问题
C++ 中的 std::string 类相比起 C 中的字符串,使用起来非常方便,编译器会根据字符串长短自动分配内存;不像 C 里,需要确定的知道字符串有多长,然后分配相应的堆或者栈空间。 但是 C++ 能做到这样,肯定是有人替你负重前行。本文接下来探究 C++ 中不同长度的字符串在内存中是如何存储的。
短字符串
测试输出
首先写下基本测试代码:
#include <iostream>
using namespace std;
int main(){
long bottom = -1;
string word = "dev";
cout << "> Current string content: " << word << endl;
cout << " &bottom: " << &bottom << endl;
cout << " &word: " << &word << endl;
char &c1 = word[0];
cout << "&word[0]: " << (void *)&c1 << endl;
auto size = (char *)&bottom - (char *)&word;
cout << " sizeof word: " << size << endl;
}
执行结果如下:
> Current string content: dev
&bottom: 0x16eee7698
&word: 0x16eee7680
&word[0]: 0x16eee7680
sizeof word: 24上述代码声明并初始化了两个变量:
- bottom:声明这个变量主要是为了获得其地址,作为基准地址就可以确认编译器给
word对象分配的栈空间大小。因为接下来的word肯定是紧贴着它的内存空间的; - word:一个 string 对象,也就是接下来我们主要研究的对象。初始值是字符串
"dev"。
接下来的代码中,我们做了这些事:
- 输出了这个字符串;
- 输出了
bottom和word的地址,并根据地址计算出编译器给word预留出了 24 个字节的栈空间; - 输出了字符串中第一个字符的地址,从目前的结果看,这个地址也就是
