文档(Document)
- elasticsearch 是面向文档的,文档是所有可搜索数据的最小单位
- 文档会被序列化为 JSON 的格式,保存在 elasticsearch 中
- JSON 对象由字段组成
- 每个字段有对应的字段类型(字符串、数值、布尔、日期、二进制、范围类型)
- 每个文档都有一个 Unique ID
- 可以自动生成/自己指定
JSON 文档
- 一篇文档包含了一系列字段。类似于数据库表中一条数据
- JSON 格式灵活,不需要预先定义格式
- 字段类型可以指定或者由 elasticsearch 自动推算
- 支持数组/嵌套
- CSV file 经过 logstash 转换,就会以 JSON 文件的格式打入 elasticsearch
文档元数据

- 用来标注文档的相关信息
- _index - 文档所属的索引名
- _type - 文档所属的类型名-默认为 “_doc”
- _id - 文档唯一 ID
- _source - 文档的原始 JSON 数据
- _version - 文档的版本信息
- _score - 相关性打分
索引(index)
-
Index - 索引是文档的容器,是一类问文档的结合
- Index 体现了逻辑空间的概念:每个索引都有自己的 Mapping 定义,用于定义包含文档的字段名和字段类型
- Shard 体现了物理空间的概念:索引中的数据被分散在 Shard 上
-
索引的 Mapping 与 Setting
- Mapping 定义文档字段的类型
- Setting 定义不同的数据分布
-
名词:一个 elasticsearch 集群中,可以创建很多个不同的索引
-
动词:保存一个文档到 elasticsearch 中的过程也叫索引(indexing)
倒排索引
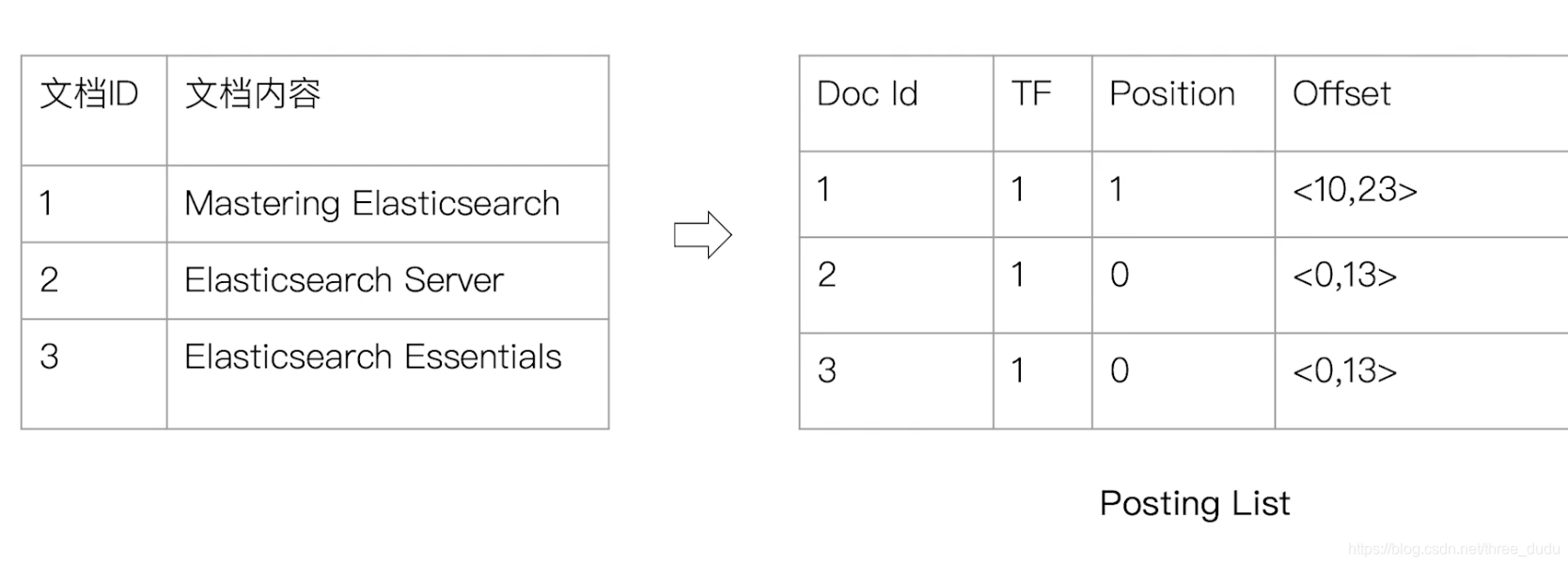
- 单词列表(Term Dictionary)- 记录所有文档的单词,记录单词到倒排列表的关联关系
- 一般较大,通过 B+ 树/哈希拉链法 实现,以满足高性能的插入与查询
- 倒排列表(Posting List)- 记录了单词对应的文档集合,由倒排索引项组成
- 倒排索引项
- 文档 ID
- 词频 TF - 该单词在文档中出现的次数,用于相关性评分
- 位置(Position)- 单词在文档中分词的位置。用于语句搜索(phrase query)
- 偏移(offset)- 记录单词的开始结束位置,实现高亮显示
- 倒排索引项
