课程设计——设备管理系统
项目要求
Springboot+web+微信小程序设计实现
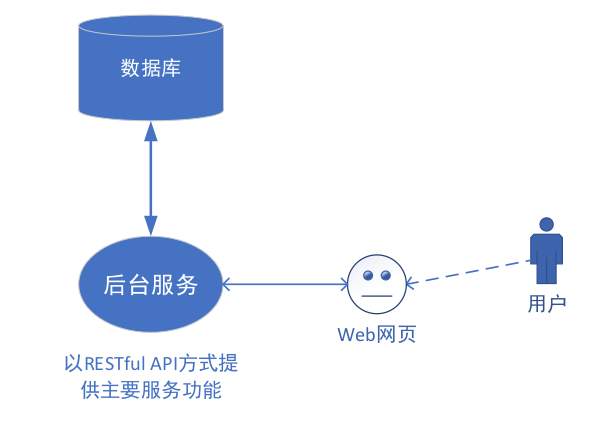
建议的体系结构:
项目要求:三人一组,最多 15 组采用该课题
项目分析
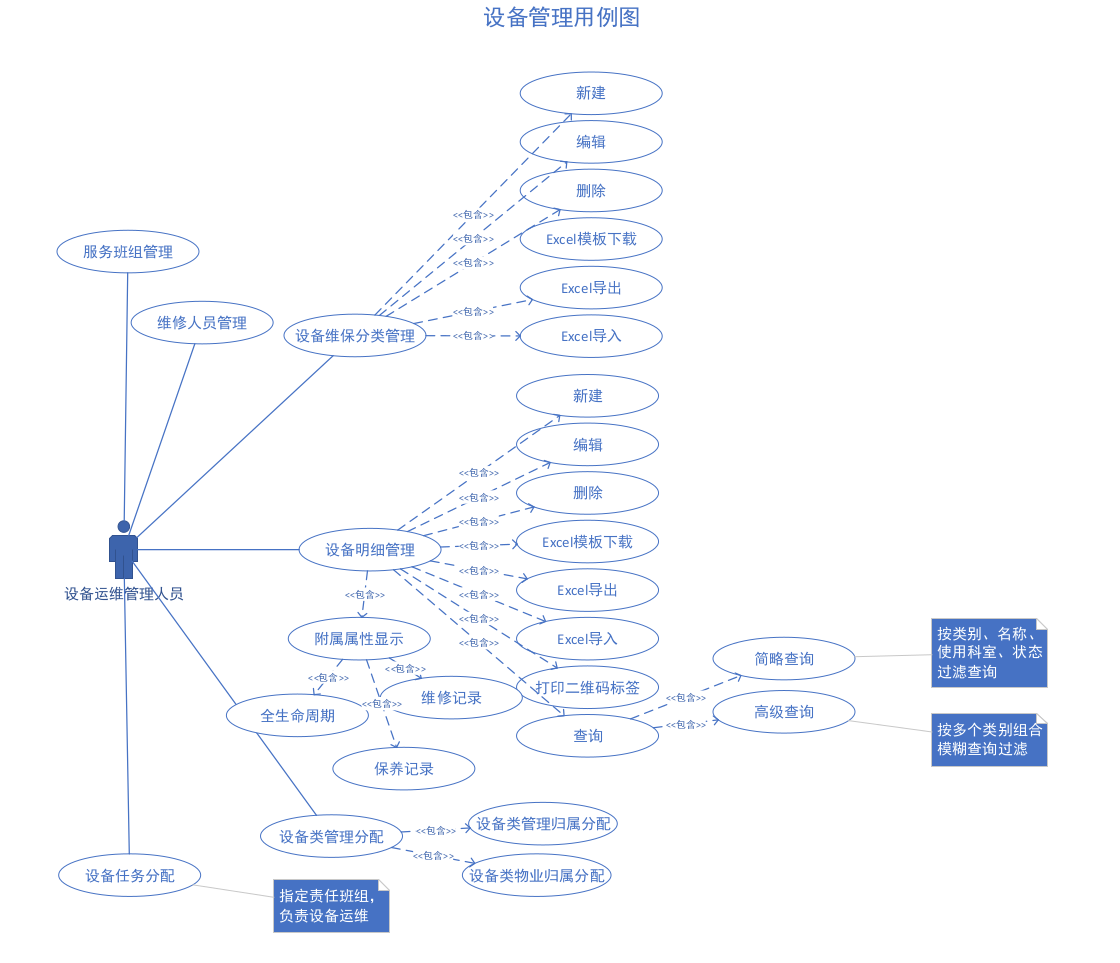
主要角色:设备运维管理人员、维修人员、物业人员
主要对象:设备
对象设备的生命周期:新建–》安装–》保养/维修–》停用
功能
- 设备类,包括该类设备信息,包括常用名称、功能、场景。
- 安装位置,安装地点、环境信息等
- 设备组,选择设备类组,填写设备信息,如厂商名、购价、使用年限等,绑定默认保养计划
- 设备,新建设备时,选择设备组,填写设备代码;安装设备时,选择安装位置、安装时间
- 保养:保养计划,为每种设备组进行设置保养计划,可以针对不同安装位置的设备进行设置。保养计划也就是物业人员每隔多长时间进行检查。
- 维修:由物业人员、管理人员提出维修任务,或者到达年限的设备会发送维修任务,维修人员收到后进行维修检查操作。
- 停用:到达年限或者不可再用的设备,由管理人员设置不可用。
环境
开发环境:Ubuntu 18.04+JDK 1.8+Maven 3.6+IntelliJ Idea 2018.3
运行环境:Ubuntu 18.04+JDK 1.8+Tomcat 9
使用技术:
- Spring boot 2.2.2.REALSE:快速开发、开箱即用
- Mybatis 3.6:持久化框架
- Mybatis plus:简化数据库访问
- Spring MVC 5:MVC框架
- zxing:二维码生成
- lombok:注解开发
- swagger ui:Web API文档生成
- easyExcel:excel操作
数据库:H2(测试)+MySQL 8.0
技术介绍
RESTful
Roy Fielding博士在2000年他的博士论文中提出REST(Representational State Transfer,资源状态转移)风格的软件架构模式,是Web API 设计规范,用于 Web 数据接口的设计
RESTful架构是对MVC架构改进后所形成的一种架构,通过使用事先定义好的接口与不同的服务联系起来。在RESTful架构中,浏览器使用POST,DELETE,PUT和GET四种请求方式分别对指定的URL资源进行增删改查操作。因此,RESTful是通过URI实现对资源的管理及访问,具有扩展性强、结构清晰的特点。
RESTful架构将服务器分成前端服务器和后端服务器两部分,前端服务器为用户提供无模型的视图;后端服务器为前端服务器提供接口。浏览器向前端服务器请求视图,通过视图中包含的AJAX函数发起接口请求获取模型。
项目开发引入RESTful架构,利于团队并行开发。在RESTful架构中,将多数HTTP请求转移到前端服务器上,降低服务器的负荷,使视图获取后端模型失败也能呈现。但RESTful架构却不适用于所有的项目,当项目比较小时无需使用RESTful架构,项目变得更加复杂。
主要原则
-
网络上的所有事物都被抽象为资源
-
每个资源都有一个唯一的资源标识符
-
同一个资源具有多种表现形式(xml,json等)
-
对资源的各种操作不会改变资源标识符
-
所有的操作都是无状态的
-
符合REST原则的架构方式即可称为RESTful
特点
RESTFUL特点包括:
- 每一个URI代表1种资源;
- 客户端使用GET、POST、PUT、DELETE4个表示操作方式的动词对服务端资源进行操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源;
- 通过操作资源的表现形式来操作资源;
- 资源的表现形式是xml,json等;
- 客户端与服务端之间的交互在请求之间是无状态的,从客户端到服务端的每个请求都必须包含理解请求所必需的信息。
举例
/emps/ HTTP GET 查询所有的emp
/emps/1 HTTP GET 查询id=1的emp
/emps/1 HTTP DELETE 删除id=1的emp
/emps/1 HTTP PUT 更新emp
/emps/ HTTP POST 新增emp
微服务
架构
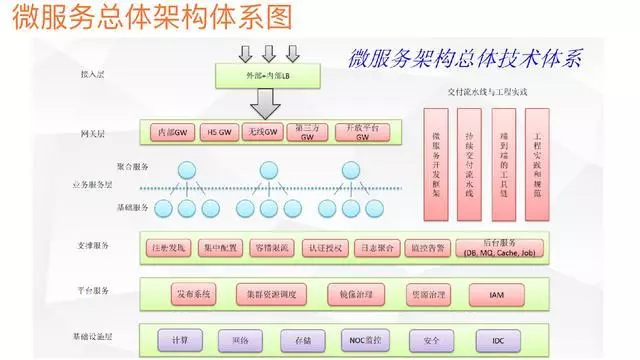
- 接入层 负载均衡作用,运维团队负责
- 网关层 反向路由,安全验证,限流等
- 业务服务层 基础服务和领域服务
- 支撑服务层
- 平台服务
- 基础设施层 运维团队负责。(或者阿里云)
特点
- 一组小的服务(大小没有特别的标准,只要同一团队的工程师理解服务的标识一致即可)
- 独立的进程(java的tomcat,nodejs等)
- 轻量级的通信(不是soap,是http协议)
- 基于业务能力(类似用户服务,商品服务等等)
- 独立部署(迭代速度快)
- 无集中式管理(无须统一技术栈,可以根据不同的服务或者团队进行灵活选择)
利
- 强模块边界 。(模块化的演化过程:类–>组件/类库(sdk)–>服务(service),方式越来越灵活)
- 可独立部署。
- 技术多样性。
弊
- 分布式复杂性。
- 最终一致性。(各个服务的团队,数据也是分散式治理,会出现不一致的问题)
- 运维复杂性。
- 测试复杂性
分布式服务框架的发展
-
第一代服务框架
代表:Dubbo(Java)、Orleans(.Net)等
特点:和语言绑定紧密
-
第二代服务框架
代表:Spring Cloud等
现状:适合混合式开发(例如借助Steeltoe OSS可以让ASP.Net Core与Spring Cloud集成),正值当年
-
第三代服务框架
代表:Service Mesh(服务网格) => 例如Service Fabric、lstio、Linkerd、Conduit等
现状:在快速发展中,更新迭代比较快
-
未来(目测不久)主流的服务架构和技术栈
基础的云平台为微服务提供了资源能力(计算、存储和网络等),容器作为最小工作单元被Kubernetes调度和编排,Service Mesh(服务网格)管理微服务的服务通信,最后通过API Gateway向外暴露微服务的业务接口。
目前,很多大公司的项目组已经在采用这种技术架构了,服务网格采用的是Linkerd,容器编排采用的是K8S,Spring Cloud已经没用了。But,不代表Spring Cloud没有学习的意义,对于中小型项目团队,Spring Cloud仍然是快速首选。

Spring Boot
Spring Boot 作为一套全新的框架,来源于 Spring 大家族,因此 Spring 所有具备的功能它都有,而且更容易使用;Spring Boot 以约定大于配置的核心思想,默认帮我们进行了很多设置,多数 Spring Boot 应用只需要很少的 Spring 配置。Spring Boot 开发了很多的应用集成包,支持绝大多数开源软件,让我们以很低的成本去集成其他主流开源软件。
特性
- 使用 Spring 项目引导页面可以在几秒构建一个项目
- 方便对外输出各种形式的服务,如 REST API、WebSocket、Web、Streaming、Tasks
- 非常简洁的安全策略集成
- 支持关系数据库和非关系数据库
- 支持运行期内嵌容器,如 Tomcat、Jetty
- 强大的开发包,支持热启动
- 自动管理依赖
- 自带应用监控
- 支持各种 IED,如 IntelliJ IDEA 、NetBeans
Spring Boot 的这些特性非常方便、快速构建独立的微服务。所以我们使用 Spring Boot 开发项目,会给我们传统开发带来非常大的便利度,可以说如果你使用过 Spring Boot 开发过项目,就不会再愿意以以前的方式去开发项目了。
改进
- Spring Boot 使编码变简单,Spring Boot 提供了丰富的解决方案,快速集成各种解决方案提升开发效率。
- Spring Boot 使配置变简单,Spring Boot 提供了丰富的 Starters,集成主流开源产品往往只需要简单的配置即可。
