目录
在上一讲中,我们学习了 基于概率采样的路径规划算法——PRM算法,这一讲我们继续学习基于概率采样的路径规划算法——RRT、RRT*。
1. RRT算法背景
快速探索随机树(RRT)由Steven M. LaValle和James J. Kuffner Jr开发, 是对状态空间中的采样点进行碰撞检测,避免了对空间的建模,能够有效地解决高维空间和复杂约束的路径规划问题。它可以轻松处理障碍物和差分约束(非完整和动力学)的问题。
RRT可以被看作是一种为具有状态约束的非线性系统生成开环轨迹的技术。
人工势场法、模糊规则法、遗传算法、神经网络、模拟退火算法、蚁群优化算法等这些方法都需要在一个确定的空间内对障碍物进行建模,计算复杂度与机器人自由度呈指数关系,不适合解决多自由度机器人在复杂环境中的规划。
快速探索随机树(Rapidly exploring Random Tree )是一种通过随机构建空间填充树来有效搜索非凸,高维空间的算法。
1.1 RRT算法核心思想
核心思想:RRT 算法首先将起点初始化为随机树的根节点,然后在机器人的可达空间中随机生成采样点,从树的根节点逐步向采样点扩展节点,节点和节点之间的连线构成了整个随机树,当某个节点与目标点的距离小于设定的阈值时,即可认为找到可行路径。
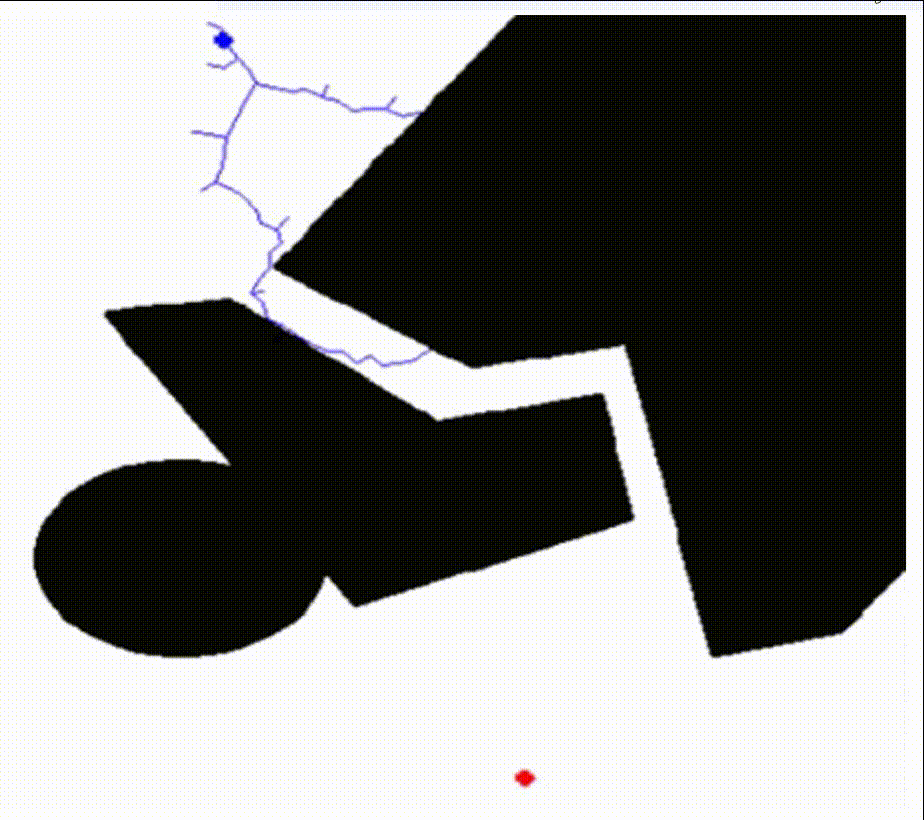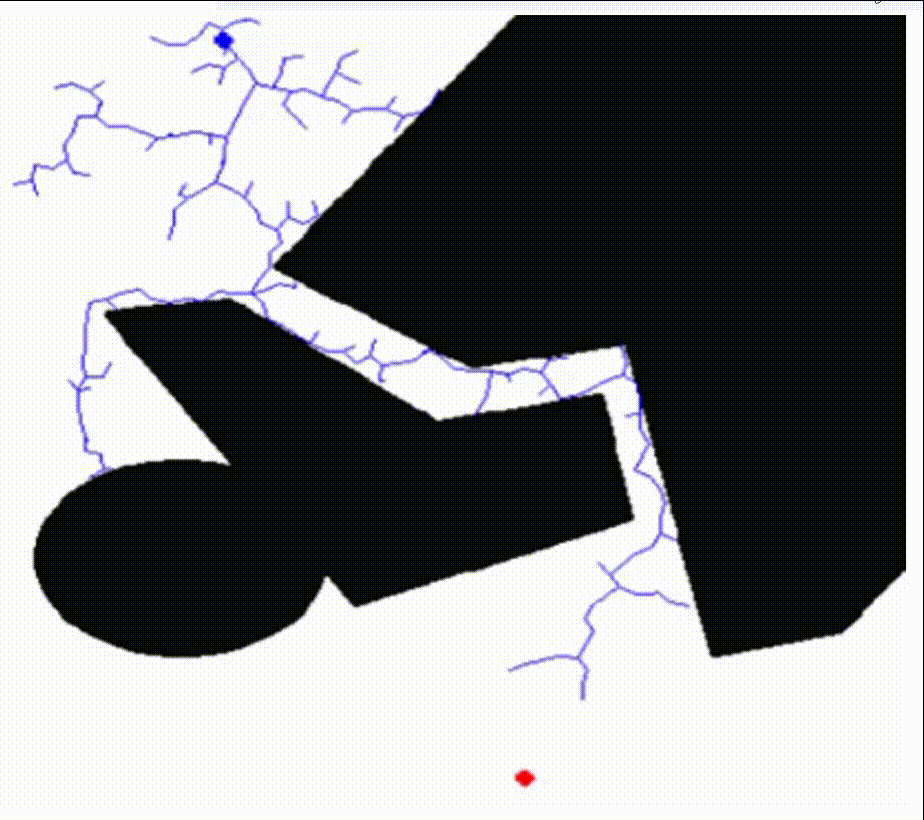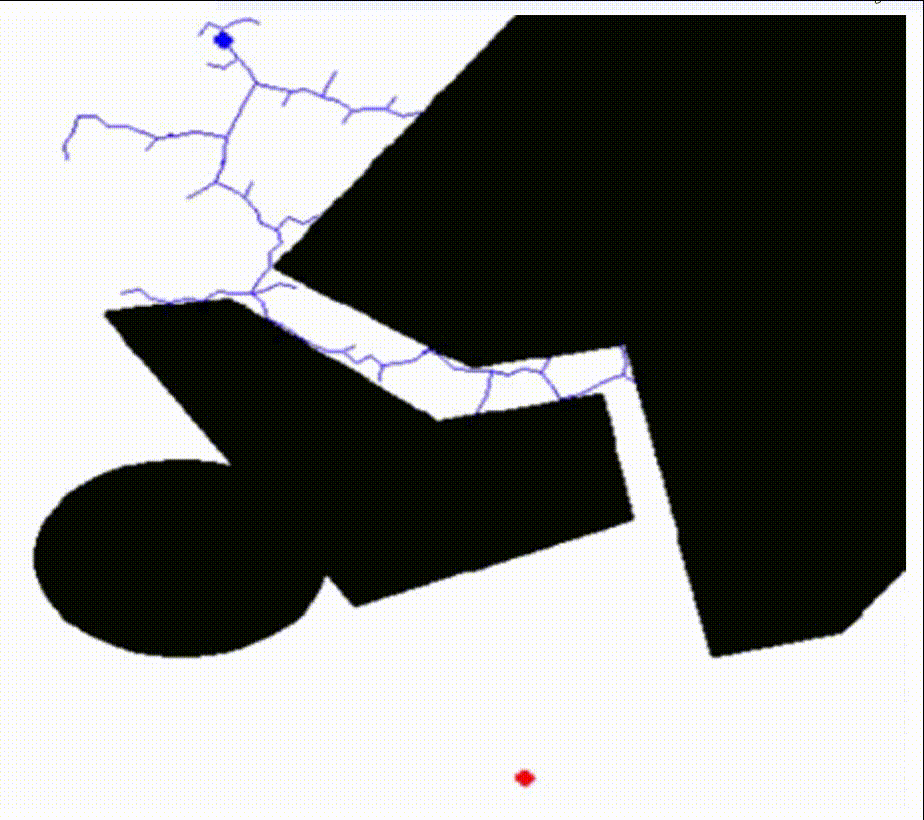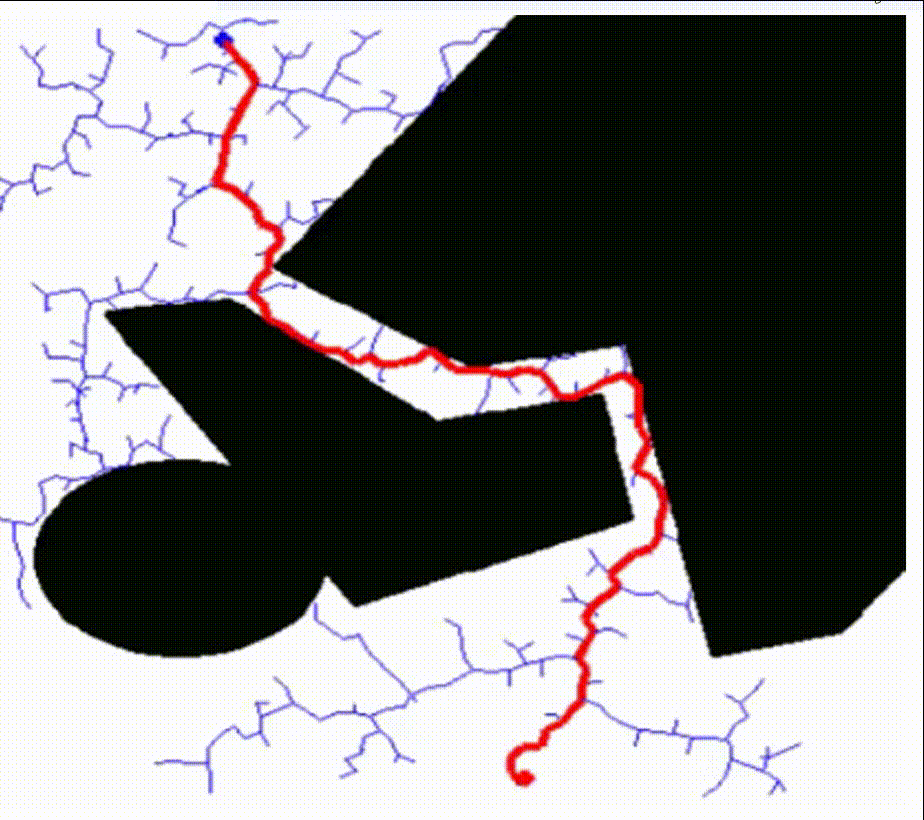
RRT算法的特点是能够快速有效地搜索高维空间,通过状态空间的随机采样点,把搜索导向空白区域,从而寻找到一条从起始点到目标点的规划路径,适合解决多自由度机器人在复杂环境下和动态环境中的路径规划。
RRT算法与PRM(Probabilistic Roadmaps)类似,该方法是概率完备且不最优的。
1.2 RRT算法优缺点
优点:
- 该算法通过尽可能少地探索环境,来实现有效的单一路径规划,对未知环境适应能力强。
- RRT 算法通过随机树向未观察的空间区域生长,并且不会回归到已经探索过的区域,这实现了对空间的快速探索。
- 搜索方法不是维持固定的栅格结构(与Astar算法不同),而是在运行中构建随机树,通过随机树内部的节点的连接找到路径。
缺点:
- 基于采样的路径规划方法需要对输入空间进行离散化,采样次数太少,则生成的路径将表现出较差的性能,采样次数太多则会增加整个规划过程的计算量,降低路径规划的实时性。
- 此外,RRT 算法生成的路径存在冗余的节点,会增加机器人实际运行中的路程.
2. 经典RRT算法
2.1 RRT算法流程
经典的 RRT 算法通过在机器人的运动空间中随机采样来构建路径树(T=(E,V)),其中点 V 是在无碰撞节点,E 为节点之间连接的边。
- 每个结点只能够创建一条边 E,连接其自身与树中最近的节点或父节点。
- 每棵树有一个父节点作为初始节点,之后通过随机生成子节点并连接到树上,以达到生长的目的。生成的树将会尽可能地遍历整个可达空间。
- 当树中保存的节点与目标位置的距离小于设定的阈值时,即可认为寻找到一条可行路径.
2.2 RRT伪代码

第 1-2 行初始化树并将起始位置插入树中。
第 4 行主要功能是在机器人可达空间中产生随机无碰撞样本点qrand。
第 5行功能是在树种的已有节点中检测,找到其中与随机样本qrand 最近的节点qnear。
第6行中最近节点qnear向随机样本点扩展一个步长,生成新节点qnew.
