一、软件介绍
文末提供下载
目前,IPEX-LLM 仅在 Windows 上提供 Ollama 可移植 zip。
ipex-llm 是一个将大语言模型高效地运行于 Intel GPU (如搭载集成显卡的个人电脑,Arc 独立显卡、Flex 及 Max 数据中心 GPU 等)、NPU 和 CPU 上的大模型 XPU 加速库。
ipex-llm可以与 llama.cpp, Ollama, HuggingFace transformers, LangChain, LlamaIndex, vLLM, Text-Generation-WebUI, DeepSpeed-AutoTP, FastChat, Axolotl, HuggingFace PEFT, HuggingFace TRL, AutoGen, ModeScope 等无缝衔接。
70+ 模型已经在 ipex-llm 上得到优化和验证(如 Llama, Phi, Mistral, Mixtral, Whisper, DeepSeek, Qwen, ChatGLM, MiniCPM, Qwen-VL, MiniCPM-V 等), 以获得先进的 大模型算法优化, XPU 加速 以及 低比特(FP8FP8/FP6/FP4/INT4) 支持;
二、快速入门
1、使用
Arc B580: 在 Intel Arc B580 GPU 上运行 ipex-llm(包括 Ollama, llama.cpp, PyTorch, HuggingFace 等)
NPU: 在 Intel NPU 上运行 ipex-llm(支持 Python 和 C++)
llama.cpp: 在 Intel GPU 上运行 llama.cpp (使用 ipex-llm 的 C++ 接口)
Ollama: 在 Intel GPU 上运行 ollama (使用 ipex-llm 的 C++ 接口)
PyTorch/HuggingFace: 使用 Windows 和 Linux 在 Intel GPU 上运行 PyTorch、HuggingFace、LangChain、LlamaIndex 等 (使用 ipex-llm 的 Python 接口)
vLLM: 在 Intel GPU 和 CPU 上使用 ipex-llm 运行 vLLM
FastChat: 在 Intel GPU 和 CPU 上使用 ipex-llm 运行 FastChat 服务
Serving on multiple Intel GPUs: 利用 DeepSpeed AutoTP 和 FastAPI 在 多个 Intel GPU 上运行 ipex-llm 推理服务
Text-Generation-WebUI: 使用 ipex-llm 运行 oobabooga WebUI
Axolotl: 使用 Axolotl 和 ipex-llm 进行 LLM 微调
Benchmarking: 在 Intel GPU 和 CPU 上运行性能基准测试(延迟和吞吐量)
2、Docker
GPU Inference in C++: 在 Intel GPU 上使用 ipex-llm 运行 llama.cpp, ollama等
GPU Inference in Python : 在 Intel GPU 上使用 ipex-llm 运行 HuggingFace transformers, LangChain, LlamaIndex, ModelScope,等
vLLM on GPU: 在 Intel GPU 上使用 ipex-llm 运行 vLLM 推理服务
vLLM on CPU: 在 Intel CPU 上使用 ipex-llm 运行 vLLM 推理服务
FastChat on GPU: 在 Intel GPU 上使用 ipex-llm 运行 FastChat 推理服务
VSCode on GPU: 在 Intel GPU 上使用 VSCode 开发并运行基于 Python 的 ipex-llm 应用
3、应用
GraphRAG: 基于 ipex-llm 使用本地 LLM 运行 Microsoft 的 GraphRAG
RAGFlow: 基于 ipex-llm 运行 RAGFlow (一个开源的 RAG 引擎)
LangChain-Chatchat: 基于 ipex-llm 运行 LangChain-Chatchat (使用 RAG pipline 的知识问答库)
Coding copilot: 基于 ipex-llm 运行 Continue (VSCode 里的编码智能助手)
Open WebUI: 基于 ipex-llm 运行 Open WebUI
PrivateGPT: 基于 ipex-llm 运行 PrivateGPT 与文档进行交互
Dify platform: 在Dify(一款开源的大语言模型应用开发平台) 里接入 ipex-llm 加速本地 LLM
三、代码示例
1、低比特推理
INT4 inference: 在 Intel GPU 和 CPU 上进行 INT4 LLM 推理
FP8/FP6/FP4 inference: 在 Intel GPU 上进行 FP8,FP6 和 FP4 LLM 推理
INT8 inference: 在 Intel GPU 和 CPU 上进行 INT8 LLM 推理
INT2 inference: 在 Intel GPU 上进行 INT2 LLM 推理 (基于 llama.cpp IQ2 机制)
2、FP16/BF16 推理
在 Intel GPU 上进行 FP16 LLM 推理(并使用 self-speculative decoding 优化)
在 Intel CPU 上进行 BF16 LLM 推理(并使用 self-speculative decoding 优化)
3、分布式推理
在 Intel GPU 上进行 流水线并行 推理
在 Intel GPU 上进行 DeepSpeed AutoTP 推理
4、保存和加载
Low-bit models: 保存和加载 ipex-llm 低比特模型 (INT4/FP4/FP6/INT8/FP8/FP16/etc.)
