系列文章目录
一、Spark架构设计概述
二、Spark核心组件
三、Spark架构设计举例分析
四、Job调度流程详解
五、Spark交互流程详解
文章目录
前言
Apache Spark是一个快速、通用、基于内存的分布式计算引擎,专为大规模数据处理而设计。其架构设计体现了高度的模块化和可扩展性,支持多种数据处理模式,包括批处理、实时流处理、交互式查询、机器学习和图计算等。以下将详细介绍Spark的架构设计,并结合具体例子进行分析。
一、Spark架构设计概述
Spark的架构设计遵循主从(Master-Slave)架构模式,主要由以下几部分组成:
1. 集群资源管理器(Cluster Manager)
- 负责集群资源的分配和管理,包括CPU、内存等资源。根据不同的部署模式,Cluster Manager可以是Spark自带的Standalone模式,也可以是YARN、Mesos等第三方资源管理器。
2. 工作节点(Worker Node)
- 执行提交的任务,通过注册机制向Cluster Manager汇报自身的资源使用情况。在Master的指示下,Worker Node会创建并启动Executor进程,用于执行具体的计算任务。
3. 驱动程序(Driver Program/Driver)
- 运行应用程序的main()函数,负责创建SparkContext对象,并与Cluster Manager和Executor进行通信,以协调任务的执行。
- 执行器(Executor):运行在Worker Node上的进程,负责执行Driver分配的任务,并将结果返回给Driver。Executor是Spark中真正的计算单元,它负责Task的运行并将结果数据保存到内存或磁盘上。
二、Spark核心组件
Spark基于Spark Core建立了多个核心组件,每个组件都提供了特定的数据处理能力:
1. Spark Core
- 基础设施:包括SparkConf(配置信息)、SparkContext(Spark上下文)、Spark RPC(远程过程调用)、ListenerBus(事件总线)、MetricsSystem(度量系统)、SparkEnv(环境变量)等,为Spark的各种组件提供基础支持。
- 存储系统:Spark的存储系统优先考虑在内存中存储数据,当内存不足时才会将数据写入磁盘。这种内存优先的存储策略使得Spark在处理大规模数据时具有极高的性能。
- 调度系统:由DAGScheduler和TaskScheduler组成,负责任务的调度和执行。DAGScheduler负责将用户程序转换为DAG图,并根据依赖关系划分Stage和Task;TaskScheduler则负责按照调度算法对Task进行批量调度。