word的起始地址。因此,目前可以判断,字符串就是存储在所分配的 24 个字节空间中的。
这样就引入了两个疑问:
- 总共 24 个字节,目前字符串内容是
"dev"的话,只有4 个字节是被使用的,那么其他 20 个字节里有什么? - 如果字符串超出了 24 个字节怎么办?
针对第一个问题,我们以字长为单位,输出这 24 个字节的全部内容;
long *ptr = (long *)&word;
cout << " 0. " << std::hex << *ptr << endl;
cout << " 1. " << std::hex << *(ptr + 1) << endl;
cout << " 2. " << std::hex << *(ptr + 2) << endl;
输出结果如下:
0. 766564
1. 0
2. 300000000000000内存布局
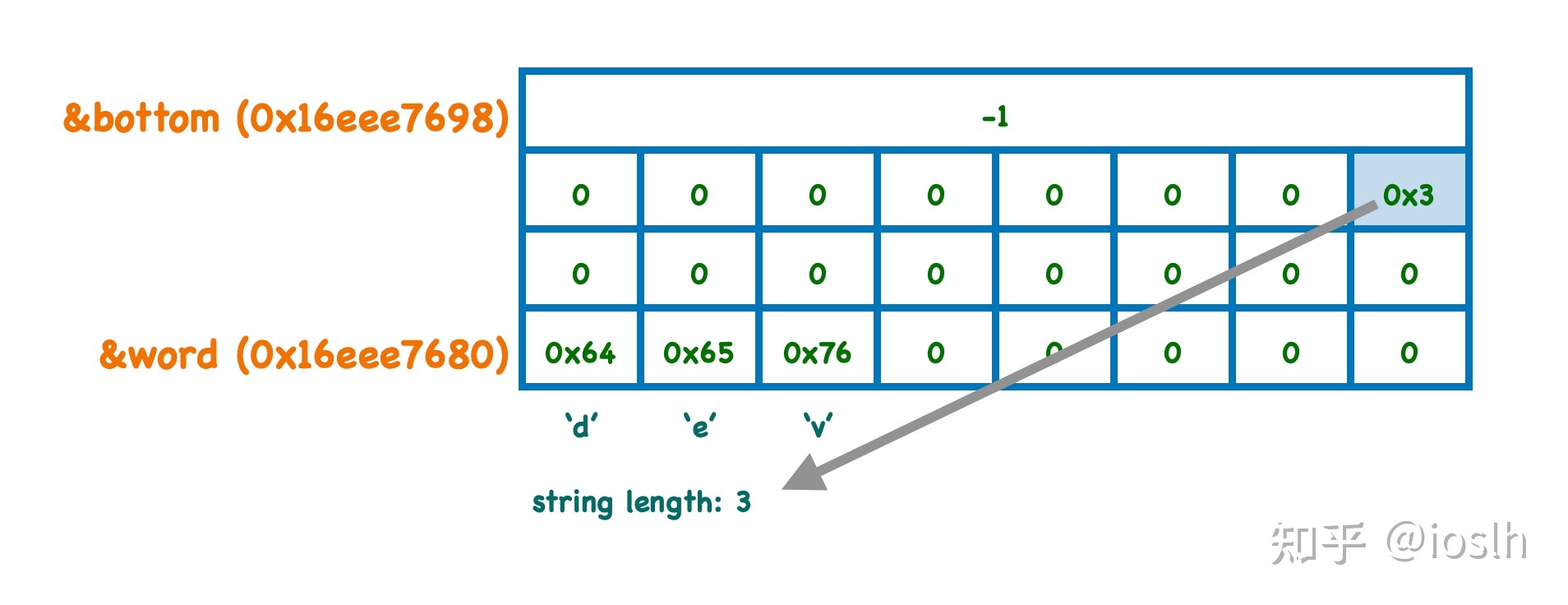
先画个图,把目前已知的关于栈空间的内容分布画出来。
短字符串内存分布
上图中,一个格子代表一个字节;栈的增长方向(地址的降低方向)是向图片下方。
根据输出,关于 word 对象有如下需要关注的地方:
- 前 8 个字节内容是 0x766564,对照一下 ASCII 表,可以确认这就是字符串
"dev",其他的字节全部是 0;另外我们还能确认当前机器是小端字节序; - 中间 8 个字节全部是 0;
- 最后 8 个字节是 0x0300000000000000,其中最高位字节 0x03,这个是什么?
一个巧合,当前存储的字符串长度刚好是 3,有没有可能这就是字符串的长度?很好验证,赋值字符串换一个不同长度的再执行上述代码,可以确认,这个字节中存储的就是字符串的长度。并且只有 24 个字节的空间,所以按照这样的存储方式,字符串最长只能是 22。
长字符串
测试输出
这是前面提出的两个问题之一:从目前的布局来看,只能存储最多 22 个字符(预留一个字节 \0 最为字符串终止,一个字节存储字符串长度);那么问题来了,如果 word 的内容超过了 24 个字节,那内存是怎么样的? 于是,我们重新把 word 赋值为一个长于 24 字节的字符串(此处是 25),看看结果如何。
