最近关于大型语言模型(LLMs)推理的研究试图通过整合元思考来进一步提高其性能——使模型能够监控、评估和控制其推理过程,从而实现更适应性和有效的解决问题。然而,当前的单智能体工作缺乏专门设计以获取元思考的能力,导致效率低下。为解决这一挑战,我们引入了 强 化学习的元思考代理框架( ReMA ),这是一个利用多智能体强化学习(MARL)激发元思考行为的新方法,鼓励LLMs进行“思考中的思考”。 ReMA 将推理过程分为两个层次的代理:一个高层次的元思考代理负责生成战略性监督和计划,以及一个低层次的推理代理负责详细执行。通过目标一致的迭代强化学习,这些代理探索并学习协作,从而提高泛化能力和鲁棒性。实验结果表明, ReMA 在复杂的推理任务上优于单智能体的强化学习基线,包括具有竞争力水平的数学基准和LLM-as-a-Judge基准。全面的消融研究进一步展示了每个不同代理的动态演变,提供了有关元思考推理过程如何增强LLMs推理能力的宝贵见解。V+cadorai,回复:AIGC++,可即时关注作者动态。
大型语言模型(LLMs)已在知识理解和复杂推理任务中展现出显著的能力 (Chowdhery 等 2023;Achiam 等 2023;R. Anil 等 2023;Dubey 等 2024) 。开发基于LLM的推理模型范式正从扩展训练时计算转向扩展测试时计算 (Snell 等 2024) 。最近的进展如OpenAI-o1 (OpenAI 2024) 、Deepseek R1 (DeepSeek-AI 等 2025) 和 Gemini 2.0 Flash Thinking (DeepMind 2025) 表明允许LLMs在生成答案前思考可以显著提高性能,并导致人类类推理模式的出现。这些模式如 “等等,让我再检查一下。” 或 “让我们分解这个问题。” 表明LLMs可以发展出一种形式的元思考能力,这种能力可以在分布外(OOD)任务上很好地泛化 (Xiang 等 2025) 。元思考,也被称为元认知技能 (Flavell 1979) ,是一种传统上被认为独特于人类的能力 (Didolkar 等 2024) 。
为了从LLMs自身培养元思考模式,最近的基于构造的监督方法利用结构化的推理轨迹进行监督微调。具体来说,这些方法通过对预定义的元思考模板采样推理轨迹,然后使用监督微调(SFT)或直接偏好优化(DPO) (Rafailov 等 2023) 来教导LLMs模仿这些模式 (Qi 等 2024;M. Yue 等,未注明日期;Xi 等 2024;L. Yang 等 2025; Muennighoff 等 2025;Yixin Ye 等 2025) 。然而,这些方法缺乏足够的灵活性让LLMs探索合适的元思考模式。因此,它们通常无法泛化到分布外(OOD)问题,导致在未见过的数据上的不稳定表现 (Kirk 等,未注明日期;Chu 等 2025) 。除了基于构造的方法,R1类似的单智能体强化学习(SARL)也被用于推理中的元思考 (DeepSeek-AI 等 2025;Xie 等 2025) 。然而,这些SARL尝试通常依赖于强大的基础模型以简化探索,或需要广泛的任务特定微调以稳定训练 (Xu 等 2025;Gandhi 等 2025) 。此外,SARL需要在单次前向传递中同时学习元思考和推理,试图完全以自回归方式捕捉复杂的推理结构 (Xie 等 2025) 。这可能导致诸如探索效率低下、可读性降低以及过早收敛到局部最优等问题 (DeepSeek-AI 等 2025;Xiang 等 2025) 。
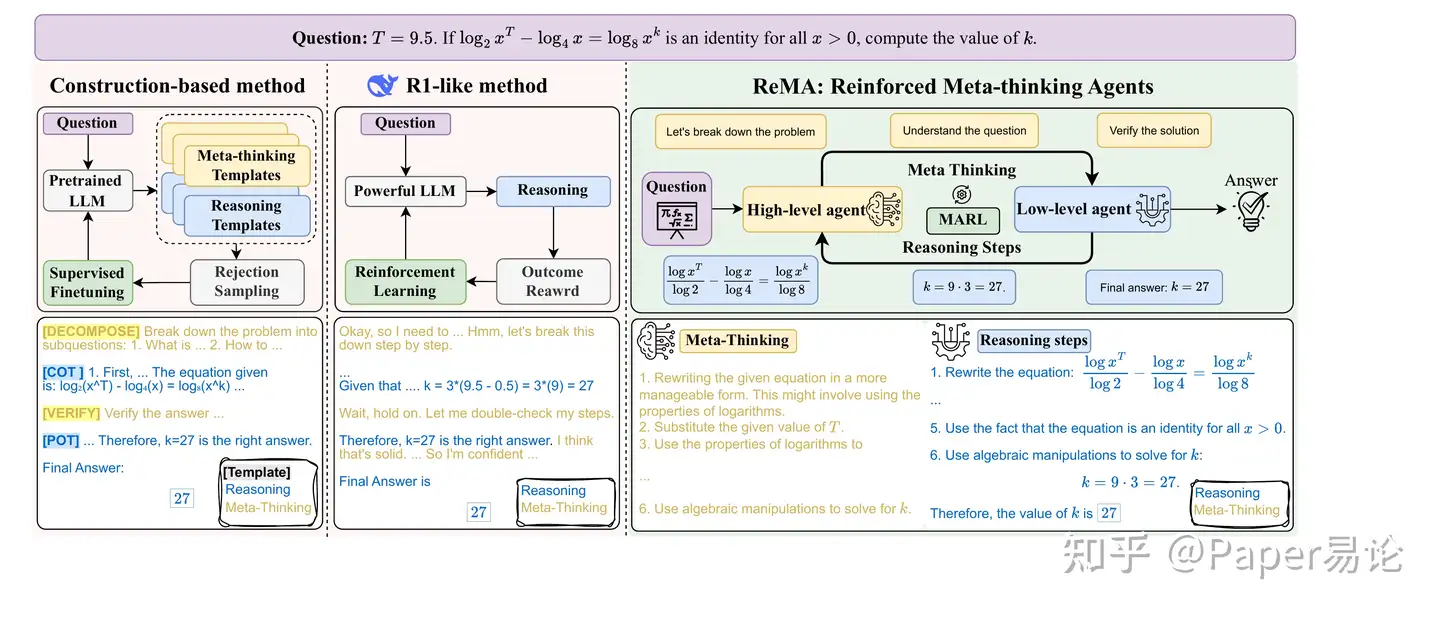
左:基于拒绝采样的方法对LLMs进行微调,搜索预定义模板的组合。中间:RL-from-base方法在训练期间混合元思考和详细的解决方案步骤。右:我们的方法 ReMA 在多智能体系统中分离元思考和推理步骤,允许代理高效探索并学习协作。
为解决这些问题,我们引入了 强 化学习的元思考代理( ReMA ),这是一种新颖的框架,通过多智能体强化学习(MARL)鼓励LLMs进行“思考中的思考”。我们的方法采用由高层次的 元思考 代理和低层次的 推理 代理组成的多智能体系统(MAS)。高层次代理负责战略监督和指令生成,而低层次代理则根据提供的指导完成详细执行过程。我们在图 1 中比较了基于构造的方法、R1类似的方法和 ReMA 的推理过程。由于MAS将SARL的探索空间分配给多个代理,它使每个代理在训练期间能够更结构性和高效地探索。然后我们对每个代理应用目标一致的迭代强化学习。通过这种方式, ReMA 有效地平衡了泛化能力和探索效率之间的权衡 。因此,它们可以学习在对方存在的情况下发挥最佳作用(要么进行元思考,要么遵循指令)。与主要导致记忆的SFT不同 (Chu 等 2025) ,这两个代理动态调整参数,最终诱导有效且稳健的合作。结果不仅缓解了OOD问题,还因分层设计刺激了更有序的元思考学习。
据我们所知,我们是第一个正式定义多智能体元思考推理过程(MAMRP)并通过(多智能体)强化学习优化它的团队。此外,我们在数学推理和LLM-as-a-Judge任务上进行了广泛的实验。在这些基准测试中, ReMA 在相同的训练数据集下实现了最高的平均性能。此外,我们进行了全面的消融分析,以说明每个不同代理的动态演变。例如,我们在不同的奖励设置下观察到了意想不到的角色反转交互模式。这些发现可以为元思考推理过程如何增强LLMs的推理能力提供有价值的见解。
2 预备知识
在本节中,我们概述了朴素推理过程的公式化(第 2.1 节)和代表性训练方法(第 2.2 节),以及本文使用的符号。
2.1 朴素推理过程(VRP)

