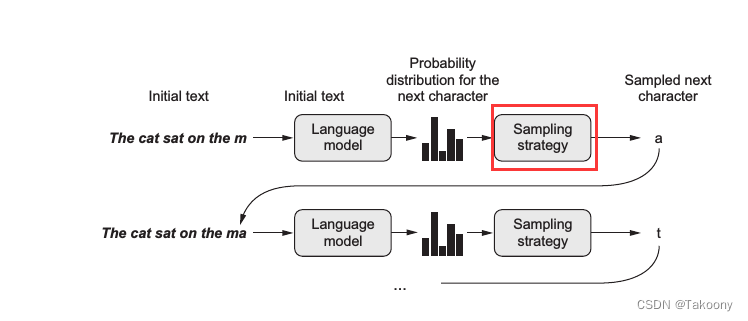
核心就在于采样策略,一图胜千言:
上图中语言模型 (language model) 的预测输出其实是字典中所有词的概率分布,而通常会选择生成其中概率最大的那个词。不过图中出现了一个采样策略 (sampling strategy),这意味着有时候我们可能并不想总是生成概率最大的那个词。设想一个人的行为如果总是严格遵守规律缺乏变化,容易让人觉得乏味;同样一个语言模型若总是按概率最大的生成词,那么就容易变成 XX讲话稿了
解码策略
temperature参数
因此在生成词的过程中引入了采样策略,在最后从概率分布中选择词的过程中引入一定的随机性,这样一些本来不大可能组合在一起的词可能也会被生成,进而生成的文本有时候会变得有趣甚至富有创造性。采样的关键是引入一个temperature参数,用于控制随机性。假设 p(x)为模型输出的原始分布,则加入 temperature 后的新分布为:
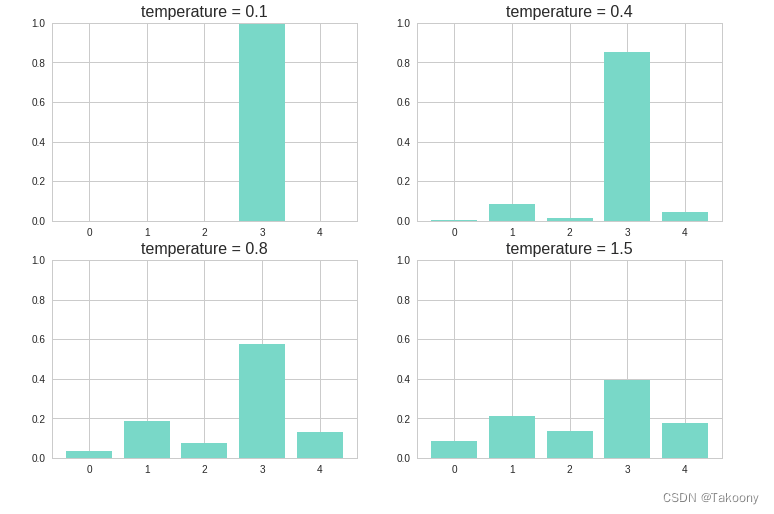
下图展示了不同的 temperature 分别得到的概率分布。temperature 越大,则新的概率分布越均匀,随机性也就越大,越容易生成一些意想不到的词。
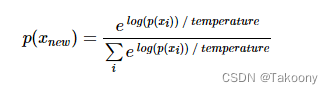
def sample(p, temperature=1.0): # 定义采样策略
distribution = np.log(p) / temperature
distribution = np.exp(distribution)
return distribution / np.sum(distribution)
p = [0.05, 0.2, 0.1, 0.5, 0.15]
for i, t in zip(range(4), [0.1, 0.4, 0.8, 1.5]):
plt.subplot(2, 2, i+1)
plt.bar(np.arange(5), sample(p, t))
plt.title("temperature = %s" %t, size=16)
plt.ylim(0,1)
top-k参数
指的是从n个token中选择概率值最大的top k个token,然后根据这k个token的概率分布进行采样

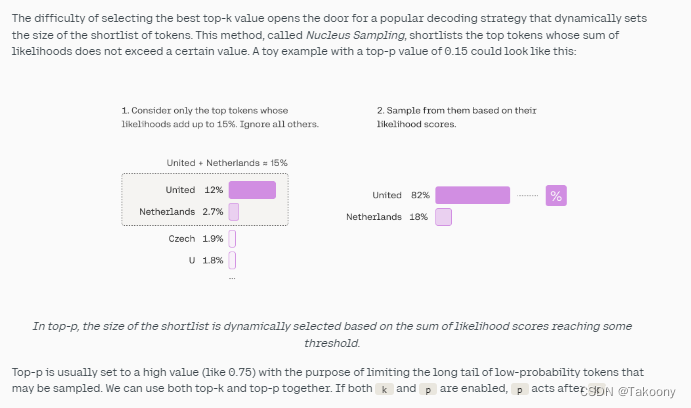
top-p参数
指的是提前设定一个固定概率阈值threshold,从n个token中按概率值排序选择最大的top p个token,这p个token的概率总和不超过threshold
https://www.cnblogs.com/massquantity/p/9511694.html
https://zhuanlan.zhihu.com/p/560847355
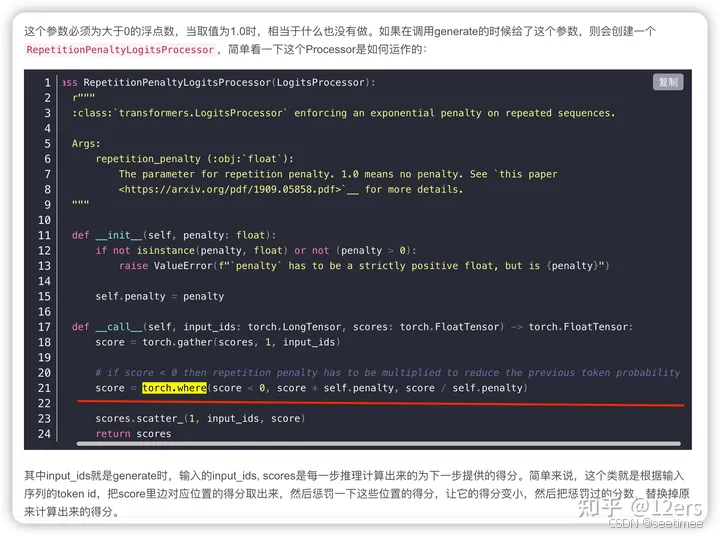
