前言:
晚上刷抖音,刷到一个关于python爬虫的视频,想着重温一下之前学过的爬虫基础,好别忘记了,于是就从网上找了一个小说网站-起点中文网,由于学艺不精,搞不定vip接口,所以只能爬一爬免费的小说咯.
网站url:免费小说大全_小说免费在线阅读-起点中文网 (qidian.com)
第一步:我定义了四个列表分别存储爬取到的数据
a = []#小说链接存储列表
b = []#小说名列表
c = []#小说章节链接列表
d = []#小说章节名列表
第二步:我定义了第一个函数,用来爬取小说名和小说详情页链接,并将爬取到的链接存储到a列表,小说名存储到b列表,之后会派上用场。
代码如下:
def qd():
m = int(input('请输入要爬取的页数:'))
for n in range(m):
url = 'https://www.qidian.com/free/all/page{}/'.format(n)
headers = {
'Cookie': '_yep_uuid=d8b52da3-2e99-6aa7-6f40-b764179d5cd7; supportwebp=true; x-waf-captcha-referer=; _csrfToken=zOBoyYeRJQmHZ9hoQUBiTL2WMoK5X07zciU9oBYG; newstatisticUUID=1718464987_786877310; fu=1199187808; traffic_utm_referer=; Hm_lvt_f00f67093ce2f38f215010b699629083=1718464988; Hm_lpvt_f00f67093ce2f38f215010b699629083=1718464988; _ga_FZMMH98S83=GS1.1.1718464988.1.0.1718464988.0.0.0; _ga_PFYW0QLV3P=GS1.1.1718464988.1.0.1718464988.0.0.0; _ga=GA1.2.1668981357.1718464988; _gid=GA1.2.1024042542.1718464988; _gat_gtag_UA_199934072_2=1; w_tsfp=ltvgWVEE2utBvS0Q6KLtkk+nHj47Z2R7xFw0D+M9Os09CKcnV56F1Yd5vNfldCyCt5Mxutrd9MVxYnGJUtAgfREQRM+Sb5tH1VPHx8NlntdKRQJtA8iOXlEYcr1yujNPKG9ccBS02j4rcdBCxLBkg1AOtiJ937ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgWmesA7uLi0lX+ZX0jPShH9KD20hlwOnZrgPa0Pvfp/zSucirTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZVignqx3I/v4baVg5CMTTq8dGgoW/QsctbQ9rxZHDSHpMyPdBPIo5AMAT/YK/8j6a2Y=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'
}
reponse = requests.get(url, headers=headers)
html = BeautifulSoup(reponse.text, 'lxml')
htmls = html.select('div.main-content-wrap div.all-book-list div.book-img-text ul li h2 a ')
htmlss = html.select('div.main-content-wrap div.all-book-list div.book-img-text ul li p a.name')
for i, k in zip(htmls, htmlss):
a.append('https:' + i['href'])
b.append(i['title'])
print('小说名为:' + i['title'] + ' ---|--- ' + '小说链接为:' + 'https:' + i['href'])第三步:我定义了第二个函数,让用户自己选择要下载的小说,并爬取选择的小说的章节链接以及章节名,并将章节链接存储在c列表,章节名存储在d列表,并且我在这一步以选择的小说名为名创建了一个文件夹。
