【工业机器视觉】基于深度学习的仪表盘识读(2)-CSDN博客
数据标注
标注扩展
Labelme 和 LabelImg 都是用于创建机器学习和计算机视觉项目所需标注数据的工具。它们都允许用户通过图形界面手动标注图像,但各自有其特点和适用场景。
Labelme
- 开发语言:Python
- 标注类型:Labelme 支持多种标注类型,包括但不限于多边形(polygon)、矩形(rectangle)、线段(line)、点(point)等。它非常适合需要精确标注物体边界的情况,比如在医疗影像、自动驾驶等领域。
- 文件格式:标注结果通常保存为 JSON 文件,其中包含每个标注对象的坐标信息、标签名称等。
- 灵活性:Labelme 提供了插件系统,可以扩展其功能,如支持更多的图像格式或添加自定义的标注类型。
- 跨平台:基于 Python 的 Qt 库构建,可以在 Windows、macOS 和 Linux 上运行。
LabelImg
- 开发语言:Python
- 标注类型:主要支持矩形框(bounding box)标注,适合于目标检测任务。对于需要简单快速地对多个对象进行框选标注的任务来说非常方便。
- 文件格式:标注结果可以保存为 Pascal VOC XML 格式或者 YOLO txt 格式,这两种格式都是目标检测任务中常用的标注文件格式。
- 轻量化:相比于 Labelme,LabelImg 更加轻量化,易于安装和使用,尤其适合初学者。
- 跨平台:同样基于 Python 的 Qt 库,可以在不同操作系统上运行。
安装扩展包:
pip install labelme labelimg指针区域
使用labelimg进行BOX标注,标签类别:{'area_p', 'p0', 'p1', 'p2', 'p3', 'p4', 'p5', 'p6', 'p7', 'p8', 'p9'},p0~p9为最低位x0.001标签类别,area_p为其他高位指针区域标签类别。
示例:

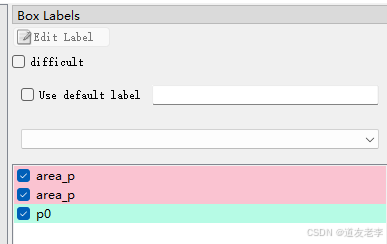
标签文件是VOC XML文件数据,后面再通过脚本转换成YOLO格式数据。
梅花针分割
使用labelme进行实例切割,标签类别:{'pointer', 'circle_area'},pointer是红色梅花针区域,circel_area是刻度圆。
示例:

标签文件是JSON格式文件数据,后面再通过脚本转换成YOLO格式数据。
字轮区域
使用labelimg进行BOX标注,标签类别:{'d0', 'd1', 'd2', 'd3', 'd4', 'd5', 'd6', 'd7', 'd8', 'd9', 'd10', 'd11', 'd12', 'd13', 'd14', 'd15', 'd16', 'd17', 'd18', 'd19'},d0~9表示数字刚好在字轮窗口中心位置,也就是非过渡状态,d10~19表示各个数字的过渡状态。
示例:


标签文件是VOC XML文件数据,后面再通过脚本转换成YOLO格式数据。
数据划分
在深度学习中,训练集和验证集是用于模型开发过程中的两个重要数据集。它们各自扮演着不同的角色,确保最终模型的性能和泛化能力。
训练集(Training Set)
- 用途:训练集主要用于训练模型。即,在这个数据集上调整模型的权重或参数,使模型能够学习到数据中的特征和模式。
- 特点:通常包含大量带标签的数据样本,这些数据样本应该尽可能地代表实际应用环境中的数据分布。
- 影响:如果训练集的质量不高(如数据量不足、标注不准确或偏差),可能会导致模型过拟合或欠拟合,从而影响其性能。
验证集(Validation Set)
- 用途:验证集用于在训练过程中评估模型的表现,帮助选择模型的最佳配置(例如,超参数调优)。它提供了一个独立于训练集的反馈机制,用以监测模型是否开始过拟合训练数据。
- 特点:与训练集类似,验证集也应该是有代表性的,并且它的标签也是已知的。但是,它不应该被用来直接更新模型参数;相反,它是用来决定何时停止训练(早停法)或选择最佳模型架构/超参数。
- 影响:通过验证集可以有效防止过拟合,确保模型不仅在训练数据上表现良好,而且在未见过的数据上也能保持良好的性能。
注意事项
- 划分比例:常见的是将数据划分为70%训练集和30%验证集,或者采用交叉验证的方法来更充分利用有限的数据。具体的比例可以根据实际情况调整。
- 测试集:除了训练集和验证集之外,有时还会有一个测试集(Test Set),用于最终评估模型的真实性能。测试集在整个训练和验证过程中都应该保持完全独立,直到最后评估时才使用。
正确管理和使用训练集和验证集对于构建一个有效的深度学习模型至关重要。这有助于确保模型不仅能很好地适应训练数据,还能对新数据做出准确预测。
数据划分代码:
import argparse
import os
import random
from os import getcwd
# root = getcwd() + '\\my_datas\\pointer-seg\\'
root = getcwd() + '\\my_datas\\detect-pointer\\'
# root = getcwd() + '\\my_datas\\detect-digit\\'
parser = argparse.ArgumentParser()
parser.add_argument('--img_path', default='IMAGES', type=str,
help='input images file path')
parser.add_argument('--txt_path', default='TXT_LABELS', type=str,
help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
imgfilepath = root + opt.img_path
txtsavepath = root + opt.txt_path
total_img = os.listdir(imgfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_img)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
try:
os.remove(txtsavepath + '/trainval.txt')
os.remove(txtsavepath + '/train.txt')
os.remove(txtsavepath + '/valid.txt')
except:
pass
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/valid.txt', 'w')
for i in list_index:
name = total_img[i] + '\n'
if i in trainval:
file_trainval.write(imgfilepath + '/' + name)
if i in train:
file_train.write(imgfilepath + '/' + name)
else:
file_val.write(imgfilepath + '/' + name)
file_trainval.close()
file_train.close()
file_val.close()
IMAGES为所有需要学习的数据图片目录
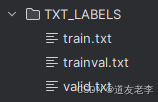
数据转换
VOC XML 转 YOLO
import os
import shutil
import xml.etree.ElementTree as ET
from tqdm import tqdm
sets = ['train', 'valid']
project_name = 'detect-pointer'
classes = ['area_p', 'p0', 'p1', 'p2', 'p3', 'p4', 'p5', 'p6', 'p7', 'p8', 'p9']
# project_name = 'detect-digit'
# classes = ['d0', 'd1', 'd2', 'd3', 'd4', 'd5', 'd6', 'd7', 'd8', 'd9',
# 'd10', 'd11', 'd12', 'd13', 'd14', 'd15', 'd16', 'd17', 'd18', 'd19']
abs_path = os.getcwd()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id, image_set):
in_file = open(r'my_datas\%s\ANNOTATIONS\%s.xml' % (project_name, image_id), encoding='UTF-8')
out_file = open(r'my_datas\%s\%s\labels\%s.txt' % (project_name, image_set, image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# 删除文件夹中所有文件
def del_all_file(path):
for root, dirs, files in os.walk(path):
for f in files:
os.remove(os.path.join(root, f))
del_all_file(f'my_datas\\{project_name}\\train\images')
print('train\images delete success.')
del_all_file(f'my_datas\\{project_name}\\train\labels')
print('train\labels delete success.')
del_all_file(f'my_datas\\{project_name}\\valid\images')
print('valid\images delete success.')
del_all_file(f'my_datas\\{project_name}\\valid\labels')
print('valid\labels delete success.')
for image_set in sets:
image_files = open(
r'my_datas\%s\TXT_LABELS\%s.txt' % (project_name, image_set)).read().strip().split()
for image_file in tqdm(image_files):
image_id = os.path.basename(image_file)[:-4]
convert_annotation(image_id, image_set)
shutil.copyfile(image_file, r'my_datas\%s\%s\images\%s' % (project_name,
image_set, os.path.basename(image_file)))

