深度学习模型评估指标
一个深度学习模型在各类任务中的表现都需要定量的指标进行评估,才能够进行横向的对比比较,包含了分类、回归、质量评估、生成模型中常用的指标。
一. 分类评测指标
图像分类是计算机视觉中最基础的一个任务,也是几乎所有的基准模型进行比较的任务,从最开始比较简单的10分类的灰度图像手写数字识别mnist,到后来更大一点的10分类的cifar10和100分类的cifar100,到后来的imagenet,图像分类任务伴随着数据库的增长,一步一步提升到了今天的水平。现在在Imagenet这样的超过1000万图像,2万类的数据集中,计算机的图像分类水准已经超过了人类。
图像分类,顾名思义就是一个模式分类问题,它的目标是将不同的图像,划分到不同的类别,实现最小的分类误差,这里只考虑单标签分类问题,即每一个图片都有唯一的类别。
对于单个标签分类的问题,评价指标主要有Accuracy,Precision,Recall,F-score,PR曲线,ROC和AUC
在计算这些指标之前,先计算几个基本指标,这些指标是基于二分类的任务,也可以拓展到多分类:
TP:真正率(正样本被预测成正样本)TP/(TP+FN)。概率越大越好
FP:假正率(负样本被预测成正样本)FN(TN+FP)
FN:假负率(正样本被预测成负样本)FN/(TP+FN)
TN:真负率(负样本被预测成负样本)TN/(TN+FP)。概率越大越好
样本总数=TP+FP+FN+TN
判别是否为正例只需要设一个概率阈值T,预测概率大于阈值T的为正类,小于阈值T的为负类,默认就是0.5。如果我们减小这个阀值T,更多的样本会被识别为正类,这样可以提高正类的召回率,但同时也会带来更多的负类被错分为正类。如果增加阈值T,则正类的召回率降低,精度增加。如果是多类,比如ImageNet1000分类比赛中的1000类,预测类别就是预测概率最大的那一类。
1.准确率
(1)准确率
单标签分类任务中每一个样本都只有一个确定的类别,预测到该类别就是分类正确,没有预测到就是分类错误,因此最直观的指标就是Accuracy,也就是准确率。 即预测正确的结果占总样本的百分比,表达式为 :
准确率