- 计算引擎:由内存管理器、任务管理器、Task Shuffle管理器等组成,负责具体的计算任务执行。
2. Spark SQL
- 提供基于SQL的数据处理方式,支持结构化数据的查询和分析。Spark SQL可以将结构化数据(如JSON、CSV、Parquet等)转换为RDD或DataFrame,并支持使用Hive元数据和SQL查询。
3. Spark Streaming
- 提供流处理能力,支持从Kafka、Flume、Kinesis、TCP等多种数据源实时获取数据流,并将其转换为可供分析和存储的批处理数据。Spark Streaming使用DStream(离散流)作为数据流的抽象,并支持一系列的转换操作。
4. Spark MLlib
- 提供机器学习库,包括统计、分类、回归、聚类等多种机器学习算法的实现。Spark MLlib的分布式计算能力使得在大规模数据上进行机器学习任务成为可能。
5. Spark GraphX
- 提供图计算库,支持对大规模图结构数据进行处理和分析。GraphX通过Pregel提供的API可以快速解决图计算中的常见问题,如社交网络分析、网络拓扑分析等。
三、Spark架构设计举例分析
- 以Spark Standalone模式为例,我们可以详细分析Spark的架构设计如何支持数据处理任务的执行:
- 集群启动:
- 在Standalone模式下,集群由一个主节点(Master)和多个工作节点(Worker)组成。主节点负责管理集群资源并分配任务给工作节点;工作节点则负责执行具体的任务。
- 集群启动时,Master节点会启动并监听来自Worker节点的注册请求。Worker节点在启动时向Master注册,并报告自身的资源情况(如CPU、内存等)。
- 任务提交:
- 用户通过Driver程序提交Spark作业到集群。Driver程序首先创建SparkContext对象,并连接到Master节点以请求资源。
- Master节点根据集群的资源情况和作业的资源需求,为Driver分配资源,并启动Executor进程。Executor进程是运行在Worker节点上的,用于执行具体的计算任务。
- 任务执行:
- Driver程序将作业划分为多个Task,并通过Executor的RPC接口将Task发送到Executor上执行。
- Executor接收到Task后,会在本地启动线程来并行执行Task。执行过程中,Executor会从存储系统(如HDFS)中加载数据,进行计算,并将结果返回给Driver。
Driver收集所有Executor的执行结果,并进行汇总和处理,最终将结果输出给用户。
