翻译
摘要
汉语拼写检查(CSC)是检测和纠正汉语自然语言拼写错误的一项任务。现有的方法试图将汉字之间的相似性知识融合起来。然而,它们将相似性知识作为外部输入资源或者仅仅作为启发式规则。本文将语音和视觉相似性知识引入汉语拼写检查(CSC)语言模型中。模型在字符上构建一个图,然后SpellGCN学习将该图映射到一组互相依赖的字符分类器中。这些分类器应用于由另一网络(例如BERT)提取的表示,使得整个网络能够端到端可训练。在人类标注数据集上进行的实验表明,我们的方法比以前的模型具有更好的性能。
- 导言
拼写错误在我们的日常生活中很常见,通常由人写、自动语音识别和光学字符识别系统引起。在这些错误中,由于字符之间的相似性,字符拼写错误经常发生。在汉语中,许多字符在语音和视觉上相似,但在语义上却截然不同。根据Liu等人(2010年),约83%的错误与语音相似性相关,48%与视觉相似性相关。中文拼写检查(CSC)的任务旨在检测和纠正这种滥用中文语言的行为。尽管最近的发展,中文的拼写检查(CSC)仍然是一个挑战性的任务。值得注意的是,中文的拼写检查与英文有很大的不同,因为汉语是由许

多象形文字组成的语言,没有定界词。每个字符的意义随着上下文的变化而急剧变化。因此,中文拼写检查(CSC)系统需要识别语义,并聚合周围的信息,以便进行必要的修改。
以前的方法遵循生成模型的路线。他们使用语言模型(Liu等人,2013年,2010年;Yu和Li,2014年)或顺序到顺序模型(Wang等人,2019年)。为了融合字符之间相似性的外部知识,他们中的一些人利用混淆集,该混淆集包含一组类似的字符对。例如,Yu和Li(2014)提出通过检索混淆集来生成几个候选,然后通过语言模型过滤它们。Wang等人(2019)使用指针网络从混淆集复制类似的字符。这些方法试图利用相似性信息来限制候选者,而不是显式地建模字符之间的关系。
本文提出了一种新的拼写检查卷积图网络(SpellGCN),它考虑了字符的发音/形状相似性,并探讨了字符之间的先验依赖关系。具体地,针对发音和形状关系构造两个相似图。SpellGCN将图形作为输入,并在相似字符交互之后为每个字符生成向量表示。然后将这些表示构造为用于从另一骨干模块提取的语义表示的字符分类器。由于其强大的语义能力,由于BERT的强大能力, 我们使用BERT(Devlin等,2019)来结合图形表示,使得SpellGCN可以利用相似性知识,并相应地生成正确的校正。关于表1中的示例,SpellGCN能够在发音约束内正确地修改句子。
在三个开放基准上进行了试验。结果表明,SpellGCN显著地提高了误码率,大大优于所有竞争模型。
总之,我们的贡献如下:
- 我们提出了一种新型的端到端可训练SpellGCN,将语音和形状相似性整合到语义空间中。本文详细研究了其特殊的图卷积和注意组合运算等基本组成部分。
- 对SpellGCN的性能进行了定性和定量研究。实验结果表明,该方法在三个基准数据集上达到了最佳效果。
- 相关工作
中文拼写检查(CSC)是一个长期存在的问题,引起了社会的广泛关注。近年来,该研究与其他主题一起出现,例如语法错误校正(GEC)(Rao等人,2018;Ji等人,2017;Chollanmpatt等人,2016;Ge等人,2018)。中文拼写检查(CSC)的重点是检测和纠正字符错误,而GEC还包括需要删除和插入的错误。之前的工作使用无监督的语言模型处理中文拼写检查(CSC)(Liu等人,2013;Yu和Li,2014)。通过评估句子/短语的困惑来检测/校正错误。然而,这些模型不能对输入句子进行修正。为了避免这个问题,汉字拼写检查(CSC)采用了几种鉴别序列标记方法(Wang等人,2018)。为了更大的灵活性和更好的性能,还采用了若干个序列到序列模型(Wang等,2019;Ji等,2017;Chollampatt等,2016;Ge等,2018)以及BERT(Hong等,2019)。
