一、找到合适的分词工具
Python有很多分词工具可以使用,其中最常用的是使用jieba库进行中文分词处理。在python的三方标准库中可以找到,这里是链接,对应的文档点击这里查看。
二、实战使用
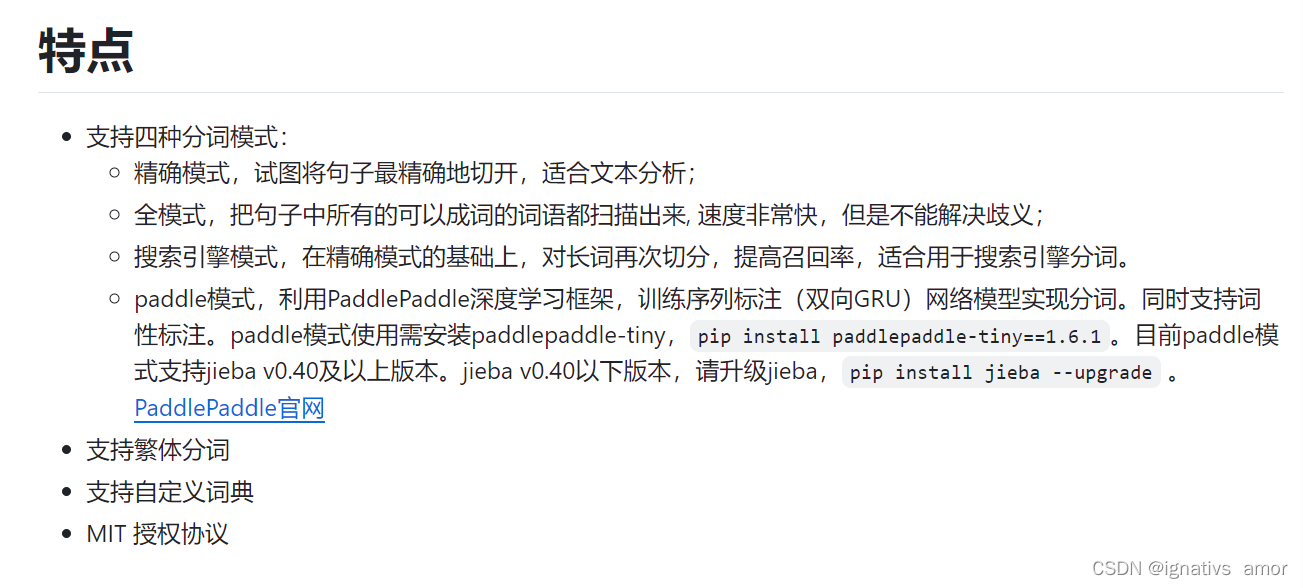
2.1、Jieba特点
2.2、安装
使用库,需要先安装哈,然后再在项目中导入。

2.3、主要功能

2.4、代码使用
# encoding=utf-8
import jieba
jieba.enable_paddle()# 启动paddle模式。 0.40版之后开始支持,早期版本不支持
strs=["我来到北京清华大学","乒乓球拍卖完了","中国科学技术大学"]
for str in strs:
seg_list = jieba.cut(str,use_paddle=True) # 使用paddle模式
print("Paddle Mode: " + '/'.join(list(seg_list)))
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
输出:
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
2.5、更多使用
更多使用可以参考文档里哈,这次就先分享到这里,我主要是用到分词这个功能