简介
种子调度,用来确定种子选择的顺序,很大影响了fuzzer的性能。现有的方法利用历史变异信息来调度,但是忽视了控制流图的结构。检查CFG可以帮助种子调度从变异种子上提高边的覆盖率。
一个理想的策略是基于种子通过突变产生的所有可达和可行边的数量来调度种子。但是计算所有边的可达性的开销很大。因此,种子调度策略需要估计这个数量。作者发现估计的count需要满足三个属性:
-
当一个种子可以到达更多的边的时候,count需要增加
-
当一个历史变异信息提示边很难到达的时候或者边离当前访问的边很远的时候,count需要减少
-
需要在大型CFG中进行计算。
作者观察到图分析里的中心性提供了这三个属性,因此可以高效地估计到达未访问边的概率。然后,构建一种名为edge horizon 的图,能够连接种子到他们最近的未访问节点,然后计算种子的中心性去测量变异一个种子的边覆盖率增量(gain)。
作者实现了他们的方法,叫做K-Scheduler,并且和其他著名的种子调度策略比较。发现K-Scheduler在12个谷歌的fuzzbench上,相比Entropic提高了25.89%的特征覆盖率,比next-best AFL-Based调度器的边覆盖率要高4.21%。同样也发现了3个未知的漏洞。
方法
给定目标程序,种子语料库和程序的过程间控制流图。基于控制流图先生成edge horizon graph。这个图只包含种子,horizon和non-horizon未访问的节点。然后对edge horizon graph计算Katz中心性。然后fuzzer会优先变异更高中心性的种子。后续fuzzer访问到了这些之前没访问过的节点后,就删除这些新访问的节点,然后重新在更新后的edge horizon graph上计算Katz 中心性。
图a是最左边小程序的控制流图。图b是edge horizon graph。节点A和B是horizon node,因为他们是未访问的节点,且他们的父节点是访问过的。然后把种子节点插入到CFG中,然后将他们与horizon node相连。与之相连的horizon node的父节点需要在种子的执行路径上。所以a=5,b=30这一种子只与A节点相连。最后删除掉所有已访问过的节点。
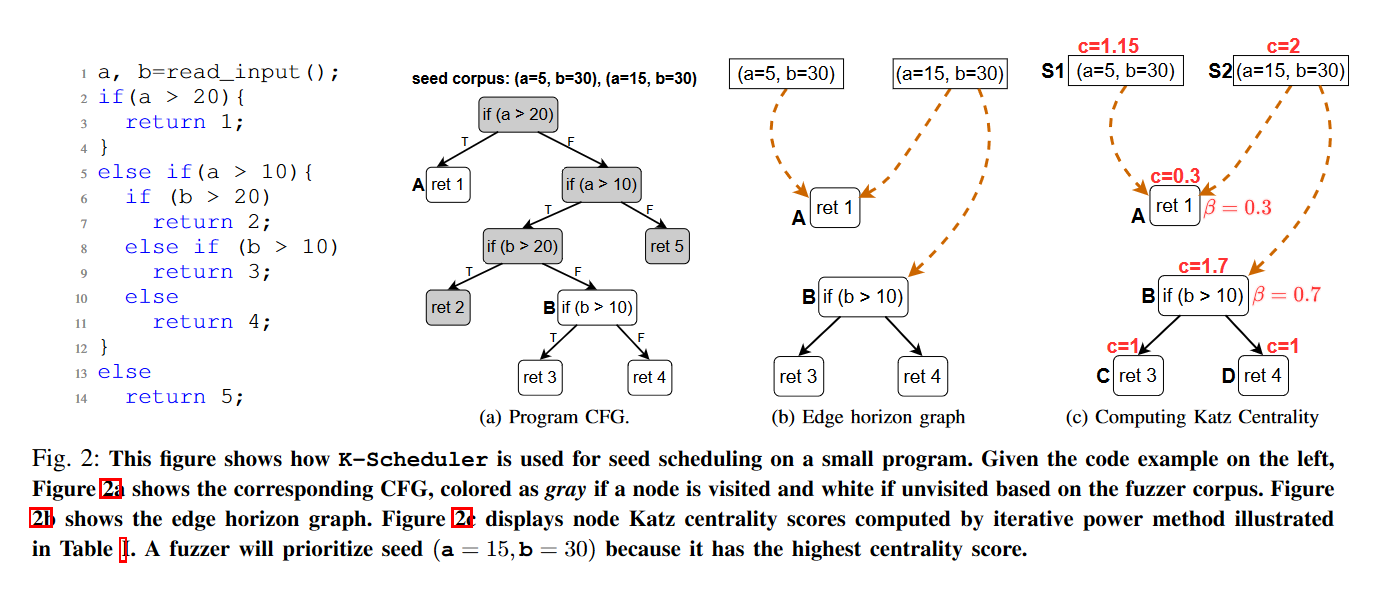
katz中心性计算如下:使用β来表示通过变异到达一个节点的难易程度。例如,在100次变异过程中,70次到达了horizon node A的父节点,30次到达了horizon node B的父节点,所以A的β值为1-0.7=0.3,B的值为0.7。这说明节点A更难到达。Katz中心性也会随着节点越远而减少。中心性的计算采取迭代的方式计算,最终会收敛。

论文中还介绍了如何构造Edge horizon graph,如何计算Katz 中心性以及实际是如何应用到fuzz中的。对这部分内容感兴趣的可以去看原文。本文就不再赘述了。
结果
结果部分主要回答以下五个问题:
- 和其他的调度策略相比如何?