repetition_penalty
方式:在每步时对之前出现过的词的概率做出惩罚,即降低出现过的字的采样概率,让模型趋向于解码出没出现过的词
参数:repetition_penalty(float,取值范围>0)。默认为1,即代表不进行惩罚。值越大,即对重复的字做出更大的惩罚
代码实现逻辑:如果字的概率score<0,则score = score*penalty, 概率会越低; 如果字的概率score>0, 则则score = score/penalty,同样概率也会变低。
整体概览
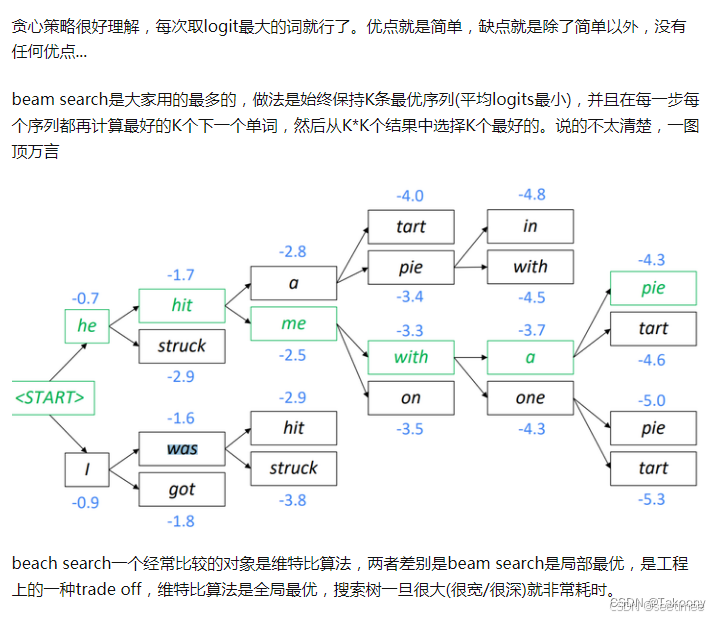
如果需要非常清晰读懂每个参数,需要了解一下与大模型配套的Beam Search算法。
| 参数 | 推荐值 | 简介 | 定义 |
|---|---|---|---|
temperature | 0.95 | 这个值越大生成内容越随机,多样性更好 | 这个参数控制着生成的随机性。较高的温度值(如 1.2)会增加文本的多样性和创造性,但可能会牺牲一些准确性或连贯性。具体地,temperature 会调整概率输出的softmax概率分布,如果 temperature 的值为1,则没有任何调整;如果其值比1大,则会生成更加随机的文本;如果其值比1小,则生成的文本更加保守。 |
top_p | 0.95 | 单步累计采用阈值,越大越多token会被考虑 | 如果累计概率已经超过0.95,剩下的token不会被考虑例如有下面的token及其概率,a:0.9,b:0.03,c:0.03,d:0.015,e... 。则只会采用用abc,因为已经是0.96超过了0.95 |
top_k | 50 | 单步采用token的数量,越大采用token会越多 | 单步中最多考虑的token数量 |
max_length | 512 | 最大采样长度 | 模型生成的文本最大长度,超过的话会做截断,512是参考值,这个依赖于实际情况自己设置 |
num_beams | 1 | beam搜索数量,越大文本质量越高 | 想象一棵树,这个树在每一层的叶子节点数量都是num_beams个,正常模型推理时设置成1就行啦;num_beams=20 表示在每一步时,模型会保留20个最有可能的候选序列,保留方式是累计概率乘积。这有助于生成更加精确和高质量的文本。 |
do_sample | False | 是否概率采样token得到结果 | 当设置为 False 时,模型在生成文本时不会随机采样,而是选择最可能的下一个词。这使得生成的文本更加确定和一致。 |
num_beam_groups | 1 | 分成num_beam_groups组进行搜索 | 这个参数与束搜索相关。它将搜索的束分为不同的组,每个组内部进行搜索。这可以增加文本的多样性。num_beam_groups包含num_beams |
num_return_sequences | 1 | 有多少条返回的结果 | 推理的话设成1就好了 |