- 容错与恢复:
- Spark通过RDD的容错机制来保证数据的可靠性和作业的可恢复性。RDD具有可容错性,当某个节点发生故障
四、Job调度流程详解

-
1- Driver进程启动后,底层PY4J创建SparkContext顶级对象。在创建该对象的过程中,还会创建另外两个对象,分别是: DAGScheduler和TaskScheduler
DAGScheduler: DAG调度器。将Job任务形成DAG有向无环图和划分Stage的阶段
TaskScheduler: Task调度器。将Task线程分配给到具体的Executor执行 -
2- 一个Spark程序遇到一个Action算子就会触发产生一个Job任务。SparkContext将Job任务给到DAG调度器,拿到Job任务后,会将Job任务形成DAG有向无环图和划分Stage的阶段。并且会确定每个Stage阶段有多少个Task线程,会将众多的Task线程放到TaskSet的集合中。DAG调度器将TaskSet集合给到Task调度器
-
3- Task调度器拿到TaskSet集合以后,将Task分配给到给到具体的Executor执行。底层是基于SchedulerBackend调度队列来实现的。
-
4- Executor开始执行任务。并且Driver会监控各个Executor的执行状态,直到所有的Executor执行完成,就认为任务运行结束
-
5- 后续过程和之前一样
五、Spark交互流程详解
1、client_Spark集群
driver任务: Driver进程中负责资源申请的工作并且负责创建SparkContext对象的代码映射为Java对象,进行创建任务的分配、任务的管理工作。
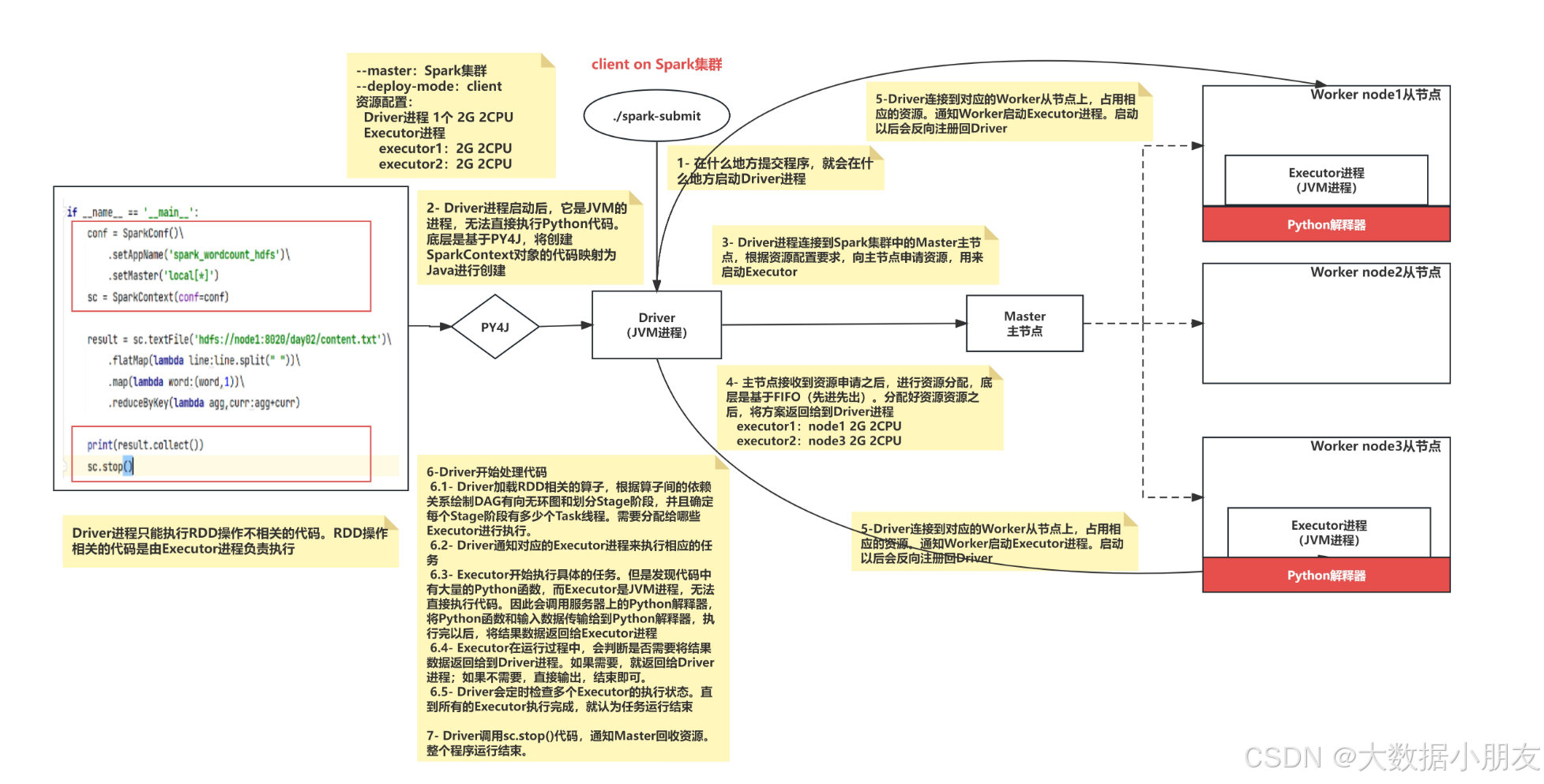
1- submit提交任务到主节点Master
2- 在提交任务的那个客户端上启动Driver进程
3- Driver进程启动后,执行main函数,首先创建SparkContext对象。底层是基于PY4J,将创建SparkContext对象的代码映射为Java进行创建
4- Driver进程连接到Spark集群中的Master主节点,根据资源配置要求,向主节点申请资源,用来启动Executor
5- 主节点接收到资源申请之后,进行资源分配,底层是基于FIFO(先进先出)。分配好资源资源之后,将方案返回给到Driver进程
executor1:node1 2G 2CPU
executor2:node3 2G 2CPU
6-Driver连接到对应的Worker从节点上,占用相应的资源。通知Worker启动Executor进程。启动以后会反向注册回Driver