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
准确率=\frac{TP+TN}{TP+TN+FP+FN}
准确率=TP+TN+FP+FNTP+TN
表示的就是所有样本都正确分类的概率,可以使用不同的阈值T。
虽然准确率能够判断总的正确率,但是在样本不均衡的情况下,并不能作为很好的指标来衡量结果。
比如在样本集中,正样本有90个,负样本有10个,样本是严重的不均衡。对于这种情况,我们只需要将全部样本预测为正样本,就能得到90%的准确率,但是完全没有意义。对于新数据,完全体现不出准确率。因此,在样本不平衡的情况下,得到的高准确率没有任何意义,此时准确率就会失效。所以,我们需要寻找新的指标来评价模型的优劣。
(2)扩展
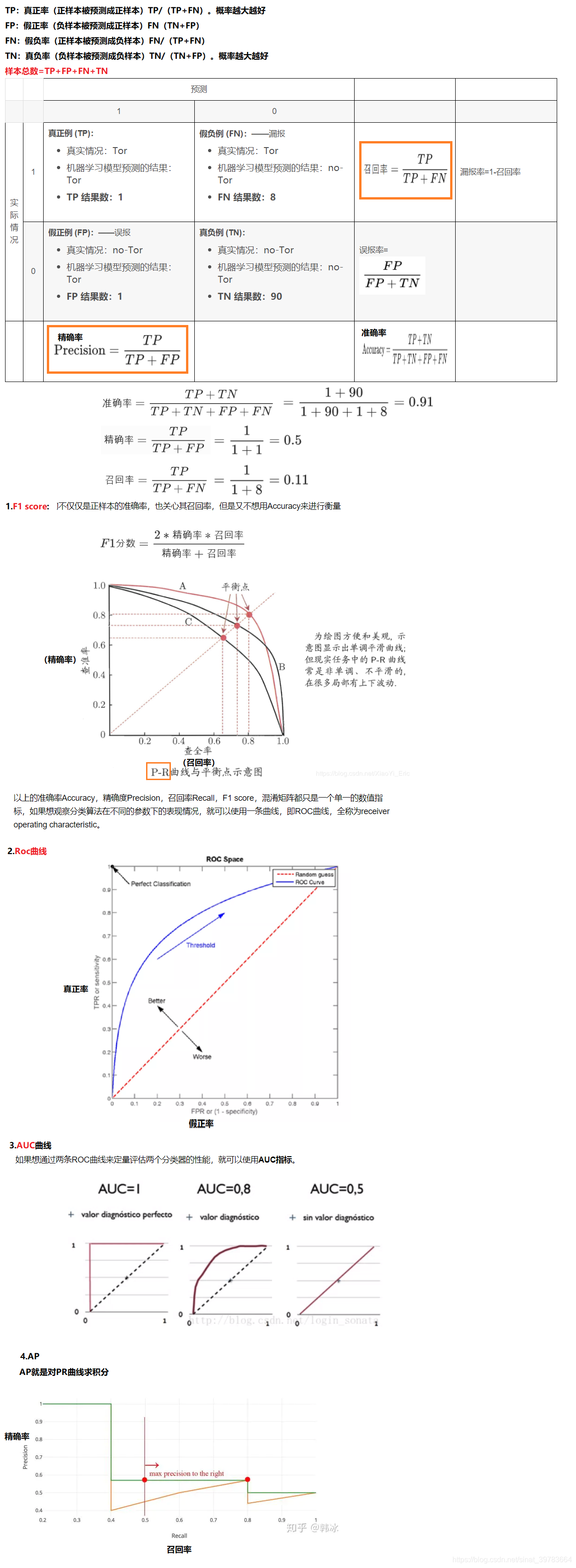
在ImageNet中使用的Accuracy指标包括Top_1 Accuracy和Top_5 Accuracy,Top_1 Accuracy就是前面计算的Accuracy。
记样本
x
i
x_i
xi的类别为
y
i
y_i
yi,类别种类为(0,1,…,C),预测类别函数为f,则Top-1的计算方法如下:
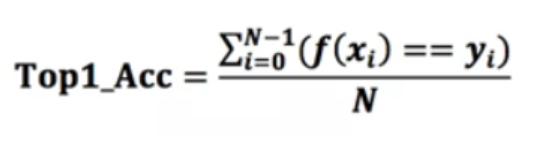
如果给出概率最大的5个预测类别,只要包含了真实的类别,则判定预测正确,计算出来的指标就是Top-5。目前在ImageNet上,Top-5的指标已经超过95%,而Top-1的指标还在80%左右。
2.精确率和召回率
如果只考虑正样本的指标,有两个很常用的指标,精确度和召回率。
(1)精确率
正样本精确率表示的是召回为正样本的样本中,到底有多少是真正的正样本。
精确率(Precision) 是针对预测结果而言的,其含义是在被所有预测为正的样本中实际为正样本的概率,表达式为 :
精确率
=
T
P
T
P
+
F
P
精确率=\frac{TP}{TP+FP}
精确率=TP+FPTP
精确率和准确率看上去有些类似,但是是两个完全不同的概念。精确率代表对正样本结果中的预测准确程度,准确率则代表整体的预测准确程度,包括正样本和负样本。