- 能否提高fuzzer发现漏洞的能力
- 运行时的开销如何?
- K-Scheduler的各种设计选择会如何影响他的性能
- 能否应用到非进化算法的模糊测试中?
问题1:和其他的调度策略相比如何?
第一个表是跑1小时,第二个表是跑24小时。整体上的覆盖率都是高的。
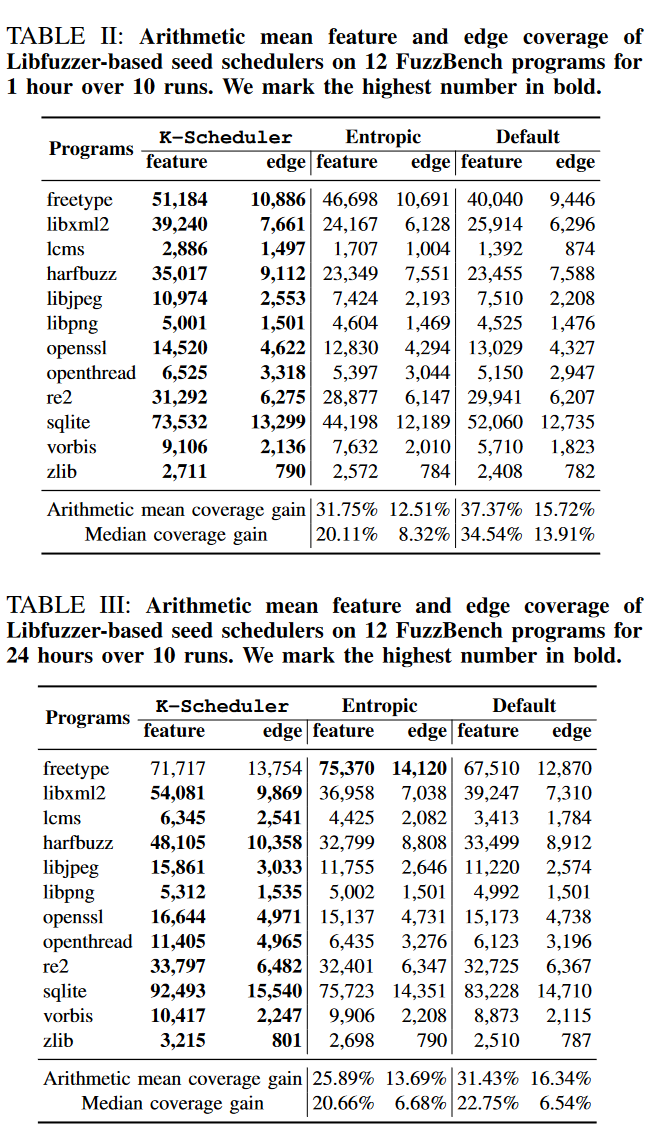
作者认为他们的工作能在前期有个比较好的提升。随着时间的增加,entropic也会分配能量到那些好的种子上去,从而就缩小了差距。
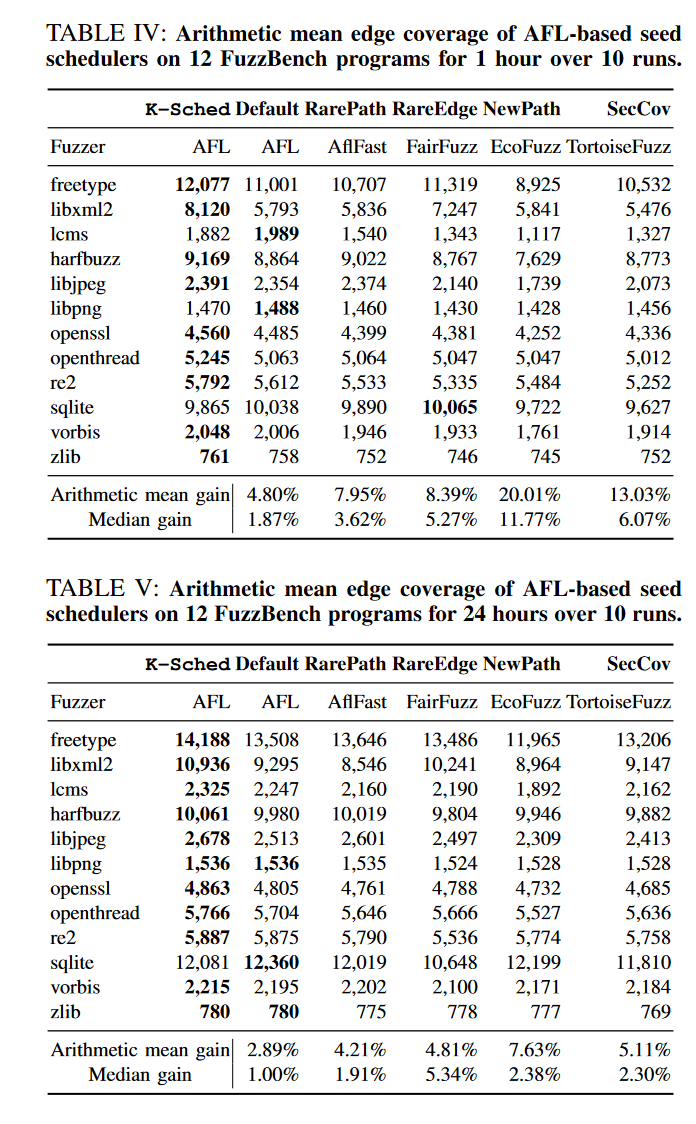
对比AFL上实现的工作,感觉在1h增加的覆盖率更高一些。AFL上增加的幅度实际上不是很大。
问题2:能否提高fuzzer发现漏洞的能力
能比最好的多找3个。作者计算漏洞的数量是先用AFL-Cmin去减少崩溃输入的数量。然后通过stack traces进一步过滤。最后追踪剩下的崩溃输入,并且人工检查他们的stack traces和源码。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aYIIo4VE-1665486095989)(C:\Users\zhang\AppData\Roaming\Typora\typora-user-images\image-20221011173051707.png)]
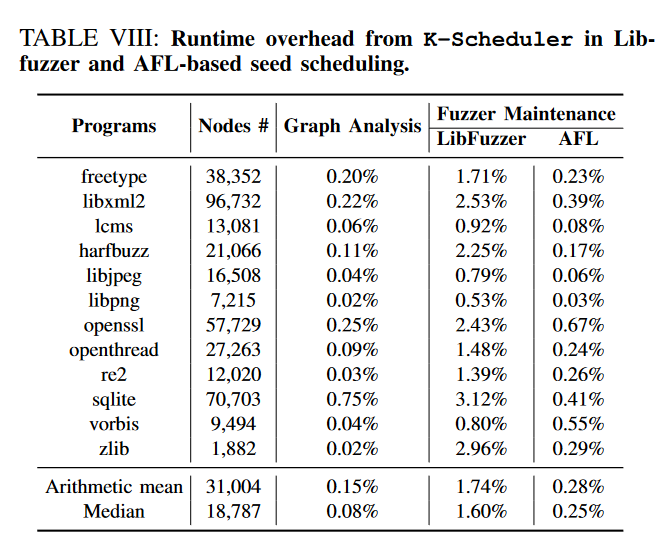
3. 运行开销
运行开销主要分为
- fuzzer记录边命中的数量和计算种子能量
- 调用K-Scheduler来调度种子
运行开销不大,看起来可以忽略不计。开销和程序CFG节点的数量有关。
4. 哪些参数会影响
1)中心性算法:对比了PageRank,Eigenvector,Degree,Katz这几种
2)Katz的β,α参数的影响。(有点像调参出来的)
3)删除已访问的节点:虽然文章没说原因,感觉是减少了运行开销,所以最后的覆盖率增加了。