7-Driver开始处理代码
7.1- Driver加载RDD相关的算子,根据算子间的依赖关系绘制DAG有向无环图和划分Stage阶段,并且确定每个Stage阶段有多少个Task线程。需要分配给哪些Executor进行执行。
7.2- Driver通知对应的Executor进程来执行相应的任务
7.3- Executor开始执行具体的任务。但是发现代码中有大量的Python函数,而Executor是JVM进程,无法直接执行代码。因此会调用服务器上的Python解释器,将Python函数和输入数据传输给到Python解释器,执行完以后,将结果数据返回给Executor进程
7.4- Executor在运行过程中,会判断是否需要将结果数据返回给到Driver进程。如果需要,就返回给Driver进程;如果不需要,直接输出,结束即可。
7.5- Driver会定时检查多个Executor的执行状态。直到所有的Executor执行完成,就认为任务运行结束
8- Driver调用sc.stop()代码,通知Master回收资源。整个程序运行结束。
2、cluster_Spark集群
driver任务: Driver进程中负责资源申请的工作并且负责创建SparkContext对象的代码映射为Java对象,进行创建任务的分配、任务的管理工作。
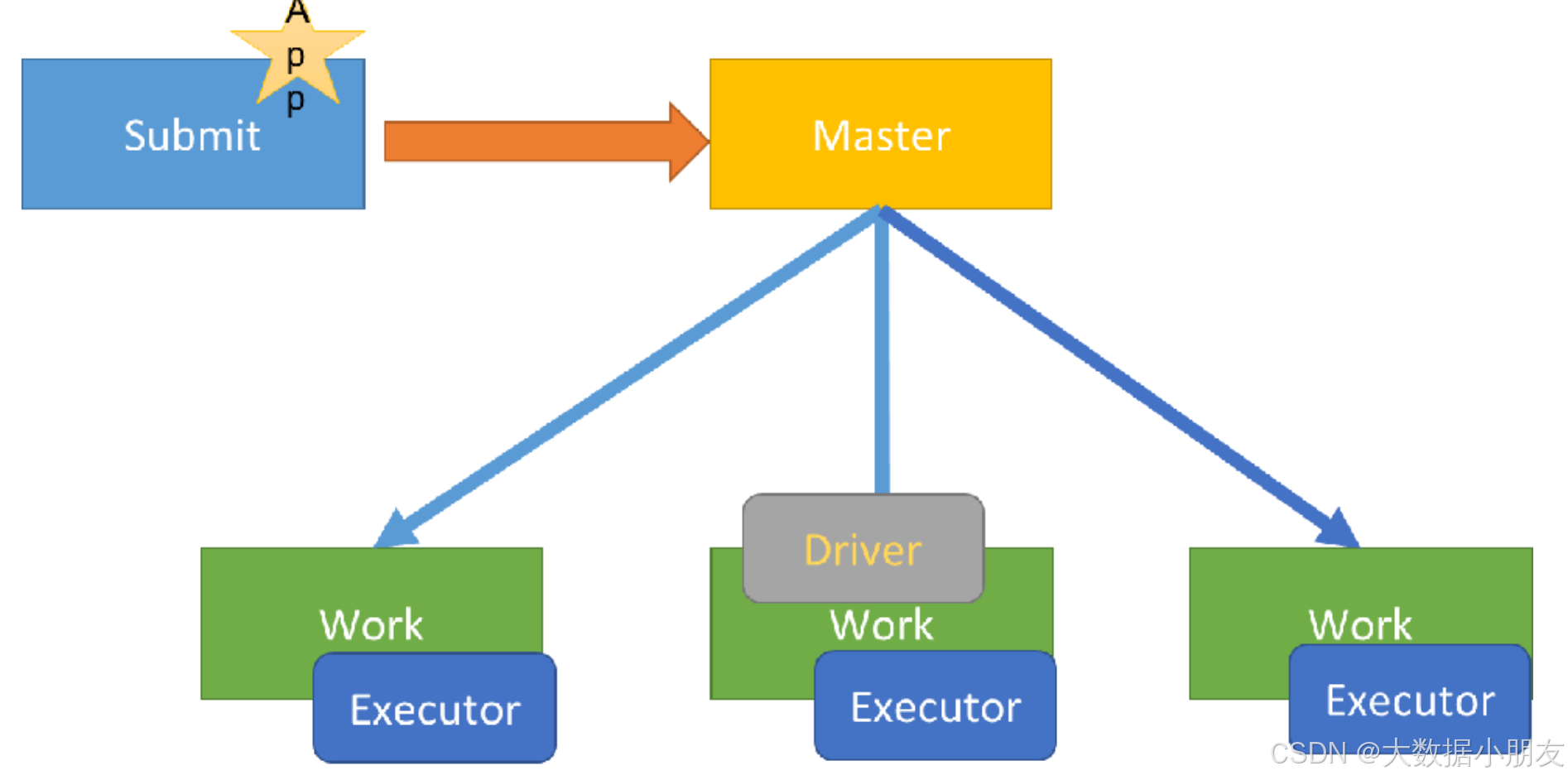
和client on spark集群的区别点: Driver进程不是运行在提交任务的那台机器上了,而是在Spark集群中随机选择一个Worker从节点来启动和运行Driver进程
1- submit提交任务到主节点Master
2- Master主节点接收到任务信息以后,根据Driver的资源配置要求,在集群中随机选择(在资源充沛的众多从节点中随机选择)一个Worker从节点来启动和运行Driver进程
3- Driver进程启动以后,执行main函数,首先创建SparkContext对象。底层是基于PY4J,将创建SparkContext对象的代码映射为Java进行创建
4- Driver进程连接到Spark集群中的Master主节点,根据资源配置要求,向主节点申请资源,用来启动Executor
5- 主节点接收到资源申请之后,进行资源分配,底层是基于FIFO(先进先出)。分配好资源资源之后,将方案返回给到Driver进程
executor1:node1 2G 2CPU
executor2:node3 2G 2CPU
6-Driver连接到对应的Worker从节点上,占用相应的资源。通知Worker启动Executor进程。启动以后会反向注册回Driver