近年来,人们开始注意利用人物相似性的外部知识。相似性知识可被收集到字典,即混淆集,其中存储相似对。俞敏洪和李(2014)首先使用字典来检索类似的候选词以发现潜在的错误。Wang等人(2019)将复制机制并入递归神经模型。当给定类似字符作为输入时,它们的模型使用复制机制来直接将字符复制到目标句子。在某种意义上,由于相似性信息仅用于候选选择,所以这些模型难以对相似字符之间的关系建模。为了捕获发音/形状相似性并探索字符之间的先验依赖性,我们提出使用图卷积网络(GCN)(Kipf和Welling,2017)来建模字符间依赖性,其结合BERT的预训练(Devlin等,2019;Cheng等,2019)用于中文拼写检查(CSC)任务。
GCN已应用于多个任务的关系建模。Yan等人(2019)将其装备到关系提取任务中,其中关系构造分层树。Li等人(2018年);Cheng等人(2018年)用它来模拟时空来预测交通流。GCN还用于建模多标签任务中的标签之间的关系(Chen等人,2019)。本文首次将GCN成功地应用于汉语拼写检查(CSC)任务中。中文拼写检查(CSC)中的关系与图中的对象语义相关的任务有很大不同。相比之下,在汉语拼写检查(CSC)中,相似字符在语义上是截然不同的。因此,我们深入研究了SpellGCN的作用,并提出了一些基本技术。
- 方法
在本节中,我们详细阐述了中文拼写检查(CSC)的方法。首先,给出了问题的表达式。然后,我们介绍了SpellGCN的动机,随后对其做了详细描述。最后,介绍了它在中文拼写检查任务中的应用。
3.1 问题的表达式
中文拼写检查任务旨在检测和纠正中文错误。当给定文本序列
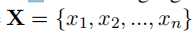
,}由n个字符组成,模型以X作为输入并输出目标字符序列
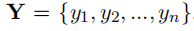
。通过对条件概率p(Y|X)的建模和令其最大化,将任务表示为条件生成问题。
- 动机
所提出的方法的框架如图1所示,它由两个组件组成,即字符表示提取器和SpellGCN。提取器为每个字符导出表示向量。在提取器之上,SpellGCN用于建模字符之间的相互依赖关系。它输出包含交互后相似字符信息的目标向量。
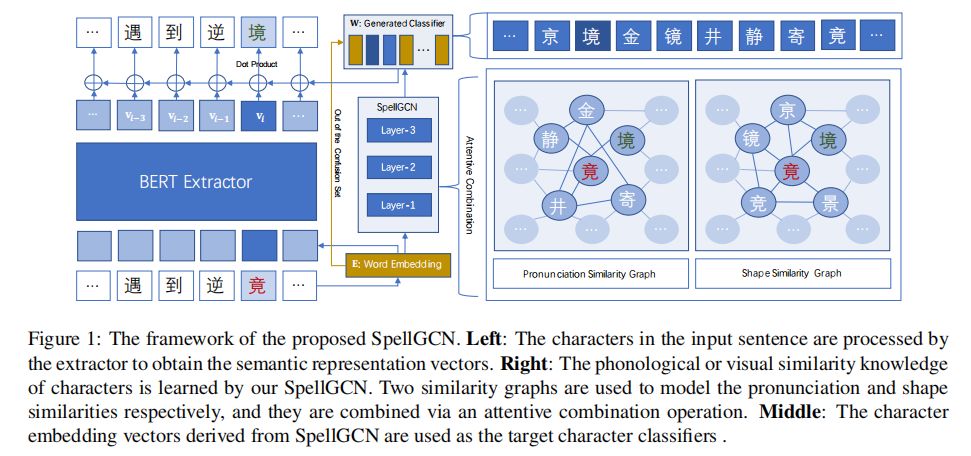
如表1所示,普通的语言模型能够在语义上提供可行的校正,但是在满足发音约束方面面临困难。虽然更正

在语义上是合理的发音,但是它的发音与
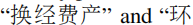
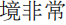
还是不同的,这表明字符之间的相似性信息是必要的,以便模型能够学习生成相关的答案。以前的方法已经考虑了相似性。然而,他们通常将相似的字符做为潜在的候选者,而忽略了他们在发音和形状上的相互关系。本文试图将符号空间(语音和视觉相似性知识)和语义空间(语言语义知识)融合到一个模型中去,初步尝试解决这一问题。为此,我们利用图神经网络(GNN)直接融合相似知识。基本思想是通过在类似字符之间聚集信息来更新表示。直观地,模型在使用我们的方法时,很可能具有类似的符号感。
在各种GNN模型之中,我们在实现时选择了GCN。由于图中有多达5K的汉字,所以轻量级GCN更适合我们的问题。所提出的SpellGCN详细描述如下。
3.3 SpellGCN架构
SpellGCN需要两个相似图
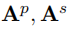
来表示发音和形状的相似性。为了简单起见,如果不必要的话,将省略上标,并且A表示这两个相似图中的一个。每个相似图是

大小的二进制相邻矩阵,由混淆集中的N个字符构成。第i字符和第j字符之间的边缘

表示混淆集中是否存在(i,j)对。 SpellGCN的目标是学习一个映射函数,通过A定义的卷积运算,将第l层的输入节点嵌入

