文章目录
在本篇文章中,我们主要介绍一下LangChain的基础理论知识。
一、LangChain 是什么
LangChain 是一个开源的基于 LLM 的上层应用开发框架,LangChain 提供了一系列的工具和接口,让开发者可以轻松地构建和部署基于 LLM 的应用 。LangChain 围绕将不同组件“链接”在一起的核心概念构建,简化了与 GPT-3.5、GPT-4 等 LLM 合作的过程,使得我们可以轻松创建定制的高级用例。
- LangChain官网:https://python.langchain.com/v0.2/docs/introduction/
- LangChain官方代码仓库:https://github.com/langchain-ai/langchain
二、LangChain 解决了什么问题
通过上面的概念,我们可以看到 LangChain 实际上是基于大语言模型上层的一个应用框架,那么 LangChain 具体解决了大模型时代的哪些问题才让他脱颖而出呢。具体来说,主要有以下几个方面:
1.模型接口的统一
现在的大模型除了大家熟知的 ChatGPT,还有 Meta 开源的 LLaMA,清华大学的 GLM 等,这些模型的使用方法包括 api 和推理方式都相差甚远,如果你想从使用 ChatGPT 切换到调用 LLaMA,需要花费不少的精力去开发前置的模型使用模块,会有大量重复繁琐的工作。而 LangChain 对好多常见的 API 和大模型做了封装,可以直接拿来就用,节省了大量的时间。
2.打破了 LLM 提示词和返回内容 token 限制,为最新知识的检索、推理提供了更大的前景
像 ChatGPT 这样的语言模型,数据只更新到 2021 年,如何让大模型回答和学习到之后的知识就是一个很重要的问题。而且 ChatGPT 的 API 是有提示词和返回内容的限制的,3.5 是 4k,4 则是 8k,而我们往往需要从自己的数据、自己的文档中获取特定的信息,这可能是一本书、一个 PDF 文件、一个带有专有信息的数据库。这些信息的 token 数量会远高于 4k 的阈值,直接使用大模型是无法获取到相应的知识的,因为超过阈值的信息就被截断了。
LangChain 提供了对向量数据库的支持,能够把超长的 txt、pdf 等通过大模型转换为 embedding 的形式,存到向量数据库中,然后利用数据库进行检索。这样就可以支持更多长度的输入,解放了 LLM 的优势。
三、LangChain 的基本概念
LangChain 能解决大模型的两个痛点,包括模型接口复杂、输入长度受限离不开自己精心设计的模块。
根据LangChain 的最新文档,目前在 LangChain 中一共有六大核心组件,分别是:
- 模型的输入输出 (Model I/O)
- 数据连接 (Data Connection)
- 内存记忆(Memory)
- 链(Chains)
- 代理(Agent)
- 回调(Callbacks)
下面我们将分别讲述每一个模块的功能和作用。
目前,最新的官网中将数据连接部分改为了检索(Retrieval),但基本内容差异不大。
3.1 Model I/O
模型是任何 LLM 应用中最核心的一点,LangChain 可以让我们方便的接入各种各样的语言模型,并且提供了许多接口,主要有三个组件组成,包括模型(Models),提示词(Prompts)和解析器(Output parsers)。
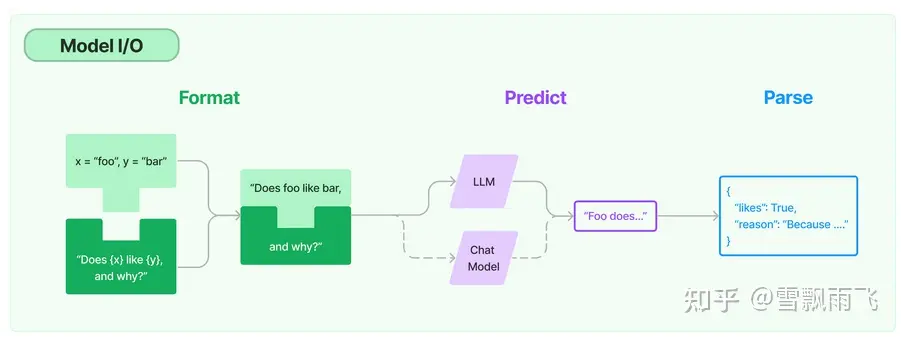
3.1.1 Models
LangChain 中提供了多种不同的语言模型,按功能划分,主要有两种:
- 语言模型(LLMs):我们通常说的语言模型,给定输入的一个文本,会返回一个相应的文本。常见的语言模型有 GPT3.5,chatglm,GPT4All 等。
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
- 聊天模型(Chat model):可以看做是封装好的拥有对话能力的 LLM,这些模型允许你使用对话的形式和其进行交互,能够支持将聊天信息作为输入,并返回聊天信息。这些聊天信息都是封装好的结构体,而非一个简单的文本字符串。常见的聊天模型有 GPT4、Llama 和 Llama2,以及微软云 Azure 相关的 GPT 模型。
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(openai_api_key="...")