(2)召回率
正样本召回率表示的是有多少样本被召回类。当然,如果对负样本感兴趣的,也可以计算对应的精确率和召回率,这里记得区分精确率和准确率的分别。
召回率(Recall) 是针对原样本而言的,其含义是在实际为正的样本中被预测为正样本的概率,表达式为 :
召回率
=
T
P
T
P
+
F
N
召回率=\frac{TP}{TP+FN}
召回率=TP+FNTP
下面我们通过一个简单例子来看看精确率和召回率。假设一共有10篇文章,里面4篇是你要找的。根据你的算法模型,你找到了5篇,但实际上在这5篇之中,只有3篇是你真正要找的。
那么算法的精确率是3/5=60%,也就是你找的这5篇,有3篇是真正对的。算法的召回率是3/4=75%,也就是需要找的4篇文章,你找到了其中三篇。以精确率还是以召回率作为评价指标,需要根据具体问题而定。
(3)比较
通常召回率越高,精确度越低,根据不同的值可以绘制Recall-Precision曲线,如下图:
横轴就是recall,纵轴就是precision,曲线越接近右上角,说明其性能越好,可以用该曲线与坐标轴包围的面积来定量评估,值在0~1之间。
3.误报率

4.混淆矩阵
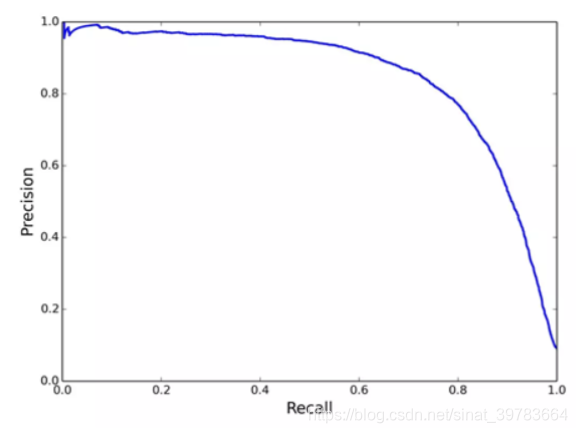
如果对于每一类,若想知道类别之间相互误分的情况,查看是否有特定的类别之间相互混淆,就可以用混淆矩阵画出分类的详细预测结果。对于包含多个类别的任务,混淆矩阵很清晰的反映出各类别之间的错分概率,如下图:
上图表述的是一个包含20个类别的分类任务,混淆矩阵为20*20的矩阵,其中第
i
i
i行第
j
j
j列,表示第
i
i
i类目标被分类为第j类的概率,越好的分类器对角线上的值更大,其他地方应该越小。
5.F1分数
有的时候关注的不仅仅是正样本的准确率,也关心其召回率,但是又不想用Accuracy来进行衡量,一个折中的指标是采用F-score
精确率和召回率又被叫做查准率和查全率,可以通过P-R图(双高)进行表示 :
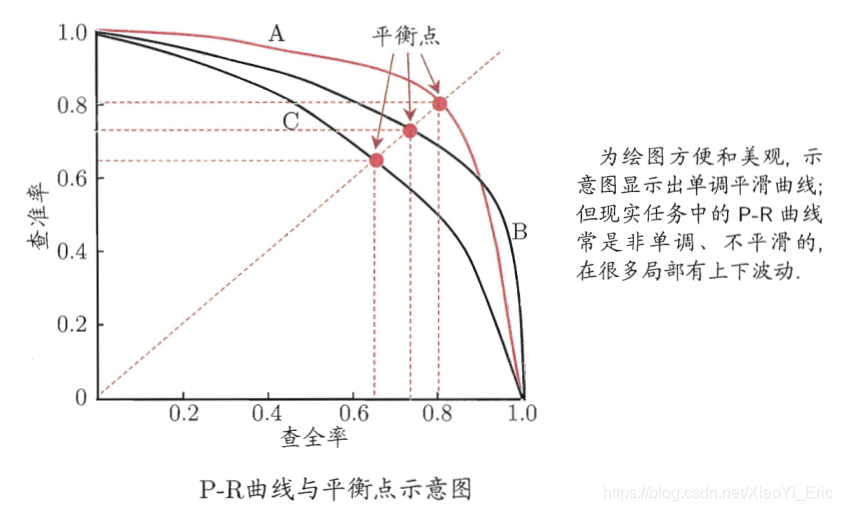
如何理解P-R(精确率-召回率)曲线呢?或者说这些曲线是根据什么变化呢?