cout << string(40, '-') << endl;
word = string(size + 1, 'C');
cout << " &word: " << &word << endl;
char &c2 = word[0];
cout << "&word[0]: " << (void *)&c2 << endl;
cout << " 0. " << std::hex << *pword << endl;
cout << " 1. " << std::hex << *(pword + 1) << endl;
cout << " 2. " << std::hex << *(pword + 2) << endl;
执行结果如下:
----------------------------------------
&word: 0x16eee7680
&word[0]: 0x600000730000
0. 600000730000
1. 19
2. 8000000000000020可以观察到:
word对象本身的地址没有变;word对象中所存储字符串的第一个字符地址变了,C/C++ 规范要求字符串肯定是占据连续的空间,可以肯定整个字符串被移到了其他的地方;
内存布局
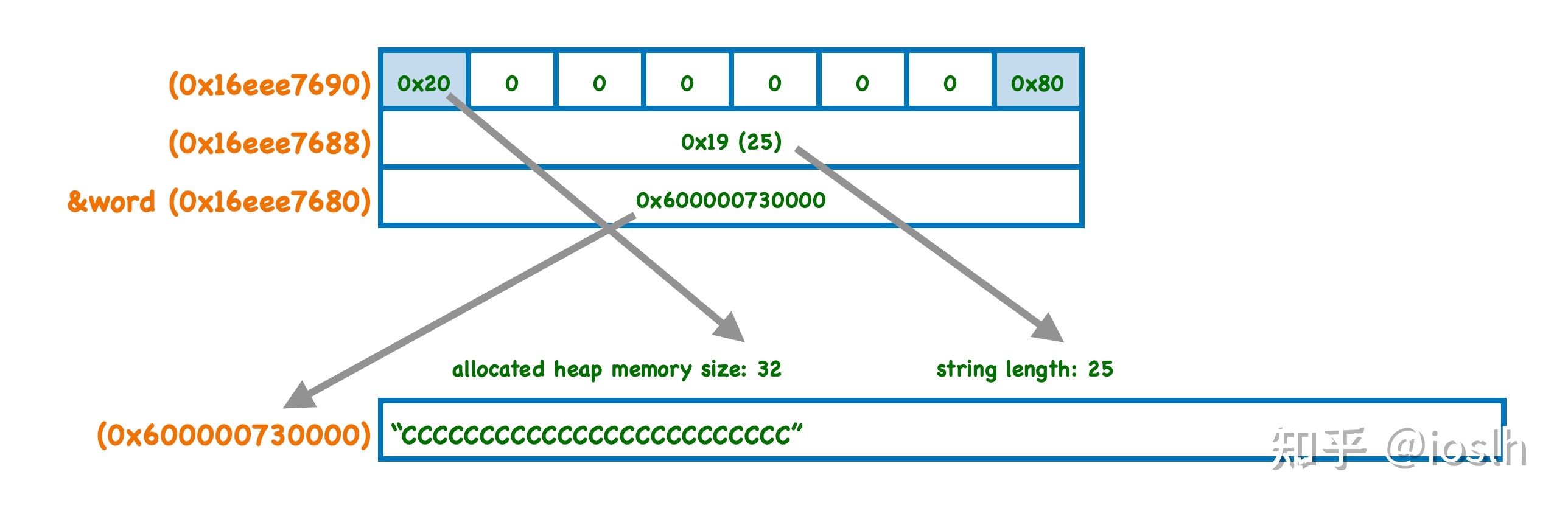
同样可以把此时的内存布局画出来:
长字符串内存分布
图中展示了一些即将要提到的细节。另外图中地址的相对大小令我有些疑惑,按我当前学习到的虚拟内存布局模型,堆的地址应该比栈更小才对,但是测试下来地址却如图中所示,莫非字符串不是分配在堆内存中?不过可以确定的是,string 对象的地址(&word)跟其包含的字符串是分开存储的。
观察此时 word 对象的 24 个字节的内容:
- 前 8 字节内容改了,而且刚好是的字符串第一个字符的地址,可以确认这里存储的是一个指针(
char **),指向真正存储了字符串的空间。 - 中间 8 个字节
0x19(25)是什么呢?同样可以猜测并验证,这就是字符串的长度。 - 最后 8 个字节,
0x8000000000000020,这个下面详述。
