NLP-大语言模型学习系列目录
一、注意力机制基础——RNN,Seq2Seq等基础知识
二、注意力机制【Self-Attention,自注意力模型】
三、Transformer图文详解【Attention is all you need】
四、大语言模型的Scaling Law【Power Low】
文章目录
一、什么是 Scaling Law
Scaling Law(缩放法则)是人工智能和机器学习中一类理论,它描述了随着模型规模(例如参数数量)、训练数据量、计算资源的增加,模型性能如何提升的规律。简单来说,Scaling Law 研究的是模型性能与模型规模之间的关系。
定义【Scaling Law】1
在生成模型中被广泛观察到的现象,对于计算量C,模型参数量N和数据大小D,当不受另外两个因素影响时,模型的性能与每个因素都呈幂律关系:
- 性能 ∝ N α \propto N^{\alpha} ∝Nα
- 性能 ∝ D β \propto D^{\beta} ∝Dβ
- 性能 ∝ C γ \propto C^{\gamma} ∝Cγ
这些公式中的 α、β、γ 是对应维度的缩放指数。通常模型性能可以用Test Loss来表示,Loss越小说明模型性能越好。
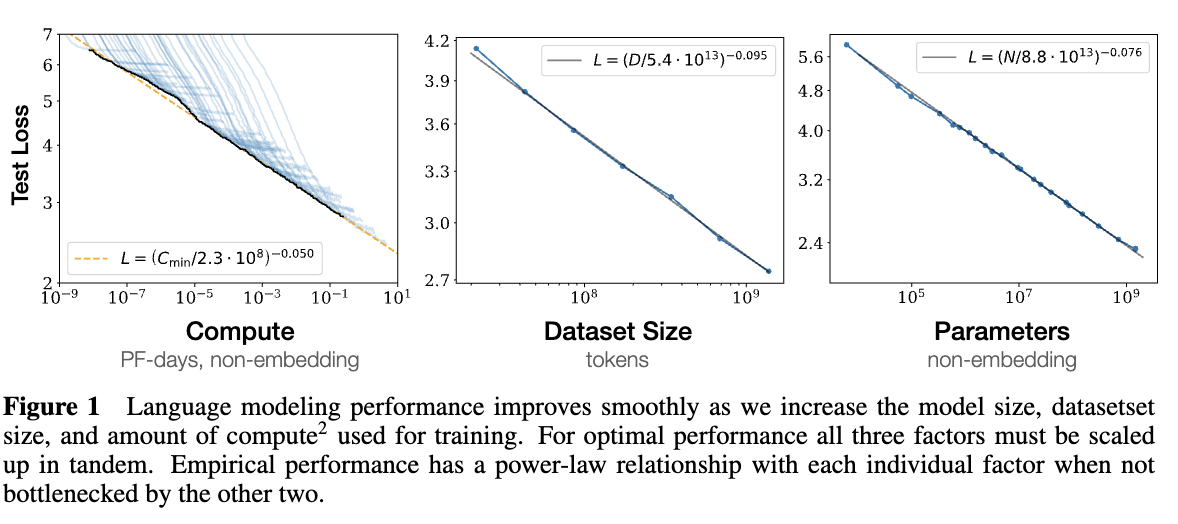
Scaling Law背后的基本思想是:模型的性能可以通过简单的扩展(例如增加模型参数、训练数据或计算资源)来不断提升,并且这种提升往往遵循一定的幂律关系。通过研究这种关系,研究者可以预测模型在不同规模下的性能表现,指导大模型的设计和训练。
二、 Scaling Law的应用
Scaling Law总结出来的一个规律是:
C
≈
6
N
D
C\approx6ND
C≈6ND
其中C是计算量,N是参数量,D是训练数据量。举个例子:
假设一个模型有 10亿个参数( N = 1 0 9 N=10^9 N=109 ), 并且训练数据集的规模是 D = 1 0 12 \mathrm{D}=10^{12} D=1012 (1万亿个 token).使用公式 C = 6ND, 总的计算量就是:
C = 6 × 1 0 9 × 1 0 12 = 6 × 1 0 21 F L O P s C=6 \times 10^9 \times 10^{12}=6 \times 10^{21} \mathrm{FLOPs} C=6×109×1012=6×1021FLOPs
这表明要训练这个模型, 大约需要 6 × 1 0 21 6\times 10^{21} 6×1021 次浮点运算。
这个规律有什么用呢?通过前面的Scaling Law我们知道,训练大模型时,增加模型的参数量或者训练的数据量,模型性能会得到提升。但是我们并不能无止境的增加,因为现实训练模型收到计算量的制约,训练一个语言大模型是很费钱的。所以当给定一个计算量budget,我们怎么分配N和D得到一个最好的模型呢?

