开题报告
题目:Python+大模型恶意木马流量检测与分类
一、研究背景与意义
随着互联网技术的飞速发展,网络安全问题日益严峻,恶意木马流量成为网络攻击的重要手段之一。传统的网络安全检测方法往往基于规则匹配和统计分析,面对复杂多变的网络攻击时,其准确性和效率难以保证。因此,开发一种高效、智能的恶意木马流量检测与分类系统具有重要意义。
本研究旨在利用Python编程语言和大型机器学习模型(大模型)的优势,构建一种能够高效分析网络流量数据、准确识别恶意木马流量并进行分类的系统。该系统将为网络安全防护提供有力的支持,有助于提高网络安全检测的准确性和效率,降低网络安全风险。
二、研究内容与目标
- 数据采集与预处理
- 利用Python的爬虫技术从网络中实时采集流量数据,包括IP地址、端口号、协议类型、数据包长度等关键信息。
- 对采集到的数据进行清洗、格式化和标准化处理,以确保数据的质量和一致性。
- 特征提取与选择
- 利用机器学习算法对预处理后的数据进行特征提取,提取出能够反映网络流量特征和规律的关键特征。
- 通过特征选择方法,筛选出对分类任务最有贡献的特征,以提高模型的性能和效率。
- 大模型构建与训练
- 选择合适的深度学习框架(如TensorFlow、PyTorch等)构建大型机器学习模型。
- 利用提取出的特征数据训练模型,生成能够分类恶意木马流量的分类器。
- 系统实现与测试
- 将模型集成到系统中,实现实时流量数据的采集、预处理、特征提取、分类和报警等功能。
- 通过实验验证系统的有效性和准确性,评估模型的性能表现。
- 优化与改进
- 根据实验结果对系统进行优化和改进,提高系统的稳定性和可靠性。
- 探索将系统应用于不同行业和领域,以适应不同场景下的网络安全需求。