掩码
通过前面的代码测试,我们明确了字符串可能存储在栈,也可能存储在堆;这就带来了不确定性,那么编译器怎么进行区分呢?
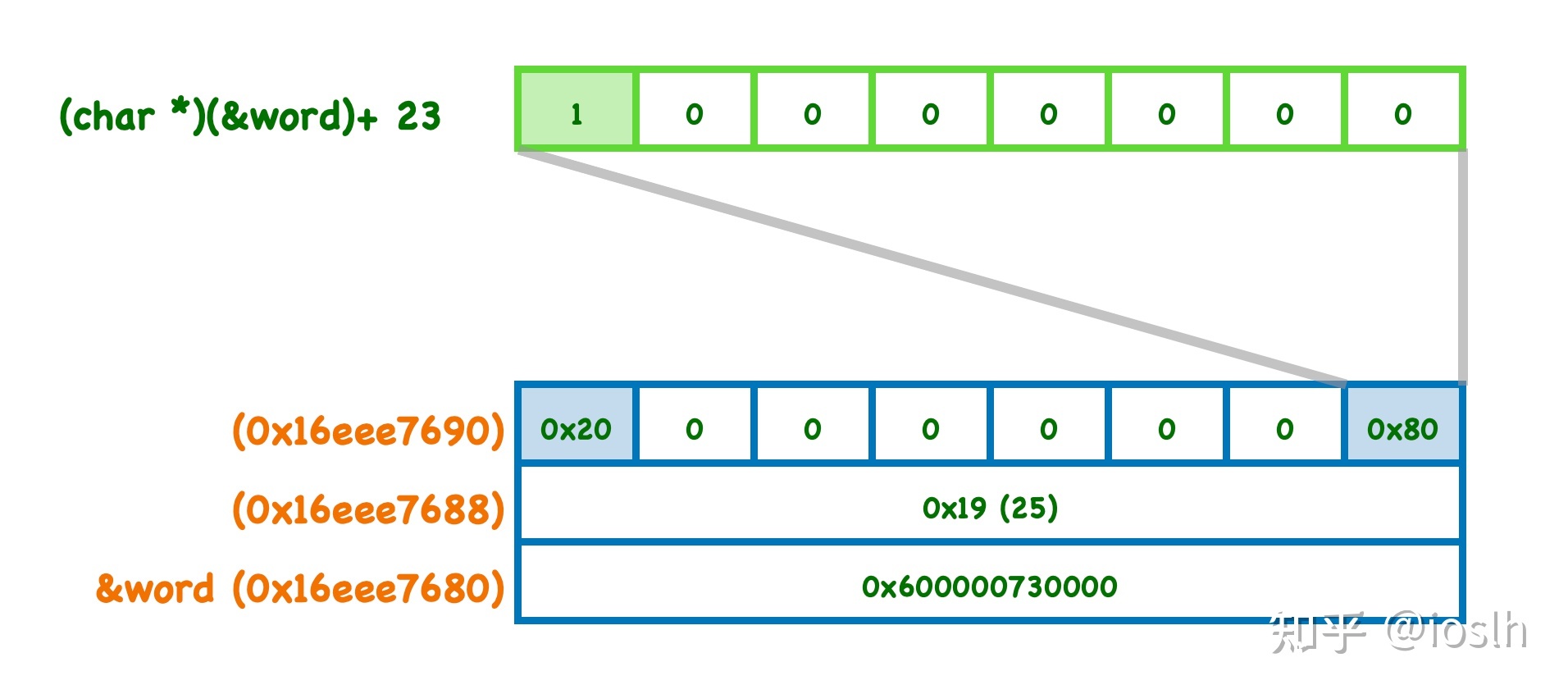
使用掩码确认字符串的真正位置
回想长字符串栈空间中最后 8 个字节 0x8000000000000020,其最高位字节0x80,最高比特位是 1;跟短字符串的情形不一样,这里肯定不再是字符串的长度了。短字符串情形下,这个字节存储的内容最大是 22,最高比特位是 0。
此时我们可以推测一下,编译器就是用这个 0x80 字节的最高位来区分:一个字符串到底是原地存储在 24 字节的栈中,还是存储在另外开辟的堆空间中。顺便可以关注一下,这个字节是在距离 &word 起始地址偏移 23 字节的位置,记住这个位置,等下会有用。
堆大小
还有个问题,0x8000000000000020 这里的最低位字节 0x20(32)是什么(前面图中已经剧透)?凭目前的代码及输出结果,还无法推测。我在这个 Stackoverflow 回答里看到了线索:
Two common implementations are storing 3 pointers (begin of the allocated region and data, end of data, end of allocated region) or a pointer (begin of allocated region and data) and two integers (number of characters in the string and number of allocated bytes).
当字符串长度超过 22 时,无法存储在栈空间中,需要在堆内动态分配内存存储字符串,而前述的 0x20,就是分配的堆大小。同样可以通过修改更长的字符串验证,当字符串长度增长时,分配的堆空间也会增长,而且因为对齐的限制,通常会超过字符串实际长度。
汇编验证
前面提到的 0x80 字节的作用只是猜测,接下来执行调试验证一下。要验证的问题很明确,当字符串既可能存储在函数栈,也可能存储在动态堆里时,编译器是如何确定到底在哪里的?