第 7行碰撞检测通过,则将新节点的坐标和边添加到树中,随机树的一次扩展过程完成。
在算法 1 描述的函数中,Δq 称为生长节点的预定步长。生长步长可以对树的扩张产生显著影响。
如果是步长很小,最终得到的随机搜索树会有很多短枝,则需要更多节点来探索可达空间并找到可行路径,整个算法搜索时间也会变长。
如果生长步长很大,那么树会具有长枝,但是扩展树将有可能频繁地遇到障碍物而节点更新失败,导致算法重新采样新的位置。
3. 基于目标概率采样
经典的快速搜索随机树算法在探索空间方面具有极大的优势,主要原因是RRT 算法能够快速探索可达空间并找到可行路径。
然而 RRT 算法存在一个无可避免的缺点:该算法得到的路径不是最优的,而且不会收敛到渐近最优解,虽然在概率上可能会接近最优解。
目前已经有很多方法来改进这个问题,其中比较重要的且会被大多数算法采用的是基于目标概率采样的 RRT 算法和 RRT*算法。
当 RRT 算法选择随机样本时,如果随机样本距离目标位置较远时,此时生成的节点将远离目标,增加了目标位置的可达选择。
但是随机选择样本具有两个无法避免的问题,一是生成的树可能已经找到非常靠近目标的节点,但由于这种样本选择的随机性而没有连接到目标;二是这增加了对节点生成程序的调用,向树中添加了更多不必要的分支。
为了提高 RRT 算法生成路径的效率,要求 RRT 算法的搜索过程不是完全随机的采样。
因此设置目的地的方向作为随机树探索的导向,可以加快算法运行的速度。
具体的做法是:通过目标概率采样的方式生成随机点。在生成随机点qrand 时,以一定的概率采用目标点作为随机点qrand ,即 qrand =qgoal。随机点qrand在扩展的过程中相当于确定了一个随机树生长的朝向,通过把目标点设为qrand,会导致随机树以一定的概率朝着目标方向扩展。这种方法具有随机性与一定的方向性。
但是为了保持 RRT 算法对空间的探索能力,目标朝向的概率通常不该过大(通常选用 0.05-0.3)。
这种基于目标概率采样的 RRT 算法一个的缺点是在目标周围存在多个障碍时,容易陷入局部搜索无法跳出。而且目标的概率值越大陷入局部搜索后跳出的难度就越大。
基于目标概率采样的方法在选择概率时要同时考虑随机树的扩展和算法效率
4. RRT*算法
RRT *算法于 2010 年首次推出,该算法可以显著改善机器人运动空间中发现的路径质量。
RRT *算法的运行方式与 RRT 非常相似,该算法通过在机器人可达空间的随机采样来构建树,并在新节点通过碰撞和非完整约束检测后将新节点连接到树上。
虽然 RRT *确实产生了更高质量的路径,但该算法的搜索时间更长。原因是算法对在生成新节点时进行了重新选择父节点和重新布线过程,这两种方式能够不断改进发现的路径,同时也增加了算法的计算量。
4.1 RRT与RRT*的区别
RRT 和 RRT *算法之间存在两个主要差异。
第一个区别在于将新节点添加到树时父节点选择的方法。
第二个区别是在新增加节点时进行重新布线以减少整体的路径成本。
这两个方法通过迭代的方式,随着时间的推移改善已有的路径,经过多次迭代后,RRT *算法将会收敛到渐近最优解。
4.2 RRT*算法详解
4.2.1 RRT*算法总体伪代码
算法 2 的第 1-2 行初始化随机树并将起始位置添加到树中。
算法 2 的第 5行,算法选择随机采样点的最近节点。
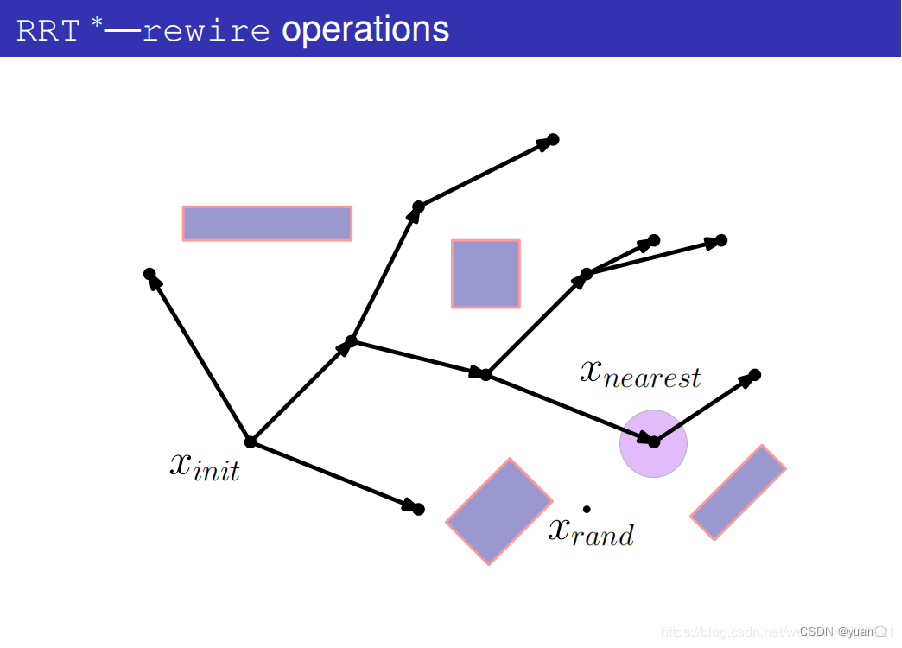
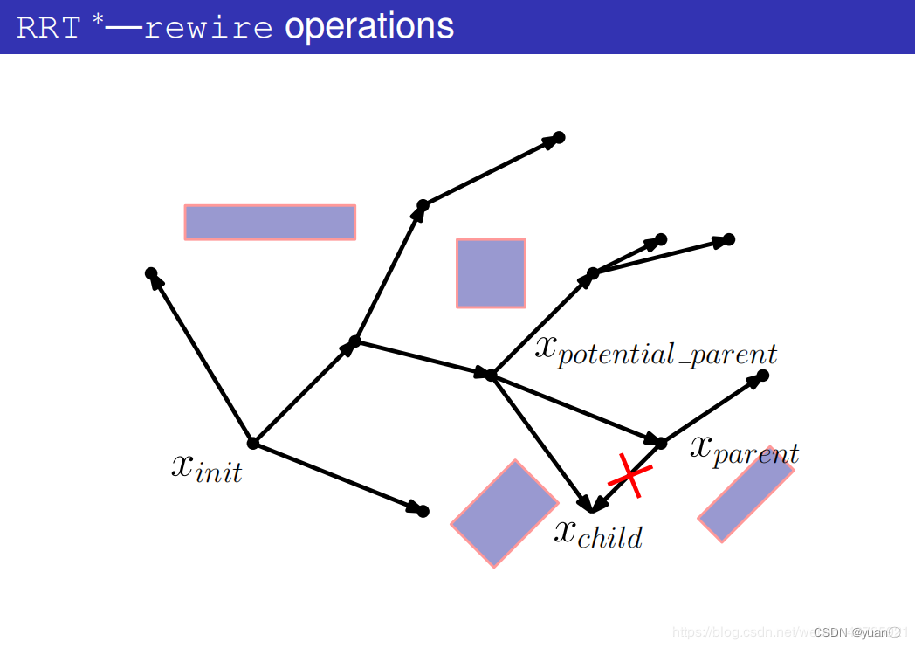
算法 2 的第 6 行是 RRT *和 RRT 之间的第一个主要区别,即重新选择父节点过程。函数 Choose Parent()的功能是从最近邻节点的邻域中选择最佳父节点,而不是直接选择最近邻节点作为随机样本的父节点。 如下图所示:RRT *算法并不是选择最近的节点作为新节点的父节点,而是在新节点周围的一定范围内,选择路径最佳的节点(代价最小)作为新节点的父节点。

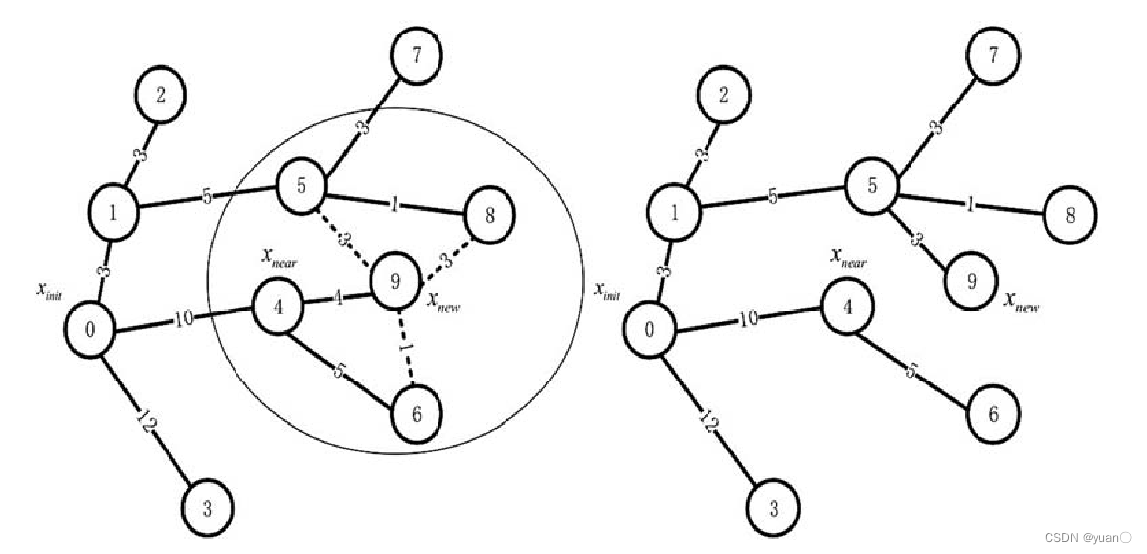
4.2.2 重新选择父节点

第3-12 行展示了重新选择父节点的过程。确定新节点qrand附近半径为 Δq 的邻域,考虑邻域中已经存在的多个节点作为最佳父节点的备选节点。
第1行先确定qrand的最近邻节点qnearest,将该节点暂时选为最佳父节点qmin。
第2行 根据qnearest确定从根节点到qrand的路径成本,记为当前最小成本cmin。
第4行,将qrand和qneart连线
第5行进行碰撞检测,如果无障碍,则计算根节点到qrand的路径成本。
第 6 行存储了新的路径成本。如果该成本低于当前最小成本,则将该附近节点选为最佳父节点qmin,并且将该成本记为最小成本cmin。

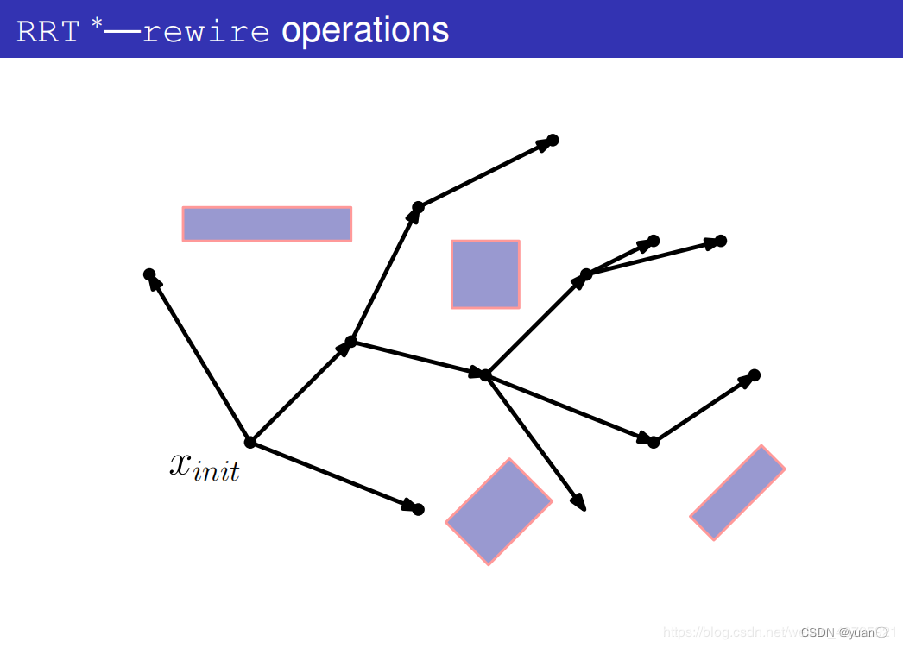
4.2.3 重新布线
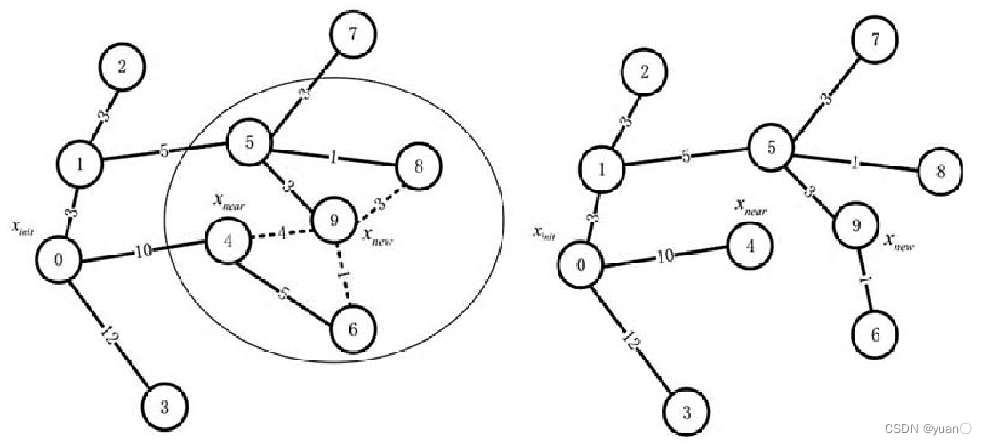
节点 9 是基于随机采样新生成的节点,其邻域内的节点为 4、6 、8 ,这三个节点的父节点分别是节点0 、4、5 。
考虑新节点邻域内的节点,将邻域内节点的父节点变为新生成的节点 9,如果这种更改能够降低当前的路径成本,则进行更改,若路径成本增加或不变,则保持原来的随机树的结构。
将节点 6 的父节点改为新节点后路径成本降低,因此进行重新布线,更改了随机树的结构。

如果此路径上没有障碍物以及路径的总成本比目前的路径成本低,则将新节点qrand选为邻域内节点的父节点。然后,将树重新布线,以删除qnear 与之前父节点的连线,并添加qnear 与新节点qrand之间的连线。
