1、最近运行MapReduce任务一直出现下面这个问题,找人帮忙看,最后终于发现问题的点了,原来是自己代码有点问题,一个方法名写错了,导致这个问题困扰了自己很久,下面我就将问题的错误贴出来,错误如下:
packageJobJar: [./map.py, /tmp/hadoop-unjar6994337348538798719/] [] /tmp/streamjob5332644889137510221.jar tmpDir=null
18/07/05 03:43:45 INFO client.RMProxy: Connecting to ResourceManager at linux102/192.168.30.102:8032
18/07/05 03:43:45 INFO client.RMProxy: Connecting to ResourceManager at linux102/192.168.30.102:8032
18/07/05 03:43:46 INFO mapred.FileInputFormat: Total input paths to process : 1
18/07/05 03:43:46 INFO mapreduce.JobSubmitter: number of splits:2
18/07/05 03:43:46 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1530784717299_0002
18/07/05 03:43:47 INFO impl.YarnClientImpl: Submitted application application_1530784717299_0002
18/07/0503:43:47INFOmapreduce.Job:Theurltotrackthejob: http://linux102:8088/proxy/application_1530784717299_0002/
18/07/05 03:43:47 INFO mapreduce.Job: Running job: job_1530784717299_0002
18/07/05 03:43:55 INFO mapreduce.Job: Job job_1530784717299_0002 running in uber mode : false
18/07/05 03:43:55 INFO mapreduce.Job: map 0% reduce 0%
18/07/05 03:44:05 INFO mapreduce.Job: Task Id : attempt_1530784717299_0002_m_000000_0, Status : FAILED
Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1
at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:322)
at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:535)
at org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:130)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)
at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:34)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:450)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
18/07/05 03:44:05 INFO mapreduce.Job: Task Id : attempt_1530784717299_0002_m_000001_0, Status : FAILED
Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1
at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:322)
at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:535)
at org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:130)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)
at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:34)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:450)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
查看了yarn管理端的日志,出现如下错误:
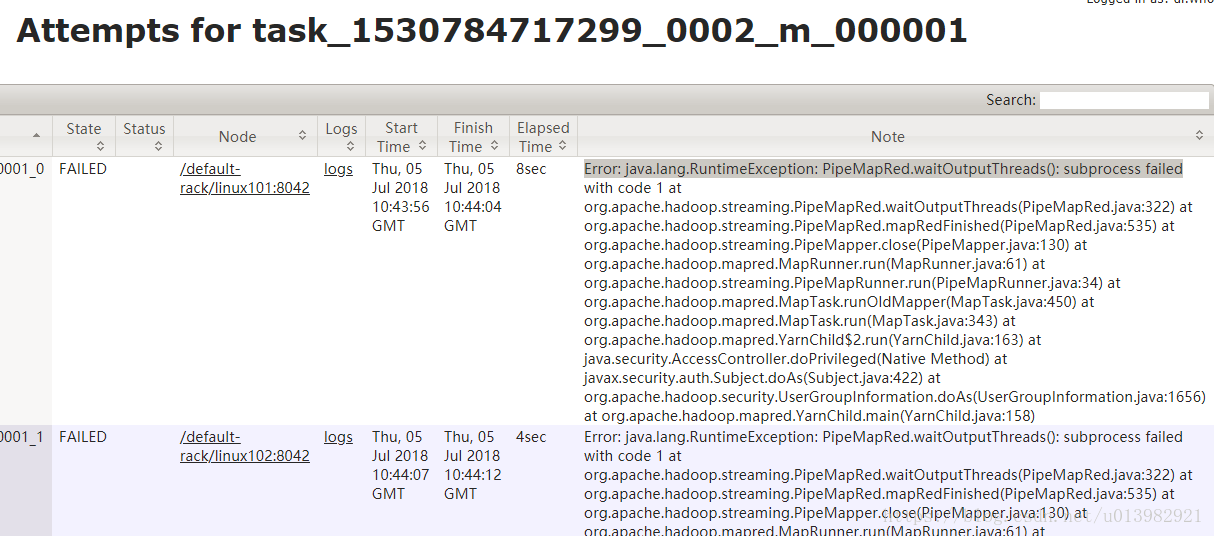
一开始先检查环境有没有问题,查看集群所有的进程是否正常,发现集群正常,而且自己重启了集群,再次运行任务,还是出现相同的错误,因此排除了集群不正常导致的问题,接下来开始检查跑任务所需的文件是否都已经上传到了集群相应的位置,也发现文件都正常上传,排除了这个问题;然后检查了集群的的配置文件,也检查了集群节点的log日志也都是正常;最后定位到是否是自己代码的问题,于是一遍一遍,一行一行开始与老师代码进行比对,还真发现是自己一个函数名称写错了导致的,如下图所示:
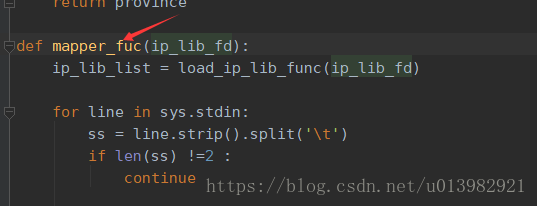
后来修改了这个函数名,再次运行可以了,经过这么多坑,一定得认真仔细。
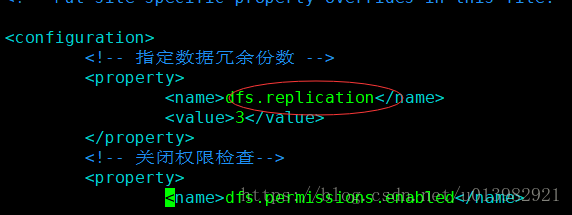
2、发现有人也遇到出现相同的错误,但不是代码当中出现了问题,最后排查到是hadoop的一个配置文件写错了,将replication少写了一个字母a;
3、还有一个比较常见的错误,也是比较不好处理的,就是用IDEA或是用pycharm编写shell脚本无法运行,或是运行时遇到一堆的命令无法识别,最后发现是用IDEA编写shell脚本会出现一堆的特殊字符,比如将换行符会识别成 \r\n,这种形式,如何解决这问题呢,就是在运行run.sh之前,先执行下面这个命令:sed -i 's/\r$//' run.sh,然后在运行shell脚本就不报错了(这里建议编写shell脚本还是使用vim在终端上编写比较好),这里简单介绍下sed这个命令,也许好多人会有疑惑:
sed命令是一个面向字符流的非交互式编辑器,也就是说sed不允许用户与它进行交互操作。sed是按行来处理文本内容的。在shell中,使用sed来批量修改文本内容是非常方便的。
-i :直接修改读取的文件内容,而不是输出到终端,'s/\r$//'这个是正则表达式 ,s/:匹配任何空白字符,\r匹配一个回车符,$匹配输入字符串的结束位置,/表达式的开始和结束的“定界符”.(想更深入了解sed命令或是正则表达式可以查阅详细资料)
总结了一下排除上述问题的一个自己的心得:
感觉MapReduce任务离线调试真的坑比较多,很难定位到问题的所在,出现上述类问题主要有以下几点:1、集群环境处于不稳定状态;2、自己代码问题,可能是很小的一个细节;3、mapreduce任务配置参数的问题。
遇到问题,不要怕麻烦,从程序的源头开始一步步排查,在排查的过程中不断总结,你的能力也就一步步在此过程中会慢慢提升。其实大多数人遇到问题最怕没有思路,不知道从哪里下手,这样会耗费大量时间。遇到问题能有个自己的思路是关键,我们首先得明白有哪些可能会导致出现这些问题,然后开始排查,这样处理问题才能有条不紊的进行下去,也是一种解决问题的比较好的方式。(踩得坑多了,路自然就平了,欢迎丢砖块)