数仓设计指对数据仓库的各项组成进行规划,在正式建设数仓之前形成指导性建设方案。
数仓设计主要分为两部分:数据仓库同操作型业务系统的数据接口设计和数仓自身建设设计。
本文从多个方面探讨数仓的设计要点,给出需要注意的问题,提供部分实践建议。
1. 体系结构
体系结构从整体描述数仓,是数仓的数据架构,包括数据导入、ETL、数仓建设、OLAP引擎以及数据的最终使用。
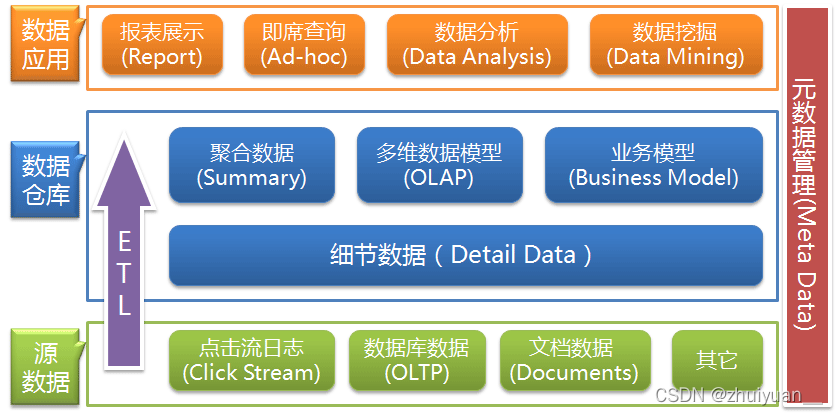
上图是一个典型的数仓体系结构。源数据经过ETL,在数仓中建设存储,被下游分析使用。元数据则被用来说明数据、管理数据。
整个体系中,包括数据的抽取、模型建设、数据加工、数据导出、数据服务以及数据的生命周期管理,这些数仓设计要素将在下文中详解。
2. 粒度
含义
粒度指数仓中数据的细节程度或综合程度的级别,通俗讲是表中每行代表的含义。Bill Inmon认为粒度是数仓设计中最重要的设计问题,这点让我有些意外,但是看完他的解释也就理解了。粒度不仅影响数仓数据量的大小,还决定数仓的查询能力以及查询性能。
粒度可以分为低粒度和高粒度,低粒度是指保存了所有数据细节,高粒度则忽略部分细节,对数据做一定聚合。
示例
比如,某通信运营商希望存储用户的通话记录。
如果用户每次通话记录在表中存储一行,每行保存用户的通话时长、通话开始/结束时间、被叫人、主叫地点、被叫地点、通话费用,该方式保存用户通话的明细,属于低粒度的保存方式。
另一种保存用户每天的通话记录,每行存储用户当天通话次数、总通话时长、总通话费用等,该方式针对用户当天的通话记录做适当的聚合汇总,称为高粒度的保存方式。
优缺点
在低粒度存储方式下,数仓能满足所有的查询需求,比如“查询某用户在某日的被叫次数”。
但是由于保存所有明细数据,整张表较大,数据查询性能损耗高且响应速度相对较慢,如统计某个月的合计通话时长,需要将该月所有的通话记录做聚合计算。
高粒度存储下,能较快响应部分需求,如“统计某个月的合计通话时长”。
由于已经提前汇聚每个用户的每日通话时长,只需将30天的数据累加即可。计算量相对低粒度方式,减少数倍以上。
高粒度数据针对部分请求无法满足,比如上文提到“查询某用户在某日的被叫次数”。
二者对比:
| 分类 | 低粒度 | 高粒度 |
| 效率 | 低 | 高 |
| 访问灵活度 | 低 | 高 |
| 回答全部问题能力 | 是 | 否 |
回答全部问题能力是指能否满足用户所有的合理的查询需求,比如上文提到“查询某用户在某日的被叫次数”。
最佳实践
数据双重/多重粒度级是建设数据仓库细节级最好的体系化结构选择。
双重粒度是指数仓既保存低粒度细节数据又保存高粒度汇总数据,多重粒度是双重粒度的优化,在双重粒度按天汇聚的基础上,增加按月/季度/全部时间等方式的汇聚。
通常情况下,95%的访问请求访问高粒度数据,剩下5%的情况必须访问低粒度细节数据才能得到结果。大部分的请求访问高粒度数据,数据量小且存取效率高。小部分的访问需要访问明细数据,麻烦、复杂且成本昂贵。
多重粒度下,数仓同时具备高效率访问和回答全部问题能力的优点。
目前多重粒度已经成为主流数仓粒度方案,阿里的《大数据之路》书和网上众多教学视频中提到的dwd/dws/dwt等层,也是多粒度的设计理念。