(1)最佳模型参数,数据量求解方法
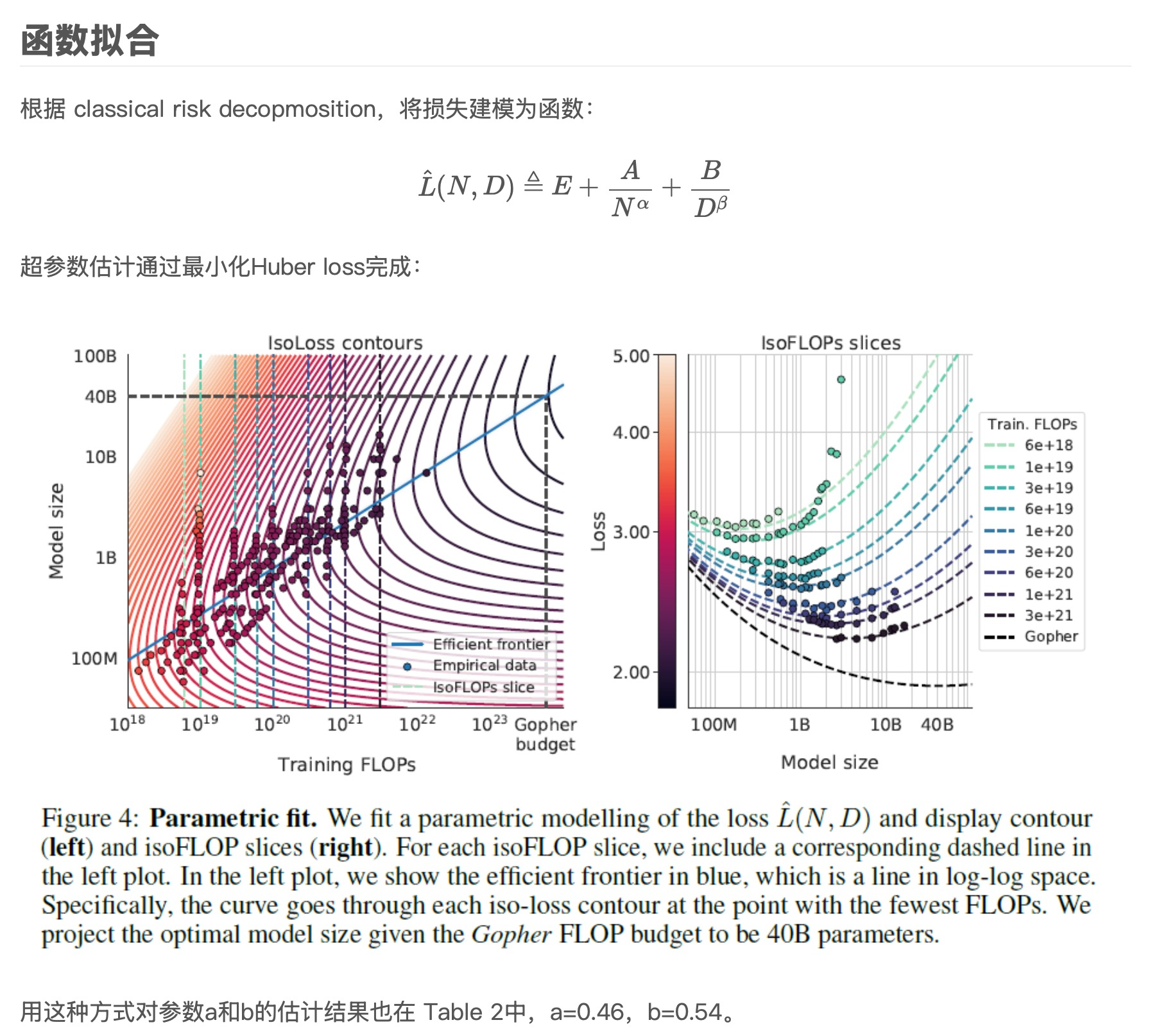
上面的问题可以建模为如下的优化问题:
N o p t ( C ) , D o p t ( C ) = argmin N , D s.t. FLOPs ( N , D ) = C L ( N , D ) , L ^ ( N , D ) ≜ E + A N α + B D β . N_{opt}(C),D_{opt}(C)=\underset{N,D\text{ s.t. FLOPs}(N,D)=C}{\operatorname*{argmin}}L(N,D),\\ \hat{L}(N,D)\triangleq E+\frac A{N^\alpha}+\frac B{D^\beta}. Nopt(C),Dopt(C)=N,D s.t. FLOPs(N,D)=CargminL(N,D),L^(N,D)≜E+NαA+DβB.
