化能力较差。
- 参数效率:对于每个位置,都需要额外的参数来学习位置编码,增加了模型的复杂性和计算成本。
处理长序列:当序列长度超过训练时见过的长度时,训练得到的位置编码可能无法有效地表示新位置的信息。
- 方法:
-
两者比较- 泛化能力:正余弦位置编码由于其固定性和周期性,能够更好地处理不同长度的序列,具有更强的泛化能力。
- 参数效率:正余弦位置编码不需要额外的参数来学习位置信息,降低了模型的复杂性和计算成本。
- 可解释性:正余弦位置编码的可解释性更强,可以直观地理解其如何捕捉位置信息。
- 实现简便性:正余弦位置编码的实现相对简单,只需按照固定公式计算即可。
2.3 Encoder
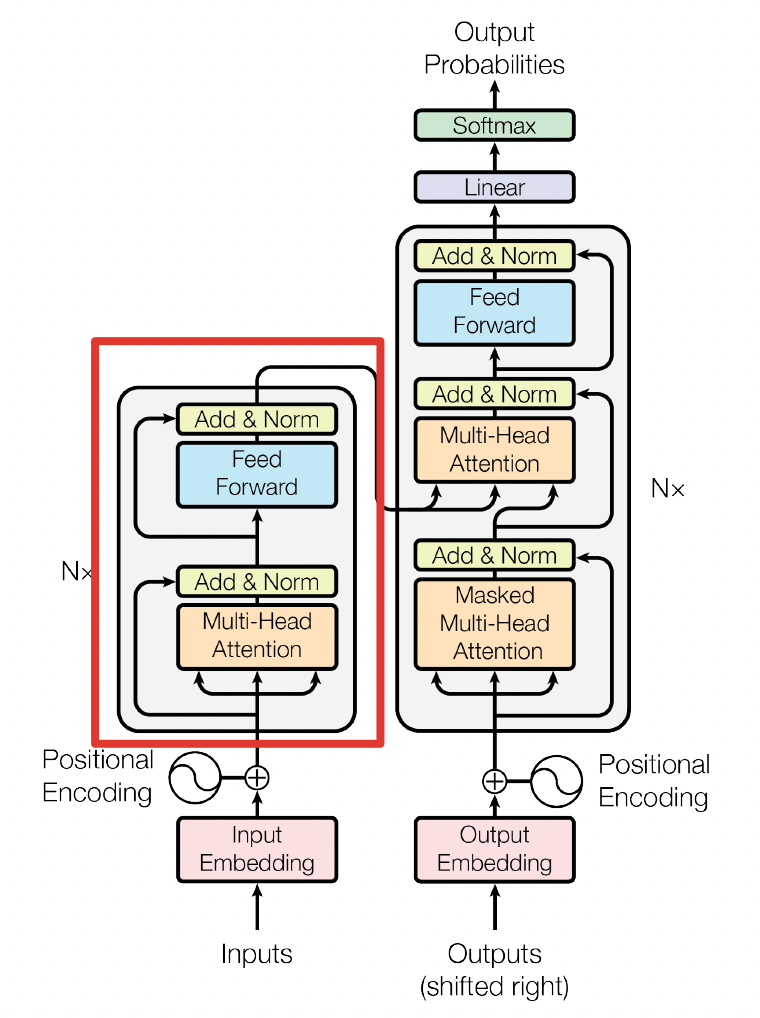
用公式把一个 Transformer Encoder block 的计算过程整理一下
- 自注意力机制
Q = X W Q Q=XW_{Q} Q=XWQ
K = X W K K=XW_{K} K=XWK
V = X W V V=XW_{V} V=XWV
X a t t e n t i o n = s e l f A t t e n t i o n ( Q , K , V ) X_{attention}=selfAttention(Q,K,V) Xattention=selfAttention(Q,K,V)
- self-attention 残差连接与 Layer Normalization
X a t t e n t i o n = L a y e r N o r m ( X a t t e n t i o n ) X_{attention}=LayerNorm(X_{attention}) Xattention=LayerNorm(Xattention)
- FeedForward,其实就是两层线性映射并用激活函数激活,比如说 RELU
