1.数据下载(不用python)
进入官网ICESat-2 Product Overviews | National Snow and Ice Data Center (nsidc.org)
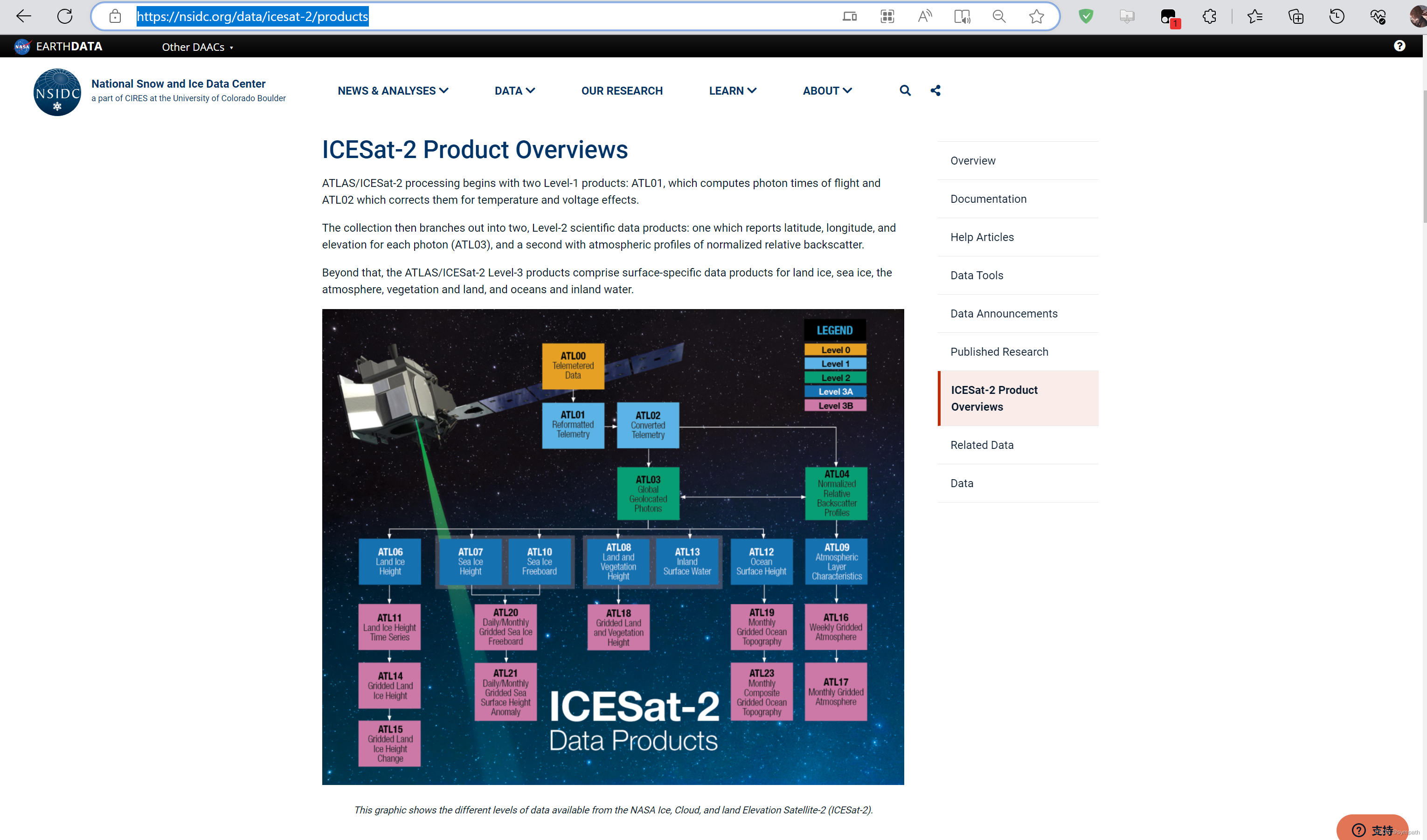
下滑找到你需要的产品,以下以ATL13为例

点击进入,找到Data Access Tool,点击get
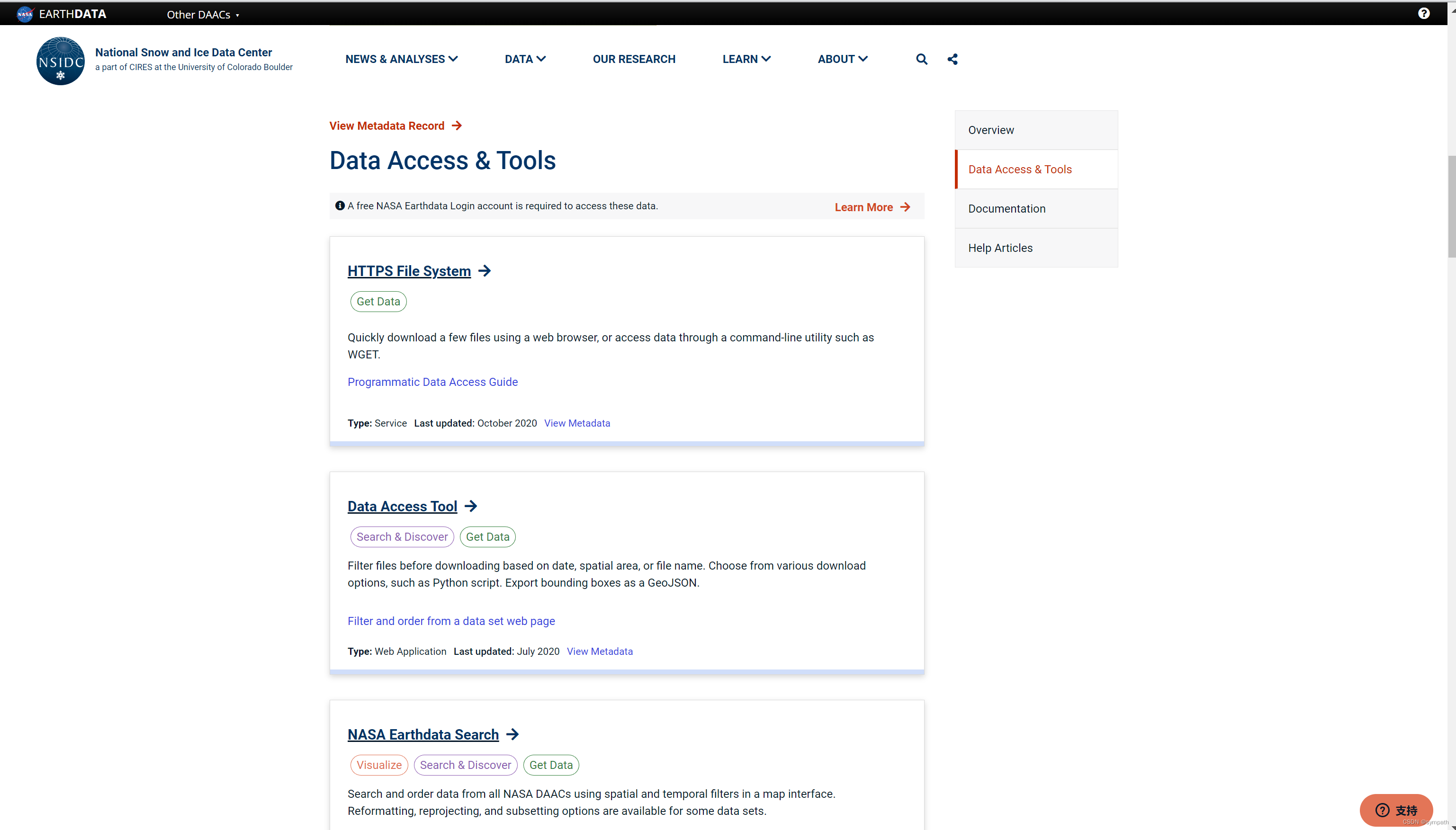
登录自己的 Earthdade账号
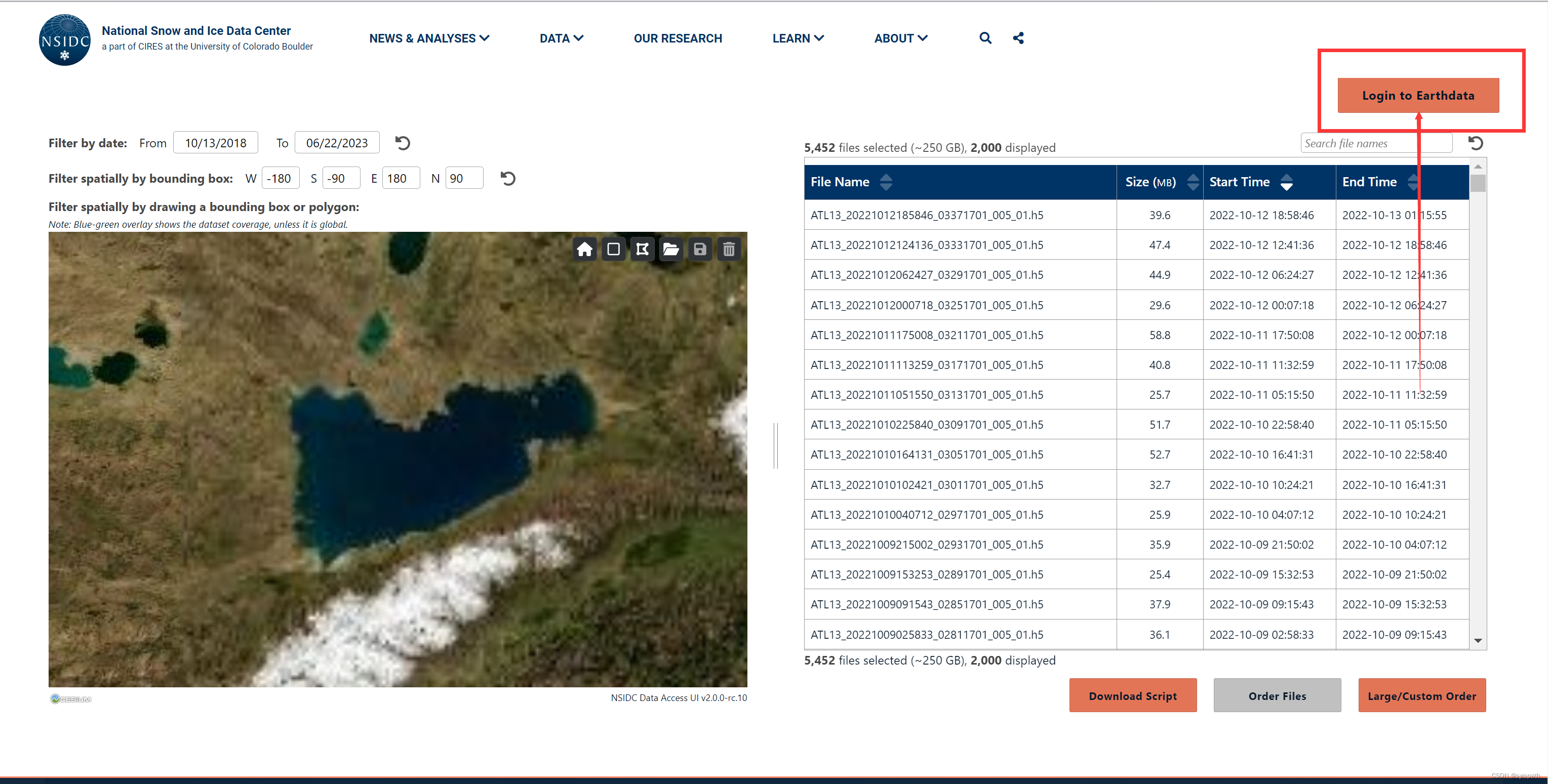
准备好自己研究区域 的shp矢量图,没有的话也可以自己圈画,