2.2 训练VRP:监督学习和强化学习
最近,人们越来越感兴趣通过在强大基础模型上进行强化学习(RL)来揭示这种推理过程,例如DeepSeek-V3-Base (Liu 等 2024) 和 Qwen2.5-Math-7B (A. Yang 等 2024) 。LLM的解码策略遵循朴素推理过程,可以进一步形式化为确定性的标记级马尔可夫决策过程 (J. Wang 等 2024) 。优化损失函数可以表示为:
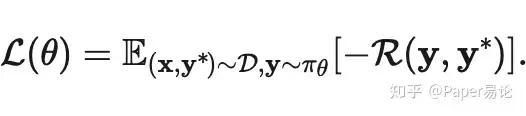



然而,在未对齐的基础LLMs上进行RL训练可能会遭受诸如可读性差和语言混杂等问题,阻止研究人员验证、理解和进一步开发他们的LLMs。并且巨大的搜索空间使得元思考的有效学习变得困难。
3 方法
在本节中,我们介绍了 强化元思考代理 ( ReMA ),一种在多智能体环境下将元思考整合到LLM推理过程中的强化学习方法(第 3.1 节),然后描述了由MARL启用的双边学习过程(第 3.2 节),最后讨论了奖励函数设计对学习动态的重大影响(第 3.3 节)。
3.1 部署元思考推理过程(MRP)用于LLMs



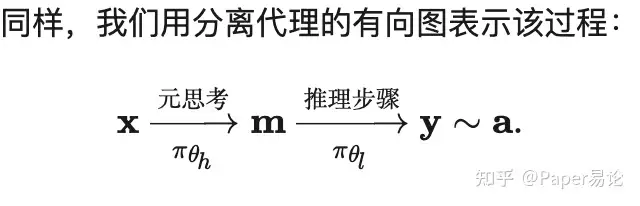
为说明此程序,我们考虑一个代表性的例子: 高层次代理首先对任务的目标、适当的解决方案策略和问题分解方案进行元思考分析。然后将此分析传递给低层次代理,作为逐步解决方案的指导。MAMRP还可以扩展到多轮设置:在后续轮次中,高层次代理还可以细化或批评低层次代理的输出。此过程重复进行,直到满足任何预定义的停止条件,例如达到最大迭代次数或获得满意的解决方案。
此外,作为一个复杂的推理系统,MAMRP在扩展推理时间计算方面提供了多种优化机会。我们将在附录 8 中进一步讨论这些方面。
3.2 训练MAMRP:一种多智能体RL方法
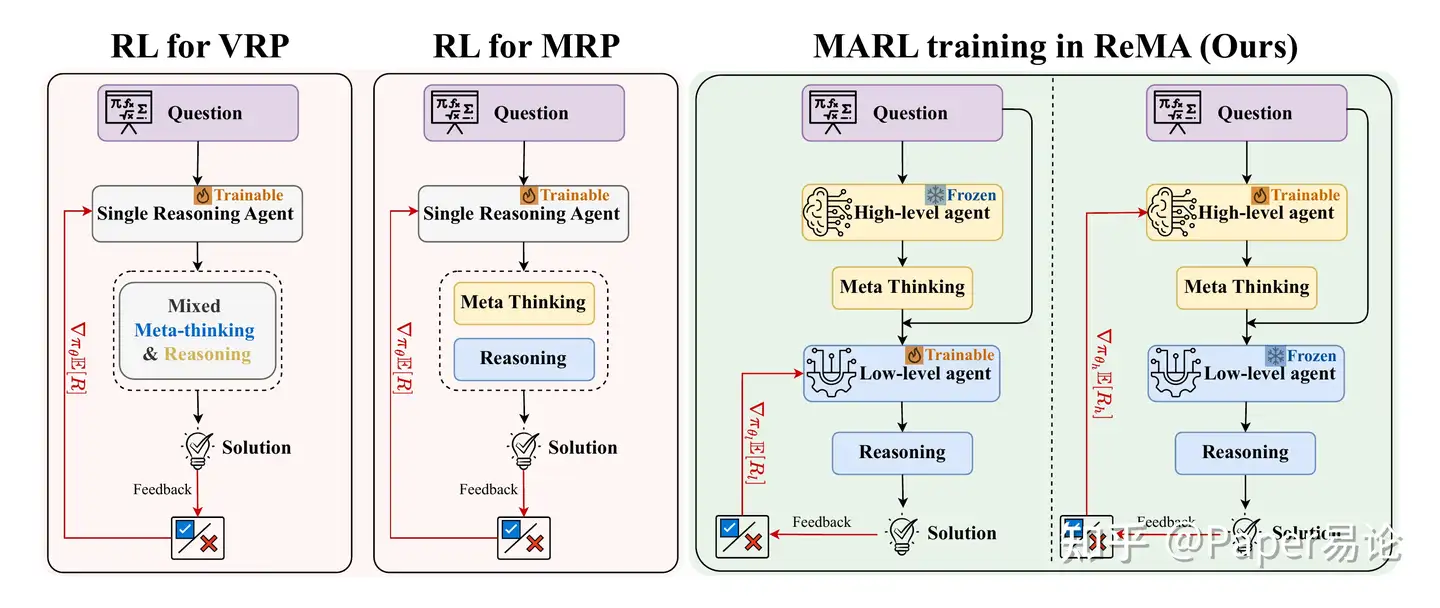
训练管道比较。左:VRP和MRP的RL训练。右: ReMA 中的MARL训练:在冻结高层次代理的同时,使用生成的元思考、执行结果和奖励对低层次代理进行训练。在冻结低层次代理的同时对高层次代理进行训练。此循环迭代重复。


3.3 奖励函数设计
如第 3.2 节所述,我们通过根据低层次策略输出分配奖励来更新高层次和低层次代理。以下是几种潜在的奖励设计方案:
- 正确性奖励:对于具有明确真实标签的任务,我们根据低层次代理输出的正确性分配奖励。
- 格式奖励:对于需要特定输出格式的任务,我们通过对规定的结构进行遵循来提供格式奖励。

