背景介绍
第三方大模型API
目前,市面上有许多第三方大模型 API 服务提供商,通过 API 接口向用户提供多样化的服务。这些平台不仅能提供更多类别和类型的模型选择,还因其用户规模较大,能够以更低的成本从原厂获得服务,再将其转售给用户。此外,这些服务商还支持一些海外 API 服务,例如 ChatGPT 等,为用户提供了更加广泛的选择。
比如上述网站以 API 接口的形式对外提供的服务,比官方的 API 要便宜。
装包:
pip install langchain langchain_openai
运行下述代码,完成上述网站的注册后,并填上述网站的 api_key 便可通过 python API 调用,就会收到 gpt-4o-mini 大模型的响应。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-4o-mini",
base_url="https://www.gptapi.us/v1/",
api_key="sk-xxx", # 在这里填入你的密钥
)
res = llm.invoke("你是谁?请你简要做一下,自我介绍?")
print(res)
介绍
在部署垂直领域模型时,我们通常会对开源大模型进行微调,并获得相应的 LoRA 权重。在接下来的部分,我将介绍如何使用 LLamafactory 将微调后的 LoRA 模型部署为 API 服务。
在 Python 中调用 API 服务时,如果采用同步方式进行请求,往往会导致请求速度较慢。因为同步方式需要在接收到上一条请求的响应后,才能发起下一条请求。
为了解决这一问题,我将为大家介绍如何通过异步请求的方式,在短时间内发送大量请求,从而提升 API 调用效率。
LLamafactory 部署API
关于 LLamafactory 的下载与微调模型,点击查看我的这篇博客:Qwen2.5-7B-Instruct 模型微调与vllm部署详细流程实战.https://blog.csdn.net/sjxgghg/article/details/144016723
vllm_api.yaml 的文件内容如下:
model_name_or_path: qwen/Qwen2.5-7B-Instruct
adapter_name_or_path: ../saves/qwen2.5-7B/ner_epoch5/
template: qwen
finetuning_type: lora
infer_backend: vllm
vllm_enforce_eager: true
# llamafactory-cli chat lora_vllm.yaml
# llamafactory-cli webchat lora_vllm.yaml
# API_PORT=8000 llamafactory-cli api lora_vllm.yaml
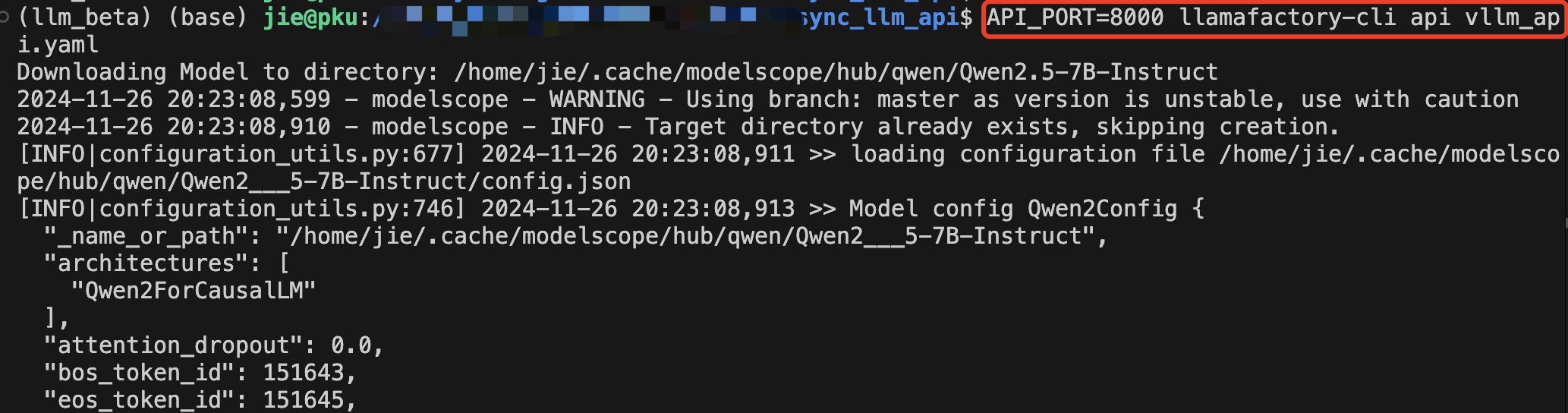
使用下述命令便可把大模型以 API 部署的方式,部署到8000端口:
API_PORT=8000 llamafactory-cli api vllm_api.yaml
LangChain 的 invoke 方法是常用的调用方式,但该方法并不支持异步操作。如果读者想了解同步与异步在速度上的差距,可以自行尝试使用一个 for 循环调用 invoke 方法,并对比其性能表现。
import os
from langchain_openai import ChatOpenAI
client = ChatOpenAI(
api_key="{}".format(os.environ.get("API_KEY", "0")),
base_url="http://localhost:{}/v1".format(os.environ.get("API_PORT", 8000)),
)
res = llm.invoke("你是谁?请你简要做一下,自我介绍?")