这个多变量问题怎么解呢?主要有三种方法:
- 固定模型大小,改变训练数据
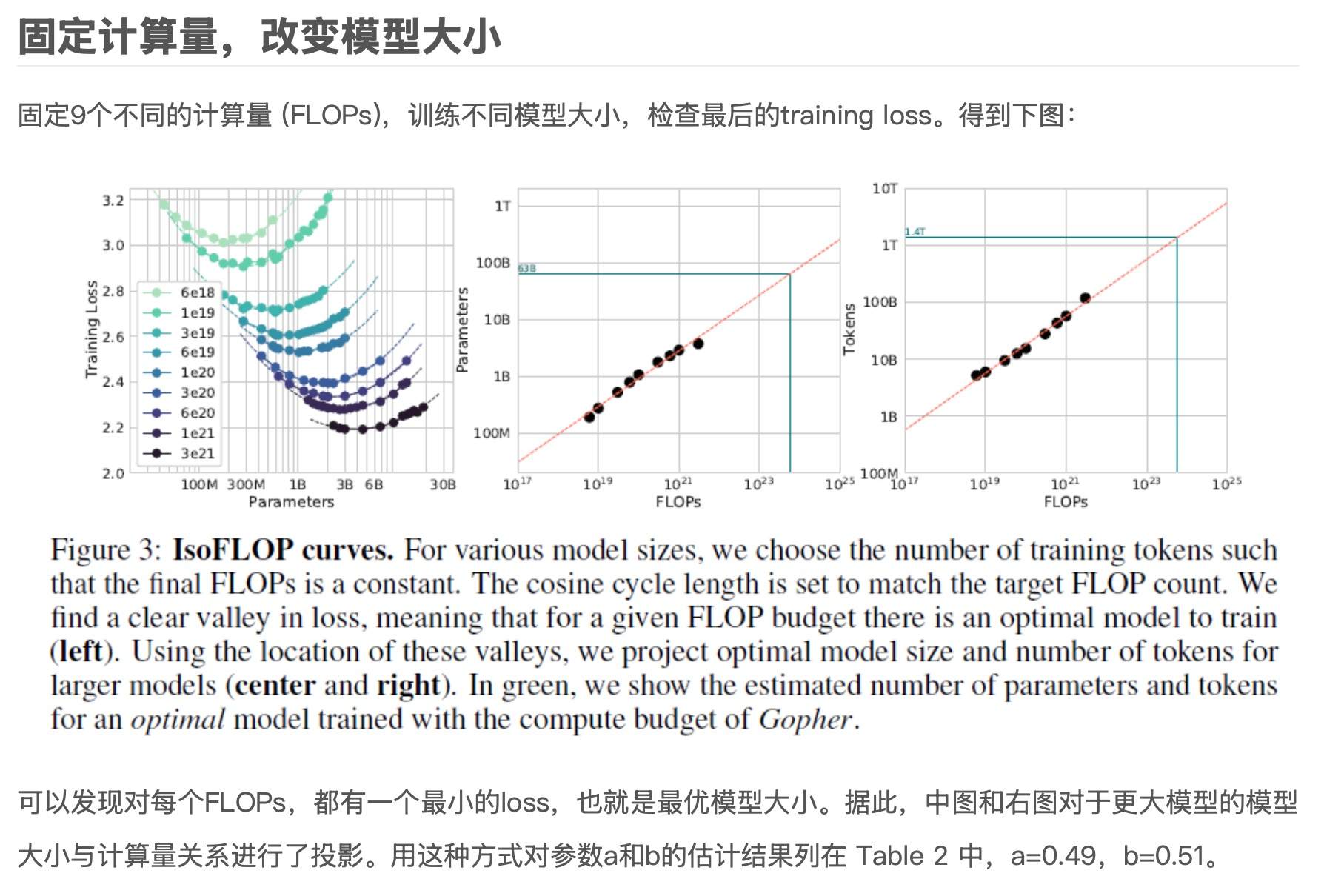
- 固定计算量,改变模型大小
- 拟合幂律曲线
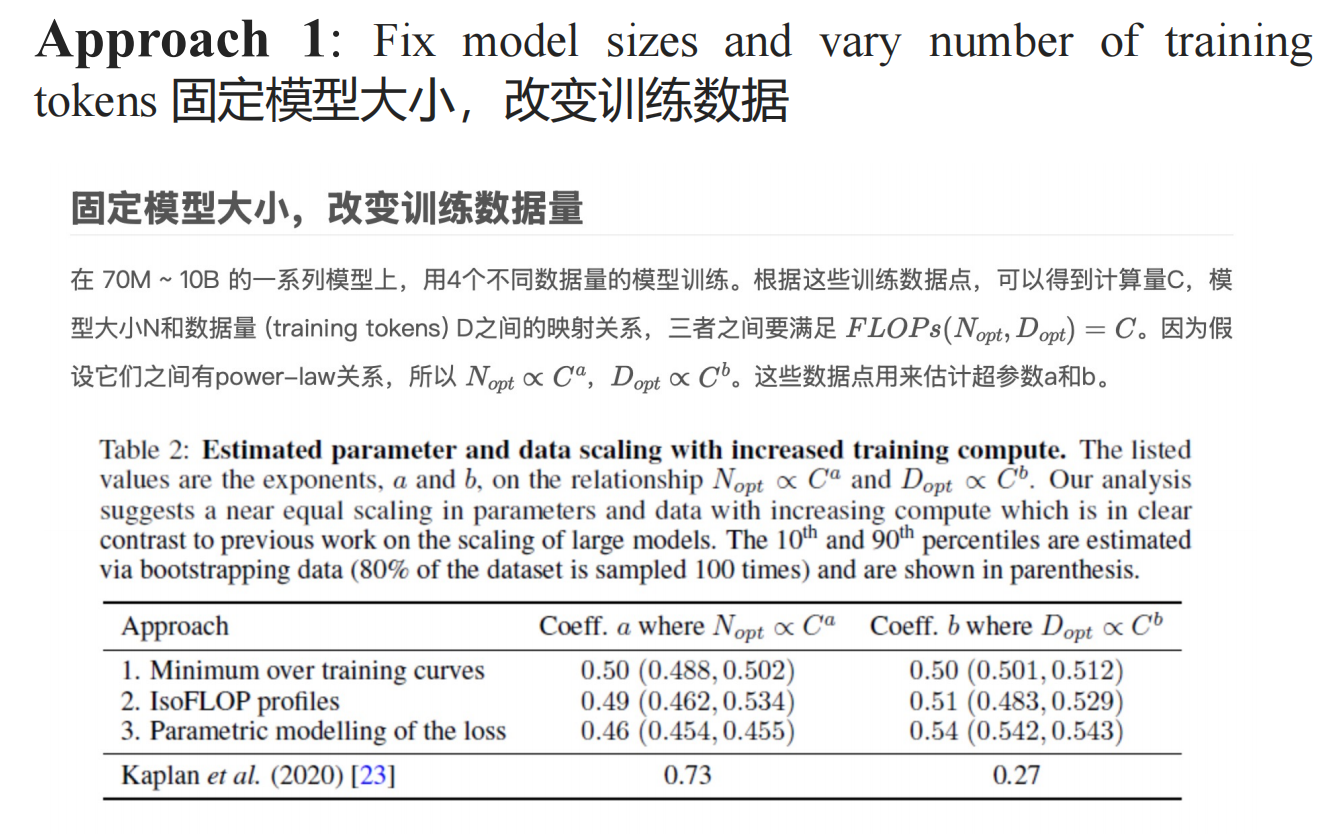
根据上表的结果,得出a=0.5,b=0.5

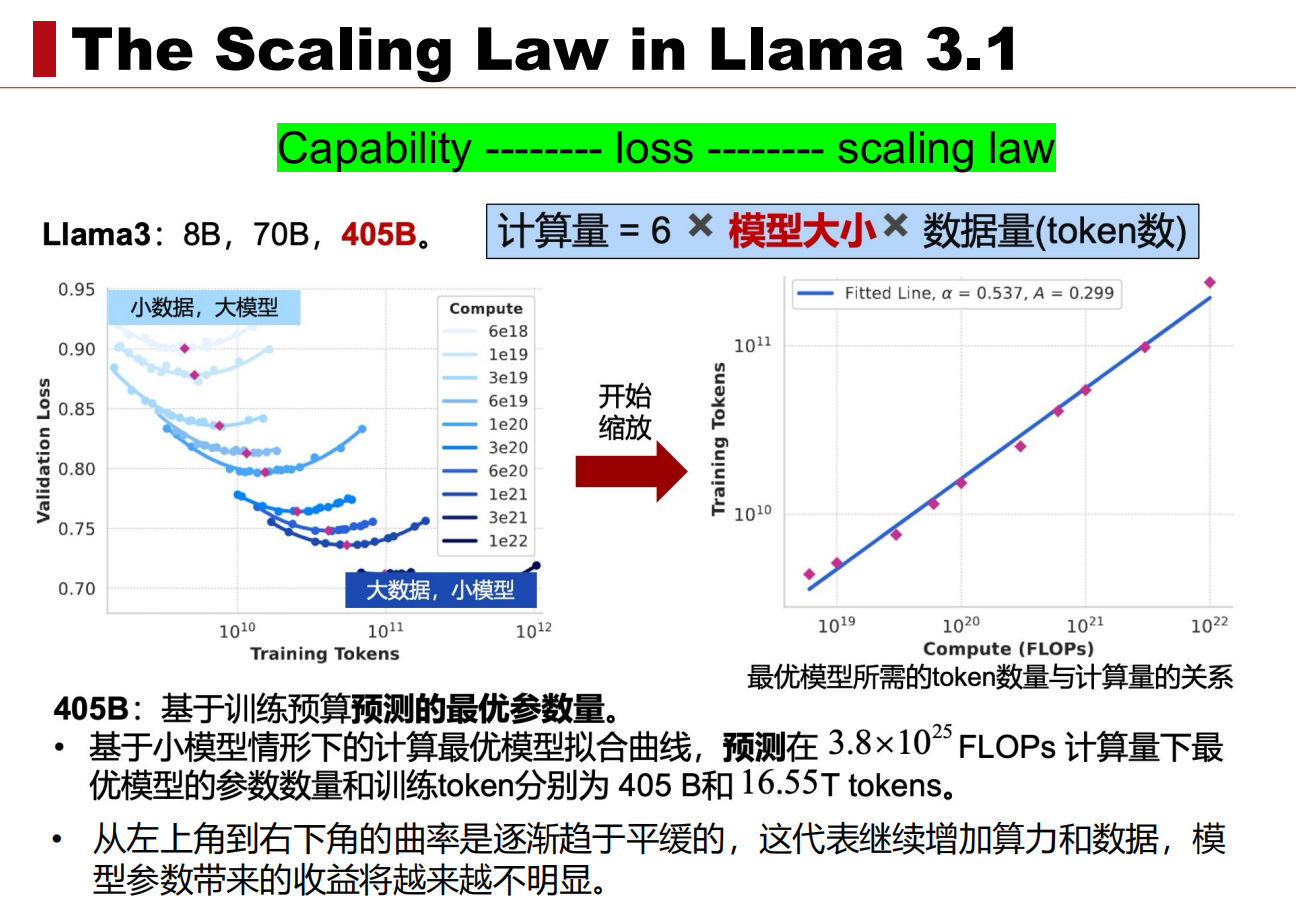
(2)LLaMA3.1中的Scaling Law
如下图所示,是LLaMA3.1中的Scaling Law,LLaMA3.1发布了3个模型,分别是8B,70B,405B.