不同奖励的组合增强了LLMs的整体性能。详细的奖励设计见附录 12 。
4 实验
为了评估 ReMA 的有效性和效率,我们在两类任务的挑战性基准上进行了实验:数学推理和LLM-as-a-Judge,并训练和测试了不同的LLMs。
4.1 基准
对于数学推理实验,我们在MATH (Hendrycks 等 2021) 中的7.5k训练样本上训练模型,并使用MATH500 (Lightman 等 2023) 作为分布内测试数据集。此外,我们在分布外数据集上测试优化后的模型:GSM8K (Cobbe 等 2021) 、AIME24 3 、AMC23 4 、GaoKao2023En (X. Zhang 等 2023) 、Minerva Math (Lewkowycz 等 2022) 和 Olympiad Bench (He 等 2024) 。
对于LLM-as-a-Judge基准,我们在RewardBench (Lambert 等 2024) 上训练模型。具体来说,我们将原始数据转换为包含两个可能顺序的配对排名格式,创建5.97k条目。我们将它们分为包含5k条目的训练集和剩余970条目的测试集,表示为RewardBench970。为了确保有意义的数据分割,我们验证了两种分离策略:
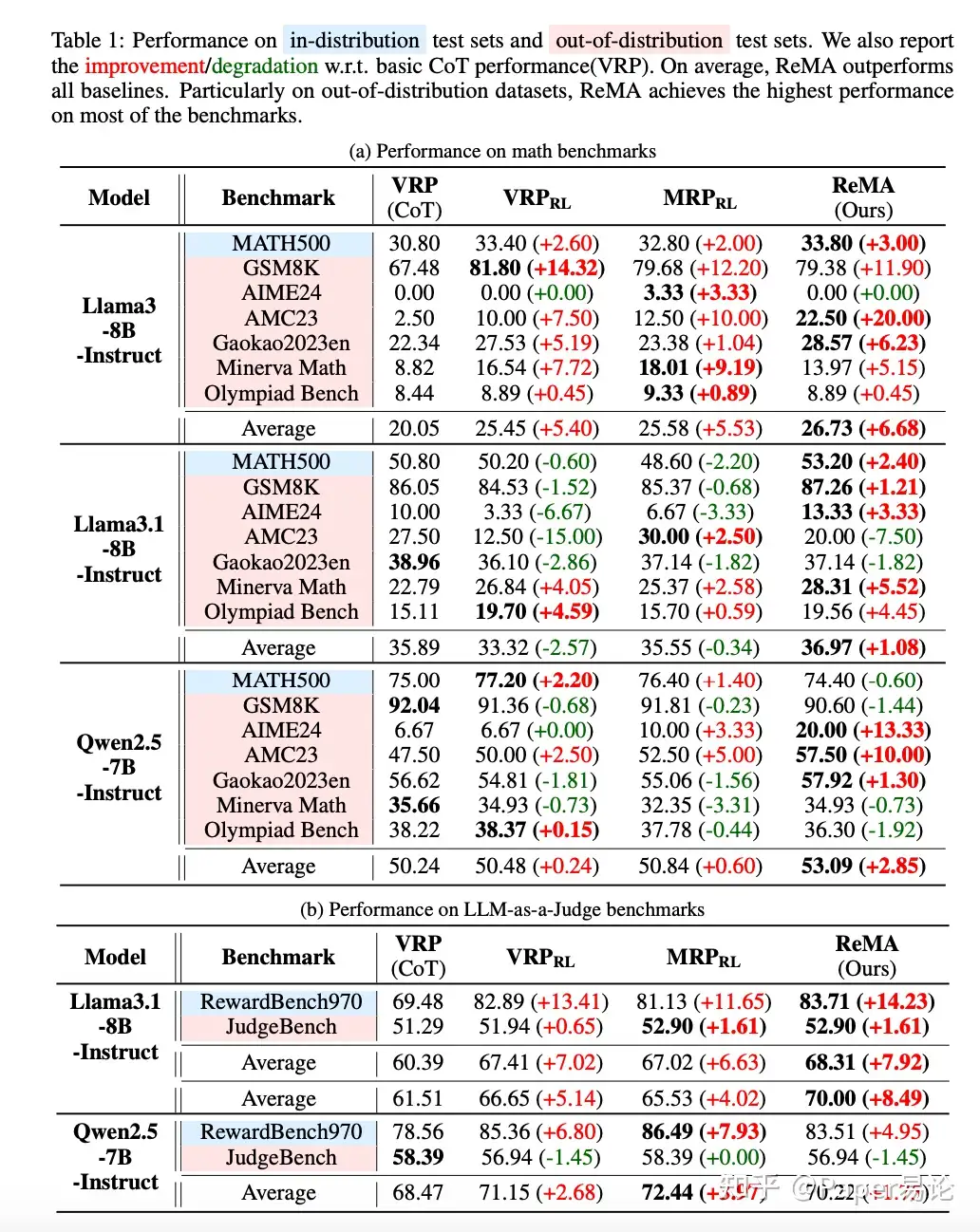
- 宽松设置:我们仅确保训练集和测试集之间没有直接重叠的条目。
- 严格设置:我们进一步强制规定训练集和测试集中不出现相同的指令。该设置的结果在主要结果(表 [tab:exp_main.laaj] )中呈现。
此外,由于原始RewardBench数据源自不同的子集,我们确保所有原始子集在训练集和测试集中均匀表示。
表 [tab:exp.abl.data_split.laaj] 报告了在宽松数据分割设置下各种方法的学习性能。与表 [tab:exp_main.laaj] 中的结果相比, ReMA 在所有模型上显著优于其他RL调优基线,特别是在分布外(OOD)基准上。 这两种设置在OOD数据集上的持续改进表明ReMA增强了元思考能力,从而在多样化的任务分布中实现了更好的泛化。
10 RL训练带来的改进
在本节中,我们展示了RL训练前后性能的差异。我们比较了三种推理设置: - VRP:单个LLM直接分步解决问题。
- MRP:单个LLM首先生成元思考消息,然后基于此解决问题。
- MAMRP:一个LLM生成元思考消息,另一个LLM根据此消息解决问题。
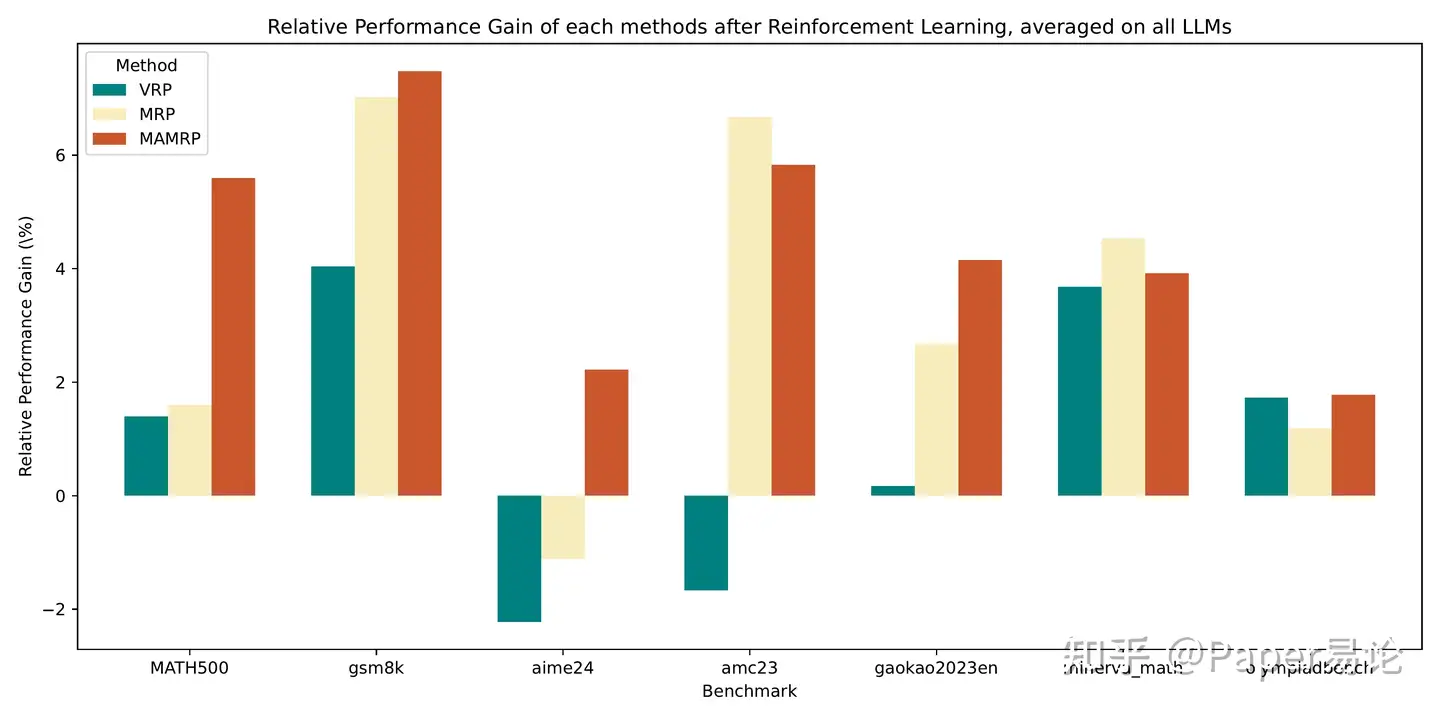
经过RL训练后三种不同推理设置的相对性能提升。
图 5 展示了结果。我们首先在没有RL训练的情况下评估这些设置,即使用直接推理作为基线。然后,我们将它们的性能与第 4.3 节中的RL训练模型进行比较。结果显示RL训练提升了所有设置下的整体性能,尤其在MRP和MAMRP中有显著改进。这强调了RL微调在优化推理质量方面的重要性。
11 简要收敛分析
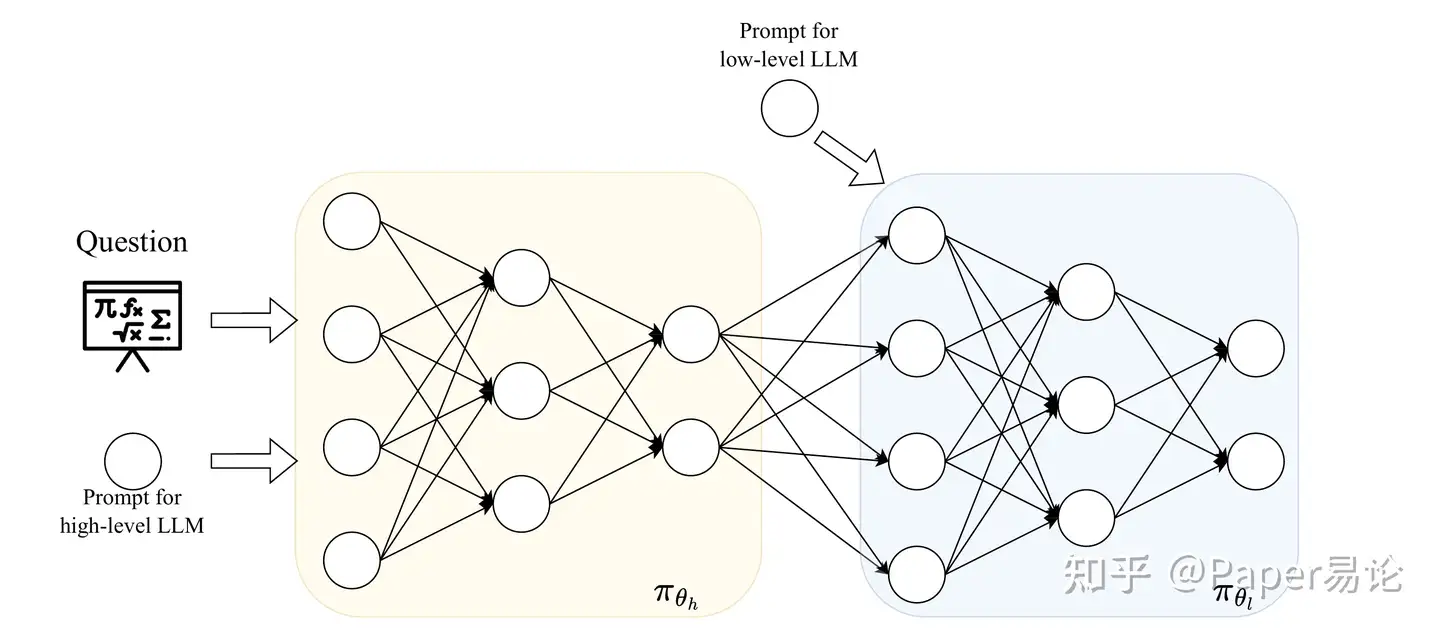
我们的方法可以看作是实用TRPO和块坐标上升的结合,将高和低层次模型视为更大神经网络中的不同组件。请注意,该图并不表示精确的梯度反向传播流程,而是突出了我们分离高和低层次模型的关键思想。这种分离允许独立计算梯度并独立训练每个模型。