X h i d d e n = L i n e a r ( R E L U ( L i n e a r ( X a t t e n t i o n ) ) ) X_{hidden}=Linear(RELU(Linear(X_{attention}))) Xhidden=Linear(RELU(Linear(Xattention)))
- FeedForward 残差连接与 Layer Normalization
X h i d d e n = X a t t e n t i o n + X h i d d e n X_{hidden}=X_{attention}+X_{hidden} Xhidden=Xattention+Xhidden
X h i d d e n = L a y e r N o r m ( X h i d d e n ) X_{hidden}=LayerNorm(X_{hidden}) Xhidden=LayerNorm(Xhidden)
其中: X h i d d e n ∈ R b a t c h s i z e ∗ s e q l e n ∗ e m b e d d i m X_{hidden} \in R^{batch_size*seq_len*embed_dim} Xhidden∈Rbatchsize∗seqlen∗embeddim
2.3.1 多头注意力机制(Multi-head Attention)
通过添加一种多头注意力机制,进一步完善自注意力层。首先,通过 h 个不同的线性变换对 Query、Key 和 Value 进行映射;然后,将不同的 Attention 拼接起来;最后,再进行一次线性变换。基本结构如下图所示:
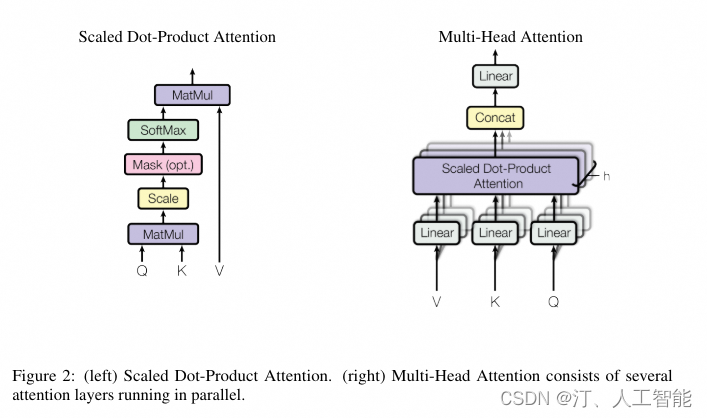
每一组注意力用于将输入映射到不同的子表示空间,这使得模型可以在不同子表示空间中关注不同的位置。整个计算过程可表示为:
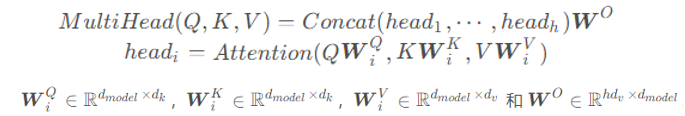