- Spring Boot 使部署变简单,Spring Boot 本身内嵌启动容器,仅仅需要一个命令即可启动项目,结合 Jenkins 、Docker 自动化运维非常容易实现。
- Spring Boot 使监控变简单,Spring Boot 自带监控组件,使用 Actuator 轻松监控服务各项状态。
微服务架构下,数据被分隔到 N 个独立的微服务中,如何应对市场、业务对大量数据的查询、分析就变的非常急迫,利用 Spring Boot 和 MongoDB 可以轻松的解决这个问题,通过技术手段将分裂到 N 个微服务的数据同步到 MongoDB 集群中,在同步的过程中进行数据清洗,来满足公司的各项业务需求。Spring Boot 对 MongoDB 的支持非常友好,一方面 Spring Data 技术预生成很多常用方法便于使用,另一方面 Spring Boot 封装了分布式计算的相关函数,可以让我们以较简洁的方式来实现统计查询。
Spring Boot 是 Java 领域微服务架构最优落地技术,Spring Boot+MongoDB 方案是在微服务架构下数据治理的最佳方案之一。
Spring Cloud
微服务是一种分布式系统架构,是一种思想,是一种设计原则。通过springboot来创建服务,而Spring Cloud是关注全局的服务治理框架。
Spring Cloud 是 Pivotal 推出的基于Spring Boot的一系列框架的集合,旨在帮助开发者快速搭建一个分布式的服务或应用。Spring Cloud 由众多子项目组成,如Spring Cloud Config、Spring Cloud Netflix、Spring Cloud Consul等,提供了搭建分布式系统及微服务常用的工具,如配置管理、服务发现、服务容错、服务路由等。下图可以参考。
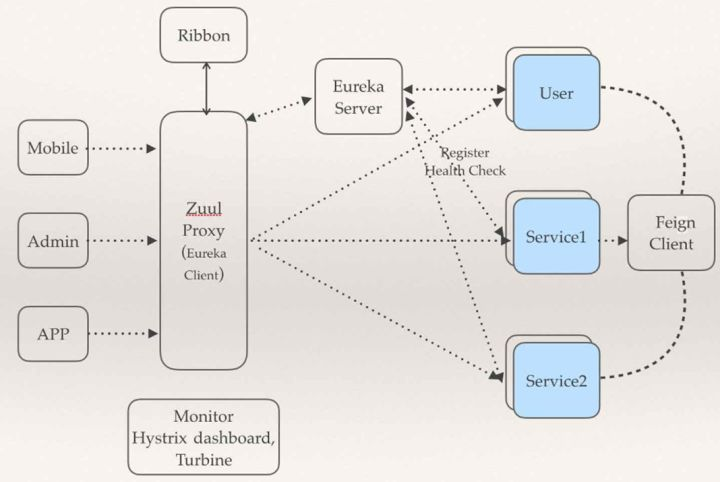
当然,微服务应用生命周期要解决的问题不仅仅是微服务治理,完整的微服务平台应该可以提供覆盖从开发、测试、构建、发布到上线运维的问题。
Spring Cloud作为第二代微服务的代表性框架,已经在国内众多大中小型的公司有实际应用案例。许多公司的业务线全部拥抱Spring Cloud,部分公司选择部分拥抱Spring Cloud。例如,拍拍贷资深架构师杨波老师就根据自己的实际经验以及对Spring Cloud的深入调研,并结合国内一线互联网大厂的开源项目应用实践结果,认为Spring Cloud技术栈中的有些组件离生产级开发尚有一定距离,最后提出了一个可供中小团队参考的微服务架构技术栈,又被称为“中国特色的微服务架构技术栈1.0”:
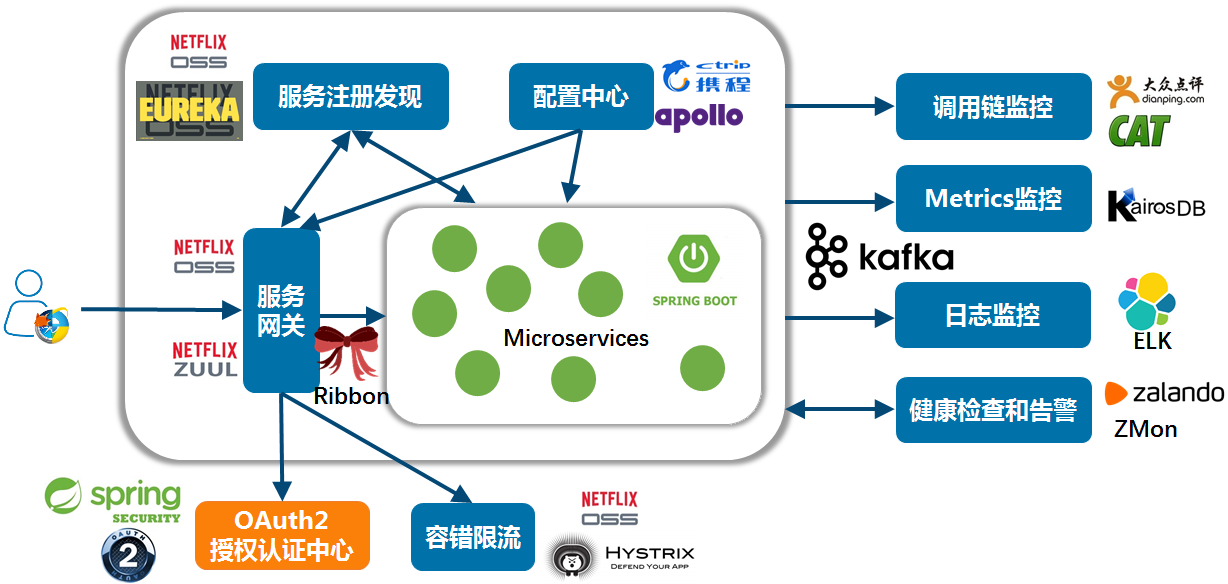
核心子项目
- Spring Cloud Netflix:核心组件,可以对多个Netflix OSS开源套件进行整合,包括以下几个组件:
- Eureka:服务治理组件,包含服务注册与发现
- Hystrix:容错管理组件,实现了熔断器
- Ribbon:客户端负载均衡的服务调用组件
- Feign:基于Ribbon和Hystrix的声明式服务调用组件
- Zuul:网关组件,提供智能路由、访问过滤等功能
- Archaius:外部化配置组件
- Spring Cloud Config:配置管理工具,实现应用配置的外部化存储,支持客户端配置信息刷新、加密/解密配置内容等。
- Spring Cloud Bus:事件、消息总线,用于传播集群中的状态变化或事件,以及触发后续的处理
- Spring Cloud Security:基于spring security的安全工具包,为我们的应用程序添加安全控制
- Spring Cloud Consul : 封装了Consul操作,Consul是一个服务发现与配置工具(与Eureka作用类似),与Docker容器可以无缝集成
- …
微信小程序
渲染层和逻辑层
小程序的运行环境分成渲染层和逻辑层,其中 WXML 模板和 WXSS 样式工作在渲染层,JS 脚本工作在逻辑层。
小程序的渲染层和逻辑层分别由2个线程管理:渲染层的界面使用了WebView 进行渲染;逻辑层采用JsCore线程运行JS脚本。一个小程序存在多个界面,所以渲染层存在多个WebView线程,这两个线程的通信会经由微信客户端(下文中也会采用Native来代指微信客户端)做中转,逻辑层发送网络请求也经由Native转发,小程序的通信模型下图所示。
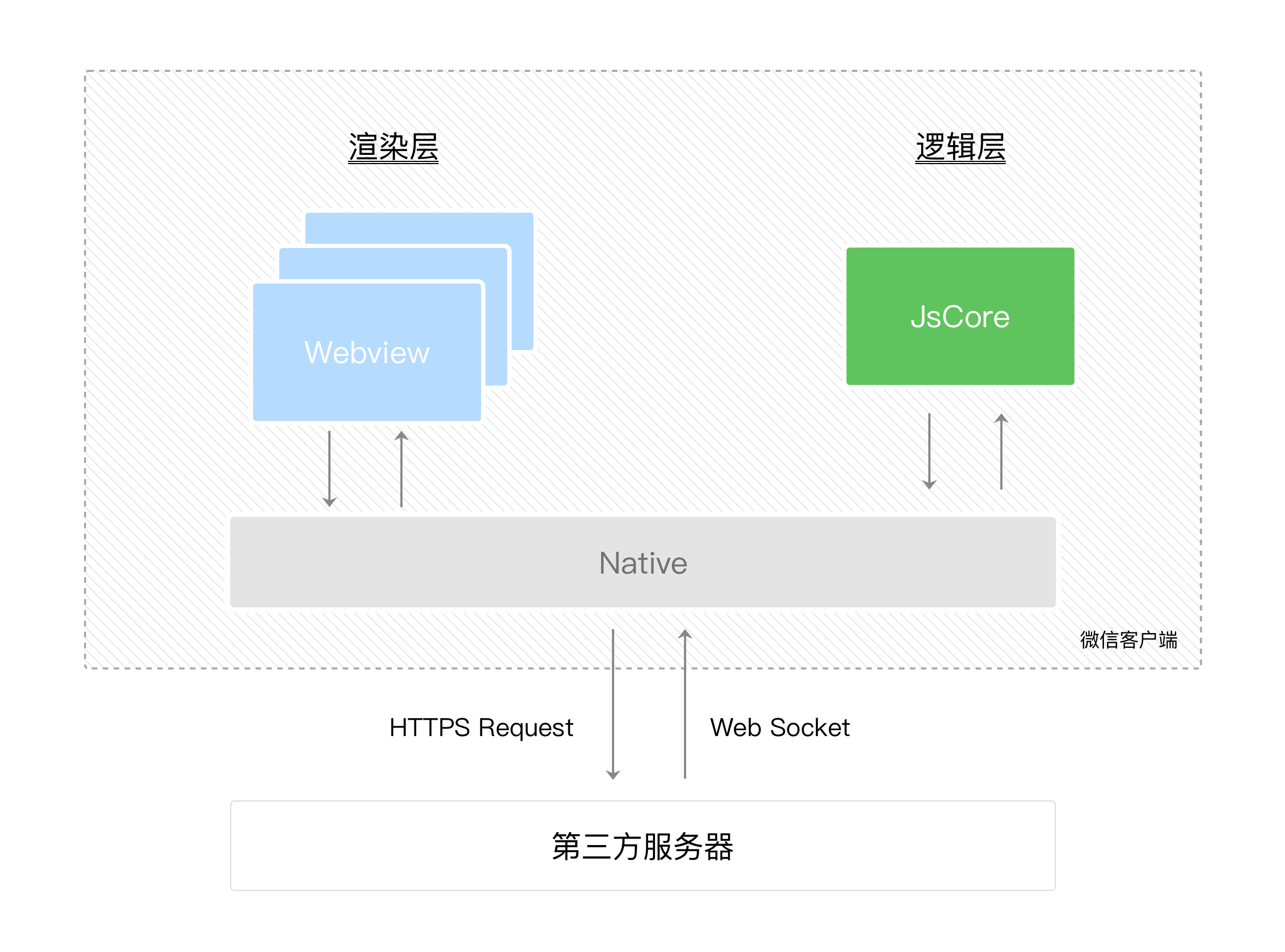
程序与页面
微信客户端在打开小程序之前,会把整个小程序的代码包下载到本地。
紧接着通过 app.json 的 pages 字段就可以知道你当前小程序的所有页面路径
而写在 pages 字段的第一个页面就是这个小程序的首页(打开小程序看到的第一个页面)。
于是微信客户端就把首页的代码装载进来,通过小程序底层的一些机制,就可以渲染出这个首页。
小程序启动之后,在 app.js 定义的 App 实例的 onLaunch 回调会被执行:
App({
onLaunch: function () {
// 小程序启动之后 触发
}
})
整个小程序只有一个 App 实例,是全部页面共享的
组件
小程序提供了丰富的基础组件给开发者,开发者可以像搭积木一样,组合各种组件拼合成自己的小程序。
就像 HTML 的 div, p 等标签一样,在小程序里边,你只需要在 WXML 写上对应的组件标签名字就可以把该组件显示在界面上,例如,你需要在界面上显示地图,你只需要这样写即可:
<map></map>
使用组件的时候,还可以通过属性传递值给组件,让组件可以以不同的状态去展现,例如,我们希望地图一开始的中心的经纬度是广州,那么你需要声明地图的 longitude(中心经度) 和 latitude(中心纬度)两个属性:
<map longitude="广州经度" latitude="广州纬度"></map>
组件的内部行为也会通过事件的形式让开发者可以感知,例如用户点击了地图上的某个标记,你可以在 js 编写 markertap 函数来处理:
<map bindmarkertap="markertap" longitude="广州经度" latitude="广州纬度"></map>
当然你也可以通过 style 或者 class 来控制组件的外层样式,以便适应你的界面宽度高度等等。
API
为了让开发者可以很方便的调起微信提供的能力,例如获取用户信息、微信支付等等,小程序提供了很多 API 给开发者去使用。
要获取用户的地理位置时,只需要:
wx.getLocation({
type: 'wgs84',
success: (res) => {
var latitude = res.latitude // 纬度
var longitude = res.longitude // 经度
}
})
调用微信扫一扫能力,只需要:
wx.scanCode({
success: (res) => {
console.log(res)
}
})
需要注意的是:多数 API 的回调都是异步,需要处理好代码逻辑的异步问题。
serverless
Serverless架构即“无服务器”架构,它是一种全新的架构方式,是云计算时代一种革命性的架构模式
所谓“无服务器”,并不是说基于Serverless架构的软件应用不需要服务器就可以运行,其指的是用户无须关心软件应用运行涉及的底层服务器的状态、资源(比如CPU、内存、磁盘及网络)及数量。软件应用正常运行所需要的计算资源由底层的云计算平台动态提供。
Serverless应用满足了云原生应用的定义,充分利用了云平台的各种能力,极大地提高了应用开发、交付和运维的效率。因此,Serverless应用是原生应用的一种实现,Serverless架构是用户通向云原生应用的道路之一
价值
-
降低运营复杂度
-
降低运营成本
-
缩短产品的上市时间
-
增强创新能力
FaaS与BaaS