三、研究方法与技术路线
- 文献调研
- 查阅相关文献和资料,了解恶意木马流量检测与分类的研究现状和发展趋势。
- 数据采集与预处理
- 使用Python的Scapy库进行网络流量数据的采集。
- 利用pandas库进行数据清洗和格式化处理。
- 特征提取与选择
- 使用scikit-learn库进行特征提取和选择。
- 尝试不同的特征提取方法和选择策略,以找到最优的特征组合。
- 大模型构建与训练
- 选择TensorFlow或PyTorch等深度学习框架进行模型的构建和训练。
- 通过调整模型结构、参数和训练策略,优化模型的性能。
- 系统实现与测试
- 使用Django等框架进行系统前后端开发。
- 利用MySQL等数据库存储和管理数据。
- 通过实验验证系统的功能和性能,评估模型的准确性和效率。
- 优化与改进
- 根据实验结果对系统进行优化和改进,提高系统的稳定性和可靠性。
- 尝试将系统应用于不同的行业和领域,以验证其泛化能力和实用性。
四、预期成果与创新点
- 预期成果
- 构建一个基于Python和大模型的恶意木马流量检测与分类系统。
- 实现实时流量数据的采集、预处理、特征提取、分类和报警等功能。
- 通过实验验证系统的有效性和准确性,评估模型的性能表现。
- 创新点
- 利用大型机器学习模型进行恶意木马流量的检测与分类,提高了检测的准确性和效率。
- 结合Python编程语言的强大功能和深度学习框架的先进算法,实现了系统的实时性和智能化。
- 通过对系统的优化和改进,提高了其稳定性和可靠性,并探索了在不同行业和领域的应用场景。
五、研究计划与时间表
- 文献调研与方案设计(第1-2个月)
- 查阅相关文献和资料,了解研究背景和现状。