3.1.2 Prompts
提示词是模型的输入,通过编写提示词可以和模型进行交互。LangChain 中提供了许多模板和函数用于模块化构建提示词,这些模板可以提供更灵活的方法去生成提示词,具有更好的复用性。根据调用的模型方式不同,提示词模板主要分为 普通模板 以及 聊天提示词模板。
1. 提示模板(PromptTemplate)
- 提示模板是一种生成提示的方式,包含一个带有可替换内容的模板,从用户那获取一组参数并生成提示
- 提示模板用来生成 LLMs 的提示,最简单的使用场景,比如“我希望你扮演一个代码专家的角色,告诉我这个方法的原理 {code}”。
- 类似于 python 中用字典的方式格式化字符串,但在 langchain 中都被封装成了对象
一个简单的调用样例如下所示:
from langchain import PromptTemplate
template = """\
You are a naming consultant for new companies.
What is a good name for a company that makes {product}?
"""
prompt = PromptTemplate.from_template(template)
prompt.format(product="colorful socks")
输出结果:
# 实际输出
You are a naming consultant for new companies.
What is a good name for a company that makes colorful socks?
2. 聊天提示模板(ChatPromptTemplate)
- 聊天模型接收聊天消息作为输入,这些聊天消息通常称为 Message,和原始的提示模板不一样的是,这些消息都会和一个角色进行关联。
- 在使用聊天模型时,建议使用聊天提示词模板,这样可以充分发挥聊天模型的潜力。
一个简单的使用示例如下:
from langchain.prompts import (
ChatPromptTemplate,
PromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# get a chat completion from the formatted messages
chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages()
输出结果:
[SystemMessage(content='You are a helpful assistant that translates English to French.', additional_kwargs={}),
HumanMessage(content='I love programming.', additional_kwargs={})]
3.1.3 Output parsers
语言模型输出的是普通的字符串,有的时候我们可能想得到结构化的表示,比如 JSON 或者 CSV,一个有效的方法就是使用输出解析器。
输出解析器是帮助构建语言模型输出的类,主要实现了两个功能:
- 获取格式指令:一个文本字符串需要指明语言模型的输出应该如何被格式化
- 解析:一种接受字符串并将其解析成固定结构的方法,可以自定义解析字符串的方式
一个简单的使用示例如下:
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field, validator
from typing import List
model_name = 'text-davinci-003'
temperature = 0.0
model = OpenAI(model_name=model_name, temperature=temperature)
# Define your desired data structure.
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
# You can add custom validation logic easily with Pydantic.
@validator('setup')
def question_ends_with_question_mark(cls, field):
if field[-1] != '?':
raise ValueError("Badly formed question!")
return field
# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
# And a query intended to prompt a language model to populate the data structure.
joke_query = "Tell me a joke."
_input = prompt.format_prompt(query=joke_query)
output = model(_input.to_string())
parser.parse(output)
输出结果:
Joke(setup='Why did the chicken cross the road?', punchline='To get to the other side!')