经过 Rewire 函数的重新布线,在随机树扩展一个新节点时改变树的结构,尽可能的优化已知节点的路径成本。
从随机树的整体结构来看,最终采用的路径可能不包含经过优化的节点,对每个节点进行优化而且增加了算法的计算量降低了路径生成的效率。
但在每一个节点生成时都尽可能的降低路径成本,这为最终路径成本的减小增加了可能性。
RRT*算法的关键在于上述的两个函数:Choose Parent 和 Rewire 函数。
这两个函数相互联系,重选父节点保证新节点路径成本相对最小,重布线保证增加节点后随机树的结构合理,减少了路径成本。
与 RRT 算法相比,函数 Choose Parent 和Rewire 更改了搜索树的结构。RRT 生成的树具有向各个方向移动的分支,而由 RRT *算法生成的随机树则很少有沿父节点向后移动的分支。
通过 Rewire 函数改变树的内部结构,以确保内部从根节点到末端节点的路径渐近最优。
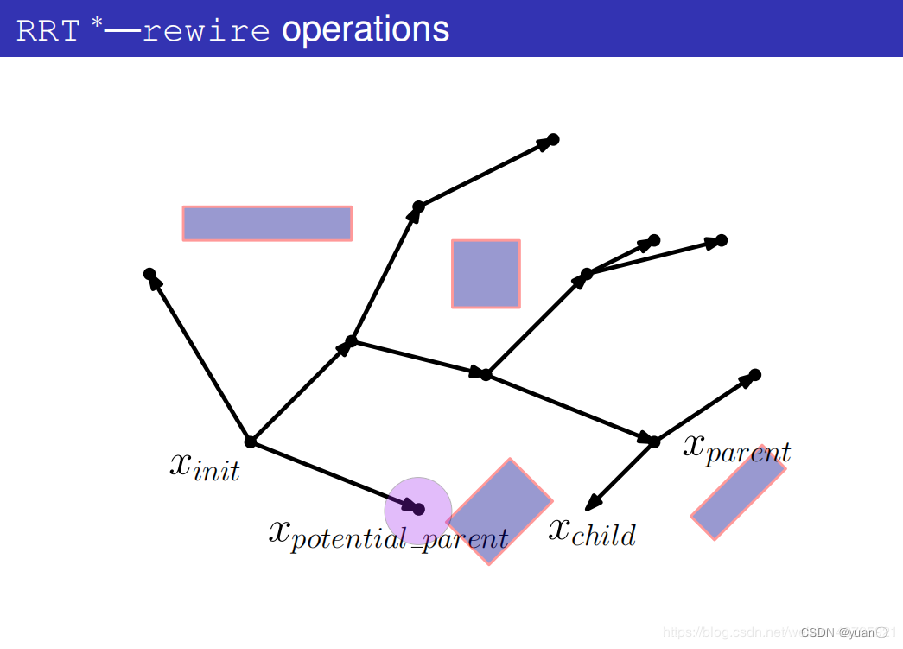
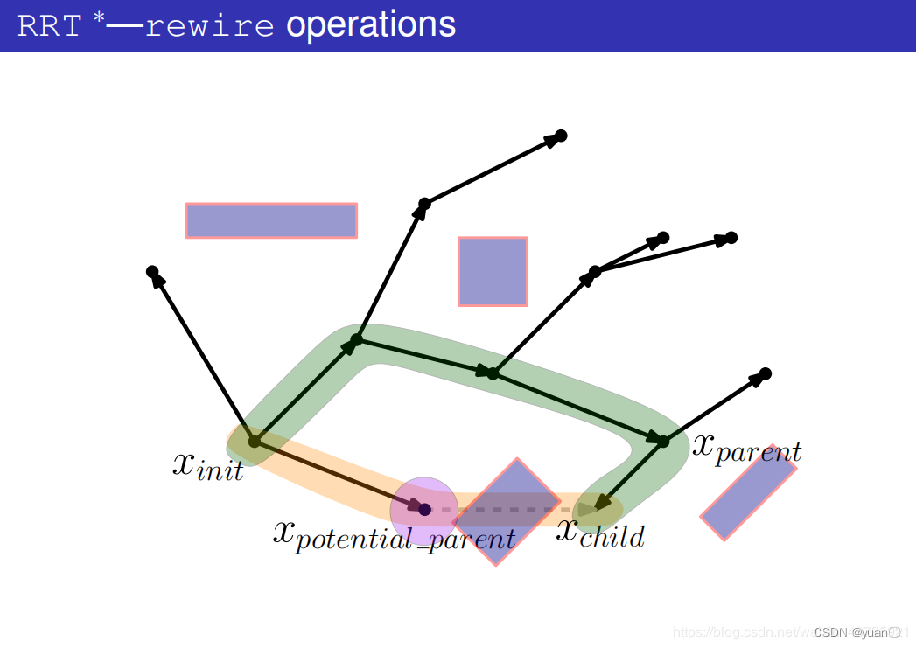
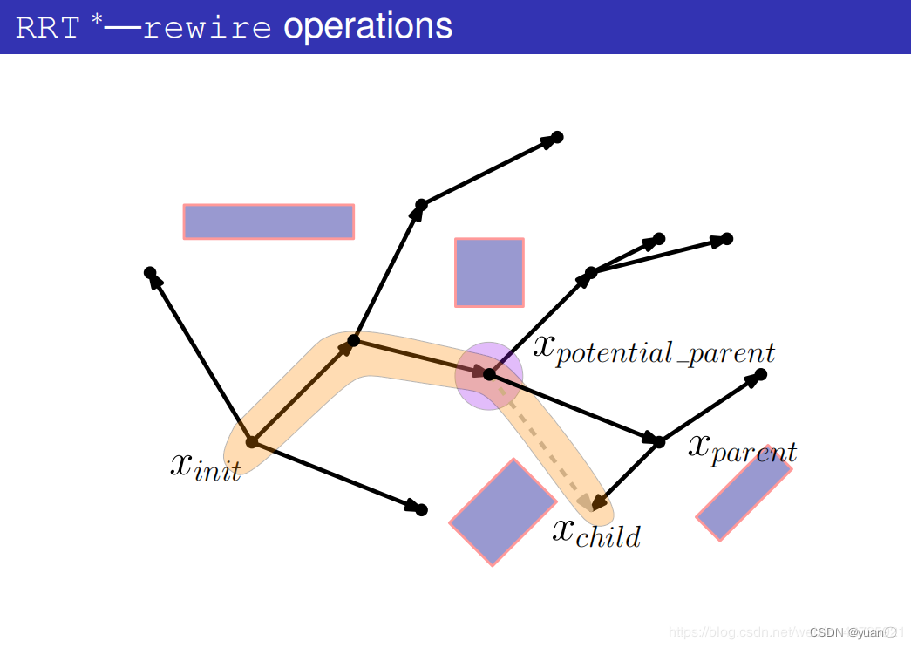
4.2.4 RRT*算法Choose Parent过程详解
-
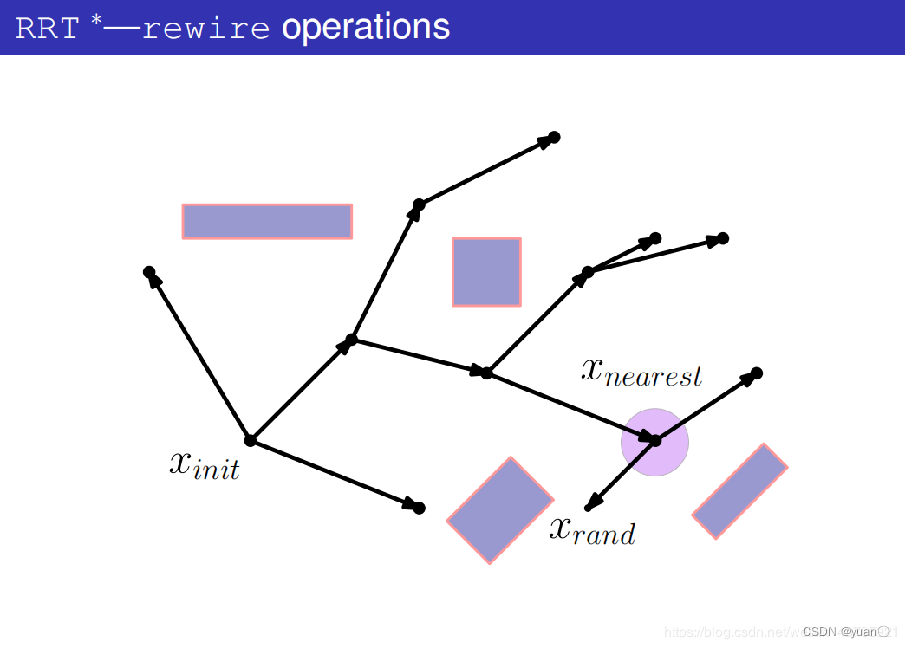
产生一个随机点xrand
-
在树上找到与xrand最近的节点xnearest
-
连接xrand与xnearest
-
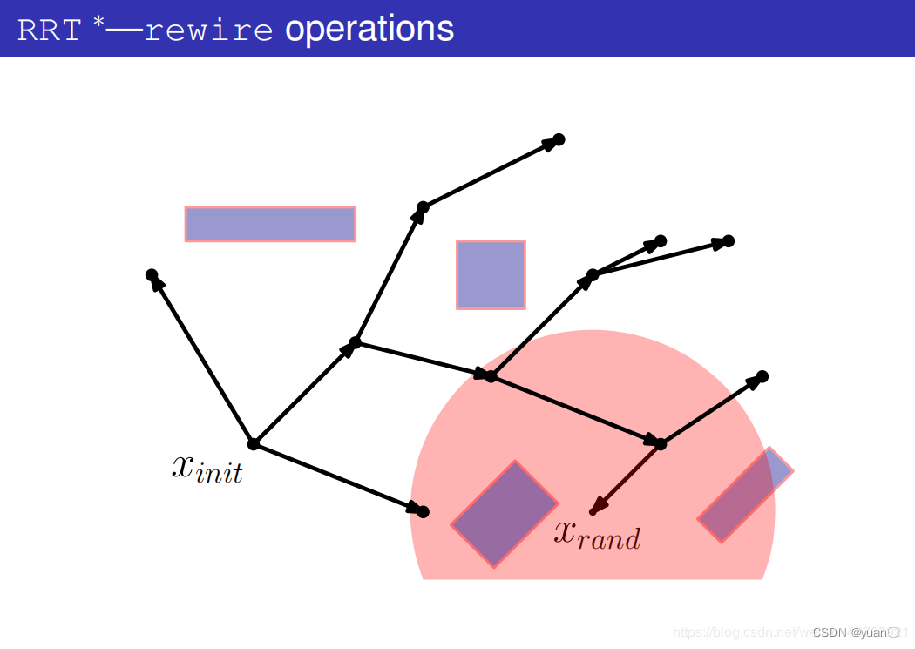
以xrand为中心,ri为半径,在树上搜索节点。
-
找出潜在的父节点集合Xpotential_parent,其目的是要更新xrand,看看有没有比它更好的父节点。
-
从某一个潜在的父节点xpotential_parent开始考虑
-
计算出xparent作为父节点时的代价。
-
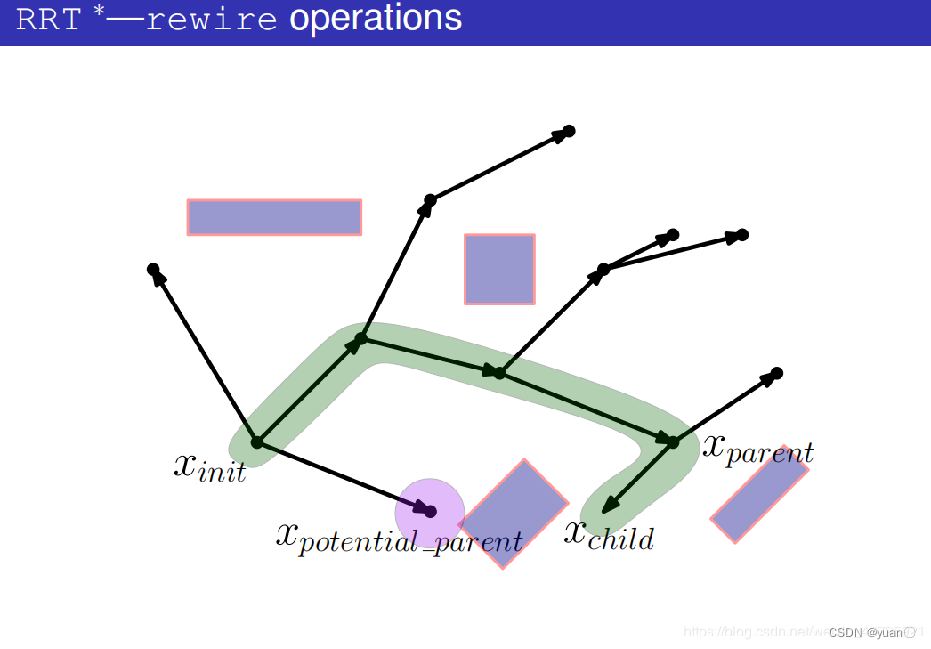
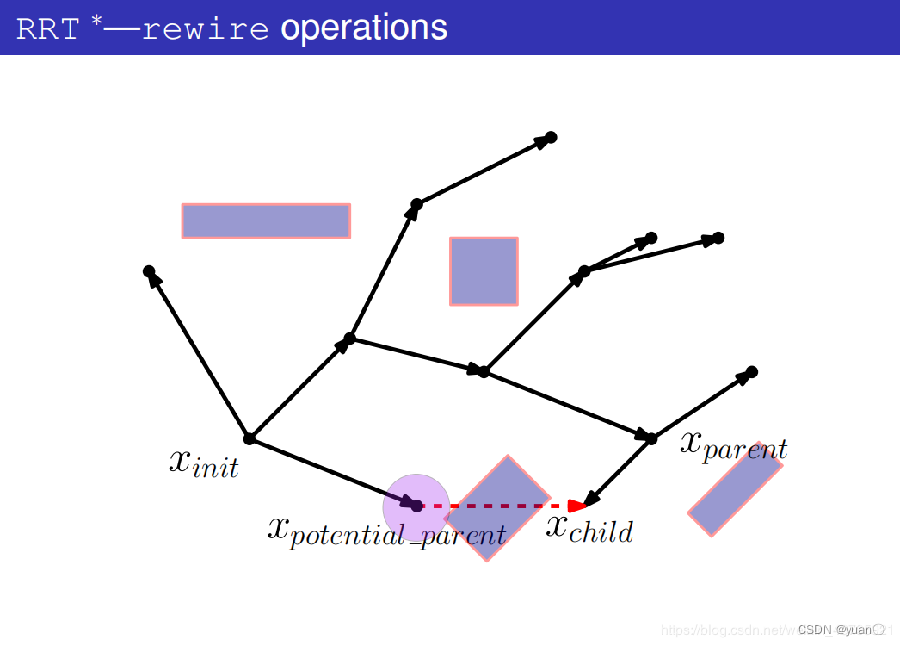
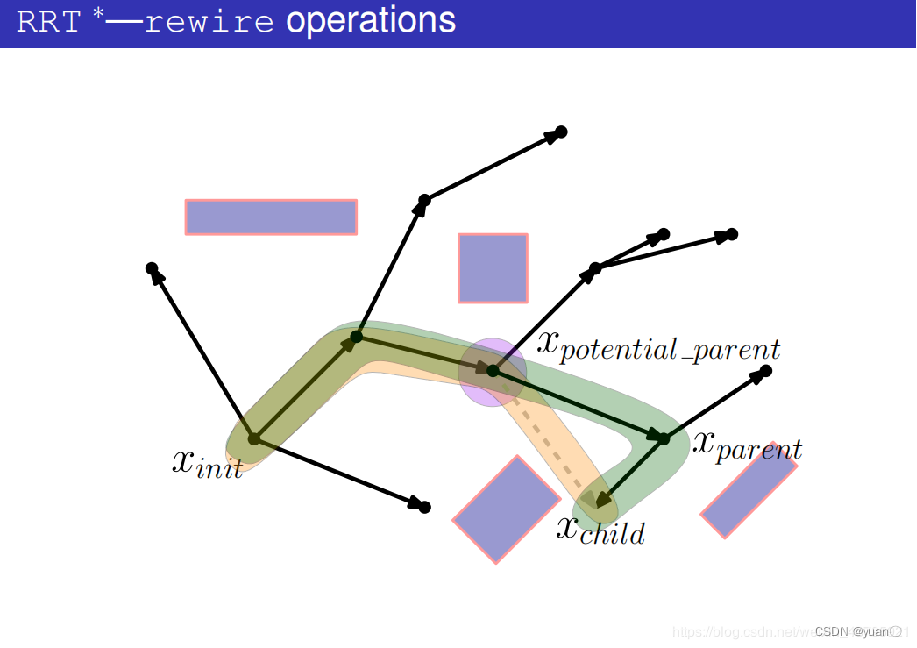
先不进行碰撞检测,而是将xpotential_parent与xchild(也就是xrand)连接起来
-
计算出这条路径的代价。
-
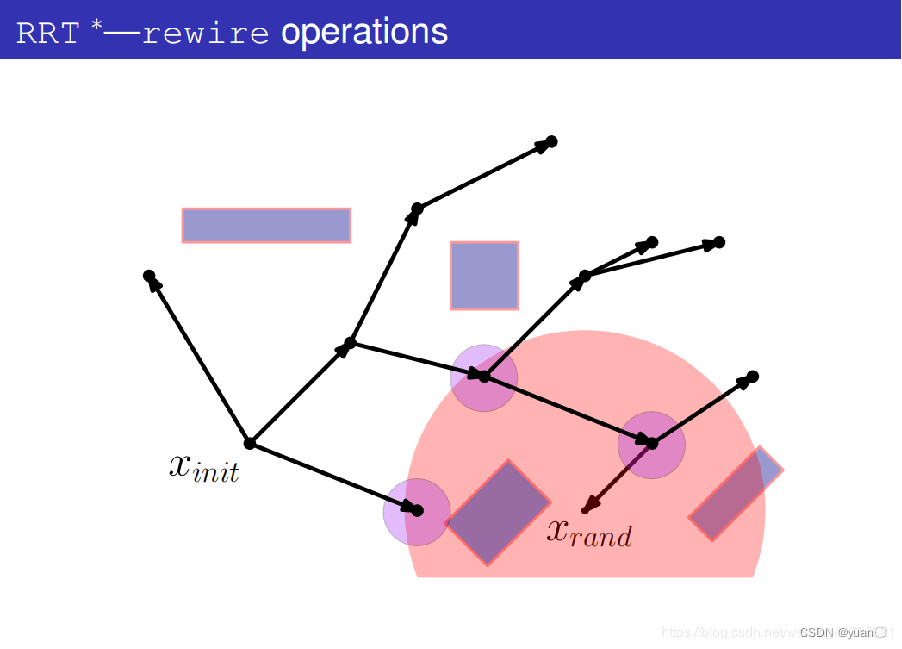
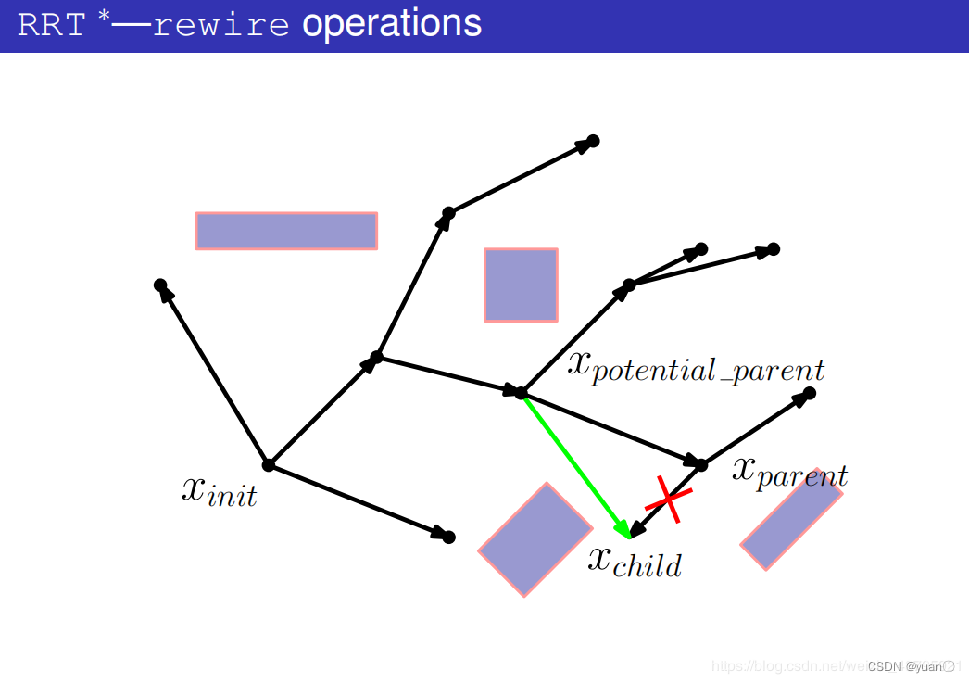
将新的这条路径的代价与原路径的代价作比较,如果新的这条路径的代价更小则进行碰撞检测,如果新的这条路径代价更大则换为下一个潜在的父节点。
-
碰撞检测失败,该潜在父节点不作为新的父节点。
-
开始考虑下一个潜在父节点。
-
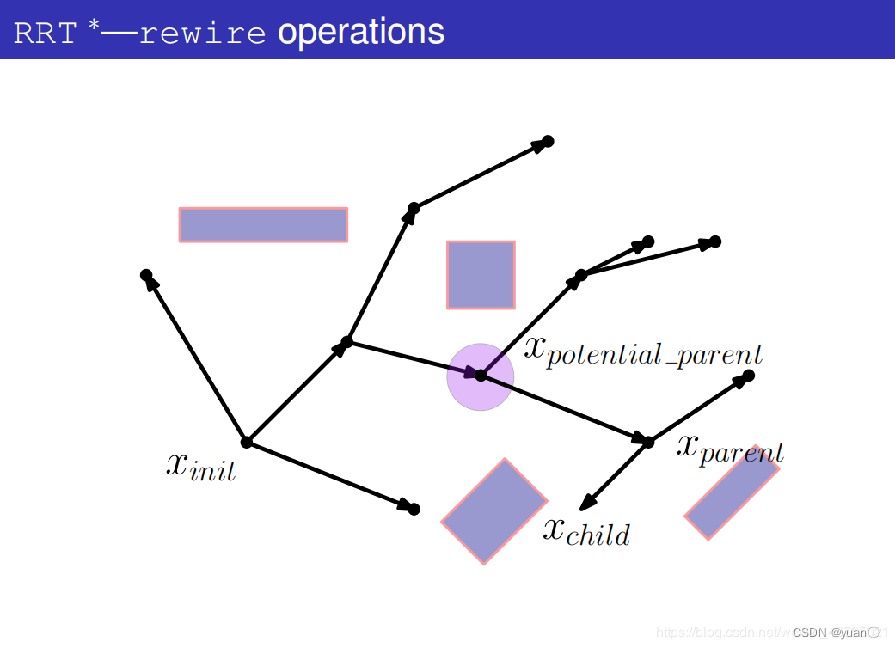
将潜在父节点和xchild连接起来
-
计算出这条路径的代价。
-
将新的这条路径的代价与原路径的代价作比较,如果新的这条路径的代价更小则进行碰撞检测,如果新的这条路径代价更大则换为下一个潜在的父节点。
-
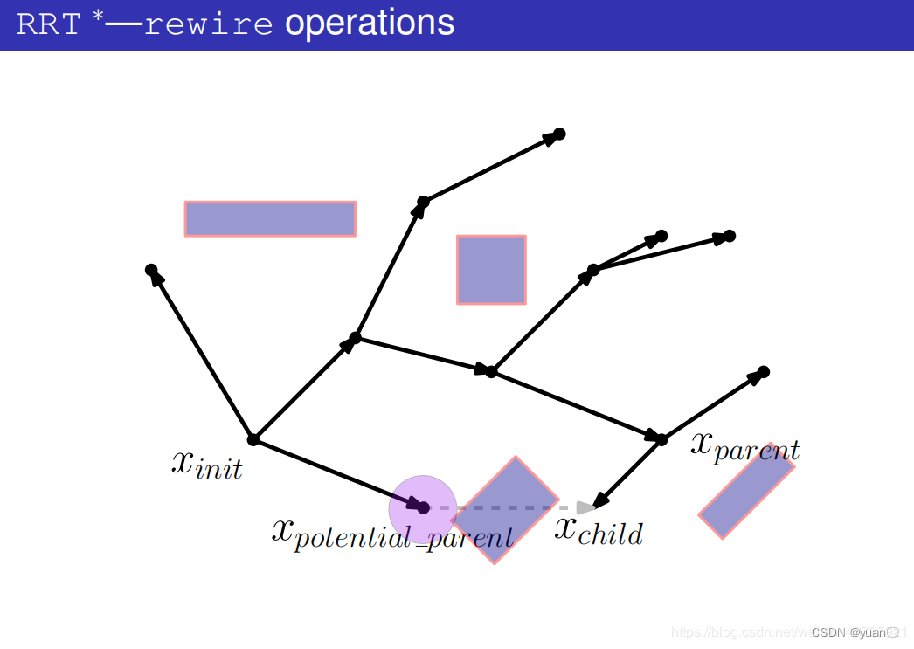
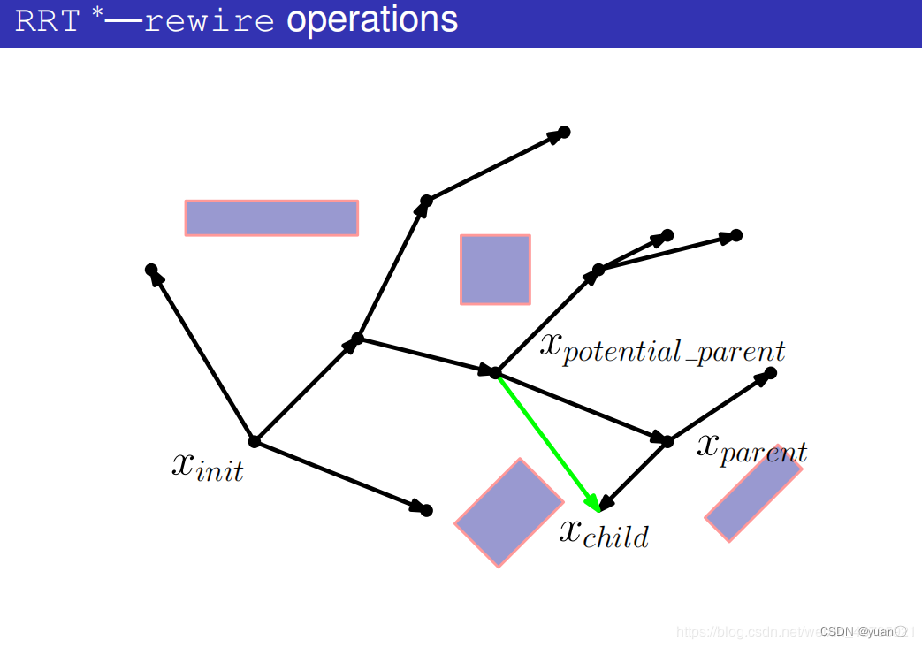
碰撞检测通过。
-
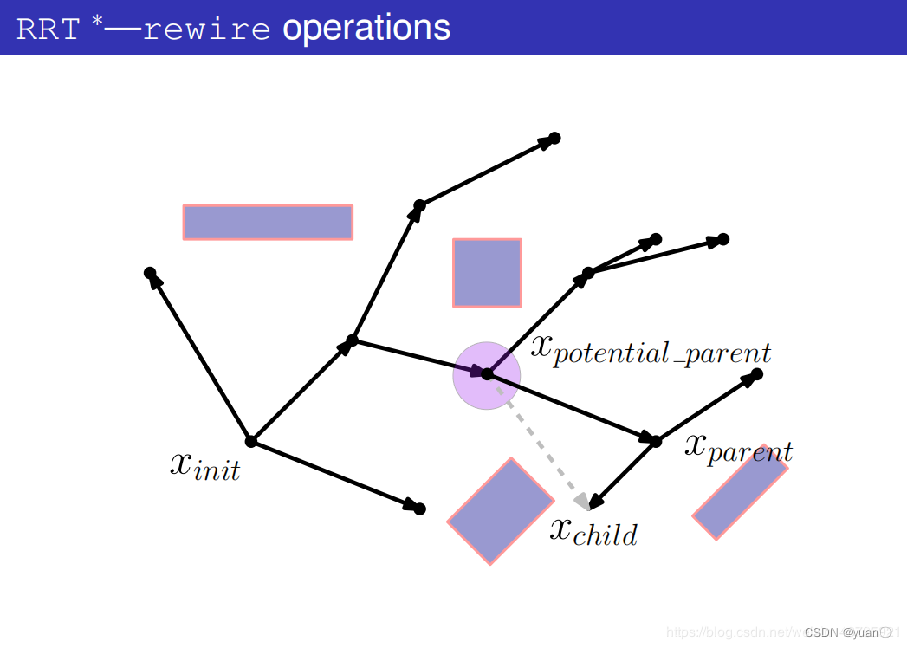
在树中将之前的边删掉
-
在树中将新的边添加进去,将xpotential_parent作为xparent。
-
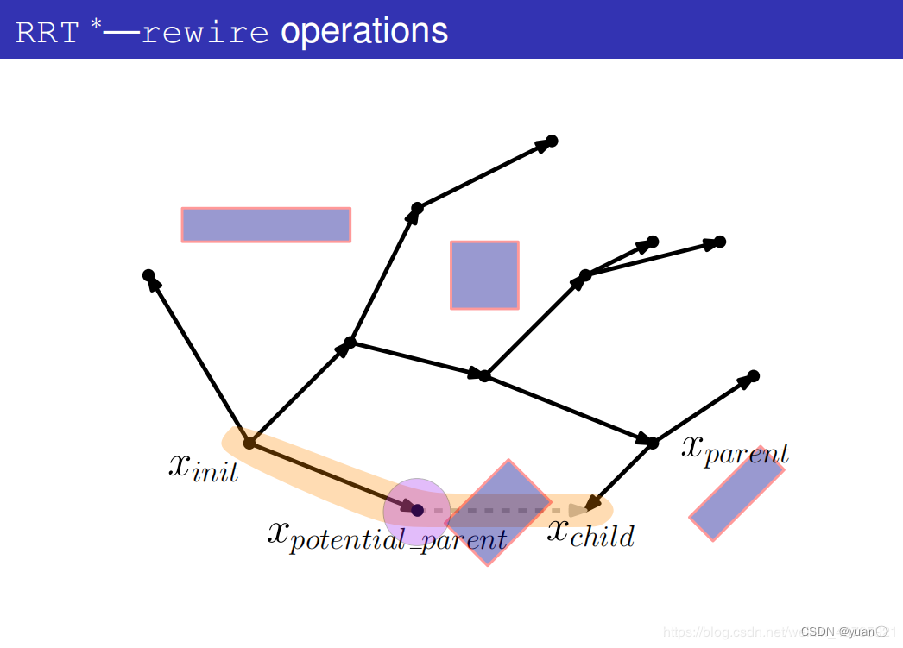
遍历所有的潜在父节点,得到更新后的树。
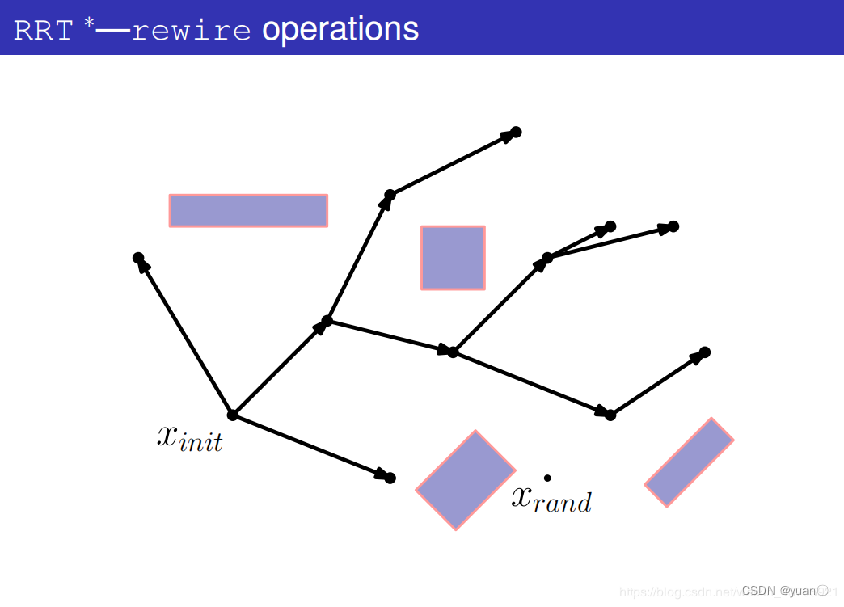
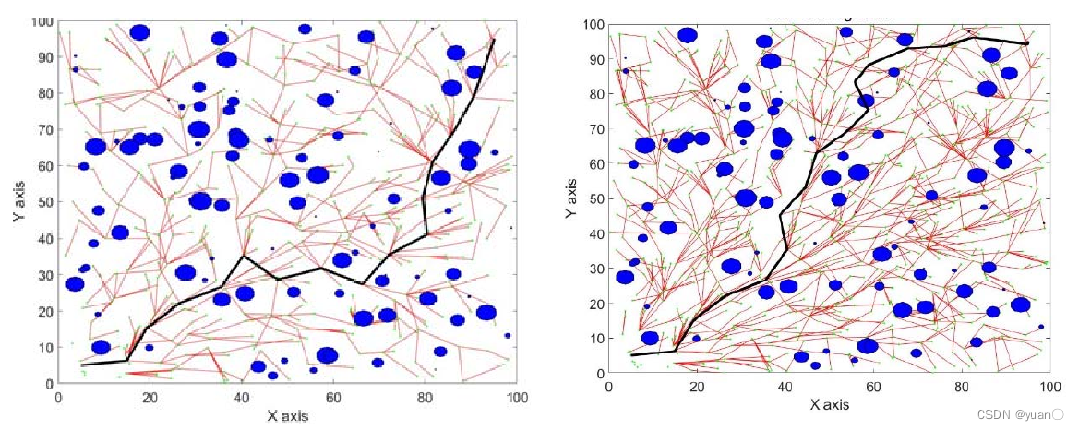
4.3 迭代次数对RRT*的影响
RRT*算法的重选父节点和重布线过程保证了生成的路径是渐近最优的,因为随着迭代次数的增加,整体的路径成本总是尽可能的降低。但是迭代次数的增加同时增加了算法的计算量。
随着迭代次数的增加,得出的路径是渐进优化的,因此,RRT*算法不可能在有限的时间中得出最优路径。
RRT*算法的收敛时间是一个比较突出的研究问题。但不可否认的是,RRT*算法计算出的路径的代价相比RRT来说减小了不少。
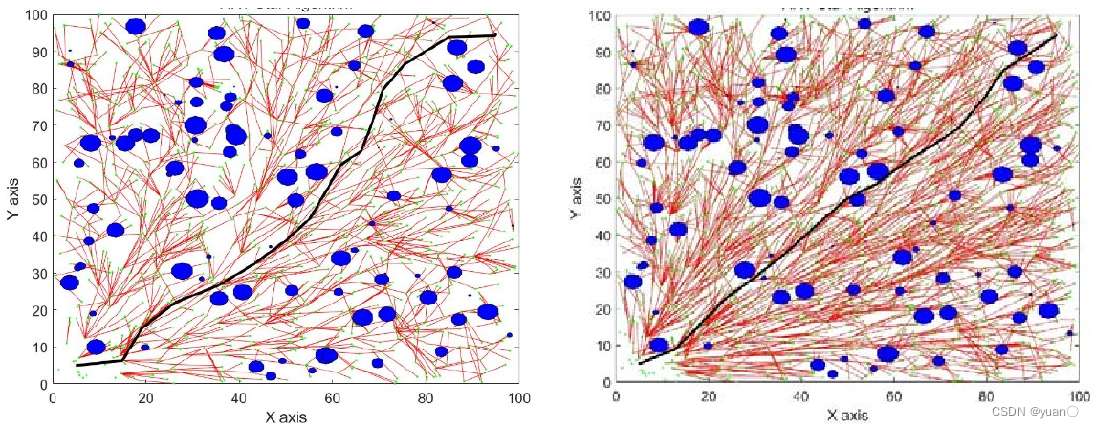
4.4 路径修剪
虽然 RRT*算法通过迭代的方式达到了渐近最优,但是由于计算机算力和计算时间的限制,迭代次数不能设置过大,得到的路径仍然会存在冗余节点。
在随机树的生长过程中,没有简单的方法来改变控制输入以移除冗余节点。
在随机树算法找到可行路径后,可以对节点进行修剪,选择和移除冗余节点,以降低最终生成路径的成本。
4.4.1 路径修剪的一般流程
上一讲中的案例也用到了路径修剪
路径修剪的一般方法:
- 从目标位置开始,向路径中倒数第二个节点(不包括目标节点开始计数)连线并进行碰撞检测。
- 如果目标位置与该节点的连线之间没有障碍,则从路径中删除最后一个节点。
- 如果目标位置与该节点的连线之间存在障碍,则从该节点开始,向该节点前面第二个节点(同样不包括该节点进行计数)连线并进行碰撞检测。
- 以此类推,直至连接到起始位置,算法结束。
