人工智能之基于阿里云快速搭建Llama-3.2-11B-Vision-Instruct
需求描述
- 基于阿里云搭建图片生成文字模型,模型名称:LLM-Research/Llama-3.2-11B-Vision-Instruct
- 使用上述模型输入图片生成文字,模型路径
业务实现
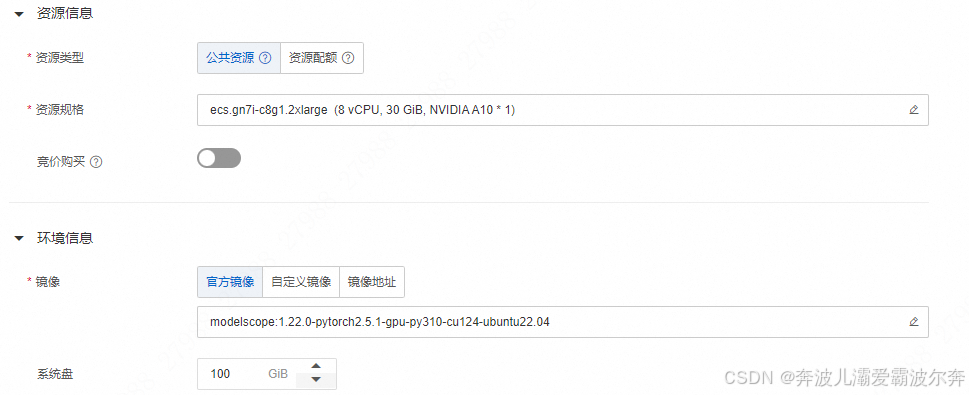
阿里云配置
阿里云配置如下:
代码验证
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
from modelscope import snapshot_download
model_id = "LLM-Research/Llama-3.2-11B-Vision-Instruct"
model_dir = snapshot_download(model_id, ignore_file_pattern=['*.pth'])
model = MllamaForConditionalGeneration.from_pretrained(
model_dir,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_dir)
url = "https://vcg01.cfp.cn/creative/vcg/800/new/VCG41519623066.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "如果你需要对图片描述,你会怎么描述?"}
]}
]
input_text \
= processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))
结果展示如下,生成的文本信息如下:
The image shows a baby in a white outfit being held by an adult, with the baby looking at the camera and smiling.
从多次搭建的经验来看,建议在搭建模型相关的内容的时候,优先选择阿里云的相关服务,很多东西阿里云的容器云已经提供底层技术,可以很快的使用modelscope提供的操作内容进行快速的模型搭建。