在多头注意力下,将输入的 X 乘以 WQ、WK 和 WV 矩阵,从而为每组注意力单独生成不同的 Query、Key 和 Value 矩阵。如下图所示:
- dot product
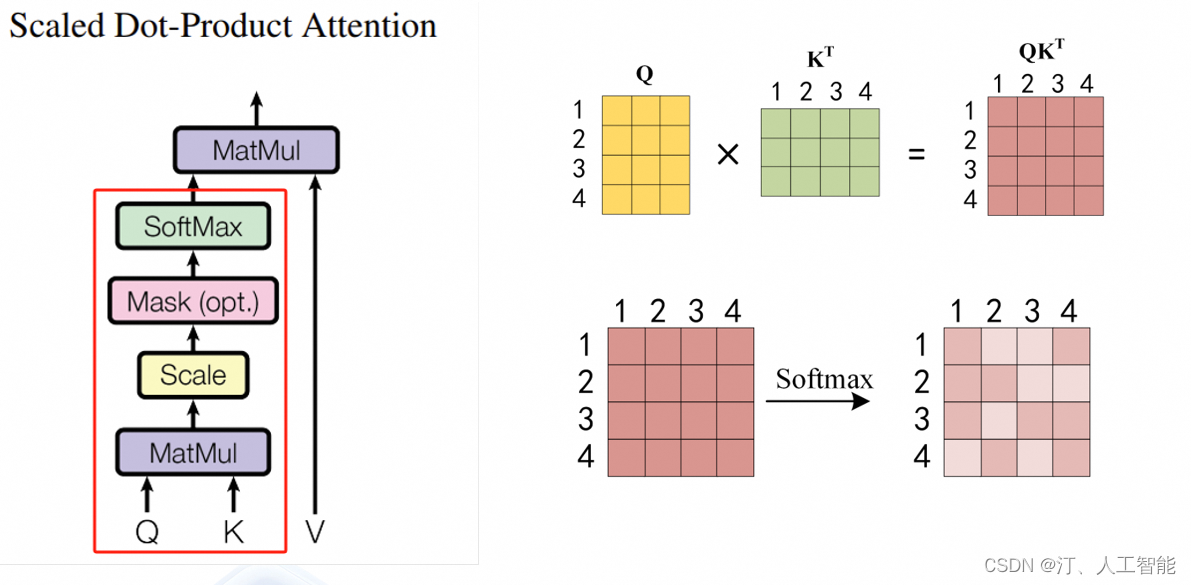
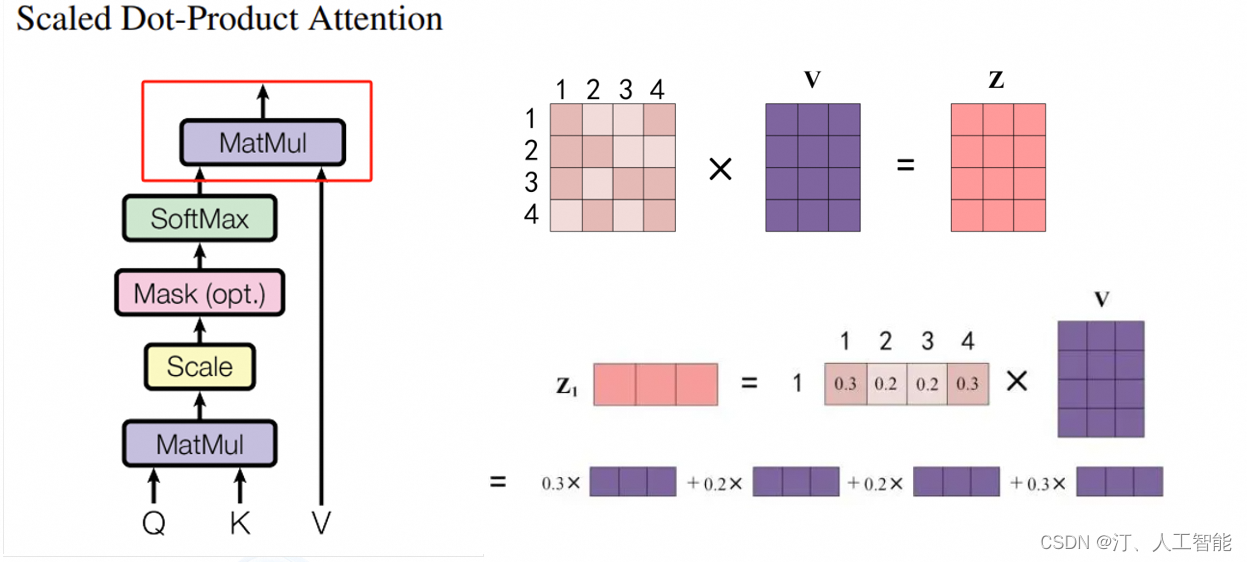
在实际的应用场景,为了提高计算速度,我们采用的是矩阵的方式,直接计算出 Query, Key, Value 的矩阵,然后把 embedding 的值与三个矩阵直接相乘,把得到的新矩阵 Q 与 K 相乘,乘以一个常数,做 softmax 操作,最后乘上 V 矩阵
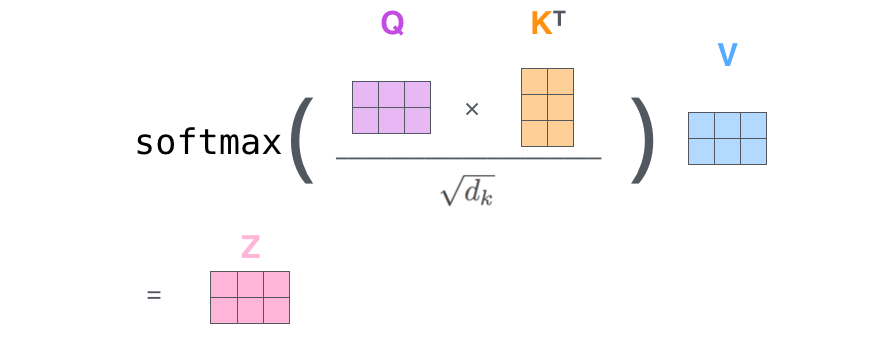

-
scaled dot product attention
这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为 scaled dot-product attention。
用公式表达如下:
Q = X W Q Q=XW_{Q} Q=XWQ
K = X W K K=XW_{K} K=XWK
V = X W V V=XW_{V} V=XWV
X a t t e n t i o n = s e l f A t t e n t i o n ( Q , K , V ) X_{attention}=selfAttention(Q,K,V) Xattention=selfAttention(Q,K,V)
2.3.2 Self-Attention 复杂度
Self-Attention 时间复杂度: O ( n 2 ⋅ d ) O(n^2 \cdot d) O(n2⋅d) ,这里,n 是序列的长度,d 是 embedding 的维度。
Self-Attention 包括三个步骤:相似度计算,softmax 和加权平均,它们分别的时间复杂度是:
相似度计算可以看作大小为 (n,d) 和(d,n)的两个矩阵相乘: ( n , d ) ∗ ( d , n ) = ( n 2 ⋅ d ) (n,d) *(d,n) =(n^2 \cdot d) (n,d)∗(d,n)=(n2⋅d),得到一个 (n,n) 的矩阵
softmax 就是直接计算了,时间复杂度为: O ( n 2 ) O(n^2) O(n2)
加权平均可以看作大小为 (n,n) 和(n,d)的两个矩阵相乘: ( n , d ) ∗ ( d , n ) = ( n 2 ⋅ d ) (n,d) *(d,n) =(n^2 \cdot d) (n,d)∗(d,n)=(n2⋅d),得到一个 (n,d) 的矩阵
因此,Self-Attention 的时间复杂度是: O ( n 2 ⋅ d ) O(n^2 \cdot d) O(n2⋅d)
2.3.4 Attention Visualizations 注意力可视化
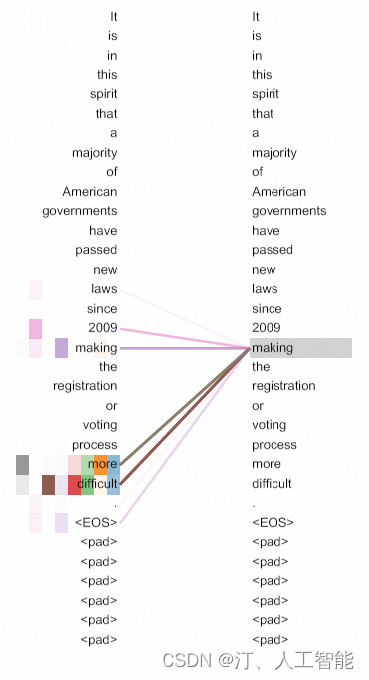
可以看到,在编码making的时候,注意力的关注情况。上面的图只将making的注意力展示出来了。颜色越深的头注意力越集中。
Top: head 5的完整注意力。Bottom: 仅是从head 5 和head 6中剥离出来的对单词‘its’的注意力
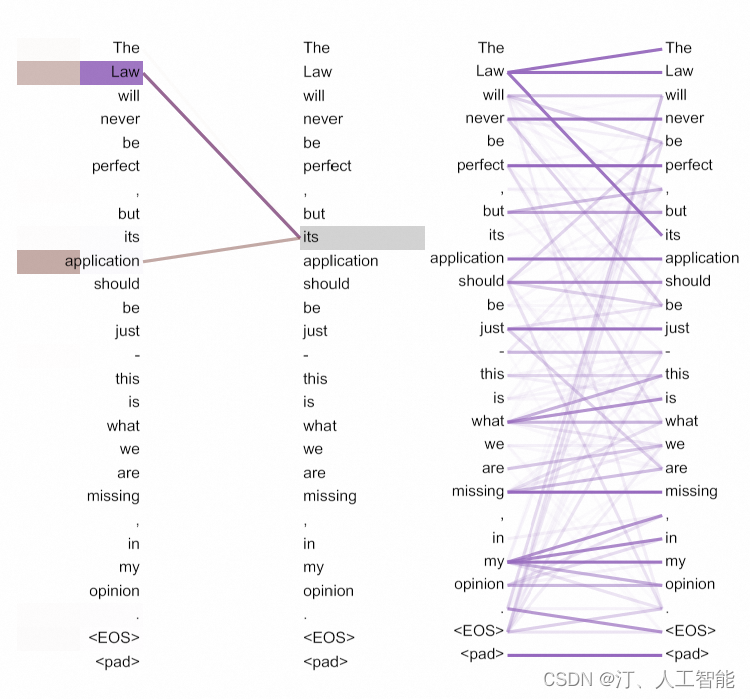
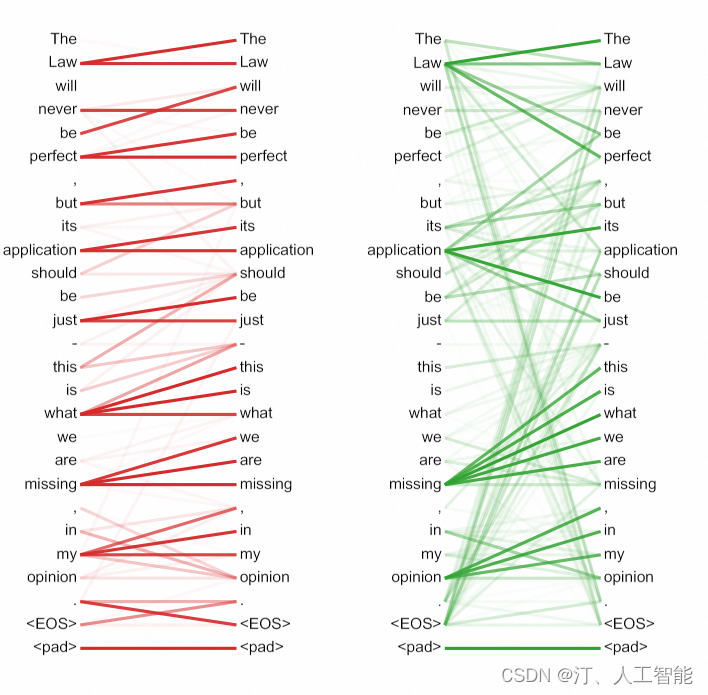
许多注意力头表现出的行为看起来都和句子的结构有些关系。论文中给出了2个例子,来自编码器中不同的注意力头。注意力头显然学会了执行不同的任务。
2.3.5 注意力六种模式
为了方便演示,这里采用以下例句:
句子A:I went to the store.句子B:At the store, I bought fresh strawberries.