以逻辑回归举例,其输出值是0-1之间的数字。因此,如果我们想要判断用户的好坏,那么就必须定一个阈值。比如大于0.5指定为好用户,小于0.5指定为坏用户,然后就可以得到相应的精确率和召回率。但问题是,这个阈值是我们随便定义的,并不知道这个阈值是否符合我们的要求。因此为了寻找一个合适的阈值,我们就需要遍历0-1之间所有的阈值,而每个阈值都对应一个精确率和召回率,从而就能够得到上述曲线。
根据上述的P-R曲线,怎么判断最好的阈值点呢?首先我们先明确目标,我们希望精确率和召回率都很高,但实际上是矛盾的,上述两个指标是矛盾体,无法做到双高。因此,选择合适的阈值点,就需要根据实际问题需求,比如我们想要很高的精确率,就要牺牲掉一些召回率。想要得到很高的召回率,就要牺牲掉一些精准率。但通常情况下,我们可以根据他们之间的平衡点,定义一个新的指标:F1分数(F1-Score)。F1分数同时考虑精确率和召回率,让两者同时达到最高,取得平衡。F1分数表达式为
F
1
分数
=
2
∗
精确率
∗
召回率
精确率
+
召回率
F1分数=\frac{2*精确率*召回率}{精确率+召回率}
F1分数=精确率+召回率2∗精确率∗召回率
上图P-R曲线中,平衡点就是F1值的分数。
只有在召回率Recall和精确率Precision都高的情况下,F1 score才会很高,因此F1 score是一个综合性能的指标 。
6.Roc、AUC曲线
以上的准确率Accuracy,精确度Precision,召回率Recall,F1 score,混淆矩阵都只是一个单一的数值指标,如果想观察分类算法在不同的参数下的表现情况,就可以使用一条曲线,即ROC曲线,全称为receiver operating characteristic。
正式介绍ROC和AUC之前,还需要再介绍两个指标,真正率(TPR)和假正率(FPR)。 (第1节中有介绍)
- 真正率(TPR) = 灵敏度(Sensitivity) = TP/(TP+FN)
- 假正率(FPR) = 1-特异度(Specificity) = FP/(FP+TN)
TPR和FPR分别是基于实际表现1、0出发的,也就是说在实际的正样本和负样本中来观察相关概率问题。因此,无论样本是否均衡,都不会被影响。
继续用上面例子,总样本中有90%的正样本,10%的负样本。TPR能够得到90%正样本中有多少是被真正覆盖的,而与那10%无关。同理FPR能够得到10%负样本中有多少是被覆盖的,而与那90%无关。因此我们从实际表现的各个结果出发,就能避免样本不平衡的问题,这就是为什么用TPR和FPR作为ROC、AUC指标的原因。