为此,我们写了个函数,如方法名所示,获取字符串中的第一个字符,要实现这个功能,汇编代码的执行肯定要涉及上述逻辑。接下来的调试只需要将断点设置在该函数即可:
char get_first_char(string *str) {
return (*str)[0];
}
函数 get_first_char 的汇编代码如下:
0x100005bd8 <+0>: sub sp, sp, #0x20
0x100005bdc <+4>: stp x29, x30, [sp, #0x10]
0x100005be0 <+8>: add x29, sp, #0x10
0x100005be4 <+12>: str x0, [sp, #0x8]
0x100005be8 <+16>: ldr x0, [sp, #0x8]
0x100005bec <+20>: mov x1, #0x0
0x100005bf0 <+24>: bl 0x100005b74 ; std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> >::operator[](unsigned long)
0x100005bf4 <+28>: ldrsb w0, [x0]
0x100005bf8 <+32>: ldp x29, x30, [sp, #0x10]
0x100005bfc <+36>: add sp, sp, #0x20
0x100005c00 <+40>: retARM 格式的汇编代码不太熟,花了一个小时入门之后勉强看懂一点, bl 是函数调用指令,所以继续跟进调用这一行打断点。
0x100007708 <+24>: bl 0x100006908 ; std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> >::__is_long() const
0x10000770c <+28>: tbz w0, #0x0, 0x100007724 ; <+52>
0x100007710 <+32>: b 0x100007714 ; <+36>
0x100007714 <+36>: ldr x0, [sp, #0x10]
0x100007718 <+40>: bl 0x100006960 ; std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> >::__get_long_pointer()
0x10000771c <+44>: str x0, [sp, #0x8]
0x100007720 <+48>: b 0x100007734 ; <+68>
0x100007724 <+52>: ldr x0, [sp, #0x10]
0x100007728 <+56>: bl 0x1000069c0 ; std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> >::__get_short_pointer()经过若干次函数调用跳转后,在汇编代码的注释里发现了可能的线索;观察上方汇编代码的注释,第 1 行似乎是调用了一个名为 __is_long 的函数。而后面又分别有 __get_long_pointer 和 __get_short_pointer 的函数,从命名上,似乎符合我们前面的猜想: 即根据某个特定比特位,判断字符串指针应该从栈里取还是堆里取。那么继续跟进去这个 __is_long 函数。
0x100006908 <+0>: sub sp, sp, #0x20
0x10000690c <+4>: stp x29, x30, [sp, #0x10]
0x100006910 <+8>: add x29, sp, #0x10
0x100006914 <+12>: str x0, [sp, #0x8]
0x100006918 <+16>: ldr x0, [sp, #0x8]
0x10000691c <+20>: bl 0x100006a20 ; std::__1::__compressed_pair<std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> >::__rep, std::__1::allocator<char> >::first() const
