背景
在学习本地构建RAG的过程中,embeding是不可避免的一步。在官方的示例文档中,使用的是openAI的embeding模型,这意味着需要先获取openAI key,并且这个过程中会产生计费。对于我们学习研究来说不太友好。因此,考虑下载预训练的模型到本地,然后使用本地的模型来进行embeding,从而避免产生额外费用。
本篇文章主要描述如何下载embeding模型并在langchain下使用embeding模型。
模型选择
目前主流的embeding模型项目包括FlagEmbedding, Ember, GTE and E5。这里我们选择FlagEmbedding作为示例,其他的类似。FlagEmbedding专注于检索增强llm领域,目前包括以下项目:
-
Long-Context LLM: Activation Beacon, LongLLM QLoRA
-
Fine-tuning of LM : LM-Cocktail
-
Embedding Model: Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding
-
Reranker Model: llm rerankers, BGE Reranker
-
Benchmark: C-MTEB
现阶段,我们只需要用到其中的Embedding Model。现有的模型包括:
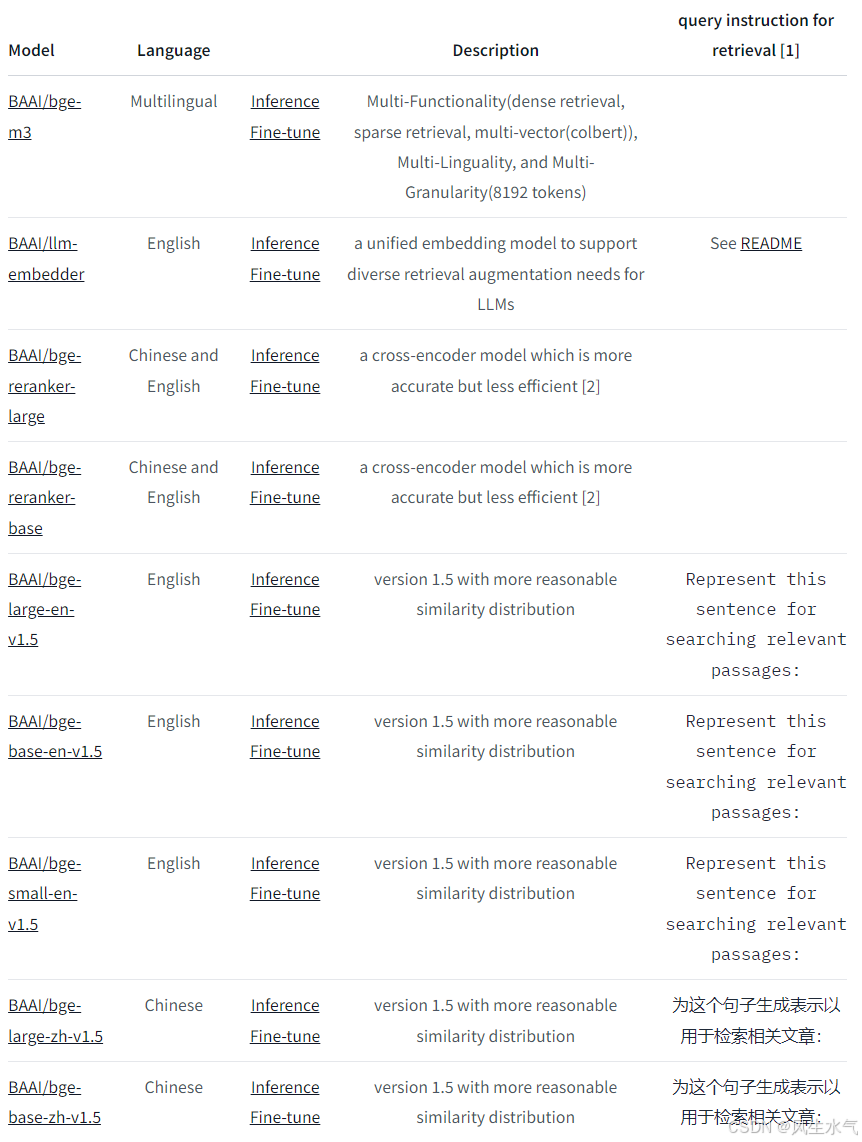