目前业界的各类Serverless实现按功能而言,主要为应用服务提供了两个方面的支持:函数即服务(Function as a Service,FaaS)以及后台即服务(Backend as a Service,BaaS)。
-
FaaS
FaaS提供了一个计算平台,在这个平台上,应用以一个或多个函数的形式开发、运行和管理。
FaaS可以根据实际的访问量进行应用的自动化动态加载和资源的自动化动态分配。大多数FaaS平台基于事件驱动(Event Driven)的思想,可以根据预定义的事件触发指定的函数应用逻辑
FaaS是目前Serverless架构实现的一个重要手段。FaaS平台的特点在很大程度上影响了目前Serverless应用的架构和实现方式。因此,有一部分人认为FaaS等同于Serverless,
目前业界主流的观点是Serverless和FaaS并不是等同关系,FaaS平台是一个完整的Serverless实现的重要组成部分,仅仅通过FaaS平台并不能完全实现Serverless架构的落地。
FaaS为应用的开发、运行和管理提供良好的Serverless基础。但是对应用整体系统而言,并没有完全实现Serverless化。因此,在实现应用架构Serverless化时,也应该实现应用所依赖的服务的Serverless化。
-
BaaS
为了实现应用后台服务的Serverless化,BaaS(后台即服务)也应该被纳入一个完整的Serverless实现的范畴内。
BaaS涵盖的范围很广泛,包含任何应用所依赖的服务。AWS的DynamoDB数据库就是DBaaS的一个例子。用户按需申请使用数据库服务,而无须关注数据库的运维和缩扩容。数据库的运维完全由服务提供方AWS负责。
要实现完整的Serverless架构,用户必须结合FaaS和BaaS的功能,使得应用整体的系统架构实现Serverless化,最大化地实现Serverless架构所承诺带来的价值。因此,一个完整的Serverless实现,必须同时提供FaaS和BaaS两个方面的功能。
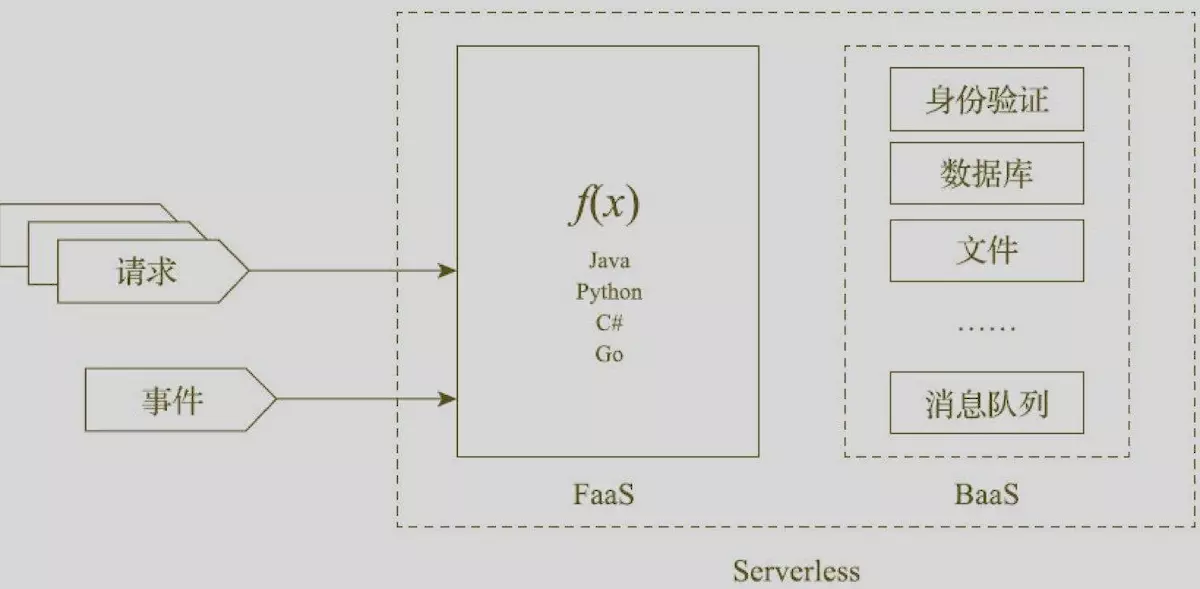
应用架构
下面我们通过一个简单的例子观察Serverless架构下的应用与传统架构下的应用的异同
-
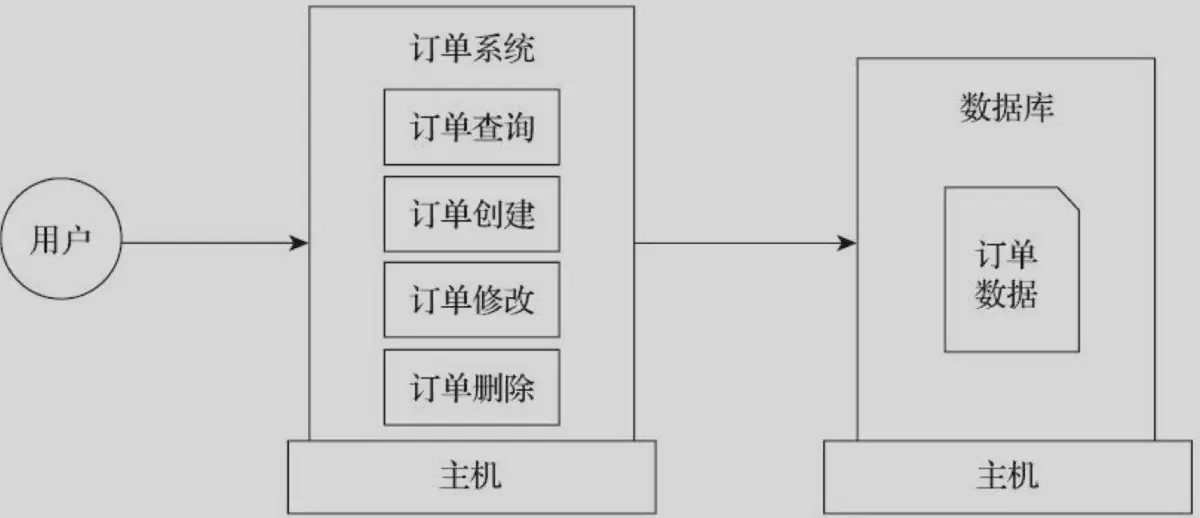
传统架构
-
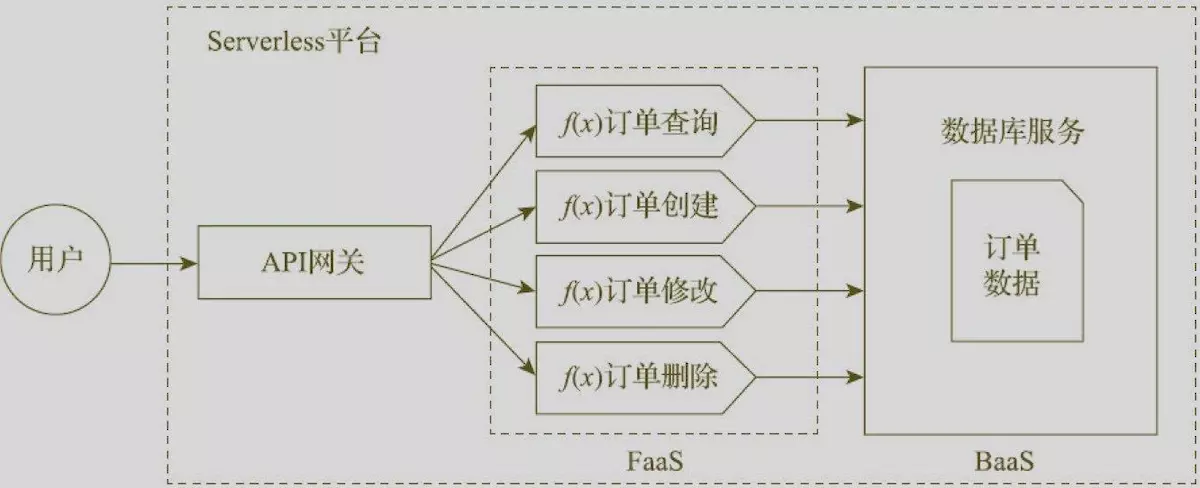
Serverless应用架构
Serverless架构下的应用架构图。这个应用实现的功能和前文的应用一样,即为用户提供订单的增删查改服务。应用被部署在Serverless平台之上。应用的功能点变成若干个函数定义,部署于FaaS之中。
两种架构的比较
- 传统架构的应用部署在主机之上,而Serverless架构的应用部署于Serverless平台之上,由Serverless平台提供运行所需的计算资源
- 传统架构的应用里,所有的逻辑都集中在同一个部署交付件中。Serverless应用的逻辑层部署运行在Serverless平台的FaaS服务之上。因此,应用的逻辑被打散成多个独立的细颗粒度的函数逻辑。因为业务逻辑运行在FaaS服务之上,所以相关的业务逻辑拥有事件驱动、资源自动弹性扩展、高可用等特性。用户也无须运维业务逻辑所消耗的计算资源
- Serverless架构的应用所依赖的数据库从具体的特定数据库实例,变成了数据库服务。用户无须关注数据库所消耗的计算资源的运维
- 在Serverless架构下,由于应用的逻辑分散成了若干个函数,推荐通过API网关对这些函数逻辑进行统一的管控(如流量控制、安全管控、版本管理等)。在完备的Serverless平台上,API网关也会作为一种用户可以快速消费的服务而存在
- 在Serverless架构下,具体的主机资源不再是用户关注的对象,不存于应用架构图中。取而代之的是Serverless平台及其子服务,如FaaS和各类BaaS服务。
技术特点
-
按需加载
在Serverless架构下,应用的加载(load)和卸载(unload)由Serverless云计算平台控制。这意味着应用不总是一直在线的。只有当有请求到达或者有事件发生时才会被部署和启动。
-
事件驱动
Serverless架构的应用并不总是一直在线,而是按需加载执行。
通过将不同事件来源(Event Source)的事件(Event)与特定的函数进行关联,实现对不同事件采取不同的反应动作,这样可以非常容易地实现事件驱动(Event Driven)架构。
-
状态非本地持久化
应用不再与特定的服务器关联。因此应用的状态不能,也不会保存在其运行的服务器之上,
-
非会话保持
应用不再与特定的服务器关联。每次处理请求的应用实例可能是相同服务器上的应用实例,也可能是新生成的服务器上的应用实例。因此,Serverless架构更适合无状态的应用。
-
自动弹性伸缩
Serverless应用原生可以支持高可用,可以应对突发的高访问量。应用实例数量根据实际的访问量由云计算平台进行弹性的自动扩展或收缩,云
-
应用函数化
Serverless架构下的应用会被函数化,但不能说Serverless就是Function as a Service(FaaS)。
-
依赖服务化
在Server-less架构下的应用的依赖应该服务化和无服务器化,也就是实现Backend as a Service(BaaS)。所有应用依赖的服务都是一个个后台服务(Backend Service),应用通过BaaS方便获取,而无须关心底层细节。和FaaS一样,BaaS是Serverless架构实现的另一个重要组件。
应用场景
-
Web应用
Serverless架构可以很好地支持各类静态和动态Web应用。
通过FaaS的自动弹性扩展功能,Serverless Web应用可以很快速地构建出能承载高访问量的站点。
举一个有意思的例子,为了应对每5年一次的人口普查,澳大利亚政府耗资近1000万美元构建了一套在线普查系统。但是由于访问量过大,这个系统不堪重负而崩溃了。在一次编程比赛中,两个澳大利亚的大学生用了两天的时间和不到500美元的成本在公有云上构建了一套类似的系统。在压力测试中,这两个大学生的系统顶住了类似的压力。
-
移动互联网
Serverless应用通过BaaS对接后端不同的服务而满足业务需求,提高应用开发的效率。
开发者可以通过函数快速地实现业务逻辑,而无须耗费时间和精力开发整个服务端应用。
-
物联网
物联网(Internet of Things,IoT)应用需要对接各种不同的数量庞大的设备。不同的设备需要持续采集并传送数据至服务端。Serverless架构可以帮助物联网应用对接不同的数据输入源。
多媒体处理视频和图片网站需要对用户上传的图片和视频信息进行加工和转换。但是这种多媒体转换的工作并不是无时无刻都在进行的,只有在一些特定事件发生时才需要被执行,比如用户上传或编辑图片和视频时。通过Serverless的事件驱动机制,用户可以在特定事件发生时触发处理逻辑,从而节省了空闲时段计算资源的开销,
-
数据及事件流处理
Serverless可以用于对一些持续不断的事件流和数据流进行实时分析和处理,对事件和数据进行实时的过滤、转换和分析,进而触发下一步的处理。比如,对各类系统的日志或社交媒体信息进行实时分析,针对符合特定特征的关键信息进行记录和告警。
-
系统集成
Serverless应用的函数式架构非常适合用于实现系统集成。用户无须像过去一样为了某些简单的集成逻辑而开发和运维一个完整的应用,用户可以更专注于所需的集成逻辑,只编写和集成相关的代码逻辑,而不是一个完整的应用。
局限
-
控制力
对于一些希望掌控底层计算资源的应用场景,Serverless架构并不是最合适的选择。
-
可移植性
Serverless应用的实现在很大程度上依赖于Serverless平台及该平台上的FaaS和BaaS服务。不同IT厂商的Serverless平台和解决方案的具体实现并不相同。
-
安全性
Serverless架构下,用户不能直接控制应用实际所运行的主机。不同用户的应用,或者同一用户的不同应用在运行时可能共用底层的主机资源。对于一些安全性要求较高的应用,这将带来潜在的安全风险