(其中D是字符嵌入的维数)映射到一个新的表示
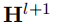
。
图卷积运算图卷积运算 图卷积运算图卷积运算是吸收图中相邻字符的信息。在每一层中,采用GCN中的轻量级卷积层(Kipf和Welling,2017):
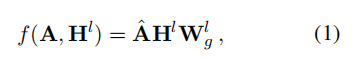
其中,
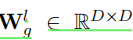
是可训练的矩阵,而
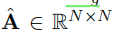
是相邻矩阵A的正规化版本。注意,我们使用BERT的特征嵌入作为初始节点特征H°,并且省略了卷积后的非线性函数。由于我们采用BERT作为提取器,该提取器具有自己的学习语义空间,所以我们从方程中移除激活函数,以保持导出的表示与原始空间相同,而不是完全不同的空间。在我们的实验中,使用诸如ReLU的非线性激活是无效的,导致性能下降。
注意图组合操作图卷积操作 注意图组合操作图卷积操作处理单个图的相似性。为了结合发音和形状相似图,采用了注意机制(Bahdanau等人,2015)。对于每个字符,我们表示组合操作如下:
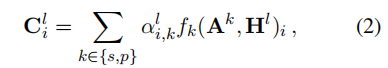
其中
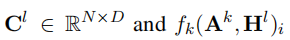
是图k的第i行卷积表示,
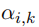
是表示图k权重的第i字符的标量。该权重计算如下
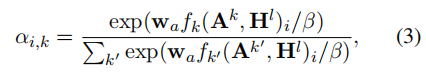
其中,
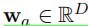
是跨层共享的可学习向量,并且
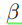
是控制注意力权重的平滑度的超参数。我们发现
对注意机制至关重要)。
累积输出 经过图卷积和细致的组合运算,得到l-th层的表示
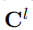
。为了保持提取器的原始语义,累积先前层的所有输出作为输出:
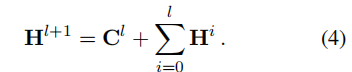
通过这种方式,SpellGCN能够专注于捕获字符相似性的知识,将语义推理的责任留给提取器。希望每个层可以学习聚合特定跳的信息。在实验过程中,模型在排除H°时失效。
- SpellGCN应用于汉语拼写检查
在这里,我们将介绍如何将SpellGCN应用于中文拼写检查(CSC)任务。受最近GCN在关系建模中的应用的推动(Chen等,2019;Yan等,2019),我们使用SpellGCN的最终输出作为目标字符的分类器。
从混淆集中获取相似图 SpellGCN中使用的相似图是从(Wu等,2013)中提供的混淆集构造的。汉字大部分(~95%)是由相似字符组成的一组预定义字符,这些字符分为五类,即(1)相似形状,(2)相同发音和同音,(3)相同发音和不同音,(4)相似发音和同音,(5)相似发音和不同音。由于发音相似度比形状相似度更细粒度,我们将发音相似度组合成一个图。因此,我们构造了与发音和形状相似性相对应的两个图。
基于提取器的字符表示 字符由提取器表示用于最终分类的字符由提取器给出。我们可以使用能够输出n个表示向量
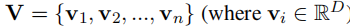
来表示n个输入字符

。在我们的实验中,采用BERT作为骨干模型。以X为输入,最后层的输出为V。我们用基础版进行实验,该基础版有12层,12个隐藏尺寸为7682的自注意力头。
将Spell GCN做为字符分类器 当给定字符Xi的表示向量vi时,模型需要通过完全连接层预测目标字符,该完全连接层的权重