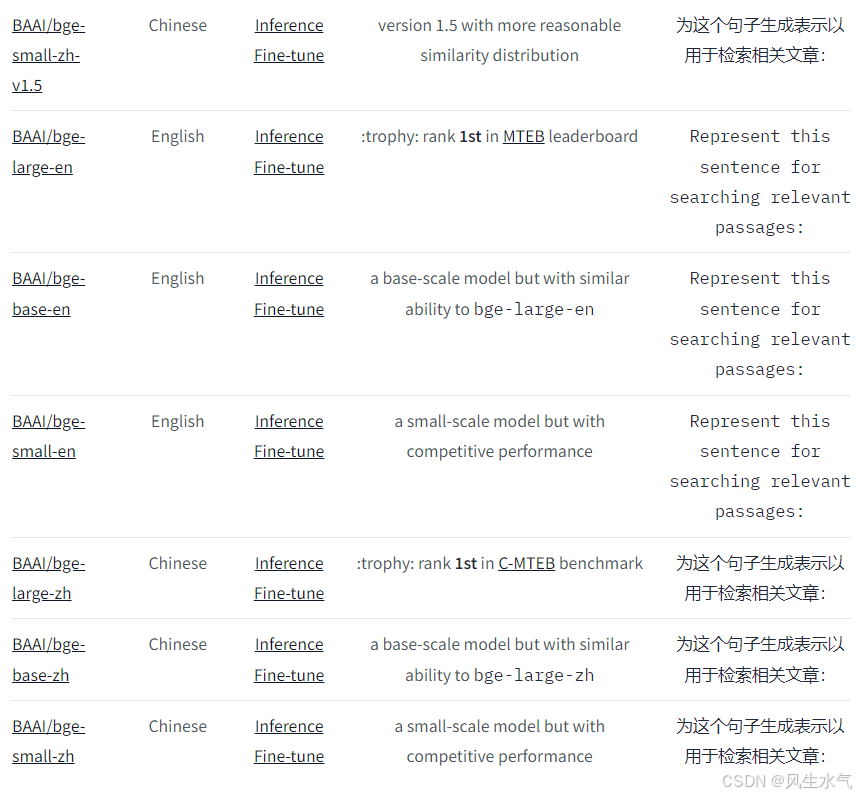
在这里我们选择bge-small-zh-v1.5为例,来进行后续的流程。
模型下载
这里介绍两种模型下载的方法。
AutoModel.from_pretrained
使用transformers库中的AutoModel.from_pretrained方法来下载模型。下面是如何下载bge-small-zh-v1.5模型的代码示例:
from transformers import AutoModel, AutoTokenizer
model_name = "BAAI/bge-small-zh-v1.5"
# 下载模型
model = AutoModel.from_pretrained(model_name)
# 下载分词器
tokenizer = AutoTokenizer.from_pretrained(model_name) 模型的下载可能会花费一些时间和网络流量,具体取决于你的网络速度和模型的大小。模型一旦下载,通常会被缓存在~/.cache/huggingface/transformers目录下,这样在未来的调用中可以快速加载。如果想要自定义安装下载路径,可以
model = AutoModel.from_pretrained(model_name, cache_dir="/path/to/your/cache/directory")可能的问题:ConnectionError: (ProtocolError('Connection aborted.', ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。'。 这种情况一般是因为网络原因无法下载。只能尝试离线手动下载。