鉴于理论上的单调改进与TRPO和块坐标上升,我们在实验中采用了实用版本的TRPO,具体为近端策略优化(PPO) (Schulman 等 2017) 或REINFORCE++ (J. Hu 2025b) 。
12 详细的奖励设计
为了考察不同奖励设计下的多智能体元认知整合推理,我们尝试了不同的奖励函数设计,以鼓励有效的协作和结构化推理。以下是几种奖励方案的介绍和理由。
12.0.0.1 1. 正确性和格式感知奖励(基础设置)
在我们的主要奖励设置中,系统的整体正确性用作主要奖励信号,并辅以针对高和低层次代理的基于格式的奖励。以数学问题求解为例:


12.0.0.2 2. 一致性奖励
这种方法不是使用正确性作为高层次奖励信号,而是奖励高层次代理促进低层次代理的一致性响应,无论实际正确性如何。一致性奖励定义为所有采样响应中最频繁出现的答案的比例:

如果大多数响应不包含确定的答案,则奖励设为零。如果高层次代理的输出包含指定的答案指示格式,我们还会对其施加格式惩罚。这激励高层次代理引导低层次代理朝更稳定、详细、可重复的输出方向发展,而不是不规则的推理路径。
这些不同的奖励公式使我们能够研究元认知推理的不同维度:正确性、一致性等。我们在第 4.4.2 节中经验性地比较了它们对学习元认知推理模式的影响。
13 从领导者跟随者游戏的角度学习推理
除了主文中提到的损失函数,我们还提出将问题框架为领导者跟随者游戏。通过分析领导者跟随者游戏的均衡点,我们证明了我们的框架本质上识别了与低层次模型能力相匹配的最佳子任务。这确保了高层次决策受到低层次模型优势的指导,从而实现更高效和针对性的任务分解。
13.1 领导者-跟随者游戏

C. Anil 等 (2021) 将领导者-跟随者游戏应用于确保证明者-验证者游戏中答案的可检查性。目标是一个既完整(接受所有正确证明)又可靠(拒绝所有错误证明)的验证者。他们分析了不同场景,其中验证者作为领导者,证明者作为跟随者,以及两者同时宣布策略形成Nash均衡。研究得出结论,在验证者主导的PVG中,达到一个Stackelberg均衡对于实现一个完整且可靠的验证者是必要且充分的,而在其他配置中,Stackelberg均衡不是必要或充分条件。
13.2 LLM的有效性

13.3 LLM推理中的领导者-跟随者游戏


为了分析通过最小化损失函数得到的结果代理,我们采用了PVG框架中的完整性与可靠性属性用于LLM推理。具体来说,如果高阶策略生成了一个在低阶策略能力范围内可执行的子任务序列,则问题必须得到解决(完整性)。相反,如果子任务序列错误或超出了低阶策略的能力范围,则问题无法解决(可靠性)。为了实现这一点,我们利用了 C. Anil 等 (2021) 的结论,即将低阶策略视为领导者,高阶策略视为跟随者,均衡保证了完整且可靠的低阶策略。
当高阶策略担任领导者时,低阶策略被迫适应高阶策略定义的具体策略,这可能导致既不完整也不可靠的低阶策略。例如,如果高阶策略规定它只会生成涉及加减法的子任务,那么低阶策略就被限制为只为这些任务优化。尽管它们可能达到均衡,但低阶策略仍然不完整,这种局限性影响了两个策略。对于同时的PVG游戏,可能会收敛到纳什均衡,但这不足以保证完整性和可靠性。例如,低阶策略可能会完全忽略高阶策略(例如,如果高阶策略提供了错误指令,但低阶策略仍然表现正确)。然而,这种方法由于涉及显著更大的搜索空间,实施起来具有挑战性。