7-Driver开始处理代码
7.1- Driver加载RDD相关的算子,根据算子间的依赖关系绘制DAG有向无环图和划分Stage阶段,并且确定每个Stage阶段有多少个Task线程。需要分配给哪些Executor进行执行。
7.2- Driver通知对应的Executor进程来执行相应的任务
7.3- Executor开始执行具体的任务。但是发现代码中有大量的Python函数,而Executor是JVM进程,无法直接执行代码。因此会调用服务器上的Python解释器,将Python函数和输入数据传输给到Python解释器,执行完以后,将结果数据返回给Executor进程
7.4- Executor在运行过程中,会判断是否需要将结果数据返回给到Driver进程。如果需要,就返回给Driver进程;如果不需要,直接输出,结束即可。
7.5- Driver会定时检查多个Executor的执行状态。直到所有的Executor执行完成,就认为任务运行结束
8- Driver调用sc.stop()代码,通知Master回收资源。整个程序运行结束。
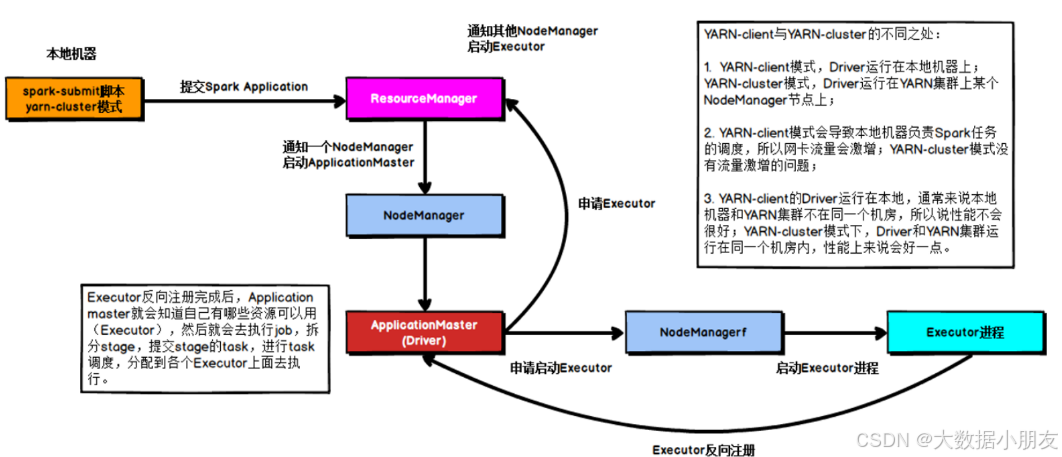
3、client on Yarn集群
区别点: 将Driver进程中负责资源申请的工作,转交给到Yarn的ApplicationMaster来负责。Driver负责创建SparkContext对象的代码映射为Java对象,进行创建任务的分配、任务的管理工作。
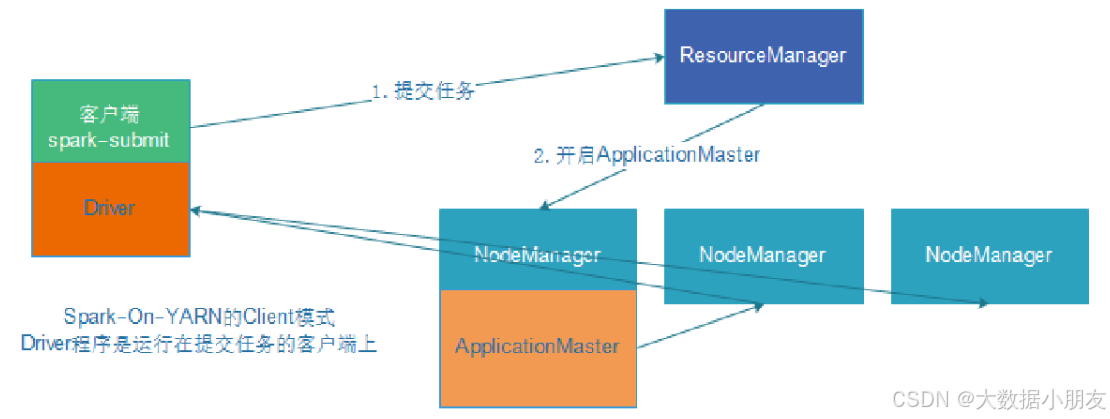
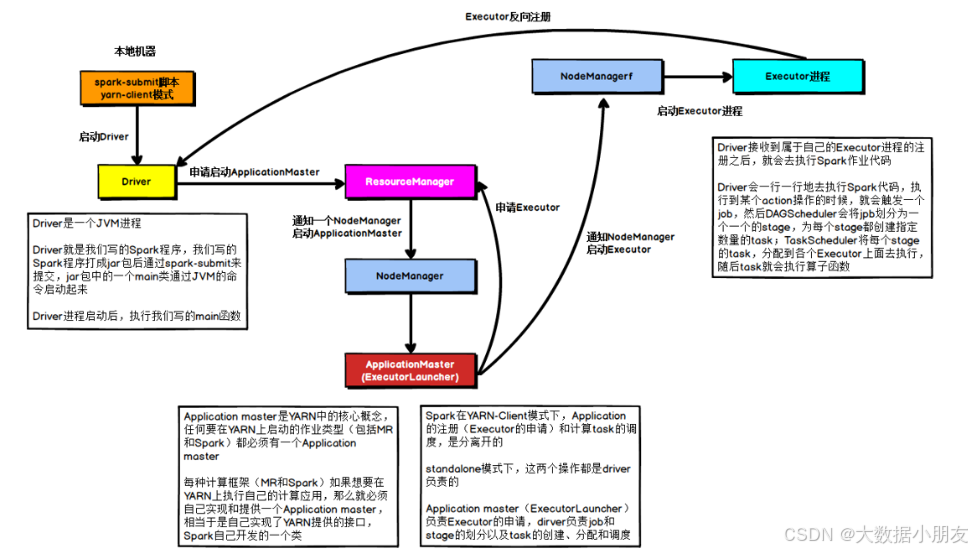
1- 首先会在提交的节点启动一个Driver进程
2- Driver进程启动以后,执行main函数,首先创建SparkContext对象。底层是基于PY4J,将创建SparkContext对象的代码映射为Java进行创建
3- 连接Yarn集群的主节点(ResourceManager),将需要申请的资源封装为一个任务,提交给到Yarn的主节点。主节点收到任务以后,首先随机选择一个从节点(NodeManager)启动ApplicationMaster
4- 当ApplicationMaster启动之后,会和Yarn的主节点建立心跳机制,告知已经启动成功。启动成功以后,就进行资源的申请工作,将需要申请的资源通过心跳包的形式发送给到主节点。主节点接收到资源申请后,开始进行资源分配工作,底层是基于资源调度器来实现(默认为Capacity容量调度器)。当主节点将资源分配完成以后,等待ApplicationMaster来拉取资源。ApplicationMaster会定时的通过心跳的方式询问主节点是否已经准备好了资源。一旦发现准备好了,就会立即拉取对应的资源信息。