-
性能
应用的首次加载及重新加载的过程将产生一定的延时。对于一些对延时敏感的应用,需要通过预先加载或延长空闲超时时间等手段进行处理。
-
执行时长
大部分Serverless平台对FaaS函数的执行时长存在限制。因此Serverless应用更适合一些执行时长较短的作业。
-
技术成熟度
目前Serverless相关平台、工具和框架还处在一个不断变化和演进的阶段,开发和调试的用户体验还需要进一步提升。Serverless相关的文档和资料相对比较少,深入了解Serverless架构的架构师、开发人员和运维人员也相对较少
云原生
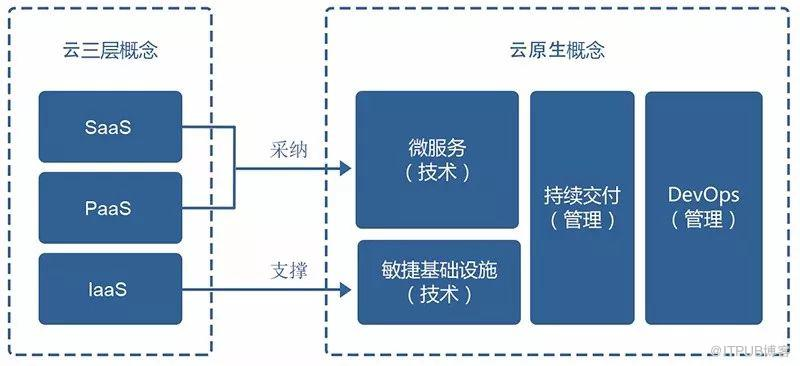
云原生从字面意思上来看可以分成云和原生两个部分。云原生是一种构建和运行应用程序的方法,是一套技术体系和方法论。
Cloud表示应用程序位于云中,而不是传统的数据中心;Native表示应用程序从设计之初即考虑到云的环境,原生为云而设计,在云上以最佳姿势运行,充分利用和发挥云平台的弹性+分布式优势。
四要素
微服务
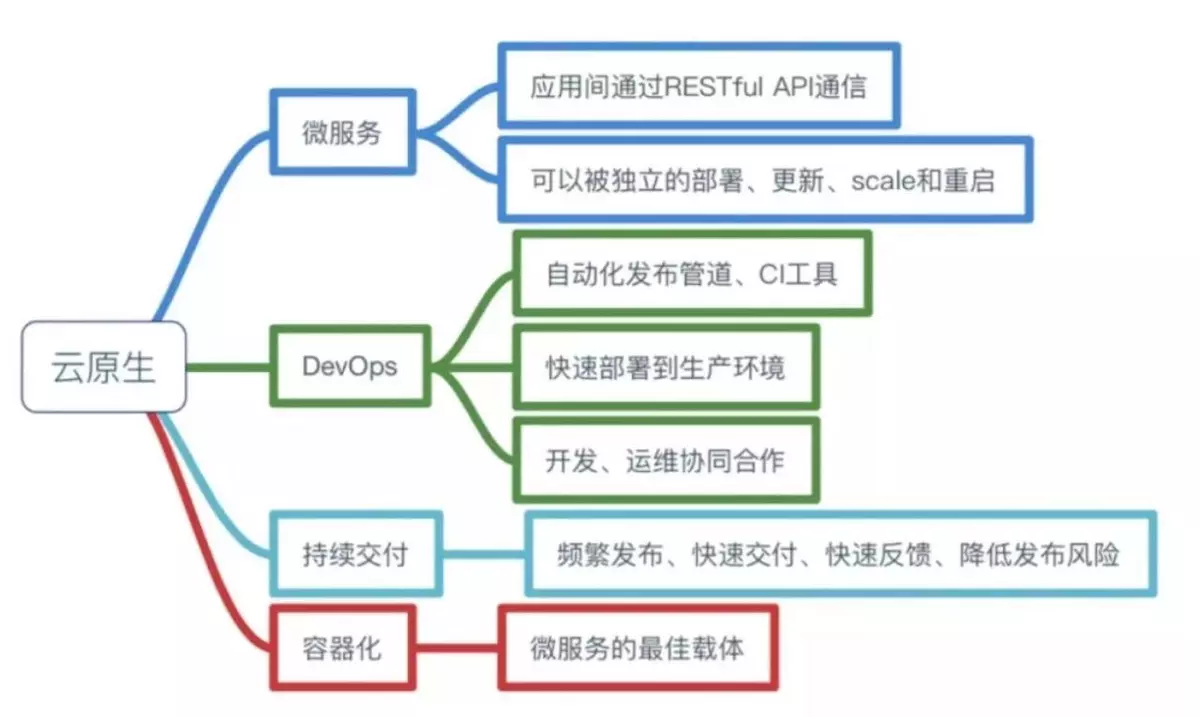
微服务解决的是我们软件开发中一直追求的低耦合+高内聚
微服务可以解决这个问题,微服务的本质是把一块大饼分成若干块低耦合的小饼,比如一块小饼专门负责接收外部的数据,一块小饼专门负责响应前台的操作,小饼可以进一步拆分,比如负责接收外部数据的小饼可以继续分成多块负责接收不同类型数据的小饼,这样每个小饼出问题了,其它小饼还能正常对外提供服务。
DevOps
DevOps的意思就是开发和运维不再是分开的两个团队,而是你中有我,我中有你的一个团队。
持续交付
持续交付的意思就是在不影响用户使用服务的前提下频繁把新功能发布给用户使用,要做到这点非常非常难。
容器化
容器化的好处在于运维的时候不需要再关心每个服务所使用的技术栈了,每个服务都被无差别地封装在容器里,可以被无差别地管理和维护,现在比较流行的工具是docker和k8s。
所以你也可以简单地把云原生理解为:云原生 = 微服务 + DevOps + 持续交付 + 容器化
要转向云原生应用需要以新的云原生方法开展工作,云原生包括很多方面:基础架构服务、虚拟化、容器化、容器编排、微服务。
项目设计
数据结构设计
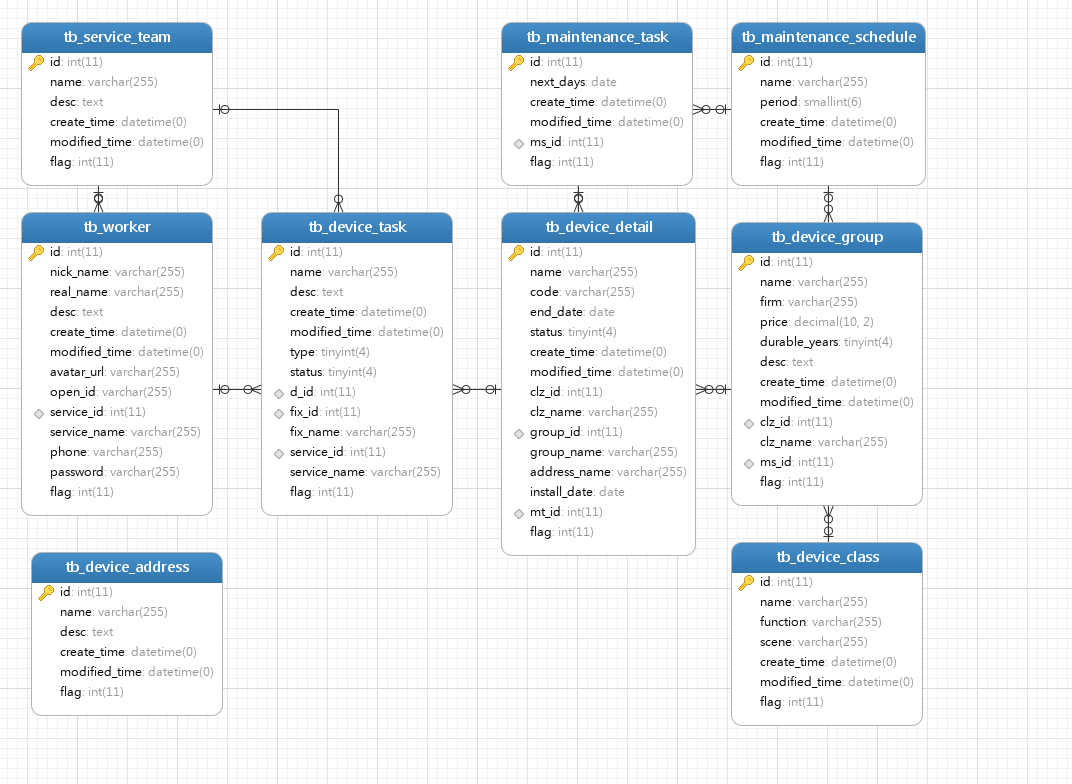
SQL代码:
drop table if exists `tb_device_task`;
drop table if exists `tb_worker`;
drop table if exists `tb_service_team`;
drop table if exists `tb_device_detail`;
drop table if exists `tb_device_group`;
drop table if exists `tb_maintenance_task`;
drop table if exists `tb_maintenance_schedule`;
drop table if exists `tb_device_class`;
drop table if exists `tb_device_address`;
CREATE TABLE `tb_device_class`
(
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`function` varchar(255) NULL,
`scene` varchar(255) NULL,
`create_time` datetime NULL DEFAULT NOW(),
`modified_time` datetime NULL DEFAULT NOW() ON UPDATE CURRENT_TIMESTAMP,
`flag` int default 1,
PRIMARY KEY (`id`)
);
CREATE TABLE `tb_device_task`
(
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`desc` text NULL,
`create_time` datetime NULL DEFAULT NOW(),
`modified_time` datetime NULL DEFAULT NOW() ON UPDATE CURRENT_TIMESTAMP,
`type` tinyint NULL COMMENT '任务类型',
`status` tinyint NULL,
`d_id` integer NULL,
`fix_id` integer NULL,
`fix_name` varchar(255) NULL,
`service_id` integer NULL,
`service_name` varchar(255) NULL,
`flag` int default 1,
PRIMARY KEY (`id`)
);
CREATE TABLE `tb_worker`
(
`id` int NOT NULL AUTO_INCREMENT,
`nick_name` varchar(255) NOT NULL,
`real_name` varchar(255) NOT NULL,
`desc` text NULL,
`create_time` datetime NULL DEFAULT NOW(),
`modified_time` datetime NULL DEFAULT NOW() ON UPDATE CURRENT_TIMESTAMP,
`avatar_url` varchar(255) NULL,
`open_id` VARCHAR(255) NULL,
`service_id` int(11) NULL,
`service_name` varchar(255) NULL,
`phone` varchar(255) NULL,
`password` varchar(255) not null,
`flag` int default 1,
PRIMARY KEY (`id`)
);
CREATE TABLE `tb_service_team`
(
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`desc` text NULL,
`create_time` datetime NULL DEFAULT NOW(),
`modified_time` datetime NULL DEFAULT NOW() ON UPDATE CURRENT_TIMESTAMP,
`flag` int default 1,
PRIMARY KEY (`id`)
);
CREATE TABLE `tb_device_group`
(
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`firm` varchar(255) NULL,
`price` decimal(10, 2) NULL,
`durable_years` tinyint NULL,
`desc` text NULL,
`create_time` datetime NULL DEFAULT NOW(),
`modified_time` datetime NULL DEFAULT NOW() ON UPDATE CURRENT_TIMESTAMP,
`clz_id` integer NULL,
`clz_name` varchar(255) NULL,
`ms_id` INTEGER null,
`flag` int default 1,
PRIMARY KEY (`id`)
);
CREATE TABLE `tb_device_detail`
(
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`code` varchar(255) NULL,