- elasticsearch 会对 JSON 中每一个字段都建立索引,但也可以指定字段不进行建立
相关概念类比
| RDBMS | Elasticsearch |
|---|---|
| Table | Index(Type) |
| Row | Document |
| Column | Filed |
| Schema | Mapping |
| SQL | DSL |
分布式特性
集群(Cluster)
-
elasticsearch 分布式架构的好处
- 存储的水平扩容
- 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
-
Elasticsearch 的分布式架构
- 不同的集群通过不同名字来区分,defualt:‘elasticsearch’
- 通过配置文件修改,或在命令行中 − E c l u s t e r . n a m e = c l u s t e r 1 -E cluster.name=cluster1 −Ecluster.name=cluster1 来指定
集群状态(Cluster State)
- 维护了一个集群所必要的信息
- 所有节点 信息
- 所有的索引和其相关的 Mapping 与 Setting 信息
- 分片的路由信息
- 只有主节点才能修改
集群状况(health)
GET _cluster/health
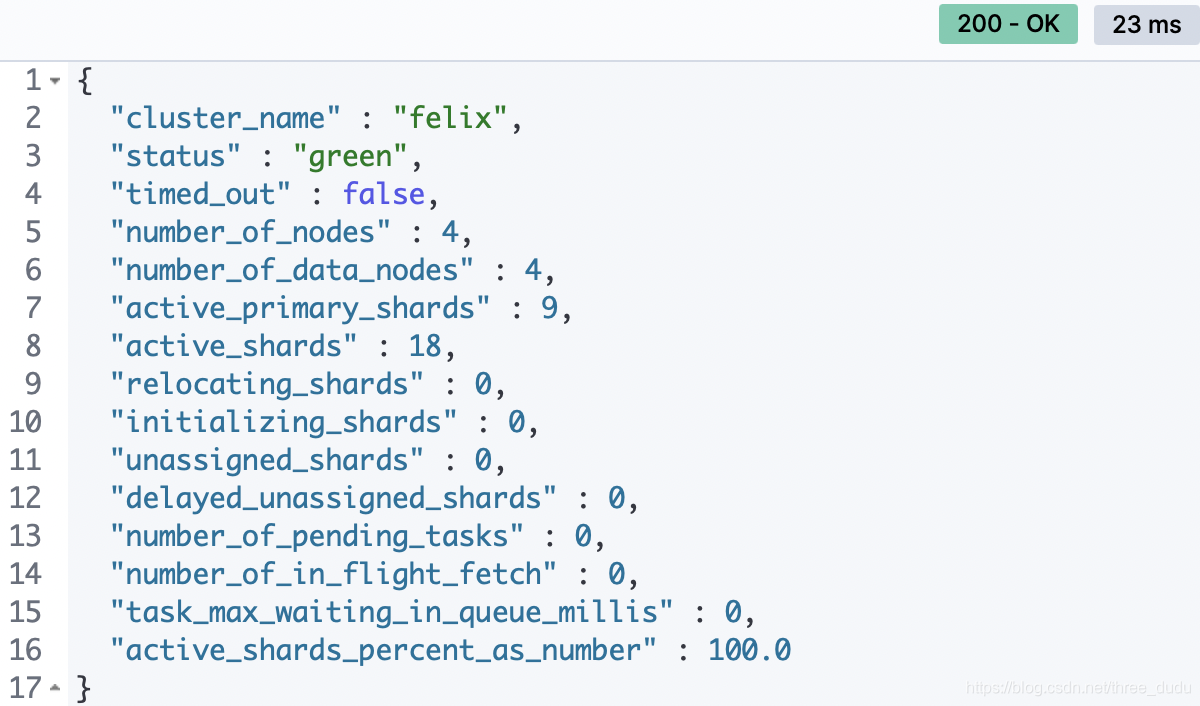
- Green - 主分片与副本都正常分配
- Yellow - 主分片全部正常分配,有副本分片未能正常分配
- Red - 有主分片未能分配
- 如磁盘容量超过负载
节点(node)
- 节点是一个 elasticsearch 实例
- 本质上就是一个 Java 进程
- 一台机器上可以运行多个 elasticsearch 的进程,生产环境只建议一个
- 节点名称也可以通过配置文件,或者启动的时候 − E n o d e . n a m e = n o d e 1 -E node.name=node1 −Enode.name=node1 指定
- 每个节点在启动后,都会分配到一个 UID,在data 目录下
Master-eligible nodes 和 Master Node
具有投票权的节点和主节点
- 每个节点启动后,默认就是一个 Master eligible 节点
- 可以设置 node.master : false 来禁止
- Master-eligible 节点可以参加选举进程,成为 Master 节点