3.2 Data Connection
有的时候,我们希望语言模型可以从自己的数据中进行查询,而不是仅依靠自己本身输出一个结果。数据连接器的组件就允许你使用内置的方法去读取、修改,存储和查询自己的数据,主要有下面几个组件组成:
- 文档加载器(Document loaders):连接不同的数据源,加载文档。
- 文档转换器(Document transformers):定义了常见的一些对文档加工的操作,比如切分文档,丢弃无用的数据
- 文本向量模型(Text embedding models):将非结构化的文本数据转换成一个固定维度的浮点数向量
- 向量数据库(Vector stores):存储和检索你的向量数据
- 检索器(Retrievers):用于检索你的数据
3.3 Chains
只使用一个 LLM 去开发应用,比如聊天机器人是很简单的,但更多的时候,我们需要用到许多 LLM 去共同完成一个任务,这样原来的模式就不足以支撑这种复杂的应用。
为此 LangChain 提出了 Chain 这个概念,也就是一个所有组件的序列,能够把一个个独立的 LLM 链接成一个组件,从而可以完成更复杂的任务。举个例子,我们可以创建一个 chain,用于接收用户的输入,然后使用提示词模板将其格式化,最后将格式化的结果输出到一个 LLM。通过这种链式的组合,就可以构成更多更复杂的 chain。
在 LangChain 中有许多实现好的 chain,以最基础的 LLMChain 为例,它主要实现的就是接收一个提示词模板,然后对用户输入进行格式化,然后输入到一个 LLM,最终返回 LLM 的输出。
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
LLMChain 不仅支持 llm,同样也支持 chat llm,下面是一个调用示例:
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
human_message_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
template="What is a good name for a company that makes {product}?",
input_variables=["product"],
)
)
chat_prompt_template = ChatPromptTemplate.from_messages([human_message_prompt])
chat = ChatOpenAI(temperature=0.9)
chain = LLMChain(llm=chat, prompt=chat_prompt_template)
print(chain.run("colorful socks"))
3.4 Memory
大多数的 LLM 应用程序都会有一个会话接口,允许我们和 LLM 进行多轮的对话,并有一定的上下文记忆能力。但实际上,模型本身是不会记忆任何上下文的,只能依靠用户本身的输入去产生输出。而实现这个记忆功能,就需要额外的模块去保存我们和模型对话的上下文信息,然后在下一次请求时,把所有的历史信息都输入给模型,让模型输出最终结果。
而在 LangChain 中,提供这个功能的模块就称为 Memory,用于存储用户和模型交互的历史信息。在 LangChain 中根据功能和返回值的不同,会有多种不同的 Memory 类型,主要可以分为以下几个类别:
- 对话缓冲区内存(ConversationBufferMemory):最基础的内存模块,用于存储历史的信息
- 对话缓冲器窗口内存(ConversationBufferWindowMemory):只保存最后的 K 轮对话的信息,因此这种内存空间使用会相对较少
- 对话摘要内存(ConversationSummaryMemory):这种模式会对历史的所有信息进行抽取,生成摘要信息,然后将摘要信息作为历史信息进行保存。
- 对话摘要缓存内存(ConversationSummaryBufferMemory):这个和上面的作用基本一致,但是有最大 token 数的限制,达到这个最大 token 数的时候就会进行合并历史信息生成摘要
值得注意的是,对话摘要内存的设计出发点就是 语言模型能支持的上下文长度是有限的(一般是 2048),超过了这个长度的数据天然的就被截断了。这个类会根据对话的轮次进行合并,默认值是 2,也就是每 2 轮就开启一次调用 LLM 去合并历史信息。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history")
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("whats up?")
参考官方的教程,Memory 同时支持 LLM 和 Chat model。
- LLM model:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
# llm
llm = OpenAI(temperature=0)
# Notice that "chat_history" is present in the prompt template
template = """You are a nice chatbot having a conversation with a human.