BERT 用 WordPiece工具来进行分词,并插入特殊的分离符([CLS],用来分隔样本)和分隔符([SEP],用来分隔样本内的不同句子)。
因此实际输入序列为: [CLS] i went to the store . [SEP] at the store , i bought fresh straw ##berries . [SEP]
模式1:注意下一个词
在这种模式中,每个位置主要注意序列中的下一个词(token)。下面将看到第2层0号头的一个例子。(所选头部由顶部颜色条中突出的显示色块表示。)
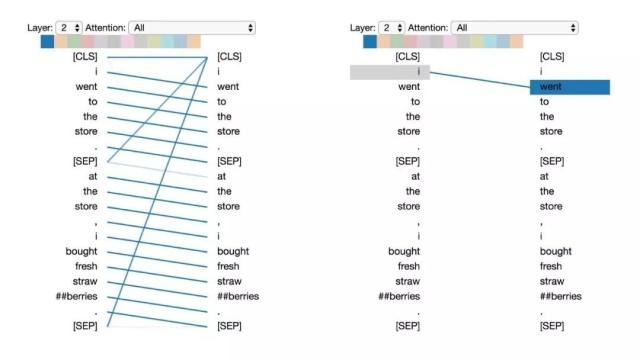
模式1:注意下一个词。
左:所有词的注意力。 右:所选词的注意力权重(“i”)
左边显示了所有词的注意力,而右侧图显示一个特定词(“i”)的注意力。在这个例子中,“i”几乎所有的注意力都集中在“went”上,即序列中的下一个词。
在左侧,可以看到 [SEP]符号不符合这种注意力模式,因为[SEP]的大多数注意力被引导到了[CLS]上,而不是下一个词。因此,这种模式似乎主要在每个句子内部出现。
该模式与后向RNN 有关,其状态的更新是从右向左依次进行。模式1出现在模型的多个层中,在某种意义上模拟了RNN 的循环更新。
模式2:注意前一个词
在这种模式中,大部分注意力都集中在句子的前一个词上。例如,下图中“went”的大部分注意力都指向前一个词“i”。
这个模式不像上一个那样显著。有一些注意力也分散到其他词上了,特别是[SEP]符号。与模式1一样,这与RNN 有些类似,只是这种情况下更像前向RNN。
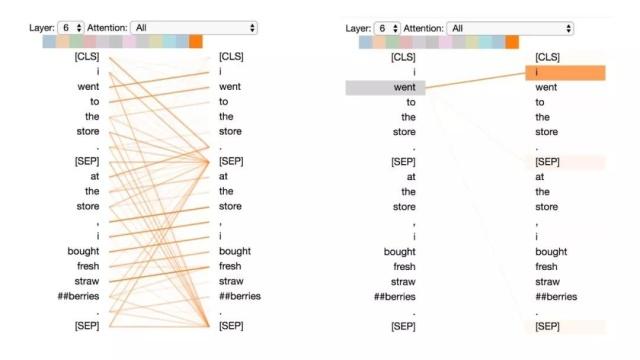
模式2:注意前一个词。
左:所有词的注意力。 右:所选词的注意力权重(“went”)
模式3:注意相同或相关的单词
这种模式注意相同或相关的单词,包括其本身。在下面的例子中,第一次出现的“store”的大部分注意力都是针对自身和第二次出现的“store”。这种模式并不像其他一些模式那样显著,注意力会分散在许多不同的词上。
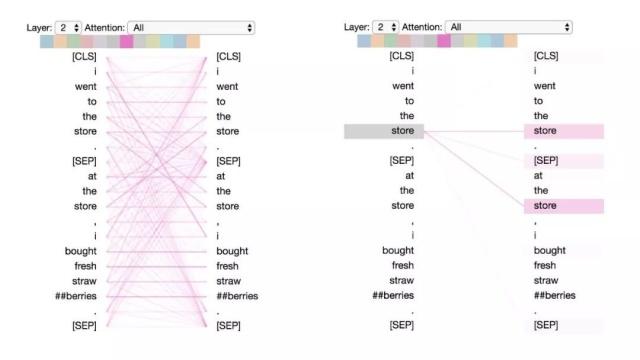
模式3:注意相同/相关的词。
左:所有词的注意力。 右:所选词的注意权重(“store”)
模式4:注意“其他”句子中相同或相关词
这种模式注意另一个句子中相同或相关的单词。例如,第二句中“store”的大部分注意力都指向第一句中的“store”。可以想象这对于下句预测任务(BERT预训练任务的一部分)特别有用,因为它有助于识别句子之间的关系。

模式4:注意其他句子中相同/相关的单词。
左:所有词的注意力。 右:所选词的注意权重(“store”)