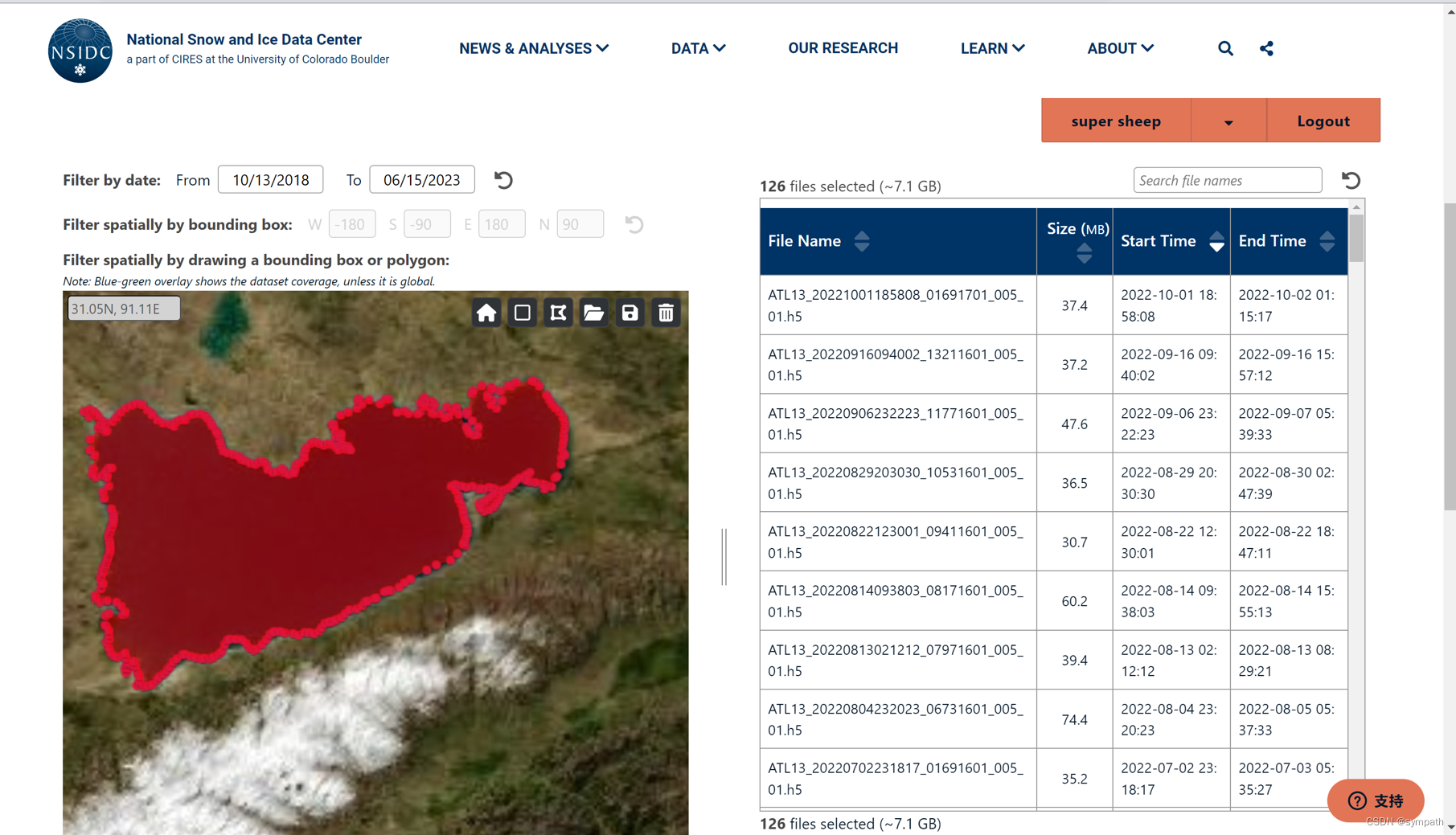
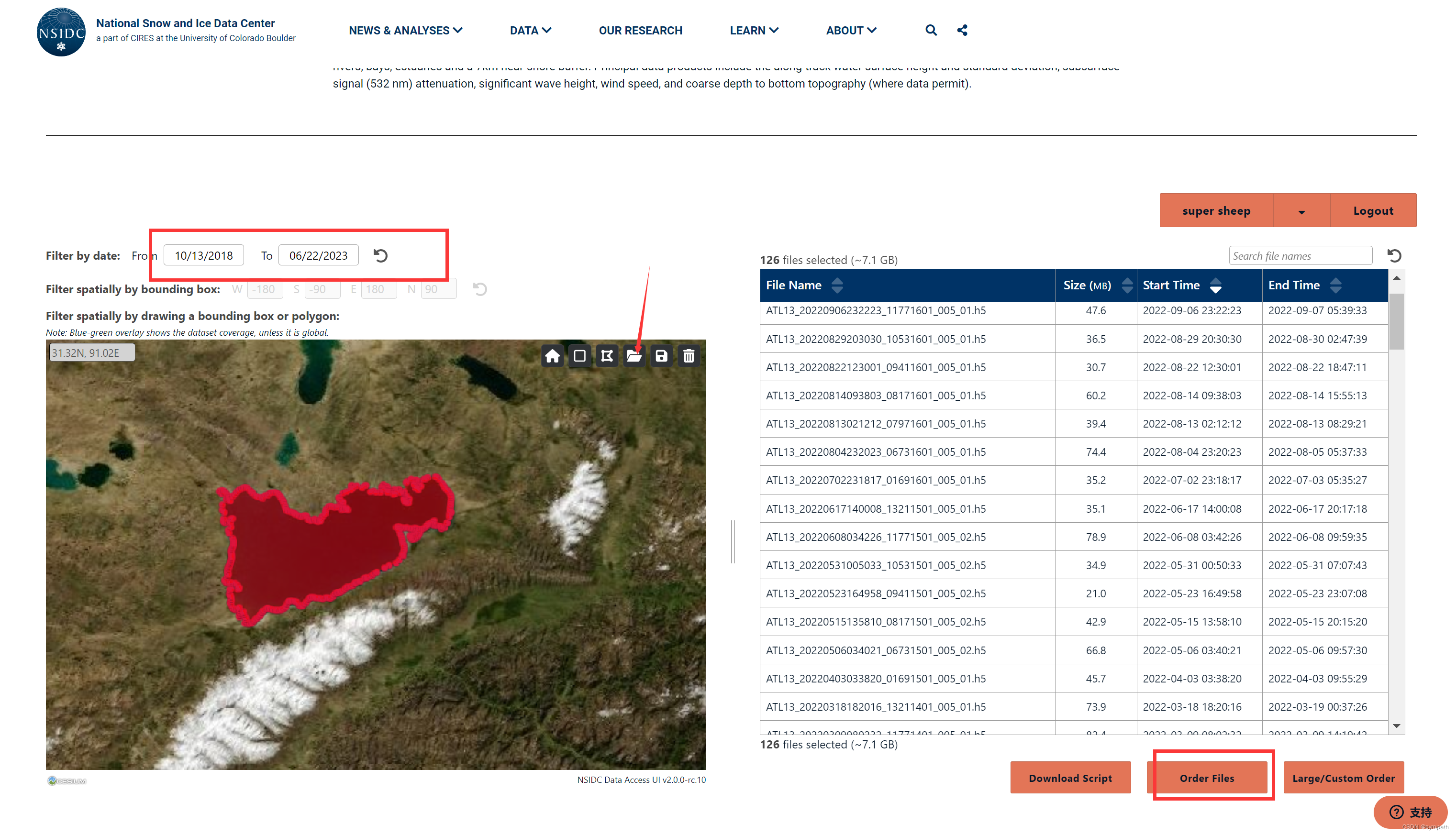
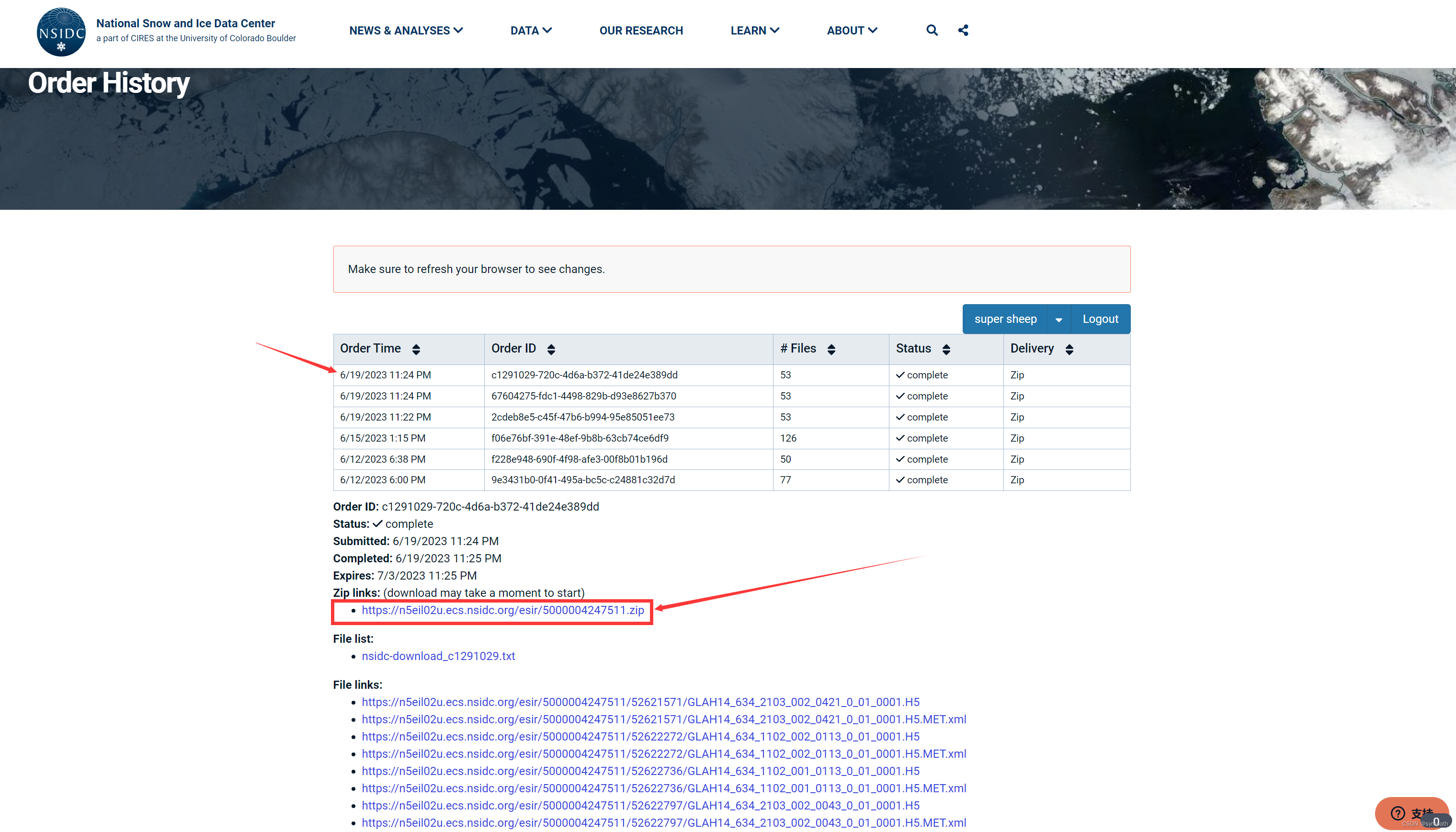
点击order之后点击两次ok,然后再这个网址找到你的订单(也会给你发送邮件Order History | National Snow and Ice Data Center (nsidc.org)),点击你现在的订单目录查看,下边zip下载,点击稍等片刻就会有下载弹窗
2数据处理(python3.11)
借鉴大佬的方法利用python读取ICESat-2ATL13数据_icesat2数据处理_华仔不爱marathon的博客-CSDN博客