这个405B是怎么定下来的呢,难道是领导拍脑袋想出来的吗(国内可能是hh).显然他们做了实验,先在小数据和小模型上进行实验(左图),然后根据实验结果画出Scaling Law曲线,找到对应计算量的最优模型大小和最优训练数据量。
(3)计算实例【根据计算量和数据量,求最佳模型大小】
例:
- 假设你有1000张H100显卡,并且可以用6个月。
- 假设你有10T的数据。
- 那么你应该训练多大的模型?

另一种更快的估计方法:

三、未来挑战
尽管 Scaling Law 提供了重要的理论指导,仍然存在一些挑战:
- 计算成本问题:大规模扩展模型的参数和训练数据通常需要极高的计算成本。虽然 Scaling Law 提供了理论依据,但大规模训练的实际成本可能难以承受。
- 数据质量:Scaling Law 假设数据量的增加会提升模型性能,但在实际应用中,数据的质量同样至关重要,低质量数据可能会导致性能下降甚至模型偏差。
- 性能饱和:Scaling Law 研究表明,性能提升并不是无限的,通常会在某个点达到瓶颈。因此,研究者需要找到其他方法(如新架构、知识蒸馏)来进一步提高性能。
参考资料
Scaling Laws for Neural Language Models【paper】 ↩︎