这种方法可以看作是高阶“证明者”和低阶“验证者”之间的一场游戏。验证者代表低阶策略,遵循高阶策略的指示来验证其推理。与经典PVG设置不同的是,证明者拥有真实标签,而我们高阶策略的标签取决于可调的低阶策略。这种区别表明低阶策略(领导者)本质上更为复杂,由于高阶和低阶策略之间的相互依赖关系增加了复杂性。

14 ReMA 的伪代码
伪代码如算法 [alg:MAMRP_training] 所示。

15 监督微调数据收集
针对第 4.4.1 节中的实验,我们收集专家数据以增强推理模式, 即 RL from SFT 。具体而言,我们在MATH训练数据集(7.5k个问题)上从GPT-4o Mini收集演示数据 Hendrycks 等 (2021) 并用其微调LLMs。数据生成遵循以下步骤: 首先,我们提示GPT-4o Mini为高层次模型训练生成元认知推理。具体来说,我们使用不同的提示要求它重述和分解给定的问题而不提供最终答案。我们使用两个预定义的动作,“重述”和“分解”,收集元认知推理,这些动作与人类解决复杂问题的方法一致,同时保持答案多样性。接下来,我们使用生成的指令提示GPT-4o Mini遵循元认知步骤并解决问题,获得用于低层次策略训练的SFT数据。以下是为高、低层次模型使用的提示。
用于元认知推理重述的提示:
用于元认知推理分解的提示:
用于根据问题和元认知推理生成最终答案的提示:
16 训练细节
关于训练期间使用的提示,请参阅附录 18 。我们使用OpenRLHF (J. Hu 等 2024) 实现训练管道,这是一个高效的代码库,易于扩展。我们选择REINFORCE++以节省资源并进行高效训练。所有实验均在一个包含8块NVIDIA A100 GPU的节点上进行。我们使用bf16、Zero2、Flash-Attention和梯度检查点运行实验。
在采样过程中,我们将温度设为1.0,top_p设为1.0,top_k设为-1,并使用vLLM加速推理。我们将最大生成长度设为2048,采样批次大小设为1000。每次提示的样本数量为4。在训练过程中,我们使用Adam优化器,学习率为5e-7。我们将小批量大小设为500,裁剪比设为0.2。其他超参数,如KL系数和训练轮数,基于验证集性能进行了仔细调整,以确保稳健可靠的结果。为了与OpenRLHF中的超参数保持一致,我们将#Training Episode定义为在整个数据集上进行强化学习训练的轮数。

16.1 在MATH上的训练
16.1.0.1 VRP
对于Llama3-8B-Instruct、Llama3.1-8B-Instruct和Qwen2.5-7B-Instruct,我们都使用KL系数为1e-2,并分别为这三个模型设置了#Training Episode为12、6、6。
16.1.0.2 MRP
对于Llama3-8B-Instruct、Llama3.1-8B-Instruct和Qwen2.5-7B-Instruct,我们都使用KL系数为1e-2,并分别为这三个模型设置了#Training Episode为10、6、6。
16.1.0.3 MAMRP

16.2 在Reward Bench上的训练
16.2.0.1 VRP
对于Llama3.1-8B-Instruct和Qwen2.5-7B-Instruct,我们都使用KL系数为1e-2,对于#Training Episode,我们分别为这两个模型使用4和6。
16.2.0.2 MRP
对于Llama3.1-8B-Instruct和Qwen2.5-7B-Instruct,我们都使用KL系数为1e-2,对于#Training Episode,我们分别为这两个模型使用4和6。
16.2.0.3 MAMRP

17 定性结果
17.1 高层策略找到更好的计划
以下是一个示例,展示了高层策略如何改变LLM的解题方法,增加提供正确答案的可能性。从下面的例子可以看出,如果没有高层策略,LLM会统计所有整数坐标,包括边界上的坐标,然后减去边界坐标。相比之下,高层策略识别出一种更好的方法,直接指导LLM只统计严格位于边界内的坐标。

案例研究比较有无高层元认知的结果。
17.2 第 3.3 节实验的案例研究
图 8 和图 9 展示了第 3.3 节中的实验案例研究。
尽管两个代理都接收到与主实验结果相同的指令,但高层代理的一致性奖励显著改变了学习动态。正如图 8 所示,高层代理生成了详细的解决方案尝试而非战略性计划。因此,低层代理演变为验证高层代理的解决方案。这表明,在强化学习(RL)训练期间,两个代理发展出了一种以角色反转为特征的新颖问题解决模式,其中一个代理生成答案,而另一个代理对其进行验证。

高层代理一致性奖励的案例研究

高层代理基础正确性奖励的案例研究
17.3 第 4.5 节实验的案例研究
图 10 展示了在JSON动作中训练的两组LLMs的详细输出。与我们的主要实验相比,输出最终收敛到相对更容易和更短的句子。这可能是由于小型LM在同时生成有效JSON格式响应和探索多样推理策略时容量不足。