6.1Roc曲线
- Roc曲线
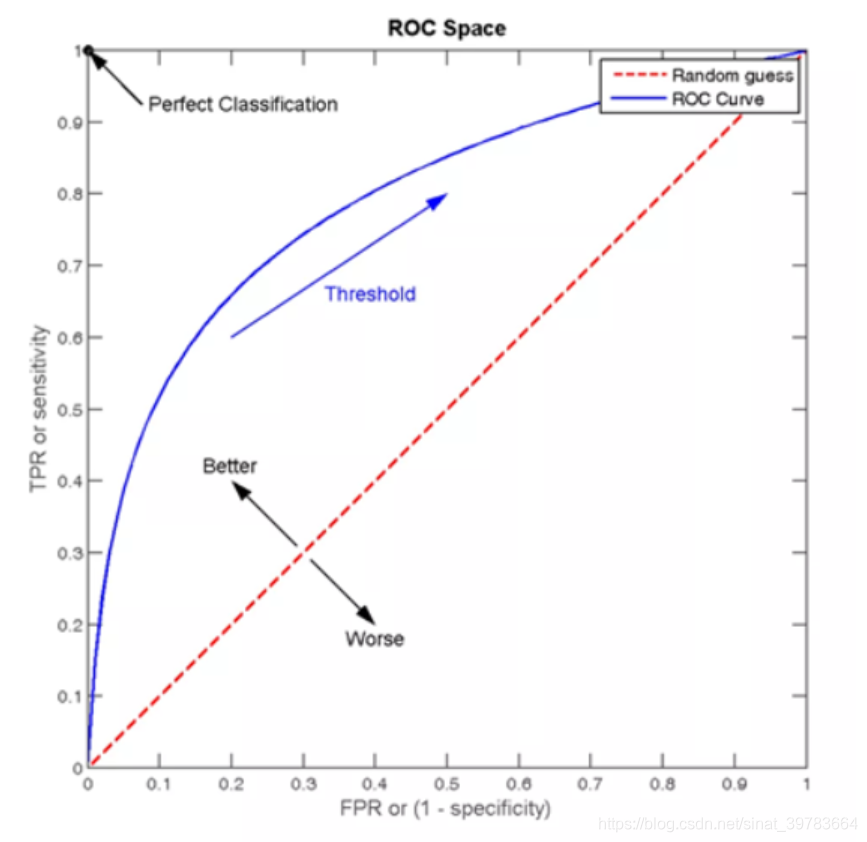
ROC曲线可以用于评价一个分类器在不同阈值下的表现情况。 ROC曲线图如下所示,每个点的横坐标为假正率(FPR),纵坐标为真正率(TPR),描绘了分类器在True Positive和False Positive间的平衡 。
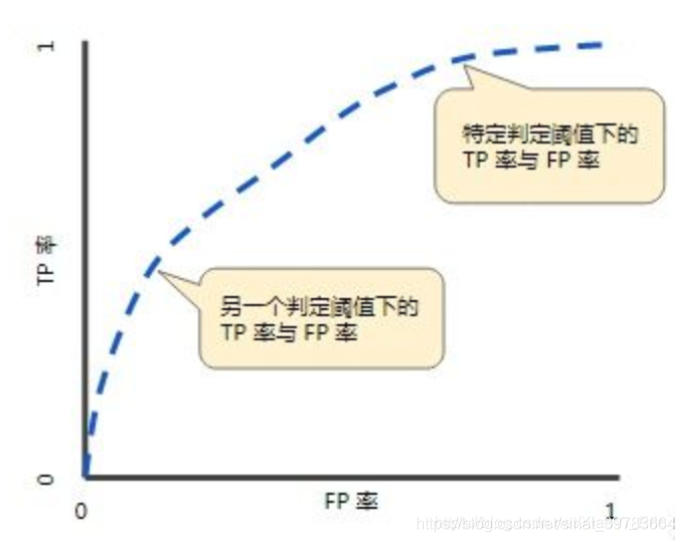
其中有4个关键的点:
点(0,0):FPR=TPR=0,分类器预测所有的样本都为负样本;
点(1,1):FPR=TPR=1,分类器预测所有的样本都为正样本;
点(0,1):FPR=0, TPR=1,此时FN=0且FP=0,所有的样本都正确分类;
点(1,0):FPR=1,TPR=0,此时TP=0且TN=0,最差分类器,避开了所有正确答案。
与前面的P-R曲线类似,ROC曲线也是通过遍历所有阈值来绘制曲线的。如果我们不断的遍历所有阈值,预测的正样本和负样本是在不断变化的,相应的ROC曲线TPR和FPR也会沿着曲线滑动。
同时,我们也会思考,如何判断ROC曲线的好坏呢?我们来看,FPR表示模型虚报的程度,TPR表示模型预测覆盖的程度。理所当然的,我们希望虚报的越少越好,覆盖的越多越好。所以TPR越高,同时FPR越低,也就是ROC曲线越陡,那么模型的性能也就越好。
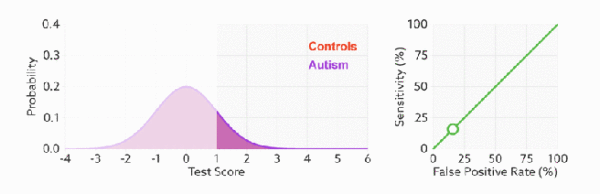
最后,我们来看一下,不论样本比例如何改变,ROC曲线都没有影响,也就是ROC曲线无视样本间的不平衡问题
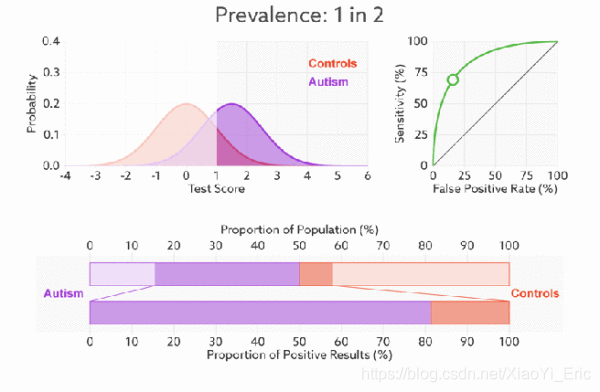
- 附加
ROC曲线相对于PR曲线有个很好的特性:
**当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变,即对正负样本不均衡问题不敏感。**比如负样本的数量增加到原来的10倍,TPR不受影响,FPR的各项也是成比例的增加,并不会有太大的变化。所以不均衡样本问题通常选用ROC作为评价标准。
ROC曲线越接近左上角,该分类器的性能越好,若一个分类器的ROC曲线完全包住另一个分类器,那么可以判断前者的性能更好。
6.2AUC
如果想通过两条ROC曲线来定量评估两个分类器的性能,就可以使用AUC指标。