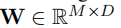
,由SpellGCN的输出配置(M是提取器词汇表的大小):
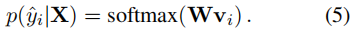
具体来说,SpellGCN的输出向量起着分类器的作用。我们使用SpellGCNHL的最后一层的输出(其中L是层数)对混淆集中的字符进行分类。由于混淆集只覆盖词汇表的一个子集,所以我们使用提取器的单词嵌入作为混淆集排除的分类器。这样,表示
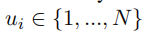
是提取器词汇表中第i个字符的混淆集的索引,W由下式表示:

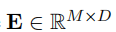
是提取器的嵌入矩阵。简言之,如果字符在混淆集中,则使用SpellGCN的嵌入。否则,嵌入向量与BERT一样使用。为了计算效率,我们选择了这个实现而不是对包含提取器词汇表中所有字符的大型紧凑图建模,因为在混淆集中有大约5K个字符,在提取器词汇表中有大于20K个字符。
总体而言,目标是最大化目标字符的对数可能性:
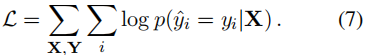
- 预测推理
中文拼写检查(CSC)任务由两个子任务组成,即检测和校正。以前的一些工作(Yu和Li,2014;Liu等人,2013)分别使用了两个模型来执行这些子任务。在本文中,我们简单地使用具有最高概率
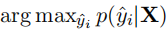
的字符作为校正任务的预测。并且,通过检查预测是否匹配目标字符yi来实现检测。
- 实验实验
在本节中,我们详细描述了我们的实验。我们首先呈现训练数据和测试数据以及评估度量。然后介绍SpellGCN的主要结果。之后,进行消融研究以分析所提议的部件的效果,随后进行个案研究。最后给出了定量结果。

4.1 数据集
训练数据 由三个训练数据集组成(Wu等人,2013年;Yu等人,2014年;Tseng等人,2015年),总共有10K数据样本。随后(Wang等,2019),我们还包括额外的27IK样本作为训练数据,其通过自动方法(Wang等,2018)3生成。
测试数据 为了评估所提出方法的性能,我们使用来自SIGHAN 2013、SIGHAN 2014、SIGHAN 2015基准的三个测试数据集(Wu等人,2013;Yu等人,2014;Tseng等人,2015)(Wang等人,2019)。我们还遵循相同的数据预处理过程,即使用OpenCC 4将这些数据集中的字符转换为简体中文。数据的统计列于表2。
基准模型 我们比较了我们的方法和五个典型的基线。
•LMC(Xie等人,2015):该方法利用混淆集来替换字符,然后通过Ngram语言模型来评估修改后的句子。
·SL(Wang等人,2018):该方法提出了一种流水线,其中采用序列标记模型进行检测。不正确的字符被标记为1(0)。
- PN(Wang等人,2019):该方法结合指针网络来考虑来自混淆集的额外候选者。
- FASpell(Hong等人,2019):该模型利用基于相似性度量的专门候选选择方法。该度量使用一些经验方法测量,例如,编辑距离,而不是预定义的混淆集。
·BERT(Devlin等,2019):对于中文拼写检查(CSC)务,将字嵌入用作BERT顶部的软最大层。我们使来训练这个模型。
超参数
我们的代码是基于BERT的存储库。我们使用AdamW(Loshchilov和Hutter,2018)优化器对模型进行6个epoch的微调,批量大小为32,学习率为5e-5。在SpellGCN中,层数为2,使用与因子3的仔细组合操作。所有实验进行4次,并报告平均度量。代码和经过训练的模型将在审查后公开发布(目前,代码附加在补充文件中)