里边涉及的软件包,缺少那个就直接使用win+r,cmd面板pip install +(缺少的软件)然后回车,等待下载完成。
后续的代码是我自己手搓的,处理过程较为分散。
由于后边批量提取的时候需要将所有的h5文件和附带的xml文件提取到同一个文件夹中
代码实现如下:
# Python 脚本。
import os
import shutil
def merge_folders(source_folder, destination_folder):
# 检查目标文件夹是否存在,如果不存在则创建它
if not os.path.exists(destination_folder):
os.makedirs(destination_folder)
# 遍历源文件夹及其子文件夹中的所有文件
for root, dirs, files in os.walk(source_folder):
for file in files:
# 构建源文件的完整路径
source_path = os.path.join(root, file)
# 构建目标文件的完整路径
destination_path = os.path.join(destination_folder, file)
# 将源文件复制到目标文件夹中
shutil.copy2(source_path, destination_path)
print("文件夹合并完成!")
# 指定源文件夹和目标文件夹的路径
source_folder = 'D:/ATL/icesat18-20'
destination_folder = 'D:/ATL/icesatALLH5'
# 调用函数进行文件夹合并
merge_folders(source_folder, destination_folder)
#说明:请确保将 source_folder 和 destination_folder 的值替换为
#实际的文件夹路径。此代码将遍历源文件夹及其所有子文件夹,并将所有文
#件复制到目标文件夹中。最后,它将输出"文件夹合并完成!"作为合并过程
#的确认。
使用利用python批量读取ICESat-2ATL13数据_利用python读取icesat-2atl13数据_华仔不爱marathon的博客-CSDN博客文章中的代码实现批量提取信息,将其稍作修改
代码如下:
import os
import glob
import h5py
import numpy as np
import pandas as pd
def batch_process_atl13(input_folder, output_folder, bbox=None):
"""
Batch process ATL13 files in the input folder and save output files in the specified output folder.