AUC(Area Under Curve)为ROC曲线下的面积,它表示的就是一个概率,这个面积的数值不会大于1。随机挑选一个正样本以及一个负样本,AUC表征的就是有多大的概率,分类器会对正样本给出的预测值高于负样本,当然前提是正样本的预测值的确应该高于负样本。用于判断模型的优劣。
如ROC曲线所示,连接对角线的面积刚好是0.5,对角线的含义也就是随机判断预测结果,正负样本覆盖应该都是50%。另外,ROC曲线越陡越好,所以理想值是1,即正方形。所以AUC的值一般是介于0.5和1之间的。AUC评判标准可参考如下
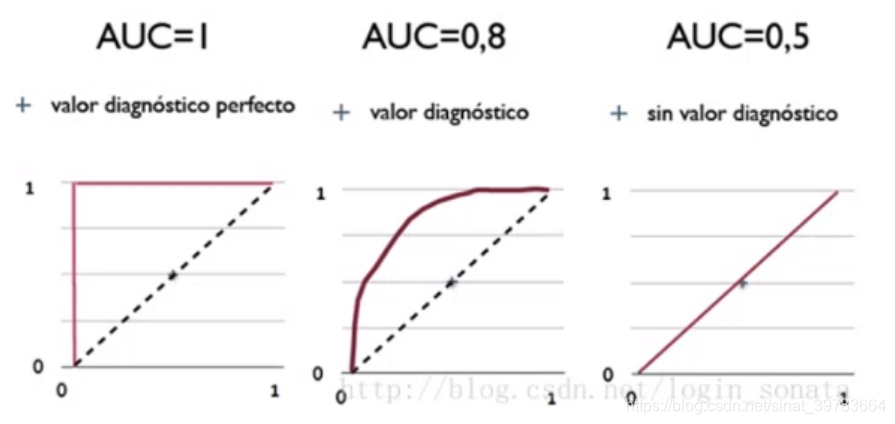
- 0.5-0.7:效果较低。
- 0.7-0.85:效果一般。
- 0.85-0.95:效果很好。
- 0.95-1:效果非常好。
7. TAR,FRR,FAR
这几个指标在人脸验证中被广泛使用,人脸验证即匹配两个人是否是同一个人,通常用特征向量的相似度进行描述,如果相似度概率大于阈值T,则被认为是同一个人。
TAR(True Accept Rate)表示正确接受的比例,多次取同一个人的两张图像,统计该相似度值超过阈值T的比例。FRR(False Reject Rate)就是错误拒绝率,把相同的人的图像当做不同人的了,它等于1-TAR。
与之类似,FAR(False Accept Rate)表示错误接受的比例,多次取不同人的两张图像,统计该相似度值超过T的比例。
增大相似度阈值T,FAR和TAR都减小,意味着正确接受和错误接受的比例都降低,错误拒绝率FRR会增加。减小相似度阈值T,FAR和TAR都增大,正确接受的比例和错误接受的比例都增加,错误拒绝率FRR降低。
二.检索与回归指标
1.IOU
IoU全称Intersection-over-Union,即交并比,在目标检测领域中,定义为两个矩形框面积的交集和并集的比值,IoU=A∩B/A∪B 。
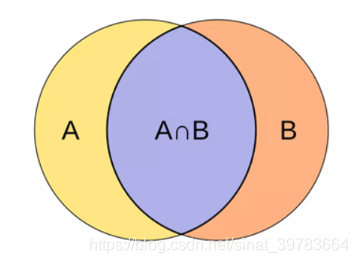
如果完全重叠,则IoU等于1,是最理想的情况。一般在检测任务中,IoU大于等于0.5就认为召回,如果设置更高的IoU阈值,则召回率下降,同时定位框也越更加精确。
在图像分割中也会经常使用IoU,此时就不必限定为两个矩形框的面积。比如对于二分类的前背景分割,那么IoU=(真实前景像素面积∩预测前景像素面积)/(真实前景像素面积∪预测前景像素面积),这一个指标,通常比直接计算每一个像素的分类正确概率要低,也对错误分类更加敏感。