`end_date` date NULL,
`status` tinyint NULL,
`create_time` datetime NULL DEFAULT NOW(),
`modified_time` datetime NULL DEFAULT NOW() ON UPDATE CURRENT_TIMESTAMP,
`clz_id` integer NULL,
`clz_name` varchar(255) NULL,
`group_id` integer NULL,
`group_name` varchar(255) NULL,
`address_name` varchar(255) NULL,
`install_date` date NULL,
`mt_id` INTEGER null,
`flag` int default 1,
PRIMARY KEY (`id`)
);
CREATE TABLE `tb_maintenance_schedule`
(
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`period` smallint NULL,
`create_time` datetime NULL DEFAULT NOW(),
`modified_time` datetime NULL DEFAULT NOW() ON UPDATE CURRENT_TIMESTAMP,
`flag` int default 1,
PRIMARY KEY (`id`)
);
CREATE TABLE `tb_device_address`
(
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`desc` text NULL,
`create_time` datetime NULL DEFAULT NOW(),
`modified_time` datetime NULL DEFAULT NOW() ON UPDATE CURRENT_TIMESTAMP,
`flag` int default 1,
PRIMARY KEY (`id`)
);
CREATE TABLE `tb_maintenance_task`
(
`id` int NOT NULL,
`next_days` date NULL,
`create_time` datetime NULL DEFAULT NOW(),
`modified_time` datetime NULL DEFAULT NOW() ON UPDATE CURRENT_TIMESTAMP,
`ms_id` integer NULL,
`flag` int default 1,
PRIMARY KEY (`id`)
);
ALTER TABLE `tb_device_detail`
ADD CONSTRAINT `fk_tb_device_detail_tb_device_group_1` FOREIGN KEY (`group_id`) REFERENCES `tb_device_group` (`id`);
ALTER TABLE `tb_maintenance_task`
ADD CONSTRAINT `fk_tb_maintenance_task_tb_maintenance_schedule_1` FOREIGN KEY (`ms_id`) REFERENCES `tb_maintenance_schedule` (`id`);
ALTER TABLE `tb_device_group`
ADD CONSTRAINT `fk_tb_device_group_tb_maintenance_schedule_1` FOREIGN KEY (`ms_id`) REFERENCES `tb_maintenance_schedule` (`id`);
ALTER TABLE `tb_device_detail`
ADD CONSTRAINT `fk_tb_device_detail_tb_maintenance_task_1` FOREIGN KEY (`mt_id`) REFERENCES `tb_maintenance_task` (`id`);
ALTER TABLE `tb_device_group`
ADD CONSTRAINT `fk_tb_device_group_tb_device_class_1` FOREIGN KEY (`clz_id`) REFERENCES `tb_device_class` (`id`);
ALTER TABLE `tb_device_task`
ADD CONSTRAINT `fk_tb_device_task_tb_device_detail_1` FOREIGN KEY (`d_id`) REFERENCES `tb_device_detail` (`id`);
ALTER TABLE `tb_device_task`
ADD CONSTRAINT `fk_tb_device_task_tb_user_1` FOREIGN KEY (`fix_id`) REFERENCES `tb_worker` (`id`);
ALTER TABLE `tb_worker`
ADD CONSTRAINT `fk_tb_device_repairer_tb_service_team_1` FOREIGN KEY (`service_id`) REFERENCES `tb_service_team` (`id`);
ALTER TABLE `tb_device_task`
ADD CONSTRAINT `fk_tb_device_task_tb_service_team_1` FOREIGN KEY (`service_id`) REFERENCES `tb_service_team` (`id`);
功能设计
接下来讲一下一些核心功能的实现。
二维码生成
为了演示,没有进行加密
maven依赖:
<!-- 二维码支持包 -->
<dependency>
<groupId>com.google.zxing</groupId>
<artifactId>core</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>com.google.zxing</groupId>
<artifactId>javase</artifactId>
<version>3.2.0</version>
</dependency>
QRCodeUtil 生成二维码工具类:
import com.google.zxing.BarcodeFormat;
import com.google.zxing.EncodeHintType;
import com.google.zxing.MultiFormatWriter;
import com.google.zxing.common.BitMatrix;
import com.google.zxing.qrcode.decoder.ErrorCorrectionLevel;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.geom.RoundRectangle2D;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.OutputStream;
import java.util.Hashtable;
/**
* QRCodeUtil 生成二维码工具类
*/
public class QRCodeUtil {
private static final String CHARSET = "utf-8";
private static final String FORMAT_NAME = "JPG";
// 二维码尺寸
private static final int QRCODE_SIZE = 300;
// LOGO宽度