第 4.5 节可解释性实验的案例研究
Achiam, Josh, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, et al. 2023. “Gpt-4 技术报告。” arXiv 预印本 arXiv:2303.08774 .
Akata, Elif, Lion Schulz, Julian Coda-Forno, Seong Joon Oh, Matthias Bethge, and Eric Schulz. 2023. “用大语言模型进行重复博弈。” arXiv 预印本 arXiv:2305.16867 .
Anil, Cem, Guodong Zhang, Yuhuai Wu, and Roger B. Grosse. 2021. “通过证明者-验证者博弈学习给出可检查的答案。” CoRR abs/2108.12099. https://arxiv.org/abs/2108.12099 .
Anil, Rohan, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, et al. 2023. “Gemini: 一个功能强大的多模态模型家族。” arXiv 预印本 arXiv:2312.11805 1.
Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “语言模型是少样本学习者。” 神经信息处理系统进展会议论文集 33: 1877–1901.
Chen, Jiaqi, Yuxian Jiang, Jiachen Lu, and Li Zhang. 2024. “S-Agents: 开放式环境中的自组织代理。” arXiv 预印本 arXiv:2402.04578 .
Chen, Qiguang, Libo Qin, Jiaqi WANG, Jingxuan Zhou, and Wanxiang Che. 2024. “解锁思维能力:量化和优化链式思维的推理边界框架。” 在 第三十八届神经信息处理系统年度会议 中。 https://openreview.net/forum?id=pC44UMwy2v .
Chen, Shuhao, Weisen Jiang, Baijiong Lin, James T Kwok, and Yu Zhang. 2024. “RouterDC: 基于双重对比学习的查询路由器,用于组装大型语言模型。” arXiv 预印本 arXiv:2409.19886 .
Chen, Weize, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, et al. 2023. “Agentverse: 促进多代理协作并探索新兴行为。” 在 第十二届国际学习表征会议 中.
Chen, Yongchao, Jacob Arkin, Charles Dawson, Yang Zhang, Nicholas Roy, and Chuchu Fan. 2024. “Autotamp: 自回归任务与运动规划,LLM作为翻译器和检查器。” 在 2024 IEEE 国际机器人与自动化大会 (ICRA) 中, 6695–6702. IEEE.
Chowdhery, Aakanksha, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, et al. 2023. “Palm: 通过Pathways扩展语言建模。” 机器学习杂志研究 24 (240): 1–113.
Chu, Tianzhe, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. 2025. “SFT 记忆,RL 泛化:基础模型后训练的比较研究。” arXiv 预印本 arXiv:2501.17161 .
Cobbe, Karl, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, et al. 2021. “训练验证器以解决数学文字问题。” arXiv 预印本 arXiv:2110.14168 .
Cui, Ganqu, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, et al. 2025. “通过隐含奖励进行过程强化。” arXiv 预印本 arXiv:2502.01456 .
DeepMind, Google. 2025. “Gemini Flash Thinking.” https://deepmind.google/technologies/gemini/flash-thinking/ .
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, et al. 2025. “DeepSeek-R1: 通过强化学习激励LLM推理能力。” https://arxiv.org/abs/2501.12948 .
Didolkar, Aniket, Anirudh Goyal, Nan Rosemary Ke, Siyuan Guo, Michal Valko, Timothy Lillicrap, Danilo Rezende, Yoshua Bengio, Michael Mozer, and Sanjeev Arora. 2024. “LLMs的元认知能力:数学问题解决中的探索。” arXiv 预印本 arXiv:2405.12205 .
Ding, Dujian, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks VS Lakshmanan, and Ahmed Hassan Awadallah. 2024. “混合LLM:成本高效且质量感知的查询路由。” arXiv 预印本 arXiv:2404.14618 .
Dong, Kefan, 和 Tengyu Ma. 2025. “STP: 自我博弈LLM定理证明者,通过迭代猜想和证明。” https://arxiv.org/abs/2502.00212 .
Dong, Yixin, Charlie F Ruan, Yaxing Cai, Ruihang Lai, Ziyi Xu, Yilong Zhao, 和 Tianqi Chen. 2024. “Xgrammar: 大型语言模型灵活高效的结构化生成引擎。” arXiv 预印本 arXiv:2411.15100 .
Du, Yilun, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, 和 Igor Mordatch. 2023. “通过多代理辩论提高语言模型的事实性和推理能力。” 在 第四十一届国际机器学习会议 中.
Dubey, Abhimanyu, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, et al. 2024. “Llama 3 模型家族。” arXiv 预印本 arXiv:2407.21783 .
Estornell, Andrew, Jean-Francois Ton, Yuanshun Yao, 和 Yang Liu. 2024. “ACC-Debate: 多代理辩论的演员-评论家方法。” https://arxiv.org/abs/2411.00053 .
Feng, Xidong, Ziyu Wan, Muning Wen, Stephen Marcus McAleer, Ying Wen, Weinan Zhang, 和 Jun Wang. 2023. “AlphaZero-like树搜索可以指导大型语言模型解码和训练。” arXiv 预印本 arXiv:2309.17179 .
Flavell, John H. 1979. “元认知与认知监控:认知发展研究的新领域。” American Psychologist 34 (10): 906.
Gandhi, Kanishk, Ayush Chakravarthy, Anikait Singh, Nathan Lile, 和 Noah D. Goodman. 2025. “实现自我改进推理的认知行为,或,高效STaRs的四种习惯。” https://arxiv.org/abs/2503.01307 .
Gao, Peizhong, Ao Xie, Shaoguang Mao, Wenshan Wu, Yan Xia, Haipeng Mi, 和 Furu Wei. 2024. “大型语言模型的元推理。” arXiv 预印本 arXiv:2406.11698 .
Graves, Alex. 2012. “基于循环神经网络的序列转导。” arXiv 预印本 arXiv:1211.3711 .
Haji, Fatemeh, Mazal Bethany, Maryam Tabar, Jason Chiang, Anthony Rios, 和 Peyman Najafirad. 2024. “通过多代理思维树验证代理改进LLM推理。” https://arxiv.org/abs/2409.11527 .
Hao, Rui, Linmei Hu, Weijian Qi, Qingliu Wu, Yirui Zhang, 和 Liqiang Nie. 2025. “Chatllm 网络:更多的大脑,更聪明的智能。” AI Open .
He, Chaoqun, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, et al. 2024. “Olympiadbench:一个具有挑战性的基准测试,用于通过奥林匹克级别的双语多模态科学问题促进AGI发展。” arXiv 预印本 arXiv:2402.14008 .
Hendrycks, Dan, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, 和 Jacob Steinhardt. 2021. “通过Math数据集测量数学问题解决能力。” arXiv 预印本 arXiv:2103.03874 .
Hong, Sirui, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, et al. 2023. “Metagpt:用于多代理协作框架的元编程。” arXiv 预印本 arXiv:2308.00352 3 (4): 6.
Hu, Jian. 2025a. “REINFORCE++:对齐大型语言模型的简单高效方法。” arXiv 预印本 arXiv:2501.03262 .
———. 2025b. “REINFORCE++:对齐大型语言模型的简单高效方法。” https://arxiv.org/abs/2501.03262 .
Hu, Jian, Xibin Wu, Zilin Zhu, Xianyu, Weixun Wang, Dehao Zhang, 和 Yu Cao. 2024. “OpenRLHF:易于使用、可扩展且高性能的RLHF框架。” arXiv 预印本 arXiv:2405.11143 .
Hu, Qitian Jason, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, 和 Shriyash Kaustubh Upadhyay. 2024. “Routerbench:多LLM路由系统的基准测试。” arXiv 预印本 arXiv:2403.12031 .
Hui, Binyuan, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, et al. 2024. “Qwen2. 5-Coder 技术报告。” arXiv 预印本 arXiv:2409.12186 .
Jiao, Fangkai, Geyang Guo, Xingxing Zhang, Nancy F Chen, Shafiq Joty, 和 Furu Wei. 2024. “偏好优化用于伪反馈推理。” arXiv 预印本 arXiv:2411.16345 .