0x100006920 <+24>: ldrb w8, [x0, #0x17]
0x100006924 <+28>: ands x8, x8, #0x80
0x100006928 <+32>: cset w8, ne
0x10000692c <+36>: and w0, w8, #0x1
0x100006930 <+40>: ldp x29, x30, [sp, #0x10]
0x100006934 <+44>: add sp, sp, #0x20
0x100006938 <+48>: ret看看 __is_long 部分的汇编代码,我感觉可以宣告破案了。上面汇编代码的第 7、8 两行,有一个熟悉的十六进制数字:0x17,也就是 23,这就是前面提到的 0x80 字节的偏移量。这两行的逻辑是:
- 取出 x1 寄存器中内存地址偏移 23(#0x17)个字节的字节,放到 x8 寄存器中;
- 将该值与 0x80 进行与运算并将结果返回;
代码验证
上面的汇编代码,其实大部分我都看不懂,主要是注释给了我提醒,那么实现 string 类的代码里,是不是应该有注释里提到的这些方法? 跟随 IDE (我使用的是 CLion)的提示,点击进入 string 的类定义里:
typedef basic_string<char, char_traits<char>, allocator<char> > string;
继续进入 basic_string 的定义,可以找到如下的方法:
pointer __get_pointer() _NOEXCEPT
{return __is_long() ? __get_long_pointer() : __get_short_pointer();}
_LIBCPP_INLINE_VISIBILITY
const_pointer __get_pointer() const _NOEXCEPT
{return __is_long() ? __get_long_pointer() : __get_short_pointer();}
另外还定义了两个静态常量作为掩码。
#ifdef _LIBCPP_BIG_ENDIAN
static const size_type __short_mask = 0x01;
static const size_type __long_mask = 0x1ul;
#else // _LIBCPP_BIG_ENDIAN
static const size_type __short_mask = 0x80;
static const size_type __long_mask = ~(size_type(~0) >> 1);
#endif // _LIBCPP_BIG_ENDIAN
这部分基本上印证了汇编代码中体现的逻辑。C++ Primer 我才看到第三章,所以 basic_string 中其他的代码我根本看不懂。代码部分就说到这里吧。
结论
到目前为止,可以得出 string 对象到底如何存储字符串的结论:
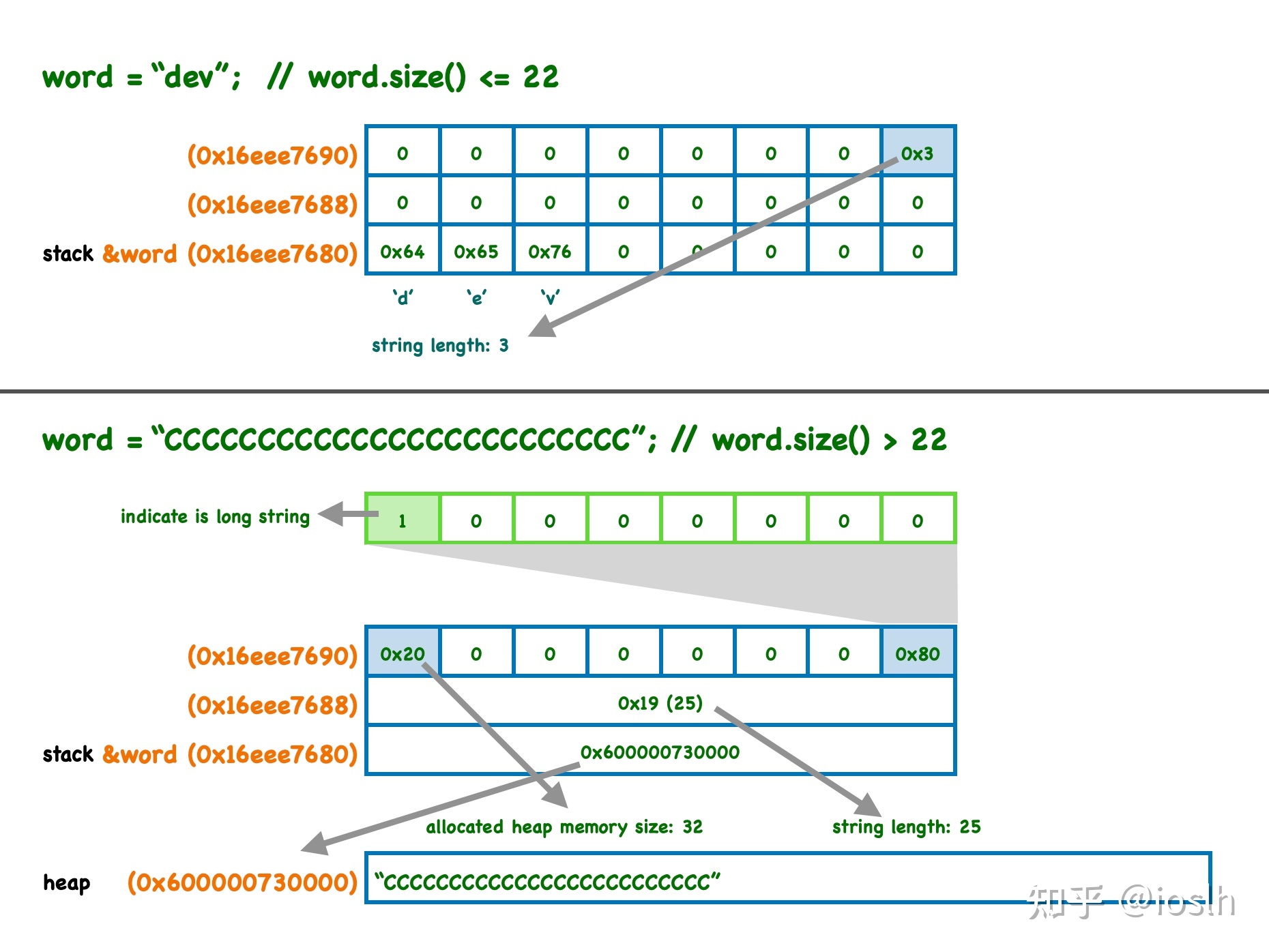
std::string 的内存分布
- 编译器会为每一个 string 对象分配 24 个字节的栈空间;
- 如果要存储的字符串长度(strlen 而非 sizeof)小于等于 22,则直接存储在函数栈中;最后一个字节(地址最高处)存储字符串的实际长度;
- 如果要存储的字符串长度超过 22,会另外分配堆内存空间存储字符串本身,栈内的 24 个字节空间另有他用:
- 将字符串在堆中的地址存储在 24 个字节的前 8 个字节;
- 中间 8 个字节存储字符串的长度;
- 最后 8 个字节:地址最高的字节固定为 0x80,剩余字节存储分配的堆空间大小。
注意:以上的测试基于我当前使用的编译器,根据 StackOverflow 的一些回答,其他的编译器可能有不同的存储策略,本文暂不涉及。
文中涉及到的完整代码请参考 GitHub Gist。
文章原始地址:C++ 中 std::string 的内存布局