output_scores | True | 调试实验时用到 | 设为True时模型在生成文本的每一步都会输出每个词的分数(或概率),这有助于了解模型是如何在不同选项中做出选择的。 |
repetition_penalty | 1 | 重复惩罚值,越大越不会生成重复token | 默认值为1.0,其中较高的值意味着更强的惩罚,生成的文本中将出现更少的重复。如果取值为0,则没有惩罚,生成的文本可能包含大量重复的内容。 |
max_new_tokens | 256 | 模型生成的最大新词数 | 在这里设置为256,意味着每次生成的文本最多包含256个新词。 |
diversity_penalty | 1.5 | 当使用多束搜索时,这个参数惩罚那些在不同束中过于相似的词,以提高生成文本的多样性。 | 设置为1.5意味着对相似性施加较大的惩罚。如果在同一个step中某个beam生成的词和其他beam有相同的,那么就减去这个值作为惩罚,仅在 num_beam_groups 启用时这个值才有效 |
length_penalty | 1 | beam search分数会受到生成序列长度的惩罚 | length_penalty=0.0:无惩罚、length_penalty<0.0:鼓励模型生成长句子、length_penalty>0.0:鼓励模型生成短句子 |
eos_token_id | - | 指定搜索时的结束token | 有时可以提升模型性能,例如同时指定<eos>和<user>为结束符可以让模型在<user>出现时也结束,防止模型停不下来 |
bad_words_ids | - | 禁止生成的token | 帮助解决伦理安全、种族歧视等问题 |
prefix_allowed_tokens_fn | - | 约束模型只能在给定的tokens里生成token | 帮助特定功能的模型提升性能 |
辅助理解案例:
- 贪婪搜索:当
num_beams=1而且do_sample=False时,,每个step生成条件概率最高的词,因此生成单条文本。代码中,调用 greedy_search()方法 - 随机贪婪搜索:当
num_beams=1且do_sample=True时,每个单步时会根据模型输出的概率进行采用,而不是选条件概率最高的词,增加多样性。调用 sample() 方法 - 贪婪柱搜索:当
num_beams>1且do_sample=False时,做一个num_beams的柱搜索,每次都是贪婪选择top N个柱。调用 beam_search() 方法 - 采样柱搜索:当
num_beams>1且do_sample=True时,相当于每次不再是贪婪选择top N个柱,而是加了一些采样。调用 beam_sample() 方法 - 多组柱搜索搜索:当 num_beams>1 且 num_beam_groups>1 时,多组柱搜索同时进行,最后返回
num_beam_groups个结果。调用 group_beam_search() 方法