/ K8S 已经 10 岁了,但仍然有许多方面要继续努力 /
Kubernetes 于 2014 年 6 月推出,自那时起,它在推广云原生应用设计和支持更多微服务部署方面发挥了巨大作用。容器部署的增长非常迅速,而 Kubernetes 对于企业管理这些部署至关重要——根据 CNCF 上一份报告的调查结果,84% 的组织正在使用或评估 Kubernetes,而 66% 的潜在和实际消费者在生产中使用 Kubernetes。
如今,Kubernetes 已不仅仅是一个容器编排器。它是一个构建平台的平台。统一的 API 使 Kubernetes 成为跨多个云和混合环境(本地和公有云均在运行)运行工作负载的绝佳工具,使企业能够避免云供应商锁定。这反过来又为架构决策提供了灵活性,并显著降低了基础设施成本(特别是云账单)。
这种逐年增长的采用率在很短的时间内在每个组织中都树立了 Kubernetes 不可避免的形象。
问题是 Kubernetes 的下一步是什么?所有问题都解决了吗?
1
数据库复杂性
在数据库领域,各种社区团体开始与 Kubernetes 合作,以评估它如何与他们的项目合作,以及如何实施在 Kubernetes 上运行的项目。这些社区想要回答的关键问题是围绕在 Kubernetes 上运行数据库存在的挑战,以及分享初始部署的最佳实践和可以使用的性能优化步骤。
起步并不顺利。随着 StatefulSets 和 Persistent Volumes 的首次发布,工程师们能够在 Kubernetes 中运行有状态工作负载。但启动数据库并使其正常运行是两个不同的挑战。在 K8s 中运行数据库的复杂性尚未得到很好的理解。这导致人们错误地认为 Kubernetes 仅适用于无状态工作负载。
但值得庆幸的是,工程师们的好奇心并没有停止。容器存储接口日趋成熟,为管理员提供了更好的存储控制。随着 Kubernetes Operators 的推出,开发人员能够大大简化复杂应用程序(如数据库)的部署和管理。
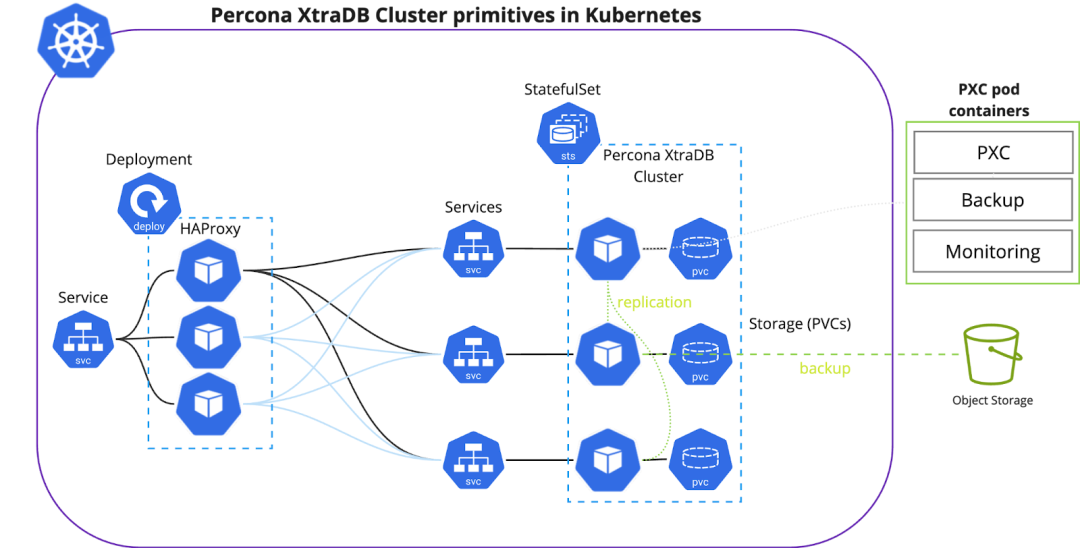
通过使在容器中以云原生数据部署的形式运行 PostgreSQL、MySQL 和 MongoDB 等数据库变得更加容易,更多开发人员能够普遍采用云原生应用程序方法。这种迁移为公司带来了更多价值和更多机会——根据 Kubernetes 上的数据社区,83% 的受访公司将其 10% 以上的收入归因于在 Kubernetes 上运行数据,三分之一的组织将其生产力提高了两倍。这些公司现在在 Kubernetes 上运行更复杂的工作负载,包括分析(67%)和 AI/ML(50%)。
2
Operator 问题
Operator 确实简化了数据库部署,但更重要的是,他们为第二天的操作所做的一切——消除了执行常规任务的需要,并最大限度地减少了人为错误的可能性。
但并非所有问题都得到了解决。
2.1
复杂
Operator 抽象了 Kubernetes 原语,并消除了配置数据库的需要。但这并不能完全消除复杂性,仍然需要工程师连接到 Kubernetes 并与 kubectl 交互来解决问题或执行各种操作任务。
2.2
多云
如上所述,Kubernetes 抽象了基础架构并提供统一的 API。这样,它就成为构建多云和混合云平台的理想工具。但与此同时,多云的故事并不完整。曾有人尝试通过 Federation(著名的已退休 KubeFed)解决多集群部署问题,还有正在进行的项目,如 Elotl Nova 或 Karmada。
缺乏统一的解决方案迫使工程师们不得不自己创造方式来提供多集群功能。例如,所有 Percona Operator 都允许用户为数据库设置跨集群复制,但故障检测和故障转移都是手动的。
2.3
多数据库
根据 Redgate 的数据,79% 的公司在其堆栈中使用两种或更多种数据库技术。将其映射到 Kubernetes,需要为每个数据库技术运行一个操作员。每个操作员都有自己的配置模式和学习曲线。这又增加了复杂性和运营负担。
3
未来:超越 Operator
展望未来,我们期望看到另一个抽象层次,这将有助于用户应对上述问题的复杂性。我们猜测,更多的开源解决方案将以 Web 应用程序或新 API 的形式出现。这就是开源软件的力量——构建像 Kubernetes 这样的解决方案,然后使其变得更好。