- 制定研究方案和技术路线。
- 数据采集与预处理(第3-4个月)
- 实现网络流量数据的采集和预处理功能。
- 对数据进行清洗、格式化和标准化处理。
- 特征提取与选择(第5-6个月)
- 实现特征提取和选择功能。
- 筛选出对分类任务最有贡献的特征。
- 大模型构建与训练(第7-8个月)
- 构建大型机器学习模型并进行训练。
- 调整模型结构、参数和训练策略以优化性能。
- 系统实现与测试(第9-10个月)
- 实现系统的前后端开发和数据库管理功能。
- 通过实验验证系统的功能和性能。
- 优化与改进(第11-12个月)
- 对系统进行优化和改进以提高稳定性和可靠性。
- 探索将系统应用于不同行业和领域的应用场景。
六、参考文献
[此处列出相关文献和资料,由于篇幅限制,未具体列出。]
以上开题报告仅为示例,具体研究内容和计划可能需要根据实际情况进行调整和完善。希望该研究能够为网络安全防护领域做出一定的贡献。

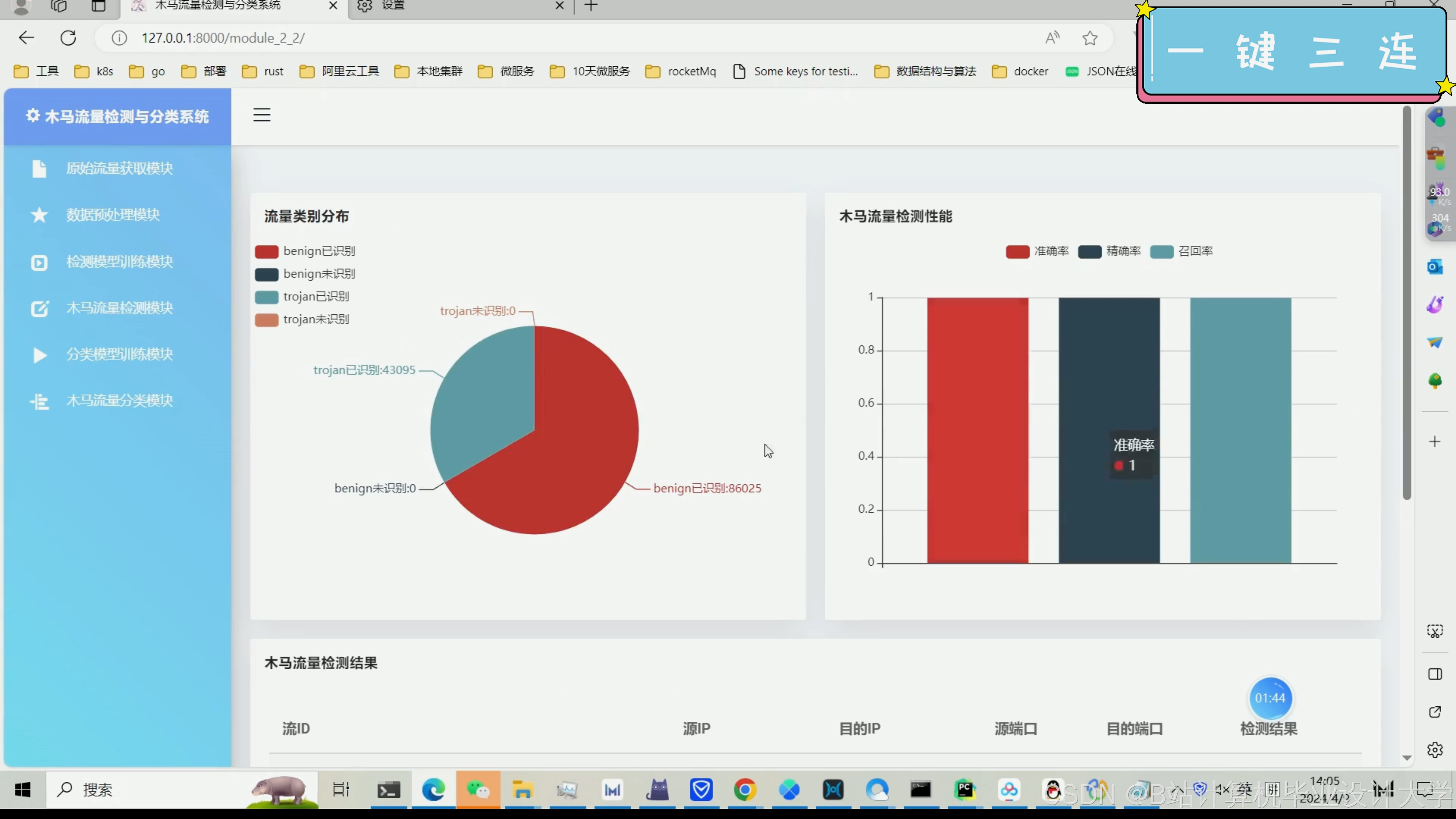
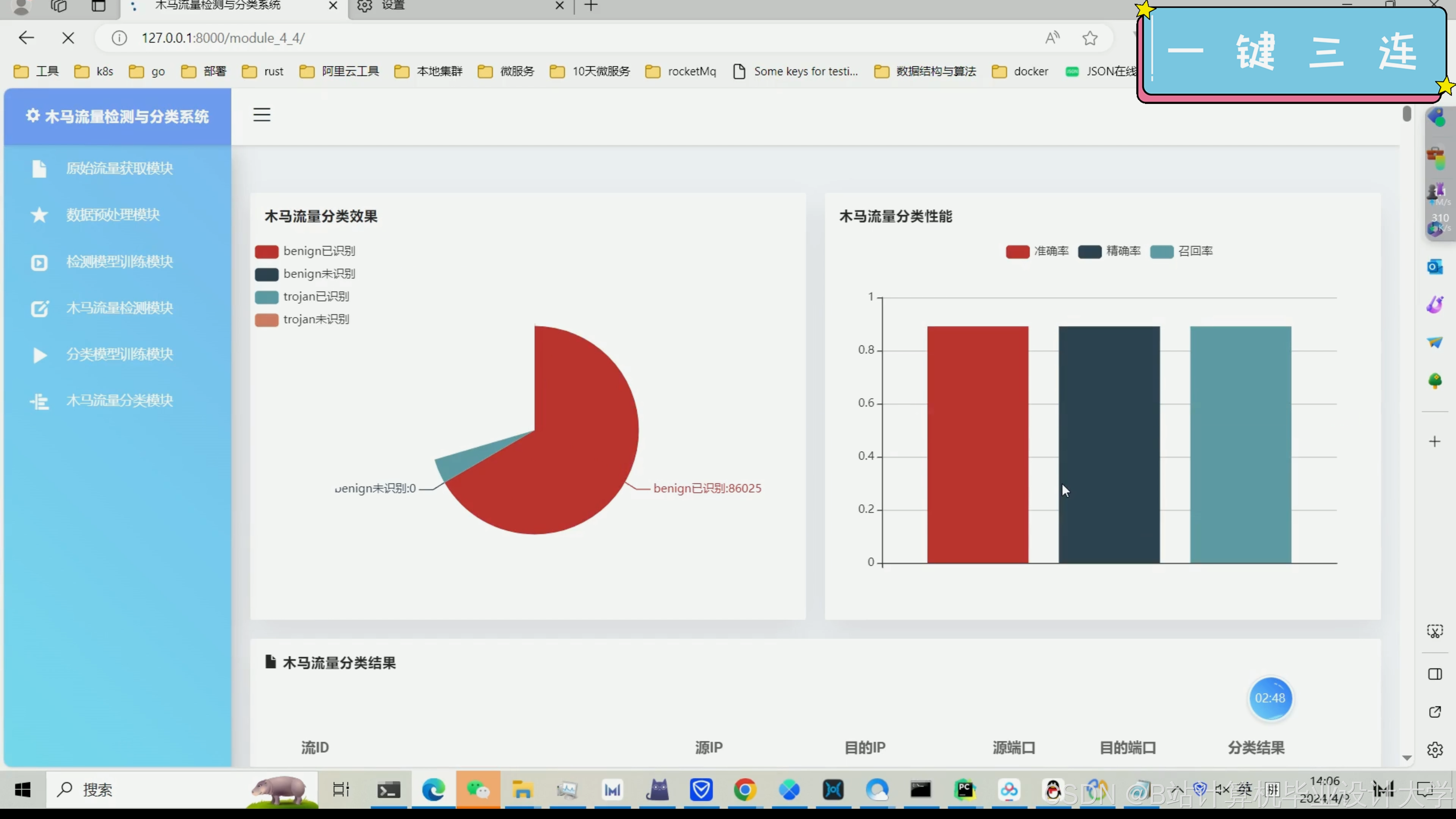


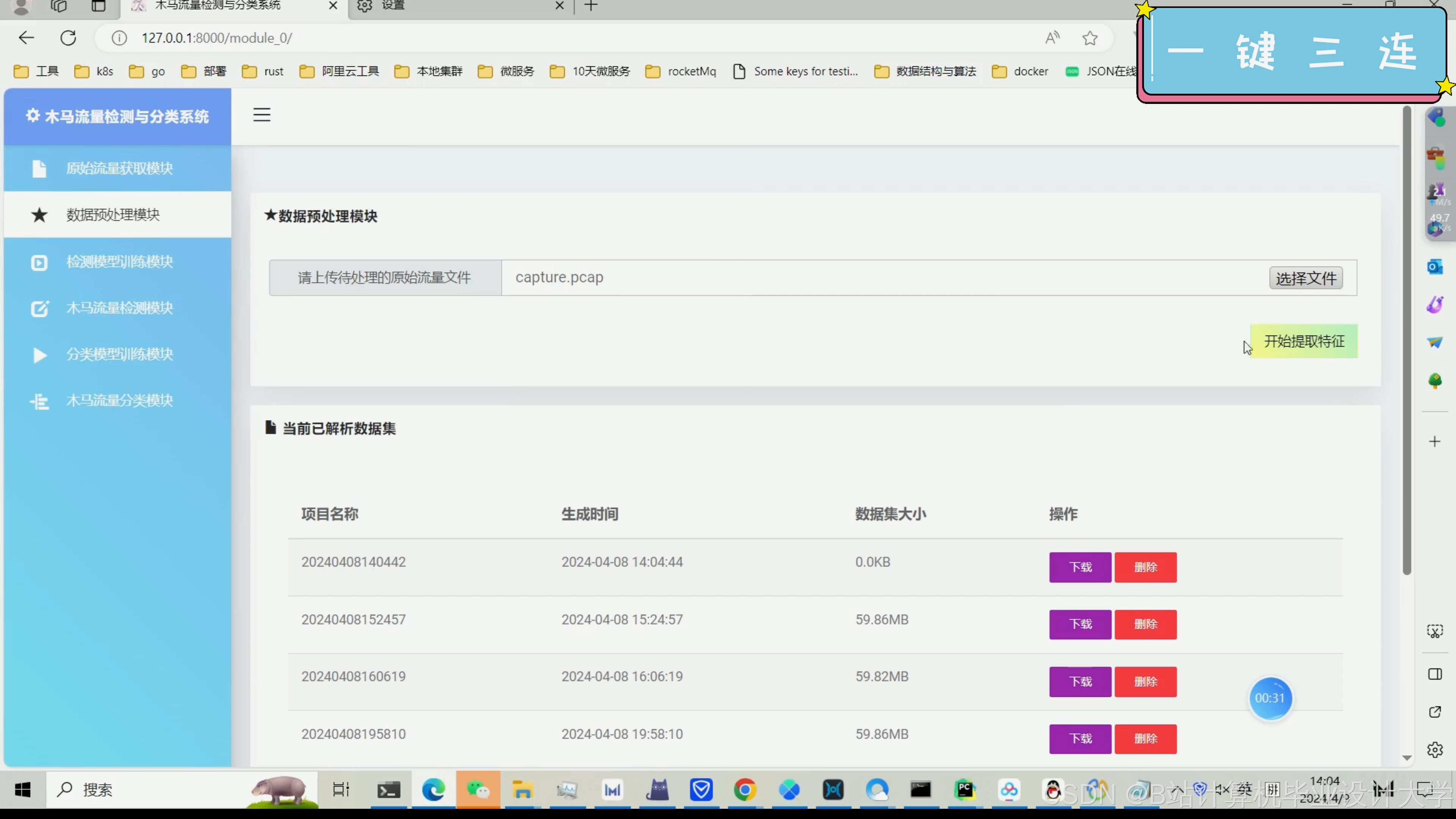

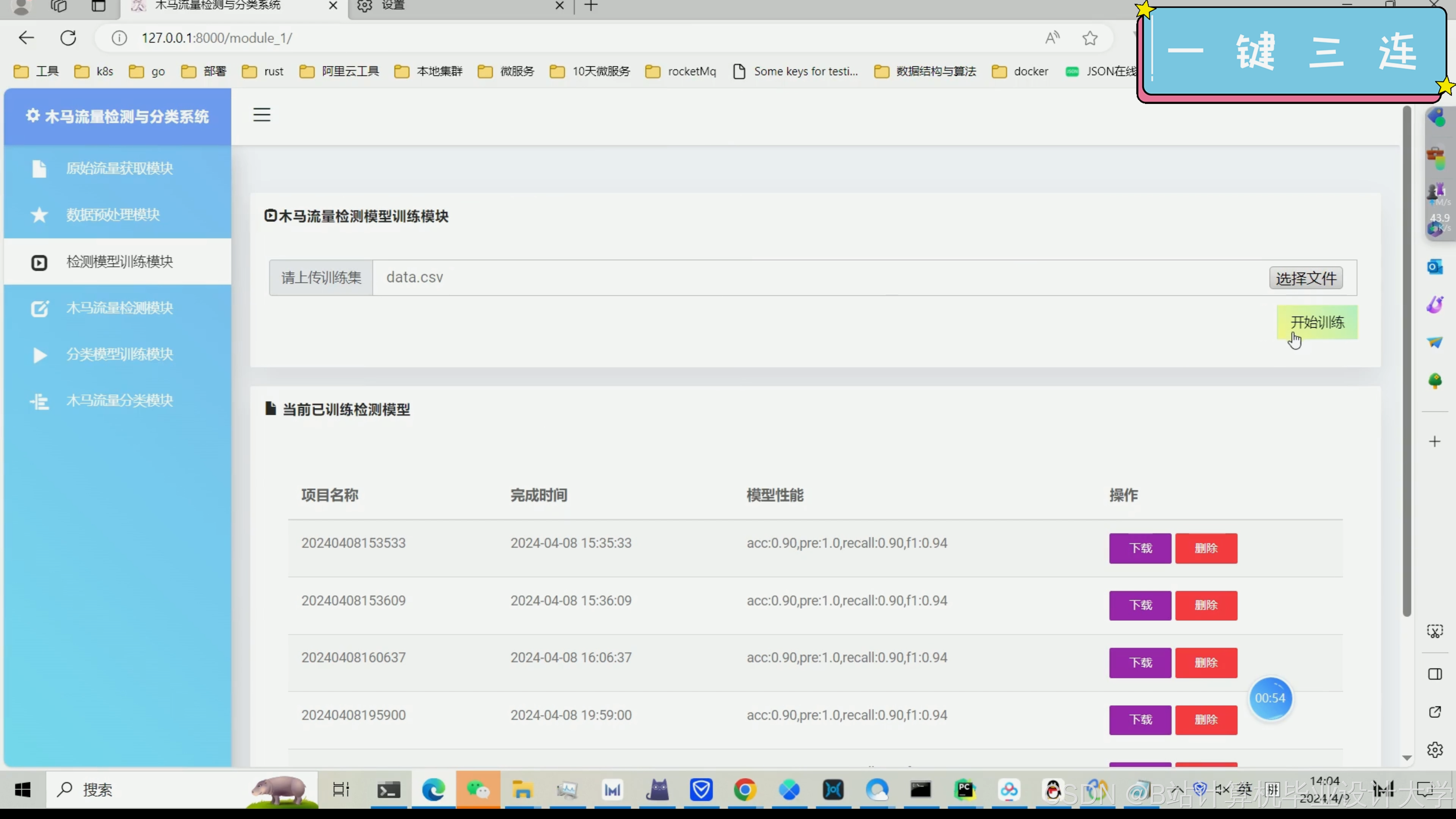







以下是一个基于TensorFlow的恶意木马流量检测与分类系统的核心代码示例。这段代码主要展示了如何使用TensorFlow构建一个简单的神经网络模型来对网络流量数据进行分类。请注意,这只是一个简化示例,实际应用中可能需要更复杂的模型和更多的预处理步骤。
import tensorflow as tf