Kirchner, Jan Hendrik, Yining Chen, Harri Edwards, Jan Leike, Nat McAleese, 和 Yuri Burda. 2024a. “证明者-验证者游戏提高LLM输出的可解释性。” https://arxiv.org/abs/2407.13692 .
———. 2024b. “证明者-验证者游戏提高LLM输出的可解释性。” arXiv 预印本 arXiv:2407.13692 .
Kirk, Robert, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, 和 Roberta Raileanu. n.d. “理解RLHF对LLM泛化和多样性的影响。” 在 第十二届国际学习表征会议 中.
Kumar, Aviral, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, et al. 2024. “通过强化学习训练语言模型进行自我纠正。” arXiv 预印本 arXiv:2409.12917 .
Kwon, Woosuk, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, 和 Ion Stoica. 2023. “通过分页注意力管理大型语言模型服务的高效内存管理。” 在 ACM SIGOPS 第29届操作系统原理研讨会论文集 中.
Lambert, Nathan, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, et al. 2024. “Rewardbench:评估语言建模奖励模型。” arXiv 预印本 arXiv:2403.13787 .
Langley, Pat, Kirstin Cummings, 和 Daniel Shapiro. 2004. “层次技能与认知架构。” 在 年度认知科学学会会议论文集 中. 卷 26. 26.
Lewkowycz, Aitor, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, et al. 2022. “通过语言模型解决定量推理问题。” 神经信息处理系统进展会议论文集 35: 3843–57.
Li, Ming, Jiuhai Chen, Lichang Chen, 和 Tianyi Zhou. 2024. “LLMs能否代表多样化的人群?通过辩论微调LLMs以生成可控的争议性陈述。” arXiv 预印本 arXiv:2402.10614 .
Liang, Tian, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, 和 Zhaopeng Tu. 2023. “通过多代理辩论鼓励大型语言模型的发散思维。” arXiv 预印本 arXiv:2305.19118 .
Lightman, Hunter, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, 和 Karl Cobbe. 2023. “逐步验证。” arXiv 预印本 arXiv:2305.20050 .
Liu, Aixin, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, et al. 2024. “Deepseek-V3 技术报告。” arXiv 预印本 arXiv:2412.19437 .
Ma, Chengdong, Ziran Yang, Minquan Gao, Hai Ci, Jun Gao, Xuehai Pan, 和 Yaodong Yang. 2023. “红队博弈:一种针对语言模型的博弈论框架。” arXiv 预印本 arXiv:2310.00322 .
Ma, Hao, Tianyi Hu, Zhiqiang Pu, Boyin Liu, Xiaolin Ai, Yanyan Liang, 和 Min Chen. 2024. “与另一个你共同进化:通过顺序合作多代理强化学习微调LLM。” CoRR abs/2410.06101. https://doi.org/10.48550/ARXIV.2410.06101 .
Madaan, Aman, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, et al. 2023. “Self-Refine:通过自反馈进行迭代细化。” 神经信息处理系统进展会议论文集 36: 46534–94.
Mahan, Dakota, Duy Van Phung, Rafael Rafailov, Chase Blagden, Nathan Lile, Louis Castricato, Jan-Philipp Fränken, Chelsea Finn, 和 Alon Albalak. 2024. “生成式奖励模型。” arXiv 预印本 arXiv:2410.12832 .
Motwani, Sumeet Ramesh, Chandler Smith, Rocktim Jyoti Das, Markian Rybchuk, Philip H. S. Torr, Ivan Laptev, Fabio Pizzati, Ronald Clark, 和 Christian Schroeder de Witt. 2024. “MALT:通过多代理LLM训练改进推理。” https://arxiv.org/abs/2412.01928 .
Muennighoff, Niklas, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, 和 Tatsunori Hashimoto. 2025. “S1:简单的测试时扩展。” arXiv 预印本 arXiv:2501.19393 .
OpenAI. 2024. “OpenAI O1 系统卡。” https://openai.com/o1/ .
Ouyang, Long, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, et al. 2022. “通过人类反馈训练语言模型遵循指令。” 神经信息处理系统进展会议论文集 35: 27730–44.
Park, Chanwoo, Seungju Han, Xingzhi Guo, Asuman Ozdaglar, Kaiqing Zhang, 和 Joo-Kyung Kim. 2025. “MAPoRL:通过强化学习进行协同大型语言模型的多代理后联合训练。” https://arxiv.org/abs/2502.18439 .
Perez, Ethan, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, 和 Geoffrey Irving. 2022. “用语言模型进行红队博弈。” arXiv 预印本 arXiv:2202.03286 .
Puerta-Merino, Israel, Carlos Núñez-Molina, Pablo Mesejo, 和 Juan Fernández-Olivares. 2025. “整合LLM到分层规划中的路线图。” arXiv 预印本 arXiv:2501.08068 .
Qi, Zhenting, Mingyuan Ma, Jiahang Xu, Li Lyna Zhang, Fan Yang, 和 Mao Yang. 2024. “相互推理使较小的LLM成为更强的问题解决者。” arXiv 预印本 arXiv:2408.06195 .
Qin, Yiwei, Xuefeng Li, Haoyang Zou, Yixiu Liu, Shijie Xia, Zhen Huang, Yixin Ye, et al. 2024. “O1复制旅程:战略性进度报告 - 第一部分。” https://arxiv.org/abs/2410.18982 .
Rafailov, Rafael, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, 和 Chelsea Finn. 2023. “直接偏好优化:你的语言模型实际上是隐藏的奖励模型。” 神经信息处理系统进展会议论文集 36: 53728–41.
Rana, Krishan, Jesse Haviland, Sourav Garg, Jad Abou-Chakra, Ian Reid, 和 Niko Suenderhauf. 2023. “Sayplan:利用3D场景图将大型语言模型接地以实现可扩展的机器人任务规划。” arXiv 预印本 arXiv:2307.06135 .
Saha, Swarnadeep, Xian Li, Marjan Ghazvininejad, Jason Weston, 和 Tianlu Wang. 2025a. “学习计划和推理以评估思考-LLM作为法官。” https://arxiv.org/abs/2501.18099 .
———. 2025b. “学习计划和推理以评估思考-LLM作为法官。” arXiv 预印本 arXiv:2501.18099 .
Schulman, John, Sergey Levine, Pieter Abbeel, Michael I. Jordan, 和 Philipp Moritz. 2015. “信任区域策略优化。” 在 ICML 2015 第32届国际机器学习会议论文集,法国里尔,2015年7月6日至11日 中, 由 Francis R. Bach 和 David M. Blei 编辑,37:1889–97. JMLR 工作坊和会议记录。JMLR.org. http://proceedings.mlr.press/v37/schulman15.html .
Schulman, John, Filip Wolski, Prafulla Dhariwal, Alec Radford, 和 Oleg Klimov. 2017. “近端策略优化算法。” CoRR abs/1707.06347. http://arxiv.org/abs/1707.06347 .
Snell, Charlie, Jaehoon Lee, Kelvin Xu, 和 Aviral Kumar. 2024. “最优扩展LLM测试时计算比扩展模型参数更有效。” arXiv 预印本 arXiv:2408.03314 .
Song, Chan Hee, Jiaman Wu, Clayton Washington, Brian M Sadler, Wei-Lun Chao, 和 Yu Su. 2023. “LLM-Planner:使用大型语言模型进行少样本接地规划的实体代理。” 在 IEEE/CVF 国际计算机视觉会议论文集 中,2998–3009.
Stripelis, Dimitris, Zijian Hu, Jipeng Zhang, Zhaozhuo Xu, Alay Dilipbhai Shah, Han Jin, Yuhang Yao, Salman Avestimehr, 和 Chaoyang He. 2024. “TensorOpera 路由器:用于高效LLM推理的多模型路由器。” arXiv 预印本 arXiv:2408.12320 .
Subramaniam, Vighnesh, Yilun Du, Joshua B. Tenenbaum, Antonio Torralba, Shuang Li, 和 Igor Mordatch. 2025. “多代理微调:通过多样推理链实现自我改进。” https://arxiv.org/abs/2501.05707 .
Sun, Chuanneng, Songjun Huang, 和 Dario Pompili. 2024. “检索增强的层次上下文强化学习和事后模块化反思,用于LLM任务规划。” arXiv 预印本 arXiv:2408.06520 .
Sutton, Richard. 2019. “苦涩的教训。” Incomplete Ideas (博客) 13 (1): 38.