private static final int WIDTH = 60;
// LOGO高度
private static final int HEIGHT = 60;
private static BufferedImage createImage(String content, String imgPath, boolean needCompress) throws Exception {
Hashtable<EncodeHintType, Object> hints = new Hashtable<EncodeHintType, Object>();
hints.put(EncodeHintType.ERROR_CORRECTION, ErrorCorrectionLevel.H);
hints.put(EncodeHintType.CHARACTER_SET, CHARSET);
hints.put(EncodeHintType.MARGIN, 1);
BitMatrix bitMatrix = new MultiFormatWriter().encode(content, BarcodeFormat.QR_CODE, QRCODE_SIZE, QRCODE_SIZE,
hints);
int width = bitMatrix.getWidth();
int height = bitMatrix.getHeight();
BufferedImage image = new BufferedImage(width, height, BufferedImage.TYPE_INT_RGB);
for (int x = 0; x < width; x++) {
for (int y = 0; y < height; y++) {
image.setRGB(x, y, bitMatrix.get(x, y) ? 0xFF000000 : 0xFFFFFFFF);
}
}
if (imgPath == null || "".equals(imgPath)) {
return image;
}
// 插入图片
QRCodeUtil.insertImage(image, imgPath, needCompress);
return image;
}
private static void insertImage(BufferedImage source, String imgPath, boolean needCompress) throws Exception {
File file = new File(imgPath);
if (!file.exists()) {
System.err.println("" + imgPath + " 该文件不存在!");
return;
}
Image src = ImageIO.read(new File(imgPath));
int width = src.getWidth(null);
int height = src.getHeight(null);
if (needCompress) { // 压缩LOGO
if (width > WIDTH) {
width = WIDTH;
}
if (height > HEIGHT) {
height = HEIGHT;
}
Image image = src.getScaledInstance(width, height, Image.SCALE_SMOOTH);
BufferedImage tag = new BufferedImage(width, height, BufferedImage.TYPE_INT_RGB);
Graphics g = tag.getGraphics();
g.drawImage(image, 0, 0, null); // 绘制缩小后的图
g.dispose();
src = image;
}
// 插入LOGO
Graphics2D graph = source.createGraphics();
int x = (QRCODE_SIZE - width) / 2;
int y = (QRCODE_SIZE - height) / 2;
graph.drawImage(src, x, y, width, height, null);
Shape shape = new RoundRectangle2D.Float(x, y, width, width, 6, 6);
graph.setStroke(new BasicStroke(3f));
graph.draw(shape);
graph.dispose();
}
public static void encode(String content, String imgPath, String destPath, boolean needCompress) throws Exception {
BufferedImage image = QRCodeUtil.createImage(content, imgPath, needCompress);
mkdirs(destPath);
ImageIO.write(image, FORMAT_NAME, new File(destPath));
}
public static BufferedImage encode(String content, String imgPath, boolean needCompress) throws Exception {
BufferedImage image = QRCodeUtil.createImage(content, imgPath, needCompress);
return image;
}
public static void mkdirs(String destPath) {
File file = new File(destPath);
// 当文件夹不存在时,mkdirs会自动创建多层目录,区别于mkdir.(mkdir如果父目录不存在则会抛出异常)
if (!file.exists() && !file.isDirectory()) {
file.mkdirs();
}
}
public static void encode(String content, String imgPath, OutputStream output, boolean needCompress)
throws Exception {
BufferedImage image = QRCodeUtil.createImage(content, imgPath, needCompress);
ImageIO.write(image, FORMAT_NAME, output);
}
public static void encode(String content, OutputStream output) throws Exception {
QRCodeUtil.encode(content, null, output, false);
}
}
设备 前端控制器进行接口的编写
/**
* 根据 url 生成 普通二维码
*/
@GetMapping(value = "/{id}/qrcode")
@ApiOperation("根据id生成 普通二维码")
public void createQRCode(@PathVariable("id") String id, HttpServletResponse response) throws Exception {
ServletOutputStream stream = null;
try {
DeviceDetail detail = detailService.getById(id);
if (detail != null) {
stream = response.getOutputStream();
//使用工具类生成二维码
QRCodeUtil.encode(JSONObject.toJSONString(detail), stream);