2.AP和mAP
(1)AP
Average Precision简称AP,这是一个在检索任务和回归任务中经常使用的指标,实际等于Precision-Recall曲线下的面积,这个曲线在上一小节已经说过,下面针对目标检测中举出一个例子进行计算,这一个例子在网上也是广泛流传。AP是对所有图片的某一类来说的。计算方法如下:
- 首先使用训练好的模型获得所有测试样本的confideutnce score,每个类别(如person、car等)都会获得一组confidence score,假设现在共有20个测试样本,如下给出这20个样本的id、confidence score、真实标签ground truth label。
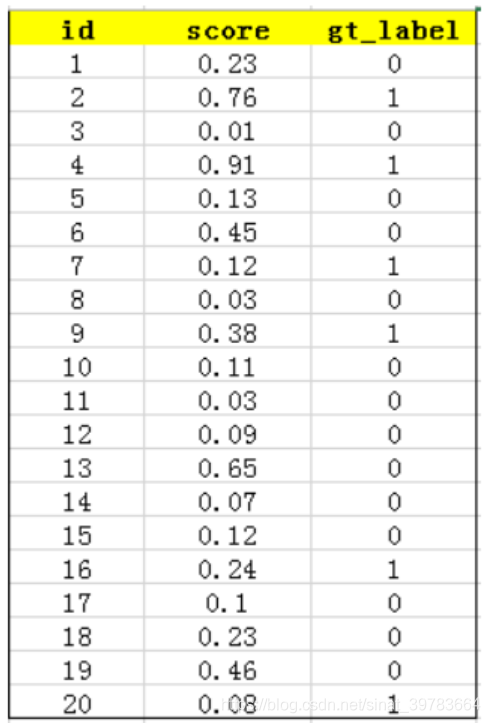
-
按照上图中的score值从大到小对所有样本进行排序,排序后结果如下图所示:
-
计算precision和recall值
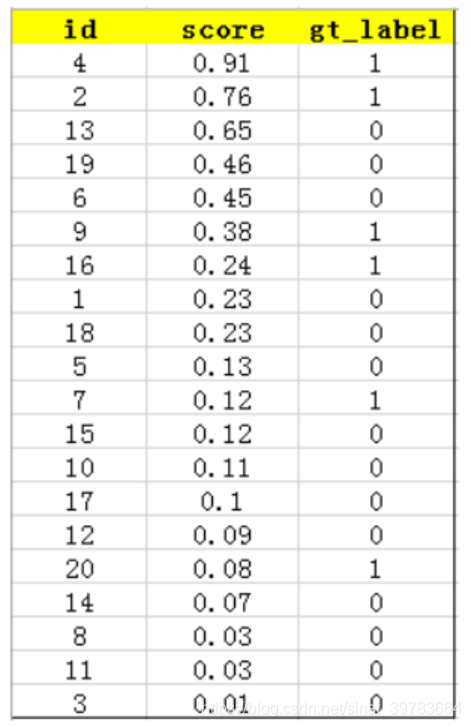
precision(准确率):你预测出的结果有多少是正确的。
recall(召回率):正确的结果有多少被你给出来了。
- 说明
用(True Positive+False Positive)来表示分类任务中我们取出来的结果,如在测试集上取出Top-5的结果为
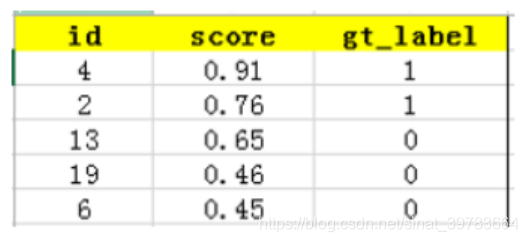
其中id为4和2的样本图片为True Positive,id为13、19、6的样本为False Positive。
这个例子中precision=2/5,recall=2/6。
- 计算AP
设总数为N的样本中总共有M个正样本,则从Top-1至Top-N可以有M个recall值,分别为(1/M,2/M,…,M/M),对于每个recall值r,可以从对应的(r’>=r)中计算出一个最大的precision,对这M个precision求平均得到AP,如下图所示:
在上图所示中,共有6个正例,因此共有6个recall值,分别为1/6、2/6、3/6、4/6、5/6、6/6,
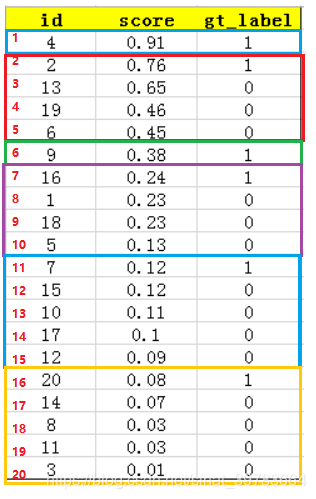

当recall=1/6时,r’为1/6、2/6、3/6、4/6、5/6、6/6,最大的precision=1;
当recall=2/6时,r’为2/6、3/6、4/6、5/6、6/6,最大的precision=2/2=1;