然而对于实际情况来说,机器人存在最大转弯半径,因此需要考虑最大转弯半径对路径修剪的约束。
将移动机器人的前轮转角记作γ,最大转角记作γmax,一般机器人最大转角在 30°~40°之间,这里取 γmax =35。为了保证机器人能够采用 RRT 算法规划出的路径,要求机器人的最小转弯半径小于所得路径的曲率半径。
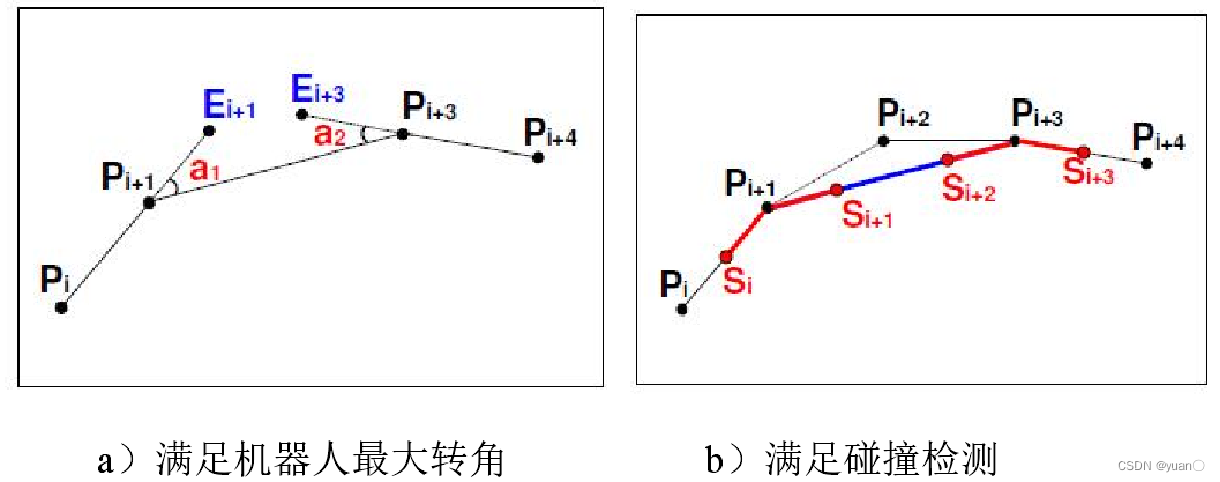
因此在进行路径修剪时,从路径的一端开始,逐一计算两相邻边之间的夹角,在同时满足碰撞要求和角度要求(碰撞检测和非完整约束检测)时,才能删除该冗余节点。
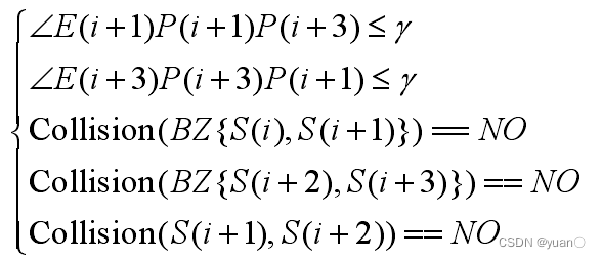
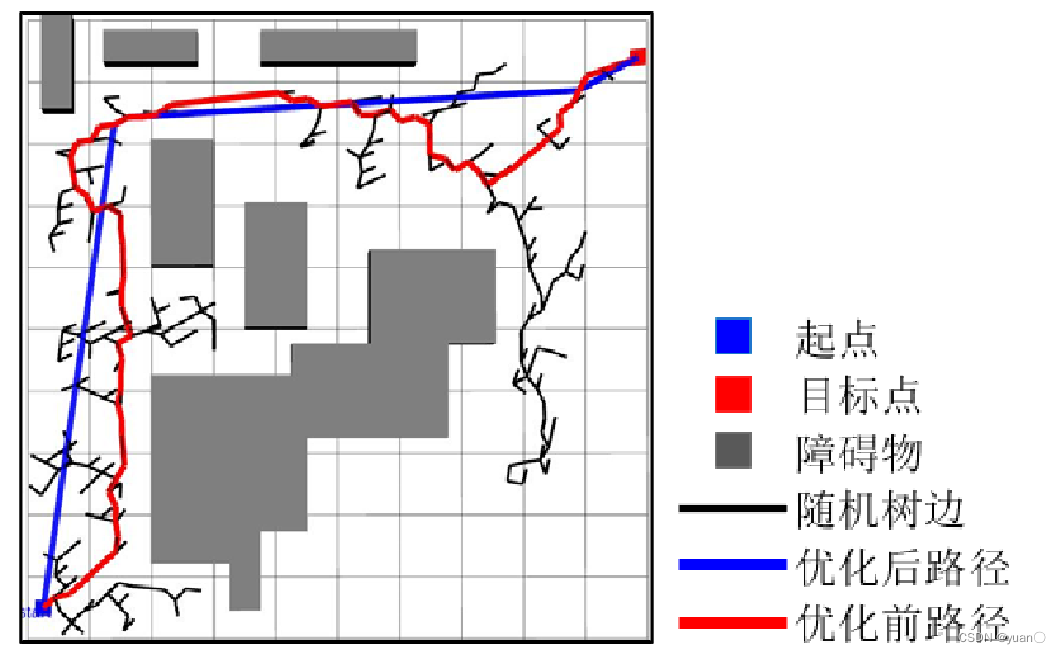
下图展示了采用路径修剪算法前后的路径对比,其中红色线条为初始生成的路径,蓝色线条为修剪冗余节点后的路径。可以看出在采用路径修剪算法后,路径中的节点下降为 4 个,大大减少了路径的整体长度。
5. 其他RRT算法
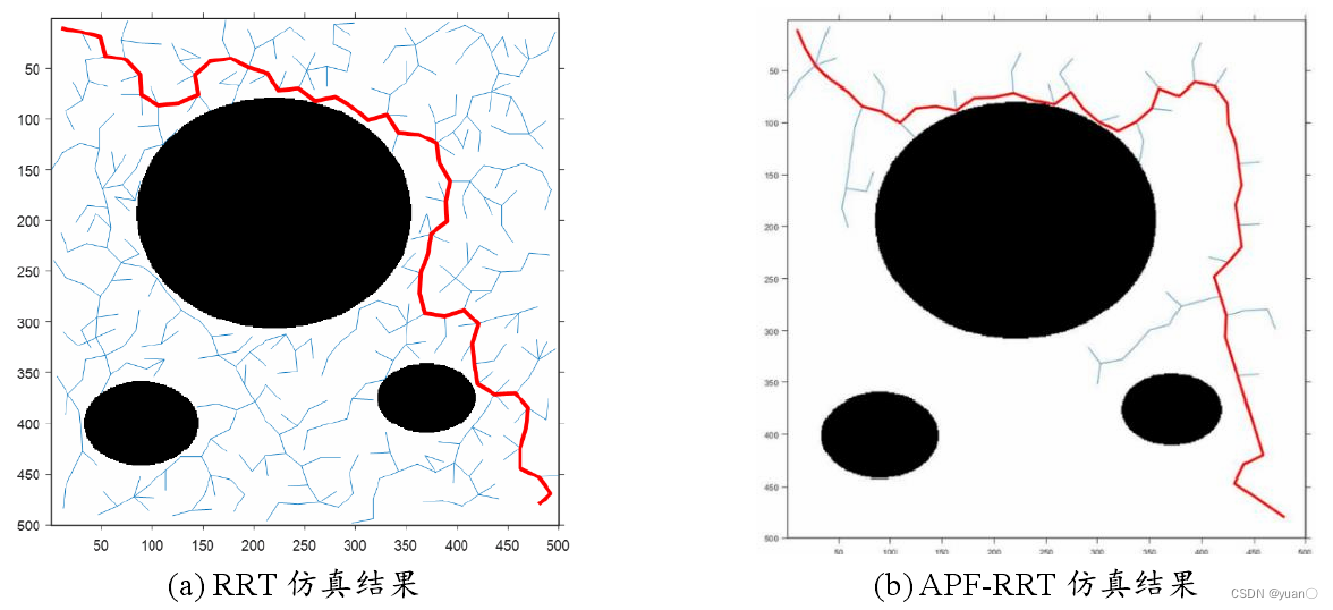
5.1 APF-RRT
人工势场法与RRT结合:
在势场法中,势场函数携带了障碍物和目标的信息。如果能把障碍物和目标的信息告诉 RRT,RRT在探索空间时将会有倾向地沿着势场的方向前进。
此外,RRT 出色的探索能力刚好可以弥补势场法容易陷入局部极小值的缺点。
将人工势场法中的目标引力函数加入到 RRT 算法中,将目标点的位置作为启发信息,引导随机树朝着目标方向生长,提高算法的效率。
APF-RRT在每个节点都引入目标引力函数g(n),生成新节点xnew:
f
(
n
)
=
h
(
n
)
+
g
(
n
)
f(n) = h(n) + g(n)
f(n)=h(n)+g(n)
f(n)—随机树的扩展指导函数;
h(n)—随机采样所带来的生长函数;
g(n)—目标引力函数。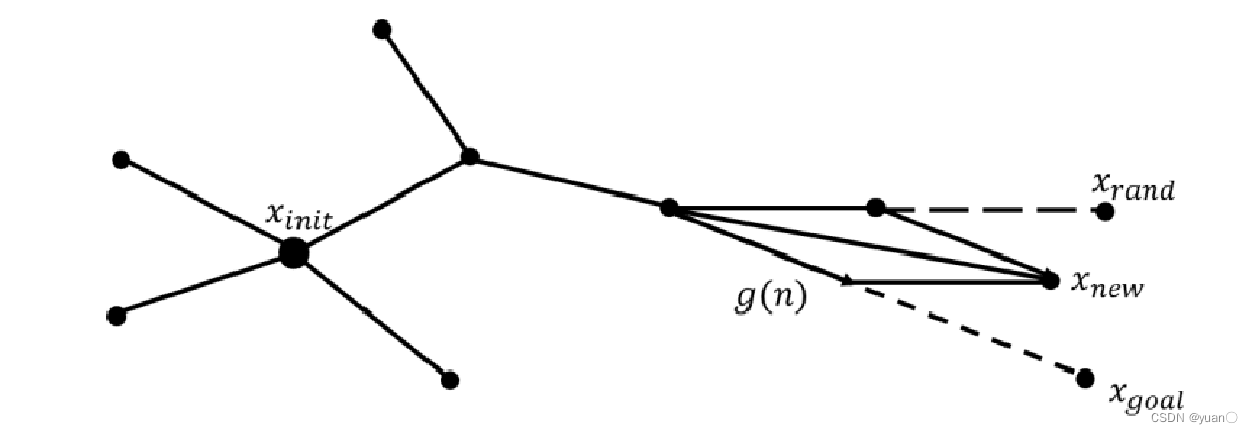
由于随机分量h(n)的存在,APF-RRT 算法仍然具备概率完备性。
目标引力函数为:
g
(
n
)
=
k
p
(
x
g
o
a
l
−
x
n
e
a
r
)
∥
x
g
o
a
l
−
x
n
e
a
r
∥
g(n) = {k_p}\frac{{({x_{goal}} - {x_{near}})}}{{\left\| {{x_{goal}} - {x_{near}}} \right\|}}
g(n)=kp∥xgoal−xnear∥(xgoal−xnear)
新节点的生成函数(取的是在xgoal和xnear共同作用下的方向向量):
x
n
e
w
=
x
n
e
a
r
+
ρ
(
(
x
r
a
n
d
−
x
n
e
a
r
)
∥
x
r
a
n
d
−
x
n
e
a
r
∥
+
k
p
(
x
g
o
a
l
−
x
n
e
a
r
)
∥
x
g
o
a
l
−
x
n
e
a
r
∥
)
{x_{new}} = {x_{near}} + \rho \left( {\frac{{({x_{rand}} - {x_{near}})}}{{\left\| {{x_{rand}} - {x_{near}}} \right\|}} + {k_p}\frac{{({x_{goal}} - {x_{near}})}}{{\left\| {{x_{goal}} - {x_{near}}} \right\|}}} \right)
xnew=xnear+ρ(∥xrand−xnear∥(xrand−xnear)+kp∥xgoal−xnear∥(xgoal−xnear))
5.2 APFG-RRT
5.2.1 算法原理
Goal-bias RRT 加入了目标点信息,使 RRT 的搜索更有目的性,从而提高搜索效率。
但是它没有考虑到障碍物信息,而障碍物信息在大多场景都能够获取。
为了加强算法对周围环境的感知,用障碍物信息进一步引导搜索,APFG-RRT 将人工势场融入到 RRT 中,根据目标点和周围障碍物信息构建人工势场,引导 RRT 进行搜索,使扩展随机树能够更有效地避开障碍物,从而快速搜索到到达目标的安全路径。
在 RRT 中,每次节点生长的增量仅由随机采样点xrand相对xnearest的方向和步长 ε 决定,而在 APFG-RRT 中,生长的增量还由机器人在xnearest处受到的引力和斥力决定。
与大多数 RRT 等步长的扩展方式不同,APFG-RRT 由随机分量和势场分量共同决定生长的距离。
当节点离障碍物较近时,势场分量的方向主要由斥力决定,使得向障碍物区域的生长步长较小,有利于随机树通过狭窄区域;
而当节点远离障碍物时,势场分量的方向主要由引力决定,使得向目标区域的生长步长较大,有利于快速接近目标。
假如将 Goal-bias RRT 和 APFG-RRT 中选取目标点作为采样点的概率都设置为 100%,则 Goal-bias RRT 和 APFG-RRT 在简单场景中如下图所示。
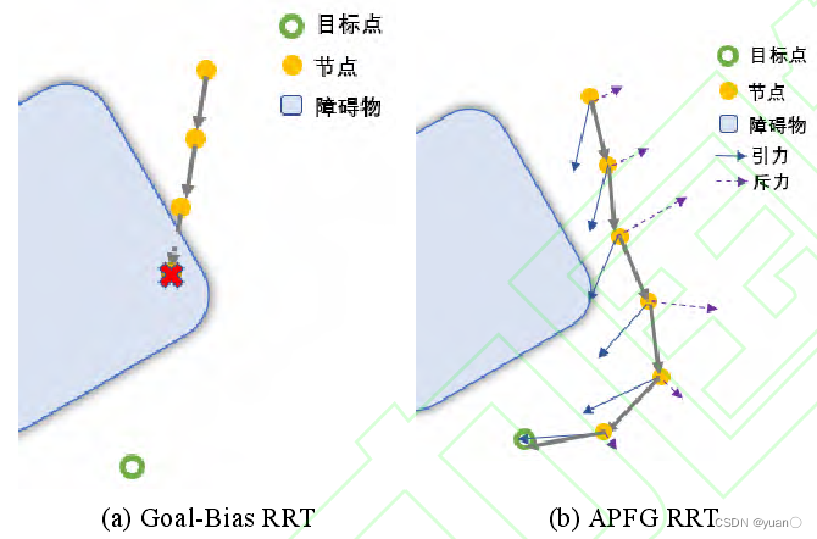
Goal-bias RRT 直接向目标生长,很容易在障碍物表面陷入局部极小值,需要依靠概率为100%的随机采样跳出局部极小值。而融合了人工势场的 APFG-RRT 由于加入了斥力机制,拥有了一定的绕开障碍物的能力。
Goal-bias RRT 概率选取目标点作为采样点的策略不仅可以引导随机树向目标生长,还具有优先生长一条分支的特性,这有利于快速规划出一条路径。