评估度量 精度评分、召回评分和Fl评分作为评估度量,常用于中文拼写检查(CSC)任务。这些度量被提供用于检测和校正子任务。除了对字符级别的评估外,我们还报告了检测与校正子任务的句子级别度量,这对现实世界的应用更有吸引力。在句子层面上,我们认为只有当句子中的所有错误都像在(Hong等,2019)5中那样被纠正时,句子才被正确地注释。在字符级别上,我们使用来自(Wang等,2019)6的评估脚本来计算度量。我们还通过官方评估度量工具7对BERT和SpellGCN进行了评估,它们给出了虚正率(FTR)、准确度和精确度/recall/F1。
4.3 主要结论
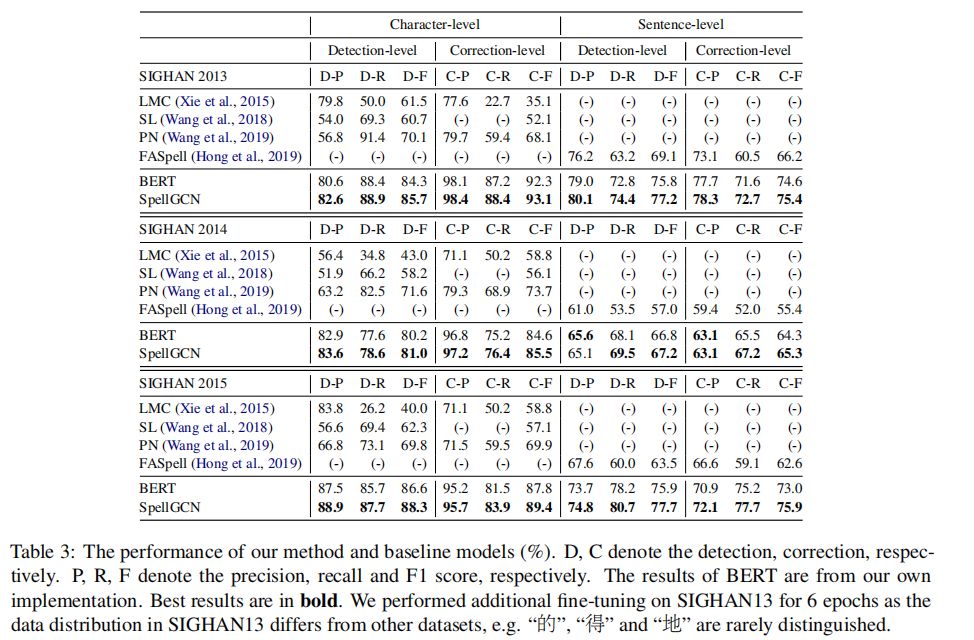
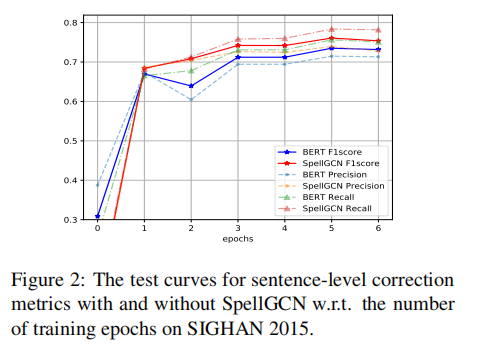
表3显示了与五个典型的中文拼写检查(CSC)系统相比,所提出的方法在三个中文拼写检查(CSC)数据集上的性能。当使用SpellGCN时,该模型在普通的BERT的所有测试集中都取得了较好的效果,验证了模型的有效性。有了如此大量的培训数据(参见图2中的比较),情况有了很大的改善。这表明相似知识对于汉语拼写检查(CSC)是必不可少的,通过简单地增加数据量很难获得相似知识。在校正子任务中的句子级Fl评分度量(即最后一栏中的C-F评分)方面,相对于先前最佳结果(FASPell)的改进分别为9.2%、9.7%和13.3%。然而,应当指出,FASpell接受了关于不同培训数据的培训,而本文遵循PN论文中提到的设置(Wang等人,2019年)。理想情况下,我们的方法与FASpell兼容,当使用FASpell时可以获得更好的结果。
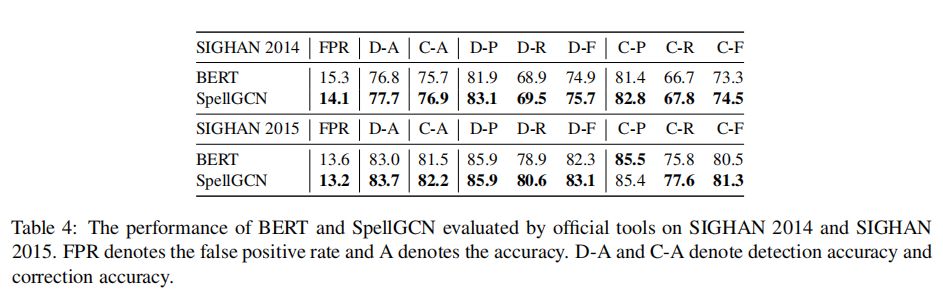
FASpell使用了他们自己的度量,这些度量不同于官方评估工具包的句子级假后置和假否定计数策略。我们使用PGNet和FASpell的脚本来计算它们的度量,以便进行公平的比较。我们还将BERT和SpellGCN的官方评估结果添加到表4中。实际上,SpellGCN在通过PGNet/FASpell脚本和官方评估工具包进行评估时始终能够提高性能。我们将在我们的修订中增加FPR结果。在SIGHAN 14上,FPR评分为14.1%(SpellGCN)vs.15.3%(BERT),在SIGHAN 15上,FPR评分为13.2%(SpellGCN)vs.13.6%(BERT)。SIGHAN13上的FPR在统计上是毫无意义的,因为几乎所有测试的句子都有拼写错误。
4.4 消融研究
在本小节中,我们分析了几个因素的影响,包括层数和注意机制。使用10K训练数据进行消融实验。
层数的影响 一般而言,GCN的性能随层数而变化。我们研究SpellGCN层的数量如何影响汉语拼写检查(CSC)的性能。在这个比较中,层数从1变为4,结果如图3所示。为了清楚起见,我们在三个测试数据集上报告字符级C-F。结果表明,SpellGCN能够利用多层结构。使用多层,SpellGCN可以在更多的跳中聚集信息,从而获得更好的性能。然而,当层数大于3时,Fl得分下降。这是合理的,正如(Yan等人,2019)中提到的过平滑问题。当GCN层的数目增加时,相似性图中相邻字符的表示将变得越来越相似,因为它们都通过相似性图中相邻字符的表示来计算。
注意机制的影响 我们研究如何更好地结合SpellGCN层中的图。这里,我们比较了不同超参数
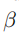
(3.3节中提到的)的注意机制与和池和平均池化操作。实验是基于SIGHAN2013测试集上的2层SpellGCN进行的。表5中给出的结果表明,sum pooling操作在中文拼写检查(CSC)任务中失败。所以我们提出的sum pooling与 规范化的CSC中的不一致,并且不能组合来自不同通道(即图)的信息。平均集合是可行的,但被注意机制所超越。这表明每个字符节点的自适应组合是有益的。我们将超参数
