SPP-Net是对rcnn的改进,spatial Pyramid Pooling,主要观点:
(1)共用特征卷积图
(2)空间金字塔池化,有效地解决了不同尺度的图片在全连接层输出不一致的问题。
RCNN存在的问题:
(1)RCNN通过对图像的裁剪crop或缩放warp,使得输入图片的信息缺失或变形,降低了图片识别的准确率。
(2)对每个RP进行卷积计算,算力过大。
下图上是RCNN的网络结构,下图下是SPP-net的网络结构。
SPP-net优势:
只对原图进行卷积处理,引入SPP池化进行特征图候选框的维度统一。
以下是转载的相关内容,转载自SPP-Net 是怎么让 CNN 实现输入任意尺寸图像的?
ECCV2014
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
解决的问题: there is a technical issue in the training and testing of the CNNs: the prevalent CNNs require afixedinput image size (e.g., 224*224), which limits both the aspect ratio and the scale of the input image
其实就是CNN的输入尺寸限制问题 ,那么CNN为什么需要固定输入图像的尺寸了?CNN有两部分组成:卷积层和全连接层。卷积层对于图像是没有尺寸限制要求的,全连接层需要固定输入向量的维数,(全连接层输入向量的维数对应全连接层的神经元个数,所以如果输入向量的维数不固定,那么全连接的权值参数个数也是不固定的,这样网络就是变化的。而在卷积层,我们需要学习的是11*11的kernal filter 参数个数是固定的)。这里我们在卷积层后面,全连接层之前加入一层 SPP,用于解决CNN输入固定尺寸的限制问题。
由于之前的大部分CNN模型的输入图像都是固定大小的(大小,长宽比),比如NIPS2012的大小为224X224,而不同大小的输入图像需要通过crop或者warp来生成一个固定大小的图像输入到网络中。这样子就存在问题,1.尺度的选择具有主观性,对于不同的目标,其最适合的尺寸大小可能不一样,2.对于不同的尺寸大小的图像和长宽比的图像,强制变换到固定的大小会损失信息;3.crop的图像可能不包含完整的图像,warp的图像可能导致几何形变。所以说固定输入到网络的图像的大小可能会影响到他们的识别特别是检测的准确率。
那么究竟SPP是怎么解决图像输入尺寸问题的了?
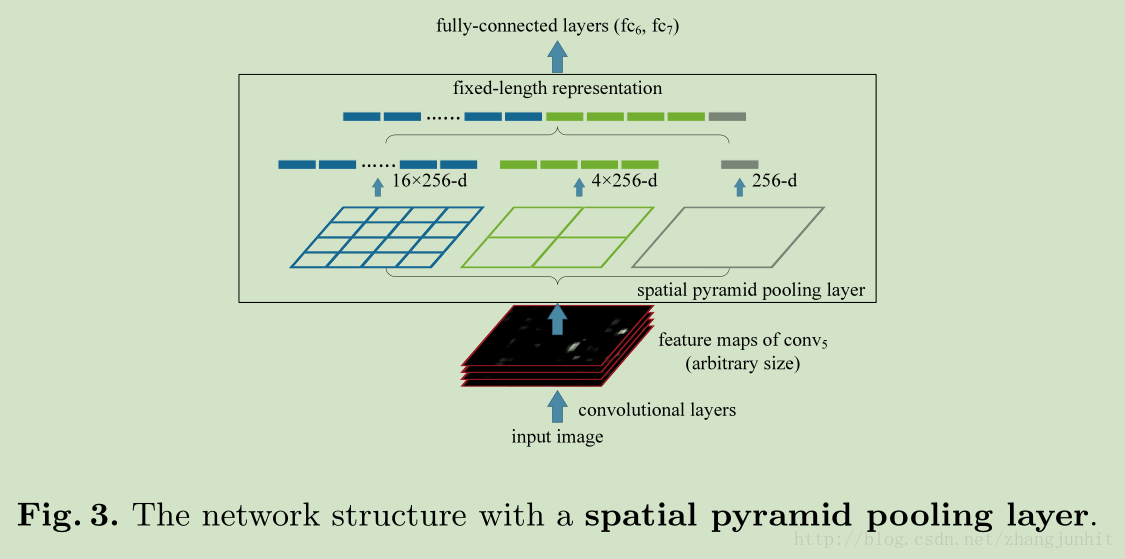
对于任意尺寸图像,卷积层都是可以接受的,多大尺寸进去,多大尺寸出来嘛,所以上面说卷积层对图像尺寸大小不敏感。卷积完之后,我们得到了一组特征图(feature maps), 文中指出 第五卷积层一共有256个滤波器, 所以对应 256个 feature maps。
1)对每个 feature maps 进行 max pooling 操作得到一个输出, 于是256个feature maps,我们都 max pooling,将这256个池化结果组成一个向量,维数是 256。 这就是上图中间部分最右边 256-d 是怎么来的。(d 指 dimension,维度)
2)接下来说中间那个4×256-d,我们将一个 feature map 等分为4块(直观理解就是将一幅图像等分为4块区域,这里是对特征图进行等分)。对每个小块进行max pooling 操作,所以我们从每个特征小块得到一个输出,一个 feature map 就有4个输出,256个 feature maps 就有 4×256-d
3)最左边的 16×256-d,显然就是将一个feature map 等分为16块,256个 feature maps 就有 16×256-d。
如果只进行上面三个步骤,那么我们一共得到向量维数是: 256+4*256+16*256=(21*256)维度。 对于任何输入尺寸图像,经过卷积之后,再用 SPP层处理,我们都会得到这个固定维度的特征向量。这个向量维度固定之后,后面的全连接层就可以固定了,因为神经元个数固定下来了,就是这个向量维度。