}
} catch (Exception e) {
e.getStackTrace();
} finally {
if (stream != null) {
stream.flush();
stream.close();
}
}
}
举例,下面是数据:
{"clzId":1,"clzName":"路由器","code":"001122","createTime":"2020-01-05T20:52:12.997","endDate":"2025-05-01","flag":0,"groupId":1,"groupName":"华为 AR1200","id":1,"modifiedTime":"2020-01-05T20:52:12.997","name":"华为 AR1200","status":"NEW"}
Excel模板下载
默认情况下,Spring Boot从classpath下一个叫/static(/public,/resources或/META-INF/resources)的文件夹或从ServletContext根目录提供静态内容。这使用了Spring MVC的ResourceHttpRequestHandler,所以你可以通过添加自己的WebMvcConfigurerAdapter并覆写addResourceHandlers方法来改变这个行为(加载静态文件)。
在一个单独的web应用中,容器默认的servlet是开启的,如果Spring决定不处理某些请求,默认的servlet作为一个回退(降级)将从ServletContext根目录加载内容。大多数时候,这不会发生(除非你修改默认的MVC配置),因为Spring总能够通过DispatcherServlet处理请求。
//org.springframework.boot.autoconfigure.web.ResourceProperties
@ConfigurationProperties(prefix = "spring.resources", ignoreUnknownFields = false)
public class ResourceProperties {
//可以设置和静态资源有关的参数,缓存时间等
}
//org.springframework.boot.autoconfigure.web.servlet.WebMvcAutoConfiguration
//自动配置
@Configuration(proxyBeanMethods = false)
@ConditionalOnWebApplication(type = Type.SERVLET)
@ConditionalOnClass({ Servlet.class, DispatcherServlet.class, WebMvcConfigurer.class })
@ConditionalOnMissingBean(WebMvcConfigurationSupport.class)
@AutoConfigureOrder(Ordered.HIGHEST_PRECEDENCE + 10)
@AutoConfigureAfter({ DispatcherServletAutoConfiguration.class, TaskExecutionAutoConfiguration.class,
ValidationAutoConfiguration.class })
public class WebMvcAutoConfiguration {
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
if (!this.resourceProperties.isAddMappings()) {
logger.debug("Default resource handling disabled");
return;
}
Duration cachePeriod = this.resourceProperties.getCache().getPeriod();
CacheControl cacheControl = this.resourceProperties.getCache().getCachecontrol().toHttpCacheControl();
if (!registry.hasMappingForPattern("/webjars/**")) {
customizeResourceHandlerRegistration(registry.addResourceHandler("/webjars/**")
.addResourceLocations("classpath:/META-INF/resources/webjars/")
.setCachePeriod(getSeconds(cachePeriod)).setCacheControl(cacheControl));
}
String staticPathPattern = this.mvcProperties.getStaticPathPattern();
//静态资源文件夹映射
if (!registry.hasMappingForPattern(staticPathPattern)) {
customizeResourceHandlerRegistration(registry.addResourceHandler(staticPathPattern)
.addResourceLocations(getResourceLocations(this.resourceProperties.getStaticLocations()))
.setCachePeriod(getSeconds(cachePeriod)).setCacheControl(cacheControl));
}
}
//配置欢迎页映射
@Bean
public WelcomePageHandlerMapping welcomePageHandlerMapping(ApplicationContext applicationContext,
FormattingConversionService mvcConversionService, ResourceUrlProvider mvcResourceUrlProvider) {
WelcomePageHandlerMapping welcomePageHandlerMapping = new WelcomePageHandlerMapping(
new TemplateAvailabilityProviders(applicationContext), applicationContext, getWelcomePage(),
this.mvcProperties.getStaticPathPattern());
welcomePageHandlerMapping.setInterceptors(getInterceptors(mvcConversionService, mvcResourceUrlProvider));
return welcomePageHandlerMapping;
}
private Optional<Resource> getWelcomePage() {
String[] locations = getResourceLocations(this.resourceProperties.getStaticLocations());
return Arrays.stream(locations).map(this::getIndexHtml).filter(this::isReadable).findFirst();
}
private Resource getIndexHtml(String location) {
return this.resourceLoader.getResource(location + "index.html");
}
//....