"""
#创建输出文件夹,如果它不存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 获取输入文件夹中所有h5文件的列表
files = glob.glob(os.path.join(input_folder, '*.h5'))
# Process each file
for file in files:
# Get the filename without the path
filename = os.path.basename(file)
# Each beam is a group
group = ['/gt1l', '/gt1r', '/gt2l', '/gt2r', '/gt3l', '/gt3r']
# Loop through beams
for k, g in enumerate(group):
# -----------------------------------#
# 1) Read in data for a single beam #
# -----------------------------------#
# Load variables into memory (more can be added!)
with h5py.File(file, 'r') as fi:
lat = fi[g + '/segment_lat'][:]
lon = fi[g + '/segment_lon'][:]
ht_water_surf = fi[g + '/ht_water_surf'][:]
segment_geoid = fi[g + '/segment_geoid'][:]
ht_ortho = fi[g + '/ht_ortho'][:]
if bbox:
lonmin, lonmax, latmin, latmax = bbox
bbox_mask = (lon >= lonmin) & (lon <= lonmax) & \
(lat >= latmin) & (lat <= latmax)
else:
bbox_mask = np.ones_like(lat, dtype=bool) # get all
# 定义输出文件名
output_filename = filename.replace('.h5', '_' + g[1:] + '.h5')
output_file = os.path.join(output_folder, output_filename)
# Save variables
with h5py.File(output_file, 'w') as f:
f['lon'] = lon
f['lat'] = lat
f['ht_water_surf'] = ht_water_surf
f['segment_geoid'] = segment_geoid
f['ht_ortho'] = ht_ortho
print('Output file:', output_file)
# 另存为CSV
output_csv = os.path.join(output_folder, output_filename.replace('.h5', '.csv'))
result = pd.DataFrame()
result['lon'] = lon
result['lat'] = lat
result['ht_water_surf'] = ht_water_surf
result['segment_geoid'] = segment_geoid
result['ht_ortho'] = ht_ortho
result.to_csv(output_csv, index=None)
print('Output CSV:', output_csv)
# 指定输入文件夹,输出文件夹和bbox如果需要
input_folder = r'D:/ATL/icesatALLH5'
output_folder = r'D:/ATL/Processed'
bbox = None
# Call the batch processing function
batch_process_atl13(input_folder, output_folder, bbox)
将input_folder = r'D:/ATL/icesatALLH5'替换为你含有所有h5文件的文件夹
output_folder = r'D:/ATL/Processed'替换为你想要输出的位置
将得到的csv文件使用自己研究区域的shp矢量图进行筛选。新的CSV文件的命名方式为原文件名加上"_shp"后缀:
代码实现如下:
#可以读取一个Shapefile文件(.shp)和一个文件夹中所有CSV文件(.csv),然后分别筛选出每个
#位于Shapefile范围内的CSV数据,并将筛选出的数据分别写入一个新的CSV文件中,新的CSV文件的命
#名方式为原文件名加上"_shp"后缀:
import os
import geopandas as gpd
import pandas as pd
# 读取Shapefile文件
gdf = gpd.read_file('D:/ATL/NMCshapefile/111.shp')
# 创建保存筛选结果的文件夹
output_folder = 'D:/ATL/FilteredCSV/'
os.makedirs(output_folder, exist_ok=True)
# 遍历CSV文件夹中的所有文件
csv_folder = 'D:/ATL/CSV2/'
for filename in os.listdir(csv_folder):
if filename.endswith('.csv'):
csv_path = os.path.join(csv_folder, filename)
# 读取CSV文件
df = pd.read_csv(csv_path)
# 筛选出Shapefile范围内的数据
df = df[(df['lon'] > gdf.bounds['minx'][0]) &
(df['lat'] > gdf.bounds['miny'][0]) &
(df['lon'] < gdf.bounds['maxx'][0]) &
(df['lat'] < gdf.bounds['maxy'][0])]
# 生成新的CSV文件路径
output_filename = os.path.splitext(filename)[0] + '_shp.csv'