模式5:注意能预测该词的其他单词
这种模式似乎是更注意能预测该词的词,而不包括该词本身。在下面的例子中,“straw”的大部分注意力都集中在“##berries”上(strawberries 草莓,因为WordPiece分开了),而“##berries”的大部分注意力也都集中在“straw”上。

模式5:注意能预测该单词的其他单词。
左:所有词的注意力。 右:所选词的注意力(“## berries”)
这个模式并不像其他模式那样显著。例如,词语的大部分注意力都集中在定界符([CLS])上,而这是下面讨论的模式6的特征。
模式6:注意分隔符
在这种模式中,词语的大部分注意力都集中在分隔符[CLS]或 [SEP]上。在下面的示例中,大部分注意力都集中在两个 [SEP]符号上。这可能是模型将句子级状态传播到单个词语上的一种方式。
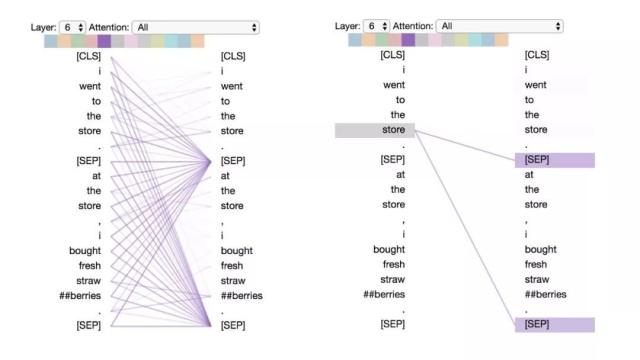
模式6:注意分隔符。 左:所有词的注意力。 右:所选词的注意权重(“store”)
2.4 Decoder
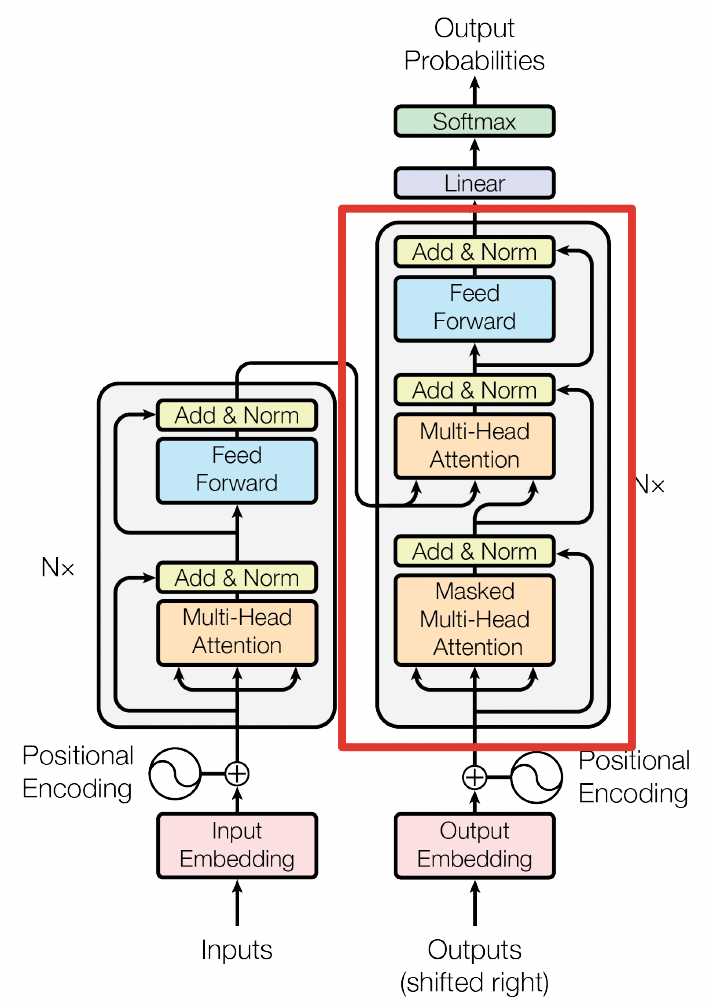
和 Encoder 一样,上面三个部分的每一个部分,都有一个残差连接,后接一个 Layer Normalization。Decoder 的中间部件并不复杂,大部分在前面 Encoder 里我们已经介绍过了,但是 Decoder 由于其特殊的功能,因此在训练时会涉及到一些细节,下面会介绍 Decoder 的 Masked Self-Attention 和 Encoder-Decoder Attention 两部分,其结构图如下图所示
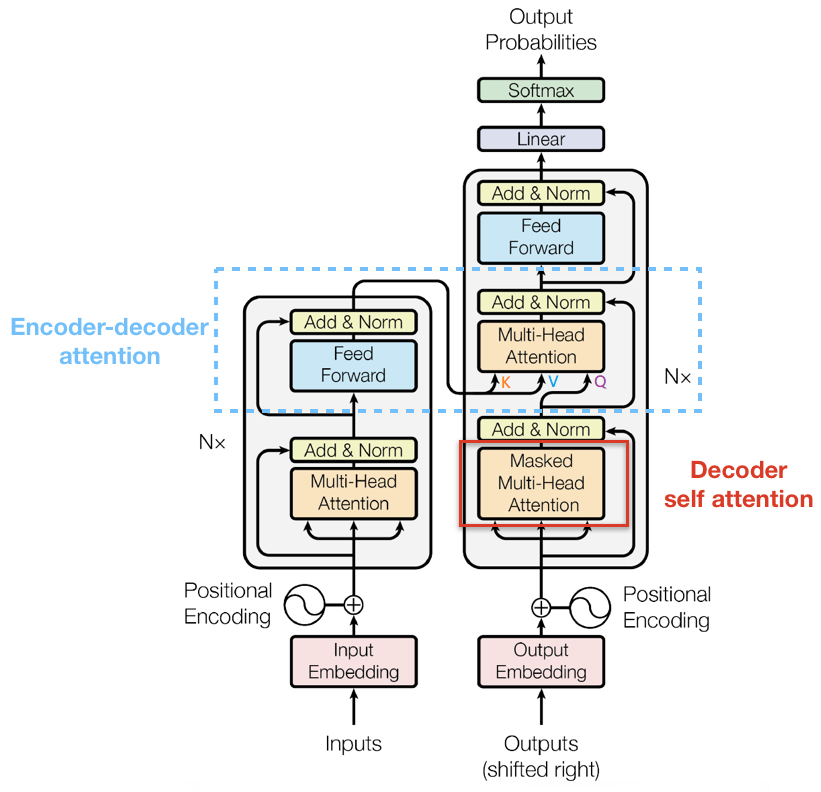
2.4.1 Masked Self-Attention
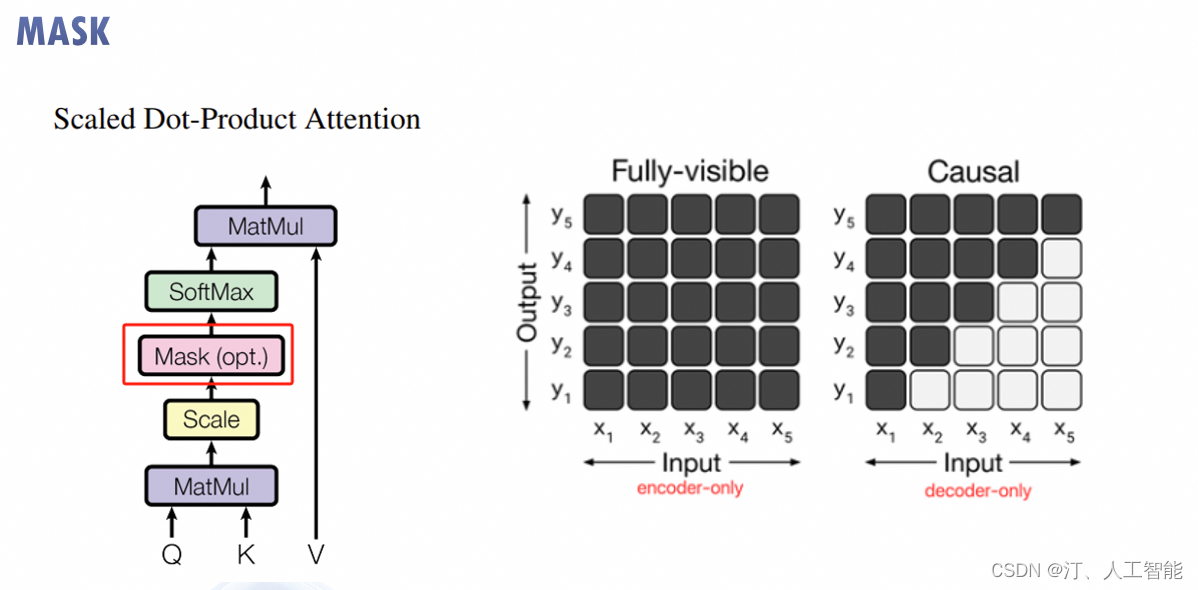
传统 Seq2Seq 中 Decoder 使用的是 RNN 模型,因此在训练过程中输入因此在训练过程中输入 t 时刻的词,模型无论如何也看不到未来时刻的词,因为循环神经网络是时间驱动的,只有当 t 时刻运算结束了,才能看到 t+1 时刻的词。而 Transformer Decoder 抛弃了 RNN,改为 Self-Attention,由此就产生了一个问题,在训练过程中,整个 ground truth 都暴露在 Decoder 中,这显然是不对的,我们需要对 Decoder 的输入进行一些处理,该处理被称为 Mask。
Mask 非常简单,首先生成一个下三角全 0,上三角全为负无穷的矩阵,然后将其与 Scaled Scores 相加即可,之后再做 softmax,就能将 -inf 变为 0,得到的这个矩阵即为每个字之间的权重。