但是,Goal-bias RRT 选取目标点作为采样点的概率 P 是固定的,当随机树陷入局部极小值时,选取目标点作为采样点的扩展一般是无效的,这会浪费大量的计算资源。
为此,可以采用概率自适应的采样方法:
当选取目标点作为采样点的扩展无效时,可认为随机树陷入局部极小值,将 P 设置为 0,使算法专注于通过随机生长跳出局部极小值;
而随着随机生长的次数增加,随机树跳出局部极小值的可能性越来越大,所以相应地 P 也随着随机生长次数的增加而增加。
5.2.2 算法伪代码
首先在机器人的初始位置建立随机树的根节点,将选择目标点作为采样点的概率 P 设为Pmax,当随机数小于 P 时,选取目标点作为采样点xrand,而当随机数大于 P 时,在机器人构型空间中随机采样。
然后选取随机树上离xrand最近的节点xnearest 作为待生长节点,计算出障碍物上离xnearest最近的点Onearest ,计算出xnew,判断xnew是否与障碍物碰撞,若碰撞且采样点为xgoal,则认为随机树陷入局部极小值;若无碰撞则xnew作为新节点添加到随机树中,并且如果采样点是xgoal,则认为随机树没有陷入局部极小值或者已经跳出局部极小值,将 P 重新设为Pmax 。
接着若随机树处于陷入局部极小值状态,则更新 P 。
不断重复上述步骤,直到随机树生长到目标点邻域或者迭代次数超过设定的最大值。

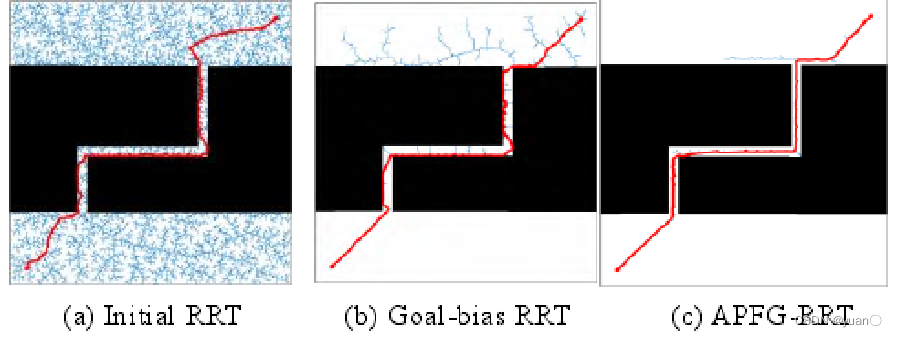
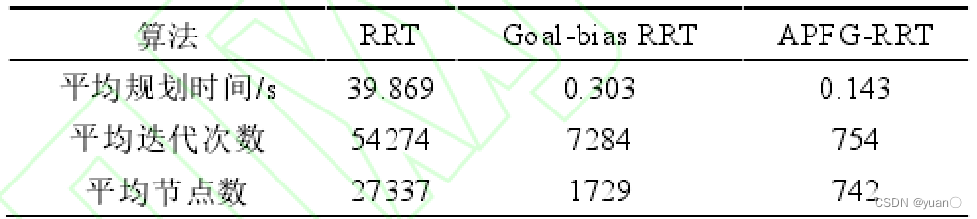
5.2.3 RRT、Goal-bias RRT和APFG-RRT的比较
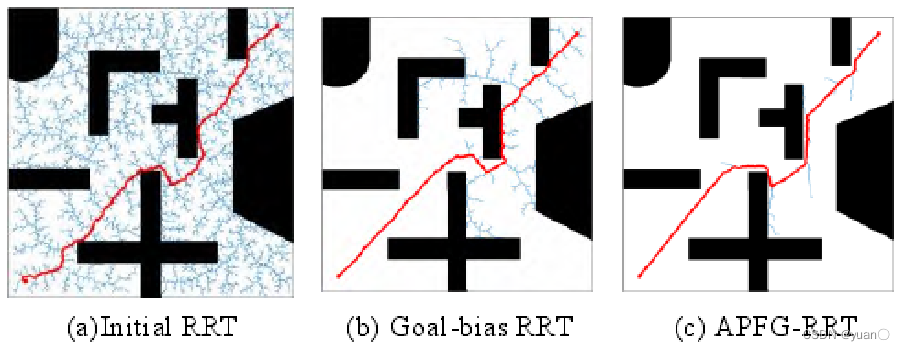
为了测试 APFG-RRT 的收敛速度,与初始的 RRT 和 Goal-bias RRT进行比较。三种算法中相应的参数保持相同。考虑到 RRT 自身的随机性,在一般环境和狭窄环境的地图上重复进行 100次的路径规划,取平均值作为测试结果。 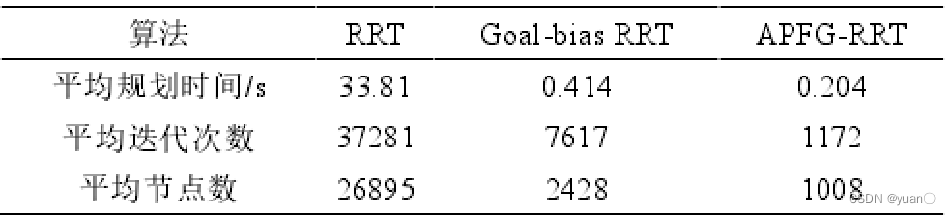
在贴近通道表面时随机树的生长方向受到限制,支持有效生长的采样空间较小;
而 APFG-RRT 因狭窄通道中间的势能最小,容易使随机树沿着通道中间生长。
5.3 Bi-RRT
基本的RRT每次搜索都只有从初始状态点生长的快速扩展随机树来搜索整个状态空间,如果从初始状态点和目标状态点同时生长两棵快速扩展随机树来搜索状态空间,效率会更高。为此,基于双向扩展平衡的连结型双树RRT算法,即RRT_Connect算法被提出。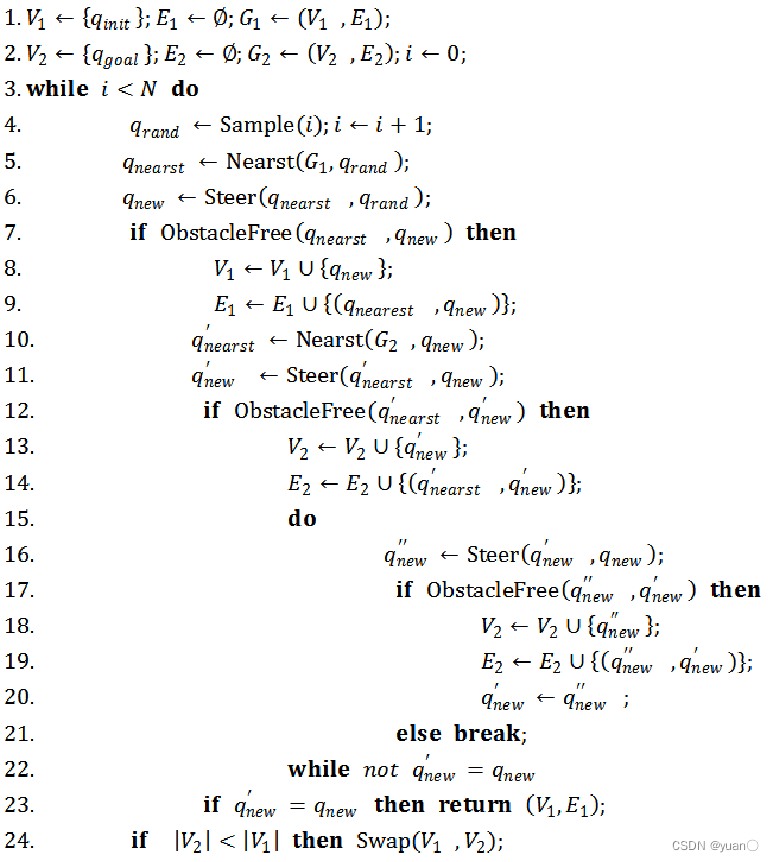
当然每次迭代中必须考虑两棵树的平衡性,即两棵树的节点数的多少(也可以考虑两棵树总共花费的路径长度),交换次序选择“小”的那棵树进行扩展。
如下图所示,Tree_a的扩展方式与以往相同。对于Tree_b而言,相当于将通过Tree_a扩展得到的qnew作为q’rand进行扩展。
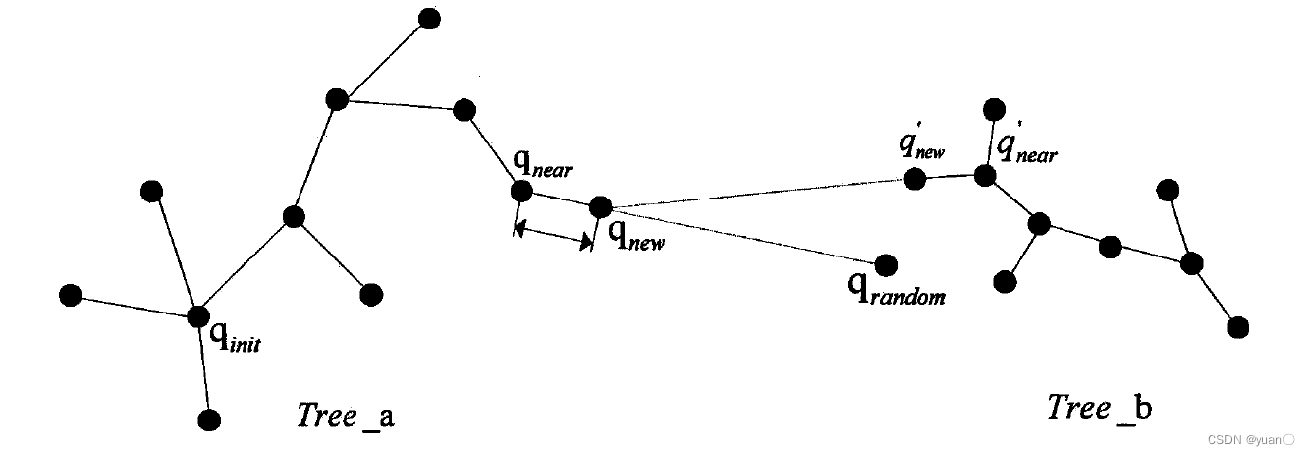
Connect算法较之前的算法在扩展的步长上更长,使得树的生长更快;
两棵树不断朝向对方交替扩展,而不是采用随机扩展的方式,特别当起始位姿和目标位姿处于约束区域时,两棵树可以通过朝向对方快速扩展而逃离各自的约束区域。
这种带有启发性的扩展使得树的扩展更加贪婪和明确,使得双树RRT算法较之单树RRT算法更加有效。

6. RRT算法总结
RRT与其他算法进行对比
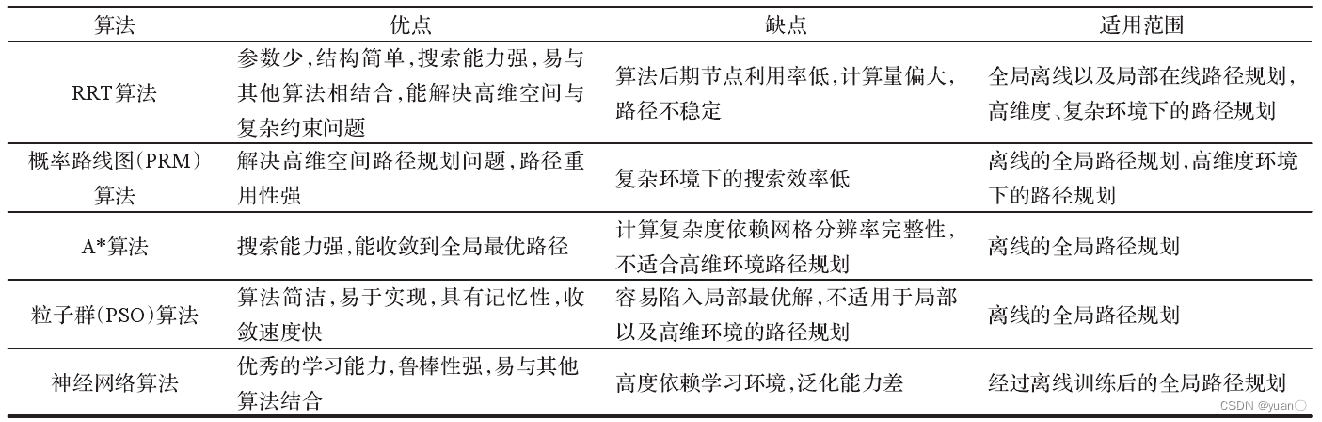
主要原因在于改进的 RRT*算法需要不断调整步长以提高路径精度,生成最优路径所消耗的内存资源及计算时间呈指数增长,不适于实际应用的机器人系统。
此外,环境中的不规则障碍物区域采样、机器人的传感器精度、路面的凹凸性等因素也会影响路径质量。
6.1 RRT的不足与改进
6.1.1 提高节点利用率
RRT 及 RRT*生成大量节点避免产生局部最优路径或搜索失败。
算法通过均匀采样探索整个区域,树中大部分探索节点离生成路径的优化区域远,优化路径的概率小。
此外,树的概率完备性使这些节点不断添加无效分支,增加计算时间。
现有改进算法中,路径重规划速度受到随机树节点数量限制,不同约束条件的采样算法需根据环境人为调节条件参数,自适应能力不足。
因此,需要进一步提高路径优化中节点利用率,生成更智能的算法。
6.1.2 改进最近邻搜索算法
随机树经过均匀采样搜索,寻找最近邻节点的计算量会随着节点指数增长而增长,直接降低了算法收敛速度。
最近邻搜索算法作为限制RRT收敛速度的瓶颈,受到了研究者的高度重视。
改进算法结合 KD-tree等高效的数据结构存储节点,优化最近邻节点的选取方式。但是,改进的数据结构存在添加节点时间长,节点数量大导致资源消耗大,后期维护困难等不足。
在树结构的基础上使用其他技术生成更快的搜索算法,降低最近邻节点连接成本,有助于进一步提高算法收敛速度。
6.1.3 优化狭窄区域采样
RRT 均匀采样性质降低了狭窄区域选取随机节点的概率。作为采样算法的研究难点,很少有算法专门解决狭窄区域的最优路径。
现有改进算法主要通过直接采样解决狭窄区域渐进收敛问题,通过不断减少采样区间,提高路径中的狭窄区域采样概率。
使用深度学习离线训练,得到经过筛选的高回报值节点,能优化最终路径稳定性。
现阶段仍需进一步提高上述算法性能,并着重研究实际机器人系统在狭窄区域的优化过程。
6.1.4 优化非完整约束方程