代码如下:
def xz1():
url = input('请选择你要下载的小说,将url复制到此:')
headers = {
'Cookie': '_yep_uuid=d8b52da3-2e99-6aa7-6f40-b764179d5cd7; supportwebp=true; x-waf-captcha-referer=; _csrfToken=zOBoyYeRJQmHZ9hoQUBiTL2WMoK5X07zciU9oBYG; newstatisticUUID=1718464987_786877310; fu=1199187808; traffic_utm_referer=; Hm_lvt_f00f67093ce2f38f215010b699629083=1718464988; Hm_lpvt_f00f67093ce2f38f215010b699629083=1718464988; _ga_FZMMH98S83=GS1.1.1718464988.1.0.1718464988.0.0.0; _ga_PFYW0QLV3P=GS1.1.1718464988.1.0.1718464988.0.0.0; _ga=GA1.2.1668981357.1718464988; _gid=GA1.2.1024042542.1718464988; _gat_gtag_UA_199934072_2=1; w_tsfp=ltvgWVEE2utBvS0Q6KLtkk+nHj47Z2R7xFw0D+M9Os09CKcnV56F1Yd5vNfldCyCt5Mxutrd9MVxYnGJUtAgfREQRM+Sb5tH1VPHx8NlntdKRQJtA8iOXlEYcr1yujNPKG9ccBS02j4rcdBCxLBkg1AOtiJ937ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgWmesA7uLi0lX+ZX0jPShH9KD20hlwOnZrgPa0Pvfp/zSucirTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZVignqx3I/v4baVg5CMTTq8dGgoW/QsctbQ9rxZHDSHpMyPdBPIo5AMAT/YK/8j6a2Y=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'
}
reponse = requests.get(url,headers=headers)
html = BeautifulSoup(reponse.text,'lxml')
htmls = html.select('div.catalog-volume ul li a')
print('你选择的小说章节如下:')
for h in htmls:
print('章节名为:' + h.text + ' ---+--- ' + '章节链接为:' 'https:' + h['href'])
c.append('https:' + h['href'])
d.append(h.text)
global urls
urls = a.index(url)
#print(urls)
if not os.path.exists(b[urls]):
os.makedirs(b[urls])
第四步:创建了第三个函数,用来下载小说,并将内容下载到上一步创建的文件夹中,以txt文件的形式,txt文件名为章节名。
代码如下:
def xz2():
for i in c:
url = i
headers = {