官网下载
官网下载的方式需要我们去huggingface的官网去进行下载,国内可以去hf-mirror.com 镜像网站去下载,以上述模型为例。搜索到相应模型后,切换到第二个tab,然后点击下载按钮进行下载。
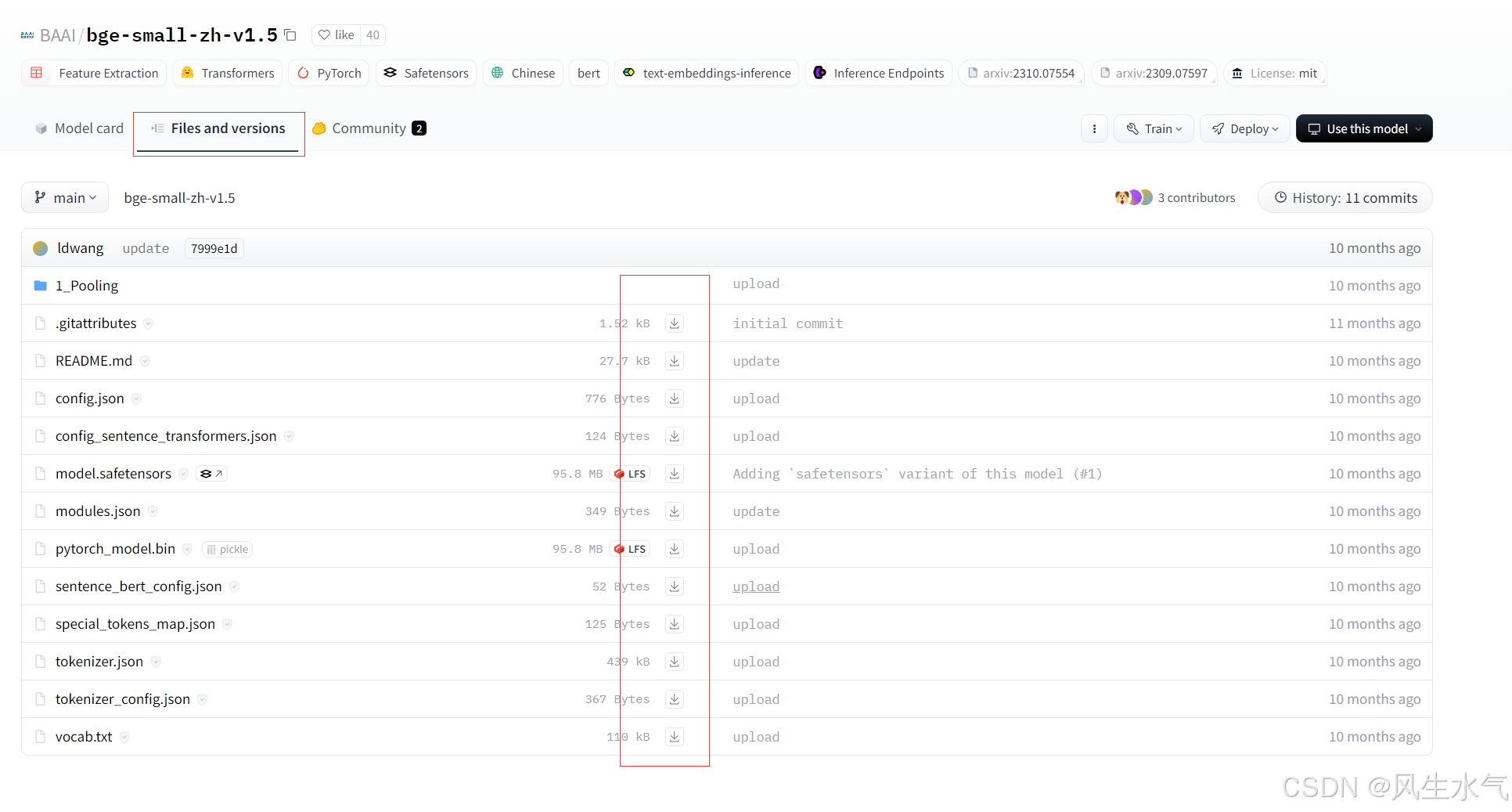
下载完成后将相关文件放到同一个目录下。以我的电脑为例,将下载的文件放置到D:\model\embeding\bge-small-zh-v1.5目录下,之后在构建向量数据库的时候通过下面方式进行引用
vectorstore = Chroma.from_documents(documents=splits, embedding=HuggingFaceEmbeddings(model_name='D:\\model\\embeding\\bge-small-zh-v1.5'))参考文档
-
https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md
-
https://hf-mirror.com/BAAI/bge-large-zh-v1.5
-
https://blog.csdn.net/weixin_41862755/article/details/120686480