2.4.2 Masked Encoder-Decoder Attention
其实这一部分的计算流程和前面 Masked Self-Attention 很相似,结构也一摸一样,唯一不同的是这里的 K,V 为 Encoder 的输出,Q 为 Decoder 中 Masked Self-Attention 的输出
其实这一部分的计算流程和前面 Masked Self-Attention 很相似,结构也一摸一样,唯一不同的是这里的 K,V 为 Encoder 的输出,Q 为 Decoder 中 Masked Self-Attention 的输出
3.4.3 Decoder 的解码
下图展示了 Decoder 的解码过程,Decoder 中的字符预测完之后,会当成输入预测下一个字符,知道遇见终止符号为止。

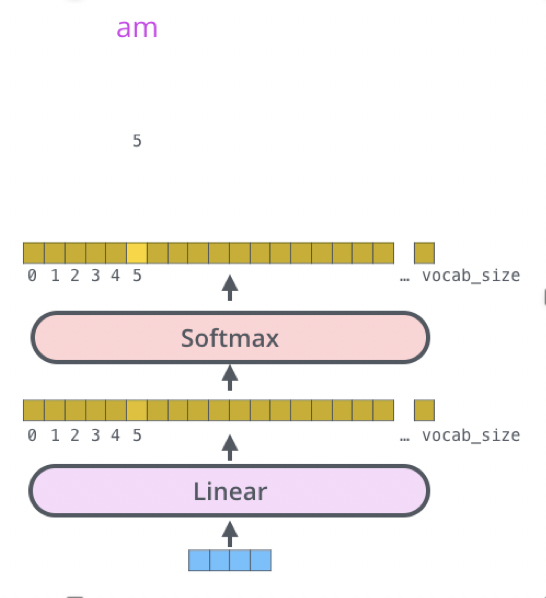
2.5 Transformer 的最后一层和 Softmax
线性层是一个简单的全连接的神经网络,它将解码器堆栈生成的向量投影到一个更大的向量,称为 logits 向量。如图 linear 的输出
softmax 层将这些分数转换为概率(全部为正值,总和为 1.0)。选择概率最高的单元,并生成与其关联的单词作为此时间步的输出。如图 softmax 的输出。
2.6 Transformer 的权重共享
Transformer 在两个地方进行了权重共享:
- (1)Encoder 和 Decoder 间的 Embedding 层权重共享;
《Attention is all you need》中 Transformer 被应用在机器翻译任务中,源语言和目标语言是不一样的,但它们可以共用一张大词表,对于两种语言中共同出现的词(比如:数字,标点等等)可以得到更好的表示,而且对于 Encoder 和 Decoder,嵌入时都只有对应语言的 embedding 会被激活,因此是可以共用一张词表做权重共享的。
论文中,Transformer 词表用了 bpe 来处理,所以最小的单元是 subword。英语和德语同属日耳曼语族,有很多相同的 subword,可以共享类似的语义。而像中英这样相差较大的语系,语义共享作用可能不会很大。
但是,共用词表会使得词表数量增大,增加 softmax 的计算时间,因此实际使用中是否共享可能要根据情况权衡。
- (2)Decoder 中 Embedding 层和 FC 层权重共享;
Embedding 层可以说是通过 onehot 去取到对应的 embedding 向量,FC 层可以说是相反的,通过向量(定义为 x)去得到它可能是某个词的 softmax 概率,取概率最大(贪婪情况下)的作为预测值。