'Cookie': '_yep_uuid=d8b52da3-2e99-6aa7-6f40-b764179d5cd7; supportwebp=true; x-waf-captcha-referer=; _csrfToken=zOBoyYeRJQmHZ9hoQUBiTL2WMoK5X07zciU9oBYG; newstatisticUUID=1718464987_786877310; fu=1199187808; traffic_utm_referer=; Hm_lvt_f00f67093ce2f38f215010b699629083=1718464988; Hm_lpvt_f00f67093ce2f38f215010b699629083=1718464988; _ga_FZMMH98S83=GS1.1.1718464988.1.0.1718464988.0.0.0; _ga_PFYW0QLV3P=GS1.1.1718464988.1.0.1718464988.0.0.0; _ga=GA1.2.1668981357.1718464988; _gid=GA1.2.1024042542.1718464988; _gat_gtag_UA_199934072_2=1; w_tsfp=ltvgWVEE2utBvS0Q6KLtkk+nHj47Z2R7xFw0D+M9Os09CKcnV56F1Yd5vNfldCyCt5Mxutrd9MVxYnGJUtAgfREQRM+Sb5tH1VPHx8NlntdKRQJtA8iOXlEYcr1yujNPKG9ccBS02j4rcdBCxLBkg1AOtiJ937ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgWmesA7uLi0lX+ZX0jPShH9KD20hlwOnZrgPa0Pvfp/zSucirTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZVignqx3I/v4baVg5CMTTq8dGgoW/QsctbQ9rxZHDSHpMyPdBPIo5AMAT/YK/8j6a2Y=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'
}
reponse = requests.get(url, headers=headers)
# print(reponse.text)
html = BeautifulSoup(reponse.text, 'lxml')
htmls = html.select('div.print main p ')
for j in htmls:
#print(j.text + '\'')
for k in d:
with open(f'{b[urls]}/{k}.txt','a')as f:
f.write(j.text + '\ ')
最后调用函数:
if __name__ == '__main__':
qd()
xz1()
xz2()
好看看效果:
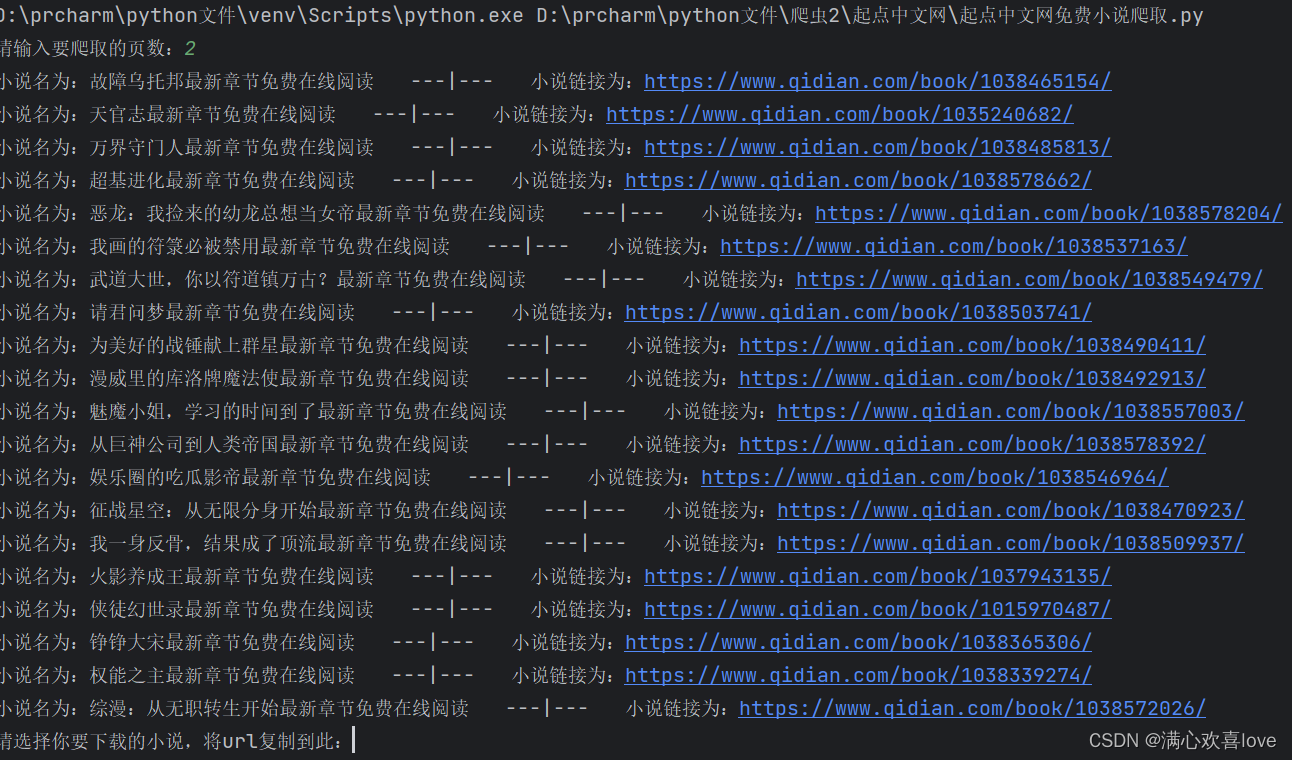
这里我选择爬取两页
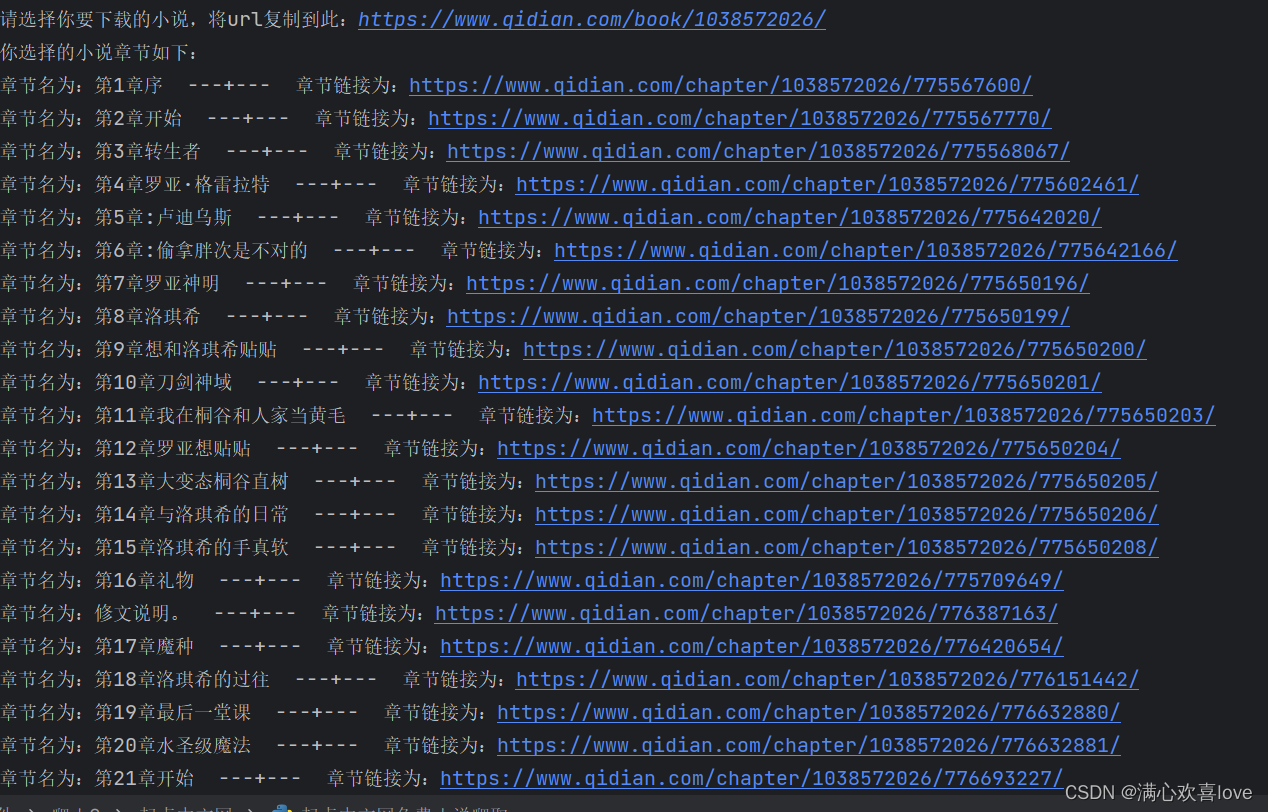
这里我选择的小说为 综漫:从无职转生开始最新章节免费在线阅读
此时正在下载了
完整代码:
import requests
from bs4 import BeautifulSoup
import os
from lxml import etree
a = []#小说链接存储列表
b = []#小说名列表
c = []#小说章节链接列表
d = []#小说章节名列表
def qd():
m = int(input('请输入要爬取的页数:'))
for n in range(m):
url = 'https://www.qidian.com/free/all/page{}/'.format(n)
headers = {
'Cookie': '_yep_uuid=d8b52da3-2e99-6aa7-6f40-b764179d5cd7; supportwebp=true; x-waf-captcha-referer=; _csrfToken=zOBoyYeRJQmHZ9hoQUBiTL2WMoK5X07zciU9oBYG; newstatisticUUID=1718464987_786877310; fu=1199187808; traffic_utm_referer=; Hm_lvt_f00f67093ce2f38f215010b699629083=1718464988; Hm_lpvt_f00f67093ce2f38f215010b699629083=1718464988; _ga_FZMMH98S83=GS1.1.1718464988.1.0.1718464988.0.0.0; _ga_PFYW0QLV3P=GS1.1.1718464988.1.0.1718464988.0.0