GGUF: 直接将 GGUF 模型加载到 ipex-llm 中
AWQ: 直接将 AWQ 模型加载到 ipex-llm 中
GPTQ: 直接将 GPTQ 模型加载到 ipex-llm 中
5、微调
在 Intel GPU 进行 LLM 微调,包括 LoRA,QLoRA,DPO,QA-LoRA 和 ReLoRA
在 Intel CPU 进行 QLoRA 微调
四、安装
先决条件
检查您的 GPU 驱动程序版本,并在需要时进行更新:
对于 Intel Core Ultra 处理器(系列 2)或 Intel Arc B 系列 GPU,我们建议您将 GPU 驱动程序更新到最新版本
对于其他 Intel iGPU/dGPU,我们建议使用 GPU 驱动程序版本 32.0.101.6078
第 1 步:下载并解压缩
(文末提供下载) IPEX-LLM Ollama 便携式 zip。
然后,将 zip 文件解压缩到文件夹中。
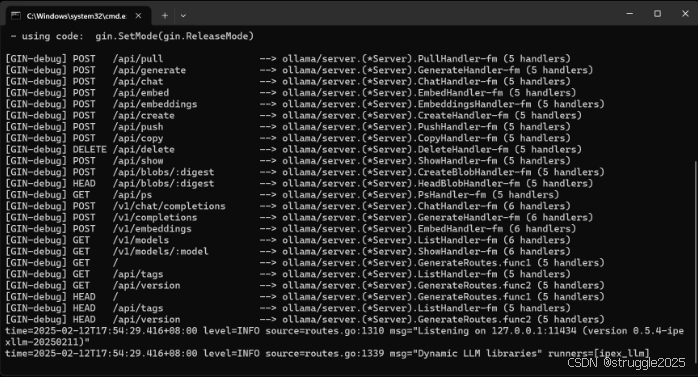
第 2 步:启动 Ollama Serve
start-ollama.bat 双击解压缩的文件夹以启动 Ollama 服务。然后会弹出一个窗口,如下所示:
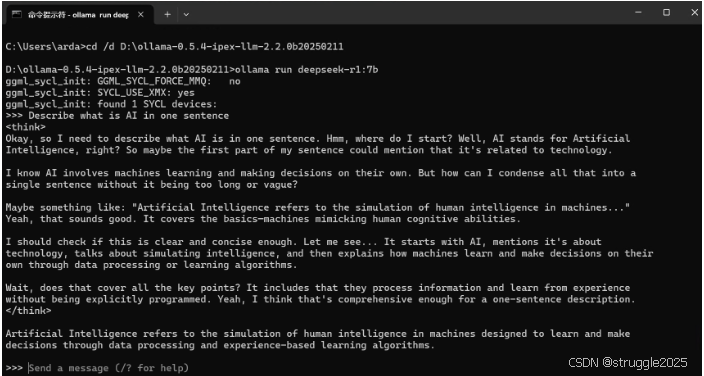
第 3 步:运行 Ollama
然后,您可以使用 Ollama 在 Intel GPU 上运行LLMs,如下所示:
- 打开“命令提示符”(cmd),然后通过
cd /d PATH\TO\EXTRACTED\FOLDER - 在 “Command Prompt” 中运行
ollama run deepseek-r1:7b(您可以使用任何其他模型)
五、软件下载
github作者地址:https://github.com/intel/ipex-llm?tab=readme-ov-file
本文信息图片来源于作者github地址