当recall=3/6时,r’为3/6、4/6、5/6、6/6,最大的precision=3/6;
当recall=4/6时,r’为4/6、5/6、6/6,最大的precision=4/7;
当recall=5/6时,r’为5/6、6/6,最大的precision=5/11;
当recall=6/6时,r’为6/6,最大的precision=6/16。
A
P
=
1
+
1
+
3
/
6
+
4
/
7
+
5
/
11
+
6
/
16
6
=
0.6501
AP=\frac{1+1+3/6+4/7+5/11+6/16}{6}=0.6501
AP=61+1+3/6+4/7+5/11+6/16=0.6501
此时AP表示训练出来的模型在当前类别上的好坏。
在一个实际的目标检测任务中,目标的数量不一定是5个,所以不能只通过top-5来来衡量一个模型的好坏,选定的id越多,recall就越高,precision整体上则会呈现出下降趋势,因为排在前面的概率高的,一般更有可能是真实的样本,而后面概率低的更有可能是负样本。
令N是所有id,如果从top-1到top-N都统计一遍,得到了对应的precision和recall,以recall为横坐标,precision为纵坐标,则得到了检测中使用的precision-recall曲线,虽然整体趋势和意义与分类任务中的precision-recall曲线相同,计算方法却有很大差别。
PASCAL VOC 2010年提出了一个更好的指标mAP,对于样本不均衡的类的计算更加有效。假设有N个id,其中有M个label,则取M个recall节点,从0到1按照1/M的等间距,对于每个recall值,计算出大于该recall值的最大precision,然后对这M个precision值取平均得到最后的AP值,mAP的计算方法不变。
AP衡量的是学出来的模型在一个类别上的好坏,mAP衡量的是学出的模型在所有类别上的好坏。
(2)mAP
mAP的对象是所有类的所有图片,衡量的是学出的模型在所有类别上的好坏。计算如下所示,其中C为类别数目 。
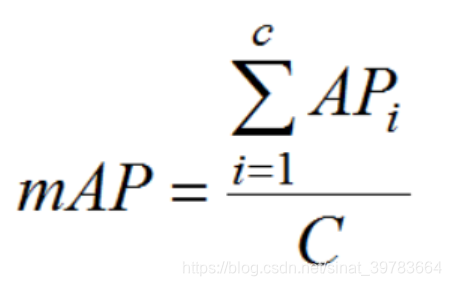
三.其他
1.FPS
检测速率Fps(frame per second)
1秒内识别的图像数(帧数)
2.参数量(parameters)
略
3.浮点运算量(FLOPS)
卷积的FLOPS比parameters大。