结合到注意操作中,因为点积可能增长大,将softmax函数推入具有极小梯度的区域。根据这些结果,我们选择了在SpellGCN中具有
=3的注意机制。

4.5 个案研究
我们由SpellGCN的几个校正结果,证明模型的有效性。除了表1所示的样本之外,在表6中给出若干预测结果。从这些案例中,我们可以看出我们的SpellGCN能够在发音和形状约束下将错误的字符修改为正确的字符。例如,在第一种情况下,“
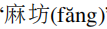
”被检测为错误并修改为“

)”。没有语音相似性限制,“
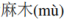
”成为最可能的答案。令人惊讶的是,在第二种情况下,我们的SpellGCN成功地修改了上下文中的字符。输入句子的意思

,我们的方法把它改正意思是“看录影机”。我们认为SpellGCN在表示空间之间和表示空间中注入一个先验相似度,以便模型得到更高的后验概率。最后给出了形状约束下的修正结果。在最后的一个例子中,我们展示了一个基于字形限制的例子,在混淆集中,“向”与“尚”类似,因此,使用 SpellGCN 可以检索正确的结果。

4.6 字符嵌入可视化
以前的实验对SpellGCN的性能进行了定量的探讨。为了定性地研究SpellGCN是否学习有意义的表示,我们深入研究了从SpellGCN导出的目标嵌入空间W。
在图4中,使用t-SNE呈现了字母
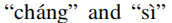
的字符嵌入(Maaten和Hinton,2008)。嵌入向量由BERT学习得到语义相似性,但未能针对汉语拼写检查(CSC)任务在语音方面建模相似性。这是合理的,因为在建模中缺少这种相似性知识。相反,我们的SpellGCN成功地将这个先验知识注入到嵌入中,由此产生的嵌入呈现集群模式。这两个不同发音的字符嵌入形成两个簇,分别对应于
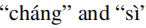
。由于这个属性,模型倾向于识别相似的字符,因此能够在发音约束下检索答案。图5显示了形状相似性的相同情况,其中两个形状类似于
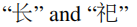
字符集是分散的。这验证了SpellGCN建模形状相似性的能力。

- 结论
我们提出了用于汉语拼写检查(CSC)的SpellGCN,以将语音和视觉相似性结合到语言模型中。通过实验比较和分析实验结果验证了该方法的有效性。除了汉语拼写检查(CSC)之外,SpellGCN还可以推广到已有特定先验知识的其他情况,也可以通过类比使用特定相似图来推广到其他语言。我们的方法还可以通过利用诸如Levenshtein Transformer(Gu等,2019)的更灵活的提取器来适应需要插入和删除的语法纠错。我们将这个方向留给今后的工作。
参考文献
Dzmitry Bahdanau、Kyunghyun Cho和Yoshua Ben-gio。神经机器翻译通过联合学习对齐和翻译。第三次国际学习代表会议,ICLR 2015,圣地亚哥,美国加利福尼亚州,2015年5月7日至9日,会议轨道会议记录。
陈兆敏,秀神伟,王鹏和郭燕文。2019年。基于卷积网络的多标签图像识别。在IEEE计算机视觉会议。模式识别,CVPR 2019,美国加利福尼亚州长滩,2019年6月16日至20日,第5177-5186页。
星艺城,徐伟迪,陈昆龙,王伟,毕斌,明燕,吴晨,罗思,楚伟和王太丰。2019。基于对称正则化的双向语义推理的BERT。CoRR, abs/1909.03405。
郑兴义,张瑞清,周杰,徐伟。
- 深度交通:学习交通状况预测的时空依赖性。2018年国际神经网络联席会议,2018年,巴西里约热内卢,2018年7月8日至13日,第1至8页。IEEE。