}
-
所有
/webjars/**,都去 classpath:/META-INF/resources/webjars/ 找资源;
webjars:以jar包的方式引入静态资源 -
"/**"访问当前项目的任何资源,都去(静态资源的文件夹)找映射"classpath:/META‐INF/resources/", "classpath:/resources/", "classpath:/static/", "classpath:/public/" "/":当前项目的根路径 localhost:8080/pingxin === 去静态资源文件夹里面找pingxin 静态资源默认访问路径是:META-INF/resources > resources > static > public -
欢迎页; 静态资源文件夹下的所有index.html页面;被
"/**"映射;localhost:8080/ 找index页面 -
所有的
**/favicon.ico都是在静态资源文件下找
结论
所以可以讲模板文件放在静态文件夹下,通过URL直接访问。如下:
//模板文件放在static文件夹下doc/Device_upload_sample_file.xlsx
@GetMapping(path = "/template")
@ApiOperation("模板下载")
public String getTemplate(HttpServletRequest request, HttpServletResponse response) throws IOException {
String serviceRoot = request.getScheme() + "://" + request.getServerName() + ":" + request.getServerPort() + request.getContextPath() + "/";
return serviceRoot + "doc/Device_upload_sample_file.xlsx";
}
返回值:
{"code":0,"data":"http://127.0.0.1:8080/em/doc/Device_upload_sample_file.xlsx","error":false,"message":"成功","success":true}
根据返回值中的data字段,可以下载模板文件。
Excel导出
使用阿里开源框架easyexcel
Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。easyexcel重写了poi对07版Excel的解析,能够原本一个3M的excel用POI sax依然需要100M左右内存降低到几M,并且再大的excel不会出现内存溢出,03版依赖POI的sax模式。在上层做了模型转换的封装,让使用者更加简单方便
引入maven依赖:
<!--excel操作-->
<!-- https://mvnrepository.com/artifact/com.alibaba/easyexcel -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>2.1.4</version>
</dependency>
数据导出的DTO类,包括需要导出的数据以及表头名
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class DeviceDto {
/**
* 字段属性注解,value表头名,index顺序
*/
@ExcelProperty(value = "序号", index = 0)
private Integer id;
@ExcelProperty(value = "名称", index = 2)
private String name;
@ExcelProperty(value = "编号", index = 1)
private String code;
@ExcelProperty(value = "过期日期", index = 10)
private String endDate;
/**
* 自定义枚举类型转换器
*/
@ExcelProperty(value = "状态", index = 3, converter = DeviceDetailStatusAutoConverter.class)
private DeviceDetailStatus status;
@ExcelProperty(value = "设备类id", index = 4)
private Integer clzId;
@ExcelProperty(value = "设备类", index = 5)
private String clzName;
@ExcelProperty(value = "设备组id", index = 6)
private Integer groupId;
@ExcelProperty(value = "设备组", index = 7)
private String groupName;
@ExcelProperty(value = "安装位置", index = 8)
private String addressName;
@ExcelProperty(value = "安装时间", index = 9)
private String installDate;
@ExcelProperty(value = "创建时间", index = 11)
@DateTimeFormat("yyyy年MM月dd日HH时mm分ss秒")
private String createTime;
}
枚举类需要自定义Converter类,定义转换的结果:
public class DeviceDetailStatusAutoConverter implements Converter<DeviceDetailStatus> {
/**
* Back to object types in Java
*
* @return Support for Java class
*/
@Override
public Class supportJavaTypeKey() {
return DeviceDetailStatus.class;
}
/**
* Back to object enum in excel
*
* @return Support for {@link CellDataTypeEnum}
*/
@Override
public CellDataTypeEnum supportExcelTypeKey() {
return CellDataTypeEnum.STRING;
}
/**
* Convert excel objects to Java objects
*
* @param cellData Excel cell data.NotNull.
* @param contentProperty Content property.Nullable.
* @param globalConfiguration Global configuration.NotNull.
* @return Data to put into a Java object
* @throws Exception Exception.
*/
@Override
public DeviceDetailStatus convertToJavaData(CellData cellData, ExcelContentProperty contentProperty, GlobalConfiguration globalConfiguration) throws Exception {
String s = cellData.getStringValue();
return DeviceDetailStatus.from(s);
}
/**
* Convert Java objects to excel objects
*
* @param value Java Data.NotNull.
* @param contentProperty Content property.Nullable.
* @param globalConfiguration Global configuration.NotNull.
* @return Data to put into a Excel
* @throws Exception Exception.
*/
@Override
public CellData convertToExcelData(DeviceDetailStatus value, ExcelContentProperty contentProperty, GlobalConfiguration globalConfiguration) throws Exception {
return new CellData(value.getMsg());
}
}
Jdk 1.8时新增了日期类,但是easyexcel不支持LocalDate的转换器,因此需要进行修改,这里将LocalDate转换为String,下面是导出接口的实现:
/**
* 文件下载(失败了会返回一个有部分数据的Excel)
* <p>1. 创建excel对应的实体对象
* <p>2. 设置返回的 参数
* <p>3. 直接写,这里注意,finish的时候会自动关闭OutputStream,当然你外面再关闭流问题不大
*/
@GetMapping("/export")
@ApiOperation("导出")
public void download(HttpServletResponse response,
@RequestParam(defaultValue = "2010-01-01") String from,
@RequestParam(defaultValue = "2030-01-01") String to) throws IOException {
try {
LocalDate fromDate = LocalDate.parse(from);
LocalDate toDate = LocalDate.parse(to);
DeviceDetail deviceDetail = new DeviceDetail();
List<DeviceDetail> details = detailService.list(Wrappers.query(deviceDetail).between("create_time", fromDate, toDate));
List<DeviceDto> dtos = details.stream().map(
(item) -> {
DeviceDto dto = new DeviceDto();
BeanUtils.copyProperties(item, dto);
if (Objects.nonNull(item.getEndDate())) {
dto.setEndDate(item.getEndDate().toString());
}
if (Objects.nonNull(item.getInstallDate())) {
dto.setInstallDate(item.getInstallDate().toString());
}
if (Objects.nonNull(item.getCreateTime())) {
dto.setCreateTime(item.getCreateTime().format(DateTimeFormatter.ofPattern("yyyy年MM月dd日HH时mm分ss秒")));
}
return dto;
}
).collect(Collectors.toList());
// 这里注意 有同学反应使用swagger 会导致各种问题,请直接用浏览器或者用postman
response.setContentType("application/vnd.ms-excel");
response.setCharacterEncoding("utf-8");
// 这里URLEncoder.encode可以防止中文乱码 当然和easyexcel没有关系
String fileName = URLEncoder.encode("设备信息" + from.toString() + "to" + to.toString(), "UTF-8");
response.setHeader("Content-disposition", "attachment;filename=" + fileName + ".xlsx");
EasyExcel.write(response.getOutputStream(), DeviceDto.class).sheet(from.toString() + "to" + to.toString()).doWrite(dtos);
} catch (Exception e) {
throw new ServiceException("下载文件失败" + e.getMessage(), CommonCode.MISSING_REQUEST_PARAM_ERROR);
}
}
测试
数据库内数据:
insert into `tb_device_detail`
values (1, '华为 AR1200', '001122', '2025-05-01', 1, NOW(), NOW(), 1, '路由器', 1, '华为 AR1200', null, null, null, 0)
, (3, '华为 AR1200', '001123', '2026-09-01', 2, NOW(), NOW(), 1, '路由器', 1, '华为 AR1200', '主楼一楼', '2019-09-01', 2, 0)
, (2, '华为 AR1200', '001124', '2025-05-01', 3, NOW(), NOW(), 1, '路由器', 1, '华为 AR1200', '数据中心一楼', '2019-05-01', 1, 0)
, (4, '浪潮 NF5280M5', '001155', '2030-05-01', 4, '2010-02-01', NOW(), 4, '服务器', 10, '浪潮 NF5280M5', '副楼一楼', '2019-05-01', 3,
0)
, (5, '华为USG6350', '001133', '2025-05-01', 5, '2009-01-01', NOW(), 3, '防火墙', 8, '华为USG6350', '数据中心一楼', '2019-01-01', 4,
0);
来调用导出接口,可以指定需要下载设备的安装时间范围,默认是2010-01-01到2030-01-01。
测试链接:http://127.0.0.1:8080/em/device-details/export?from=2010-01-01&to=2030-01-01
导出数据为:

最后一条数据创建时间不符,因此没有导出。
excel数据导入
使用阿里开源框架easyexcel,按照要求,需要增加监听器
// 有个很重要的点 DeviceDataListener 不能被spring管理,要每次读取excel都要new,然后里面用到spring可以构造方法传进去
public class DeviceDataListener extends AnalysisEventListener<DeviceDto> {
private static final Logger LOGGER =
LoggerFactory.getLogger(DeviceDataListener.class);
/**
* 每隔5条存储数据库,实际使用中可以3000条,然后清理list ,方便内存回收
*/
private static final int BATCH_COUNT = 5;
List<DeviceDto> list = new ArrayList<DeviceDto>();
/**
* 假设这个是一个DAO,当然有业务逻辑这个也可以是一个service。当然如果不用存储这个对象没用。
*/
private IDeviceDetailService deviceDetailService;
/**
* 如果使用了spring,请使用这个构造方法。每次创建Listener的时候需要把spring管理的类传进来
*/
public DeviceDataListener(IDeviceDetailService deviceDetailService) {
this.deviceDetailService = deviceDetailService;
}
/**
* 这个每一条数据解析都会来调用
*
* @param data one row value. Is is same as {@link AnalysisContext#readRowHolder()}
* @param context
*/
@Override
public void invoke(DeviceDto data, AnalysisContext context) {
LOGGER.info("解析到一条数据:{}", JSON.toJSONString(data));
list.add(data);
// 达到BATCH_COUNT了,需要去存储一次数据库,防止数据几万条数据在内存,容易OOM
if (list.size() >= BATCH_COUNT) {
saveData();
// 存储完成清理 list
list.clear();
}
}
/**
* 所有数据解析完成了 都会来调用
*
* @param context
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 这里也要保存数据,确保最后遗留的数据也存储到数据库
saveData();
LOGGER.info("所有数据解析完成!");
}
/**
* 加上存储数据库
*/
private void saveData() {
LOGGER.info("{}条数据,开始存储数据库!", list.size());
List<DeviceDetail> details = list.stream().map(
(item) -> {
DeviceDetail detail = new DeviceDetail();
BeanUtils.copyProperties(item, detail);
if (StringUtils.isNotBlank(item.getEndDate())) {
detail.setEndDate(LocalDate.parse(item.getEndDate()));
}
if (StringUtils.isNotBlank(item.getInstallDate())) {
detail.setInstallDate(LocalDate.parse(item.getInstallDate()));
}
if (StringUtils.isNotBlank(item.getCreateTime())) {
detail.setCreateTime(LocalDateTime.parse(item.getCreateTime(), DateTimeFormatter.ofPattern("yyyy年MM月dd日HH时mm分ss秒")));
}
return detail;
}
).collect(Collectors.toList());
//有id则更新否则新增
deviceDetailService.saveOrUpdateBatch(details);
LOGGER.info("存储数据库成功!");
}
}
然后在上传excel解析时,就会使用该监听器来解析数据,如果解析没有出错误就将进行持久化,每隔5条进行批插入。