5- ApplicationMaster根据拉取到的资源信息,连接到对应的从节点。占用相应的资源,通知从节点启动Executor进程。从节点启动完Executor之后,会反向注册回Driver进程
6-Driver开始处理代码
6.1- Driver加载RDD相关的算子,根据算子间的依赖关系绘制DAG有向无环图和划分Stage阶段,并且确定每个Stage阶段有多少个Task线程。需要分配给哪些Executor进行执行。
6.2- Driver通知对应的Executor进程来执行相应的任务
6.3- Executor开始执行具体的任务。但是发现代码中有大量的Python函数,而Executor是JVM进程,无法直接执行代码。因此会调用服务器上的Python解释器,将Python函数和输入数据传输给到Python解释器,执行完以后,将结果数据返回给Executor进程
6.4- Executor在运行过程中,会判断是否需要将结果数据返回给到Driver进程。如果需要,就返回给Driver进程;如果不需要,直接输出,结束即可。
6.5- Driver会定时检查多个Executor的执行状态。直到所有的Executor执行完成,就认为任务运行结束。同时ApplicationMaster也会接收到各个节点的执行完成状态,然后通知主节点。任务执行完成了,主节点回收资源,关闭ApplicationMaster,并且通知Driver。
7- Driver执行sc.stop()代码。Driver进程退出
4、cluster on Yarn集群
区别点: 在集群模式下,Driver进程的功能和ApplicationMaster的功能(角色)合二为一了。Driver就是ApplicationMaster,ApplicationMaster就是Driver。既要负责资源申请,又要负责任务的分配和管理。
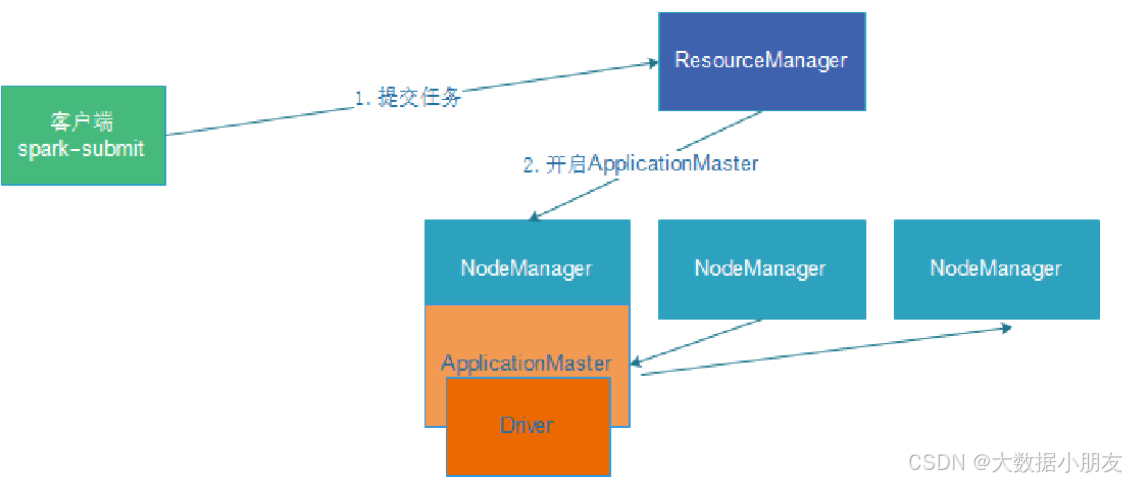
1- 首先会将任务提交给Yarn集群的主节点(ResourceManager)
2- ResourceManager接收到任务信息后,根据Driver(ApplicationMaster)的资源配置信息要求,选择一个
nodeManager节点(有资源的,如果都有随机)来启动Driver(ApplicationMaster)程序,并且占用相对应资源
3- Driver(ApplicationMaster)启动后,执行main函数。首先创建SparkContext对象(底层是基于PY4J,识