4)Loop removal:引入了loop removal transform来缓解循环对中心性计算的影响。
5. 应用到QSYM上
作者把k-scheduler整合进QSYM中,发现也提高了不少覆盖率。但是实验结果还比较初步,准备留到未来再详细讨论。
相关工作
相关工作部分主要讲了图中心性和种子调度这两方面。
图中心性
图中心性列举了不少指标,包括degree centrality, semi-local centrality, closeness centrality, betweenness centrality, eigenvector centrality, katz centrality, PageRank。这些中心性指标已经被应用到各种领域,比如社交网络分析,生物,经济和地理等等。作者认为他们是第一个用在fuzzing的种子选择里。
种子调度
种子调度包含两部分主要模块:种子选择和能量调度。
前人工作在选择种子上,有利用边和路径覆盖率的,也有用一些安全敏感的指标,比如执行时间,可利用性,内存访问或者他们的组合。另一类选择种子的工作是基于调用图。而作者的工作是基于完整的过程间的控制流图。AFLGo也基于完整的过程间控制流图,不过他计算的是距离,并且用来作定向模糊测试。而本文侧重的是增加覆盖率。SAVIOR也估计这个分数,不过是用在bug-driven的混合测试里。他的假设是所有的边都是同等可到达的,也不管种子执行路径的距离。这个假设和真实程序的场景不太吻合。不管哪个,都用了变异的历史信息来优化这个估计过程。
总结
文章提出的horizon node graph的图很有意思。并且katz中心性是可以根据fuzzer状态动态更新的。这点或许可以借鉴。
实验部分也做得好扎实,足足有7页,再加上一大堆图表。就是对benchmark程序的选择有些疑惑。没明白为什么选这些程序。虽然提到了未来要测试所有的程序。
开源于:https://github.com/Dongdongshe/K-Scheduler