一.基于任务窃取的分布式调度
下图是典型的分布式调度线程池示意图(Eigen中的线程池,MindSpore与其类似):
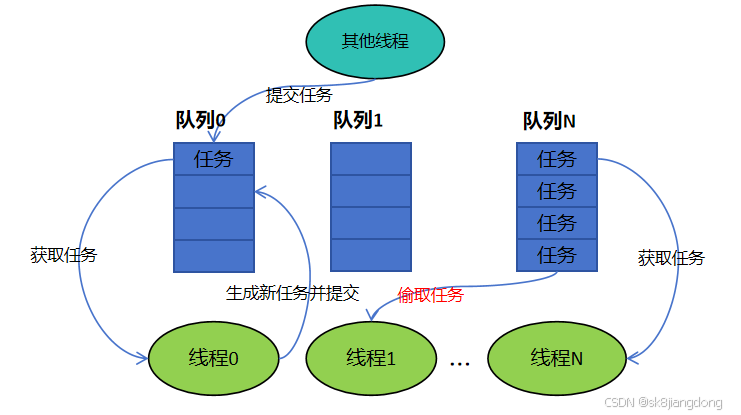
主要逻辑:
1.线程池初始化时,一般根据系统的CPU核数创建相应的线程数(也可传递参数配置)
2.开始一般会有一个不属于线程池内的线程向线程池任务队列提交任务(可能随机选择一个队列提交)
3.每个线程在创建时绑定一个Run函数,函数逻辑:先尝试从本地队列(线程自己的任务队列)取任务(一般从头部取,第5条解释),如果本地队列没有任务,则尝试从其它线程的队列尾部(第5条解释)偷取任务执行。在满足一定条件时(如长时间未有效获取到任务,只是在浪费CPU资源)进入休眠状态,等待被唤醒
4.线程在执行完某个任务(例如深度学习计算图中某个算子)后,可能会产生新的任务,将该任务提交到本地任务队列
5. 之所以每个线程从本地队列取任务是从头部,提交任务也是向头部提交,而偷取别的队列任务是从尾部,是为了提高cache的数据亲和性进而提高执行效率。举例来说:线程0完成算子A的执行,生成了新任务(算子B),那么很可能算子A的输出数据就是算子B的输入,此时线程0所在的CPU核的cache中还缓存着A的输出数据,那么将算子B的任务提交到本地队列头部,再从头部取任务,大概率会取到算子B任务,则cache中缓存的数据有效利用起来,提高效率;别的线程从本线程任务队列尾部偷取任务,避免了刚生成的算子B任务被别的线程抢走执行,导致无法利用cache中的数据
6. 任务调度机制设计出发点都是为了效率,上面调度机制好处有几点:
1)分布式调度:没有中央调度器,避免调度器的任务调度能力成为系统瓶颈
2)实现了动态的负载均衡:当任务量充足时,所有线程都会忙碌起来,充分利用多核算力
3)避免CPU算力浪费:任务量不足时,获取不到任务的线程会休眠
4)考虑了cache数据亲和性:提高cache命中率进而提高任务执行效率,避免大量访问内存
二.Worker关键代码解析
Worker类就是线程池中的工作线程,只不过对其做了一层封装,下面介绍主要方法(代码位置:mindspore/core/mindrt/src/thread/threadpool.cc):
Worker::CreateThread
void Worker::CreateThread() { thread_ = std::make_unique<std::thread>(&Worker::Run, this); }该方法用于实例化一个std::thread对象并启动执行,该线程生命周期内只执行Worker::Run方法
Worker::Run
void Worker::Run() {
if (!core_list_.empty()) {
SetAffinity();
}
#if !defined(__APPLE__) && !defined(_MSC_VER)
static std::atomic_int index = {0};
(void)pthread_setname_np(pthread_self(), ("KernelThread_" + std::to_string(index++)).c_str());
#endif
#ifdef PLATFORM_86
// Some CPU kernels need set the flush zero mode to improve performance.
_MM_SET_FLUSH_ZERO_MODE(_MM_FLUSH_ZERO_ON);
_MM_SET_DENORMALS_ZERO_MODE(_MM_DENORMALS_ZERO_ON);
#endif
while (alive_) {
if (RunLocalKernelTask()) {
spin_count_ = 0;
} else {
RunOtherKernelTask();
YieldAndDeactive();
}
if (spin_count_ > max_spin_count_) {
WaitUntilActive();
spin_count_ = 1;
}
}
}由上面代码可见,Worker生命周期内执行的是一个循环,流程:
1.调用RunLocalKernelTask尝试从本地任务队列取任务执行,如果成功,则将spin_count置0(下文解释)。
2.如果没能成功执行本地队列任务(一般是本地队列没任务),则运行RunOtherKernelTask,从其它Worker任务队列中偷取任务执行。然后,调用YieldAndDeactive(内部调用了std::this_thread::yield)让出CPU,给其它线程执行。
3.判断spin_count的值,如果大于max_spin_count_,则调用WaitUntilActive使Worker进入休眠状态,直到被唤醒。
这里要讲一下spin_count的作用,先看哪些地方会对其赋值:
1)RunLocalKernelTask成功执行后,将spin_count赋0
2)在YieldAndDeactive中将spin_count++,如下:
void Worker::YieldAndDeactive() {
// deactivate this worker only on the first entry
if (spin_count_ == 0) {
std::lock_guard<std::mutex> _l(mutex_);
if (local_task_queue_->Empty()) {
status_.store(kThreadIdle);
} else {
return;
}
}
spin_count_++;
std::this_thread::yield();
}3)当休眠后被唤醒时(WaitUntilActive()之后)将spin_count置1(为什么不置0,我没有完全明白,以后弄懂了再更新)
说明spin_count是个表征Worker“空转率”的值,值越大空转率越高,越应该被休眠。其实就是说明该Worker的任务队列中没有任务,尽管能够偷取任务来执行,但依然会spin_count++,说明偷取任务这种行为虽然被允许,但偷取的频率需要被控制
Worker类还有很多方法,包括绑核设置(SetAffinity方法,将线程固定调度到某个CPU核上执行,以提高cache命中率)等,这些属于在实现线程池基础逻辑之上的优化,本文不展开。
mindspore/core/mindrt/src/thread/threadpool.cc中还有一个ThreadPool类,在下篇文章解析