常见的非完整约束机器人路径规划先通过 RRT 算法求得可行路径,再采用曲率平滑后处理生成满足运动方程约束的路径。
然而,实际规划中路径目标更新快,后处理计算量大。非完整约束的运动方程需要考虑以下问题:优化运动方程,减少方程计算量;平衡实时性强的非完整约束机器人中曲线计算效率与路径精度;选取适合狭窄区域的非完整约束机器人度量准则,提高狭窄区域下的路径稳定性。
未来对非完整约束的研究应着重解决实际的动力学问题,并进一步优化路径平滑度。
7. 基于MATLAB实现RRT*以及相应改进算法
7.1 rrt_toolbox
首先介绍一个关于RRT算法的工具箱——rrt_toolbox。该工具箱实现了关于RRT、RRT以及RRTFN(基于RRT*,具有渐进最优性,占据较少内存容量)等算法。导入到MATLAB后其文件结构如下图所示:
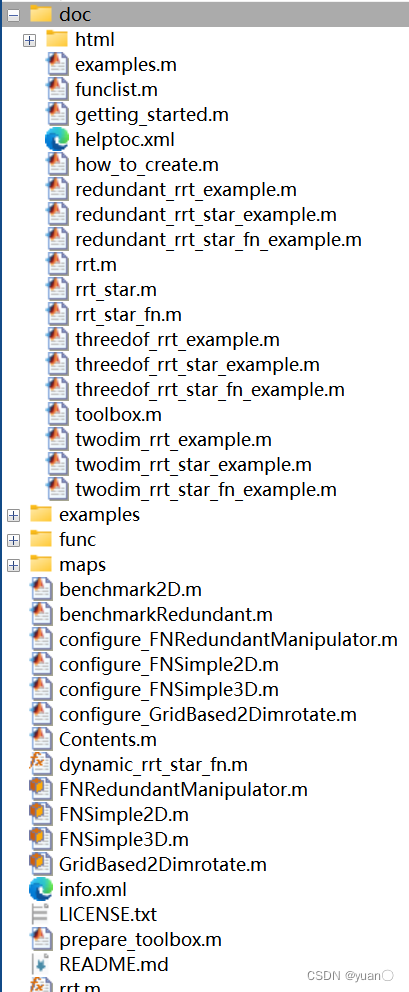
- html文件夹中包含了相关算法的说明、算法实现的具体流程、伪代码、编写代码的具体步骤
- example文件夹中包含了相关算法的演示案例
- func文件夹中是编写的函数
- maps文件夹中存放了地图

7.2 matlab-rrt-variants
matlab-rrt-variants这个代码库则在MATLAB中实现了2D、3D的RRT、RRT*、RRT-connect以及lazy-RRT等算法。
在MATLAB中打开后,我们主要是对benchmarkRRT.m 这个文件进行调试与修改:
- 选取执行RRT-planner的个数——num_of_runs =1;
表示执行一种算法 - 选取执行算法的种类——run_RRTconnect =0 or 1;
run_RRTextend = 0 or 1;
run_LazyRRT = 0 or 1;
run_RRTstar = 0 or 1;
0或1表示是否执行该算法。 - 定义维度——dim = 3;
表示维度为3维。 - 定义步长大小,2D的地图为100x100,3D的地图为100x100x100——stepsize = [10];
- 是否选取随机的障碍物——random_world = 0 or 1;
- 选取采样点数目——samples = 4000;
- 选择输出与否——show_output = 0 or 1;
show_benchmark_results = 0 or 1;
7.3 基于栅格地图实现RRT
7.3.1 MATLAB 编写 RRT 算法的几个核心思想
MATLAB 编写 RRT 算法的几个核心思想:
-
在随机采样撒点时,可以利用 randi 函数,随机生成一个[1,n]范围的整数,代表采样栅格;
-
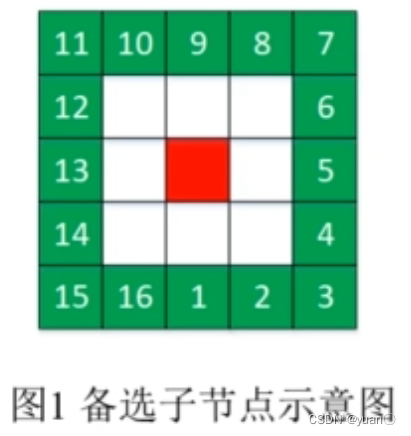
如何根据子节点扩展方向确定对应的栅格?首先把父节点邻近的16个节点作为备选的子节点,从正下方编号为1,逆时针依次增加,如图1。
-
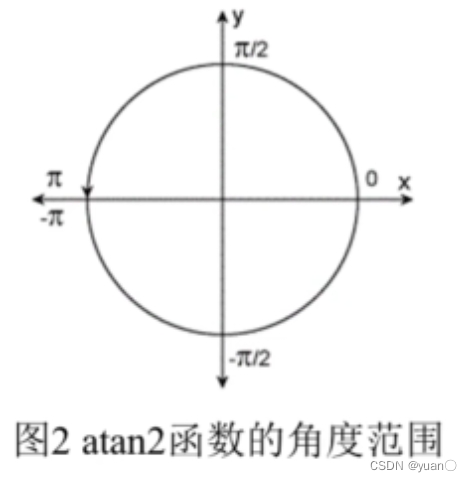
然后把2元角度划分为16份,根据所确定的父节点与采样点的连线可以可以计算一个角度,根据这个角度在16份角度的范围,从而确定被选中的子节点。同时,考虑到行列坐标与 x / y 坐标的不对应,在计算连线角度时采用atan2函数,而不用 atan 函数,如图2。
-
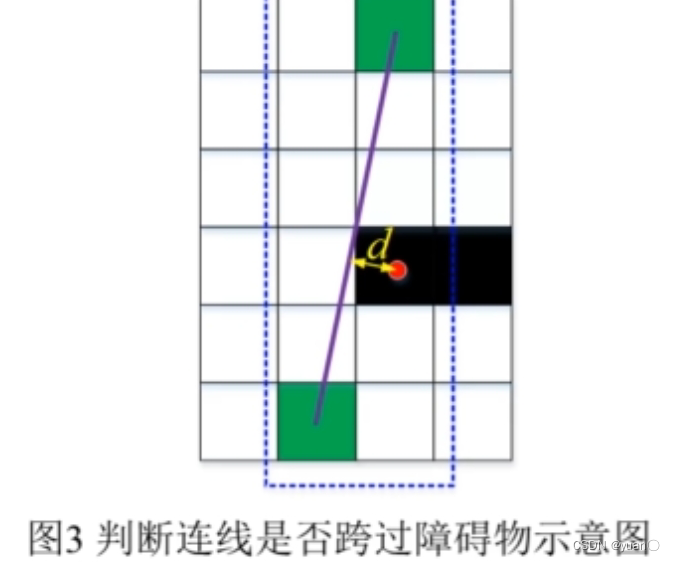
如何判断父节点与子节点的连线是否跨过障碍物?如图3,父子节点的连线与障碍物的最短距离 d>栅格单位长度的一半,表明未跨过障碍物。并且仅需讨论蓝色虚线框内的障碍物栅格即可。
基于栅格地图实现RRT主要有以下几个程序组成
7.3.2 defColorMap.m
定义地图
function [field,cmap] = defColorMap(rows, cols)
cmap = [1 1 1; ... % 1-白色-空地
0 0 0; ... % 2-黑色-静态障碍
1 0 0; ... % 3-红色-已经搜索过的点
1 1 0;... % 4-黄色-起始点
1 0 1;... % 5-品红-目标点
0 1 0; ... % 6-绿色-到目标点的规划路径
0 1 1]; % 7-青色-动态规划的路径
% 构建颜色MAP图
colormap(cmap);
% 定义栅格地图全域,并初始化空白区域
field = ones(rows, cols);
% 障碍物区域
obsRate = 0.3;
obsNum = floor(rows*cols*obsRate);
obsIndex = randi([1,rows*cols],obsNum,1);
field(obsIndex) = 2;
7.3.3 getSamplePoint.m
得到采样点
function samplePoint = getSamplePoint(field, treeNodes)
[rows, cols] = size(field);
field(treeNodes(:,1)) = 3;
while true
samplePoint = randi([1,rows*cols]);
if field(samplePoint) == 1
break;
end
end
7.3.4 getChildNode.m
得到子节点
function childNode = getChildNode(field, parentNode, samplePoint)
% 定义生长单步长为2个栅格,选取父节点周边16个节点作为备选子节点