print(res)

在项目文件夹下,新建一个 .env 文件, 其中 API_KEY 的值便是API接口调用的 API_KEY。
API_KEY=sk-12345678
LLamafactory 通过API部署的大模型地址是: http://localhost:8000/v1
API_KEY 是.env 文件中 API_KEY:sk-12345678
大模型 API 调用工具类
使用异步协程加快 API 的调用速度,可以参考我们前面的这篇文章:大模型 API 异步调用优化:高效并发与令牌池设计实践.https://blog.csdn.net/sjxgghg/article/details/143858730
我们在前面一篇文章的基础上,对异步类再封装了一下。
装包:
pip install langchain tqdm aiolimiter python-dotenv
import os
import random
import asyncio
import pandas as pd
from tqdm import tqdm
from typing import List
from dataclasses import dataclass, field
from aiolimiter import AsyncLimiter
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
def generate_arithmetic_expression(num: int):
"""
生成数学计算的公式和结果
"""
# 定义操作符和数字范围,除法
operators = ["+", "-", "*"]
expression = (
f"{random.randint(1, 100)} {random.choice(operators)} {random.randint(1, 100)}"
)
num -= 1
for _ in range(num):
expression = f"{expression} {random.choice(operators)} {random.randint(1, 100)}"
result = eval(expression)
expression = expression.replace("*", "x")
return expression, result
@dataclass
class AsyncLLMAPI:
"""
大模型API的调用类
"""
base_url: str
api_key: str # 每个API的key不一样
uid: int = 0
cnt: int = 0 # 统计每个API被调用了多少次
model: str = "gpt-3.5-turbo"
llm: ChatOpenAI = field(init=False) # 自动创建的对象,不需要用户传入
num_per_second: int = 6 # 限速每秒调用6次
def __post_init__(self):
# 初始化 llm 对象
self.llm = self.create_llm()
# 创建限速器,每秒最多发出 5 个请求
self.limiter = AsyncLimiter(self.num_per_second, 1)
def create_llm(self):
# 创建 llm 对象
return ChatOpenAI(
model=self.model,
base_url=self.base_url,
api_key=self.api_key,
)
async def __call__(self, text):
# 异步协程 限速
self.cnt += 1
async with self.limiter:
return await self.llm.agenerate([text])
@staticmethod
async def _run_task_with_progress(task, pbar):
"""包装任务以更新进度条"""
result = await task
pbar.update(1)
return result
@staticmethod
def async_run(
llms: List["AsyncLLMAPI"],
data: List[str],
keyword: str = "", # 文件导出名
output_dir: str = "output",
chunk_size=500,
):
async def _func(llms, data):
"""
异步请求处理一小块数据
"""
results = [llms[i % len(llms)](text) for i, text in enumerate(data)]
with tqdm(total=len(results)) as pbar:
results = await asyncio.gather(
*[
AsyncLLMAPI._run_task_with_progress(task, pbar)
for task in results
]
)
return results
idx = 0
all_df = []
while idx < len(data):
file = f"{idx}_{keyword}.csv"
file_dir = os.path.join(output_dir, file)
if os.path.exists(file_dir):
print(f"{file_dir} already exist! Just skip.")
tmp_df = pd.read_csv(file_dir)
else:
tmp_data = data[idx : idx + chunk_size]
loop = asyncio.get_event_loop()
tmp_result = loop.run_until_complete(_func(llms=llms, data=tmp_data))
tmp_result = [item.generations[0][0].text for item in tmp_result]
tmp_df = pd.DataFrame({"infer": tmp_result})
# 如果文件夹不存在,则创建
if not os.path.exists(tmp_folder := os.path.dirname(file_dir)):
os.makedirs(tmp_folder)
tmp_df.to_csv(file_dir, index=False)
all_df.append(tmp_df)
idx += chunk_size
all_df = pd.concat(all_df)
all_df.to_csv(os.path.join(output_dir, f"all_{keyword}.csv"), index=False)
return all_df
if __name__ == "__main__":
# 生成 数学计算数据集
texts = []
labels = []
for _ in range(1000):
text, label = generate_arithmetic_expression(2)
texts.append(text)
labels.append(label)
llm = AsyncLLMAPI(
base_url="http://localhost:{}/v1".format(os.environ.get("API_PORT", 8000)),
api_key="{}".format(os.environ.get("API_KEY", "0")),
)
AsyncLLMAPI.async_run(
[llm], texts, keyword="数学计算", output_dir="output", chunk_size=500
)
使用异步类,在短时间内向对方服务器,发送大量的请求可能会导致服务器拒绝响应。
由于使用了异步的请求,则必须在所有的请求都完成后才能拿到结果。为了避免程序中途崩溃导致前面的请求的数据丢失,故 使用 chunk_size 对请求的数据进行切分,每完成一块数据的请求则把该块数据保存到csv文件中。
本文使用 generate_arithmetic_expression 生成1000条数学计算式,调用大模型 API 完成计算。
运行效果如下:
原始的 1000 条数据,设置chunk_size为500,故拆分为2块500条,分批进行处理。

为了避免程序崩垮,分批进行异步推理,若程序崩溃了,可重新运行,程序会从上一次崩溃的点重新运行。(要保证数据集输入的一致!)
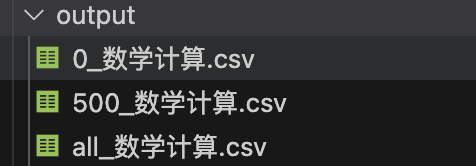
最终的输出文件是 all_数学计算.csv ,它是所有分快csv文件的汇总。
项目开源
https://github.com/JieShenAI/csdn/tree/main/24/11/async_llm_api
- vllm_api.yaml 是 llamafactory 的API部署的配置;
- core.py 是主要代码;