关于维度建模中数据粒度,Kinball在《维度建模工具箱》一书给出建议:事实表总是选择最细粒度的数据,即低粒度存储方式。
针对数据汇总,计算出一组数据的最大/最小/平均值,都是建设高粒度数据的有效方式。
3. 分区
分区指把数据分散到可独立访问理或更新的分离物理单元/目录中。
以用户通话记录表为例,假设有2天的数据记录:‘2022-03-23’和‘2022-03-24’两天的通话记录,23号的通话记录存储在目录1中,24号的通话记录存储在目录2中。对23号的数据计算时,只需要读取目录1中数据,减少了数据的处理量。
大数据领域,分区功能非常重要。实际工作体验中,分区几乎是最简单也最有效的性能优化手段。如果做到合理分区和有效分区剪裁,性能优化就做到了事半功倍。常见大数据计算引擎Hive和Spark对于分区的支持非常完善。
分区优点:
- 数据更新:允许只更新特定目录,减少数据更新量;
- 数据访问:计算或访问时,只访问特定目录,无需每次都全表扫描,减少数据读取量,在大数据领域,这个特性非常重要;
- 数据存档:分区后,生命周期管理可以具体到某个分区,数据回收/存档更精细化;
- 数据监控:分区后,元数据采集可以精确到分区,更准确进行数据管理;
分区标准
- 时间:最常见的分区方式,通常采用日期按天分区,准实时任务采用天-时的方式分区。时间通常指业务相关时间,如业务发生时间/结束时间/上报时间等;
- 业务范围:根据业务进行划分,如所有贷款订单中,信用贷款放在分区A中,抵押贷款放在分区B中;
- 地址位置:根据地理位置:如按照国家/省份/城市划分;
- 组织单位:如某个业务多个子公司在做,根据子公司名称进行业务分区;
- 所有上述标准:即上述多种分区方式的组合使用,如先根据时间分区,在跟进业务范围进行划分。
实践
维度表:针对数据量不大的维度表,分区保存。比如每天一个分区,每个分区包含全量信息。在占用存储空间不大的情况下又保留跟踪维度变化的能力。对外提供只能访问最新分区的视图供下游使用。
事实表:针对大数据量的事实表,推荐总是采用分区的方式存储。在模型设计和ETL上多花点精力,实现事实表的分区增量存储。非增量存储的大型事实表对于下游使用将是灾难。
在后期数据治理过程中,通过设置分区生命周期,自动回收过期的分区数据,减少数据的存储空间。回收策略参考文末附录1。
还可以针对分区做进一步的治理优化。如某大型事实表存有近3年的分区数据,通过元数据梳理发现部分程序每日访问全量分区或最初几个月的分区。由于事实表本身是增量分区设计,通常情况下无需访问很早的历史分区,因此可以考虑对下游进行优化。
数据处理过程中,分区剪裁是否生效,在实际业务中也值得关注。大型事实表的分区过滤如果没有生效,对性能影响非常大,在性能优化时应该留意这块,更多参考文末附录2。
4. 生命周期
定义
生命周期是指数据从产生至最终销毁/归档的整个过程,包括:
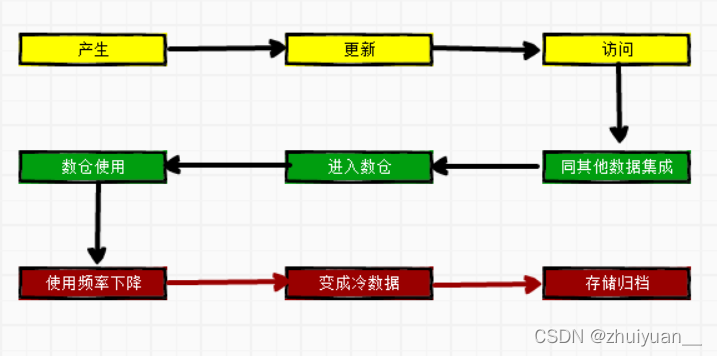
其中黄色部分发生在业务库中,绿色部分发生在数仓使用过程,红色部分为数据治理过程。
如果数据没有遵守这个流程会怎么样?答案是数据将只进不出,在大数据场景下,存储快速膨胀,集群成本增长大于业务增长。
数据生命周期管理,