% 根据随机采样点与父节点的角度,确定生长的子节点
[rows, cols] = size(field);
[row_samplePoint, col_samplePoint] = ind2sub([rows, cols], samplePoint);
[row_parentNode, col_parentNode] = ind2sub([rows, cols], parentNode);
% 定义16个点的行列坐标
% 注意,为了行列坐标与x/y坐标匹配,从父节点的下节点逆时针开始定义,依次编号
childNode_set = [ row_parentNode+2, col_parentNode;
row_parentNode+2, col_parentNode+1;
row_parentNode+2, col_parentNode+2;
row_parentNode+1, col_parentNode+2;
row_parentNode, col_parentNode+2;
row_parentNode-1, col_parentNode+2;
row_parentNode-2, col_parentNode+2;
row_parentNode-2, col_parentNode+1;
row_parentNode-2, col_parentNode;
row_parentNode-2, col_parentNode-1;
row_parentNode-2, col_parentNode-2;
row_parentNode-1, col_parentNode-2;
row_parentNode, col_parentNode-2;
row_parentNode+1, col_parentNode-2;
row_parentNode+2, col_parentNode-2;
row_parentNode+2, col_parentNode-1];
% 计算16个子节点的角度范围集,和当前随机点的角度范围
theta_set = linspace(0,2*pi,16);
theta = atan2((col_samplePoint - col_parentNode), ...
(row_samplePoint - row_parentNode));
% 若theta位于第三四象限,加上2*pi
if theta < 0
theta = theta + 2*pi;
end
% 遍历周围的16个点,判断角度位于哪一个范围
for i = 1:15
if theta >= theta_set(i) && theta < theta_set(i+1)
childNodeIdx = i;
break
end
end
% 选中的子节点
childNode = childNode_set(childNodeIdx,:);
7.3.5 judgeObs.m
判断连线是否与障碍物碰撞
function flag = judgeObs(field, parentNode, childNode)
flag = 0;
[rows, cols] = size(field);
% 判断子节点是否在障碍物上
obsIdx = find(field == 2);
if ismember(childNode, obsIdx)
flag = 1;
return
end
% 判断父节点与子节点的连线是否跨过障碍物
[parentNode(1), parentNode(2)] = ind2sub([rows, cols], parentNode);
[childNode(1), childNode(2)] = ind2sub([rows, cols], childNode);
P2 = parentNode;
P1 = childNode;
row_min = min([P1(1), P2(1)]);
row_max = max([P1(1), P2(1)]);
col_min = min([P1(2), P2(2)]);
col_max = max([P1(2), P2(2)]);
for row = row_min:row_max
for col = col_min:col_max
if field(row, col) == 2
P = [row, col];
% 直接计算障碍物节点距P1和P2构成的连线的距离
d = abs(det([P2-P1;P-P1]))/norm(P2-P1);
if d < 0.5
flag = 1;
return
end
end
end
end
7.3.6 RRT.m
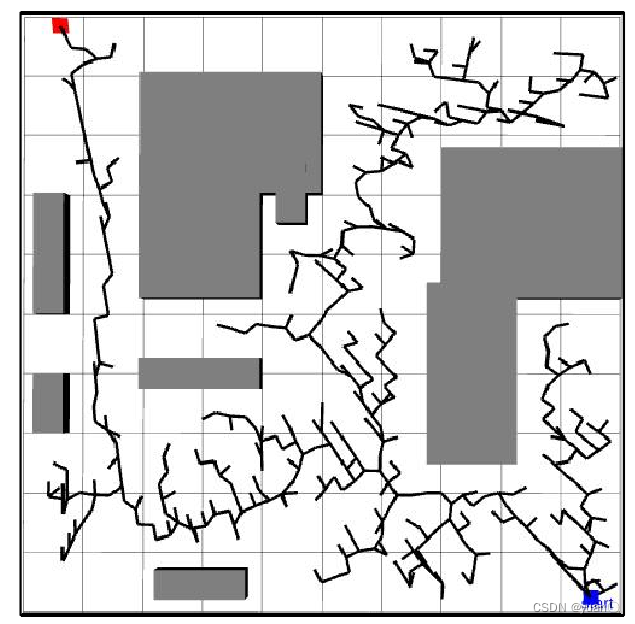
% 基于栅格地图的机器人路径规划算法
% 第4节:RRT算法
clc
clear
close all
%% 障碍物、空白区域、起始点、目标点定义
% 行数和列数
rows = 30;
cols = 50;
[field,cmap] = defColorMap(rows, cols);
% 起点、终点、障碍物区域
startPos = 2;
goalPos = rows*cols-2;
field(startPos) = 4;
field(goalPos) = 5;
image(1.5,1.5,field);
grid on;
set(gca,'gridline','-','gridcolor','k','linewidth',2,'GridAlpha',0.5);
set(gca,'xtick',1:cols+1,'ytick',1:rows+1);