- 第一个节点会自动选举为 Master 节点
- 每个节点都保存了集群的状态,只有 Master 节点才能修改集群的状态信息
Data Node & Coordinating Node
-
Date Node
- 可以保存数据的节点
- 负责保存分片数据,数据扩展时起到了至关重要的作用
-
Coordiating Node
- 负责接收 Client 的请求,将请求分发带合适的节点,最终吧结果汇集到一起
- 每个节点默认都有 Coordinating Node 的职责
Hot & Warm Node
- 不同硬件配置的 Data Node,可以实现 Hot & Warm 架构,降低集群部署的成本
- Hot 热数据-配置较高,warm数据-配置较低
Machine Learning Node
- 负责跑机器学习的 Job,用来做异常检测
配置节点类型
- 开发中一个节点可以承担多个角色
- 生产中应该设置单一的角色的节点(dedicated node)
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| master-eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| coordinating only | N/A | 恒为true |
| machine learning | tode.ml | true |
分片(Primary Shard & Replica Shard)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eTefzgny-1612083459487)(/Users/felix/Desktop/截屏2021-01-31 上午12.39.24.png)]
- 主分片,用以解决数据水平扩展的问题,将数据分布到集群内的所有节点之上
- 一个分片就是 一个运行的 Lucene 的实例
- 主分片数在索引创建时指定,后续不允许修改,除非 Reindex
- 副本,用以解决数据高可用的问题。分片其实是主分片的拷贝
- 提高副本数量达到高吞吐的效果
- 副本分片数量可以动态调整
分片的设定
-
分片数量过小
- 后续无法增加节点实现水平扩展
- 单个分片数据量太大,导致数据重新分配耗时长
-
分片数量过大
- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单个节点过多的分片,会导致资源浪费,也会影响性能
- 7.0 开始默认为 1 ,防止 over-sharding