output_path = os.path.join(output_folder, output_filename)
# 将筛选出的数据写入新的CSV文件
df.to_csv(output_path, index=False)
由于相同时间有六个csv文件,将其合并起来。
代码实现如下:
import os
import pandas as pd
# 创建保存整合结果的文件夹
output_folder = 'D:/ATL/OutputCSV/'
os.makedirs(output_folder, exist_ok=True)
# 遍历CSV文件夹中的所有文件
csv_folder = 'D:/ATL/FilteredCSV'
for filename in os.listdir(csv_folder):
if filename.endswith('.csv'):
csv_path = os.path.join(csv_folder, filename)
# 从文件名中提取时间信息
year = filename[6:10]
month = filename[10:12]
day = filename[12:14]
date = f"{year}-{month}-{day}"
# 读取CSV文件
df = pd.read_csv(csv_path)
# 生成新的CSV文件路径
output_filename = f"{date}.csv"
output_path = os.path.join(output_folder, output_filename)
# 将数据追加到新的CSV文件中
df.to_csv(output_path, mode='a', index=False, header=not os.path.exists(output_path))
然后就要将相同时间的水位高程信息进行平均,内有删除异常高程的方法(仅使用于湖泊等,按自己需要修改)
代码如下:
#将提取的时间和过滤后的水位平均值数据生成CSV文件
#在这个修改后的代码中,我们在计算过滤后的水位平均值之前,添加了一个条件判断,
#检查过滤后的数据是否为空。如果过滤后的数据非空,即存在过滤后的水位平均值数据,
#才进行计算和添加到 data_list 列表中。这样可以剔除没有过滤后的水位平均值数据对应的记录。
import os
import pandas as pd
import matplotlib.pyplot as plt
# 创建空列表用于存储时间和水位平均值数据
data_list = []
# 遍历CSV文件夹中的所有文件
csv_folder = 'D:/ATL/OutputCSV/'
for filename in os.listdir(csv_folder):
if filename.endswith('.csv'):
csv_path = os.path.join(csv_folder, filename)
# 从文件名中提取时间信息
time = os.path.splitext(filename)[0]
# 读取CSV文件
df = pd.read_csv(csv_path)
# 计算水位平均值和标准差
average_water_level = df['ht_water_surf'].mean()
std_water_level = df['ht_water_surf'].std()
# 根据平均值和标准差过滤异常值
filtered_df = df[
(df['ht_water_surf'] >= average_water_level - 3 * std_water_level) &
(df['ht_water_surf'] <= average_water_level + 3 * std_water_level)
]
# 如果过滤后的数据非空,则计算过滤后的水位平均值
if not filtered_df.empty:
filtered_average_water_level = filtered_df['ht_water_surf'].mean()
# 将时间和过滤后的水位平均值添加到列表中
data_list.append([time, filtered_average_water_level])
# 创建DataFrame对象
df_data = pd.DataFrame(data_list, columns=['Time', 'Average Water Level'])
# 生成CSV文件
csv_output_path = 'D:/ATL/FilteredData2.csv'
df_data.to_csv(csv_output_path, index=False)
最终得到下面数据:
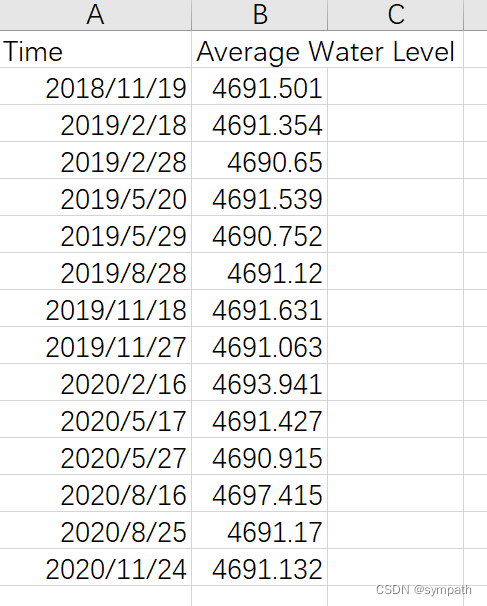
由于湖泊的纪年法为水文年,青藏高原的湖泊水文年为上一年10月01日到本年的9月30日。先使用代码将时间转换为相应的水文年,在对其每年的水位求平均值。
代码实现如下:
import pandas as pd
# 读取CSV文件
data = pd.read_csv('F:/I11.csv')
# 将时间列解析为日期格式
data['Time'] = pd.to_datetime(data['Time'])
# 筛选上一年10月1日至本年9月30日的数据
start_date = pd.Timestamp(data['Time'].dt.year.min(), 10, 1) # 上一年10月1日
end_date = pd.Timestamp(data['Time'].dt.year.max() + 1, 9, 30) # 本年9月30日
filtered_data = data[(data['Time'] >= start_date) & (data['Time'] <= end_date)]
# 计算水位平均值
average_elevation = filtered_data.groupby(filtered_data['Time'].dt.year)['Elevation'].mean()
# 导出到新的CSV文件
average_elevation.to_csv('F:/水位平均值_年度.csv', header=False, index=True)
得到
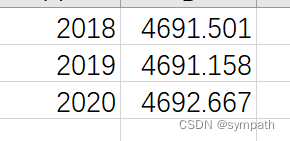
ok,后续就可以使用这些数据对湖泊水位变化进行绘图。
以上就是我对这一部分知识的全部了解了