Shamil Chollampatt、Kaveh Taghipour和Hwee Tou Ng。用于语法错误纠正的神经网络翻译模型。《第二十五次人工智能问题国际联席会议记录,IJCAI2016,2016年7月9日至15日,美国纽约州,纽约》,第2768-2774页。
Jacob Devlin, Ming-Wei Chang, Kenton Lee和Kristina Toutanova。BERT:对深层双向变压器进行语言理解预训练。计算语言学协会北美分会2019年会议记录:人类语言技术,NAACL-HLT 2019,明尼阿波利斯,美国明尼阿波利斯,2019年6月2日至7日,第1卷(长短文),第4171-4186页。
加布里埃尔·朴昌凤、马克西姆·德博斯谢尔、王定民、博利、朱佳和王锦辉。NLPTEA2017共享任务-中文拼写检查。第四期教育应用自然语言处理技术研讨会论文集,NLP-TEA@IJCNLP 2017,台湾台北,2017年12月1日,第29-34页。
陶革,芙蓉薇,明周。2018。流利性促进神经语法错误纠正的学习和推理。在计算语言学协会第56届年会记录中,ACL 2018,澳大利亚墨尔本,1520年7月,2018年,第1卷:长篇论文,第1055-1065页。
顾家涛,王长汉,赵杰克。2019。变压器。CoRR, abs/1905.11006。
余中红,祥国宇,嫩河,刘楠,刘俊辉。2019。Faspell:基于后台解码器范式的快速、适应性强、简单、强大的中文拼写检查器。在第五期关于噪声用户生成文本(W-NUT 2019)讲习班记录中,第160-169页。
季建树、王秦龙、图塔诺娃、龚永恩、张史蒂文、高建峰。2017年。一种用于语法纠错的嵌套注意神经混合模型。在计算语言学协会第55届年会记录中,ACL 2017,加拿大温哥华,7月30日至8月4日,第1卷:长篇论文,第753-762页。
贾仲业、王佩璐、赵海等。中文拼写检查的图形模型。《第七届SIGHAN中文处理讲习班论文集》,SIGHAN@IJCNLP,2013年10月14日至18日,日本名古屋,第88-92页。
托马斯·基普夫和马克斯·韦林。卷积网络的半监督分类。第五届国际学习代表会议,ICLR 2017,法国图伦,2017年4月24日至26日,会议轨道会议。
李京,彭浩,刘琳,熊贵熙,杜伯贤,马宏源,王力宏,和夫人。Zakirul Alam Bhuiyan.2018。城市交通客流预测的图形。2018年,IEEE SmartWorld, Ubiquity Intelligence&Computing, Advanced&Trusted Computing, Scalable Computing&Communications, Cloud&Big Data Computing, Internet of People and Smart City Innovation, Smart-World/SCIC/ATC/CBDCom/IOP/IOP/SCI 2018, 2018, 广州, 2018, 2018, 2018年10月8-12页,29-36。IEEE。
刘超林,赖敏华,庄一宣,李嘉颖。2010。在视觉和语音上相似的字符在错误的简体中文。2010年COLING,第23届计算语言学国际会议,海报卷,2010年8月23日至27日,中国北京,第739-747页。
刘小东、程凯文、罗燕燕、杜凯文、松本裕二。使用语言模型和统计机器翻译与重新排序的混合汉语拼写校正。《第七届SIGHAN中文处理讲习班论文集》,SIGHAN@IJCNLP,2013年10月14日至18日,日本名古屋,第54至58页。
伊利亚·洛希洛夫和弗兰克·哈特。解耦重量衰减正则化。
Laurens van der Maaten和Geoffrey Hinton.2008。使用t-sne可视化数据。机器学习研究杂志,9(11月):2579-2605。