那哪一个会是概率最大的呢?在 FC 层的每一行量级相同的前提下,理论上和 x 相同的那一行对应的点积和 softmax 概率会是最大的(可类比本文问题 1)。
因此,Embedding 层和 FC 层权重共享,Embedding 层中和向量 x 最接近的那一行对应的词,会获得更大的预测概率。实际上,Decoder 中的 Embedding 层和 FC 层有点像互为逆过程。
通过这样的权重共享可以减少参数的数量,加快收敛。
3.总结
Transformer模型,作为自然语言处理(NLP)领域的一项重大突破,彻底改变了序列建模的传统范式。与传统的循环神经网络(RNN)和卷积神经网络(CNN)相比,Transformer凭借其并行化计算和自注意力机制,在多个NLP任务上取得了显著的性能提升。
-
核心特点:
自注意力机制:Transformer通过自注意力机制捕捉输入序列中的依赖关系,无论这些关系在序列中的距离有多远。这使得模型能够同时关注到整个序列的信息,从而提高了信息处理的效率和准确性。并行化计算:Transformer模型摒弃了RNN的递归结构,转而采用全连接的自注意力层。这种设计使得模型在训练时可以并行化计算,大大加速了训练速度。位置编码:为了弥补Transformer模型无法直接处理序列顺序的缺陷,模型引入了位置编码(Positional Encoding),将序列的位置信息嵌入到输入中。
-
组成结构:
Transformer模型主要由编码器(Encoder)和解码器(Decoder)两部分组成。编码器负责将输入序列映射到一个连续的表示空间中,而解码器则根据这个表示空间生成输出序列。编码器:由多个相同的层堆叠而成,每层包含一个自注意力子层和一个前馈神经网络子层。自注意力子层用于捕捉输入序列中的依赖关系,而前馈神经网络子层则用于对自注意力层的输出进行非线性变换。解码器:同样由多个相同的层堆叠而成,但每层除了包含编码器中的两个子层外,还增加了一个额外的跨注意力子层。这个跨注意力子层用于在生成输出序列时,同时考虑编码器输出的表示和已生成的输出序列。
- 应用场景:
Transformer模型在多个NLP任务上均取得了卓越的性能,包括但不限于机器翻译、文本摘要、问答系统、情感分析等。其强大的并行化计算能力和自注意力机制使得模型能够处理长序列数据,并在大规模数据集上快速训练。
- 未来展望:
随着计算能力的提升和模型架构的进一步优化,Transformer模型在未来有着广阔的应用前景。例如,可以将其应用于跨语言理解、多模态数据处理等更复杂的NLP任务中。同时,结合其他深度学习技术,如强化学习、生成对抗网络等,可以进一步拓展Transformer模型的应用领域和性能边界。