.0; _ga=GA1.2.1668981357.1718464988; _gid=GA1.2.1024042542.1718464988; _gat_gtag_UA_199934072_2=1; w_tsfp=ltvgWVEE2utBvS0Q6KLtkk+nHj47Z2R7xFw0D+M9Os09CKcnV56F1Yd5vNfldCyCt5Mxutrd9MVxYnGJUtAgfREQRM+Sb5tH1VPHx8NlntdKRQJtA8iOXlEYcr1yujNPKG9ccBS02j4rcdBCxLBkg1AOtiJ937ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgWmesA7uLi0lX+ZX0jPShH9KD20hlwOnZrgPa0Pvfp/zSucirTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZVignqx3I/v4baVg5CMTTq8dGgoW/QsctbQ9rxZHDSHpMyPdBPIo5AMAT/YK/8j6a2Y=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'
}
reponse = requests.get(url, headers=headers)
html = BeautifulSoup(reponse.text, 'lxml')
htmls = html.select('div.main-content-wrap div.all-book-list div.book-img-text ul li h2 a ')
htmlss = html.select('div.main-content-wrap div.all-book-list div.book-img-text ul li p a.name')
for i, k in zip(htmls, htmlss):
a.append('https:' + i['href'])
b.append(i['title'])
print('小说名为:' + i['title'] + ' ---|--- ' + '小说链接为:' + 'https:' + i['href'])
def xz1():
url = input('请选择你要下载的小说,将url复制到此:')
headers = {
'Cookie': '_yep_uuid=d8b52da3-2e99-6aa7-6f40-b764179d5cd7; supportwebp=true; x-waf-captcha-referer=; _csrfToken=zOBoyYeRJQmHZ9hoQUBiTL2WMoK5X07zciU9oBYG; newstatisticUUID=1718464987_786877310; fu=1199187808; traffic_utm_referer=; Hm_lvt_f00f67093ce2f38f215010b699629083=1718464988; Hm_lpvt_f00f67093ce2f38f215010b699629083=1718464988; _ga_FZMMH98S83=GS1.1.1718464988.1.0.1718464988.0.0.0; _ga_PFYW0QLV3P=GS1.1.1718464988.1.0.1718464988.0.0.0; _ga=GA1.2.1668981357.1718464988; _gid=GA1.2.1024042542.1718464988; _gat_gtag_UA_199934072_2=1; w_tsfp=ltvgWVEE2utBvS0Q6KLtkk+nHj47Z2R7xFw0D+M9Os09CKcnV56F1Yd5vNfldCyCt5Mxutrd9MVxYnGJUtAgfREQRM+Sb5tH1VPHx8NlntdKRQJtA8iOXlEYcr1yujNPKG9ccBS02j4rcdBCxLBkg1AOtiJ937ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgWmesA7uLi0lX+ZX0jPShH9KD20hlwOnZrgPa0Pvfp/zSucirTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZVignqx3I/v4baVg5CMTTq8dGgoW/QsctbQ9rxZHDSHpMyPdBPIo5AMAT/YK/8j6a2Y=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'