高桥饶、祁公、张宝琳、恩东迅。2018年。NLPTEA-2018共享任务汉语语法错误诊断概述。在NLP-TEA@ACL 2018年第5期教育应用自然语言处理技术讲习班记录中,
- 第42-51页。
曾俊欣,李龙浩,张立平,陈新喜。2015。SIGHAN 2015中文拼写检查介绍。《第八届SIGHAN中文处理工作会议记录》,SIGHAN@IJCNLP 2015,中国北京,2015年7月30日至31日,第3237页。
王定民,严松,李京,韩嘉龙,张海松。2018。一种用于中文拼写检查的自动语料库生成混合方法。2018年自然语言处理经验方法会议记录,比利时布鲁塞尔,2018年10月31日至11月4日,第2517-2527页。
王定民,李泰和李忠。2019年。用于中文拼写检查的模糊集引导指针网络。计算语言学协会第57次会议记录,ACL 2019,意大利佛罗伦萨,7月28日至8月2日,
- 第1卷:长篇论文,第5780-5785页。
吴世雄,刘超林,李龙浩。2013年SIGHAN bake-off中文拼写检查评估。《第七届SIGHAN中文处理讲习班论文集》,SIGHAN@IJCNLP,2013年10月14日至18日,日本名古屋,第35-42页。
谢伟健,黄佩杰,张新瑞,洪开铎,黄羌,陈炳州,和雷黄。基于n-gram模型的中文拼写检查系统。《第八届SIGHAN中文处理工作会议记录》,SIGHAN@IJCNLP 2015,中国北京,2015年7月30日至31日,第128-136页。
杨欣,海兆,王玉竹,和贾中业。一种改进的中文拼写检查图形模型。《第三次CIPS-SIGHAN中文处理联席会议记录,2014年10月20日至21日,中国武汉》,第157-166页。
严浩然、金小龙、孟祥滨、郭嘉峰、程学启。2019年。多阶卷积和聚集注意力的事件检测。2019年自然语言处理经验方法会议和第九次自然语言处理国际联席会议记录,第5770-5774页。
余俊杰和李正华。基于语言模型、发音和形状的汉语拼写错误检测和纠正。在
第三届CIPS-SIGHAN中文处理联席会议,2014年10月20日至21日,中国武汉,第220-223页。
梁智瑜,李龙浩,曾俊欣,陈新喜。2014。SIGHAN2014中文拼写检查概要。《第三次CIPS-SIGHAN中文处理联席会议记录》,2014年10月20日至21日,中国武汉,第126-132页。
表3显示了与五个典型的中文拼写检查(CSC)系统相比,所提出的方法在三个中文拼写检查(CSC)数据集上的性能。当使用SpellGCN时,该模型在针对vanillaBERT的所有测试集中都取得了较好的效果,验证了模型的有效性。有了如此大量的培训数据(参见图2中的比较),情况有了很大的改善。这表明相似知识对于汉语拼写检查(CSC)是必不可少的,通过简单地增加数据量很难获得相似知识。在校正子任务中的句子级Fl评分度量(即最后一栏中的C-F评分)方面,相对于先前最佳结果(FASPell)的改进分别为9.2%、9.7%和13.3%。然而,应当指出,FASpell接受了关于不同培训数据的培训,而本文遵循PN文件中提到的设置(Wang等人,2019年)。理想情况下,我们的方法与FASpell兼容,当使用FASpell时可以获得更好的结果。
FASpell使用了他们自己的度量,这些度量不同于官方评估工具包的句子级假后置和假否定计数策略。我们使用PGNet和FASpell的脚本来计算它们的度量,以便进行公平的比较。我们还将BERT和SpellGCN的官方评估结果添加到表4中。实际上,SpellGCN在通过PGNet/FASpell脚本和官方评估工具包进行评估时始终能够提高性能。我们将在我们的修订中增加FPR结果。在SIGHAN 14上,FPR评分为14.1%(SpellGCN)vs.15.3%(BERT),在SIGHAN 15上,FPR评分为13.2%(SpellGCN)vs.13.6%(BERT)。SIGHAN13上的FPR在统计上是毫无意义的,因为几乎所有测试的句子都有拼写错误。