别python的构建方式,将其映射为Java代码)。创建成功后,会向ResourceManager进行建立心跳机制,告知已经
启动成功了
4- 根据executor的资源配置要求,向ResourceManager通过心跳的方式申请资源,用于启动executor(提交的任
务的时候,可以自定义资源信息)
5- ResourceManager接收到资源申请后,根据申请要求,进行分配资源。底层是基于资源调度器来资源分配(默认
为Capacity容量调度)。然后将分配好的资源准备好,等待Driver(ApplicationMaster)拉取操作
executor1: node1 2个CPU 2GB内存
executor2: node3 2个CPU 2GB内存
6- Driver(ApplicationMaster)会定时询问是否准备好资源,一旦准备好,立即获取。根据资源信息连接对应的
节点,通知nodeManager启动executor,并占用相应资源。nodeManager对应的executor启动完成后,反向注册
回给Driver(ApplicationMaster)程序(已经启动完成)
7- Driver(ApplicationMaster)开始处理代码:
7.1 首先会加载所有的RDD相关的API(算子),基于算子之间的依赖关系,形成DAG执行流程图,划分stage阶
段,并且确定每个阶段应该运行多少个线程以及每个线程应该交给哪个executor来运行(任务分配)
7.2 Driver(ApplicationMaster)程序通知对应的executor程序, 来执行具体的任务
7.3 Executor接收到任务信息后, 启动线程, 开始执行处理即可: executor在执行的时候, 由于RDD代
码中有大量的Python的函数,Executor是一个JVM程序 ,无法解析Python函数, 此时会调用Python解析器,执
行函数, 并将函数结果返回给Executor
7.4 Executor在运行过程中,如果发现最终的结果需要返回给Driver(ApplicationMaster),直接返回
Driver(ApplicationMaster),如果不需要返回,直接输出 结束即可
7.5 Driver(ApplicationMaster)程序监听这个executor执行的状态信息,当Executor都执行完成后,
Driver(ApplicationMaster)认为任务运行完成了
8- 当任务执行完成后,Driver执行sc.stop()通知ResourceManager执行完成,ResourceManager回收资源,
Driver程序退出即可