from tensorflow.keras import layers, models
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
# 假设我们有一个包含网络流量数据的CSV文件
# 数据集应包含特征列(如流量包大小、协议类型等)和目标列(标记为恶意或良性)
data_path = 'network_traffic_data.csv'
# 读取数据
data = pd.read_csv(data_path)
# 分离特征和标签
X = data.drop('label', axis=1).values # 假设标签列为'label'
y = data['label'].values
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 构建神经网络模型
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(X_train.shape[1],)))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid')) # 二分类问题,使用sigmoid激活函数
# 编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy', # 二分类问题使用binary_crossentropy损失函数
metrics=['accuracy'])
# 训练模型
history = model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
# 评估模型
test_loss, test_acc = model.evaluate(X_test, y_test)
print(f'Test accuracy: {test_acc}')
# 保存模型
model.save('malware_traffic_detection_model.h5')
# 使用模型进行预测(示例)
new_data = np.array([[/* 这里填入新的网络流量数据,注意要进行相同的预处理和标准化 */]])
new_data_scaled = scaler.transform(new_data)
prediction = model.predict(new_data_scaled)
print(f'Prediction: {prediction[0][0] > 0.5}') # 根据阈值判断是否为恶意流量注意事项:
-
数据预处理:在实际应用中,数据预处理步骤可能更加复杂,包括处理缺失值、异常值、特征选择、特征缩放等。
-
模型选择:这里的模型是一个简单的全连接神经网络。在实际应用中,可能需要尝试不同的模型架构,如卷积神经网络(CNN)或循环神经网络(RNN),特别是当数据具有时间序列特性时。
-
超参数调优:模型的性能可以通过调整超参数(如层数、神经元数量、学习率等)来优化。
-
数据增强和平衡:如果数据集中恶意和良性流量的比例不平衡,可能需要使用数据增强技术或重采样方法来平衡数据集。
-
模型评估:除了准确率外,还可以考虑其他评估指标,如精确率、召回率、F1分数等,以更全面地评估模型的性能。
-
部署:训练好的模型可以部署到生产环境中,用于实时检测恶意流量。这通常涉及到将模型集成到现有的网络安全框架中,并配置适当的报警和响应机制。