Tan, Sijun, Siyuan Zhuang, Kyle Montgomery, William Y Tang, Alejandro Cuadron, Chenguang Wang, Raluca Ada Popa, 和 Ion Stoica. 2024. “Judgebench:评估基于LLM的法官的基准。” arXiv 预印本 arXiv:2410.12784 .
Tang, Xiangru, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, 和 Mark Gerstein. 2023. “Medagents:大型语言模型作为零样本医学推理的合作者。” arXiv 预印本 arXiv:2311.10537 .
Team, Qwen. 2024. “Qwen2.5:基础模型的派对。” https://qwenlm.github.io/blog/qwen2.5/ .
Wang, Jun, Meng Fang, Ziyu Wan, Muning Wen, Jiachen Zhu, Anjie Liu, Ziqin Gong, et al. 2024. “Openr:用于高级推理的开源框架。” arXiv 预印本 arXiv:2410.09671 .
Wang, Tianlu, Ilia Kulikov, Olga Golovneva, Ping Yu, Weizhe Yuan, Jane Dwivedi-Yu, Richard Yuanzhe Pang, Maryam Fazel-Zarandi, Jason Weston, 和 Xian Li. 2024. “自学评估者。” arXiv 预印本 arXiv:2408.02666 .
Wang, Xuezhi, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, 和 Denny Zhou. 2022. “自一致性在语言模型中提升链式思维推理。” arXiv 预印本 arXiv:2203.11171 .
Wang, Yuqing, 和 Yun Zhao. 2023. “元认知提示提高了大型语言模型的理解能力。” arXiv 预印本 arXiv:2308.05342 .
Wang, Zhenhailong, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, 和 Heng Ji. 2023. “释放大型语言模型中出现的认知协同作用:通过多角色自我------ 协作的任务求解代理。” arXiv 预印本 arXiv:2307.05300 .
Wei, Jason, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. “链式思维提示在大型语言模型中激发推理。” 神经信息处理系统进展会议论文集 35: 24824–37.
Welleck, Sean, Ximing Lu, Peter West, Faeze Brahman, Tianxiao Shen, Daniel Khashabi, 和 Yejin Choi. 2022. “通过学习自我纠正生成序列。” arXiv 预印本 arXiv:2211.00053 .
Williams, Ronald J. 1992. “连接主义强化学习的简单统计梯度跟随算法。” 机器学习 8: 229–56. https://doi.org/10.1007/BF00992696 .
Xi, Zhiheng, Dingwen Yang, Jixuan Huang, Jiafu Tang, Guanyu Li, Yiwen Ding, Wei He, et al. 2024. “通过测试时和训练时监督的批判模型增强LLM推理。” arXiv 预印本 arXiv:2411.16579 .
Xiang, Violet, Charlie Snell, Kanishk Gandhi, Alon Albalak, Anikait Singh, Chase Blagden, Duy Phung, et al. 2025. “朝着LLM中的系统2推理迈进:通过元链式思考学习如何思考。” arXiv 预印本 arXiv:2501.04682 .
Xiao, Yihang, Jinyi Liu, Yan Zheng, Xiaohan Xie, Jianye Hao, Mingzhi Li, Ruitao Wang, et al. 2024. “Cellagent:一种由LLM驱动的多代理框架,用于自动化的单细胞数据分析。” BioRxiv , 2024–05.
Xie, Tian, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, 和 Chong Luo. 2025. “Logic-RL:通过基于规则的强化学习释放LLM推理能力。” arXiv 预印本 arXiv:2502.14768 .
Xu, Fengli, Qianyue Hao, Zefang Zong, Jingwei Wang, Yunke Zhang, Jingyi Wang, Xiaochong Lan, et al. 2025. “迈向大型推理模型:使用大型语言模型进行强化推理的综述。” arXiv 预印本 arXiv:2501.09686 .
Yadav, Prateek, Tu Vu, Jonathan Lai, Alexandra Chronopoulou, Manaal Faruqui, Mohit Bansal, 和 Tsendsuren Munkhdalai. 2024. “规模模型合并中什么最重要?” arXiv 预印本 arXiv:2410.03617 .
Yan, Xue, Yan Song, Xinyu Cui, Filippos Christianos, Haifeng Zhang, David Henry Mguni, 和 Jun Wang. 2023. “问得更多,知道得更好:通过强化学习生成提示问题以利用大型语言模型进行决策。” arXiv 预印本 arXiv:2310.18127 .
Yang, An, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, et al. 2024. “Qwen2.5-Math 技术报告:通过自我改进实现数学专家模型。” arXiv 预印本 arXiv:2409.12122 .
Yang, Ling, Zhaochen Yu, Bin Cui, 和 Mengdi Wang. 2025. “ReasonFlux:通过扩展思维模板实现分层LLM推理。” arXiv 预印本 arXiv:2502.06772 .
Yao, Shunyu, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, 和 Karthik Narasimhan. 2023. “思维树:利用大型语言模型进行深思熟虑的问题解决。” 在 神经信息处理系统进展会议第36卷:2023年神经信息处理系统年度会议,NeurIPS 2023,美国路易斯安那州新奥尔良,2023年12月10日至16日 中, 由 Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, 和 Sergey Levine 编辑。 http://papers.nips.cc/paper_files/paper/2023/hash/271db9922b8d1f4dd7aaef84ed5ac703-Abstract-Conference.html .
Ye, Guanghao, Khiem Duc Pham, Xinzhi Zhang, Sivakanth Gopi, Baolin Peng, Beibin Li, Janardhan Kulkarni, 和 Huseyin A Inan. 2025. “论LLM中思考的出现:寻找正确的直觉。” arXiv 预印本 arXiv:2502.06773 .
Ye, Peijun, Tao Wang, 和 Fei-Yue Wang. 2018. “过去20年认知架构的综述。” IEEE 网络科学与工程汇刊 48 (12): 3280–90.
Ye, Yaowen, Cassidy Laidlaw, 和 Jacob Steinhardt. 2025. “弱监督下的迭代标签细化比偏好优化更重要。” arXiv 预印本 arXiv:2501.07886 .
Ye, Yixin, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, 和 Pengfei Liu. 2025. “LIMO:推理中少即是多。” arXiv 预印本 arXiv:2502.03387 .
Yu, Le, Bowen Yu, Haiyang Yu, Fei Huang, 和 Yongbin Li. 2024. “语言模型是超级马里奥:吸收同源模型的能力作为免费午餐。” 在 第四十一届国际机器学习会议 中.
Yue, Murong, Wenlin Yao, Haitao Mi, Dian Yu, Ziyu Yao, 和 Dong Yu. 2024. “DOTS:通过最优推理轨迹搜索在LLM中动态学习推理。” CoRR abs/2410.03864. https://doi.org/10.48550/ARXIV.2410.03864 .
———. n.d. “DOTS:通过最优推理轨迹搜索在LLM中动态学习推理。” 在 第十三届国际学习表征会议 中.
Yue, Yanwei, Guibin Zhang, Boyang Liu, Guancheng Wan, Kun Wang, Dawei Cheng, 和 Yiyan Qi. 2025. “MasRouter:为多代理系统学习路由LLM。” arXiv 预印本 arXiv:2502.11133 .
Zhang, Di, Jianbo Wu, Jingdi Lei, Tong Che, Jiatong Li, Tong Xie, Xiaoshui Huang, et al. 2024. “LLaMA-Berry:O1类奥林匹克级别数学推理的成对优化。” https://arxiv.org/abs/2410.02884 .
Zhang, Hangfan, Zhiyao Cui, Xinrun Wang, Qiaosheng Zhang, Zhen Wang, Dinghao Wu, 和 Shuyue Hu. 2025. “如果多代理辩论是答案,那么问题是什么?” arXiv 预印本 arXiv:2502.08788 .
Zhang, Jiayi, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, et al. 2024. “Aflow:自动化代理工作流生成。” arXiv 预印本 arXiv:2410.10762 .
Zhang, Xiaotian, Chunyang Li, Yi Zong, Zhengyu Ying, Liang He, 和 Xipeng Qiu. 2023. “评估大型语言模型在高考基准上的表现。” arXiv 预印本 arXiv:2305.12474 .
Zhang, Yiqun, Peng Ye, Xiaocui Yang, Shi Feng, Shufei Zhang, Lei Bai, Wanli Ouyang, 和 Shuyue Hu. 2025. “受自然启发的大型语言模型种群进化。” arXiv 预印本 arXiv:2503.01155 .
Zhao, Yu, Huifeng Yin, Bo Zeng, Hao Wang, Tianqi Shi, Chenyang Lyu, Longyue Wang, Weihua Luo, 和 Kaifu Zhang. 2024. “Marco-O1: 面向开放式解决方案的开放推理模型。” https://arxiv.org/abs/2411.14405 .
Zhuge, Mingchen, Haozhe Liu, Francesco Faccio, Dylan R Ashley, Róbert Csordás, Anand Gopalakrishnan, Abdullah Hamdi, et al. 2023. “基于自然语言的思维社会中的思维风暴。” arXiv 预印本 arXiv:2305.17066 .