Previous conversation:
{chat_history}
New human question: {question}
Response:"""
prompt = PromptTemplate.from_template(template)
# Notice that we need to align the `memory_key`
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({"question": "hi"})
- Chat model:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({"question": "hi"})
3.5 Agents
代理的核心思想就是使用 LLM 去选择对用户的输入,应该使用哪个特定的工具去进行操作。这里的工具可以是另外的一个 LLM,也可以是一个函数或者一个 chain。在代理模块中,有三个核心的概念:
-
代理(Agent):依托于强力的语言模型和提示词,代理是用来决定下一步要做什么,其核心也是构建一个优秀的提示词。这个提示词大致有下面几个作用:
- 角色定义,给代理设定一个符合自己的身份
- 上下文信息,提供给他更多的信息来要求他可以执行什么任务
- 丰富的提示策略,增加代理的推理能力
-
工具(Tools):代理会选择不同的工具去执行不同的任务。工具主要给代理提供调用自己的方法,并且会描述自己如何被使用。工具的这两点都十分重要,如果你没有提供可以调用工具的方法,那么代理就永远完不成自己的任务;同时如果没有正确的描述工具,代理就不知道如何去使用工具。
-
工具包(Toolkits):LangChain 提供了工具包的使用,在一个工具包里通常包含 3-5 个工具。
Agent 技术是目前大语言模型研究的一个前沿和热点方向,但是目前受限于大模型的实际效果,仅 GPT 4.0 可以有效的开展 Agent 相关的研究。我们相信在未来,随着大模型性能的优化和迭代,Agent 技术应该能有更好的发展和前景。
3.6 Callbacks
回调,字面解释是让系统回过来调用我们指定好的函数。在 LangChain 中就提供了一个这样的回调系统,允许你进行日志的打印、监控,以及流式传输等其他任务。通过直接在 API 中提供的回调参数,就可以简单的实现回调的功能。LangChain 内置了许多可以实现回调功能的对象,我们通常称为 handlers,用于定义在不同事件触发的时候可以实现的功能。
不管使用 Chains、Models、Tools、Agents,去调用 handlers,均通过是使用 callbacks 参数,这个参数可以在两个不同的地方进行使用:
- 构造函数中,但它的作用域只能是该对象。比如下面这个 LLMChain 的构造函数可以进行回调,但这个回调函数对于链接到它的 LLM 模型是不生效的。
LLMChain(callbacks=[handler], tags=['a-tag'])
- 在 run()/apply() 方法中调用,只有当前这一次请求才会相应这个回调函数,但是当前请求包含的子请求都会调用这个回调。比如,使用了一个 chain 去触发这个请求,连接到它的 LLM 模型也会调用这个回调。
chain.run(input, callbacks=[handler])
四、LangChain 的优势
和 LangChain 类似的 LLM 应用开发框架:
- OpenAI 的 GPT-3.5/4 API
- Hugging Face 的 Transformers(多模态机器学习模型,支持上千预训练模型)
- Google 的 T5(NLP 框架)等
LangChain 的优势:
- 能力更强,更新 by days
- 代码设计优雅,模块化程度高,Chain、Agent、Memory 模块的抽象程度高,便于结合应用
- 集成工具完善,从数据预处理、LLM 模型、向量化到图数据库等
- 支持常用 LLM 和大量商业化 NLP 模型
- 商业化:Azure OpenAI、OpenAI
- 开源:Hugging Face、GPT4All
- 有大量的 LLM 用例供参考
五、基于 LangChain 的应用
从上文中,我们了解了 LangChain 的基本概念,以及主要的组件,利用这些能帮助我们快速上手构建 app。LangChain 能够在很多使用场景中进行应用,包括但不限于:
- 个人助手和聊天机器人:能够记住和你的每一次互动,并进行个性化的交互
- 基于文档的问答系统:在特定文档上回答问题,可以减少大模型的幻觉问题
- 表格数据查询:提供了对结构化数据的查询功能,如 CSV,PDF,SQL,DataFrame 等
- API 交互:可以对接不同语言模型的API,并产生交互和调用
- 信息提取:从文本中提取结构化的信息,并输出
- 文档总结:利用 LLM 和 embedding 对长文档进行压缩和总结
而且在 github 上也有很多人开源了基于 LangChain 开发的开源应用,LangChain-Chatchat 就是其中比较火的一个。
LangChain-Chatchat (原 Langchain-ChatGLM): 基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,开源、可离线部署的 RAG 与 Agent 应用项目。
- 项目地址:https://github.com/chatchat-space/Langchain-Chatchat
- 项目亮点:可以本地上传知识库,并且计划支持联网搜索。
在下一篇博客中,我们会详细介绍关于 LangChain-Chatchat 的理论及应用。