}
reponse = requests.get(url,headers=headers)
html = BeautifulSoup(reponse.text,'lxml')
htmls = html.select('div.catalog-volume ul li a')
print('你选择的小说章节如下:')
for h in htmls:
print('章节名为:' + h.text + ' ---+--- ' + '章节链接为:' 'https:' + h['href'])
c.append('https:' + h['href'])
d.append(h.text)
global urls
urls = a.index(url)
#print(urls)
if not os.path.exists(b[urls]):
os.makedirs(b[urls])
def xz2():
for i in c:
url = i
headers = {
'Cookie': '_yep_uuid=d8b52da3-2e99-6aa7-6f40-b764179d5cd7; supportwebp=true; x-waf-captcha-referer=; _csrfToken=zOBoyYeRJQmHZ9hoQUBiTL2WMoK5X07zciU9oBYG; newstatisticUUID=1718464987_786877310; fu=1199187808; traffic_utm_referer=; Hm_lvt_f00f67093ce2f38f215010b699629083=1718464988; Hm_lpvt_f00f67093ce2f38f215010b699629083=1718464988; _ga_FZMMH98S83=GS1.1.1718464988.1.0.1718464988.0.0.0; _ga_PFYW0QLV3P=GS1.1.1718464988.1.0.1718464988.0.0.0; _ga=GA1.2.1668981357.1718464988; _gid=GA1.2.1024042542.1718464988; _gat_gtag_UA_199934072_2=1; w_tsfp=ltvgWVEE2utBvS0Q6KLtkk+nHj47Z2R7xFw0D+M9Os09CKcnV56F1Yd5vNfldCyCt5Mxutrd9MVxYnGJUtAgfREQRM+Sb5tH1VPHx8NlntdKRQJtA8iOXlEYcr1yujNPKG9ccBS02j4rcdBCxLBkg1AOtiJ937ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgWmesA7uLi0lX+ZX0jPShH9KD20hlwOnZrgPa0Pvfp/zSucirTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZVignqx3I/v4baVg5CMTTq8dGgoW/QsctbQ9rxZHDSHpMyPdBPIo5AMAT/YK/8j6a2Y=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'
}
reponse = requests.get(url, headers=headers)
# print(reponse.text)
html = BeautifulSoup(reponse.text, 'lxml')
htmls = html.select('div.print main p ')
for j in htmls:
#print(j.text + '\'')
for k in d:
with open(f'{b[urls]}/{k}.txt','a')as f:
f.write(j.text + '\ ')
if __name__ == '__main__':
qd()
xz1()
xz2()
希望能帮助到大家。