axis image;
hold on;
%% 算法
% 定义树节点,第一列放节点编号,第二列放该节点的父节点
treeNodes = [startPos, 0];
while true
% 初始化parentNode和childNode
parentNode = [];
childNode = [];
% 在地图空间随机采样撒点
samplePoint = getSamplePoint(field, treeNodes);
% 依次遍历每一个树节点到采样点的距离,取最小值对应的树节点
for i = 1:size(treeNodes,1)
[row_treeNode, col_treeNode] = ind2sub([rows, cols], treeNodes(i,1));
[row_samplePoint, col_samplePoint] = ind2sub([rows, cols], samplePoint);
dist(i) = norm([row_treeNode, col_treeNode] - [row_samplePoint, col_samplePoint]);
end
[~,idx] = min(dist);
parentNode = treeNodes(idx,1);
% 生成新的子节点,行列坐标
childNode = getChildNode(field, parentNode, samplePoint);
% 判断该子节点是否超过地图限制
if childNode(1) < 1 || childNode(1) > rows ||...
childNode(2) < 1 || childNode(2) > cols
continue
else
% 转为线性索引
childNode = sub2ind([rows, cols], childNode(1), childNode(2));
end
% 判断父节点与子节点的连线是否跨过障碍物
flag = judgeObs(field, parentNode, childNode);
if flag
continue
end
hold on;
[parent_y0,parent_x0] = ind2sub([rows,cols], parentNode);
parent_y = parent_y0 + 0.5;
parent_x = parent_x0 + 0.5;
[child_y0,child_x0] = ind2sub([rows,cols], childNode);
child_y = child_y0 + 0.5;
child_x = child_x0 + 0.5;
X = [parent_x,child_x];
Y = [parent_y,child_y];
line(X,Y,'LineWidth',1.5);
hold on;
% 判断该子节点是否已经存在于treeNodes,未在则追加到treeNodes
if ismember(childNode, treeNodes(:,1))
continue
else
treeNodes(end+1,:) = [childNode, parentNode];
end
% 判断子节点是否位于目标区域
[row_childNode, col_childNode] = ind2sub([rows, cols], childNode);
[row_goalPos, col_goalPos] = ind2sub([rows, cols], goalPos);
if abs(row_childNode - row_goalPos) + ...
abs(col_childNode - col_goalPos) < 2
break
end
end
%% 找出目标最优路径
% 最优路径
path_opt = [];
idx = size(treeNodes,1);
while true
path_opt(end+1) = treeNodes(idx,1);
parentNode = treeNodes(idx,2);
if parentNode == startPos
break;
else
idx = find(treeNodes(:,1) == parentNode);
end
end
%% 画栅格图
hold on;
[y0,x0] = ind2sub([rows,cols], path_opt);
y = y0 + 0.5;
x = x0 + 0.5;
plot(x,y,'-','Color','r','LineWidth',2.5);
hold on;
values = spcrv([[x(1) x x(end)];[y(1) y y(end)]],3);
plot(values(1,:),values(2,:), 'b','LineWidth',2.5);
% image(1.5,1.5,field);
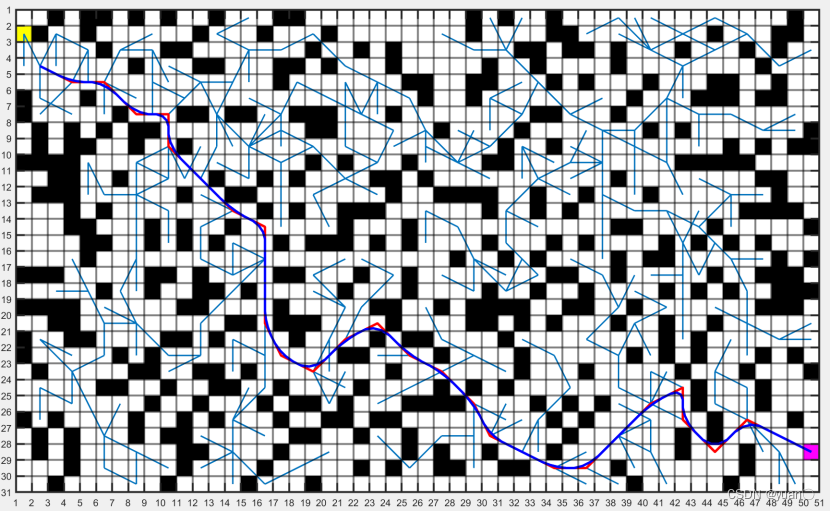
7.3.7 效果

参考文献
[1] 路径规划算法学习笔记(二)——基于采样
[2] 基于采样的运动规划算法-RRT(Rapidly-exploring Random Trees)
[3] RRT路径规划算法
[4] 路径规划——改进RRT算法
声明
本人所有文章仅作为自己的学习记录,若有侵权,联系立删。
相关代码资料整理
链接:https://pan.baidu.com/s/1U5ct13Ue5lAjf1khf1M9GA?pwd=8fng
提取码:8fng