JSON 转 YOLO
import json
import os
import shutil
from tqdm import tqdm
import numpy as np
project_name = 'pointer-seg'
sets = ['train', 'valid']
classes = ['pointer', 'circle_area']
abs_path = os.getcwd()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def pointer_distance(x1, y1, x2, y2):
dis = np.sqrt((x2 - x1) ** 2 + (y2 - y1) ** 2)
return dis
def json_to_yolo(path):
with open(path, encoding='UTF-8') as f:
labelme_data = json.load(f)
width = labelme_data["imageWidth"]
height = labelme_data["imageHeight"]
yolo_lines = []
for shape in labelme_data["shapes"]:
if shape['shape_type'] == 'polygon':
# 多边形
label = shape["label"]
points = shape["points"]
class_idx = classes.index(label)
txt_string = f"{class_idx} "
for x, y in points:
x /= width
y /= height
txt_string += f"{x} {y} "
yolo_lines.append(txt_string.strip() + "\n")
elif shape['shape_type'] == 'circle':
# 圆
label = shape["label"]
points = shape["points"]
class_idx = classes.index(label)
txt_string = f"{class_idx} "
# 圆心
a, b = points[0]
# 计算半径
r = pointer_distance(a, b, points[1][0], points[1][1])
# 生成一些在圆上的点
X = np.linspace(a - r, a + r - 1, 15)
f = lambda x: np.sqrt(r ** 2 - (x - a) ** 2) + b
y1 = f(X)
y2 = 2 * b - y1
c_points = []
for i, x in enumerate(X):
c_points.append([x, y1[i]])
c_points.append([x, y2[i]])
for x, y in c_points:
x /= width
y /= height
txt_string += f"{x} {y} "
yolo_lines.append(txt_string.strip() + "\n")
return yolo_lines
def convert_annotation(image_id, image_set):
lines = json_to_yolo(r'my_datas\%s\ANNOTATIONS\%s.json' % (project_name, image_id))
with open(r'my_datas\%s\%s\labels\%s.txt' % (project_name, image_set, image_id), 'w') as out_file:
out_file.writelines(lines)
def del_all_file(path):
for root, dirs, files in os.walk(path):
for f in files:
os.remove(os.path.join(root, f))
del_all_file(f'my_datas\\{project_name}\\train\images')
print('train\images delete success.')
del_all_file(f'my_datas\\{project_name}\\train\labels')
print('train\labels delete success.')
del_all_file(f'my_datas\\{project_name}\\valid\images')
print('valid\images delete success.')
del_all_file(f'my_datas\\{project_name}\\valid\labels')
print('valid\labels delete success.')
for image_set in sets:
image_files = open(
r'my_datas\%s\TXT_LABELS\%s.txt' % (project_name, image_set)).read().strip().split()
for image_file in tqdm(image_files):
image_id = os.path.basename(image_file)[:-4]
convert_annotation(image_id, image_set)
shutil.copyfile(image_file, r'my_datas\%s\%s\images\%s' % (project_name,
image_set, os.path.basename(image_file)))
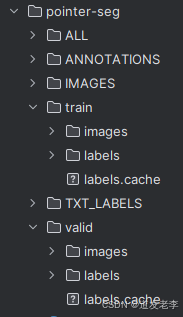
完整目录结构:
至此,用于深度学习所需的所有训练、验证数据已准备好,下一篇开始基于Utralytics YOLO系列进行训练和预测。